【慢SQL性能优化】 一条SQL的生命周期 | 京东物流技术团队
一、 一条简单SQL在MySQL执行过程
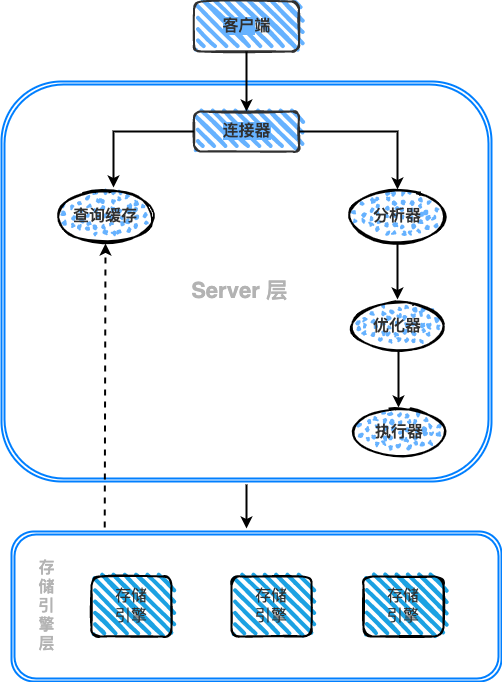
一张简单的图说明下,MySQL架构有哪些组件和组建间关系,接下来给大家用SQL语句分析
例如如下SQL语句
SELECT department_id FROM employee WHERE name = 'Lucy' AND age > 18
GROUP BY department_id其中name为索引,我们按照时间顺序来分析一下
-
客户端:如MySQL命令行工具、Navicat、DBeaver或其他应用程序发送SQL查询到MySQL服务器。
-
连接器:负责与客户端建立连接、管理连接和维护连接。当客户端连接到
MySQL服务器时,连接器验证客户端的用户名和密码,然后分配一个线程来处理客户端的请求。 -
查询缓存:查询缓存用于缓存先前执行过的查询及其结果。当收到新的查询请求时,
MySQL首先检查查询缓存中是否已有相同的查询及其结果。如果查询缓存中有匹配的查询结果,MySQL将直接返回缓存的结果,而无需再次执行查询。但是,如果查询缓存中没有匹配的查询结果,MySQL将继续执行查询。 -
分析器:
◦ 解析查询语句,检查语法。
◦ 验证表名和列名的正确性。
◦ 生成查询树。
-
优化器:分析查询树,考虑各种执行计划,估算不同执行计划的成本,选择最佳的执行计划。在这个例子中,优化器可能会选择使用
name索引进行查询,因为name是索引列。 -
执行器:根据优化器选择的执行计划,向存储引擎发送请求,获取满足条件的数据行。
-
存储引擎(如
InnoDB):
◦ 负责实际执行索引扫描,如在employee表的name索引上进行等值查询,因查询全部列,涉及到回表访问磁盘。
◦ 在访问磁盘之前,先检查InnoDB的缓冲池(Buffer Pool)中是否已有所需的数据页。如果缓冲池中有符合条件的数据页,直接使用缓存的数据。如果缓冲池中没有所需的数据页,从磁盘加载数据页到缓冲池中。
- 执行器:
◦ 对于每个找到的记录,再次判断记录是否满足索引条件name。这是因为基于索引条件加载到内存中是数据页,数据页中也有可能包含不满足索引条件的记录,所以还要再判断一次name条件,满足name条件则继续判断age > 18过滤条件。
◦ 根据department_id对满足条件的记录进行分组。
◦ 执行器将处理后的结果集返回给客户端。
在整个查询执行过程中,这些组件共同协作以高效地执行查询。客户端负责发送查询,连接器管理客户端连接,查询缓存尝试重用先前查询结果,解析器负责解析查询,优化器选择最佳执行计划,执行器执行优化器选择的计划,存储引擎(如InnoDB)负责管理数据存储和访问。这些组件的协同作用使得MySQL能够高效地执行查询并返回结果集。
根据索引列过滤条件加载索引的数据页到内存这个操作是存储引擎做的。加载到内存中之后,执行器会进行索引列和非索引列的过滤条件判断。
二、 查询SQL关键字执行顺序
执行顺序,如下:
1、对存储引擎的操作
(1)FROM:用于查询SQL的数据表。执行器会根据优化器选择的执行计划从存储引擎中获取相关表的数据。
(2)ON: 与JOIN一起使用,用于指定连接条件。执行器会根据ON给定的条件条件从存储引擎获取匹配条件的记录。如果连接条件涉及到索引列,存储引擎会使用索引进行优化。
(3)JOIN:指定表之间连接方式(如INNER JOIN,LEFT JOIN等)。执行器会根据优化器选择的执行计划,从存储引擎中获取连接表数据。然后执行器根据JOIN连接类型和ON连接条件,对数据连接处理。
(4)WHERE:执行器对从存储引擎返回的数据进行过滤,只保留满足WHERE子句条件的记录。过滤条件如有索引,存储引擎层会通过索引过滤后返回。
2、对返回结果集的操作
(5)GROUP BY:执行器对满足WHERE条件的记录按照GROUP BY指定的列分组。
(6)HAVING:执行器在执行分组后,根据HAVING条件对分组后的记录再次过滤。
(7)SELECT:执行器根据优化器选择的执行计划和指定列获取查询结果。
(8)DISTINCT:执行器对查询结果进行去重,只返回不重复的记录。
(9)ORDER BY:执行器对查询结果按照ORDER BY子句中指定的列进行排序。
(10)LIMIT:执行器根据LIMIT子句中指定的限制条件对查询结果进行截断,只返回部分记录
三、表关联查询SQL在MySQL中的执行过程
SELECT s.id, s.name, s.age, es.subject, es.score
FROM employee s JOIN employee_score es ON s.id = es.employee_id
WHERE s.age >18 AND es.subject_id =3 AND es.score >80;这个例子中,subject_id和score是联合索引,age是索引。 我们按照时间顺序来分析一下
-
连接器:当客户端连接到
MySQL服务器时,连接器负责建立和管理连接。它验证客户端提供的用户名和密码,确定客户端具有相应的权限,然后建立连接。 -
查询缓存:
MySQL服务器在处理查询之前,会先检查查询缓存。如果查询缓存中已经存在该结果集,服务器将直接返回缓存中的结果。 -
解析器:解析并检查
SQL语法正确性。解析器会将查询语句分解成多个组成部分,例如表、列、条件等。在这个示例中,解析器会识别出涉及的表(employee和employee_score)以及需要的列(id、name、age、subject、score)。 -
优化器:根据解析器提供的信息生成执行计划。优化器会分析多种可能的执行策略,并选择成本最低的策略。在这个示例中,优化器会选择
age索引和subject_id与score的联合索引。对于连接操作,优化器还要决定连接策略,例如是否使用Nested-Loop Join或Hash Join等一些连接策略。优化器还会根据表的大小、索引、查询条件和统计信息来决定哪张表作为驱动表,以及选择最佳的连接策略。例如,如果两个表的大小差异很大,**Nested-Loop Join**可能是一个好的选择,而对于大小相似的两个表,**Hash Join**或**Sort-Merge Join**可能更加高效。 -
执行器:根据优化器生成的执行计划执行查询,向存储引擎发送请求,获取满足条件的数据行。
-
存储引擎(如
InnoDB):管理数据存储和检索。存储引擎首先接收来自执行器的请求,该请求可能是基于优化器的执行计划。
◦ 存储引擎首先接收来自执行器的请求。请求可能包括获取满足查询条件的数据行,以及使用哪种扫描方法(如全表扫描或索引扫描)。
◦ 假设执行器已经决定使用索引扫描。在这个示例中,存储引擎可能会先对employee表进行索引扫描(使用age索引),然后对employee_score表进行索引扫描(使用subject_id和score的联合索引)。
◦ 存储引擎会根据请求查询相应的索引。在employee索引中会找到满足age > 18条件的记录。在employee_score索引中找到满足subject_id = 3 AND score > 80条件的记录。
◦ 一旦找到了满足条件的记录,存储引擎需要将这些记录所在的数据页从磁盘加载到内存中。存储引擎首先检查缓冲池(InnoDB Buffer Pool),看这些数据页是否已经存在于内存中。如果已经存在,则无需再次从磁盘加载。如果不存在,存储引擎会将这些数据页从磁盘加载到缓冲池中。
◦ 加载到缓冲池中的记录可以被多个查询共享,这有助于提高查询效率。
- 执行器:处理连接、排序、聚合、过滤等操作。
◦ 在内存中执行连接操作,将employee表和employee_score表的数据行连接起来。
◦ 对连接后的结果集进行过滤,只保留满足查询条件(age > 18、subject_id = 3、score > 80)的数据行。
◦ 将过滤后的数据行作为查询结果返回给客户端。
前面说过,根据存储引擎根据索引条件加载到内存的数据页有多数据,可能有不满足索引条件的数据,如果执行器不再次进行索引条件判断, 则无法判断哪些记录满足索引条件的,虽然在存储引擎判断过了,但是在执行器还是会有索引条件
age > 18、subject_id = 3、score > 80的判断。
我们再以全局视野来分析一下
- 确定驱动表: 首先,
MySQL优化器会选择一个表作为"驱动表"。通常,返回记录数较少的表会被选为驱动表。假设employee_score表中满足subject_id = 3 AND score > 80条件的记录数量较少,那么这张表可能被选为驱动表。这是优化器的工作,它预估哪个表作为驱动表更为高效,制定执行计划。虽然驱动表的选择很大程度上是基于预估的返回记录数,但实际选择还会受其他因素影响,例如表之间的连接类型、可用的索引等。 - 使用驱动表的索引进行筛选: 优化器会首先对驱动表进行筛选。如果
employee_score是驱动表,优化器会使用subject_id和score的联合索引来筛选出subject_id = 3 AND score > 80的记录。这是执行器按照优化器的计划向存储引擎发出请求,获取需要的数据。存储引擎负责访问索引,并根据索引定位到实际的数据页,从而获取数据行。 - 连接操作: 执行器会基于上一步从驱动表中筛选出的记录对另一个表(即
employee表)进行连接。这时,执行器会使用employee表上的索引(如id索引)来高效地找到匹配的记录。 - 进一步的筛选: 在连接的过程中,执行器会考虑
employee表的其他筛选条件,如age > 18,通常连接后才过滤筛选,这也是执行器的工作,执行器在连接过程中或之后,根据优化器制定的计划进一步筛选结果集。但是这里employee表的age索引其叶子节点包含age和主键id信息,在进行连接时,可以直接按照age范围扫描该索引,利用其叶子节点中的id信息进行高效的JOIN操作,因此在连接时就完成筛选,这个过程由MySQL优化器自动完成。从上面可以看到,当存在可以被利用的索引时,MySQL可以在连接过程中执行这些过滤操作。 - 返回结果: 这是执行器最后的步骤,返回最终的查询结果。
四、总结
本文采用一张简单的架构图说明了MySQL查询中使用的组件和组件间关系。
解析了一条sql语句从客户端请求mysql服务器到返回给客户端的整个生命周期流程。
列举了单表sql、关联表sql 两种不同SQL在整个生命周期中的执行顺序和及内部组件逻辑关系。
通过如上案例的解析可以让开发者们掌握到单表sql、关联表sql的底层sql知识,为理解慢sql的产生和优化鉴定基础。
作者:京东物流 高峰
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
相关文章:
【慢SQL性能优化】 一条SQL的生命周期 | 京东物流技术团队
一、 一条简单SQL在MySQL执行过程 一张简单的图说明下,MySQL架构有哪些组件和组建间关系,接下来给大家用SQL语句分析 例如如下SQL语句 SELECT department_id FROM employee WHERE name Lucy AND age > 18 GROUP BY department_id其中name为索引&a…...

小程序day05
使用npm包 Vant Weapp 类似于前端boostrap和element ui那些的样式框架。 安装过程 注意:这里建议直接去看官网的安装过程。 vant-weapp版本最好也不要指定 在项目目录里面先输入npm init -y 初始化一个包管理配置文件: package.json 使用css变量定制vant主题样式࿰…...
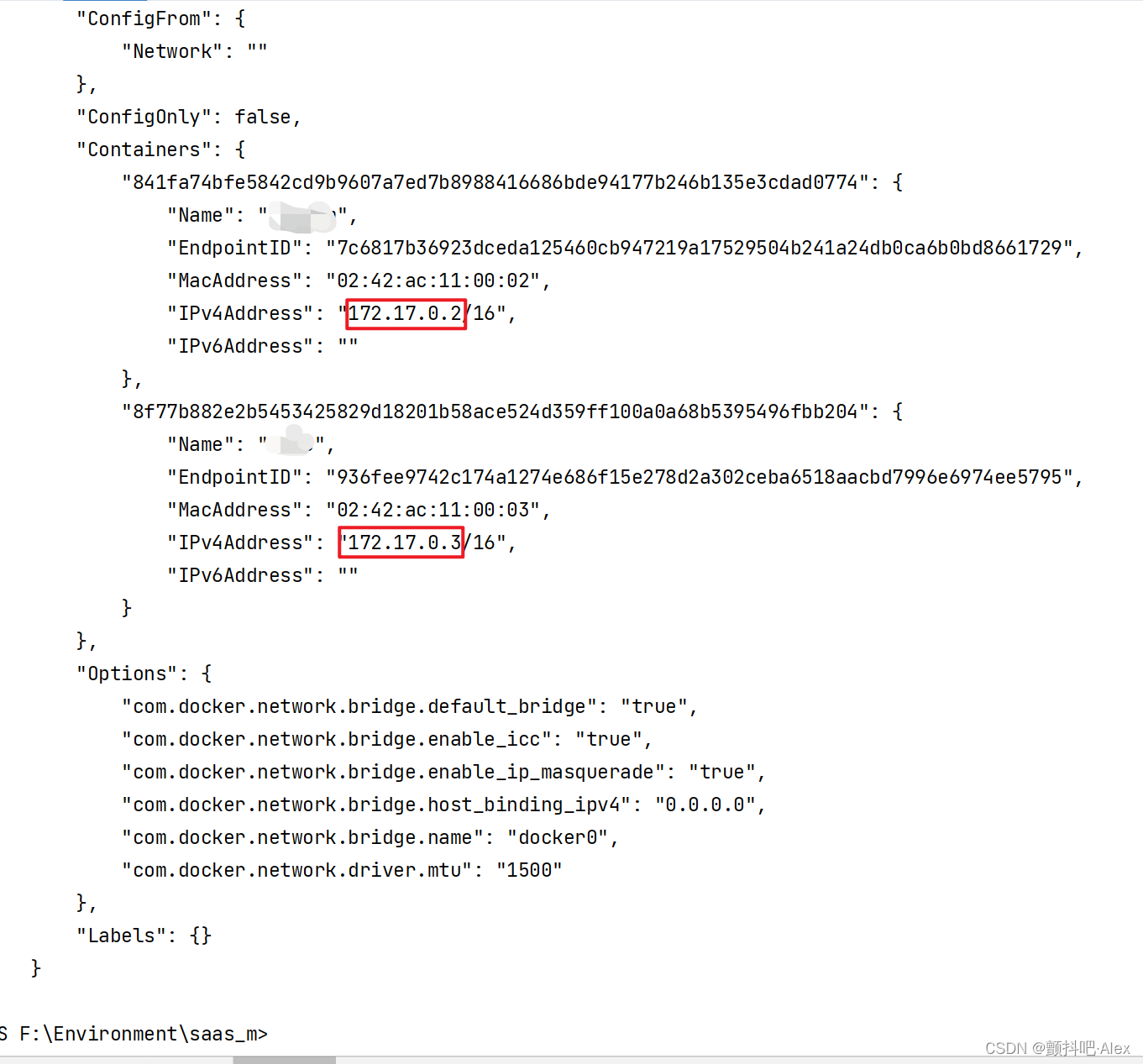
Docker两个容器互相请求接口
BEGIN 环境:Docker-Windows-Hyperf 1. 过以下命令查看Docker中的所有网络 docker network ls这个命令会列出所有的Docker网络,包括其ID、名称、驱动以及作用范围 在 Docker 中,容器通过 Docker 网络进行相互通信;在 Docker 中有…...

UML与PlantUML简介
UML与PlantUML 1、UML与PlantUML概述2、PlantUML使用 1、UML与PlantUML概述 UML(Unified Modeling Language)是一种统一建模语言,为面向对象开发系统的产品进行说明、可视化、和编制文档的一种标准语言,独立于任何具体程序设计语言…...

面试--springboot基础
1、约定优于配置,理解 是一种软件设计的范式,减少开发人员对于配置项的维护,更加聚焦在业务逻辑上 基于spring框架开发web项目,只需要做一次配置 springboot starter启动依赖,帮我们管理jar包版本 当前应用依赖spring…...

“高端化”围城中,方太集团茅忠群的理想与现实
撰稿|行星 来源|贝多财经 “成为一家伟大的企业”,这是深耕厨电领域27年的方太集团(下称“方太”)矢志不渝的宏伟愿景。 在历经厨电行业十余年的高速发展期后,面临市场热度渐退、赛道高手林立的局面,在行业逆流中坚…...

Linux文件管理知识:文本处理
上篇文章详细介绍了Linux系统中查找文件的工具或者命令程序的相关操作内容介绍。那么,今天呢,这篇文章围绕Linux系统中文本处理来阐述。 众所周知,所有Linux操作系统都离不开一个核心原则,那就是它是由很多种文件组成的࿰…...

flink的带状态的RichFlatMapFunction函数使用
背景 使用RichFlatMapFunction可以带状态来决定如何对数据流进行转换,而且这种用法非常常见,根据之前遇到过的某个key的状态来决定再次遇到同样的key时要如何进行数据转换,本文就来简单举个例子说明下RichFlatMapFunction的使用方法 RichFl…...
MySQL的安装使用(入学篇)
目录 1 MySQL安装 1.1 安装epel源 1.2 安装MySQL Repository 1.3 安装MySQL官方yum源 1.4 安装服务端、客户端 1.5 启动MySQL服务 2 MySQL 使用 2.1 获取初始登录密码 2.2 登录MySQL数据库 2.3 修改密码 2.4 退出数据库 2.5 使用新密码登录数据库 2.6 重启数据库 2.7 创建数据…...
面试复习整理
redis持久化方式和原理 Redis持久化是指将Redis内存中的数据以某种形式保存到磁盘上,以保证在Redis重启后数据不会丢失。Redis支持两种持久化方式:RDB(Redis DataBase)和AOF(Append Only File)。 RDB持久…...

第四章 :Spring Boot 配置文件指南
第四章 :Spring Boot 配置文件 前言 本章知识重点:作者结合开发实际经验与应用场景结合,整理了5种获取配置属性的方式。配置文件中获取属性应该是SpringBoot开发中最为常用的功能之一,但是常用的功能,仍然有很多开发者在这个方面踩坑。通过本章节学习在实际中避免一些坑,…...

常用中间件分类
常见的中间件包括: 消息中间件:用于处理应用程序之间的异步消息传递,常见的消息中间件包括 RabbitMQ、Apache Kafka、ActiveMQ 等。 缓存中间件:用于缓存数据以加快访问速度,常见的缓存中间件包括 Redis、Memcached 等…...
中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载
中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件…...

Spring Boot 启动加速
一、简介 本文将带你了解如何通过调整 Spring 应用的配置、JVM 参数和使用 GraalVM 原生镜像来缩短 Spring Boot 的启动时间。 二、调整 Spring 应用 首先,创建一个 Spring Boot(2.5.4)应用,添加 Spring Web、Spring Actuator …...

UDP数据报文格式
...

软考-系统架构-2023-反思
2023年11月4日,参加了软考的高级架构设计考试。针对于这次考试做一些总结和反思。 我的考试准备周期非常长,但是实际的时间非常少。差不多一年前我就开始有这个计划和想法准备考试了,但是前期基本上就是翻翻书,跟没有开始区别并不…...
day52
今日内容概要 web应用程序 手写web框架(帮助我们理解别人写好的成熟框架、重点在于思路的理解、代码无需掌握) Django框架的学习 Python中得主流框架 框架的下载、安装、版本、怎么启动、怎么使用等 三板斧问题 web应用程序 Django框架是一款专门用来开发web应用的框架 …...
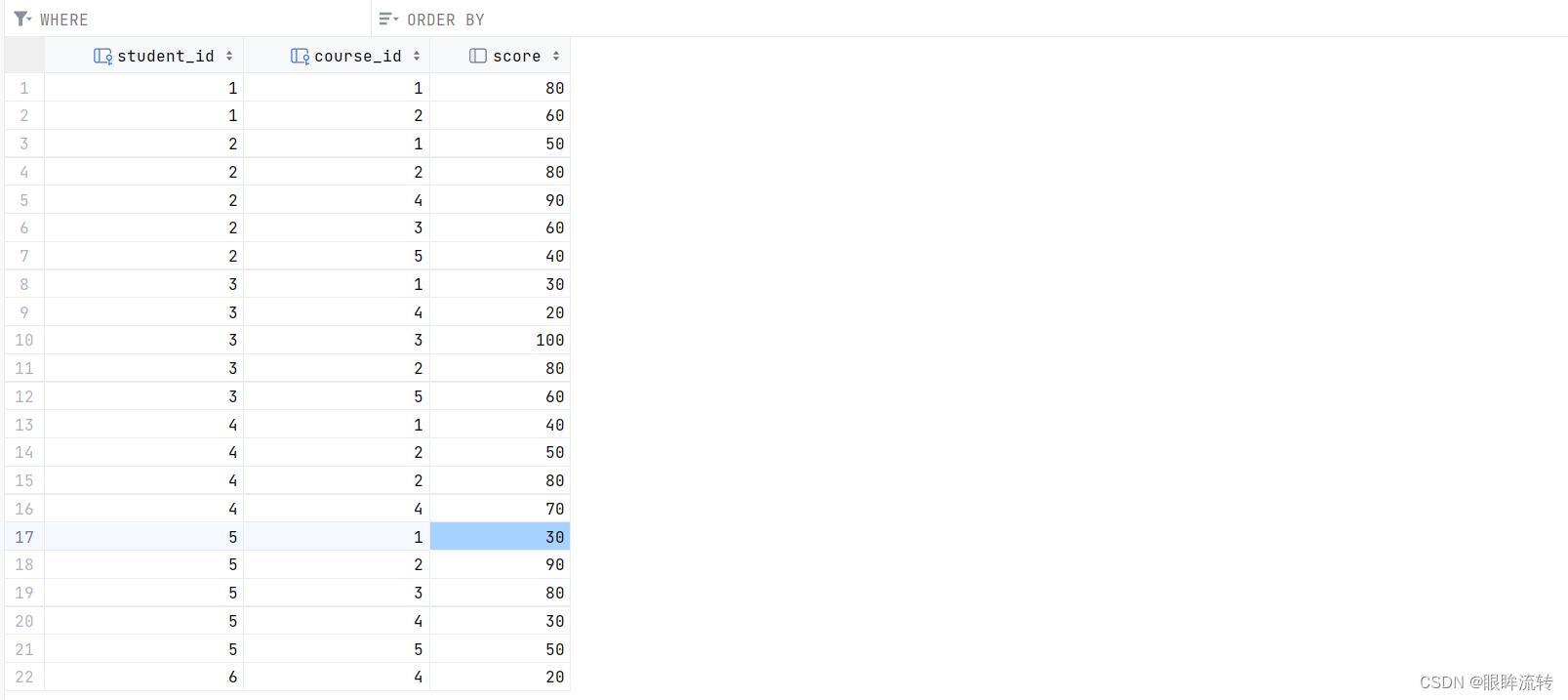
Mysql关联查询
Mysql关联查询 1、数据准备 # 班级表 create table class(id int primary key auto_increment,name varchar(20),description varchar(100) );# 学生表 create table student(id int primary key auto_increment,sn varchar(20),name varchar(20),email varchar(20),class_id…...
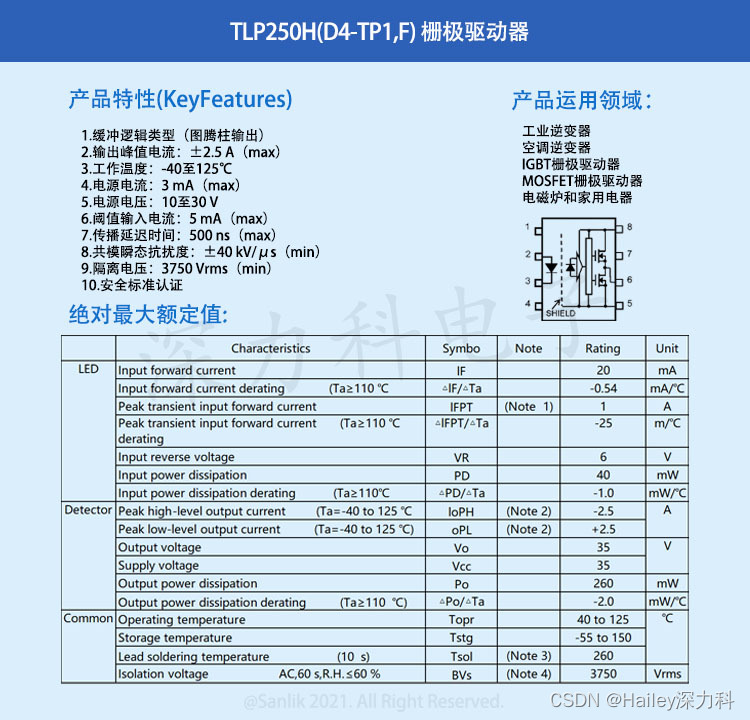
MOSFET和IGBT栅极驱动器TLP250H(D4-TP1,F)电路的基本原理
TLP250H,TLP250H(D4-TP1,F)是SOP8封装中的光电耦合器,由GaA组成ℓ作为红外发光二极管(LED)光学耦合到集成的高增益、高速光电探测器IC芯片。它在高达125℃的温度下提供有保证的性能和规格. TLP250H具有内部法拉第屏蔽,…...
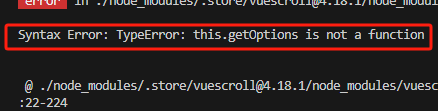
Vue - Syntax Error: TypeError: this.getOptions is not a function 项目运行时报错,详细解决方案
报错问题 关于此问题网上的教程都无法解决,如果您的报错与本文相似,本文即可 100% 完美解决。 在 vue2.js 项目中,执行 npm run serve 运行时出现如下报错信息, Syntax Error: TypeError: this.getOptions is not a function 解决方案 按照以下步骤,即可完美解决。 这个错…...

揭秘智能音乐解锁神器:QMCDecode让QQ音乐加密格式自由播放
揭秘智能音乐解锁神器:QMCDecode让QQ音乐加密格式自由播放 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默…...

终极Windows和Office激活指南:KMS_VL_ALL_AIO完全解决方案
终极Windows和Office激活指南:KMS_VL_ALL_AIO完全解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?Office突然变成只读模式让你束手…...

STM32定时器PWM输出简单总结
PWM输出 脉冲宽度调制模式可以生成一个信号,该信号频率由TIMx_ARR自动重载寄存器值决定,其占空比则由TIMx_CCRx捕获比较寄存器值决定。 通过向TIMx_CCMRx寄存器中的OCxM位写入110(PWM模式1)或111(PWM模式2)…...

把数组排成最小的数-C++
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程https://www.captainai.net/troubleshooter // 面试题45:把数组排成最小的数 // 题目:输入一…...

如何快速解决Windows热键冲突:3步定位占用程序的终极指南
如何快速解决Windows热键冲突:3步定位占用程序的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否…...

FanControl终极配置指南:3步实现Windows风扇精准温控
FanControl终极配置指南:3步实现Windows风扇精准温控 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

告别“跟风学“!AI系统班7大模块,带你从0到1成为全栈开发者
本文指出,AI时代的红利不属于盲目跟风学习者。文章分析了学习者常遇到的四大问题:缺乏规划、理论与实践脱节、学用结合困难、缺少反馈指导。为解决这些问题,作者推荐了一套系统化的AI学习路线,包含7大模块:必备基础、核…...
)
【往届五届全部见刊检索!SPIE出版!大连线下召开】第六届计算机视觉与模式分析国际学术大会 (ICCPA 2026)
2026年第六届计算机视觉与模式分析国际会议(ICCPA 2026)将于2026年5月8-10日在中国大连召开。ICCPA 2026汇集了来自世界各地的计算机视觉与模式分析领域的学者、研究人员、工程师和企业家,旨在搭建一个促进学术交流和成果共享的重要平台&…...

详解CN域名注册:流程、要求、材料及注意事项全解析
CN域名作为中国国家顶级域名,凭借其本土标识和稳定性能,成为深耕国内市场的首选。注册受CNNIC严格监管,遵循规范流程至关重要。本文国科云将系统梳理cn域名注册全流程、核心要求及关键注意事项。一、CN域名注册核心流程CN域名注册遵循“先申请…...

国产SCA工具评测:谁在开源治理赛道上领跑?
在数字化浪潮席卷全球的当下,软件供应链安全已成为国家安全的重要组成部分。近年来,从SolarWinds供应链攻击到Log4j漏洞事件,一系列重大安全事件不断为行业敲响警钟。根据Gartner最新预测,到2026年,全球60%的企业将把软…...