大语言模型(LLM)综述(七):大语言模型设计应用与未来方向
A Survey of Large Language Models
- 前言
- 8 A PRACTICAL GUIDEBOOK OF PROMPT DESIGN
- 8.1 提示创建
- 8.2 结果与分析
- 9 APPLICATIONS
- 10 CONCLUSION AND FUTURE DIRECTIONS
前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示了惊人的潜力。从生成文本和对话系统到更为复杂的任务,如文本摘要、机器翻译和情感分析,LLM正在逐渐改变我们与数字世界的互动方式。
然而,随着模型规模的增加,也出现了一系列挑战和问题,包括但不限于计算复杂性、数据偏见以及模型可解释性。因此,对这些模型进行全面而深入的了解变得至关重要。
本博客旨在提供一个全面的大型语言模型综述,探讨其工作原理、应用范围、优点与局限,以及未来的发展趋势。无论您是该领域的研究者、开发者,还是对人工智能有广泛兴趣的读者,这篇综述都将为您提供宝贵的洞见。
本系列文章内容大部分来自论文《A Survey of Large Language Models》,旨在使读者对大模型系列有一个比较程序化的认识。
论文地址:https://arxiv.org/abs/2303.18223
8 A PRACTICAL GUIDEBOOK OF PROMPT DESIGN
正如在第6节中所讨论的那样,提示是利用LLMs解决各种任务的主要方法。由于提示的质量将在特定任务中对LLMs的性能产生很大影响,我们设置了一个特殊的部分来讨论实际中的提示设计。在本节中,我们首先介绍提示的关键组成部分,并讨论几个提示设计的原则。然后,我们将使用不同的提示来评估ChatGPT,展示在几个代表性任务上的结果。我们知道已经有一些现有的论文[627, 628]和网站[629631]提供了设计良好提示的建议和指南。与之对比,我们主要旨在讨论对提示创建有用的关键因素(成分和原则),并提供初学者参考的流行任务上的实验结果和分析。
8.1 提示创建
创建合适的提示的过程也被称为提示工程 [628, 632]。一个精心设计的提示对于引发LLMs完成特定任务的能力非常有帮助。在这部分中,我们简要总结提示的关键成分,并讨论提示设计的几个基本原则。
关键成分
通常,提示的功能性由四个关键成分来描述,包括任务描述、输入数据、上下文信息和提示样式。为了更直观地理解我们的讨论,我们还在表15中提供了三个提示示例,分别用于问答、元审查生成和文本到SQL。
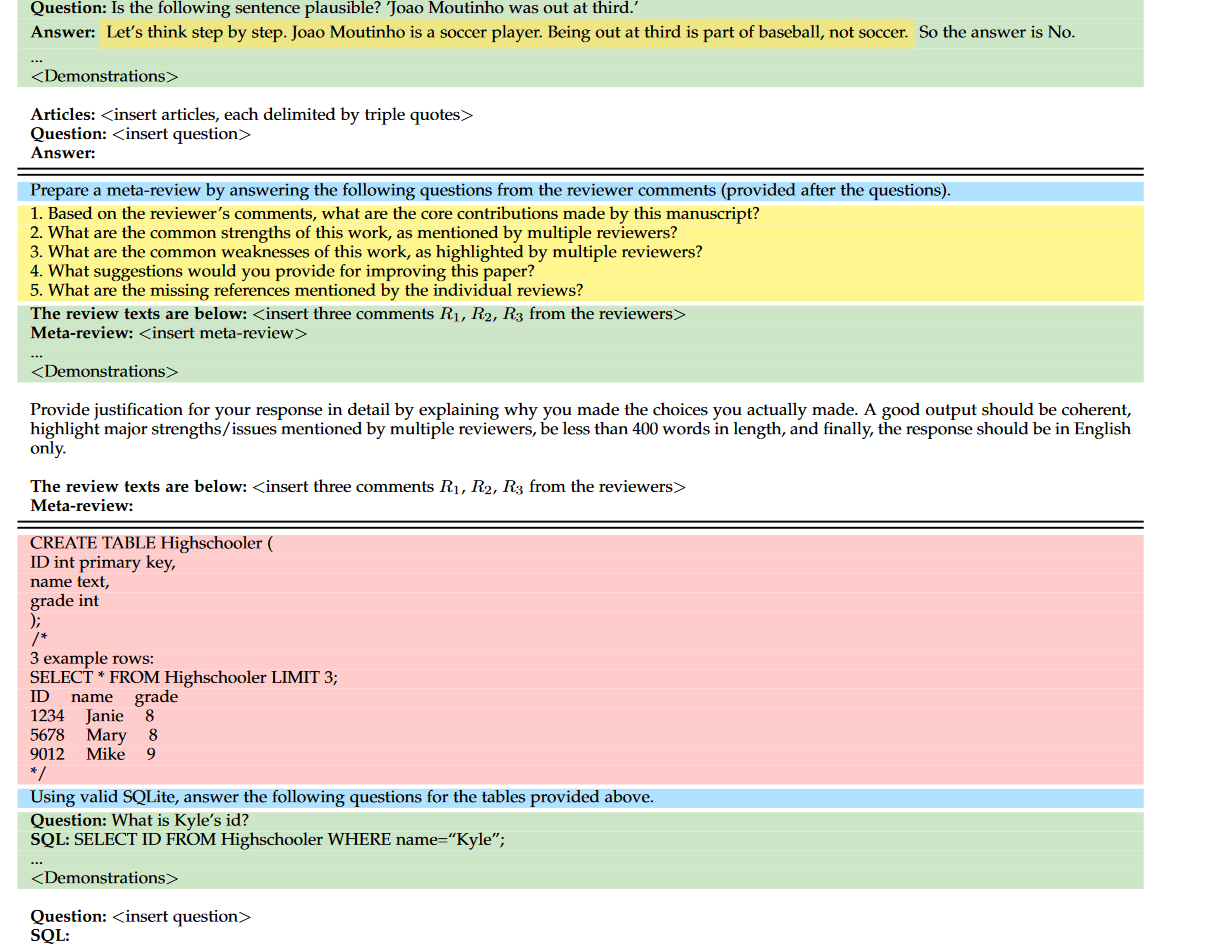
表 15:从 [627, 636] 收集的示例指令。蓝色文本表示任务描述,红色文本表示上下文信息,绿色文本表示演示,金色文本表示提示样式。
• 任务描述。任务描述通常是LLMs预期遵循的具体指令。一般来说,应该用自然语言清楚地描述任务目标。对于具有特殊输入或输出格式的任务,通常需要详细的说明,可以进一步利用关键词来突出特殊设置,以更好地引导LLMs完成任务。
• 输入数据。在常见情况下,用自然语言描述输入数据(例如,LLMs要回应的一个实例)是直截了当的。对于特殊的输入数据,如知识图和表格,需要采用适当方便的方式使它们对LLMs可读。对于结构化数据,由于其简单性,通常使用线性化来将原始记录(例如,知识三元组)转换为序列[512]。此外,还可以使用编程语言(例如,可执行代码)来构建结构化数据,这也支持使用外部工具(例如,程序执行器)生成精确的结果[633, 634]。
• 上下文信息。除了任务描述和输入数据外,上下文或背景信息对于特定任务也是至关重要的。例如,检索到的文档对于开放域问答非常有用,作为支持证据。因此,在适当的提示模式或表达格式中需要包含这些信息。此外,在上下文中的任务示例对于引发LLMs完成复杂任务也有帮助,它们可以更好地描述任务目标、特殊输出格式和输入与输出之间的映射关系。
• 提示样式。对于不同的LLMs,设计一个适合的提示样式以引发其解决特定任务的能力非常重要。总体来说,应该将提示表达为一个清晰的问题或详细的指令,以便被理解和回答。在某些情况下,添加前缀或后缀也可以更好地引导LLMs。例如,使用前缀“让我们一步一步思考”可以帮助引发LLMs进行逐步推理,使用前缀“您是这个任务(或领域)的专家”可以提高LLMs在某些特定任务中的性能。此外,对于基于聊天的LLMs(例如,ChatGPT),建议将长或复杂的任务提示分解为多个子任务的提示,然后通过多轮对话[366]将它们提供给LLMs。
设计原则
基于提示的关键成分,我们总结了几个关键的设计原则,可以帮助创建更有效的提示来解决各种任务。
• 清晰表达任务目标。任务描述不应模棱两可或不清晰,这可能导致不准确或不合适的回应。这强调了在利用这些模型时需要明确和明确的指导[61]。清晰而详细的描述应包含各种元素,以解释一个任务,包括任务目标、输入/输出数据(例如,“给定一份长文档,我希望您生成一个简洁的摘要。”)以及响应约束(例如,“摘要的长度不能超过50个字。”)。通过提供明确的任务描述,LLMs可以更有效地理解目标任务并生成所需的输出。
• 分解成易于详细处理的子任务。为了解决复杂的任务,将困难的任务分解成更容易的、详细的子任务非常重要,以帮助LLMs逐步实现目标,这与第6.3节中的规划技术密切相关。例如,按照建议[627],我们可以明确以多个编号项的形式列出子任务(例如,“通过执行以下任务编织一篇连贯的叙述:1. …;2. …;3. …”)。通过将目标任务分解为子任务,LLMs可以专注于解决较容易的子任务,并最终为复杂任务实现更准确的结果。
• 提供少量示范。如第6.1节所讨论,LLMs可以受益于上下文学习来解决复杂的任务,其中提示包含少量所需输入-输出对的任务示例,即少量示范。少量示范可以帮助LLMs学习输入和输出之间的语义映射,而无需参数调整。在实践中,建议为目标任务生成少量高质量的示范,这将极大地有益于最终的任务性能。
• 利用模型友好的格式。由于LLMs是在专门构建的数据集上预训练的,因此有一些提示格式可以使LLMs更好地理解指令。例如,正如OpenAI文档建议的,我们可以使用###或"""作为停止符号来分隔指令和上下文,这可以被LLMs更好地理解。作为一般准则,大多数现有的LLMs在英语中执行任务更好,因此在机器翻译的基础上使用英语指令来解决困难任务是有用的。
有用的提示
除了设计原则外,我们还根据现有工作或我们的经验经验,提供了一些有用的提示,详见表14。请注意,这些提示以一种一般性的方式提出,这并不表示它们是相应任务的最佳提示。这部分将不断更新,以提供更多的指导或提示。我们欢迎读者为这些提示提供贡献。我们在以下链接提供了有关如何为提示提供贡献的详细步骤:https://github.com/RUCAIBox/LLMSurvey/tree/main/Prompts。
8.2 结果与分析
在上述子节中,我们已经讨论了设计提示的一般原则。这部分提供了解决一些常见任务的具体提示示例。特别地,这些任务提示大多来自现有的论文,实验是使用基于ChatGPT的相应任务提示进行的。
实验设置
为了进行实验,我们选择了涵盖了语言生成、知识利用、复杂推理、结构化数据生成和信息检索的各种任务。对于每个任务,我们手动编写一个提示,遵循第8.1节介绍的一般准则。请注意,测试的提示可能不是这些任务的最佳提示,因为它们主要旨在帮助读者了解如何编写有效的提示来解决不同的任务。此外,我们还添加了一个简化的提示作为大多数任务的比较。按照第7.4节的实验设置,我们检查ChatGPT在复杂推理任务(Colored Objects和GSM8k)上的3-shot性能,以及在其他任务上的零-shot性能。
结果分析
我们在表13中报告了实验结果,同时也包括了现有论文中的监督性能作为参考。
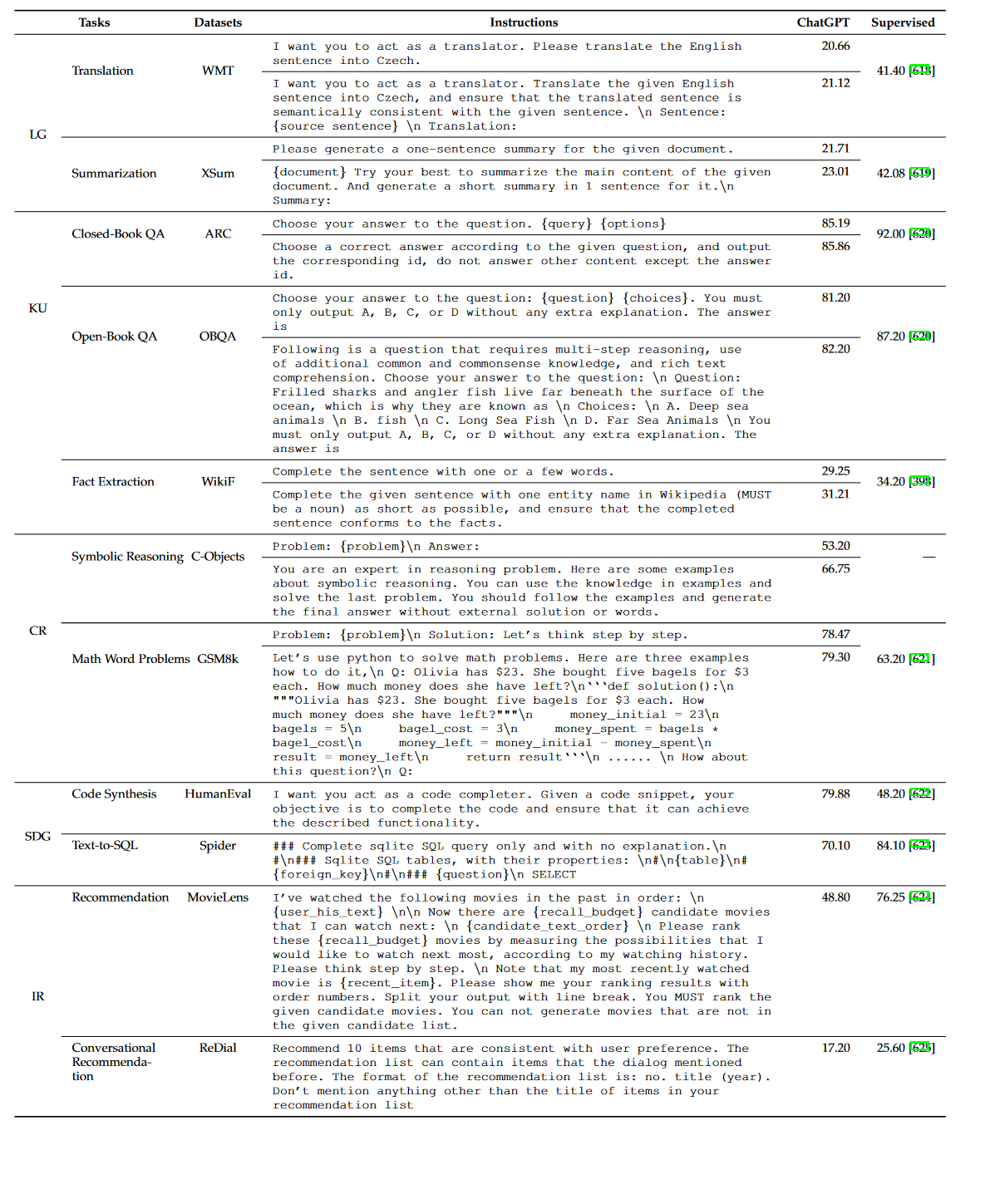
表 13:ChatGPT 在代表性任务上的提示示例及其性能。对于大多数任务,我们会比较简单和复杂提示的性能。我们还展示了监督方法的报告性能。 “LG”、“KU”、“CR”、“SDG”、“IR”是“语言生成”、“知识利用”、“复杂推理”、“结构化数据生成”、“信息检索”的缩写。 “-”表示该数据集之前没有报告过监督结果。
• 精心设计的提示可以提高ChatGPT的零-shot或few-shot性能。通过比较在同一任务上使用不同提示的结果,我们可以看到使用精心设计的提示可以获得比较简单提示更好的性能。在精心设计的提示中,我们提供了更明确的任务描述(例如,WMT和WikiFact),或者使用了模型友好的格式(例如,GSM8k和OBQA)。例如,对于WikiFact任务,更详细的任务描述导致性能从29.25提高到31.21。
• 更复杂的任务可以更多地受益于ChatGPT上的仔细提示工程。在WikiFact和Colored Objects任务中,设计的提示极大地提高了ChatGPT的性能,即从23.61提高到28.47的WikiFact和从53.20提高到66.75的Colored Objects。这表明了在复杂任务上进行提示工程对于LLMs表现良好是必要的,因为这些任务通常具有特定的输出格式或需要背景知识。我们的示例提示提供了更详细的任务描述(例如,输出格式和任务目标),这可以帮助ChatGPT更好地理解完成复杂任务所需的复杂任务要求。
• 对于数学推理任务,基于编程语言格式设计具体提示更加有效。对于GSM8k,设计的提示采用了代码格式的few-shot示范,将这个数学推理任务转化为代码生成任务,可以利用ChatGPT强大的代码合成能力来解决数学问题。此外,在外部程序执行器的帮助下,我们能够获得更精确的结果,而不是使用LLMs进行算术运算。正如我们所看到的,GSM8k的性能从78.47提高到了79.30,表明了编程语言在数学推理任务中的有用性。
• 在知识利用和复杂推理任务中,ChatGPT在合适的提示下可以实现可比较的性能,甚至胜过监督基线方法。在知识利用和复杂推理任务中,具有合适零-shot或few-shot提示的ChatGPT可以实现可比较的性能,甚至在监督方法上表现更好,例如,在WikiFact上为31.21(ChatGPT)与34.20(监督基线)。尽管如此,ChatGPT在一些特定任务上仍然表现不如监督基线模型(例如,ARC和WikiFact),因为这些监督模型已经经过特殊优化,具有任务特定的数据。
• 通过合适的提示工程,LLMs可以处理一些非传统的NLP任务。在特定提示的帮助下,ChatGPT还可以完成非传统的NLP任务,例如一般建议和对话建议。关键点是这些任务可以用自然语言很好地表达或描述。然而,ChatGPT的性能仍然远远低于这些任务中的参考性能,因为LLMs无法直接适应这些需要特定领域知识和任务适应的任务。

表14:设计提示的有用技巧的集合,这些技巧是从在线笔记 [627-630] 和我们作者的经验中收集的,其中我们还展示了相关的成分和原则(在第 8.1 节中介绍)。我们将原则缩写为 Prin。并列出每个提示的相关原则的ID。 1:明确表达任务目标; 2:分解为简单、详细的子任务; 3:提供少镜头演示; 4 :利用模型友好的格式。
9 APPLICATIONS
LLMs是在多种来源的语料库上进行预训练的,它们可以从大规模的预训练数据中获取丰富的知识,因此有潜力成为特定领域的领域专家或专家。在本节中,我们简要回顾了LLMs在几个代表性领域中的应用的最新进展,包括医疗保健、教育、法律、金融和科学研究。
医疗保健是与人类生活密切相关的重要应用领域。自ChatGPT问世以来,许多研究已经将ChatGPT或其他LLMs应用于医学领域。已经证明LLMs能够处理各种医疗保健任务,例如生物信息提取[637]、医疗咨询[638]、心理健康分析[639]和报告简化[640]。作为主要的技术方法,研究人员通常设计特定的提示或指导LLMs执行各种医疗任务。为了进一步发挥LLMs在医疗领域的作用,研究人员建议开发与医疗保健相关的LLMs。具体而言,Med-PaLM模型[282, 641]在美国医学许可考试(USMLE)上实现了专家级的表现,并在回答消费者的医学问题方面得到了医生们更高的认可。然而,LLMs可能会制造医学错误信息[640, 642],例如误解医学术语并提供与医学指南不一致的建议。此外,将患者的健康信息[637]上传到支持LLMs的商业服务器还可能引发隐私问题。
教育也是LLMs可能产生重大影响的重要应用领域。现有研究发现LLMs可以在多个数学科目(例如物理学、计算机科学)上的标准化测试中实现学生水平的表现,包括选择题和自由回答问题[46]。此外,实证研究表明LLMs可以作为教育的写作或阅读助手[643, 644]。最近的一项研究[644]发现ChatGPT能够在各个学科中生成逻辑一致的答案,平衡深度和广度。另一项定量分析[643]显示,利用ChatGPT(保留或完善LLMs结果作为他们自己的答案)的学生在计算机安全领域的一些课程中表现优于平均水平的学生。最近,几篇前瞻性论文[645, 646]还探讨了LLMs在课堂教学中的各种应用场景,例如师生合作、个性化学习和评估自动化。然而,LLMs在教育中的应用可能引发一系列实际问题,如抄袭、人工智能生成内容中的潜在偏见、过度依赖LLMs以及非英语使用者的不平等获取[647]。
法律是一个建立在专业领域知识基础上的专业领域。最近,许多研究已经应用LLMs来解决各种法律任务,例如法律文件分析[648]、法律判决预测[649]和法律文件撰写[650]。一项最近的研究[651]发现LLMs表现出强大的法律解释和推理能力。此外,最新的GPT-4模型在模拟的律师考试中与人类考生相比获得了前10%的成绩[46]。为了进一步提高LLMs在法律领域的性能,采用了专门设计的法律提示工程,以在长篇法律文件理解和复杂法律推理方面获得高级性能[652, 653]。总之,LLMs可以充当法律专业的有用助手。尽管取得了进展,但在法律领域使用LLMs引发了一系列法律挑战的担忧,包括版权问题[654]、个人信息泄露[655]以及偏见和歧视[656]。
金融是一个LLMs具有潜在应用前景的重要领域。LLMs已经被应用于各种金融相关任务,例如数字索赔检测[657]、金融情感分析[658]、金融命名实体识别[659]和金融推理[660]。尽管通用LLMs在金融任务中表现出了竞争力的零-shot性能,但它们仍然在包含百万级参数的领域特定PLMs的性能下表现不佳[657]。为了利用LLMs的扩展效应,研究人员收集了大规模的金融语料库,以持续进行LLMs的预训练(例如,BloombergGPT [286]、XuanYuan 2.0 [661]和FinGPT [662])。BloombergGPT在各种金融任务中展示出了出色的性能,同时在通用任务中保持了竞争性能[286]。然而,需要更严格的审查和监控来考虑在金融领域使用LLMs的潜在风险,因为LLMs生成不准确或有害内容可能对金融市场产生重大不利影响[286]。
科学研究是另一个LLMs可以促进发展的有前途的领域。先前的研究表明,LLMs在处理知识密集型的科学任务方面非常有效(例如PubMedQA [663]、BioASQ [664]),尤其是对于在科学相关语料库上进行预训练的LLMs(例如Galactica [35]、Minerva [163])。由于其出色的通用能力和广泛的科学知识,LLMs在科学研究流程的各个阶段都具有重要潜力,可以充当有用的助手[665]。首先,在文献综述阶段,LLMs可以帮助对特定研究领域的进展进行全面的概述[666, 667]。其次,在研究思路生成阶段,LLMs展示出生成引人入胜的科学假设的能力[668]。第三,在数据分析阶段,可以利用LLMs进行自动数据分析,包括数据探索、可视化和得出分析性结论[669, 670]。第四,在论文写作阶段,研究人员还可以从LLMs的帮助中受益,用于科学写作[671, 672],在这方面,LLMs可以通过多种方式提供科学写作的有价值的支持,例如总结现有内容和润色写作[673]。此外,LLMs还可以协助自动化的论文审阅过程,包括错误检测、检查清单验证和候选人排名[674]。尽管取得了这些进展,LLMs在充当有用的、值得信赖的科学助手方面仍有很大的提升空间,以提高生成的科学内容的质量并减少有害的幻觉。
总结。除了前面提到的工作外,LLMs的应用还在其他几个领域进行了讨论。例如,在心理学领域,一些最近的研究已经研究了LLMs的类似人类的特征,如自我意识、心灵理论(ToM)和情感计算[675, 676]。特别是,在两个经典的虚假信仰任务上进行的ToM的实证评估推测,LLMs可能具有类似ToM的能力,因为GPT-3.5系列中的模型在ToM任务中的表现与九岁的儿童相当[675]。此外,另一项研究工作探讨了将LLMs应用于软件开发领域,例如代码建议[677]、代码摘要[678]和自动程序修复[679]。总之,通过LLMs在现实世界的任务中辅助人类已经成为一个重要的研究领域。然而,这也带来了挑战。在将LLMs应用于现实场景时,确保LLMs生成的内容的准确性、解决偏见以及维护用户隐私和数据安全都是重要的考虑因素。
10 CONCLUSION AND FUTURE DIRECTIONS
在本综述中,我们回顾了大型语言模型(LLMs)的最新进展,并介绍了理解和利用LLMs的关键概念、发现和技术。我们专注于大型模型(即大小超过10B的模型),同时排除了早期预训练语言模型(例如BERT和GPT2)的内容,因为这些内容在现有文献中已经得到了充分覆盖。特别是,我们的调查讨论了LLMs的四个重要方面,即预训练、适应调整、利用和评估。对于每个方面,我们强调了对LLMs成功的关键技术或发现。此外,我们还总结了开发LLMs的可用资源,并讨论了重要的实施指南,以复制LLMs。这项调查试图涵盖关于LLMs的最新文献,并为研究人员和工程师提供了有关这一主题的良好参考资源。
接下来,我们将总结本调查的讨论,并介绍LLMs在以下方面的挑战和未来方向。
理论和原则
为了理解LLMs的基本工作机制,其中一个最大的谜团之一是信息如何通过非常大、深的神经网络进行分布、组织和利用。揭示建立LLMs能力基础的基本原理或元素非常重要。特别是,扩展似乎在增加LLMs的容量方面发挥了重要作用[31, 55, 59]。已经表明,当语言模型的参数规模增加到关键大小(例如10B)时,会以意想不到的方式出现一些新出现的能力(突然的性能飞跃),通常包括在上下文学习、遵循指令和逐步推理方面。这些新出现的能力既令人着迷又令人困惑:LLMs何时以及如何获得它们尚不清楚。最近的研究要么进行了大量实验来研究新出现的能力的影响以及导致这些能力的因素[345, 680, 681],要么用现有的理论框架解释了一些特定的能力[60, 380]。一篇富有见地的技术文章还专门讨论了这个话题[47],以GPT系列模型为目标。然而,用于理解、描述和解释LLMs的能力或行为的更正式的理论和原则仍然缺乏。由于新出现的能力与自然界中的相变存在密切的类比[31, 58],跨学科的理论或原则(例如,LLMs是否可以被视为某种复杂系统)可能有助于解释和理解LLMs的行为。这些基本问题值得研究界进一步探讨,对于开发下一代LLMs非常重要。
模型架构
由于可扩展性和有效性,由多层堆叠的多头自注意力层组成的Transformer已经成为构建LLMs的事实标准架构。已经提出了各种策略来提高这种架构的性能,例如神经网络配置和可扩展的并行训练(请参阅第4.2.2节中的讨论)。为了增强模型的容量(例如,多轮对话的能力),现有的LLMs通常保持一个很长的上下文窗口,例如,GPT-4-32k具有极大的上下文长度,达到了32,768个标记。因此,一个实际考虑的问题是减少标准自注意力机制引起的时间复杂度(原本是二次成本)。研究更高效的Transformer变体在构建LLMs时的影响非常重要[682],例如,在GPT3中使用了稀疏注意力。此外,灾难性遗忘一直是神经网络的长期挑战,这也对LLMs产生了负面影响。当使用新数据来调整LLMs时,原先学到的知识很可能会受损,例如,根据一些特定任务来微调LLMs将影响LLMs的通用能力。当LLMs与人类价值观对齐时也会出现类似的情况(称为对齐税[61, 295])。因此,有必要考虑通过更灵活的机制或模块来扩展现有架构,以有效支持数据更新和任务专业化。
模型训练
在实践中,要预训练出有能力的LLMs非常困难,这是因为需要大量的计算资源,而且对数据质量和训练技巧非常敏感[69, 84]。因此,特别重要的是开发更系统的、经济的预训练方法来优化LLMs,考虑到模型的有效性、效率优化和训练稳定性因素。应该开发更多的模型检查或性能诊断方法(例如,GPT-4中的可预测的扩展[46]),以便在训练过程中检测到早期的异常问题。此外,还需要更灵活的硬件支持或资源调度机制,以更好地组织和利用计算集群中的资源。由于从头开始预训练LLMs非常昂贵,因此重要的是设计合适的机制,以根据公开可用的模型检查点(例如LLaMA [57]和FlanT5 [64])进行持续的预训练或微调。为此,必须解决许多技术问题,例如灾难性遗忘和任务专业化。然而,到目前为止,仍然缺少具有完整的预处理和训练日志(例如准备预训练数据的脚本)的LLMs的开源模型检查点,以便进行再现。我们认为,在LLMs的研究中报告更多的技术细节将具有很大的价值。此外,开发更多有效激发模型能力的改进调整策略也非常重要。
模型利用
由于在实际应用中微调非常昂贵,提示已经成为使用LLMs的突出方法。通过将任务描述和演示示例组合成提示,上下文学习(提示的一种特殊形式)赋予LLMs在新任务上表现良好的能力,甚至在某些情况下超过了完整数据微调模型。此外,为增强复杂推理能力,已经提出了高级提示技术,例如链式思维(CoT)策略,将中间推理步骤包括在提示中。然而,现有的提示方法仍然存在一些不足,如下所述。首先,它需要大量人力来设计提示。自动生成用于解决各种任务的有效提示将非常有用。其次,一些复杂任务(例如正式证明和数值计算)需要特定的知识或逻辑规则,这些规则可能无法用自然语言清晰表达或通过示例演示。因此,重要的是为提示开发更具信息量、灵活性的任务格式化方法。第三,现有的提示策略主要集中在单轮性能上。为解决复杂任务,开发交互式提示机制(例如通过自然语言对话)将非常有用,ChatGPT已经证明这对解决复杂任务非常有用。
安全性和对齐性
尽管LLMs具有强大的能力,但它们面临着与小型语言模型类似的安全挑战。例如,LLMs表现出生成幻觉的倾向[518],这些文本看起来似乎合理,但事实可能不正确。更糟糕的是,LLMs可能会被有意的指令激发,以产生有害、偏见或有毒的文本,用于恶意系统,从而导致潜在的滥用风险[55, 61]。关于LLMs的安全问题(例如隐私、过度依赖、虚假信息和影响运营)的详细讨论,读者可以参考GPT3/4的技术报告[46, 55]。作为规避这些问题的主要方法,强化学习从人类反馈中学习(RLHF)[61, 103]已经广泛应用,通过将人类纳入培训循环,以开发对齐良好的LLMs。为了提高模型的安全性,在RLHF过程中包含与安全相关的提示也非常重要,正如GPT-4所示[46]。然而,RLHF严重依赖于来自专业标注者的高质量人类反馈数据,这使得在实践中难以正确实施。因此,有必要改进RLHF框架,以减少人工标注者的工作量,并寻求一种拥有保证数据质量的更高效的注释方法,例如LLMs可以用于协助标注工作。此外,在使用特定领域数据进行微调LLMs时,还需要考虑隐私问题,联邦学习库[683]可以在受隐私限制的情况下非常有用。
应用与生态系统
由于LLMs在解决各种任务方面显示出强大的能力,它们可以在广泛的现实世界应用中应用(即遵循任务特定的自然语言指令)。作为一项显著的进展,ChatGPT潜在地改变了人类获取信息的方式,这已经在新版Bing中实施。在不久的将来,可以预见LLMs将对信息检索技术产生重大影响,包括搜索引擎和推荐系统。此外,LLMs的技术升级将极大推动智能信息助手的发展和使用。在更广泛的范围内,这波技术创新将导致一个由LLMs增强的应用生态系统(例如,ChatGPT支持插件),这与人类生活密切相关。最后,LLMs的崛起照亮了人工通用智能(AGI)的探索。开发比以往任何时候都更智能的智能系统(可能具有多模式信号)是有希望的。然而,在这个发展过程中,AI安全应该是主要关注的问题之一,即确保AI对人类有益而不是有害[40]。
相关文章:
大语言模型(LLM)综述(七):大语言模型设计应用与未来方向
A Survey of Large Language Models 前言8 A PRACTICAL GUIDEBOOK OF PROMPT DESIGN8.1 提示创建8.2 结果与分析 9 APPLICATIONS10 CONCLUSION AND FUTURE DIRECTIONS 前言 随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-…...
牛客网:链表分割
一、题目 函数原型: ListNode* partition(ListNode* pHead, int x) 二、思路 根据题意,可以设置两个新的链表,将原链表中所有小于x的结点链接到链表1中,大于x的结点链接到链表2中,最后再将两个链表合并即可。 此题有两…...
pytorch(小土堆)深度学习
第五节课讲项目的创建和对比 第六节:Dataset,Dataloader Dataset提供一种方式区获取数据及其label(如何获取每一个数据及其label,告诉我们总共有多少的数据) Dataloader为后面的网络提供不同的数据形式 第七节:Dataset类代码实战 显示图片 f…...

统计 boy girl 复制出来多少次。 浴谷 P1321题
统计 boy girl 复制出来多少次。 #define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <iomanip>void fun(char* s) {int boy 0, girl 0;int t 0;while (*s) {if (t 0 && *s!.) {t 1;if (*s b || *s o || *s y)boy 1;elsegirl 1;}…...

odoo16前端框架分析1 boot.js
odoo16前端框架分析1 boot.js odoo16的前端基于owl组件系统,这是一个类似vue,react的现代js框架。 前端框架都放在了web模块中,具体的位置是addons/web/static/src 不过今天要说的不是owl,而是跟前端启动有关的几个重要文件 1、…...

酷开科技持续推动智能投影行业创新发展
近年来,投影仪逐渐成为年轻人追捧的家居时尚单品。据国际数据公司(IDC)报告显示,2022年中国投影机市场总出货量505万台,超80%为家用投影仪。相比于电视,投影仪外观小巧、屏幕大小可调节,无论是卧…...
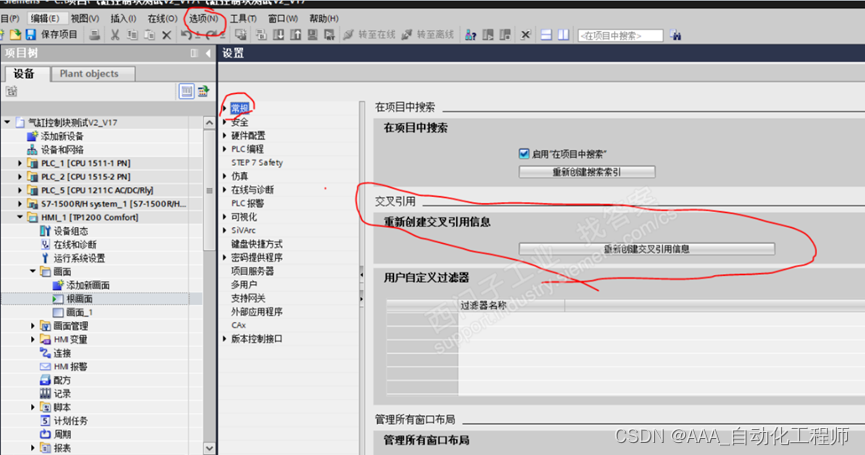
TIA博途中已经被调用的变量,为什么交叉引用时却没有显示调用信息?
TIA博途中已经被调用的变量,为什么交叉引用时却没有显示调用信息? 故障现象: 如下图所示,在HMI的画面中,已经连接了对应的变量, 如下图所示,这里为HMI变量表, 如下图所示ÿ…...
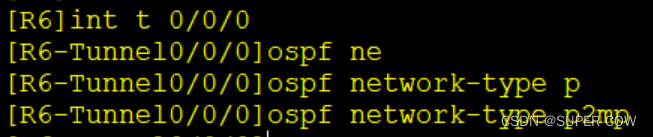
OSPF下的MGRE实验
一、实验要求 1、R1-R3-R4构建全连的MGRE环境 2、R1-R5-R6建立hub-spoke的MGRE环境,其中R1为中心 3、R1-R3...R6均存在环回网段模拟用户私网,使用OSPF使全网可达 4、其中R2为ISP路由器,仅配置IP地址 二、实验拓扑图 三、实验配置 1、给各路…...

论文速览 | TRS 2023: 使用合成微多普勒频谱进行城市鸟类和无人机分类
注1:本文系“最新论文速览”系列之一,致力于简洁清晰地介绍、解读最新的顶会/顶刊论文 论文速览 | TRS 2023: Urban Bird-Drone Classification with Synthetic Micro-Doppler Spectrograms 原始论文:D. White, M. Jahangir, C. J. Baker and M. Antoniou, “Urban Bird-Drone…...
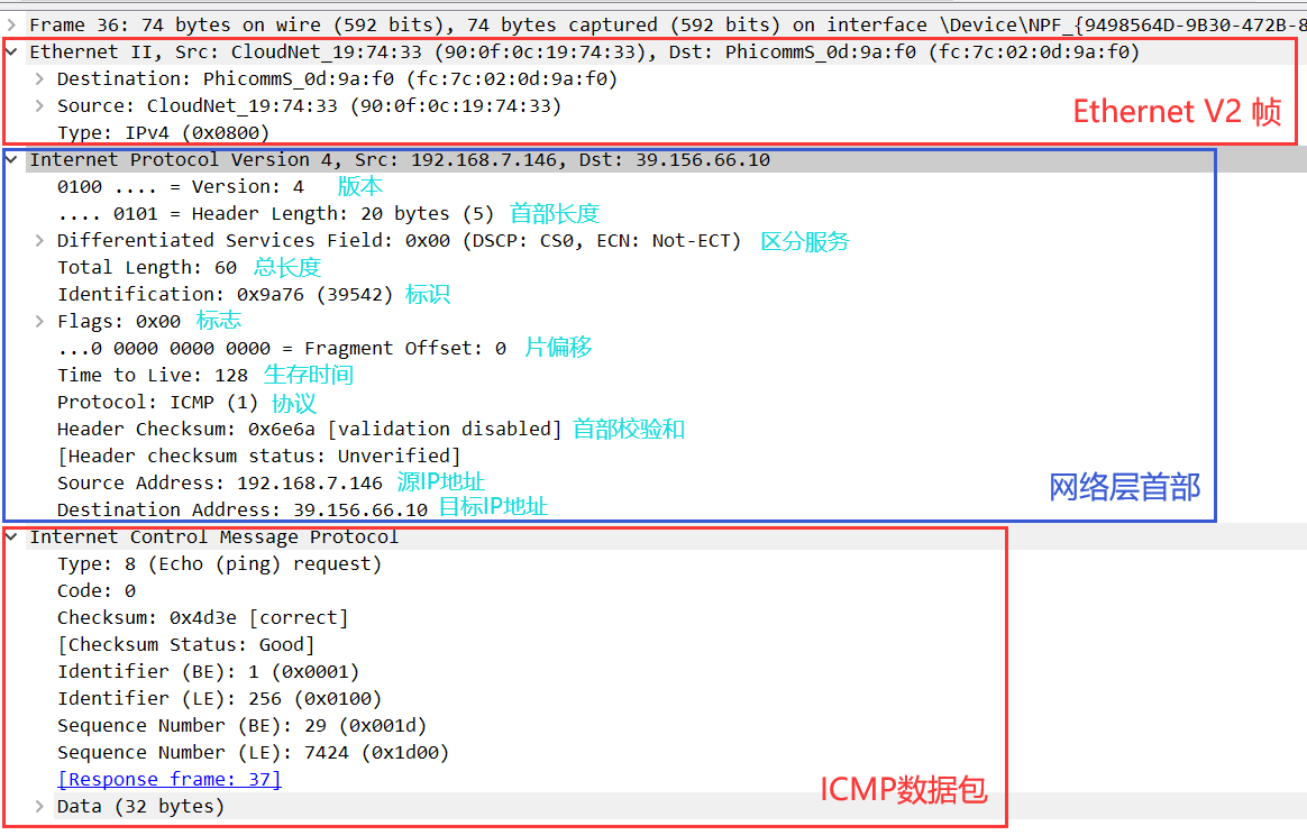
《网络协议》02. 物理层 · 数据链路层 · 网络层
title: 《网络协议》02. 物理层 数据链路层 网络层 date: 2022-08-31 22:26:48 updated: 2023-11-08 06:58:52 categories: 学习记录:网络协议 excerpt: 物理层(数据通信模型,信道)、数据链路层(封装成帧,…...

【chatgpt问答记录】双端队列、栈和函数调用栈
collections.deque和queue.Queue的区别 Q:collections.deque()跟queue.Queue()有什么区别? collections.deque() 和 queue.Queue 是两种不同的数据结构,它们有一些区别: 实现方式: collections.deque() 是 Python 标…...
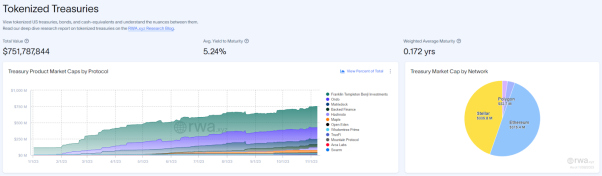
另辟蹊径者 PoseiSwap:背靠潜力叙事,构建 DeFi 理想国
前不久,灰度在与 SEC 就关于 ETF 受理的诉讼案件中,以灰度胜诉告终。灰度的胜利,也被加密行业看做是加密 ETF 在北美地区阶段性的胜利, 该事件也带动了加密市场的新一轮复苏。 此前,Nason Smart Money 曾对加密市场在 …...
如何查看笔记本电脑电池损耗
1.下载图吧工具箱 在官网下,不要下错了,不然会有很多垃圾捆绑软件,我放一个百度云链接,安装包上传上去了 链接:https://pan.baidu.com/s/18dguF5OGktbPkW7EszZZqA 提取码:1024 2.安装打开后点击主办工具-…...
一键批量视频剪辑、合并,省时省力,制作专业视频
在当今数字化的时代,视频制作的需求日益增长。无论是个人用户还是专业人士,都需要能够快速、高效地处理视频,以适应不同的需求。但是,视频剪辑和合并往往是一个耗时且需要专业技能的过程。有没有一种方法可以简化这个过程…...

使用R语言构建HTTP爬虫:IP管理与策略
目录 摘要 一、HTTP爬虫与IP管理概述 二、使用R语言进行IP管理 三、爬虫的伦理与合规性 四、注意事项 结论 摘要 本文深入探讨了使用R语言构建HTTP爬虫时如何有效管理IP地址。由于网络爬虫高频、大量的请求可能导致IP被封禁,因此合理的IP管理策略显得尤为重要…...
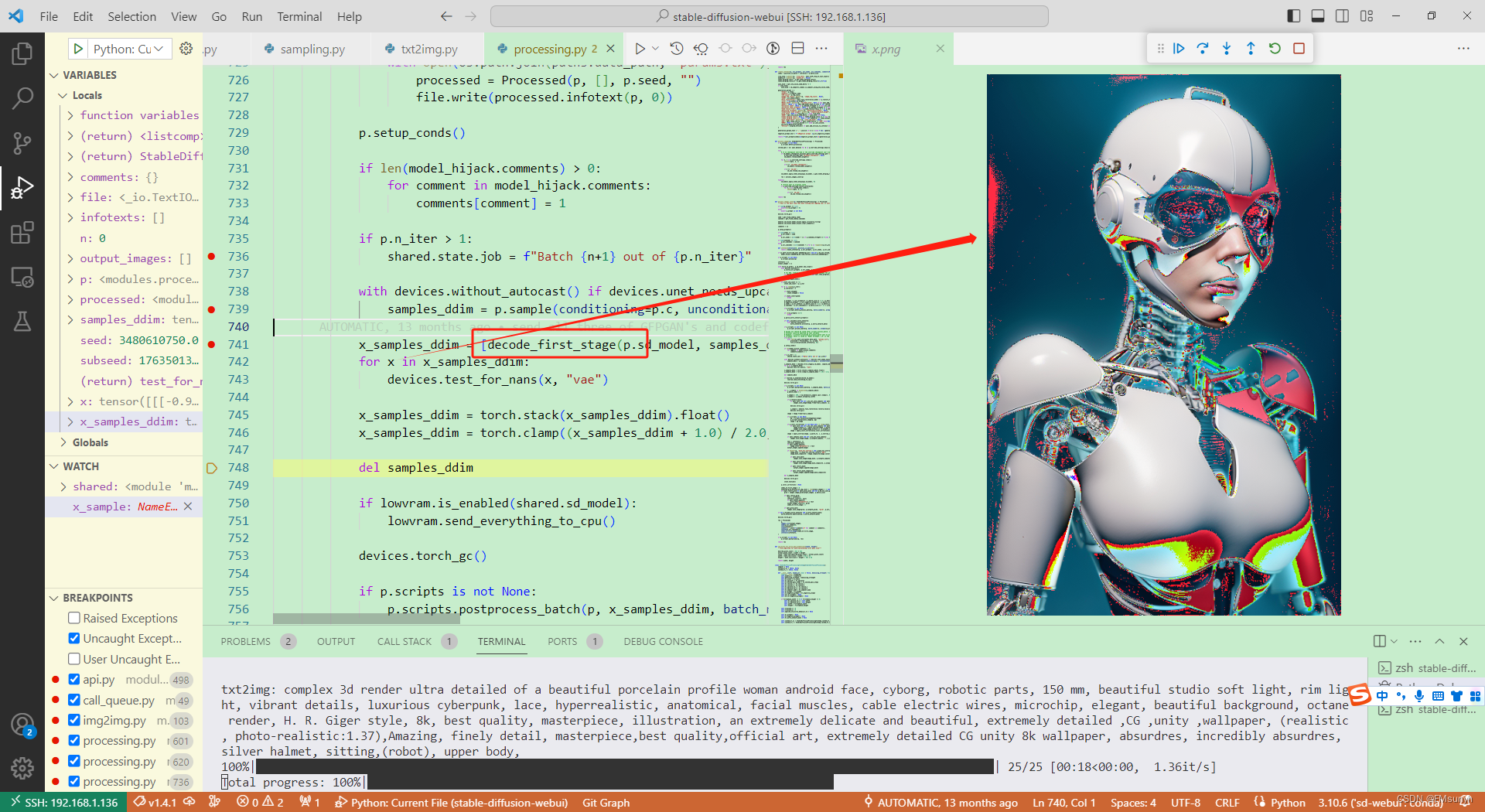
Stable Diffusion源码调试(二)
Stable Diffusion源码调试(二) 个人模型主页:https://liblib.ai/userpage/369b11c9952245e28ea8d107ed9c2746/model Stable Diffusion版本:https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.4.1 分析S…...

网络安全(黑客)-零基础自学
想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客! 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全…...

在线CRM系统的安全性高吗?企业该如何选择?
在线CRM系统具备门槛低、功能不打折扣、部署周期短等优点,相比本地化部署更加适合中小企业。但很多企业在选型软件时会顾虑在线CRM系统的安全性高吗? 通常情况下厂商会比中小企业更有实力保证数据安全,从技术手段保护企业隐私不被盗用。 数…...

R-install_miniconda()卸载 | conda命令行报错及解决方法
运行以下代码,突然报错: C:\Users\hp>conda info-e >>>>>>>>>>>>>>>>>>>>>> ERROR REPORT <<<<<<<<<<<<<<<<<<<<&…...

leaflet:利用Leaflet-Geoman绘制多种图形,导出为geojson文件(135)
第135个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中利用Leaflet-Geoman绘制多种图形,导出为geojson文件。 灵活地配置Leaflet-Geoman的属性,可以产生各种美妙的绘图效果。利用FileSaver可以导出geojson文件。 直接复制下面的 vue+leaflet源代码,操作2分钟…...

FLUX.1-dev小白教程:避开复杂配置,直接体验开源最强文生图模型
FLUX.1-dev小白教程:避开复杂配置,直接体验开源最强文生图模型 1. 为什么选择FLUX.1-dev? 如果你正在寻找一个既强大又易用的开源文生图模型,FLUX.1-dev绝对值得尝试。这个由Black Forest Labs开发的模型,在图像质量…...

拒绝手动 Debug!如何通过自动化测试让 Claude Code 效率翻倍?
2026 年了,如果你还在手动复制粘贴代码去测试,那真的有点“复古”了。随着 Claude Code 等 AI 编程智能体的普及,程序员的工作重心正在发生质变:编码不再是瓶颈,测试才是。今天分享一套提升 Claude Code 性能的核心方案…...

Claude Code 接入 SonarQube 静态扫描:AI 写代码,质量闭环了
引言 你有没有遇到过这种情况:写完代码,提了 PR,结果 CI 流水线扫出一堆质量问题,改来改去浪费了大半天。更尴尬的是,这些问题其实在编码阶段就能发现——只是没有顺手的工具提醒你。 SonarQube 是业界最流行的代码质量平台之一,能检测 Bug、漏洞、坏味道、安全热点,还…...

2026 年录音转文字工具办公会议场景横评:高效记录才是职场核心
2026 年职场办公场景中,录音转文字工具早已从 “辅助工具” 升级为 “核心生产力工具”,尤其是办公会议场景下,能否快速完成实时转写、生成结构化纪要、支持团队协作,直接影响办公效率。为了帮职场人筛选适配的工具,本…...

终极免费方案:让任天堂控制器完美兼容Windows电脑
终极免费方案:让任天堂控制器完美兼容Windows电脑 【免费下载链接】WiinUPro 项目地址: https://gitcode.com/gh_mirrors/wi/WiinUPro 还在为手中的任天堂控制器无法在Windows电脑上使用而苦恼吗?WiinUPro和WiinUSoft这两款免费开源工具为你提供…...

状态空间模型SSM:2022年关键进展与应用实践
1. 状态空间模型的历史脉络状态空间模型(State Space Models, SSM)作为一种数学框架,最早可追溯到20世纪60年代的控制理论领域。当时卡尔曼滤波器的提出为动态系统状态估计奠定了理论基础,这种将系统状态表示为隐藏变量的思路&…...

Pearcleaner:macOS应用彻底清理的终极指南
Pearcleaner:macOS应用彻底清理的终极指南 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经好奇,为什么在macOS上删除应用后…...

大语言模型在文档伪造检测中的创新应用与实践
1. 大语言模型在文档伪造检测领域的创新应用在信息安全领域,文档伪造检测一直是个棘手的难题。传统方法主要依赖人工编写验证规则,不仅效率低下,而且难以应对日益复杂的伪造手段。想象一下,一位海关工作人员每天需要核验数百份护照…...
【含GUI Matlab源码 15384期】)
【图像传输】OFDM图像加密传输(含QAM QPSK)【含GUI Matlab源码 15384期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

MySQL 多表查询详解:从外键到连接查询
MySQL 多表查询详解:从外键到连接查询 在设计关系型数据库时,为了减少数据冗余,我们通常会将不同维度的数据存储在多张表中。当需要从多张表中联合提取数据时,多表查询就成为了核心技能。本文将系统讲解 MySQL 中的外键约束、内连…...