深入理解ClickHouse跳数索引
一、跳数索引
影响ClickHouse查询性能的因素很多。在大多数场景中,关键因素是ClickHouse在计算查询WHERE子句条件时是否可以使用主键。因此,选择适用于最常见查询模式的主键对于表的设计至关重要。
然而,无论如何仔细地调优主键,不可避免地会出现不能有效使用它的查询用例。用户通常依赖于ClickHouse获得时间序列类型的数据,但他们通常希望根据其他业务维度(如客户id、网站URL或产品编号)分析同一批数据。在这种情况下,查询性能可能会相当差,因为应用WHERE子句条件可能需要对每个列值进行完整扫描。虽然ClickHouse在这些情况下仍然相对较快,但计算数百万或数十亿个单独的值将导致“非索引”查询的执行速度比基于主键的查询慢得多。
在传统的关系数据库中,解决这个问题的一种方法是将一个或多个“二级”索引附加到表上。这是一个b-树结构,允许数据库在O(log(n))时间内找到磁盘上所有匹配的行,而不是O(n)时间(一次表扫描),其中n是行数。但是,这种类型的二级索引不适用于ClickHouse(或其他面向列的数据库),因为磁盘上没有单独的行可以添加到索引中。
相反,ClickHouse提供了一种不同类型的索引,在特定情况下可以显著提高查询速度。这些结构被标记为跳数索引,因为它们使ClickHouse能够跳过保证没有匹配值的数据块。
二、基本操作
用户只能在MergeTree表引擎上使用数据跳数索引。每个跳数索引都有四个主要参数:
- 索引名称。索引名用于在每个分区中创建索引文件。此外,在删除或具体化索引时需要将其作为参数。
- 索引的表达式。索引表达式用于计算存储在索引中的值集。它可以是列、简单操作符、函数的子集的组合。
- 类型。索引的类型控制计算,该计算决定是否可以跳过读取和计算每个索引块。
- GRANULARITY。每个索引块由颗粒(granule)组成。例如,如果主表索引粒度为8192行,GRANULARITY为4,则每个索引“块”将为32768行。
当用户创建数据跳数索引时,表的每个数据部分目录中将有两个额外的文件。
- skpidx{index_name}.idx:包含排序的表达式值。
- skpidx{index_name}.mrk2:包含关联数据列文件中的相应偏移量。
如果在执行查询并读取相关列文件时,WHERE子句过滤条件的某些部分与跳数索引表达式匹配,ClickHouse将使用索引文件数据来确定每个相关的数据块是必须被处理还是可以被绕过(假设块还没有通过应用主键索引被排除)。这里用一个非常简单的示例:考虑以下加载了可预测数据的表。
CREATE TABLE skip_table
(my_key UInt64,my_value UInt64
)
ENGINE MergeTree primary key my_key
SETTINGS index_granularity=8192;INSERT INTO skip_table SELECT number, intDiv(number,4096) FROM numbers(100000000);
当执行一个不使用主键的简单查询时,将扫描my_value列所有的一亿条记录:
SELECT * FROM skip_table WHERE my_value IN (125, 700)┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘8192 rows in set. Elapsed: 0.079 sec. Processed 100.00 million rows, 800.10 MB (1.26 billion rows/s., 10.10 GB/s.
增加一个基本的跳数索引:
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
通常,跳数索引只应用于新插入的数据,所以仅仅添加索引不会影响上述查询。
要使已经存在的数据生效,那执行:
ALTER TABLE skip_table MATERIALIZE INDEX vix;
重跑SQL:
SELECT * FROM skip_table WHERE my_value IN (125, 700)┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘8192 rows in set. Elapsed: 0.051 sec. Processed 32.77 thousand rows, 360.45 KB (643.75 thousand rows/s., 7.08 MB/s.)
这次没有再去处理1亿行800MB的数据,ClickHouse只读取和分析32768行360KB的数据—4个granule的数据。
下图是更直观的展示,这就是如何读取和选择my_value为125的4096行,以及如何跳过以下行而不从磁盘读取:
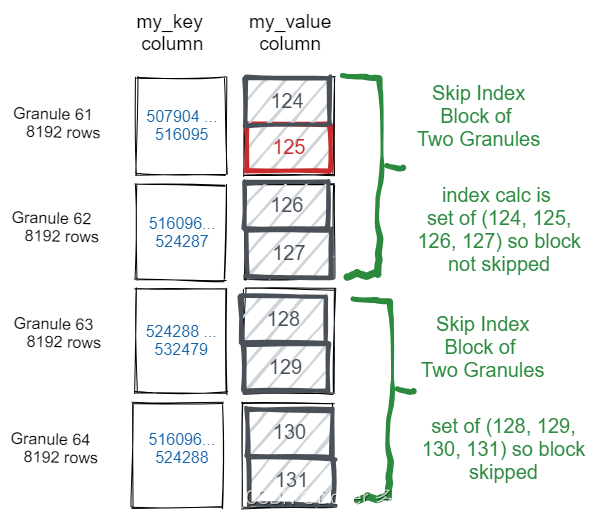 通过在执行查询时启用跟踪,用户可以看到关于跳数索引使用情况的详细信息。在clickhouse-client中设置send_logs_level:
通过在执行查询时启用跟踪,用户可以看到关于跳数索引使用情况的详细信息。在clickhouse-client中设置send_logs_level:
SET send_logs_level='trace';
这将在尝试调优查询SQL和表索引时提供有用的调试信息。上面的例子中,调试日志显示跳数索引过滤了大部分granule,只读取了两个:
<Debug> default.skip_table (933d4b2c-8cea-4bf9-8c93-c56e900eefd1) (SelectExecutor): Index `vix` has dropped 6102/6104 granules.
三、跳数索引类型
1、minmax
这种轻量级索引类型不需要参数。它存储每个块的索引表达式的最小值和最大值(如果表达式是一个元组,它分别存储元组元素的每个成员的值)。对于倾向于按值松散排序的列,这种类型非常理想。在查询处理期间,这种索引类型的开销通常是最小的。
这种类型的索引只适用于标量或元组表达式——索引永远不适用于返回数组或map数据类型的表达式。
2、set
这种轻量级索引类型接受单个参数max_size,即每个块的值集(0允许无限数量的离散值)。这个集合包含块中的所有值(如果值的数量超过max_size则为空)。这种索引类型适用于每组颗粒中基数较低(本质上是“聚集在一起”)但总体基数较高的列。
该索引的成本、性能和有效性取决于块中的基数。如果每个块包含大量惟一值,那么针对大型索引集计算查询条件将非常昂贵,或者由于索引超过max_size而为空,因此索引将不应用。
3、Bloom Filter Types
Bloom filter是一种数据结构,它允许对集合成员进行高效的是否存在测试,但代价是有轻微的误报。在跳数索引的使用场景,假阳性不是一个大问题,因为惟一的问题只是读取一些不必要的块。潜在的假阳性意味着索引表达式应该为真,否则有效的数据可能会被跳过。
因为Bloom filter可以更有效地处理大量离散值的测试,所以它们可以适用于大量条件表达式判断的场景。特别的是Bloom filter索引可以应用于数组,数组中的每个值都被测试,也可以应用于map,通过使用mapKeys或mapValues函数将键或值转换为数组。
有三种基于Bloom过滤器的数据跳数索引类型:
-
基本的bloom_filter接受一个可选参数,该参数表示在0到1之间允许的“假阳性”率(如果未指定,则使用.025)。
-
更专业的tokenbf_v1。需要三个参数,用来优化布隆过滤器:(1)过滤器的大小字节(大过滤器有更少的假阳性,有更高的存储成本),(2)哈希函数的个数(更多的散列函数可以减少假阳性)。(3)布隆过滤器哈希函数的种子。有关这些参数如何影响布隆过滤器功能的更多细节,请参阅 这里 。此索引仅适用于String、FixedString和Map类型的数据。输入表达式被分割为由非字母数字字符分隔的字符序列。例如,列值
This is a candidate for a "full text" search将被分割为Thisisacandidateforfulltextsearch。它用于LIKE、EQUALS、in、hasToken()和类似的长字符串中单词和其他值的搜索。例如,一种可能的用途是在非结构的应用程序日志行列中搜索少量的类名或行号。 -
更专业的ngrambf_v1。该索引的功能与tokenbf_v1相同。在Bloom filter设置之前需要一个额外的参数,即要索引的ngram的大小。一个ngram是长度为n的任何字符串,比如如果n是4,
A short string会被分割为A sh`` sho,shor,hort,ort s,or st,r str,stri,trin,ring。这个索引对于文本搜索也很有用,特别是没有单词间断的语言,比如中文。
四、跳数索引函数
跳数索引核心目的是限制流行查询分析的数据量。鉴于ClickHouse数据的分析特性,这些查询的模式在大多数情况下都包含函数表达式。因此,跳数索引必须与常用函数正确交互才能提高效率。这种情况可能发生在:
- 插入数据并将索引定义为一个函数表达式(表达式的结果存储在索引文件中)或者
- 处理查询,并将表达式应用于存储的索引值,以确定是否排除数据块。
每种类型的跳数索引支持的函数列表可以查看 这里 。通常,集合索引和基于Bloom filter的索引(另一种类型的集合索引)都是无序的,因此不能用于范围。相反,最大最小值索引在范围中工作得特别好,因为确定范围是否相交非常快。部分匹配函数LIKE、startsWith、endsWith和hasToken的有效性取决于使用的索引类型、索引表达式和数据的特定形状。
五、跳数索引的配置
有两个可用的设置可应用于跳数索引。
- use_skip_indexes (0或1,默认为1)。不是所有查询都可以有效地使用跳过索引。如果一个特定的过滤条件可能包含很多颗粒,那么应用数据跳过索引将导致不必要的、有时甚至是非常大的成本。对于不太可能从任何跳过索引中获益的查询,将该值设置为0。
- force_data_skipping_indexes (以逗号分隔的索引名列表)。此设置可用于防止某些类型的低效查询。在某些情况下,除非使用跳过索引,否则查询表的开销太大,如果将此设置与一个或多个索引名一起使用,则对于任何没有使用所列索引的查询将返回一个异常。这将防止编写糟糕的查询消耗服务器资源。
六、最佳实践
跳数索引并不直观,特别是对于来自RDMS领域并且习惯二级行索引或来自文档存储的反向索引的用户来说。要获得任何优化,应用ClickHouse数据跳数索引必须避免足够多的颗粒读取,以抵消计算索引的成本。关键是,如果一个值在一个索引块中只出现一次,就意味着整个块必须读入内存并计算,而索引开销是不必要的。
考虑以下数据分布:
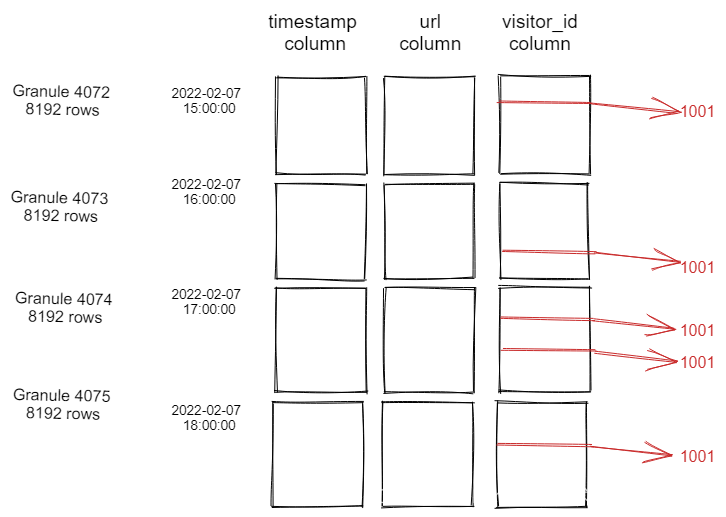 假设主键/顺序是时间戳,并且在visitor_id上有一个索引。考虑下面的查询:
假设主键/顺序是时间戳,并且在visitor_id上有一个索引。考虑下面的查询:
SELECT timestamp, url FROM table WHERE visitor_id = 1001
对于这种数据分布,传统的二级索引非常有利。不是读取所有的32678行来查找具有请求的visitor_id的5行,而是二级索引只包含5行位置,并且只从磁盘读取这5行。ClickHouse数据跳过索引的情况正好相反。无论跳转索引的类型是什么,visitor_id列中的所有32678值都将被测试。
因此,试图通过简单地向键列添加索引来加速ClickHouse查询的冲动通常是不正确的。只有在研究了其他替代方法之后,才应该使用此高级功能,例如修改主键(查看 如何选择主键)、使用投影或使用实体化视图。即使跳数索引是合适的,也经常需要对索引和表进行仔细的调优。
在大多数情况下,一个有用的跳数索引需要主键和目标的非主列/表达式之间具有很强的相关性。如果没有相关性(如上图所示),那么在包含数千个值的块中,至少有一行满足过滤条件的可能性很高,并且只有几个块会被跳过。相反,如果主键的值范围(如一天中的时间)与潜在索引列中的值强相关(如电视观众年龄),则最小值类型的索引可能是有益的。注意,在插入数据时,可以增加这种相关性,方法是在sort /ORDER by键中包含额外的列,或者以在插入时对与主键关联的值进行分组的方式对插入进行批处理。例如,即使主键是一个包含大量站点事件的时间戳,特定site_id的所有事件也都可以被分组并由写入进程插入到一起,这将导致许多只包含少量站点id的颗粒,因此当根据特定的site_id值搜索时,可以跳过许多块。
跳数索引的另一个候选者是高基数表达式,其中任何一个值在数据中都相对稀疏。一个可能的例子是跟踪API请求中的错误代码的可观察性平台。某些错误代码虽然在数据中很少出现,但对搜索来说可能特别重要。error_code列上的set skip索引将允许绕过绝大多数不包含错误的块,从而显著改善针对错误的查询。
最后,关键的最佳实践是测试、测试、再测试。同样,与用于搜索文档的b-树二级索引或倒排索引不同,跳数索引行为是不容易预测的。将它们添加到表中会在数据摄取和查询方面产生很大的成本,这些查询由于各种原因不能从索引中受益。它们应该总是在真实世界的数据类型上进行测试,测试应该包括类型、粒度大小和其他参数的变化。测试通常会暴露仅仅通过思考不能发现的陷阱。
相关文章:
深入理解ClickHouse跳数索引
一、跳数索引 影响ClickHouse查询性能的因素很多。在大多数场景中,关键因素是ClickHouse在计算查询WHERE子句条件时是否可以使用主键。因此,选择适用于最常见查询模式的主键对于表的设计至关重要。 然而,无论如何仔细地调优主键ÿ…...

ElasticSearch中实际操作细节点
ElasticSearch中的细节点 文章目录 ElasticSearch中的细节点1、提示:1.1 ElasticSearch相关文档:1.2 Kibana的常用快捷键1.3 kibana的注释方式 2、term与terms的用法以及区别3、ElasticSearch中"index":"false","doc_values&qu…...

VCG 获取指定面片与顶点的索引
文章目录 一、介绍二、实现代码三、实现效果参考资料一、介绍 VCG Lib存在许多中方式对Mesh数据进行编码,其中最为常用的为顶点+三角形(比如三角形网格以及四面体网格)。VCG关于Mesh的定义如下所示: vcg::tri::TriMesh 包含顶点的容器类型(通常是std::vector),具体的顶点…...
开发知识点-Django
Django 1 了解简介2 Django项目结构3 url 地址 和视图函数4 路由配置5 请求及响应6 GET请求和POST请求查询字符串 7 Django设计模式及模板层8 模板层-变量和标签9 模板层-过滤器和继承继承 重写 10 url反向解析11 静态文件12 Django 应用及分布式路由创建之后 注册 一下 13 模型…...

Linux系统笔记参考
Linux系统笔记 一、基本命令 1、简单的几个命令 ls:显示指定目录下的文件目录清单(list) cd:切换目录,改变当前的工作目录(change directory) cd ~ 或 cd 切换到用户主目录(用户家…...

AI:62-基于深度学习的人体CT影像肺癌的识别与分类
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
数字孪生智慧工厂3D无代码编辑工具提供强大、简单功能
相比传统的2D/2.5D,3d可视化场景脱颖而出,成为更多行业的首选,然而传统的3D可视化场景制作需要花费大量的人力财力及周期来创建复杂的3D模型和场景,对很多企业及个人来说是个挑战,3D可视化场景编辑器通过简单的拖拉拽&…...

python 为什么这么受欢迎?python的优势到底在哪里?
常言道:“流水的语言,铁打的Python”,目前它可以说是已经"睥睨天下,傲视群雄"了。它天生丽质,易于读写,非常实用,从而赢得了广泛的群众基础,被誉为"宇宙最好的编程语言"&am…...

Flutter转换png图片为jpg图片
1.需求 在xxx产品需求中,需要将png图片转为jpg图片。 2.引用库 image: ^4.1.3 Dart图像库提供了以各种图像文件格式加载、保存和操作图像的功能。 该库可以与dart:io和dart:html一起用于命令行、Flutter和web应用程序。 注:4.0是该库先前版本的主要修订…...

c++ grpc 第一个用例
一、linux 包管理工具安装 sudo apt-get update sudo apt-get install -y build-essential autoconf libtool pkg-config cmake sudo apt-get install -y libgflags-dev libgtest-dev sudo apt-get install -y clang libc-dev# 安装 gRPC C 相关依赖 sudo apt-get install -y …...
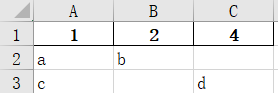
pandas笔记:读写excel
1 读excel read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。 支持读取单一sheet或几个sheet。 1.0 使用的数据 1.1 主要使用方法 pandas.read_excel(io, sheet_name0, header0, namesNone, index_colNone, usecolsNon…...

【ES分词】
分词 #测试分词器 POST /_analyze {"text": "小米手机和华为手机都是国产mobilephone", "analyzer": "english" }不管analyzer是改成:standard还是chinese都无法实现中文分词。 处理中文分词一般采用IK分词器 安装链接&…...

Git设置显示中文
git config --global i18n.comitencoding utf-8 git config --global i18n.logoutputencoding utf-8 export LESSCHARSETutf-8...

数实结合的复杂电磁环境构建解决方案
数实结合的复杂电磁环境构建解决方案 数实结合的复杂电磁环境构建 目前无线收发设备面临的电磁环境愈发恶劣。为了检验设备在复杂电磁环境下的实际工作性能,需进行各种应用条件下的测试和试验。外场测试难以提供各种应用环境,存在测试周期长、成本高、难…...

MySQL geometry 类型数据测试
MySQL的geometry类型的表的创建和测试: CREATE TABLE geom_test01( id INT NOT NULL PRIMARY KEY, info varchar(100), geom GEOMETRY ); desc geom_test01; insert into geom_test01 (id,info,geom) values (1, geom, geomfromtext(MULTIPOLYGON(((1 1…...

基于袋獾算法的无人机航迹规划-附代码
基于袋獾算法的无人机航迹规划 文章目录 基于袋獾算法的无人机航迹规划1.袋獾搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用袋獾算法来优化无人机航迹规划。 1.袋獾搜索算法 …...

2024上海智博会,上海国际智慧城市,物联网,大数据展会(世亚智博会)
中国国际智慧城市,物联网,大数据博览会(简称:世亚智博会)自2010年创办以来,至今已成功举办十多届。世亚智博会是中国较高、规模较大、影响力较广的展会;是被国际业界公认的不可错过的名展之一。随着世亚智博会的国际地位和影响不断…...

家庭教育质量提升成未来教育关注重点
随着教育改革的不断深化,家校合作模式也在实践中不断探索和丰富。 11 月 6 日,第六届长三角家校合作论坛于上海杨浦盛大开幕,此次论坛围绕“家校协同与人的学校领导”这一主题展开深度研讨。论坛旨在交流和分享相关经验及做法,以…...

python入门系列(1)—— 环境安装
前言 社区里面有好多同学想要入门python,可能源于以下原因: 易学性:Python 的语法简洁、清晰,容易理解和上手,使得初学者能够轻松入门编程。无论是编写基本的脚本还是进行更复杂的开发,Python 都提供了友…...

react组件通信
目录 前言: 父子组件通信 子父组件通信 兄弟组件通信 总结 前言: React是一种流行的JavaScript库,用于构建现代化的、高性能的Web应用程序。在React中,组件是代码的构建块。组件通信是React中一个非常重要的概念,…...

2026届必备的五大降重复率网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于内容创作进程里,若打算切实降低AIGC(人工智能生成内容)…...

DevEco Studio:多端设备预览
在工程目录中,打开任意一个ets文件:点击右侧的Previewer按钮:打开了预览窗口:点击右上角的Enable Profile Manager:打开Multi-profile preview:就可以同时在多种设备上预览了:...

MySQL 多表查询详解:从外键到连接查询
MySQL 多表查询详解:从外键到连接查询 在设计关系型数据库时,为了减少数据冗余,我们通常会将不同维度的数据存储在多张表中。当需要从多张表中联合提取数据时,多表查询就成为了核心技能。本文将系统讲解 MySQL 中的外键约束、内连…...

FineCat-NLI:动态注意力与对抗训练提升NLI性能
1. 项目概述FineCat-NLI这个项目名称直译为"精细分类-自然语言推理",从命名就能看出其核心目标:通过精细化的分类方法提升自然语言推理(NLI)编码器的性能表现。NLI作为自然语言处理(NLP)领域的基…...

3分钟搞定重复工作:KeymouseGo鼠标键盘自动化终极指南
3分钟搞定重复工作:KeymouseGo鼠标键盘自动化终极指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 你是否厌…...

2026年食品科学论文降AI工具推荐:食品安全和营养研究部分降AI方案
2026年食品科学论文降AI工具推荐:食品安全和营养研究部分降AI方案 四月答辩季,身边很多人在处理AI率问题。帮室友选过工具、帮师弟看过数据,综合对比下来推荐嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率…...

硬件指纹保护实战:三分钟掌握EASY-HWID-SPOOFER核心功能
硬件指纹保护实战:三分钟掌握EASY-HWID-SPOOFER核心功能 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 你是否曾因硬件指纹追踪而无法享受新用户优惠?或是…...

CentOS 7.9 老系统升级QEMU 6.2.0完整指南:从GCC 11到Python 3.9的依赖全搞定
CentOS 7.9 老系统升级QEMU 6.2.0完整指南:从GCC 11到Python 3.9的依赖全搞定 在虚拟化技术快速迭代的今天,许多企业仍在使用CentOS 7.9这样的"老将"系统。当我们需要在这些稳定但略显陈旧的系统上部署新版QEMU时,往往会遇到工具链…...

TinyLlama轻量级大模型微调实战:TRL与LoRA技术解析
1. 项目概述在自然语言处理领域,微调预训练语言模型已经成为定制化文本生成任务的标准方法。TinyLlama作为轻量级开源大语言模型,因其1.1B参数量和小巧的体积,特别适合在消费级硬件上进行微调实验。本项目使用TRL(Transformer Rei…...
为8.0%)
2026-2032期间,全球GNSS校正服务市场年复合增长率(CAGR)为8.0%
GNSS校正服务,即通过接收、处理和分析全球导航卫星系统(GNSS)信号,对原始GNSS定位数据进行校正和增强,以此提高定位精度与可靠性的服务。它借助地面接收站、数据处理中心和通信网络等基础设施,接收GNSS卫星…...