【redis】ssm项目整合redis,redis注解式缓存及应用场景,redis的击穿、穿透、雪崩的解决方案
目录
一、整合redis
1、介绍
1.1、redis(Remote Dictionary Server)
1.2、MySQL
1.3、区别
2、整合
2.1、配置
2.2、文件配置
2.3、key的生成规则方法
2.4、注意
二、redis注解式缓存
1、@Cacheable注解
2、@CachePut注解
3、@CacheEvict注解
4、应用场景
三、redis击穿穿透雪崩
1、击穿(Cache Miss)
2、穿透(Cache Penetration)
3、雪崩(Cache Avalanche)
一、整合redis
1、介绍
1.1、redis(Remote Dictionary Server)
- Redis是一种基于内存的键值存储系统,它将数据存储在内存中,因此读写速度非常快。
- Redis支持多种数据结构,如字符串、哈希、列表、集合、有序集合等,这使得Redis适用于各种应用场景,如缓存、消息队列、计数器等。
- Redis具有高可用性和可扩展性,支持主从复制和分片,以实现数据的备份和负载均衡。
- Redis的持久化方式有RDB(快照)和AOF(日志追加),可以将数据持久化到磁盘,保证数据的安全性。
1.2、MySQL
- MySQL是一种关系型数据库管理系统,使用标准的SQL语言进行数据操作。
- MySQL将数据存储在磁盘上,因此相对于Redis来说,读写速度较慢。
- MySQL支持事务处理和复杂的查询,适用于需要处理结构化数据的应用,如网站、电子商务等。
- MySQL具有较高的稳定性和成熟度,支持ACID特性(原子性、一致性、隔离性、持久性),可以保证数据的完整性和一致性。
1.3、区别
redis是nosql数据库
MySQL是sql数据库
更一步的理解:
- 存储方式:Redis将数据存储在内存中,而MySQL将数据存储在磁盘中。
- 数据结构:Redis支持多种数据结构,MySQL使用表格和关系进行数据存储。
- 读写性能:由于Redis使用内存存储,读写速度较快,而MySQL较慢。
- 功能特性:Redis适用于缓存和实时数据处理,MySQL适用于结构化数据的存储和复杂查询。
- ACID特性:MySQL支持事务处理和ACID特性,而Redis在默认情况下不支持事务处理。
- 持久化方式:Redis可以将数据持久化到磁盘,MySQL具有多种持久化方式,如日志文件和复制。
2、整合
2.1、配置
创建ssm的项目,在配置文件的pom文件添加
<redis.version>2.9.0</redis.version> <redis.spring.version>1.7.1.RELEASE</redis.spring.version><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>${redis.version}</version> </dependency> <dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId><version>${redis.spring.version}</version> </dependency>
2.2、文件配置
编写一个配置文件redis.properties,在我们的resources包里面。
redis.hostName:对应的IP地址
redis.port:对应的端口号
redis.password:对应的redis连接的密码redis.hostName=localhsot redis.port=6379 redis.password=123456 redis.timeout=10000 redis.maxIdle=300 redis.maxTotal=1000 redis.maxWaitMillis=1000 redis.minEvictableIdleTimeMillis=300000 redis.numTestsPerEvictionRun=1024 redis.timeBetweenEvictionRunsMillis=30000 redis.testOnBorrow=true redis.testWhileIdle=true redis.expiration=3600
spring-redis.xml里面包含了
- 添加注册
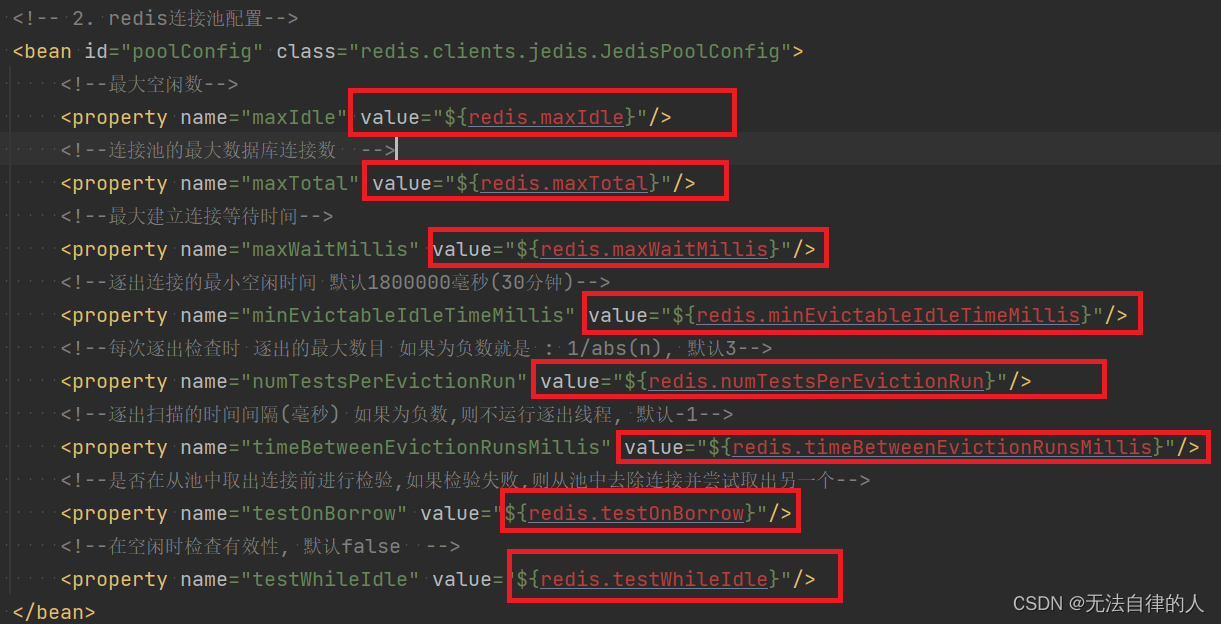
- redis的连接池配置:对应的value值是redis.properties里面的配置
- redis的的连接工厂:这里就用到了连接池的配置redis。
- 配置序列化:里面有string、json、hash的序列化器
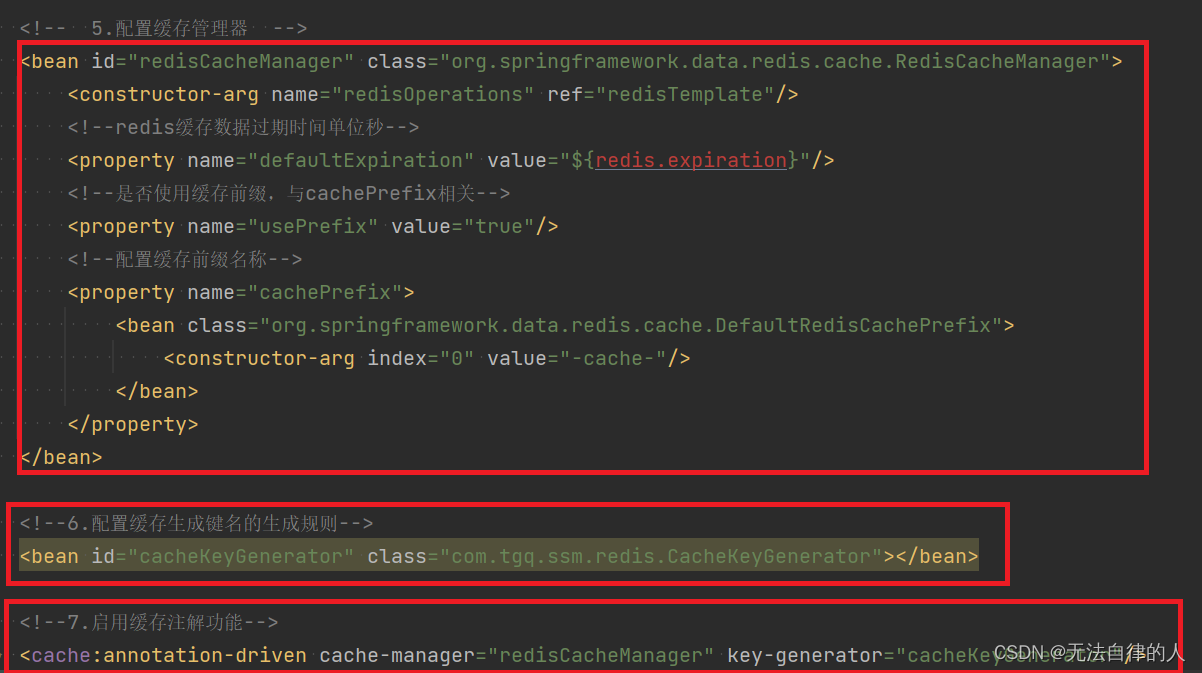
- 配置key的生成
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:cache="http://www.springframework.org/schema/cache"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context.xsdhttp://www.springframework.org/schema/cachehttp://www.springframework.org/schema/cache/spring-cache.xsd"><!-- 1. 引入properties配置文件 --><!--<context:property-placeholder location="classpath:redis.properties" />--><!-- 2. redis连接池配置--><bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig"><!--最大空闲数--><property name="maxIdle" value="${redis.maxIdle}"/><!--连接池的最大数据库连接数 --><property name="maxTotal" value="${redis.maxTotal}"/><!--最大建立连接等待时间--><property name="maxWaitMillis" value="${redis.maxWaitMillis}"/><!--逐出连接的最小空闲时间 默认1800000毫秒(30分钟)--><property name="minEvictableIdleTimeMillis" value="${redis.minEvictableIdleTimeMillis}"/><!--每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3--><property name="numTestsPerEvictionRun" value="${redis.numTestsPerEvictionRun}"/><!--逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1--><property name="timeBetweenEvictionRunsMillis" value="${redis.timeBetweenEvictionRunsMillis}"/><!--是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个--><property name="testOnBorrow" value="${redis.testOnBorrow}"/><!--在空闲时检查有效性, 默认false --><property name="testWhileIdle" value="${redis.testWhileIdle}"/></bean><!-- 3. redis连接工厂 --><bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory"destroy-method="destroy"><property name="poolConfig" ref="poolConfig"/><!--IP地址 --><property name="hostName" value="${redis.hostName}"/><!--端口号 --><property name="port" value="${redis.port}"/><!--如果Redis设置有密码 --><property name="password" value="${redis.password}"/><!--客户端超时时间单位是毫秒 --><property name="timeout" value="${redis.timeout}"/></bean><!-- 4. redis操作模板,使用该对象可以操作redishibernate课程中hibernatetemplete,相当于session,专门操作数据库。--><bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate"><property name="connectionFactory" ref="connectionFactory"/><!--如果不配置Serializer,那么存储的时候缺省使用String,如果用User类型存储,那么会提示错误User can't cast to String!! --><property name="keySerializer"><bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/></property><property name="valueSerializer"><bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/></property><property name="hashKeySerializer"><bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/></property><property name="hashValueSerializer"><bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/></property><!--开启事务 --><property name="enableTransactionSupport" value="true"/></bean><!-- 5.配置缓存管理器 --><bean id="redisCacheManager" class="org.springframework.data.redis.cache.RedisCacheManager"><constructor-arg name="redisOperations" ref="redisTemplate"/><!--redis缓存数据过期时间单位秒--><property name="defaultExpiration" value="${redis.expiration}"/><!--是否使用缓存前缀,与cachePrefix相关--><property name="usePrefix" value="true"/><!--配置缓存前缀名称--><property name="cachePrefix"><bean class="org.springframework.data.redis.cache.DefaultRedisCachePrefix"><constructor-arg index="0" value="-cache-"/></bean></property></bean><!--6.配置缓存生成键名的生成规则--><bean id="cacheKeyGenerator" class="com.tgq.ssm.redis.CacheKeyGenerator"></bean><!--7.启用缓存注解功能--><cache:annotation-driven cache-manager="redisCacheManager" key-generator="cacheKeyGenerator"/> </beans>
redis.properties与jdbc.properties在与Spring做整合时会发生冲突;所以引入配置文件的地方要放到applicationContext.xml中
applicationContext.xml配置如下
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"><!--1. 引入外部多文件方式 --><bean id="propertyConfigurer"class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"><property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE" /><property name="ignoreResourceNotFound" value="true" /><property name="locations"><list><value>classpath:jdbc.properties</value><value>classpath:redis.properties</value></list></property></bean><!-- 随着后续学习,框架会越学越多,不能将所有的框架配置,放到同一个配制间,否者不便于管理 --><import resource="applicationContext-mybatis.xml"></import><import resource="spring-redis.xml"></import><import resource="applicationContext-shiro.xml"></import> </beans>
2.3、key的生成规则方法
spring-redis.xml的最后的配置就说明了键的配置规则。
package com.tgq.ssm.redis;import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.util.ClassUtils;import java.lang.reflect.Array;
import java.lang.reflect.Method;@Slf4j
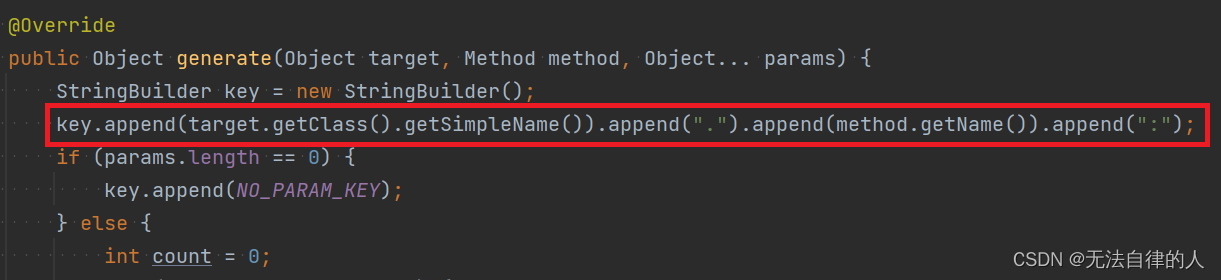
public class CacheKeyGenerator implements KeyGenerator {// custom cache keypublic static final int NO_PARAM_KEY = 0;public static final int NULL_PARAM_KEY = 53;@Overridepublic Object generate(Object target, Method method, Object... params) {StringBuilder key = new StringBuilder();key.append(target.getClass().getSimpleName()).append(".").append(method.getName()).append(":");if (params.length == 0) {key.append(NO_PARAM_KEY);} else {int count = 0;for (Object param : params) {if (0 != count) {//参数之间用,进行分隔key.append(',');}if (param == null) {key.append(NULL_PARAM_KEY);} else if (ClassUtils.isPrimitiveArray(param.getClass())) {int length = Array.getLength(param);for (int i = 0; i < length; i++) {key.append(Array.get(param, i));key.append(',');}} else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) {key.append(param);} else {//Java一定要重写hashCode和eqaulskey.append(param.hashCode());}count++;}}String finalKey = key.toString();
// IEDA要安装lombok插件log.debug("using cache key={}", finalKey);return finalKey;}
}
2.4、注意
- 在applicationContext.xml中注册多个.properties结尾配置,那么不能在spring-*.xml添加注册。
- resources的配置必须要涵盖读取.properties结尾的文件。
- redisTemplate的使用可以参考jdbcTemplate、amqpTemplate、rabbitMQTemplate等。
二、redis注解式缓存
1、@Cacheable注解
配置在方法或类上,作用:本方法执行后,先去缓存看有没有数据,如果没有,从数据库中查找出来,给缓存中存一份,返回结果,
下次本方法执行,在缓存未过期情况下,先在缓存中查找,有的话直接返回,没有的话从数据库查找。value:缓存位置的一段名称,不能为空。
key:缓存的key,默认为空,表示使用方法的参数类型及参数值作为key,支持SpEL。
condition:触发条件,满足条件就加入缓存,默认为空,表示全部都加入缓存,支持SpEL 。
- @Cacheable测试
但我们调用查询的方法而没有用@Cacheable注解的时候我们可以看到我们查询出来的结果是两个,而且查询了数据库两次。

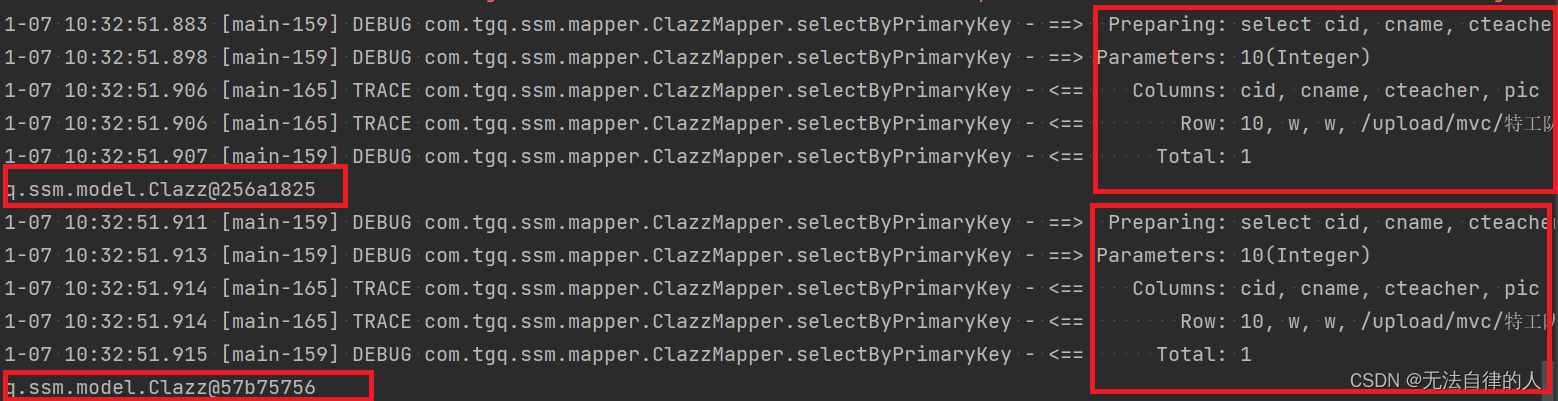
当我们用到@Cacheable注解的时候我们只查询了数据库一次,如果再次查询就不会出现sql语句,而且已经缓存到了redis里面。

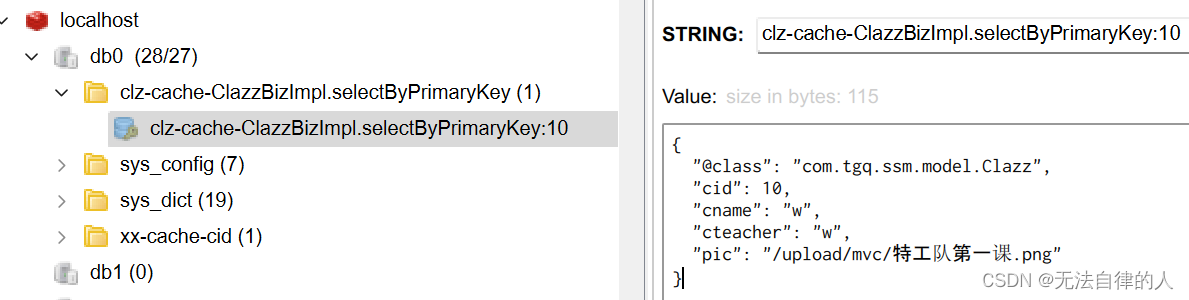
测试结果:redis中有数据,则访问redis;如果没有数据,则访问MySQL;
- 改变原有的key生成规则
改变原有的规则之后我们再次运行,我们的redis的键就不一样了。
condition:当某个值大于或者小于某个值才进行缓存。


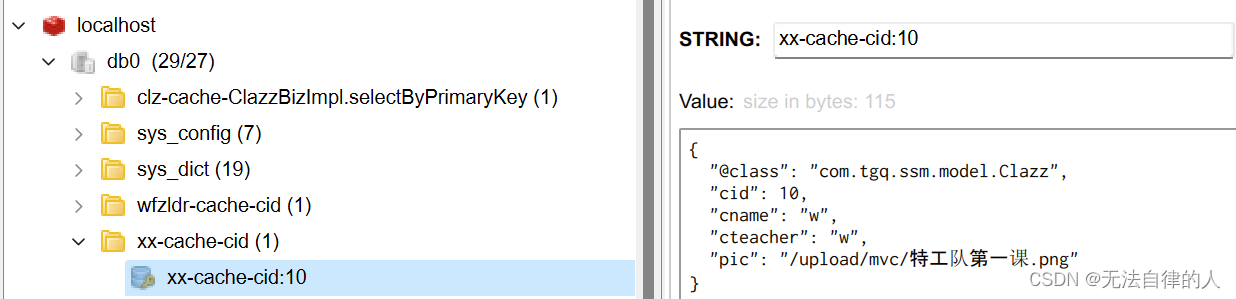
2、@CachePut注解
类似于更新操作,即每次不管缓存中有没有结果,都从数据库查找结果,并将结果更新到缓存,并返回结果。
value:缓存的名称,在 spring 配置文件中定义,必须指定至少一个。
key:缓存的 key,可以为空,如果指定要按照 SpEL 表达式编写,如果不指定,则缺省按照方法的所有参数进行组合。
condition:缓存的条件,可以为空,使用 SpEL 编写,返回 true 或者 false,只有为 true 才进行缓存。
当我们使用它测试出来的结果则是:只存不取
- @Cacheable与@CachePut区别
@Cacheable注解表示方法的返回值可以被缓存,下次访问相同的方法时,会直接从缓存中获取结果,而不会再执行方法内部的逻辑。该注解标记在方法上,指定了缓存的名称(也可以使用默认的缓存名称),也可以通过参数指定缓存的Key。如果缓存中已有相应的Key存在,则会直接返回缓存中的值;若缓存中不存在对应的Key,则会执行方法,并将方法的返回值添加到缓存中。
@CachePut注解表示无条件地执行方法内部的逻辑,并将方法的返回值添加到缓存中。该注解也标记在方法上,通常用于更新缓存的操作。它与@Cacheable注解的不同之处在于,每次调用带有@CachePut注解的方法时,都会执行方法内部的逻辑,并将结果添加到缓存中,覆盖原有的缓存值。
@CachePut注解常用于需要更新缓存中数据的场景,可以保证每次调用方法时都会执行方法内部的逻辑,并更新缓存的结果。Cacheable:会在redis中存储数据,同时也会读取数据。
CachePut:会在redis中写数据,不会读取数据。
3、@CacheEvict注解
用来清除用在本方法或者类上的缓存数据(用在哪里清除哪里)
value:缓存位置的一段名称,不能为空
key:缓存的key,默认为空,表示使用方法的参数类型及参数值作为key,支持SpEL
condition:触发条件,满足条件就加入缓存,默认为空,表示全部都加入缓存,支持SpEL
allEntries:true表示清除value中的全部缓存,默认为false
测试结果:可以配置删除指定缓存数据,也可以删除符合规则的所有缓存数据;
4、应用场景
Redis注解式缓存是一种通过使用注解来简化缓存操作的方法,它可以方便地在方法调用前后自动进行缓存的读取和写入。以下是Redis注解式缓存的常见应用场景:
-
方法结果缓存:对于一些计算成本较高的方法,可以使用注解将其结果缓存起来,避免重复计算。当下次调用相同的方法时,可以直接从缓存中获取结果,提高性能并减轻服务器负载。
-
数据查询缓存:对于频繁读取的数据查询操作,可以使用注解将查询结果缓存起来。这样可以避免反复查询数据库,提高系统的响应速度。
-
限流和熔断:通过使用注解实现限流,可以控制对某些资源或接口的并发请求量,避免系统过载。同时,可以设置特定的缓存时间,当资源或接口不可用时,返回缓存中的数据,实现熔断降级。
-
防止缓存穿透:通过使用注解和布隆过滤器等技术,可以在查询之前拦截请求,并且判断缓存中是否存在对应的数据。如果不存在,则直接返回空值,避免对数据库的无效查询。
-
异步刷新缓存:通过使用注解和异步任务,在数据更新时可以同时异步地更新相应的缓存,保持缓存和数据库的一致性。
三、redis击穿穿透雪崩
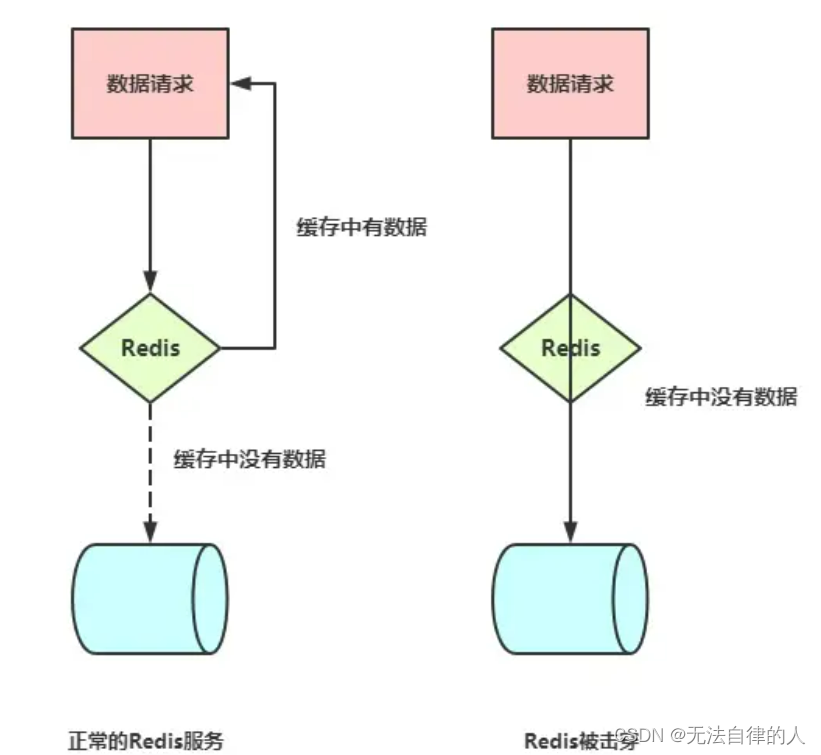
redis的简单的作用:能够极大的减轻MySQL的访问压力。
大部分的解决方案需要根据具体的场景和需求选择合适的解决方案。同时,合理的缓存策略、数据预热和监控是缓解这些问题的关键,以确保系统的稳定性和可靠性。
1、击穿(Cache Miss)
什么事缓存击穿?
缓存击穿就是在处于集中式高并发访问的情况下,当某个热点 key 在失效的瞬间,大量的请求在缓存中获取不到。瞬间击穿了缓存,所有请求直接打到数据库,就像是在一道屏障上击穿了一个洞。
高并发量的同时key失效,导致请求直接到达数据库;
- 解决方案之一:设置锁
- 使用互斥锁(Mutex Lock)或分布式锁(Distributed Lock)来防止并发请求同时访问数据库。
- 获取 Redis 锁,如果没有获取到,则回到任务队列继续排队
- 获取到锁,从数据库拉取数据并放入缓存中
- 释放锁,其他请求从缓存中拿到数据
- 另一种方式:限流
- 在缓存中设置短暂的过期时间,并使用异步更新机制,即在缓存失效时,只有一个请求重新加载数据到缓存中,其他请求等待缓存数据更新完成后再读取。
- 请求redis之前做流量削峰
2、穿透(Cache Penetration)
很多请求都在访问数据库一定不存在的数据,造成请求将缓存和数据库都穿透的情况。
解决方案如下:
- 规则排除:
- 使用布隆过滤器(Bloom Filter)等数据结构来过滤不存在的请求,在查询缓存之前先进行判断,避免对数据库进行不必要的查询。
- 或者可以增加一些参数检验。例如数据库数据 id 一般都是递增的,如果请求 id = -10 这种参数,势必绕过Redis。避免这种情况,可以对用户真实性检验等操作。
- 缓存空值(Null Cache):
- 即将空结果缓存一段时间,以避免频繁查询不存在的数据。
- 可以理解为当缓存穿透时,redis存入一个类似null的值,下次访问则直接缓存返回空,当数据库中存在该数据的值则需要把redis存在的null值清除并载入新值,此方案不能解决频繁随机不规则的key请求。
3、雪崩(Cache Avalanche)
雪崩和击穿类似,不同的是击穿是一个热点 Key 某时刻失效,而雪崩是大量的热点 Key 在一瞬间失效 。
方案如下:
- 设置合适的缓存失效时间,可以使用随机值或添加一定的时间偏移量,避免多个键同时失效,导致数据库负载过大。
- 使用多级缓存架构,将缓存分为多个层次,如本地缓存、分布式缓存等,提高缓存命中率和可用性。
- 实时监控缓存健康状态,当缓存出现异常时,采取相应的措施,如自动降级、限流等,保护后端系统。
更快捷的解决方案是:给不同的热点key设置不同的缓存策略
相关文章:
【redis】ssm项目整合redis,redis注解式缓存及应用场景,redis的击穿、穿透、雪崩的解决方案
目录 一、整合redis 1、介绍 1.1、redis(Remote Dictionary Server) 1.2、MySQL 1.3、区别 2、整合 2.1、配置 2.2、文件配置 2.3、key的生成规则方法 2.4、注意 二、redis注解式缓存 1、Cacheable注解 2、CachePut注解 3、CacheEvict注解…...

chatGPT对英语论文怎么润色呢?
chatGPT对英语论文怎么润色呢? 回答1: 润色英语论文是一项重要的任务,它有助于提高论文的质量、语法准确性和清晰度。以下是一些关于如何润色英语论文的建议: 语法和拼写检查: 使用拼写和语法检查工具,如…...

【机器学习4】降维
常见的降维方法有主成分分析、 线性判别分析、 等距映射、 局部线性嵌入、 拉普拉斯特征映射、 局部保留投影等。 1 PCA最大方差角度理解 PCA无监督学习算法。 PCA的目标, 即最大化投影方差, 也就是让数据在主轴上投影的方差最大。 在黄线所处的轴上&…...

注册商标有助于企业拓展市场渠道
拓展市场渠道 注册商标有助于企业拓展市场渠道。在商业合作和交易中,消费者往往更加倾向于选择有知名度和信誉的品牌。通过注册商标,企业可以树立自己的品牌形象,提高品牌知名度和美誉度,从而更好地开拓市场和拓展业务。同时&…...

推荐能用ios端磁力下载工具
关于ios端磁力下载工具,之前的文章给大家介绍过2个,分别是雷电下载和闪电下载。但是如今因为不可抗力和苹果商店对于磁力下载和云盘功能的限制,目前这两款工具已经不能够使用了。也就是说免费的下载工具已经没有了,毕竟实现ios端这…...

网页文档阅读的学习笔记
1. 阅读邮件 我是一名人工智能专业的博士生,请你帮我总结此页面的要点...
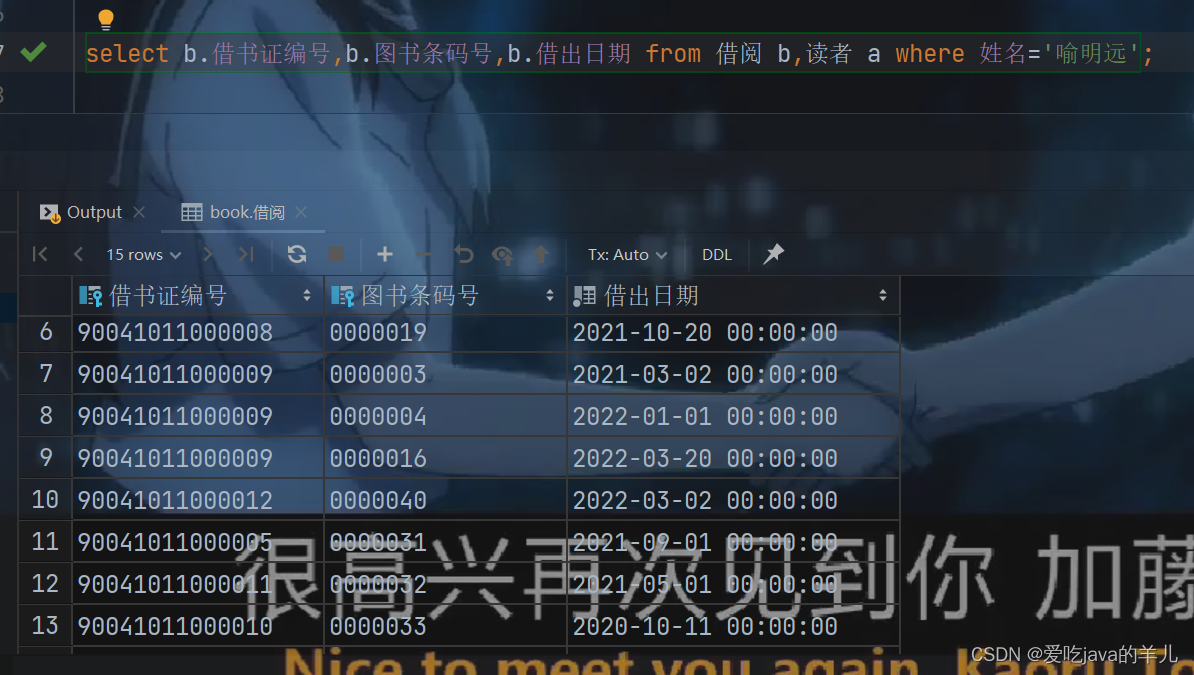
mysql图书管理系统(49-56)源代码
-- 九、 子查询 -- 无关子查询 -- 比较子查询:能确切知道子查询返回的是单值时,可以用>,<,,>,<,!或<>等比较运算符。 -- 49、 查询与“俞心怡”在同一个部门的读者的借…...

使用Docker部署开源分布式任务调度系统DolphinScheduler
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 使用Docker部署开源分布式任务调度系统DolphinScheduler 文章目录 使用Docker部署开源分布式任务…...

光猫桥接与直接拨号的对比
近期搬家,经历了一次拉宽带,换光猫,购置路由器的过程,有一些总结记录下来,备忘 装宽带之前已经知道桥接的好处就是可以路由器拨号,避免拉胯的光猫拖慢网速,但具体有什么坏处也不清楚࿰…...
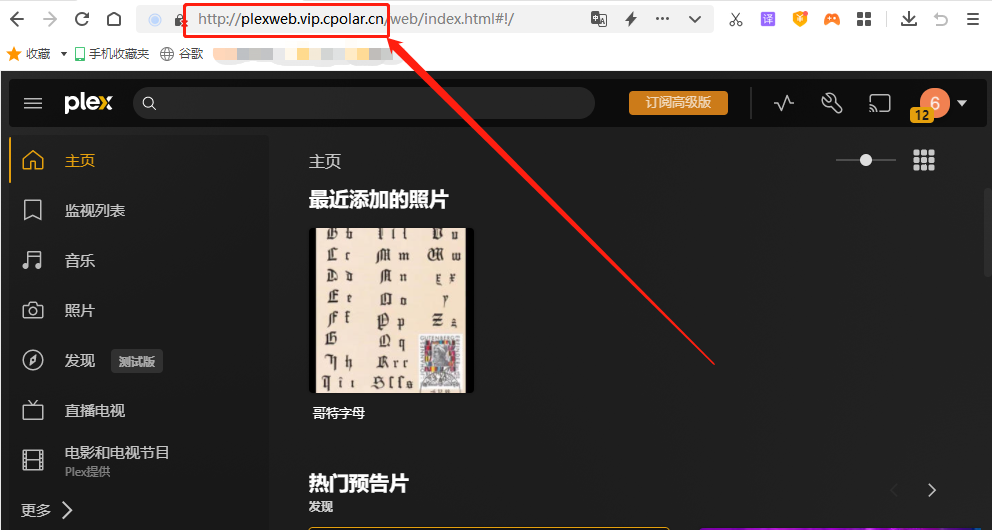
使用cpolar配合Plex搭建私人媒体站并实现远程访问
文章目录 1.前言2. Plex网站搭建2.1 Plex下载和安装2.2 Plex网页测试2.3 cpolar的安装和注册 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 用手机或者平板电脑看视频,已经算是生活中稀松平常的场景了,特别是各…...

Web APIs——综合案例
1、学生就业统计表 2、渲染业务 根据持久化数据渲染页面 步骤: ①:读取localstorage本地数据 如果有数据则转换为对象放到变量里面一会使用它渲染页面如果没有则用默认空数组[]为了测试效果,可以先把initData存入本地存储看效果 ②&…...
2023.10月考试战报|华为认证HCIP考试100%通过
相关文章: 考试战报|2023.7月-8月思科认证、华为认证-CSDN博客 2023.4月及5月最新HCIP 考试战报来袭_厦门微思网络的博客-CSDN博客 HCIP 3-4月考试战报_厦门微思网络的博客-CSDN博客 2023年HCIP/CCNP考试战报_厦门微思网络的博客-CSDN博客 2023年10月࿰…...

Oracle 三种分页方法(rownum、offset和fetch、row_number() over())
Oracle的三种分页指的是在进行分页查询时,使用三种不同的方式来实现分页效果,分别是使用rownum、使用offset和fetch、使用row_number() over() 1、使用rownum rownum是oracle中一个伪劣,它用于表示返回的行的序号。使用rownum进行分页查询的方…...

13. 一文快速学懂常用工具——Kubernetes 命令
本章讲解知识点 Kubernetes 基本命令本专栏适合于软件开发刚入职的学生或人士,有一定的编程基础,帮助大家快速掌握工作中必会的工具和指令。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。如专栏内容有错漏,欢迎在评论区指出或私聊我更改,一起学习,共同进步。…...

【Linux】shell执行文件清理
#!/usr/bin/env bash ################################################################################# # 程序名称: AutoClearFiles.sh # 创建日期: 2022-11-16 # 作者: evens # 使用说明: …...
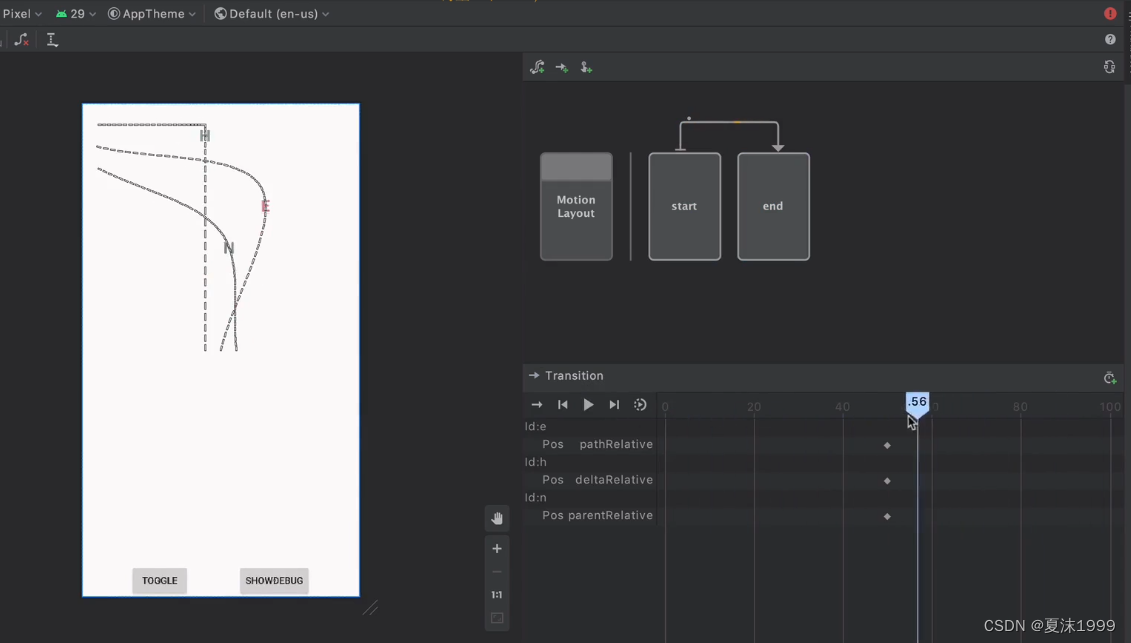
Android MotionLayout
MotionLayout exends ConstraintLayout(动画框架 过渡) View动画 API1 属性动画API11 过渡动画API18 root.width RootViewWidth TransitionManager.beginDelayedTransition(view) 过渡动画 可以改变其大小和流畅性 Fade 可以改变透明度 通过TrasitinManager管理 Go:动态替…...
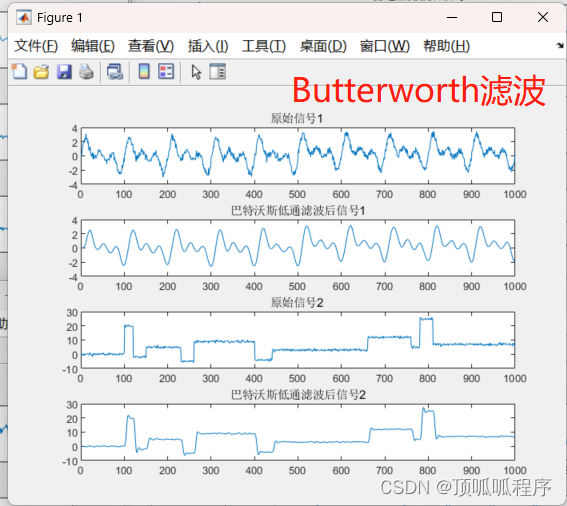
50基于matlab的传统滤波、Butterworth滤波、FIR、移动平均滤波、中值滤波、现代滤波、维纳滤波、自适应滤波、小波变换
基于matlab的传统滤波、Butterworth滤波、FIR、移动平均滤波、中值滤波、现代滤波、维纳滤波、自适应滤波、小波变换,七种滤波方法,可替换自己的数据进行滤波,程序已调通,可直接运行。 50matlabButterworth滤波 (xiaohongshu.com)…...
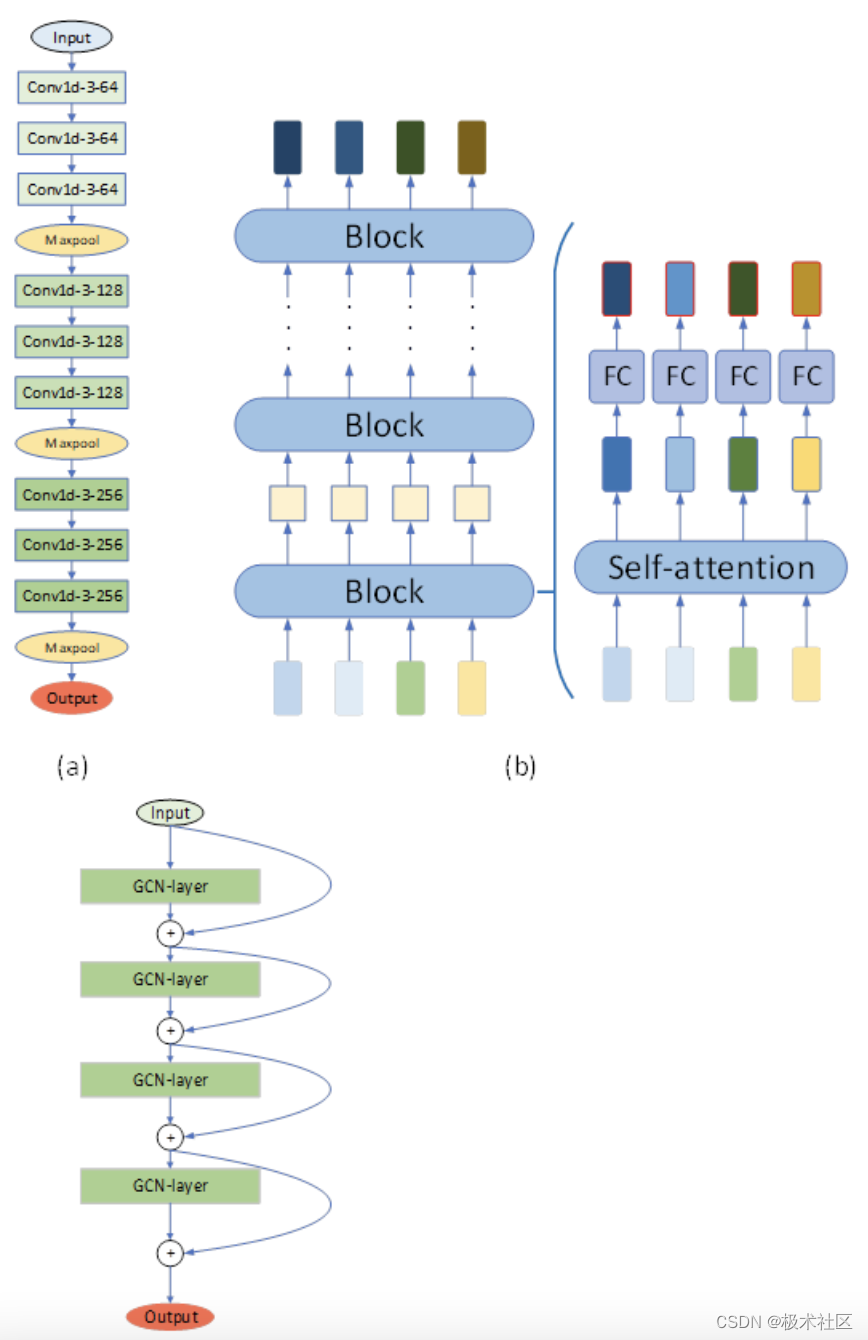
【2021研电赛】基于深度学习的蛋白质与化合物结合性质预测
本作品介绍参与极术社区的有奖征集|分享研电赛作品扩大影响力,更有重磅电子产品免费领取! 获奖情况:三等奖 1.作品简介 针对药物发现过程中的药物筛选问题,本设计基于深度学习提出新的神经网络结构和数据处理方式用于预测蛋白质与化合物之…...

物联网中的毫米波雷达:连接未来的智能设备
随着物联网(IoT)技术的飞速发展,连接设备的方式和效能变得越来越重要。毫米波雷达技术作为一种先进的感知技术,正在为物联网设备的连接和智能化提供全新的可能性。本文将深入探讨毫米波雷达在物联网中的应用,以及它是如…...

软件外包开发需求文档编写
软件外包开发需求文档是指导整个外包项目开发流程的关键文件,外包开发需求文档可能还包括修订历史记录、项目术语表、附录等其他有助于项目团队理解和实现需求的信息。它通常包含以下内容,希望对大家有所帮助。北京木奇移动技术有限公司,专业…...

3分钟搞定音乐标签乱码:Music Tag Web繁简转换实战指南
3分钟搞定音乐标签乱码:Music Tag Web繁简转换实战指南 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/music…...
)
FPGA数字信号发生器实战:基于ROM查表法生成任意波形(正弦/方波/三角波)
FPGA数字信号发生器实战:基于ROM查表法生成任意波形(正弦/方波/三角波) 在嵌入式系统开发和高频电路设计中,灵活可编程的信号发生器是不可或缺的工具。传统专用信号发生器往往价格昂贵且功能固化,而基于FPGA和ROM查表法…...

Python处理中文文件报错?别慌,教你用chardet库自动检测编码,告别UnicodeDecodeError
Python编码侦探指南:用chardet智能破解中文文件乱码困局 每次打开来源不明的文本文件时,那个令人头疼的UnicodeDecodeError就像个不速之客。作为Python开发者,你可能已经厌倦了反复猜测文件编码的游戏——GBK、UTF-8还是BIG5?今天…...

ISIS协议里的“身份证”:深入浅出聊聊NSAP和NET地址的设计哲学与实战意义
ISIS协议里的“身份证”:解码NSAP与NET地址的设计智慧与工程实践 当网络设备需要彼此识别时,它们靠什么证明自己的身份?就像人类社会的身份证承载着地域、出生信息和唯一编号,IS-IS协议中的NSAP和NET地址同样蕴含着精妙的设计哲学…...

【转载】pandas 的速查表
作者:不了哭 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 Pandas 是一个强大的分析结构化数据的工具集,它的使用基础是 Numpy(提供高性能的矩阵运算),用…...

智慧农业害虫识别 水稻病虫害数据集 农作物害虫识别数据集 褐飞虱数据集 绿叶蝉识别 卷叶螟、稻蝽检测数据集、二化螟识别数据集、稻潜叶蝇
水稻病虫害数据集核心信息简介 一、数据集核心信息速览表类别 lasses (6) 类别(6) brown-planthopper 褐飞虱 green-leafhopper 绿叶蝉 leaf-folder 卷叶虫 rice-bug 稻蝽象 stem-borer 蛀茎虫 whorl-maggot 卷叶蛆信息类别具体内容数据集类别目标检测类…...

2026年网安还值得学吗?新手程序员必看,建议收藏!
2026年网安还值得学吗?新手&程序员必看,建议收藏! 本文针对2026年网络安全学习价值答疑,指出当前互联网大厂缩编、应届生内卷,但网安岗人才缺口超200万,薪资涨幅可观,有实战经验者年薪轻松…...

LangChain Memory 最佳实践:别再用错记忆模块了
上一篇我们把 Memory 的三种策略——截断、总结、检索——从原理到选型梳理了一遍。这篇直接进实战:你现在用的 Memory 写法,可能已经被官方标注为"过时"了,而且坑还不少。 作为开发者,最怕的不是不会用,而…...

对话式AI隐私保护:从社交媒体广告困境到技术实践
1. 项目概述:社交媒体广告与隐私困境对对话式AI的启示当我在2018年第一次尝试开发聊天机器人时,发现用户最常问的不是功能问题,而是"你会记录我的聊天记录吗?"——这个现象直接反映了社交媒体时代留下的隐私创伤。斯坦福…...

终极视频对比分析工具:5分钟快速上手开源神器
终极视频对比分析工具:5分钟快速上手开源神器 【免费下载链接】video-compare Split screen video comparison tool using FFmpeg and SDL2 项目地址: https://gitcode.com/gh_mirrors/vi/video-compare 还在为视频画质差异而烦恼吗?无论是视频编…...