机器学习实战——《跟着迪哥学Python数据分析与机器学习实战》
跟着迪哥学Python数据分析与机器学习实战
- 一、基础部分
- 二、信用卡欺诈检测实战 —— 监督学习
- 2.1 下采样与过采样
- 2.1.1 过采样数据生成策略SMOTE
- 2.2 逻辑回归
- 2.3 分类结果混淆矩阵
- 2.4 过采样实战
- 2.5 实战总结
- 2.6 版本依赖排错
- 三、
- 知识加油站
- ¥银行卡的分类
一、基础部分
//@PASS,遇到有不会的再写,直接上手实战
二、信用卡欺诈检测实战 —— 监督学习
背景: 信用卡欺诈是指故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为,见《信用卡欺诈》 - 百度百科,那么有信用卡欺诈,有没有储蓄卡欺诈呢?有的,比如储蓄卡被他人冒领。
2.1 下采样与过采样
这个项目里的样本数据,异常样本非常少,这时,正常样本和异常样本的比例是不平衡的,正常数据多不是件好事吗?从采集的角度上看是的,但从模型建立角度上看不是,因为这样会导致模型认为数据都很好,就无法因对异常情况,那么只要让正常和异常数据的比例接近即可,方法是下采样和过采样。
(1) 下采样。让正常样本变少一些,可以变得和异常样本数量一样多。
(2) 过采样。造一些异常样本,让异常样本变多一些,这个造的方法是SMOTE数据生成策略。
2.1.1 过采样数据生成策略SMOTE
SMOTE = Synthetic Minority Over-sampling Technique,即合成少数类过采样技术,少数类指的是样本数量较少的类别,且合成的数据不能是一模一样的,这个过程用到了KNN聚类算法,计算每个少数类样本的K近邻,在这个实战项目里就是异常类,此算法过程如下:
(1)对于每一个少数类样本,计算其与所有其他少数类样本之间的距离,并找到其K个最近邻居,这个K被称作采样倍率,K越大,挑选的邻居越多。
(2)从这K个最近邻居中随机选择一个样本,并计算该样本与当前样本的差异。
(3)根据差异比例,生成一个新的合成样本,该样本位于两个样本之间的连线上。合成新样本的计算公式是, x x x是自身样本数据, x ~ \tilde{x} x~是邻居的样本数据
x n e w = x + r a n d ( 0 , 1 ) ∗ ( x ~ − x ) x_{new} = x + rand(0,1)*(\tilde{x} - x) xnew=x+rand(0,1)∗(x~−x)
写成下面的形式也是一样的,随着比例在0到1之间浮动,新生成的数据也在 x ~ \tilde{x} x~ 与 x x x 之间浮动。
x n e w = x ~ + r a n d ( 0 , 1 ) ∗ ( x − x ~ ) x_{new} = \tilde{x} + rand(0,1)*(x - \tilde{x}) xnew=x~+rand(0,1)∗(x−x~)
我觉得下面这种形式应该看起来更舒服
x n e w = a x + b x ~ , ( a + b = 1 , a > 0 , b > 0 ) x_{new} = ax + b\tilde{x}, \quad (a+b=1, a > 0, b > 0) xnew=ax+bx~,(a+b=1,a>0,b>0)
(4)重复上述步骤,生成指定数量的合成样本。
《解决样本不均衡问题:SMOTE过采样详解 - FAL金科应用研究院的文章 - 知乎》
2.2 逻辑回归
Logistic Regression (aka logit, MaxEnt) classifier.逻辑回归(又称为logit,最大熵分类器)
关键代码部分
# 指定算法模型,并且给定参数
lr = LogisticRegression(C = c_param, penalty = 'l1', solver='liblinear')
# 训练模型,注意索引不要给错了,训练的时候一定传入的是训练集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
第一行代码新建了一个分类器lr。
(1) C_param。惩罚力度,在sklearn包中,这个值越小,代表惩罚力度越大,值越大,惩罚力度越小,源代码的文档里是这么解释这个参数的:C: Inverse of regularization strength,正则化强度的反比。
(2) penalty = 'l1'。代表正则化惩罚项是 J = J 0 + α ∑ w ∣ w ∣ J = J_0 + \alpha \sum\limits_{w}{|w|} J=J0+αw∑∣w∣。
(3) solver='liblinear'。源代码文档里的描述是Solver: Algorithm to use in the optimization problem,即solver是一种使用在优化问题里的算法,短期内我不追求看懂什么是liblinear,liblinear论文是08年发的,所以教科书是肯定绝对没提过这些东西的,我只想知道liblinear究竟是用来做什么的,Scikit-learn solvers explained 这篇文章对solver的这些算法做了解释,我完全没有看懂,简要总结了两种
| solver | 含义 | 讲解或参考论文 |
|---|---|---|
| newton-cg | cg = conjugate gradient 牛顿-共轭梯度法 | 【数值分析6(3共轭梯度法)苏州大学】 |
| liblinear | 大型线性分类库。 liblinear是一个用于解决线性分类和线性回归问题的开源软件库。它通过使用支持向量机(SVM)等算法来执行二元分类、多元分类和回归任务。liblinear支持L1和L2正则化,并能够处理高维特征。它被广泛应用于文本分类、生物信息学、图像分类和人脸识别等领域。—— 大模型的回答 | LIBLINEAR: A Library for Large Linear Classification.pdf LIBSVM - Wikipedia LIBLINEAR算法解读,想看懂重点读 liblinear使用总结 |
继续看第二行,有了这个分类器lr后,开始对训练集进行fit拟合操作,y_train_data.iloc[indices[0],:].values.ravel()的意思是,将 Pandas DataFrame 转换为 NumPy 数组并展平
df = pd.DataFrame({'num_legs': [2, 4, 4, 6],'num_wings': [2, 0, 0, 0]})
print('example1:\n',df.iloc[df.index, :]) # better than two methods above.
print('example2:\n',df.iloc[df.index, :].values.ravel()) # better than two methods above.# example1:
# num_legs num_wings
# 0 2 2
# 1 4 0
# 2 4 0
# 3 6 0
# example2:
# [2 2 4 0 4 0 6 0]
2.3 分类结果混淆矩阵
代码调用部分,sklearn.metrics.confusion_matrix
# sklearn.metrics.confusion_matrix(真实标签值,预测标签值)
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
| 真实情况 \ 预测结果 | 正例 | 反例 | – |
|---|---|---|---|
| 正例Positive | TP(真正例) | FN(假正例) | 此行可定义查全率 R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP |
| 反例Negative | FP(假反例) | TN(真反例) | – |
| – | 此列可定义查准率 P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP | – | – |
查准率:真实值里有多少是预测对的,所以真实值做分母,这个指标更关注你预测的准不准,如果你是三体人的巫师,你可以少说话,追求查准率,否则就要被脱水了。
查全率:预测值里有多少是确实真的,所以预测值做分母,这个指标更关注你找到的多不多,如果你是地球人的医生,那请你多查房,追求查全率,否则病人就要蔫了。
看看下面这个例子,假设一个人积极揽活并且干活,身兼销售和技术双职位,销售拿下或拿不下项目,技术完成或完不成项目,但假设一个人的精力和客户关系都有限,那么要么项目拿下的多成功的少,要么拿下的少成功的多,这样收益也反而均衡,一鸣惊人和积少成多都有的,不多,拿下一个大项目和拿下多个小项目可以认为是等价的。
| 人员风格 \ 项目目标 | 大项目Big | 小项目Small | – |
|---|---|---|---|
| 一鸣惊人 | TB(完成·大) | FS(失败·小) | 此行可定义项目拿下率 P = T B T B + F S P=\frac{TB}{TB+FS} P=TB+FSTB |
| 积小成多 | FB(失败·大) | TS(完成·小) | 同上,可定义项目拿下率 |
| – | 此列可定义大项目成功率 R = T B T B + F B R = \frac{TB}{TB+FB} R=TB+FBTB | 同左,可定义小项目成功率 | – |
这里的拿下率,就可以类比为上面的查全率,关注的是项目拿下的多不多
这里的成功率,就可以类比为上面的查准率,关注的是项目完成的多不多
下面,我们来做一个对现实职场的探讨,我觉得大可以将这类情况往人际交往、情场、官场和其它地方延伸,去做一个验证,看下是不是在中国的社会环境里适用,国外也可以拿去套一套。
“好员工”是做的多 又做的好,这类员工,可能会拿一些回扣,但领导对其带来的收益还是满意的,所以睁一只眼,闭一只眼。
“清员工”是做的少所以做的好,在有些领导看来,虽然做的事情少,但每件事都狠抓落实,并且到位有成效,所以印象颇为不错。
“差员工”是做的多所以难免犯错,这类员工虽然做的事情很多,也有很多事情有成效,但做的事多难免也踩的雷多,犯下的错多,虽然给公司带来了很多收益,也造成了不小的损失,时间一长,就容易给领导留下不好的印象,这种人在某些情况下容易被边缘化,甚至是开除。
“平员工”是做的少却也会犯点小错,但在领导的印象里,这种人往往可能还要比上面那类“差员工”还要印象好些,毕竟犯错不多也犯不了大错,带来的损失不大,但要是论提拔却也谈不上,毕竟做的事不多。
2.4 过采样实战
代码运行结果表示,下采样导致了许多样本被误杀,这种宁肯错杀一千,不肯放过一个的态度,在保卫人民财产的行动中固然值得尊敬,但给整个系统的负担太过繁重,并且在实际操作中,会浪费人力物力关注到实际没有问题的卡上,导致真正应该被重点关注的异常信用卡记录,可能没有及时被注意到,从而加剧了信用卡诈骗现象。上面已经提到了SMOTE生成数据的原理,下面是实操。
调用imblearn工具包使用SMOTE算法,没装可以用pip install imblearn安装下,关键代码含义
# 使用SMOTE算法来进行生成负例样本,random_state是随机数种子,作用是控制每次随机生成的结果一致
oversampler=SMOTE(random_state=0)
# 将特征数据和标签传入,得到oversample_features,oversample_labels
os_features,os_labels=oversampler.fit_resample(features_train,labels_train)
imblearn.over_sampling.SMOTE
2.5 实战总结
下采样和过采样实战部分到此结束了,机器学习问题的处理过程,我们的妈妈才是大师。
(1) 分析问题,检查数据。(今天想吃什么菜,挑菜选菜)
(2) 清洗数据,数据预处理。(洗菜,切菜)
(3) 选择建模方法,进行建模。(蒸炸煎煮焖溜熬炖炒,下锅)
(4) 调参。(油盐酱醋放多少)
(5) 分析建模效果。(今天味道怎么样,吃的好不好,吃的饱不饱)
2.6 版本依赖排错
本项目的所有版本依赖错误的解决方法都在这:《机器学习 信用卡欺诈检测 程序迭代错误》
三、
知识加油站
¥银行卡的分类
中国人民银行已经规定商业银行发行全国使用的联名卡、IC卡、储值卡需要得到中国人民银行总行的审批,见:
《银行卡业务管理办法》 —— 中国人民银行
《银行卡种类》—— 西宁中心支行
【不是我针对谁,但在座的各位都不会用银行卡】—— bilibili
《预付卡、购物卡、储值卡有什么区别?卡券冷知识》
相关文章:

机器学习实战——《跟着迪哥学Python数据分析与机器学习实战》
跟着迪哥学Python数据分析与机器学习实战 一、基础部分二、信用卡欺诈检测实战 —— 监督学习2.1 下采样与过采样2.1.1 过采样数据生成策略SMOTE 2.2 逻辑回归2.3 分类结果混淆矩阵2.4 过采样实战2.5 实战总结2.6 版本依赖排错 三、知识加油站¥银行卡的分类 一、基础…...
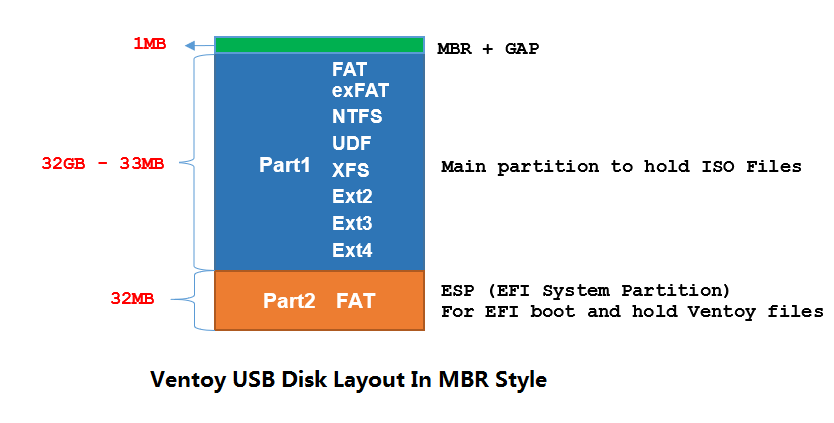
开源的全能维护 U 盘工具:Ventoy
开源的全能维护 U 盘工具:Ventoy 本篇文章聊聊迄今为止,我用着最舒服的一款开源 U 盘启动工具,Ventoy。 写在前面 好久不见,接下来计划写一个比较连续的内容,就先从最小的处着手吧。 经过长久的折腾,除…...

Redis7学习笔记01
一百零七、redis高级篇之缓存双写一致性面试题概览...

Redis的持久化机制和配置
Redis 的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制。 Redis 的持久化机制有两种,第一种是RDB快照,第二…...
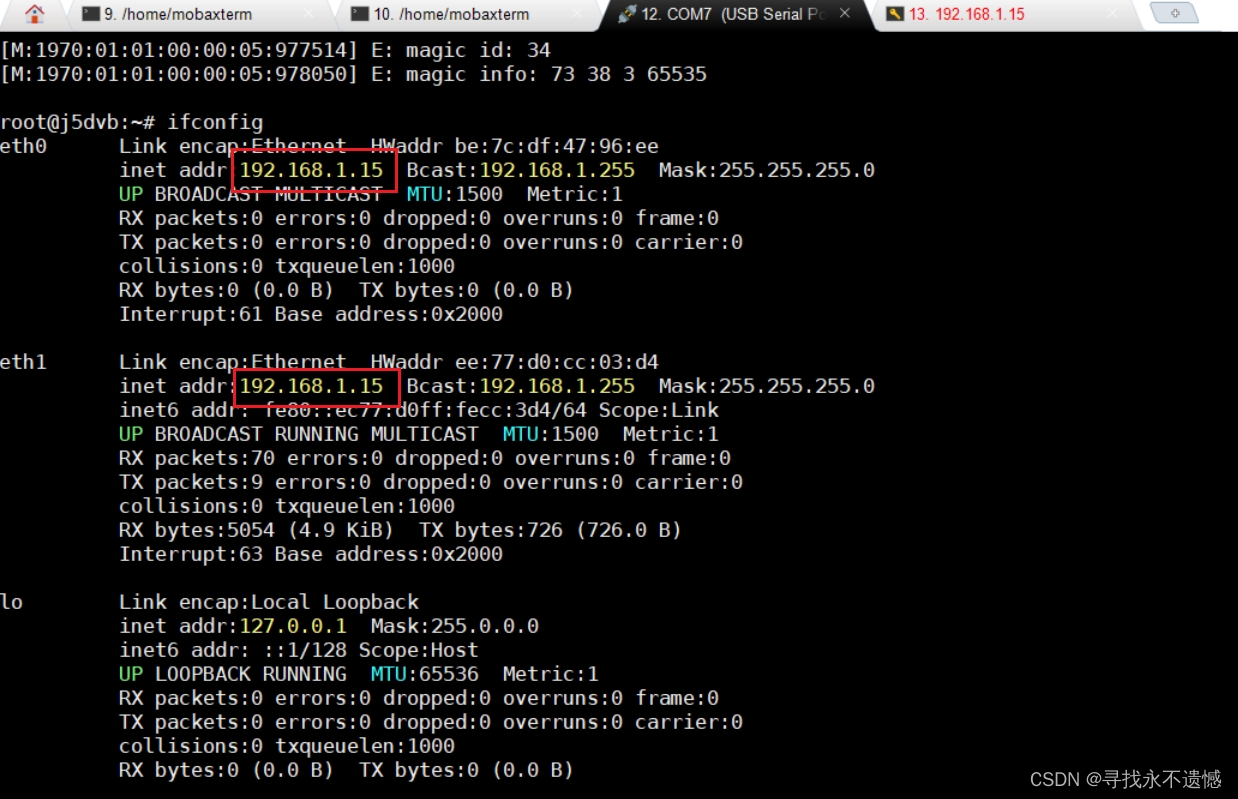
【IP固定】地平线开发板如何实现重启IP地址不变
文章目录 1 背景2 临时解决方案3 真正解决方案 1 背景 重新刷了地平线工具链OE包中BSP20230417的系统镜像,结果只能串口连接,无法实现网口连接,串口连接后,发现eth0和eth1的IP竟然是一样的,如下图所示 还挺少见的。 …...

CHATGPT----自然辩证法分析
CHATGPT----自然辩证法的要素,结构与功能 Chatgpt的要素组成: ChatGPT的构成主要包括语言模型、对话管理、知识库和用户接口等几个方面。 语言模型:ChatGPT的核心是语言模型,它是一种基于深度学习技术的自然语言处理模型&#…...
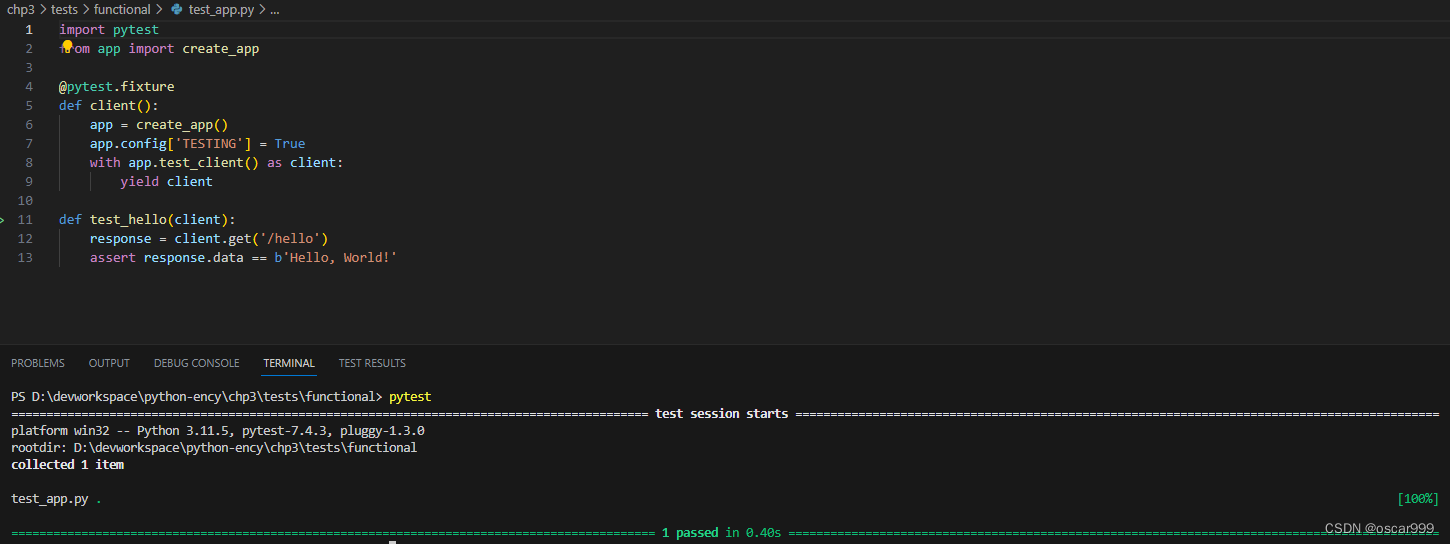
Python测试框架之pytest快速入门
pytest是一种流行的Python测试框架,支持创建简单的单元测试,也支持创建复杂的功能和集成测试。它提供了一系列有用的功能,能够方便地编写,组织和运行测试用例,并生成丰富的测试报告。 pytest的主要特点包括࿱…...

CSS 动画特效运用目录
主要是记录动画相关的特效实践案例和实现思路。 章节名称完成度难度文章地址完整代码下载地址拟态时钟动画完成一般文章地址完整代码下载...

css文本溢出省略号点点点
多行两端对齐省略号 .box {overflow: hidden;text-overflow: ellipsis;display: -webkit-box;-webkit-box-orient: vertical;-webkit-line-clamp: 3; // 限制显示的行数,单行就改成1 }...
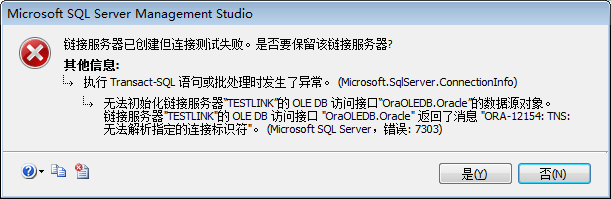
MSSQL 配置ORACLE 链接服务器
在有些场景,我们需要整合其他异构数据库的数据。我们可以使用代码去读取,经过处理后,再将数据保存到MSSQL数据库中。如果数据量比较大,但处理的逻辑并不复杂的情况下,这种方式就不是最好的办法。这时可以使用使用链接服…...

HiSilicon352 android9.0 适配红外遥控器
海思Android解决方案在原生Android基础上,基于传统电视用户使用习惯,增加了对红外遥控器和按键板的支持,使传统电视用户能更好适应智能电视方案。 一.功能描述: 在系统启动时,会先启动android_ir_user;vinp…...
0004Java安卓程序设计-springboot基于APP的鲜花商城
文章目录 **摘 要****目录**系统设计开发环境 编程技术交流、源码分享、模板分享、网课教程 🐧裙:776871563 摘 要 本毕业设计的内容是设计并且实现一个基于APP的鲜花商城。它是在Windows下,以MYSQL为数据库开发平台,java技术和…...

对Axios进行封装
封装的同时,你需要和 后端协商好一些约定,请求头,状态码,请求超时时间....... 设置接口请求前缀:根据开发、测试、生产环境的不同,前缀需要加以区分 请求头 : 来实现一些具体的业务,必须携带一…...

Python TCP服务端多线程接收RFID网络读卡器上传数据
本示例使用设备介绍:WIFI/TCP/UDP/HTTP协议RFID液显网络读卡器可二次开发语音播报POE-淘宝网 (taobao.com) #python通过缩进来表示代码块,不可以随意更改每行前面的空白,否则程序会运行错误!!!如果缩进不…...
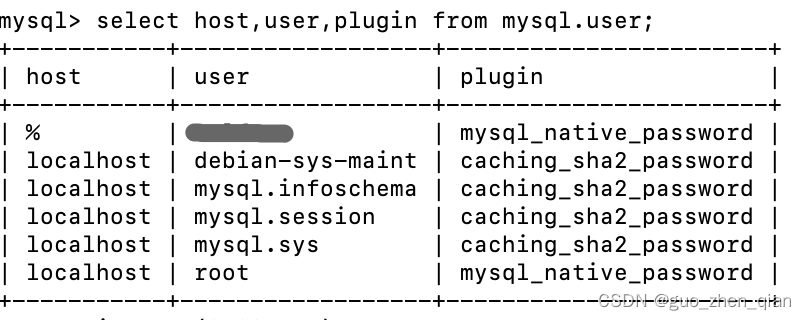
Ubuntu22.04安装MySql
在Ubuntu上安装mysql就比较简单了 1、常规操作,更新软件包列表 apt update 至少安装之前看一眼版本吧 apt list mysql-server 嗯,是8.0.35版本的 2、安装mysql apt install mysql-server 3、给root用户设置密码 # 第一次安装完无需密码,让你输入…...
)
设计模式-桥接模式(Bridge)
设计模式-桥接模式(Bridge) 一、桥接模式概述1.1 什么是桥接模式1.2 简单实现桥接模式 二、使用桥接模式注意事项三、实现桥接模式的方式3.1 使用继承和组合的方式实现桥接模式3.2 使用接口和内部类的方式实现桥接模式 一、桥接模式概述 1.1 什么是桥接…...
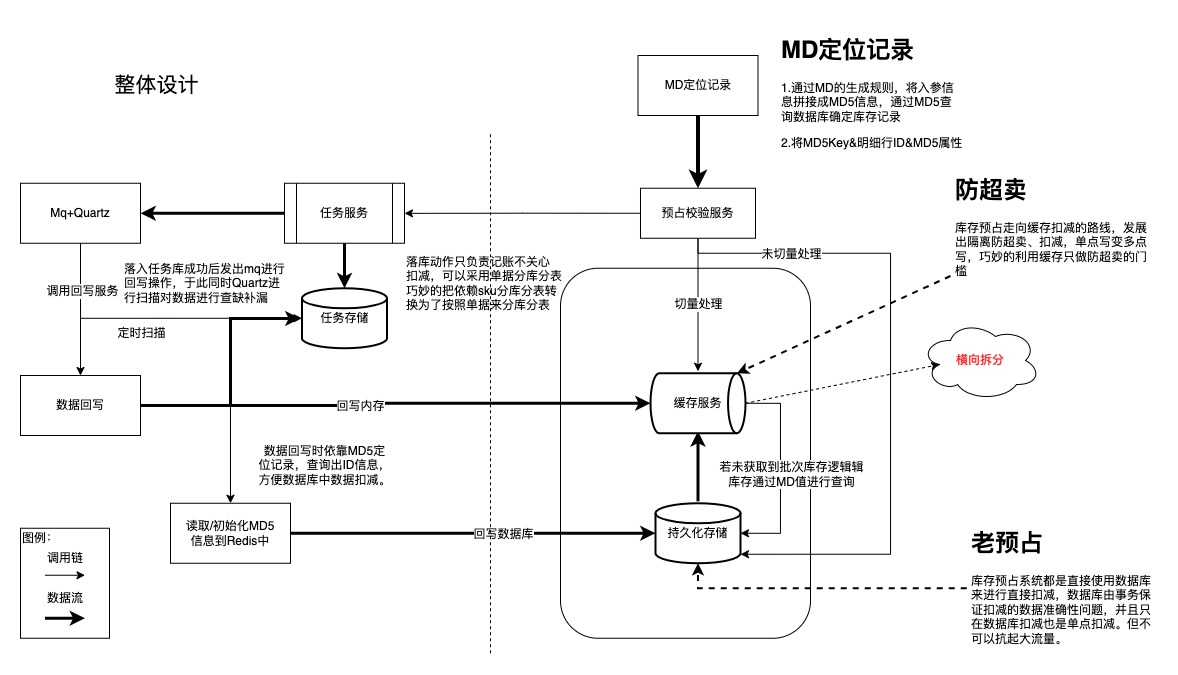
库存预占架构升级方案设计-交易库存中心
背景介绍  伴随物流行业的迅猛发展,一体化供应链模式的落地,对系统吞吐、系统稳定发出巨大挑战,库存作为供应链的重中之重表现更为明显。近三年数据可以看出:  接入商家同比增长37.64%、货…...
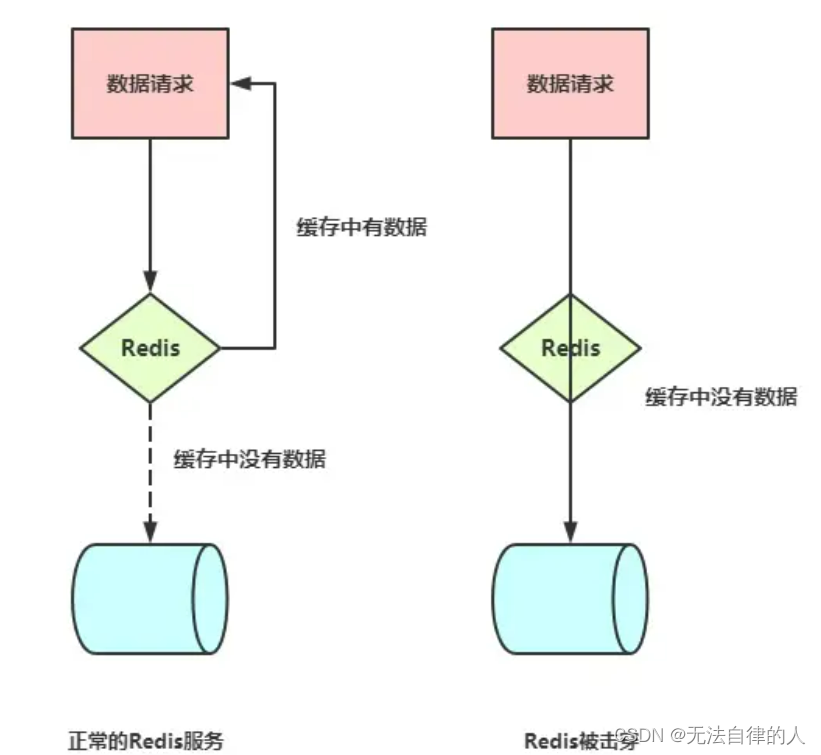
【redis】ssm项目整合redis,redis注解式缓存及应用场景,redis的击穿、穿透、雪崩的解决方案
目录 一、整合redis 1、介绍 1.1、redis(Remote Dictionary Server) 1.2、MySQL 1.3、区别 2、整合 2.1、配置 2.2、文件配置 2.3、key的生成规则方法 2.4、注意 二、redis注解式缓存 1、Cacheable注解 2、CachePut注解 3、CacheEvict注解…...

chatGPT对英语论文怎么润色呢?
chatGPT对英语论文怎么润色呢? 回答1: 润色英语论文是一项重要的任务,它有助于提高论文的质量、语法准确性和清晰度。以下是一些关于如何润色英语论文的建议: 语法和拼写检查: 使用拼写和语法检查工具,如…...

【机器学习4】降维
常见的降维方法有主成分分析、 线性判别分析、 等距映射、 局部线性嵌入、 拉普拉斯特征映射、 局部保留投影等。 1 PCA最大方差角度理解 PCA无监督学习算法。 PCA的目标, 即最大化投影方差, 也就是让数据在主轴上投影的方差最大。 在黄线所处的轴上&…...

Python量化回测框架Quantdom:从事件驱动到策略优化的实战指南
1. 从零到一:量化回测框架 Quantdom 深度解析如果你和我一样,在金融科技或者量化交易这个圈子里摸爬滚打了好些年,那你肯定对“回测”这个词又爱又恨。爱的是,它给了我们一个相对安全的沙盒,去验证那些在深夜灵光一现的…...

3步解锁Mac触控板原生体验:Windows用户必读的精准触控驱动配置指南
3步解锁Mac触控板原生体验:Windows用户必读的精准触控驱动配置指南 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision…...

把全连接层参数量砍掉90%?手把手教你用PyTorch实现Channel-Wise卷积替换分类头
用Channel-Wise卷积重构分类头:PyTorch实战指南与性能优化 在深度学习模型部署的最后一公里,全连接层往往成为内存和计算资源的黑洞。想象一下,当你的ResNet-50模型在移动设备上运行时,最后的全连接层占据了整个模型近25%的参数量…...

FanControl终极指南:让你的Windows风扇控制完全智能化
FanControl终极指南:让你的Windows风扇控制完全智能化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

14万+下载量!为什么Tavily Search是OpenClaw必装的第一技能?
没有它,你的AI Agent就是"瞎子" 一、先问一个问题 你用过ChatGPT吗? 那你一定遇到过这种情况:问它"2026年最新AI趋势",它告诉你"我的知识截止到2024年4月"。 这就是大模型的先天缺陷——知识有截…...
)
告别卡顿!在WinForm里用ScottPlot 5.0实现丝滑的XY轴缩放与拖拽(附完整源码)
告别卡顿!在WinForm里用ScottPlot 5.0实现丝滑的XY轴缩放与拖拽(附完整源码) 当工业监控系统需要实时展示数万条传感器数据,或是金融分析软件要快速响应投资者的交互操作时,图表控件的流畅度直接决定了用户体验的成败。…...

5分钟快速修复损坏视频:UnTrunc终极视频修复指南
5分钟快速修复损坏视频:UnTrunc终极视频修复指南 【免费下载链接】untrunc Restore a truncated mp4/mov. Improved version of ponchio/untrunc 项目地址: https://gitcode.com/gh_mirrors/un/untrunc 你是否遇到过珍贵的MP4视频文件意外损坏,无…...

无似然温度采样算法解析与应用实践
1. 无似然温度采样算法解析温度采样是控制生成模型输出的核心技术,传统方法通过调整softmax前的logits实现概率分布重缩放。但在无似然框架(如CALM)中,由于只能访问采样器而无法获取显式概率分布,这一方法面临根本性挑…...

如何加入DevDocs合作伙伴计划:打造技术文档生态系统的完整指南
如何加入DevDocs合作伙伴计划:打造技术文档生态系统的完整指南 【免费下载链接】devdocs API Documentation Browser 项目地址: https://gitcode.com/GitHub_Trending/de/devdocs DevDocs作为一款强大的API文档浏览器,致力于为开发者提供集中、高…...

WarcraftHelper:魔兽争霸3终极兼容性修复方案
WarcraftHelper:魔兽争霸3终极兼容性修复方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上运行不畅而烦恼…...