MapReduce 读写数据库
MapReduce 读写数据库
经常听到小伙伴吐槽 MapReduce 计算的结果无法直接写入数据库,
实际上 MapReduce 是有操作数据库实现的
本案例代码将实现 MapReduce 数据库读写操作和将数据表中数据复制到另外一张数据表中
准备数据表
create database htu;
use htu;
create table word(name varchar(255) comment '单词',count int comment '数量'
);
create table new_word(name varchar(255) comment '单词',count int comment '数量'
);
数据库持久化类
package com.lihaozhe.db;import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;/*** @author 李昊哲* @version 1.0.0* @create 2023/11/7*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class Word implements DBWritable {/*** 单词*/private String name;/*** 单词数量*/private int count;@Overridepublic String toString() {return this.name + "\t" + this.count;}@Overridepublic void write(PreparedStatement pst) throws SQLException {pst.setString(1, this.name);pst.setInt(2, this.count);}@Overridepublic void readFields(ResultSet rs) throws SQLException {this.name = rs.getString(1);this.count = rs.getInt(2);}
}MapReduce 将数据写入数据库
package com.lihaozhe.db;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import java.io.IOException;/*** @author 李昊哲* @version 1.0* @create 2023-11-7*/
public class Write {public static class WordMapper extends Mapper<LongWritable, Text, Word, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Word, NullWritable>.Context context) throws IOException, InterruptedException {String[] split = value.toString().split("\t");Word word = new Word();word.setName(split[0]);word.setCount(Integer.parseInt(split[1]));context.write(word, NullWritable.get());}}public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 设置环境变量 hadoop 用户名 为 rootSystem.setProperty("HADOOP_USER_NAME", "root");// 参数配置对象Configuration conf = new Configuration();// 配置JDBC 参数DBConfiguration.configureDB(conf,"com.mysql.cj.jdbc.Driver","jdbc:mysql://spark03:3306/htu?useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&serverTimeZone=Asia/Shanghai","root", "Lihaozhe!!@@1122");// 跨平台提交conf.set("mapreduce.app-submission.cross-platform", "true");// 本地运行// conf.set("mapreduce.framework.name", "local");// 设置默认文件系统为 本地文件系统// conf.set("fs.defaultFS", "file:///");// 声明Job对象 就是一个应用Job job = Job.getInstance(conf, "write db");// 指定当前Job的驱动类// 本地提交 注释该行job.setJarByClass(Write.class);// 本地提交启用该行// job.setJar("D:\\work\\河南师范大学\\2023\\bigdata2023\\Hadoop\\code\\hadoop\\target\\hadoop.jar");// 指定当前Job的 Mapperjob.setMapperClass(WordMapper.class);// 指定当前Job的 Combiner 注意:一定不能影响最终计算结果 否则 不使用// job.setCombinerClass(WordCountReduce.class);// 指定当前Job的 Reducer// job.setReducerClass(WordCountReduce.class);// 设置 reduce 数量为 零job.setNumReduceTasks(0);// 设置 map 输出 key 的数据类型job.setMapOutputValueClass(WordMapper.class);// 设置 map 输出 value 的数据类型job.setMapOutputValueClass(NullWritable.class);// 设置最终输出 key 的数据类型// job.setOutputKeyClass(Text.class);// 设置最终输出 value 的数据类型// job.setOutputValueClass(NullWritable.class);// 定义 map 输入的路径 注意:该路径默认为hdfs路径FileInputFormat.addInputPath(job, new Path("/wordcount/result/part-r-00000"));// 定义 reduce 输出数据持久化的路径 注意:该路径默认为hdfs路径
// Path dst = new Path("/video/ods");
// // 保护性代码 如果 reduce 输出目录已经存在则删除 输出目录
// DistributedFileSystem dfs = new DistributedFileSystem();
// String nameService = conf.get("dfs.nameservices");
// String hdfsRPCUrl = "hdfs://" + nameService + ":" + 8020;
// dfs.initialize(URI.create(hdfsRPCUrl), conf);
// if (dfs.exists(dst)) {
// dfs.delete(dst, true);
// }// FileSystem fs = FileSystem.get(conf);
// if (fs.exists(dst)) {
// fs.delete(dst, true);
// }
// FileOutputFormat.setOutputPath(job, dst);// 设置输出类job.setOutputFormatClass(DBOutputFormat.class);// 配置将数据写入表DBOutputFormat.setOutput(job, "word", "name", "count");// 提交 job// job.submit();System.exit(job.waitForCompletion(true) ? 0 : 1);}
}MapReduce 从数据库读取数据
注意:
由于集群环境 导致 MapTask数量不可控可导致最终输出文件可能不止一个,
可以在代码使用 conf.set(“mapreduce.job.maps”, “1”) 设置 MapTask 数量
package com.lihaozhe.db;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;/*** @author 李昊哲* @version 1.0* @create 2023-11-7*/
public class Read {public static class WordMapper extends Mapper<LongWritable, Word, Word, NullWritable> {@Overrideprotected void map(LongWritable key, Word value, Mapper<LongWritable, Word, Word, NullWritable>.Context context) throws IOException, InterruptedException {context.write(value, NullWritable.get());}}public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 设置环境变量 hadoop 用户名 为 rootSystem.setProperty("HADOOP_USER_NAME", "root");// 参数配置对象Configuration conf = new Configuration();// 配置JDBC 参数DBConfiguration.configureDB(conf,"com.mysql.cj.jdbc.Driver","jdbc:mysql://spark03:3306/htu?useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&serverTimeZone=Asia/Shanghai","root", "Lihaozhe!!@@1122");// 跨平台提交conf.set("mapreduce.app-submission.cross-platform", "true");// 设置 MapTask 数量conf.set("mapreduce.job.maps", "1");// 本地运行// conf.set("mapreduce.framework.name", "local");// 设置默认文件系统为 本地文件系统// conf.set("fs.defaultFS", "file:///");// 声明Job对象 就是一个应用Job job = Job.getInstance(conf, "read db");// 指定当前Job的驱动类// 本地提交 注释该行job.setJarByClass(Read.class);// 本地提交启用该行// job.setJar("D:\\work\\河南师范大学\\2023\\bigdata2023\\Hadoop\\code\\hadoop\\target\\hadoop.jar");// 指定当前Job的 Mapperjob.setMapperClass(WordMapper.class);// 指定当前Job的 Combiner 注意:一定不能影响最终计算结果 否则 不使用// job.setCombinerClass(WordCountReduce.class);// 指定当前Job的 Reducer// job.setReducerClass(WordCountReduce.class);// 设置 reduce 数量为 零job.setNumReduceTasks(0);// 设置 map 输出 key 的数据类型job.setMapOutputValueClass(Word.class);// 设置 map 输出 value 的数据类型job.setMapOutputValueClass(NullWritable.class);// 设置最终输出 key 的数据类型// job.setOutputKeyClass(Text.class);// 设置最终输出 value 的数据类型// job.setOutputValueClass(NullWritable.class);// 设置输入类job.setInputFormatClass(DBInputFormat.class);// 配置将数据写入表DBInputFormat.setInput(job, Word.class,"select name,count from word","select count(*) from word");// 定义 map 输入的路径 注意:该路径默认为hdfs路径// FileInputFormat.addInputPath(job, new Path("/wordcount/result/part-r-00000"));// 定义 reduce 输出数据持久化的路径 注意:该路径默认为hdfs路径Path dst = new Path("/wordcount/db");// 保护性代码 如果 reduce 输出目录已经存在则删除 输出目录DistributedFileSystem dfs = new DistributedFileSystem();String nameService = conf.get("dfs.nameservices");String hdfsRPCUrl = "hdfs://" + nameService + ":" + 8020;dfs.initialize(URI.create(hdfsRPCUrl), conf);if (dfs.exists(dst)) {dfs.delete(dst, true);}// FileSystem fs = FileSystem.get(conf);
// if (fs.exists(dst)) {
// fs.delete(dst, true);
// }FileOutputFormat.setOutputPath(job, dst);// 提交 job// job.submit();System.exit(job.waitForCompletion(true) ? 0 : 1);}
}MapReduce 实现数据库表复制
MapReduce 实现将数据库一张数据表的数据复制到另外一张数据表中
package com.lihaozhe.db;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;import java.io.IOException;/*** @author 李昊哲* @version 1.0* @create 2023-11-7*/
public class Copy {public static class RWMapper extends Mapper<LongWritable, Word, Word, NullWritable> {@Overrideprotected void map(LongWritable key, Word value, Mapper<LongWritable, Word, Word, NullWritable>.Context context) throws IOException, InterruptedException {context.write(value, NullWritable.get());}}public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {System.setProperty("HADOOP_USER_NAME", "root");// 参数配置对象Configuration conf = new Configuration();// 配置JDBC 参数DBConfiguration.configureDB(conf,"com.mysql.cj.jdbc.Driver","jdbc:mysql://spark03:3306/htu?useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=UTF8&useSSL=false&serverTimeZone=Asia/Shanghai","root", "Lihaozhe!!@@1122");// 跨平台提交conf.set("mapreduce.app-submission.cross-platform", "true");// 设置 MapTask 数量// conf.set("mapreduce.job.maps", "1");// 声明Job对象 就是一个应用Job job = Job.getInstance(conf, "read db");job.setJarByClass(Read.class);job.setMapperClass(Read.WordMapper.class);job.setNumReduceTasks(0);job.setMapOutputValueClass(Word.class);job.setMapOutputValueClass(NullWritable.class);// 设置输入类job.setInputFormatClass(DBInputFormat.class);// 配置将数据写入表DBInputFormat.setInput(job, Word.class,"select name,count from word","select count(*) from word");// 设置输出类job.setOutputFormatClass(DBOutputFormat.class);// 配置将数据写入表DBOutputFormat.setOutput(job, "new_word", "name", "count");System.exit(job.waitForCompletion(true) ? 0 : 1);}
}相关文章:

MapReduce 读写数据库
MapReduce 读写数据库 经常听到小伙伴吐槽 MapReduce 计算的结果无法直接写入数据库, 实际上 MapReduce 是有操作数据库实现的 本案例代码将实现 MapReduce 数据库读写操作和将数据表中数据复制到另外一张数据表中 准备数据表 create database htu; use htu; creat…...
)
设计模式 -- 状态模式(State Pattern)
状态模式:类的行为基于它的状态改变 属于行为型模式,创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。在代码中包含大量与对象状态有关的条件语句可以通过此模式将各种具体的状态类抽象出来 介绍 意图:允许对象在…...

qt quick发布程序启动失败
qt quick/qml 程序发布之后,程序启动不了 经过探究测试,程序启动的不了的情况下是因为有dll没有添加。在release文件夹下进行发布操作(不单独复制xx.exe拿出来),再次点击IDE的RUN按钮,则会提示有Moudle没有…...

nginx反向代理报错合集
本文汇集了最近在使用nginx反向代理过程中遇到的一系列错误及其解决办法。 1缺乏支持项导致nginx配置错误 在利用sudo ./configure --with-http_ssl_module --with-http_stub_status_module进行配置时,往往会遇到以下类型的错误 error: the HTTP rewrite module …...

【Linux精讲系列】——vim详解
作者主页 📚lovewold少个r博客主页 ⚠️本文重点:c入门第一个程序和基本知识讲解 👉【C-C入门系列专栏】:博客文章专栏传送门 😄每日一言:宁静是一片强大而治愈的神奇海洋! 目录 目录 作者…...

微信小程序自动化采集方案
本文仅供学习交流,只提供关键思路不会给出完整代码,严禁用于非法用途,拒绝转载,若有侵权请联系我删除! 一、引言 1、对于一些破解难度大,花费时间长的目标,我们可以先采用自动化点击触发请求&…...

操作系统第三章王道习题_内存管理_总结易错知识点
1. 静态重定位和动态重定位 静态重定位(可重定位装入):作业在装入内存的时候,就修改它的物理地址. 静态重定位进程数据一旦确定位置,就不能再移动 动态重定位(动态运行时装入):作业装入内存的时候,不修改物理地址,直到运行的时候,根据重定位寄存器再修改地址. 对…...

uniapp刻度尺的实现(swiper)滑动打分器
实现图(百分制):滑动swiper进行打分,分数加减 <view class"scoring"><view class"toggle"><view class"score"><text>{{0}}</text><view class"scoreId&quo…...
cordova Xcode打包ios以及发布流程(ionic3适用)
第一步 1、申请iOS证书 2、导入证书到钥匙串 第二步 1、xcode配置iOS证书 1.1用Xcode打开你的项目(我的Xcode版本是新版) 修改如下图 回到基本信息设置界面,Bundie 这项填写,最先创建的那个appid,跟创建iOS描述文件时选…...
,新旧版idea打开同一个项目会不会出现不兼容)
idea中的.idea文件夹以及*.iml文件(新版idea没有*.iml文件了),新旧版idea打开同一个项目会不会出现不兼容
一、背景 我们有可能会在同一台电脑上安装2个 intellj idea。比如一个community edition一个ultimate edition(一个安装板一个绿色解压版) 当然了,两个idea之间可能版本号也会有差。 这篇文章就来讨论两个问题,一是关于idea产生…...

高性能网络编程 - The C10K problem 以及 网络编程技术角度的解决思路
文章目录 C10KC10K的由来C10K问题在技术层面的典型体现C10K问题的本质C10K解决思路思路一:每个进程/线程处理一个连接思路二:每个进程/线程同时处理多个连接(IO多路复用)● 实现方式1:直接循环处理多个连接● 实现方式…...

uniapp u-tabs表单如何默认选中
首先先了解该组件;该组件,是一个tabs标签组件,在标签多的时候,可以配置为左右滑动,标签少的时候,可以禁止滑动。 该组件的一个特点是配置为滚动模式时,激活的tab会自动移动到组件的中间位置。 …...

2023年腾讯云双11活动入口在哪里?
2023年双11腾讯云推出了11.11大促优惠活动,下面给大家分享腾讯云双11活动入口、活动时间、活动详情,希望可以助力大家轻松上云! 一、腾讯云双11活动入口 活动地址:点此直达 二、腾讯云双11活动时间 腾讯云双11活动时间跨度很长…...

Windows 下编译 TensorFlow 2.12.0 CC库
大体参考 Windows 下编译 TensorFlow 2.9.1 CC库-CSDN博客 这个版本不完整,需要从 TensorFlow 2.14.0 根目录复制 WORKSPACE 覆盖原同名文件,还需要复制TensorFlow 2.14.0 的 tensorflow\tools\toolchains\python 到相同目录。...
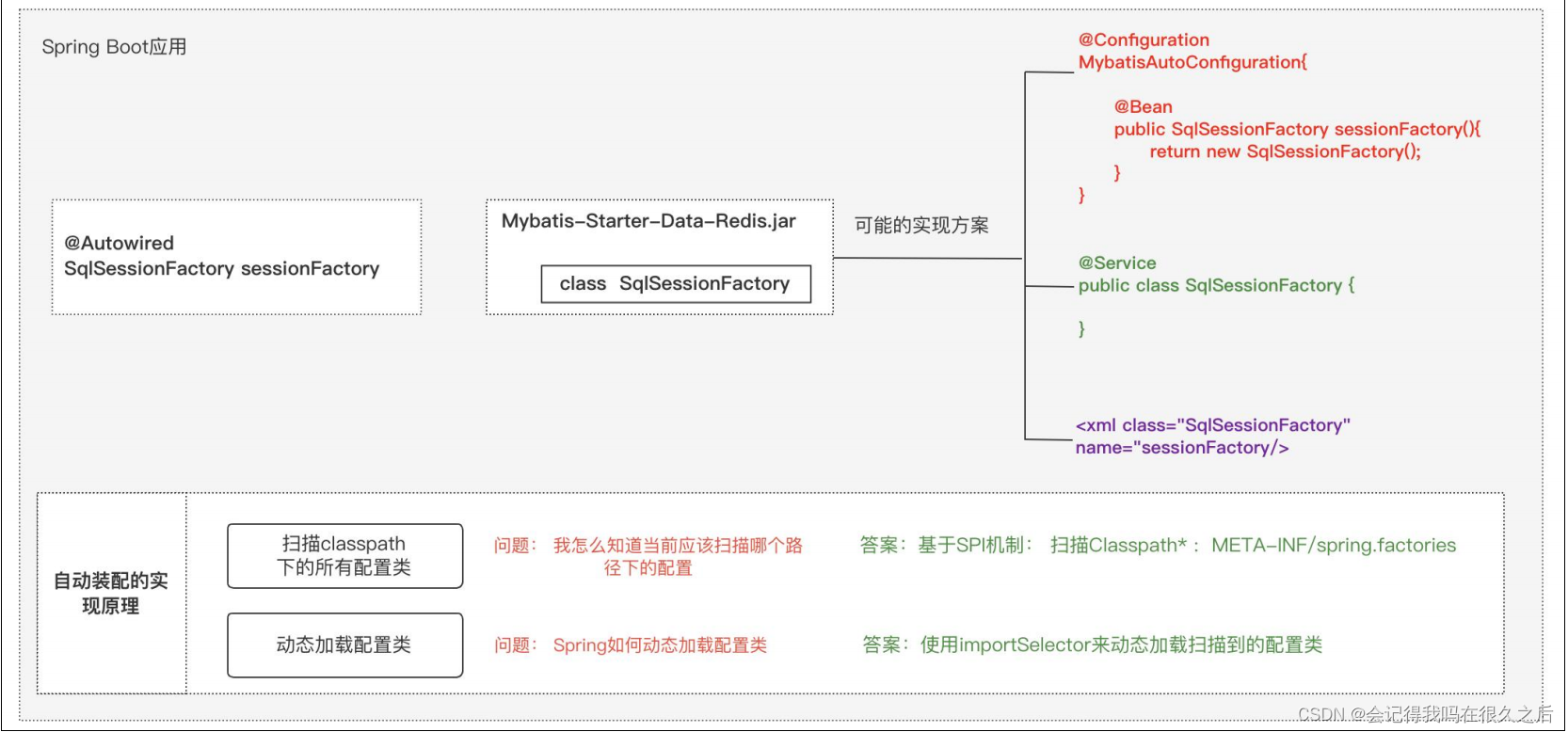
Spring Boot 中自动装配机制的原理
(摘自mic老师面试题) 最近一个粉丝说,他面试了 4 个公司,有三个公司问他:“Spring Boot 中自动装配 机制的原理” 他回答了,感觉没回答错误,但是怎么就没给 offer 呢? 对于这个问题…...
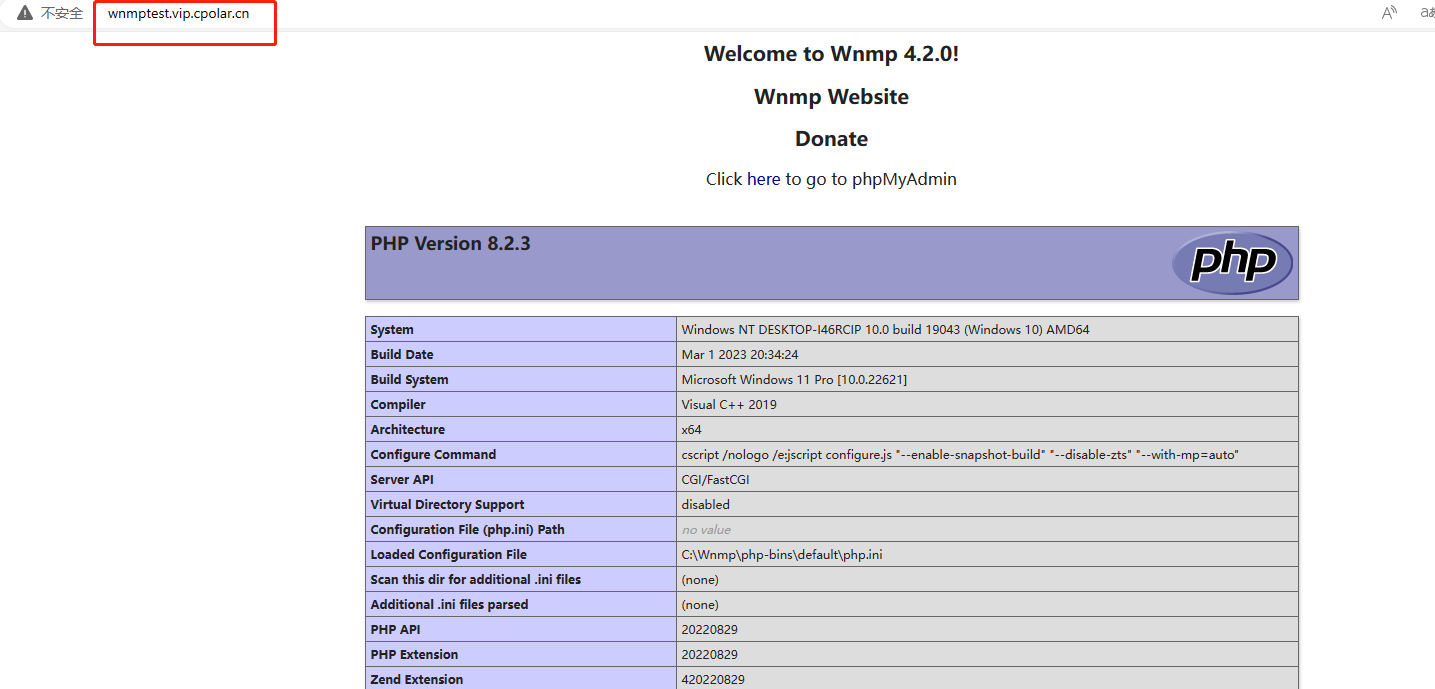
如何安装Wnmp并结合内网穿透实现外网访问内网Wnmp服务
文章目录 前言1.Wnmp下载安装2.Wnmp设置3.安装cpolar内网穿透3.1 注册账号3.2 下载cpolar客户端3.3 登录cpolar web ui管理界面3.4 创建公网地址 4.固定公网地址访问 前言 WNMP是Windows系统下的绿色NginxMysqlPHP环境集成套件包,安装完成后即可得到一个Nginx MyS…...

网工内推 | 上市公司,云平台运维,IP认证优先,13薪
01 上海新炬网络信息技术股份有限公司 招聘岗位:云平台运维工程师 职责描述: 1、负责云平台运维,包括例行巡检、版本发布、问题及故障处理、平台重保等,保障平台全年稳定运行; 2、参与制定运维标准规范与流程&#x…...

Linux安装DMETL4
Linux安装DMETL4 产品与环境介绍1 规划安装路径2 DM8安装路径2.1 达梦数据库程序安装路径2.2 初始化达梦数据库2.3 创建数据库用户名 DMETL 3 安装DMETL3.1 查看安装包与授权3.2 安装DMETL程序3.3 DMETL安装日志 4 启动DMETL5 DMETL连接数据库后会自动创建相关资源表6 达梦数据…...

Python中编码声明的方法
编码声明主要是为了解决编码问题。由于Python 3的默认编码是UTF-8,因此在使用Python 3编写源代码时,通常不需要在文件开头添加编码声明。但是,如果您使用的编码不是UTF-8,则需要在文件开头添加编码声明,以确保Python解…...
css设置浏览器表单自动填充时的背景
浏览器自动填充表单内容,会自动设置背景色。对于一般的用户,也许不会觉得有什么,但对于要求比较严格的用户,就会“指手画脚”。这里,我们通过css属性来设置浏览器填充背景的过渡时间,使用户看不到过渡后的背…...

终极Outfit字体完整指南:如何免费获得专业几何无衬线字体
终极Outfit字体完整指南:如何免费获得专业几何无衬线字体 【免费下载链接】Outfit-Fonts The most on-brand typeface 项目地址: https://gitcode.com/gh_mirrors/ou/Outfit-Fonts Outfit字体是一款专为品牌自动化设计的开源几何无衬线字体,提供从…...

机器学习自学者的高效知识管理策略
1. 机器学习自学者的知识管理策略作为一名从业多年的机器学习工程师,我深知这个领域知识更新速度之快令人窒息。每周都有新论文发表,每月都有新框架推出,而各类在线课程和教材更是层出不穷。面对如此海量的学习资源,很多初学者容易…...

机器学习不平衡分类问题:重采样技术详解与实践
1. 不平衡分类问题概述在机器学习实践中,我们经常会遇到类别分布严重不均衡的数据集。比如在信用卡欺诈检测中,正常交易可能占99.9%,而欺诈交易仅占0.1%。这种极端不平衡的数据分布会给模型训练带来显著挑战。传统分类算法在这种场景下往往表…...

概率思维训练:从认知偏差到实践应用
1. 概率直觉培养的核心价值概率思维是现代人必备的基础认知能力。从天气预报的降水概率到医疗检查的准确率,从投资决策的风险评估到人工智能算法的置信度,概率无处不在。但大多数人在面对概率问题时,第一反应往往是困惑甚至抗拒——这源于我们…...

深入PX4源码:手把手解析姿态控制PID参数如何从QGC地面站映射到飞控代码
深入PX4源码:从QGC参数到飞控代码的PID控制全链路解析 在无人机飞控开发领域,理解参数如何从配置界面传递到实际控制算法是进阶开发的必经之路。本文将以PX4中姿态控制的PID参数为例,完整追踪一个典型参数(如MC_ROLLRATE_P&#x…...

告别PDF/Word!用这个开源工具把飞书文档变成可编程的Markdown
飞书文档高效转换Markdown的终极方案 每次写完飞书文档后,你是否也经历过这样的痛苦?精心排版的文档导出成PDF后变成无法编辑的"死文件",或是转成Word后格式全乱需要重新调整。作为技术写作者,我们真正需要的是可编程、…...

如何让老旧Mac重获新生:OpenCore Legacy Patcher完全指南
如何让老旧Mac重获新生:OpenCore Legacy Patcher完全指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方抛弃的旧Mac&…...

别再傻傻分不清了!一文搞懂ROM、PROM、EPROM、EEPROM的区别与选型
嵌入式存储芯片选型指南:ROM家族技术解析与实战应用 在嵌入式系统设计中,数据存储方案的选择往往决定着产品的可靠性、成本和生产效率。面对琳琅满目的ROM、PROM、EPROM和EEPROM芯片,不少工程师在项目初期都会陷入选择困境——究竟哪种技术最…...

OpenDataLab MinerU应用案例:快速分析财务报表数据趋势
OpenDataLab MinerU应用案例:快速分析财务报表数据趋势 1. 引言:财务报表分析的痛点与解决方案 财务报表分析是企业经营决策的重要依据,但传统分析方法面临诸多挑战。以某上市公司年度报告为例,分析师通常需要: 手动…...

终极Fedora启动盘制作指南:Media Writer完全教程
终极Fedora启动盘制作指南:Media Writer完全教程 【免费下载链接】MediaWriter Fedora Media Writer - Write Fedora Images to Portable Media 项目地址: https://gitcode.com/gh_mirrors/me/MediaWriter Fedora Media Writer是制作Fedora启动盘的最佳工具&…...