5 Tensorflow图像识别(下)模型构建
上一篇:4 Tensorflow图像识别模型——数据预处理-CSDN博客
1、数据集标签
上一篇介绍了图像识别的数据预处理,下面是完整的代码:
import os
import tensorflow as tf# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 模型参数设置
BATCH_SIZE = 100# 图片尺寸统一为150*150
IMG_SHAPE = 150# 处理图像尺寸
img_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255, horizontal_flip=True, )train_data_gen = img_generator.flow_from_directory(directory=train_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')
val_data_gen = img_generator.flow_from_directory(directory=validation_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')上一篇提到系统的输入是“特征-标签”对,特征是输入的图片,标签就是标记该图片是猫还是狗。上面的代码如何知道输入的照片是猫还是狗?
这里用到了keras的一个函数flow_from_directory(),从目录中生成数据流,子目录会自动帮你生成标签。先看看train训练集的这两个子目录生成的标签是什么:
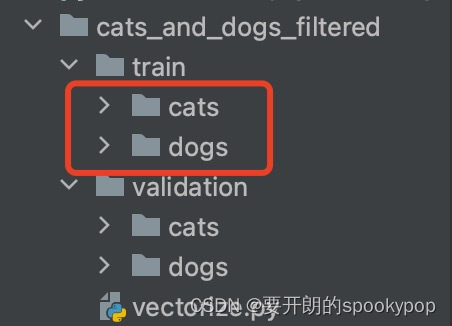
使用下面代码查看
print(train_data_gen.class_indices)运行结果:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
{'cats': 0, 'dogs': 1}
从运行结果可以看到,猫的照片系统自动打上了0的标签,狗的标签是1。
2、Relu激活函数
构建模型的完整代码如下:
import os
import tensorflow as tf
import numpy as np# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 模型参数设置
BATCH_SIZE = 100# 图片尺寸统一为150*150
IMG_SHAPE = 150# 处理图像尺寸
img_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255, horizontal_flip=True, )# 训练数据
train_data_gen = img_generator.flow_from_directory(directory=train_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')# 验证数据
val_data_gen = img_generator.flow_from_directory(directory=validation_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')model = tf.keras.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(100, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(2)])model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])EPOCHS = 20
history = model.fit_generator(train_data_gen,steps_per_epoch=int(np.ceil(2000 / float(BATCH_SIZE))),epochs=EPOCHS,validation_data=val_data_gen,validation_steps=int(np.ceil(1000 / float(BATCH_SIZE)))
)model中加入了和之前不一样的代码:
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),
这里使用了卷积神经,主要是为了突出区分不同对象的特征。一张图片的信息很多的,但往往我们只需要一些特征进行训练就可以了,后续会详细介绍。
现在先介绍 activation='relu',激活函数Relu。
ReLU,全称是线性整流函数(Rectified Linear Unit),是人工神经网络中常用的激活函数。它的图像如下:

当x<=0时,f(x)=0;
当x>0时,f(x)=x;
可以运行代码看看:
例1:
import tensorflow as tfx = -19
print(tf.nn.relu(x))运行结果:
tf.Tensor(0, shape=(), dtype=int32)
输入-19,使用relu激活函数后的结果为0
例2:
import tensorflow as tfx = 8
print(tf.nn.relu(x))运行结果:
tf.Tensor(8, shape=(), dtype=int32)
3、损失函数
代码:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
其中损失函数为SparseCategoricalCrossentropy,它是用于计算多分类问题的交叉熵,如果是两个或两个以上的分类问题可以始终这样设置。对其原理及计算过程的读者可以自行百度,此处不详细介绍。
4、训练过程详解
(1)训练准确率
运行上面的完整代码:
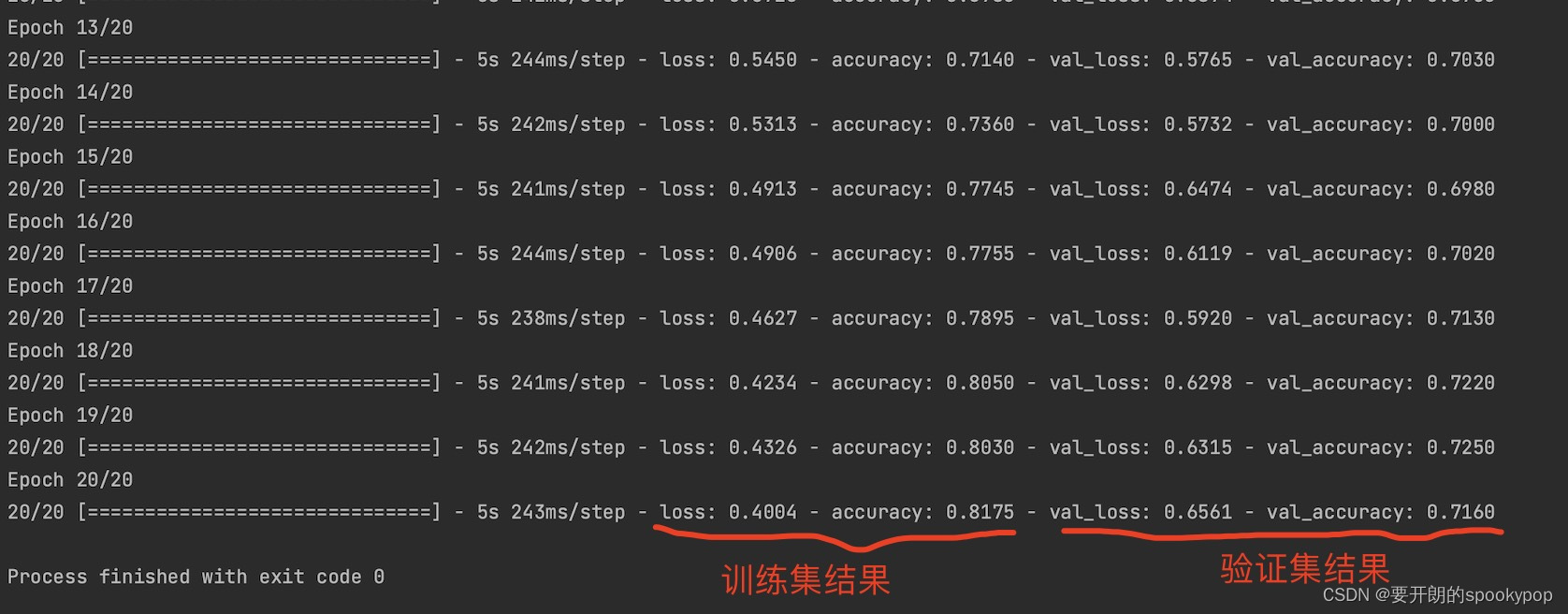
可以看到训练集和验证集的loss值在慢慢下降,准确率在提升。
划线部分是最后一个epoch的训练结果:
accuracy:0.8175,也就是说你的神经网络在分类训练数据方面的准确率约为82%;
val_accuracy:0.7160,在验证集的准确率约为72%
(2)batch_size批次大小
代码中batche_size设置的大小为100,意思是每批次生成的样本数量为100。
例如上述代码的train训练集一共有2000张图片,一个周期(epoch)分20个批次(2000/100=20)样本数据进行训练,每个批次训练完后利用优化器更新模型参数。
所以一个周期(epoch)的模型参数更新次数就是20:2000/batch_size=20
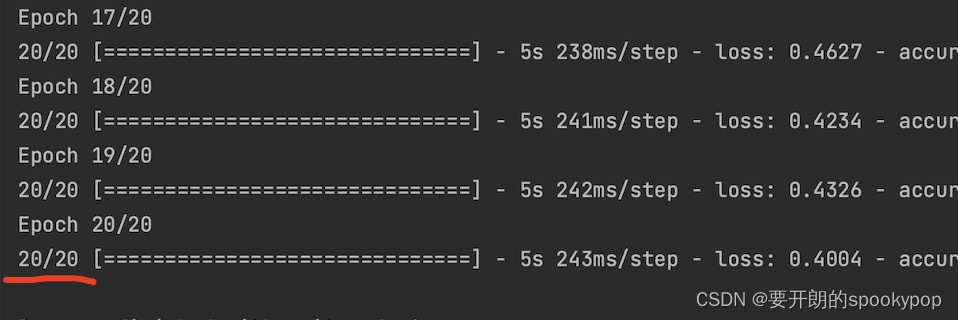
截图中红色部分,就是一个epoch分了20个批次用来更新模型参数。
训练结果会因为模型的参数的设置、训练集图片的数量等等原因结果大不相同,学习的时候可以自己动手去调整模型参数来看看训练结果。
相关文章:
5 Tensorflow图像识别(下)模型构建
上一篇:4 Tensorflow图像识别模型——数据预处理-CSDN博客 1、数据集标签 上一篇介绍了图像识别的数据预处理,下面是完整的代码: import os import tensorflow as tf# 获取训练集和验证集目录 train_dir os.path.join(cats_and_dogs_filter…...
OpenCV 图像复制和图像区域读写
图像复制 共享数据, 使用 new Mat(srcMat, ...) 和 newMatsrcMat 生成新的Mat都和原Mat共享数据, 也就是说如果修改某一Mat,其他Mat也会随之改变复制全新的Mat, 使用CopyTo() 和 Clone() 方法将生成一个全新的Mat, 新Mat和原Mat不共享数据. 图像区域和点的读写 区域读取: 通过s…...
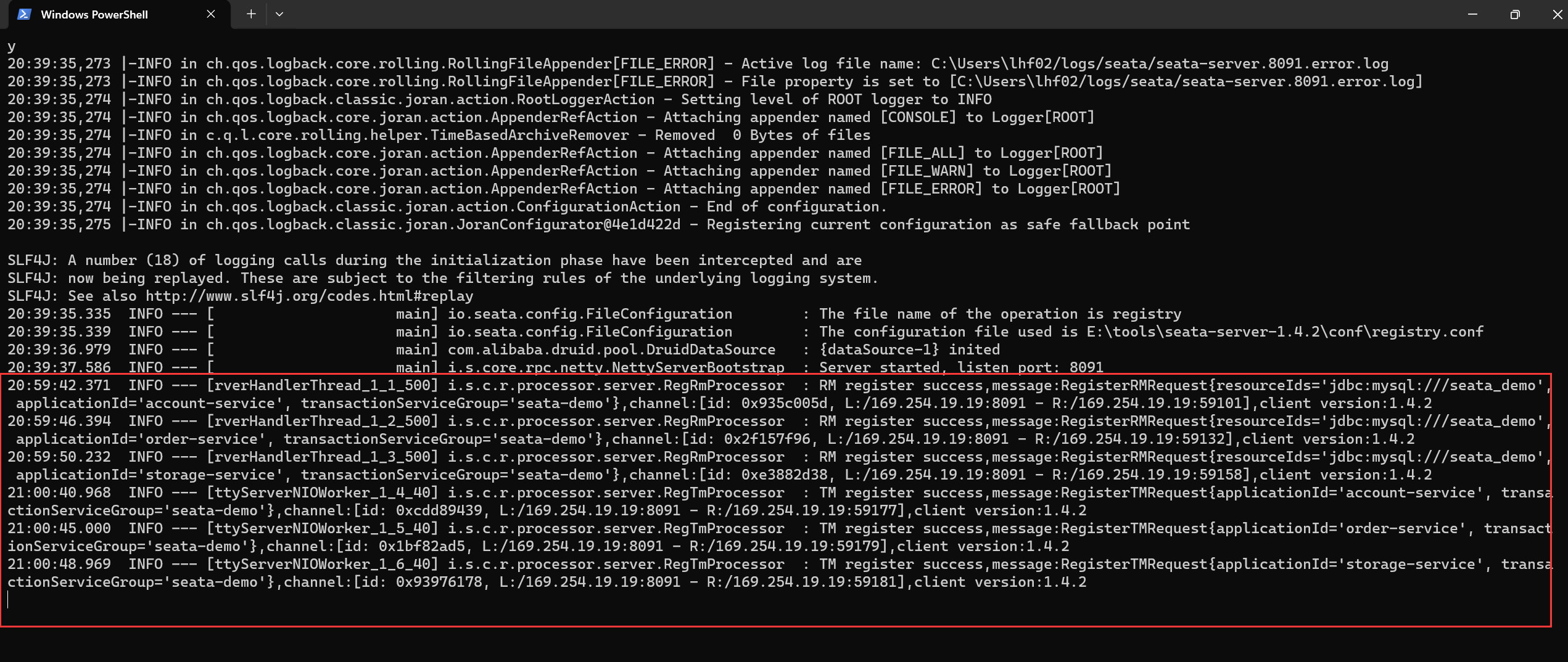
【分布式事务】初步探索分布式事务的概率和理论,初识分布式事的解决方案 Seata,TC 服务的部署以及微服务集成 Seata
文章目录 一、分布式服务案例1.1 分布式服务 demo1.2 演示分布式事务问题 二、分布式事务的概念和理论2.1 什么是分布式事务2.2 CAP 定理2.3 BASE 理论2.4 分布式事务模型 三、分布式事务解决方案 —— Seata3.1 什么是 Seata3.2 Seata 的架构3.3 Seata 的四种分布式事务解决方…...
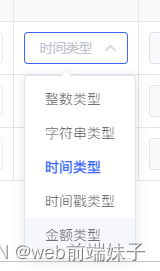
es6过滤对象里面指定的不要的值filter过滤
//过滤出需要的值this.dataItemTypeSelectOption response.data.filter(ele > ele.dictValue tree||ele.dictValue float4);//过滤不需要的值this.dataItemTypeSelectOption response.data.filter((item) > {return item.dictValue ! "float4"&&it…...

Docker从入门到上天系列第二篇:传统虚拟机和容器的对比以及Docker的作用以及所解决的问题
大神推荐:作者有幸结识技术大神孙哥为好友获益匪浅,现在把孙哥作为朋友分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员。 本专栏简介:话不多说,让我们一起干翻Docker 本文章简介:话不多说,让我们讲清楚首先讲清楚Docker是什么 文章…...

共话医疗数据安全,美创科技@2023南湖HIT论坛,11月11日见
11月11日浙江嘉兴 2023南湖HIT论坛 如约而来 深入数据驱动运营管理、运营数据中心建设、数据治理和数据安全、数据资产“入表”等热点、前沿话题 医疗数据安全、数字化转型深耕者—— 美创科技再次深入参与 全新发布:医疗数据安全白皮书 深度探讨:数字…...

乐园要吸引儿童还是家长?万达宝贝王2000万会员的求精之路
2023年6月,万达宝贝王正式迈入“400店时代”。 万达宝贝王在全国200多座城市,以游乐设施、主题活动、成长课程服务10亿多用户,拥有2000多万名会员,是真正的国内儿童乐园领跑者。 当流量时代变成“留量”时代,用户增长…...

ps人像怎么做渐隐的效果?
photoshop怎么制作人像渐隐的图片效果?渐隐效果需要使用渐变来实现,下面我们就来看看详细的教程。 首先,我们打开Photoshop,点击屏幕框选的【打开】,打开一张背景图片。 下面,我们点击左上角【文件】——【…...

为什么IN操作符一般比OR操作符清单执行更快
IN操作符一般比OR操作符清单执行更快的主要原因有以下几点: 查询优化:数据库管理系统通常会针对IN操作符进行更好的查询优化。它可以使用哈希表或二叉搜索树等数据结构来更快地查找匹配的值,从而减少了搜索时间。而OR操作符需要逐个比较每个条…...
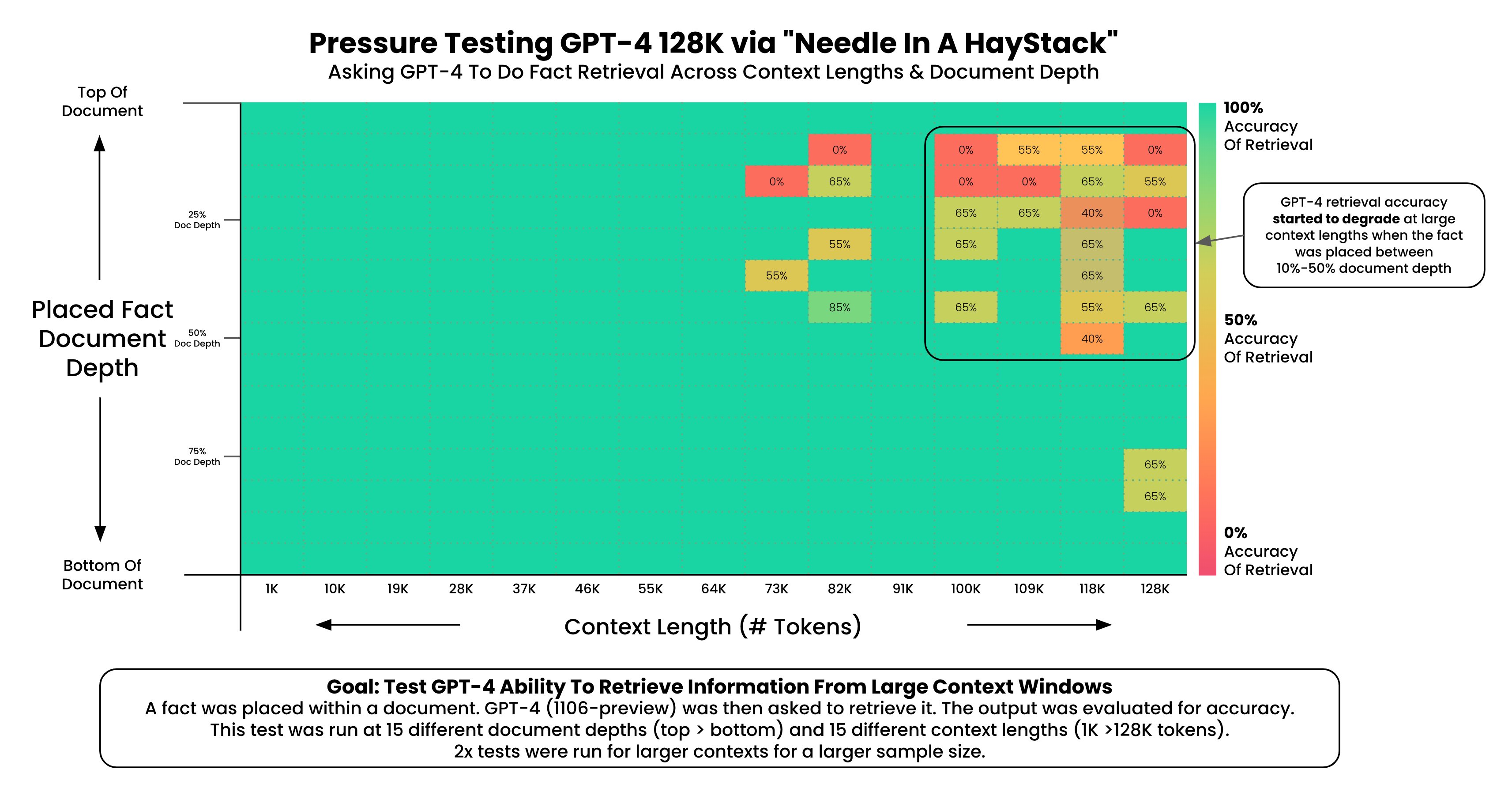
GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!
本文原文来自DataLearnerAI官方网站:GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699526438975 GPT-4 Turbo是OpenAI最新发布的号称…...
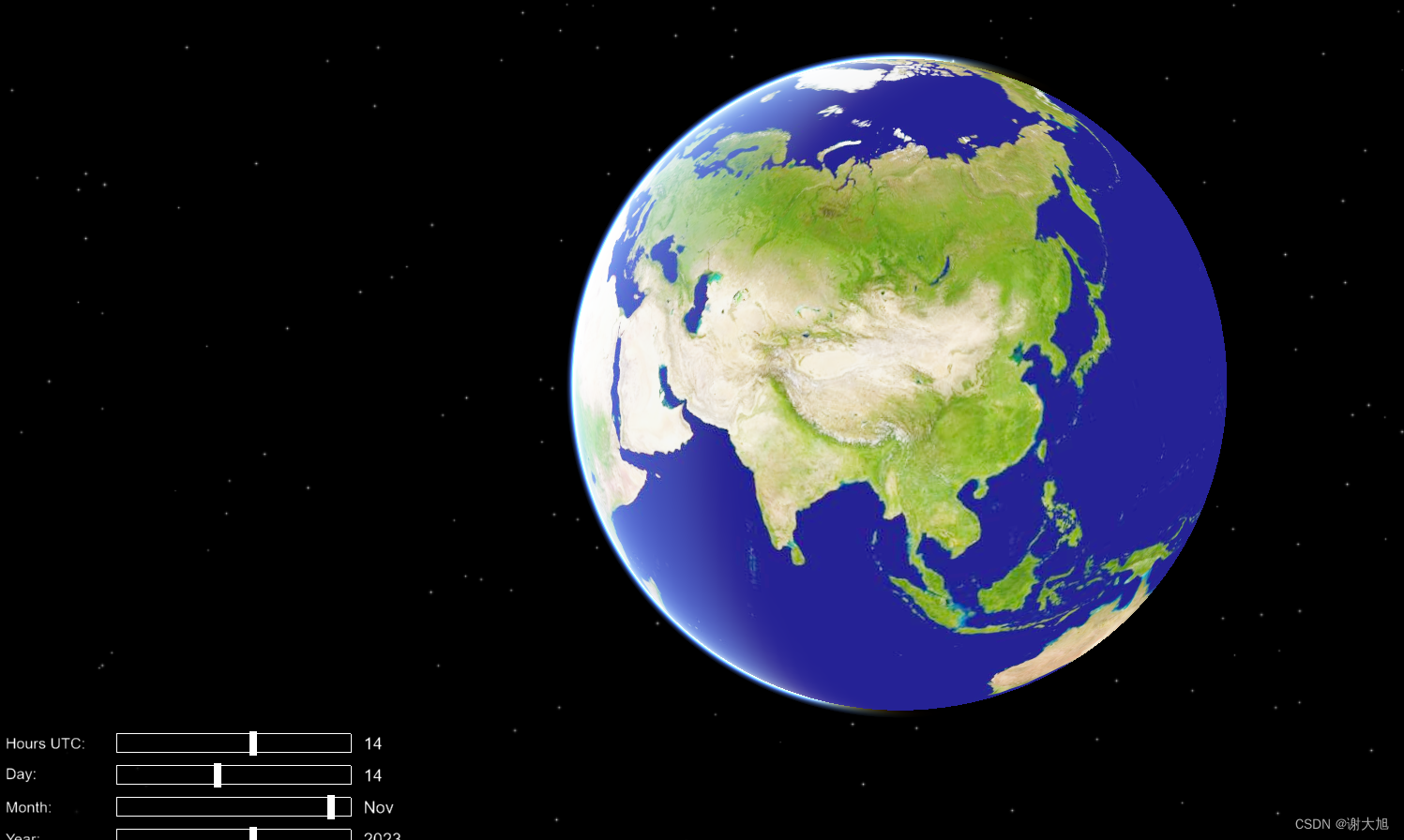
osg之黑夜背景地月系显示
目录 效果 代码 效果 代码 /** * Lights test. This application is for testing the LightSource support in osgEarth. * 灯光测试。此应用程序用于测试osgEarth中的光源支持。 */ #include "stdafx.h" #include <osgViewer/Viewer> #include <osgEarth/N…...

持续交付-Jenkinsfile 语法
实现 Pipeline 功能的脚本语言叫做 Jenkinsfile,由 Groovy 语言实现。Jenkinsfile 一般是放在项目根目录,随项目一起受源代码管理软件控制,无需像创建"自由风格"项目一样,每次可能需要拷贝很多设置到新项目,…...
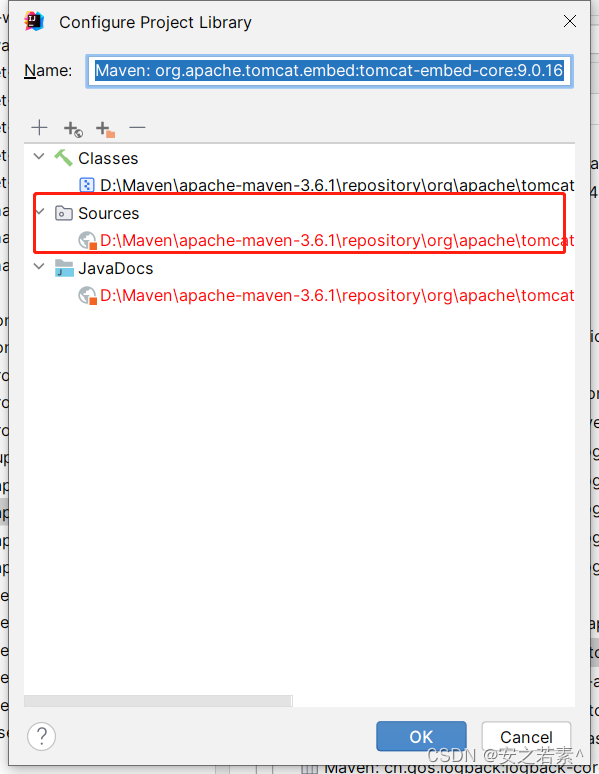
IDEA重新choose source
大概现状是这样:之前有个工程,依赖了别的模块基础包,但当时并没有依赖包的源码工程,因此,通过鼠标左键点进去,看到的是jar包里的class文件,注释什么的都去掉了的,不好看。后面有这个…...
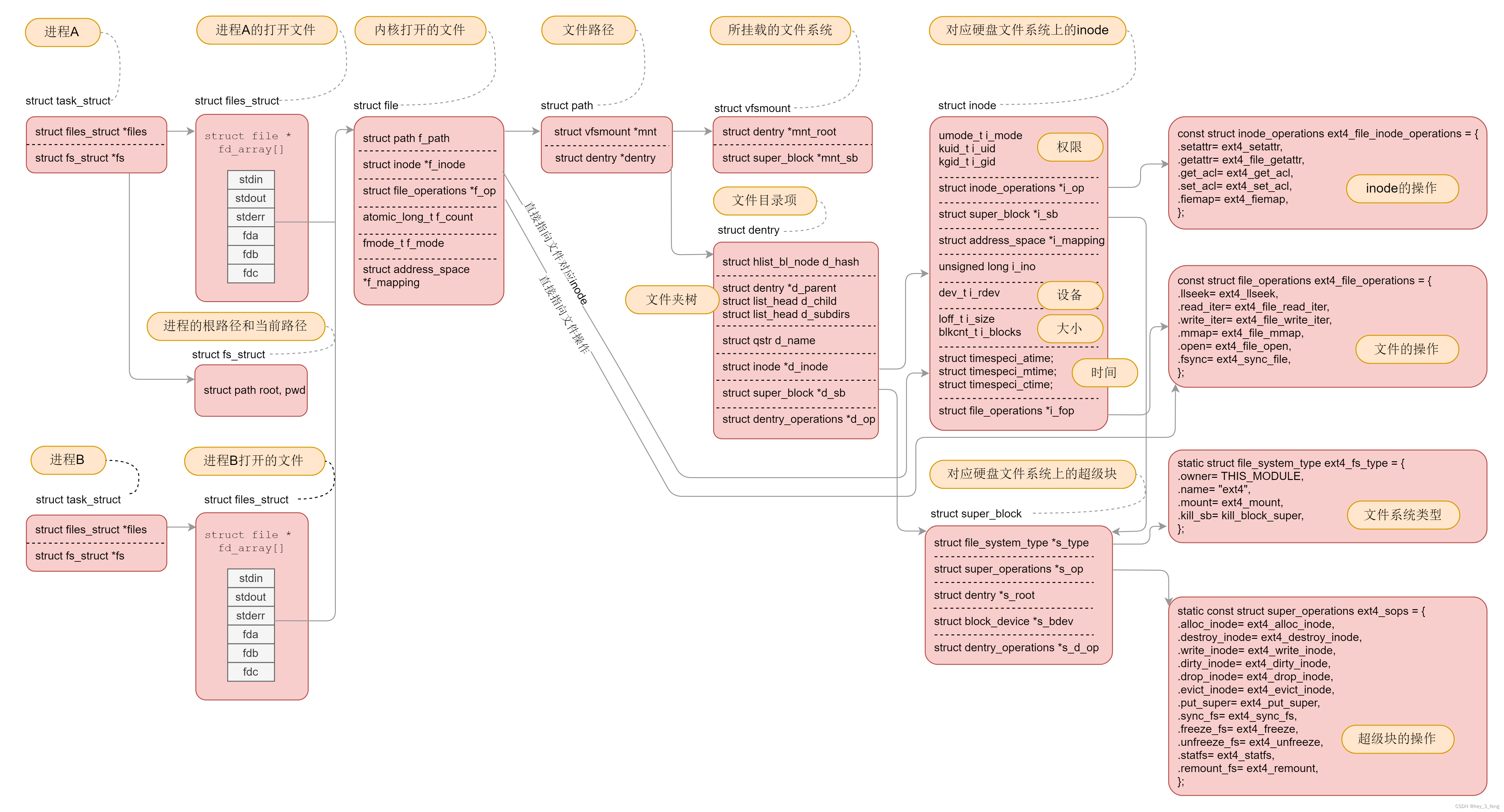
解析虚拟文件系统的调用
Linux 可以支持多达数十种不同的文件系统。它们的实现各不相同,因此 Linux 内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。它提供了常见的文件系统对象模型,例如 inode、directory entry、mount 等,以及…...
佳能相机拍出来的dat文件怎么修复为正常视频
3-3 佳能相机是普通人用得最多的相机之一,也有一些专业机会用于比较重要的场景,比如婚庆、会议录像、家庭录像使用等。 但作为电子产品,经常会出现一些奇怪的故障,最严重的应该就是拍出来的东西打不开了。 本文案例是佳能相机拍…...
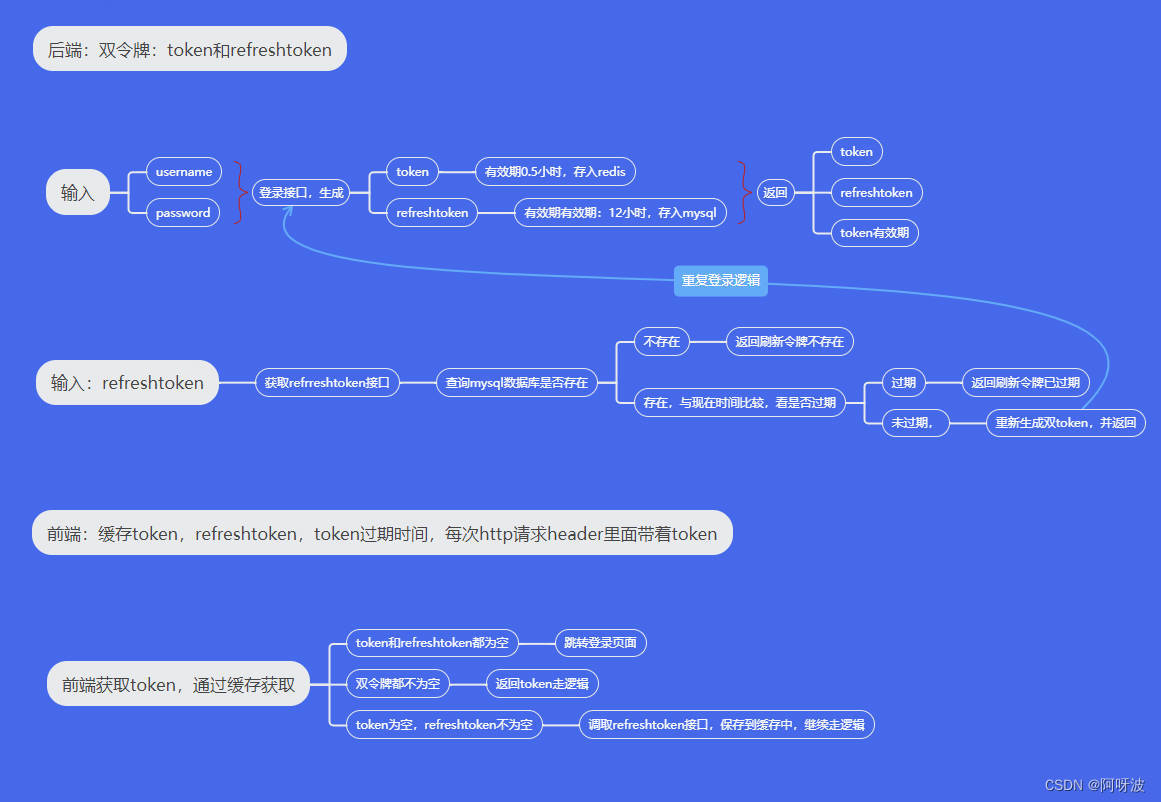
OAuth2.0双令牌
OAuth 2.0是一种基于令牌的身份验证和授权协议,它允许用户授权第三方应用程序访问他们的资源,而不必共享他们的凭据。 在OAuth 2.0中,通常会使用两种类型的令牌:访问令牌和刷新令牌。访问令牌是用于访问资源的令牌,可…...
Django(二、静态文件的配置、链接数据库MySQL)
文章目录 一、静态文件及相关配置1.以登录功能为例2.静态文件3.资源访问4.静态文件资源访问如何解决? 二、静态文件相关配置1. 如何配置静态文件配置?2.接口前缀3. 接口前缀动态匹配4. form表单请求方法补充form表单要注意的点 三、request对象方法reque…...
Linux 本地Yearning SQL审核平台远程访问
文章目录 前言1. Linux 部署Yearning2. 本地访问Yearning3. Linux 安装cpolar4. 配置Yearning公网访问地址5. 公网远程访问Yearning管理界面6. 固定Yearning公网地址 前言 Yearning 简单, 高效的MYSQL 审计平台 一款MYSQL SQL语句/查询审计工具,为DBA与开发人员使用…...

Leetcode—226.翻转二叉树【简单】
2023每日刷题(二十四) Leetcode—226.翻转二叉树 实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* …...
【阿里云】任务2-OSS对象存储教程(找我参加活动可获得京东卡奖励)
目录 前言说明第一步第二步第三步:开通并使用OSS传输加速三、清理第四步-提交作品第五步-提交记录到小程序 前言 本次任务是阿里云官方发出的,每个任务30软妹币,欢迎大家加入我的活动群,门槛很低,所有人都可以参加&…...

推荐 win11 可用的 SVN 版本:64位,下载最新的 TortoiseSVN 1.14.x 版本
【Win11兼容SVN工具推荐】推荐使用64位TortoiseSVN 1.14.x最新版本,完美适配Win11系统。该工具直接集成到资源管理器,提供右键快捷操作,完全免费且支持中文界面。安装时需注意:选择对应系统位数的安装包(推荐64位&…...

【路径规划】基于融合改进A星-麻雀搜索算法求解六边形栅格地图路径规划
✅作者简介:热爱数据处理、数学建模、仿真设计、论文复现、算法创新的Matlab仿真开发者。🍎更多Matlab代码及仿真咨询内容点击主页 🔗:Matlab科研工作室🍊个人信条:格物致知,期刊达人。&#…...

GoFr框架:加速微服务开发的Go语言利器
目录 一、核心特性:简化微服务开发的五大支柱 1.1 零配置启动与约定优于配置 1.2 全栈可观测性:日志、追踪、指标一体化 1.3 多数据源支持与弹性扩展 二、技术架构:分层设计与模块化组件 三、未来展望:持续演进的云原生生态…...

DeepSeek与Kimi多次「偶遇」,开源大模型改写中国AI产业格局!
【全球大模型更新,中国热闹非凡】 这两天,全球顶级大模型接连更新,重磅消息不断。中国也迎来热闹的一周,从周一开始,Qwen、Kimi、小米、腾讯相继发布最新模型。周五,千呼万唤的DeepSeek终于发布V4双版本&am…...

ml-intern透明度报告:AI决策过程的可解释性
ml-intern透明度报告:AI决策过程的可解释性 【免费下载链接】ml-intern 🤗 ml-intern: an open-source ML engineer that reads papers, trains models, and ships ML models 项目地址: https://gitcode.com/GitHub_Trending/ml/ml-intern 在人工…...

VS Code Dev Containers启动慢如蜗牛?5个被90%开发者忽略的内核级优化技巧,立即生效
更多请点击: https://intelliparadigm.com 第一章:Dev Containers启动性能瓶颈的底层归因分析 Dev Containers 的启动延迟并非单一因素所致,而是由容器生命周期各阶段的协同阻塞共同导致。核心瓶颈集中于镜像拉取、文件系统挂载、初始化脚本…...

HPH构造详解 内部结构拆解
HPH作为一种精密组件,其内部构造对于性能表现和使用寿命起着直接决定作用。深入理解HPH的构造,不但能够助力用户进行正确选型,而且还能为后期的维护以及故障排查提供关键依据。 下面我将从核心零部件开始,一直到整体布局ÿ…...

AI Agent如何通过声波协议实现高效通信:GibberLink项目深度解析
1. 项目概述:当AI开始用“声音”说悄悄话 去年二月,一个关于两个AI智能体在对话中“切换语言”的演示视频在技术圈里小火了一把。视频里,两个扮演“客户”和“酒店前台”的AI对话机器人,在聊了几句确认对方也是AI后,突…...

relation-graph入门指南:5分钟学会创建你的第一个关系图谱
relation-graph入门指南:5分钟学会创建你的第一个关系图谱 【免费下载链接】relation-graph relation-graph is a relationship graph display component that supports Vue2, Vue3, React. Allowing you to fully customize the graphical elements using HTML/CSS…...

如何将pmu-tools与Prometheus、Grafana集成:完整监控实战指南
如何将pmu-tools与Prometheus、Grafana集成:完整监控实战指南 【免费下载链接】pmu-tools Intel PMU profiling tools 项目地址: https://gitcode.com/gh_mirrors/pm/pmu-tools pmu-tools是Intel开发的性能监控工具集,能够深入分析CPU性能指标。本…...