18. 深度学习 - 从零理解神经网络
文章目录
- 本文目标
- 预测趋势与关系
- 波士顿房价预测

Hi, 你好。我是茶桁。
我们终于又开启新的篇章了,从今天这节课开始,我们会花几节课来理解一下深度学习的相关知识,了解神经网络,多层神经网络相关知识。并且,我们会尝试着来打造一个自己的深度学习框架。
以前很多时候都会被人问到很多问题,其中比较多的就包括现在各种各样的框架应该用到哪一个,在学习人工智能的时候,对于深度学习框架有比较多的问题。那在这里我就希望能帮助各位小伙伴彻底的去理解一下什么是学习框架。
对于我们来说,就像小孩子去学一个东西,最好的就是从头到尾能把它拆了,然后再重建起来。
从今天开始往后的几节课里,我们都会去好好了解「如何从零构建一个深度学习框架」。
本文目标
我们基本的核心目的就是来讲明白,什么是神经网络,以及神经网络的原理是什么。
我们要知道,人工智能有很多方法,但是神经网络是现代人工智能里面一个非常核心的内容。
咱们现在就是要先去了解神经网络的原理是怎么回事,然后在这个过程中我们来讲解清楚神经网络的框架到底是什么样的。
如我们之前学习过的几节机器学习课程,会发现它有很多的概念。
比方说非监督学习、监督学习、强化学习,监督学习里面又分了回归和分类等等。
很多人看到这些,在初次接触、初次学习的时候就觉得人工智能很复杂,很难学会。除此之外,我们在学到人工智能目前比较核心的一个内容是关于深度学习神经网络。好多人不知道深度学习神经网络到底是什么原理。
在整个学习过程会发现有很多很多的问题,概念很多,变体也很多,学习很困难。
那这里要跟大家强调一点,就是千万别成为「马保国」,为什么这里会提到这个人呢?在我看来,这其实是一类人,他是一类人的代表。就是整很多的概念,假装子集很厉害。
就是我们脑子里不要总是去提很多概念,或者说很多很花哨的东西,最重要的还是基本功修炼好。我一直都强调一个观念,就是基础学科,基本功才是所有学科的基石。过多的概念其实并没有什么卵用。
早些时候,我上班的地方有一个叫「李雨晨」(匿名🙄)的产品经理,各种概念信手拈来,都是一些高大上的东西。也是将面试官唬的一愣一愣的。当时大家也是没多想,心想人家既然是个牛逼人物,那就多配合人家呗,结果是没过3个月就原形毕露,当然是下面干事的人最先觉察出来的。
没办法,为了继续装下去只能是利用自己的职权和谎言去盗用别人的成果,比如设计稿啊,文档啊啥的,拿着当自己的东西向上汇报。
再然后,基本人人都开始防着他了,就开始恼羞成怒,一直打压那个最开始说他不行并防着他的产品。不过不行就是不行,其实最开始就能看出端倪,因为基本没有一家公司干活超过6个月,那肯定是有问题的。就这资质也能忽悠成高级产品经理,也能看出来那会儿产品这个行业的水份多大,门槛多低。不过终归潮水退了之后,裸泳的王八都要现行是吧。
好,说这么多吐槽的话其实也是想说一个道理,不要去搞花里胡哨的玩意,踏踏实实的把基本功练扎实,否则一时唬的了人,但是终归是走不远。
那这也是咱们这节课的目的,让大家去除掉背后这些繁杂的表象,那么它背后到底是什么,这就是咱们这三天的目的。
这些年,人工智能已经应用到我们各个地方了。先不说现在大火的AIGC,人工智能还应用到其他各个地方。
比方说在商场购物的时候,它的楼宇灯光,自动停车都是在做这些事情。买票的时候,机场,火车站都有人脸识别。每天给你推荐的各种商品,以及我们做物流配送等等这些东西,背后都有人工智能。
而这些人工智能背后有一个很重要的东西,就是用到了神经网络框架。
比方说众所周知的TensorFlow, 我们每次调用的时候,框架背后调用了很多东西。
# Store layers weight & bias
# A random value generator to initialize weights.
random_normal = tf.initializers.RandomNormal()weights = {'h1': tf.Variable(random_normal([num_features, n_hidden_1])),'h2': tf.Variable(random_normal([n_hidden_1, n_hidden_2])),'out': tf.Variable(random_normal([n_hidden_2, num_classes]))
}biases = {'b1': tf.Variable(tf.zeros([n_hidden_1])),'b2': tf.Variable(tf.zeros([n_hidden_2])),'out': tf.Variable(tf.zeros([num_classes]))
}
...# Create model.
def neural_net(x):# Hidden fully connected layer with 128 neurons.layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])# Apply sigmoid to layer_1 output for non_linerity.layer_1 = tf.nn.sigmoid(layer_1)# Hidden fully connected layer with 256 neurons.layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])# Apply sigmoid to layer_1 output for non_linerity.layer_2 = tf.nn.sigmoid(layer_2)# Output fully connected layer with a neuron for each class.out_layer = tf.matmul(layer_2, weights['out']) + biases['out']# Apply softmax to normalize the logits to a probability distributionreturn tf.nn.softmax(out_layer)
我们现在想把这些框架搞清楚,就需要知道它背后这些东西到底是什么原理、什么原因。
那这几节课之后,就希望我们能从0到1学会创建一个深度学习框架,从底层来理解这个神经网络的原理,理解现代人工智能的核心。
一开始的课程,内容也会稍微比较简单一些,越往后咱们就越难一点。最后,彻底理解深度学习神经网络原理。
预测趋势与关系
我们以一个趋势预测的问题为引入。
如果对于自然哲学或者说科学研究这些,就是对科学研究方法论感兴趣的话,你会知道我们整个科学研究其实分为三个层面。
不管是牛顿、爱因斯坦,还是伽利略、图灵等等,所有的科学研究,所有的research,不管是关于数据还是别的,它都是三个层面。
第一个层面叫做描述性的,第二个叫做因果推理,第三个叫做未来的预测。
就说我们所有的科学活动,所有的研究活动都可以归为这三类。
描述性的东西,比方说你又长胖了多少,然后又增加了多少重量。今天的体重,明天的体重等等。
除此之外第二个层面是我们要看出来它们之间的相关性。比方吃的多和你长胖,它们之间是呈正相关的。还有其他的一些关系,比方说是呈负相关的等等。
那我们最重要也是最难的一个科学活动是要对它进行未来的预测,对于未来的预测。这个未来它不仅是predict。
比方说现在你知道的是几组数据,知道每个对应的结果。然后你看到了一组没有见过的数据,你去预测它。
就好比一个孩子做题,他见过的题都能做,没见过的题他也要会做。这个其实就是属于对未来的一种预测能力。
关于预测,我们最关心的预测是关于我们的身体健康,能活多久;还有就是关于挣钱的问题。
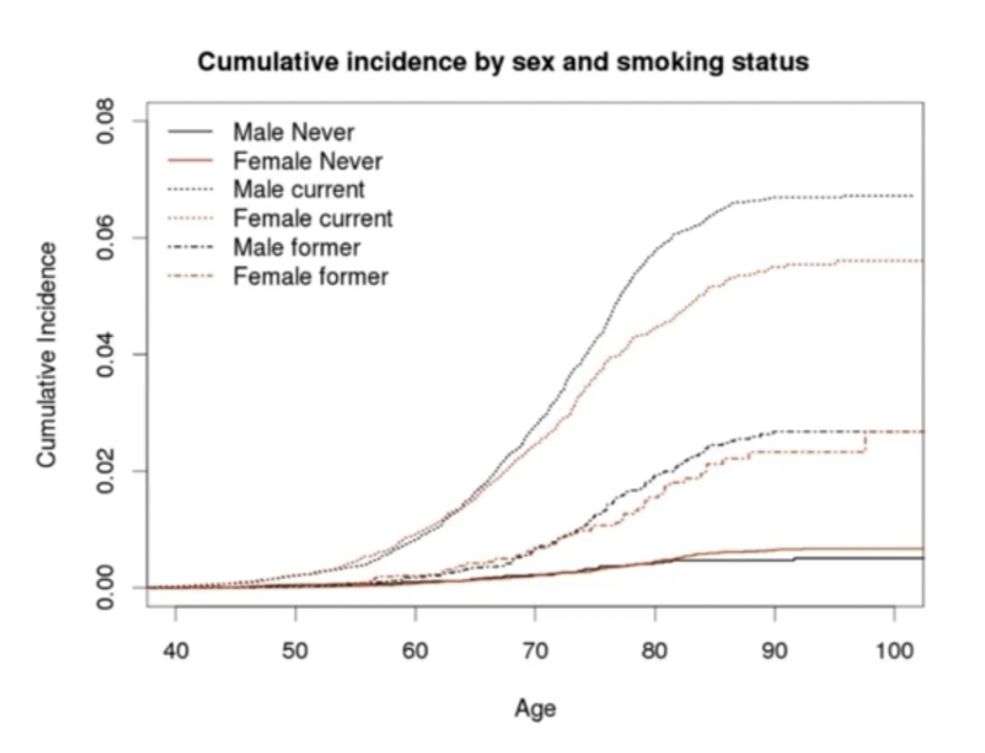
我们看一下这个例子,你的性别和你的吸烟的频率,跟一种疾病(可能是肺癌),它会有一个相对应的概率。
性别不同,年龄不同,抽烟频率不同。我们会发现,得病概率随着年龄的增大并不会有多少增加,此时男性得病概率反而比女性还小。
但是随着抽烟频率越多,得病概率上升的非常快。其中呢,同样的年龄和抽烟频率下,男性得病的概率则会更高。
假设存在一个人p,男性,年龄是72岁,他每天抽三根:P{age:72, sex: male, rate: 3/day}。那他得这种病的概率大约是多少?那我们就先在图上随意画一个,假如说就如图的位置一样的概率:
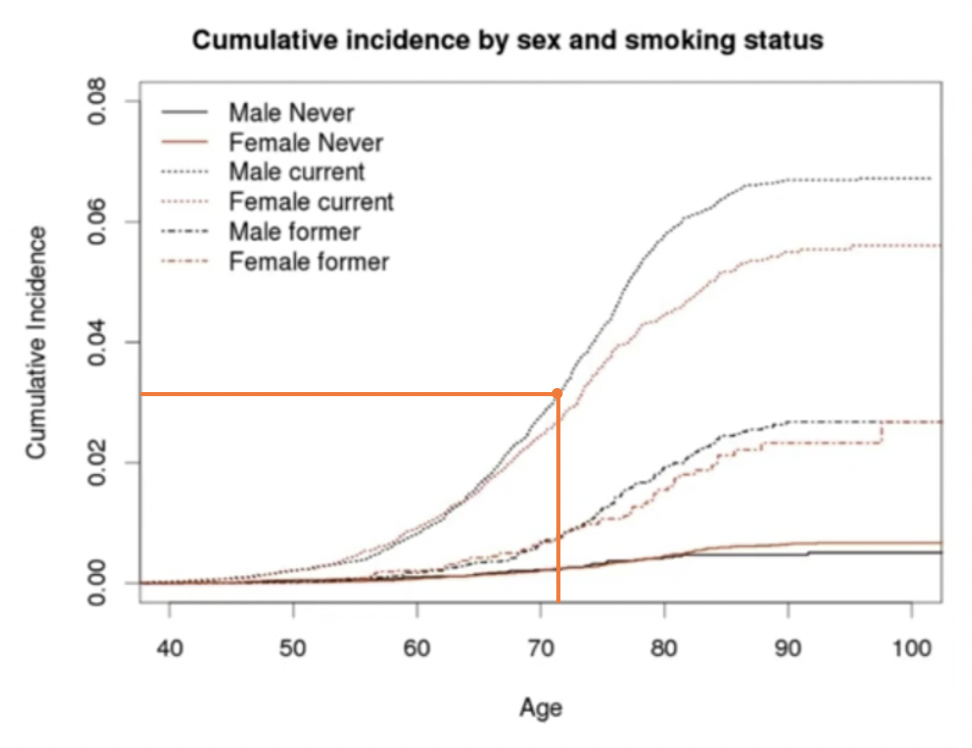
那么这个概率到底是多少?我们就需要用到数据去做预测,此时我们就得去做个拟合。
除此之外,我们再来看BMI,也就是身体指数。身体指数就是体重除以身高的平方:BMI = kg/h^2,越大就表示你越胖。
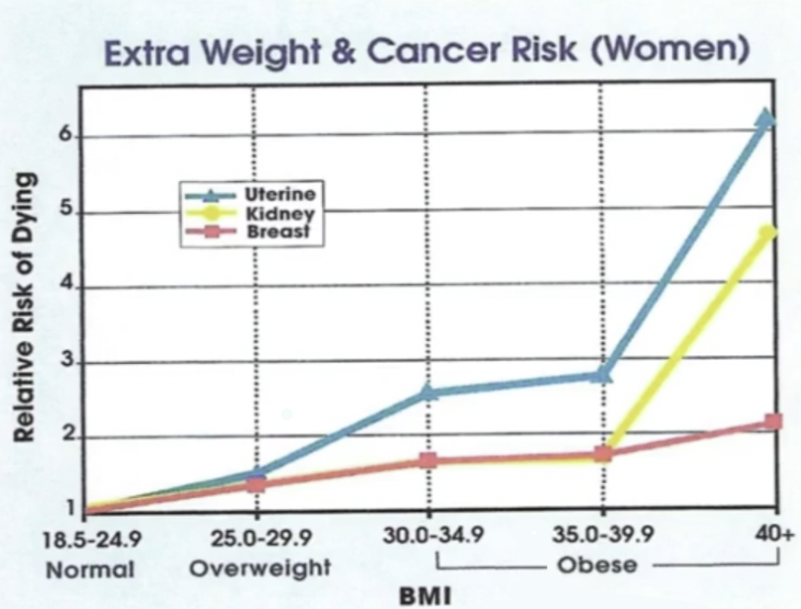
当你到某一个值的时候,可以看到得病的概率。
我们假设有一个人180斤,身高一米73,我们来预测他得肾病的概率是多少。这个时候我们还是需要去做预测。
波士顿房价预测
现在就来看一个非常经典的预测案例:波士顿房价案例。这个波士顿房价的数据,我们曾经在机器学习的线性回归里有用到,不知道小伙伴们有没有去看过。
波士顿地区是在美国东北部,房地产的价钱也比较稳定,那这个数据也是比较老的数据了,通过这些数据来考察,希望机器能够根据输入的内容来预测它的房价。
现在就以波士顿房价问题为例,来讲讲计算机怎么去预测。然后在预测的过程中我们来讲解实现深度学习的原理。最终把它封装成我们所需要的一个深度学习框架。
第一步自然是加载和分析数据。
之前的课程我提到过,这个数据由于一些原因,sklearn的datasets中已经删除了,那我们要想加载数据,就需要用到其中的fetch_openml:
from sklearn.datasets import fetch_openmldataset = fetch_openml(name='boston', version=1, as_frame=True, return_X_y=False, parser='pandas')
在我们第一次获取到这个数据不知道怎么处理的时候,我们可以使用dir来看看这个数据里面的内容:
dir(dataset)---
['DESCR', 'categories', 'data', 'details', 'feature_names', 'frame', 'target', 'target_names', 'url']
我们看到这个dataset里有一个feature_names,直觉上这个应该是一些特征名称,我们来查看一下这个的内容:
dataset['feature_names']---
['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
这里要说明一下,因为我是用的Jupyter,所以我可以这样直接打印出变量的具体内容,如果小伙伴们不是在Jupyter里,而是在Python文件中去编写代码,不要忘了使用print函数。
在拿到数据之后,我们先来定义一下问题。 就是假设你现在要买一个房子,那么你就要根据他的这个房子的相关数据,来判断这个房子到底应该能卖到多少钱。所以我们的任务就是给定一组房屋的数据,然后要能够预测售价是多少。
定义完问题之后,我们来分析一下数据。
首先,要做数据,我们会先把它装载到一个表格里边。这里,我们使用Pandas。
Pandas在Python基础课里我有详细的讲过,它是做数据科学非常常用的一个东西。不要把它认为是熊猫啊,它是panel data set的缩写,就是「面板数据集」,可以理解为一个Excel。可是它比Excel更方便编程。
import pandas as pd
data = dataset['data']
dataframe = pd.DataFrame(data)
print(len(dataframe))
dataframe.head(5)
为了节省篇幅,打印结果我就不贴出来了。
有的小伙伴在处理这里data的时候,会发现头部没有特征名,会呈现1, 2, 3, 4这样的数字。我们就需要将名称给它加上,之前我们说过,feature_name是特征名,于是:
dataframe.columns = dataset['feature_names]
这个时候我们就能看出来每一个特征到底是什么。不过这组数据里因为只是特征数据,并没有相关的价格。价格原本是目标数据,也就是最初始数据里的target,所以我们这里给这组特征数据里加上一列。
dataframe['price'] = dataset['target']
然后我们要想看看到底什么因素对房价的影响是最大的。「What’s the most significant(salient) feature of the house price」。
对于决定一个东西最重要的特征我们就叫做significant,或者silence,显著特征。
在pandas里边有一个很简单的东西,correlation。correlation就是两组变量的相关性。
关于特征相关性,我们在机器学习里面有详细的讲过,这里我们就粗略带过就行了,在使用corr()找到特征之间的相关性数据之后,可以使用seaborn来将热图可视化出来:
import seaborn as snssns.heatmap(dataframe.corr())
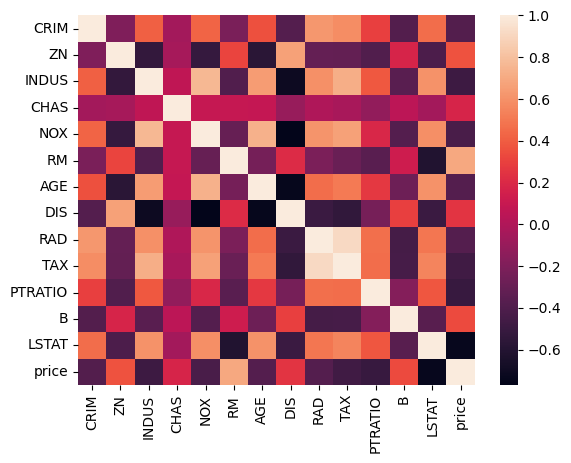
这里我们着重来看和价格相关的特征,除了它本身之外,正相关性最大的就是RM,负相关性最大的是LSTAT。
我们来看一下这两个特征的说明:
print(dataset['DESCR'])---
...
RM average number of rooms per dwelling
LSTAT % lower status of the population
...
RM是一套住宅的房间数量,一个是低收入人群的人口比例。也就是说,房间越多的房子越贵,小区内低收入人群的比例越低,小区内的房子越贵。那小区内低收入人群的比例居然比犯罪率的影响还要大一些,似乎有点让人难以接受,但是这个确实是事实。
基于以上分析,我们需要把房屋里边卧室的个数和房屋价格最成正相关。
把问题简单化:如何依据房屋里边卧室的数量来估计房子的面积?
在一九七几年的时候啊, 当时有过这样一种想法,首先,我们将所有的RM数据存下来, 还有目标数据,也就是price也存下来:
X_rm = dataframe['RM'].values
y = dataframe['price']
存下来之后我们把做一个字典映射:
rm_to_price = {r: y for r, y in zip(X_rm, y)}---
{6.575: 24.0,6.421: 21.6,...6.976: 23.9}
这样之后,问题也就相应的做了一个简化。假如有人在销售那里要求买房子,那销售就可以拿出一个字典,里面都是这样的对应关系,然后我们就可以去查一下就知道了。
这个时候假如有人告诉你有一个小区,他平均里边房屋平均是6.421。那一查就发现这个6.421的基本上卖21万。那如果小区里房屋数量是5.57的时候我卖多少钱?卖13万。这都是一一对应的关系。
rm_to_price[6.421]---
21.6
不过这个时候有一个人说我们那个小区里面平均是7个房间,那是多少呢?我们发现,我们的字典里没有超过7的数字,也就是没有这么一个对应关系。
那么找不到的时候怎么办呢?我们大部分时候解决问题都会找一个近似值,也就是最接近的数据来做参考。也可以根据以前的数据来做计算, 其实也就是一句话的事:
def find_price_by_simila(history_price, query_x, topn=3):return np.mean([p for x, p in sorted(history_price.items(), key=lambda x_y: (x_y[0] - query_x) **2)[:topn]])要根据以前的数据来做计算的话,我们定义了一个方法,传入了参数历史价格以及查询特征。然后我们返回的内容稍微有点复杂,首先给这个房屋进行排序,排序依据是按照x和query之间的距离来给他排序。排序的时候我们取最接近的这几个数字,这样就能够得到最接近的x和y。然后在x和y里面我们取它的price,这就是最接近的price。
然后我们来看看它给咱们算的如果房间数是7的情况是什么价格:
find_price_by_simila(rm_to_price, 7)---
29.233333333333334
关于排序那里看不懂的小伙伴,我们这里额外花点篇幅开个小灶。这样,假如说我们有下面一组数据:
person_and_age = {'A张学友': 62,'C周杰伦': 44,'B毛不易': 29
}
然后我们将这组数据改成列表并进行排序:
l = list(person_and_age.items())
sorted(l)---
[('A张学友', 62), ('B毛不易', 29), ('C周杰伦', 44)]
我们可以看到它是按照数据的首字母进行排序的,可是这个时候我们不想以首字母来排序,而是想根据年龄大小进行排序该怎么办?这个时候我们就可以给排序方法的key里面定规则,这个规则就是按照元素的第二个下标进行排序。
def get_first_items(element):return element[1]sorted(l, key=get_first_items)---
[('B毛不易', 29), ('C周杰伦', 44), ('A张学友', 62)]
我们这里定义了一个函数get_first_items, 其实做了一件很简单的事情,就是获得了element的第二个下标。
那么这里我们其实可以不用这样定义函数,而是直接用匿名函数。关于匿名函数,我在Python基础课里也有详细的讲到,大家可以回头去翻看一下。
sorted(l, key=lambda element: element[1])
那其实,element是一个输入参数,是一个变量,所以我们完全可以就简写一下就行:
sorted(l, key=lambda e: e[1])
然后我们再在后面多加一个切片操作:
sorted(l, key=lambda e: e[1], reverse=True)[:2]---
[('A张学友', 62), ('C周杰伦', 44)]
不用在意那个reverse=True, 只是打开了反向排序,因为个人情感上不想去掉张学友。
好,那这个时候呢我们在前面加一个for,就可以拿到名字和age,而我们只需要age:
[age for name, age in sorted(l, key=lambda e: e[1], reverse=True)[:2]]---
[62, 44]
这样我们就可以只取两个排序最靠前的年龄值,当然最后,就是mean,取平均值。
np.mean([age for name, age in sorted(l, key=lambda e: e[1], reverse=True)[:2]])---
53.0
那我们之前所写的函数内容就是这样一段话,拆解之后是不是就能明白了?
那么刚才讲到的这种方法,你会发现它是在找相似的东西,其实我们定义的这种方法,后来给它起个名字叫做:发现K个最相近的邻居,K-Neighbor-Nearest, 简称KNN。
def knn(history_price, query_x, topn=3):return np.mean([p for x, p in sorted(history_price.items(), key=lambda x_y: (x_y[0] - query_x) **2)[:topn]])
这种算法之前机器学习的章节里咱们也详细讲过,这是一个非常经典的机器学习算法。关于KNN的有优点和缺点,我们之前也讲的很详细。那大家可以回过头取看我关于机器学习KNN的部分来学习,这里就不再继续赘述KNN的内容了,在这里,我们就了解之前我们所做的这么多内容,其实就是KNN,就可以了。
好,那这节课的内容就到这里,下一节课,咱们会继续写这一篇未完成的代码,来找到X_rm和y之间的函数关系。那么代码文件就依然还是18.ipynb。
相关文章:
18. 深度学习 - 从零理解神经网络
文章目录 本文目标预测趋势与关系波士顿房价预测 Hi, 你好。我是茶桁。 我们终于又开启新的篇章了,从今天这节课开始,我们会花几节课来理解一下深度学习的相关知识,了解神经网络,多层神经网络相关知识。并且,我们会尝…...
Pycharm加载项目时异常,看不到自己的项目文件
最近看到一个朋友问,他把项目导入pycharm为什么项目里的包不在项目里显示,只在projects file里显示?问题截图如下: Project里看不到自己的项目文件 只能在Project Files里看到自己的项目文件 问题解答 我也是偶然发现的这个方案…...
)
目标检测YOLO实战应用案例100讲-基于无人机的轻量化目标检测系统设计(续)
目录 3.2 深度神经网络处理器设计 3.2.1 卷积神经网络处理器设计思路...

大文件传输小知识 | UDP和TCP哪个传输速度快?
在网络世界中,好像有两位“传输巨头”常常被提起:UDP和TCP。它们分别代表着用户数据报协议和传输控制协议。那么它们是什么?它们有什么区别?它们在传输大文件时的速度又如何?本文将深度解析这些问题,帮助企…...
【tgcalls】Instance接口的实例类的创建
tg 里有多个版本,因此设计了版本管理的map,每次可以选择一个版本进行实例创建这样,每个客户端就可以定制开发了。tg使用了c++20创建是要传递一个描述者,里面是上下文信息 G:\CDN\P2P-DEV\tdesktop-offical\Telegram\ThirdParty\tgcalls\tgcalls\Instance.cpp可以看到竟然是…...

【java:牛客每日三十题总结-3】
java:牛客每日三十题总结 总结如下 总结如下 集合相关知识点 Collection主要的子接口: List:可以存放重复内容 Set:不能存放重复内容,所有重复的内容靠hashCode()和equals()两个方法区分 Queue:队列接口 SortedSet:可以对集合中的数据进行排序 Map没有继承Collection接口&…...

区块链多链数字钱包开发
随着区块链技术的不断发展,多链数字钱包的开发逐渐成为热门领域。多链数字钱包是一种可以支持多种区块链网络的数字钱包,用户可以使用它来存储、管理和转移不同的数字资产。本文将探讨多链数字钱包的开发背景、市场需求、技术实现和未来趋势等方面。 一、…...

hive-行转列
xx...

【赠书第2期】嵌入式虚拟化技术与应用
文章目录 前言 1 背景概述 2 专家推荐 3 本书适合谁? 4 内容简介 5 书籍目录 6 权威作者团队 7 粉丝福利 前言 随着物联网设备的爆炸式增长和万物互联应用的快速发展,虚拟化技术在嵌入式系统上受到了业界越来越多的关注、重视和实际应用。嵌入式…...
如何写一篇吊炸天的竞品分析
这段时间,除了撩妹之外,最多的就是竞品分析了。最近很多临近毕业的同学也在四处应聘产品岗,而一份不错的竞品分析一定能为你的求职加分不少。于是,有着菩萨心肠天使面孔魔鬼身材的我,就来教大家怎么做一份完整的竞品分…...

校园安防监控系统升级改造方案:如何实现设备利旧上云与AI视频识别感知?
一、背景与需求分析 随着现代安防监控科技的兴起和在各行各业的广泛应用,监控摄像头成为众所周知的产品,也为人类的工作生活提供了很大的便利。由于科技的发达,监控摄像头的升级换代也日益频繁。每年都有不计其数的摄像头被拆掉闲置…...

刷题笔记day15-二叉树层序遍历
层序遍历 /*** Definition for a binary tree node.* type TreeNode struct {* Val int* Left *TreeNode* Right *TreeNode* }*/import ("container/list" )func levelOrder(root *TreeNode) [][]int {// 思路1:此处肯定要使用队列result : …...

前端 JS 经典:ES6 和 CommonJs 用法
1. 概念 都是 JavaScript 模块化规范,ES6 适用于浏览器端和 Node.js,CommonJs 适用于 Node.js。 2. 导出 // ES6 export function demo(n1, n2) {return n1 n2; }// CommonJS module.exports {demo: function (n1, n2) {return n1 n2;}, }; 3. 引入 …...

MacOS升级后命令行出现xcrun: error: invalid active developer path报错信息
在Mac上用g编译cpp文件时,出现以下(类似于工具环境问题的)报错: 解决方案:重新安装最新版的MacOS Command Line Tools xcode-select --install重新尝试编译: 编译成功(忽略这个warning&…...

【Qt】QPalette
2023年11月10日,周五上午 Palette意为“调色板”。 QPalette是Qt中用于管理控件调色板(颜色方案)的类。它允许你为Qt应用程序中的控件设置不同的颜色,以满足视觉设计需求。 QPalette可以管理各种控件的颜色属性,如前…...

专门为Web应用程序提供安全保护的设备-WAF
互联网网站面临着多种威胁,包括网络钓鱼和人为的恶意攻击等。这些威胁可能会导致数据泄露、系统崩溃等严重后果。 因此,我们需要采取更多有效的措施来保护网站的安全。其中WAF(Web application firewall,Web应用防火墙࿰…...

Android Camera App启动流程解析
前言:做了7年的camera app开发,给自己一个总结,算是对camera的一次告白吧。Camera被大家誉为手机的眼睛,是现在各大手机厂商的卖点,也是各大厂商重点发力的地方。Camera的重要性我就不在这里赘述了,让我们进…...

[工业自动化-8]:西门子S7-15xxx编程 - PLC主站 - CPU模块
目录 前言: 一、概述 二、CPU操作和显示 三、安装 四、CPU的选择 前言: 一、概述 西门子S7-1500系列是一系列高性能工业自动化控制器,广泛应用于制造业、自动化生产、物流等领域。这个系列的控制器是设计用来满足高性能、高效能要求的复…...
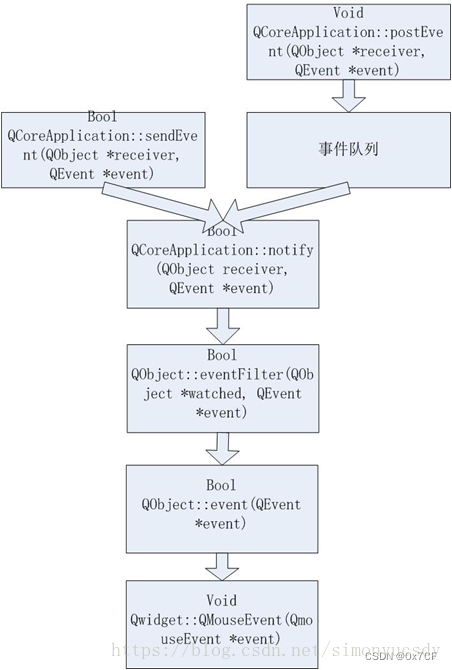
QT事件循环和事件队列的理解
Qt的事件循环机制_qt事件循环流程-CSDN博客 QT-事件循环机制_qt线程事件循环-CSDN博客 一、事件处理流程如图所示: 1.QCoreApplication::postEvent(QObject *receiver,QEvent *event): QCoreApplication::postEvent()函数用于将事件异步地发送到目标对…...

【Android】画面卡顿优化列表流畅度一
卡顿渲染耗时如图: 卡顿表现有如下几个方面: 网络图片渲染耗时大上下滑动反应慢,甚至画面不动新增一页数据加载渲染时耗时比较大,上下滑动几乎没有反应,画面停止没有交互响应 背景 实际上这套数据加载逻辑已经运行…...
)
从‘玩具’到‘工具’:我的电容主动均衡板实战笔记(解决电芯压差,提升电池组真实容量)
从‘玩具’到‘工具’:我的电容主动均衡板实战笔记 第一次意识到电池均衡的重要性,是在我的户外电源项目遭遇"容量跳水"之后。那组标称100Ah的磷酸铁锂电池,实际使用时容量竟不足70Ah——就像买了一辆宣称续航500公里的电动车&…...

智能体系统设计模式:从ReAct到多智能体协作
1. 智能体系统设计模式入门指南在构建基于人工智能的智能体系统时,设计模式的选择直接决定了系统的可靠性、可扩展性和可维护性。就像建筑设计师需要掌握结构力学原理一样,AI工程师也需要理解这些经过验证的设计范式。本文将带你系统掌握七种核心设计模式…...

MiniCPM-O-4_5-GGUF 全解析
一、模型简介MiniCPM-O-4_5-GGUF 是面壁智能(OpenBMB)推出的 MiniCPM-O-4.5 全模态大模型的轻量化量化版本,采用 GGUF 格式优化,专为端侧与低资源设备设计,是当前开源社区中性能最强、部署门槛最低的全模态小参数模型之…...

imFile下载管理器:如何实现高效的多协议下载管理?
imFile下载管理器:如何实现高效的多协议下载管理? 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop 在数字时代,文件下载已成为我们日常工作和学习中…...
)
手把手教你用STM32CubeMX配置SAI接口驱动MEMS数字麦克风(PDM转PCM实战)
STM32CubeMX实战:SAI接口驱动MEMS麦克风的PDM转PCM全流程解析 在智能语音设备爆发的时代,MEMS数字麦克风因其小尺寸、高信噪比和抗干扰能力成为嵌入式音频采集的首选。但许多开发者首次接触PDM信号转换时,常被时钟同步、滤波器设计等问题困扰…...

总结几个非常实用的Python库
一、datetimedatetime是Python处理日期和时间的标准库。1、获取当前日期和时间1234567891011>>> from datetime import datetime>>> now datetime.now()>>> print(now)2021-06-14 09:33:10.460192>>> print(type(now))<class datetime…...

别再只写“人”看了!企业GEO优化的四大核心要素,让你的品牌成为AI的“默认答案”
AI不会因为你的文采而感动,它只关心能不能在0.1秒内从你的内容里挖出它要的数据和答案。最近和不少做技术出海和B2B营销的朋友聊天,大家都有一个共同的焦虑:内容发了不少,文案也打磨得很漂亮,逻辑结构也算清晰。但无论…...
)
C++26反射不是“未来特性”——它是2026年嵌入式实时系统、游戏引擎热重载、AI推理框架插件系统的强制技术基线(附LLVM 19.0.1编译器支持矩阵)
更多请点击: https://intelliparadigm.com 第一章:C26反射特性在元编程中的应用 2026 最新趋势 C26 标准草案已正式纳入核心反射(Core Reflection)机制,其基于 std::reflexpr 和 meta::info 类型系统,为编…...

Parquet Viewer:重新定义浏览器数据查看体验的WebAssembly数据处理工具
Parquet Viewer:重新定义浏览器数据查看体验的WebAssembly数据处理工具 【免费下载链接】parquet-viewer View parquet files online 项目地址: https://gitcode.com/gh_mirrors/pa/parquet-viewer 在大数据时代,处理和分析Parquet文件已成为数据…...

从Kaggle竞赛到业务落地:XGBoost分类实战中的5个关键参数陷阱与解决方案
从Kaggle竞赛到业务落地:XGBoost分类实战中的5个关键参数陷阱与解决方案 当你在Kaggle排行榜上看到XGBoost模型大杀四方,信心满满地将它部署到业务系统中时,是否遇到过这样的困惑:为什么同样的参数设置,在实际业务中的…...