Python机器学习算法入门教程(第四部分)
接着Python机器学习算法入门教程(第三部分),继续展开描述。
十九、信息熵是什么
通过前两节的学习,我们对于决策树算法有了大体的认识,本节我们将从数学角度解析如何选择合适的“特征做为判别条件”,这里需要重点掌握“信息熵”的相关知识。
信息熵这一概念由克劳德·香农于1948 年提出。香农是美国著名的数学家、信息论创始人,他提出的“信息熵”的概念,为信息论和数字通信奠定了基础。
在理解“信息熵”这个词语前,我们应该理解什么是“信息”。信息是一个很抽象的概念,比如别人说的一段话就包含某些“信息”,或者我们所看到的一个新闻也包含“信息”,人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一篇 10 万字的论文到底包含多少信息量?信息熵就是用来解决对信息的量化问题的。
“熵”这一词语从热力学中借用过来的,热力学中的“热熵”是表示分子状态混乱程度的物理量,香农使用“信息熵”这一概念来量化“信息量”。信息的计算是非常复杂的,具有多重前提条件的信息,更是无法计算,但由于信息熵和热力熵紧密相关,所以信息熵可以在衰减的过程中被测定出来。
1、理解信息熵
想要非常清楚地讲明白“信息熵”到底是什么?需要结合物理上的知识,不过这样就有点“舍本逐末”,所以我们只要理解香农给出的相关结论即可:
信息熵是用于衡量不确定性的指标,也就是离散随机事件出现的概率,简单地说“情况越混乱,信息熵就越大,反之则越小”。
为了便于大家理解,我们通过下述示例进一步说明:
比如“台湾是中国的固有领土”和“台湾不是中国的固有领土”,你感觉哪一句话传递的信息量更大?当然是后者,因为前者属于既定事实,而后者若要发生的话,可能是发生了巨大的变革而导致的。如果一件事 100% 发生,那么这件事就是确定的事情,其信息熵无限接近于最小,但如果这件事具有随机性,比如抛硬币,其结果可能正面也可能反面,那么这件事就很不确定,此时的信息熵就无限接近于最大值。
再比如,封闭的房间一直不打扫,那么房间不可能越来越干净,只能不断的落灰和结下蜘蛛网,如果想要让它变得整洁、有序就需要外力介入去打扫房间。这个过程中趋向于混乱的房间其信息熵不断增大,而打扫后的房间,则趋向于信息熵最小。伟大数学家香农给出了信息熵的计算公式,如下所示:
![]()
其中 p 代表概率的意思,这里 “X” 表示进行信息熵计算的集合。在决策树分类算法中,我们可以按各个类别的占比(占比越高,该类别纯度越高)来理解,其中 N 表示类别数目,而 Pk 表示类别 K 在子集中的占比。理解了上述含义,再理解信息熵的计算过程就非常简单了,分为三次四则运算,即相乘、求和最后取反。
2、信息熵公式计算
下面我们举一个简单的例子,对上述信息熵计算公式进行简单的应用,在二元分类问题中,如果当前样本全部属于 k 类别,那么该类别在子集节点中的占比达到 100%(而另一个类别占比为 0),即 pk = 1,此时信息熵的计算公式如下:
![]()
关于对数函数的运算法则这里不再赘述,以 2 为底 1 的对数为 0,因此最终两个类别的信息熵求和结果为 0。信息熵为 0 说明子集内的类别一致“整齐有序”。由此也可以得知 pk=0.5 时候信息熵的取得最大值。下面根据上述信息,我们绘制信息熵的函数图像,如下所示:
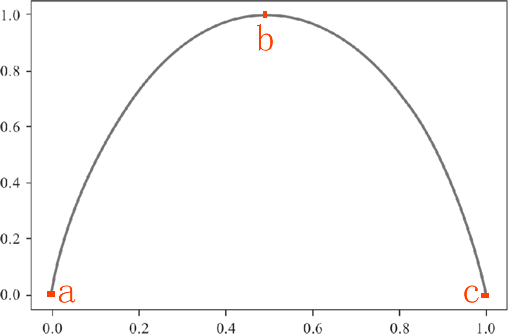
3、ID3算法—信息增益
通过前面知识的学习,我们知道决策树算法是以包含所有类别的集合为计算对象,并通过条件判别,从中筛选出纯度较高的类别,那么我们如何利用信息熵从特征集合中选择决策条件呢?下面我们以 ID3 算法为例进行说明。
ID3(Iterative Dichotomiser 3,迭代二叉树3代)算法是决策树算法的其中一种,它是基于奥卡姆剃刀原理实现的,这个原理的核心思想就是“大道至简,用尽量少的东西去做更多的事情”。
把上述原理应用到决策树中,就有了 ID3 算法的核心思想:越小型的决策树越优于大的决策树,也就是使用尽可能少的判别条件。ID3 算法使用了信息增益实现判别条件的选择,从香农的“信息论”中可以得知,ID3 算法选择信息增益最大的特征维度进行 if -else 判别。
(1) 理解信息增益
那么到底什么是信息增益?我们又如何计算特征维度信息增益值的大小呢?
简单地说,信息增益是针对一个具体的特征而言的,某个特征的有无对于整个系统、集合的影响程度就可以用“信息增益”来描述。我们知道,经过一次 if-else 判别后,原来的类别集合就被被分裂成两个集合,而我们的目的是让其中一个集合的某一类别的“纯度”尽可能高,如果分裂后子集的纯度比原来集合的纯度要高,那就说明这是一次 if-else 划分是有效过的。通过比较使的“纯度”最高的那个划分条件,也就是我们要找的“最合适”的特征维度判别条件。
(2) 信息增益公式
那么如何计算信息增益值,这里我们可以采用信息熵来计算。我们通过比较划分前后集合的信息熵来判断,也就是做减法,用划分前集合的信息熵减去按特征维度属性划分后的信息熵,就可能够得到信息增益值。公式如下所示:
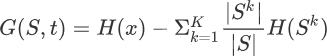
G(S,a) 表示集合 S 选择特征属性 t 来划分子集时的信息增益。H(x) 表示集合的信息熵。上述的“减数”看着有点复杂,下面重点讲解一下减数的含义:
- 大写字母 K 表示:按特征维度 t 划分后,产生了几个子集的意思,比如划分后产生了 5 个子集吗,那么 K = 5。
- 小写字母 k 表示:按特征维度 t 划分后,5 个子集中的某一个子集,k = 1 指的是从第一个子集开始求和计算。
- |S| 与 |Sk| 表示:集合 S 中元素的个数,这里的
||并不是绝对值符号,而 |Sk| 表示划分后,某个集合的元素个数。 - |S| /|Sk| 表示:一个子集的元素个数在原集合的总元素个数中的占比,指该子集信息熵所占的权重,占比越大,权重就越高。
最后,比较不同特征属性的信息增益,增益值越大,说明子集的纯度越高,分类的效果就越好,我们把效果最好的特征属性选为 if-else 的最佳判别条件。
ID3 算法是一个相当不错的决策树算法,能够有效解决分类问题,其原理比较容易理解。C4.5 算法是 ID3 算法的增强版,这个算法使用了“信息增益比”来代替“信息增益”,而 CART 算法则采用了“基尼指数”来选择判别条件,“基尼指数”并不同于“信息熵”,但却与信息熵有着异曲同工之妙,这些将作为延伸扩展知识,在后续内容中讲解。
二十、决策树算法和剪枝原理
本节我们对决策算法原理做简单的解析,帮助您理清算法思路,温故而知新。
我们知道,决策树算法是一种树形分类结构,要通过这棵树实现样本分类,就要根据 if -else 原理设置判别条件。因此您可以这样理解,决策树是由许多 if -else 分枝组合而成的树形模型。
1、决策树算法原理
决策树特征属性是 if -else 判别条件的关键所在,我们可以把这些特征属性看成一个集合,我们要选择的判别条件都来自于这个集合,通过分析与计算选择与待分类样本最合适的“判别条件”。通过前面文章的学习,我们可以知道被选择的“判别条件”使得样本集合的某个子树节点“纯度”最高。
上述过程就好比从众多的样本中提取“类别纯度”最高的样本集合,因此我们可以起一个形象化的名字“提纯”,过程示意图如下所示:

图1:决策树流程图
通过上述流程图可以得知,决策树算法通过判别条件从根节点开始分裂为子节点,子节点可以继续分裂,每一次分裂都相当于一次对分类结果的“提纯”,周而复始,从而达到分类的目的,在这个过程中,节点为“否”的不在分裂,判断为“是”的节点则继续分裂。那么你有没有考虑过决策树会在什么情况下“停止”分裂呢?下面列举了两种情况:
(1) 子节点属于同一类别
决策树算法的目的是为了完成有效的样本分类。当某个数据集集合分类完成,也就分类后的子节点集合都属于同一个类别,不可再分,此时代表着分类任务完成,分裂也就会终止。
(2) 特征属性用完
我们知道,决策树依赖特征属性作为判别条件,如果特征属性已经全部用上,自然也就无法继续进行节点分裂,此处可能就会出现两种情况:一种是分类任务完成,也就是子节点属于同一类别,还有另外一种情况就是分类还没有完成,比如,在判断为“是”的节点集合中,有 8 个正类 3 个负类,此时我们将采用占比最大的类作为当前节点的归属类。
(3) 设置停止条件
除上述情况外,我们也可以自己决定什么时候停止。比如在实际应用中我们可以在外部设置一些阈值,把决策树的深度,或者叶子节点的个数当做停止条件。
2、决策树剪枝策略
决策树算法是机器学习中的经典算法。如果要解决分类问题,决策树算法再合适不过了。不过决策树算法并非至善至美,决策树分类算法最容易出现的问题就是“过拟合”。什么是“过拟合”我们在教程的开篇已经提及过,它指的机器学习模型对于训练集数据能够实现较好的预测,而对于测试集性能较差。
“过拟合”使决策树模型学习到了并不具备普遍意义的分类决策条件,从而导致模型的分类效率、泛化能力降低。
决策树出现过拟合的原因其实很简单,因为它注重细节。决策树会根据数据集各个维度的重要性来选择 if -else 分支,如果决策树将所有的特征属性都用完的情况下,那么过拟合现象就很容易出现。
我们知道,每个数据集都会有各种各样的属性维度,总会出现一些属性维度样本分类实际上并不存在关联关系的情况。因此,在理想情况下决策树算法应尽可能少地使用这些不相关属性,但理想终归是理想,在现实情况下很难实现。那么我们要如何解决这种过拟合问题呢?这时就要用到“剪枝策略”。
“剪枝策略”这个名字非常的形象化,它是解决决策树算法过拟合问题的核心方法,也是决策树算法的重要组成部分。剪枝策略有很多种,我们根据剪枝操作触发时间的不同,可以将它们分成两种,一种称为预剪枝,另一种称为后剪枝。
(1) 预剪枝
所谓预剪枝,就是将即将发芽的分支“扼杀在萌芽状态”即在分支划分前就进行剪枝判断,如果判断结果是需要剪枝,则不进行该分支划分。
(2) 后剪枝
所谓后剪枝,则是在分支划分之后,通常是决策树的各个判断分支已经形成后,才开始进行剪枝判断。
上述两个剪枝策略,我们重要理解“预”和“后”。“预”就是打算、想要的意思,也就是在分支之前就被剪掉,不让分支生成,而“后”则是以后、后面,也就是分支形成以后进行剪枝操作。那么我要如何判断什么时候需要进行剪枝操作呢?其实很容易理解,如果剪枝后决策树模型在测试集验证上得到有效的提升,就判断其需要剪枝,否则不需要。
剪枝的操作对象是“分支的判别条件”,也就是减少不必要特征属性的介入,从而提高决策树分类效率,和测试集的预测能力。下面通过一个简单的例子进行说明:
某个样本数据集有两个类别(正类与负类),2 个特征属性,现在我们对 20 个样本进行分类。首先,在应用所有“特征属性”的情况下对样本进行分类。如下所示:

图2:决策树过拟合问题
上图 2 使用了两个特征属性对样本集合进行分类,最后正确分类的概率是 12/20。如果只通过特征 1 进行分类,也就是剪掉冗余特征 2,最后的结果又是怎样呢?如下图所示:
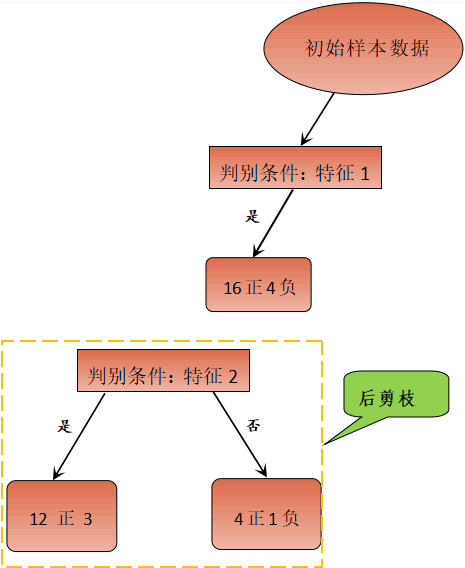
图3:决策树剪枝策略流程
通过后剪枝策略后,正确分类概率变成了 16/20。显而易见,剪枝策略使得正确分类的概率得到提高。
剪枝策略较容易理解,在实际情况中后剪枝策略使用较多。在分支生成后,使用后剪枝策略将冗余的子树及其判别条件直接剪掉,然后使用上个节点中占比最大的类做为最终的分类结果。
二十一、sklearn决策树分类算法应用
本节基于 Python Sklearn 机器学习算法库,对决策树这类算法做相关介绍,并对该算法的使用步骤做简单的总结,最后通过应用案例对决策树算法的代码实现进行演示。
1、决策树算法应用
在 sklearn 库中与决策树相关的算法都存放在sklearn.tree模块里,该模块提供了 4 个决策树算法,下面对这些算法做简单的介绍:
(1) .DecisionTreeClassifier()
这是一个经典的决策树分类算法,它提供了许多有用的参数,比如criterion,该参数有两个参数值,分别是 gini(基尼指数)和 entropy(信息增益),默认情况下使用“基尼指数”,其中“gini”用于创建 CART 分类决策树,而“entropy”用于创建 ID3 分类决策树。
注意:在其余三个决策树算法中都可以使用 criterion 参数。
(2) .DecisionTreeRegressor()
它表示用决策树算法解决回归问题。
(3) .ExtraTreeClassifier()
该算法属于决策树分类算法,但又不同于.DecisionTreeClassifier()算法,因为.ExtraTreeClassifier()选择“特征维度”作为判别条件时具有随机性,它首先从特征集合中随机抽取 n 个特征维度来构建新的集合,然后再从新的集合中选取“判别条件”。
(4).ExtraTreeRegressor()
该算法同样具有随机性,它与.ExtraTreeClassifier()随机过程类似,它主要解决机器学习中的回归问题。
2、决策树实现步骤
通过前面内容的学习,我们已经大体掌握了决策树算法的使用流程。决策树分类算法的关键在于选择合适的“判别条件”,该判别条件会使正确的分类的样本“纯度”最高。想要选取合适的特征属性就需要使用“信息熵”与“信息增益”等计算公式。
(1) 确定纯度指标
确定纯度指标,用它来衡量不同“特征属性”所得到的纯度,并选取使得纯度取得最大值的“特征属性”作为的“判别条件”。
(2) 切分数据集
通过特征属性做为“判别条件”对数据集集合进行切分。注意,使用过的“特征属性”不允许重复使用,该属性会从特征集合中删除。
(3) 获取正确分类
选择特征集合内的特征属性,直至没有属性可供选择,或者是数据集样本已经完成分类为止。切记要选择占比最大的类别做为分类结果。
3、决策树算法应用
下面使用决策树算法对 Sklearn 库中的红酒数据进行模型训练,与数据预测,示例代码如下:
# 加载红酒数据集
from sklearn.datasets import load_wine
# 导入决策树分类器
from sklearn.tree import DecisionTreeClassifier
# 导入分割数据集的方法
from sklearn.model_selection import train_test_split
# 导入科学计算包
import numpy as np# 加载红酒数据集
wine_dataset=load_wine()# 分割训练集与测试集
X_train,X_test,y_train,y_test=train_test_split(wine_dataset['data'],wine_dataset['target'],test_size=0.2,random_state=0)# 创建决策时分类器--ID3算法
tree_model=DecisionTreeClassifier(criterion="entropy")
# 喂入数据
tree_model.fit(X_train,y_train)
# 打印模型评分
print(tree_model.score(X_test,y_test))# 给出一组数据预测分类
X_wine_test=np.array([[11.8,4.39,2.39,29,82,2.86,3.53,0.21,2.85,2.8,.75,3.78,490]])
predict_result=tree_model.predict(X_wine_test)
print(predict_result)
print("分类结果:{}".format(wine_dataset['target_names'][predict_result]))输出结果如下:
0.9166666666666666
[1]
分类结果:['class_1']
二十二、初识支持向量机SVM分类算法
支持向量机,英文全称“Support Vector Machines”(简称 SVM),它是机器学习中最常用的一种“分类算法”。SVM 是一种非常优雅的算法,有着非常完善的数学理论基础,其预测效果,在众多机器学习模型中可谓“出类拔萃”。在深度学习没有普及之前,“支持向量机”可以称的上是传统机器学习中的“霸主”,下面我们将介绍本节的主人公——支持向量机(SVM)。
1、初识支持向量机
支持向量机是有监督学习中最有影响力的机器学习算法之一,该算法的诞生可追溯至上世纪 60 年代, 前苏联学者 Vapnik 在解决模式识别问题时提出这种算法模型,此后经过几十年的发展直至 1995 年, SVM 算法才真正的完善起来,其典型应用是解决手写字符识别问题。
当我们第一次见到“支持向量机”这个名词时,一定会感到“懵圈”,单从这个名字来看,它就散发这非常神秘的气息,仿佛游戏中的必杀技一样,但真的像我们感觉到的一样吗?其实名字就是“拦路虎”,就像我们前面学习的“朴素贝叶斯”一样。支持向量机并非源于“人名”,但以我们现有的知识,我们只知道“向量”是什么,至于“支持向量机”是什么,您一定做不出任何有说服力的解释。
注意:支持向量机是一个比较“难”讲解的算法,需要理解大量的数学知识,否则只能雾里看花。在写作本文的过程中,我尽量本着通俗易懂的角度来讲解,但由于个人能力有限,以及读者群体不同,难免会众口难调,还请多多包含。同时,如果文章中有任何不妥之处,也请不吝赐教。
2、支持向量机组成
首先对支持向量机做一个直观的描述:支持向量机是一个分类器算法,主要用于解决二分类的问题,最终告诉我们一个样本属于 A 集合还是属于 B 集合,这和之前学习过的分类算法别无二致。
一个算法模型就好比一台精巧的机器,有许多零部件组成,支持向量机也是如此。对于支持向量机而言有三个重要构件,分别是:
- 最大间隔
- 高维映射
- 核函数
上述三者是 SVM 支持向量机的核心,三者之间彼此独立,又互相依存,如果缺少了其中任何一个部件,都不能驱动支持向量机这台“机器”,这三个部件也是后续介绍的核心知识,只有充分理解了它们,才能将得心应手的使用 SVM 算法。如果用一句话来总结这三个部件的作用,那就是“最大间隔是标尺,高维映射是关键,最终结论看核函数”。
3、支持向量机本质
支持向量机本质上是从在线性分类算法的基础上发展而来的,就如同已经学习过的 Logistic 逻辑回归算法一样,只需给线性函数“套”上一层 Logistic “马甲”,就可以用线性模型来解决离散数据的分类问题。对于支持向量机来说,要解决分类问题,其过程则更为复杂。下面剖析一下支持向量机的本质,从而帮助您更好的理解它的算法思想。
(1) 间隔和支持向量
支持像向量机算法中有一个非常重要的角色,那就是“支持向量”,支持向量机这个算法名字也由它而来(机,指的是“一种算法”),要想理解什么是“支持向量”就首先要理解“间隔”这一个词。
支持向量机中有一个非常重要的概念就是“间隔最大化”,它是衡量 SVM 分类结果是否最优的标准之一。下面通过“象棋”的例子来理解什么是“间隔”:
中国象棋是我国独有的一类娱乐活动,棋子分为黑子和红子,并用“楚河汉界”将其分开。如果用一条直线将不同颜色的棋子进行分类,这显然信手拈来,只需要在楚河汉界的空白附带画一条“中轴线”就能以最佳的方式将它们分开,这样就能保证两边距离最近的棋子保有充分的“间隔”。
上述示例中产生的“间隔”实际上是依据两侧不同颜色的棋子划分而成的,我们把这些棋子统称为“样本点”。虽然这些样本点都参与了分类,但对于分类效果影响最大的是处于间隔“边缘”的样本,只要将处于边缘的样本正确分类,那么这两个类别也就分开了,因此我们把处于边缘样本点称为“支持向量”。
(2) 软间隔和硬间隔
间隔,又分为软间隔和硬间隔,其实这很好理解,当我们使用直线分类时会本着尽可能将类别全都区分开来的原则,但总存在一些另类的“样本点”不能被正确的分类,如果您允许这样的“样本点存在”,那么画出的间隔就成为“软间隔”,反之态度强硬必须要求“你是你,我是我”,这种间隔就被称为“硬间隔”,在处理实际业务中,硬间隔只是一种理想状态。
(3) 最大间隔
上述所说的保有充分的“间隔”,其实就是“最大间隔”,你可能会问,为什么是最大间隔呢,两个类别只要能区分开不就行了吗?其实这涉及到算法模型最优问题,就像常时所说的一样,做事要给自己留有余地,不能将自己至于危险的边缘。
如果将数据样本分割的不留余地,就会对随机扰动的噪点特别敏感,这样就很容易破坏掉之前的分类结果,学术称为“鲁棒性差”,因此我们在分类时要尽可能使正负两类分割距离达到最大间隔。
4、支持向量机应用
支持向量机是一种使得样本点达到最佳分类效果的算法,但上述示例并非支持向量机的应用场景,通过上述示例我们只是知道了“什么是间隔”以及什么是“支持向量”,那支持向量应用场景到底是怎么的呢?通过下面形象化的描述,您也许能体会到 SVM 的强大之处:
当对弈双方在下棋之前,需要将散落在棋盘上的棋子放在各自的位置上,此时这些棋子并非按照颜色排列在“楚河汉界”两边,而是“杂乱无章”的放在棋盘上,那么如何快速地将这些棋子分呢?你应该如何做呢?当然你也许会想到用手一个个的挑出来,但是这里的棋子只是类比数据样本点,在实际的业务中你可能面对的是成千上亿的数据样本,要想解决这个问题,支持向量机就派上了用场。
如果用画“直线”的方法,一定不能解决上述问题,因此简单粗暴的线性函数“貌似”派不上用场,那么到低如果解决呢?
我们不妨回忆一下 Logistic 回归分类算法,通过给线性函数“套”上一层 Logistic 函数就解决了离散数据的分类问题,SVM 能否按照同样的思维方式来解决呢,答案是肯定的。
支持向量机类似于逻辑回归,这个模型也是基于线性函数 wTx + b 的,不同于逻辑回归的是,支持向量机不输出概率,只是输出类别。
当 wTx + b 为正时,支持向量机预测属于正类;而当 wTx + b 为负时,支持向量机预测属于负类。当然,在判断类别的过程中还要用到 SVM 的另外两个重要部件,也就是“高维映射”和“核函数”,否则无法实现利用线性函数解决分类问题,至于是如何解决的,后续知识会做详细讲解。
注意:上述示例中“棋子”只是形象化的比喻,在具体的业务中,我们处理的是“数据样本点”
5、总结
本节初步认识了“支持向量机(SVM)算法”,了解了组成支持向量机的三个重要部件。通过对支持向量机本质的讲解,我们知道支持向量机是从线性函数的基础上发展而来的,因此我们可以得出,支持向量机(SVM)是一种利用线性函数解决线性不可分(分类)问题的算法。
二十三、SVM解决线性不可分问题
通过上一节的学习,我们知道 SVM 是一种用来解决性线性不可分问题的算法,那它到底是如何解决的呢?在本节我们将对其做出详细的解释。
1、让棋子飞起来
首先我们来回味一下二十二、《初识支持向量机SVM分类算法》一节提到的案例:
在一个棋盘上杂糅的摆放着黑白两种棋子,要求我们以最快的速度将它们各自分开,这时我们应该如何做呢?也许喜欢金庸武侠的小伙伴已经想到了答案。
假如你是一位拥有深厚内力的大侠,你直接可以拍盘而起,让棋子们飞起来,同时让黑子飞高一点,白子则相对低一些,这样平面无法线性区分的分类问题,瞬间成了在立体空间内使之分类,此时你以迅雷不及掩耳之势,在它们分开的间隔内插上一张薄纸,就可以轻易地将黑、白两种棋子分开。
注意:上述示例只是类比,示例中的棋子,也只是一个个“样本点”。
回到现实世界中我们只是普通人,并非武侠小说中的大侠,因此不能凭借内力让棋子飞起来。既然不能用内力来解决问题,那么我们应该如何做呢?下面回归到本节的主题——支持向量机,它也是一本武功秘籍,掌握了它,同样可以让“棋子”飞起来。下面就一起来看看支持向量机是如何让“棋子”飞起来的”。
2、SVM高维映射
宋朝的苏轼有诗云“横看成岭侧成峰,远景高低各不同,不识庐山真面目,只缘身在此山中”诗的前两句指的从不同的角度看待一个事物会得到不一样的结果,用这句诗来引出的“高维映射”这个概念再合适不过了。
支持向量机的三大核心构件分别是最大间隔、高维映射以及核函数,高维映射则是支持向量机的第二个核心构件。我们知道线性分类器最大的特点就是简单,说白了就是“一根筋”,当面对非线性分类问题时不知变通,因此就需要帮助它疏通一下,就像解决 Logostic 逻辑回归问题一样,高维映射就是我们要寻找的方法。
(1) 超平面
高维映射主要是用来解决“你中我,我中有你”的分类问题的,也就是前面所说的“线性不可分问题”,所谓高维映射就是站在更高的维度来解决低维度的问题。
我们都知道点线面可以构成三维立体图,比如棋子是棋盘上的“点",“间隔”是棋盘上的一条线,棋盘则是一个“面”,而当我们拍盘而起,棋子飞升就会形成一个多维的立体空间,示意图如下:
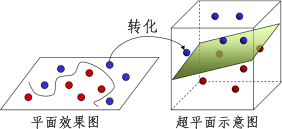
图1:超平面示意图
如图所示经过高维映射后,二维分布的样本点就变成了三维分布,而那张恰好分开棋子的纸(图 1 呈现绿色的平面), SVM 统称其为“超平面”。
通过增加一个维度的方法(给平面增加一个高度,使其变成三维空间),解决“线性不可分的问题”。在上述过程中仍存在一些问题会令你困惑,比如为什么映射到高维后就一定能保证正负类分开,还有一个更令人挠头的问题,这个高维空间应该如何找呢,以及在新的空间中,原有的数据点的位置是如何确定的呢?要想知道答案,不妨继续往下读。
3、SVM核函数
要想解决上述问题,就必须要了解支持向量机的另外一个重要部件——核函数(Kernel Function)。
核函数是一类功能性函数,类似于 Logistic 函数。SVM 规定,只要能够完成高维映射功能的数学函数都称为“核函数”,它在支持向量机中承担着两项任务,一是增加空间的维度,二是完成现有数据从原空间到高维空间的映射。接下来对其做详细的介绍。
首先我们再次强调 SVM 是一种使用线性方法来处理线性不可分问题的算法。明确了这一点,下面再来看一个实例说明,对于 “你中有我,我中有你”这句话来说,最为经典的案例,当属一类数据包围了另外一类数据。如下图 2 所示:
深蓝色的的球,被另外一种淡蓝色的球体包裹住了,在这种情况下,任何一条直线都不能将它们分开,因此就无法使用线性函数直接实现类别划分。
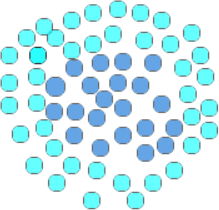
图2:SVM核函数应用
现在我们变通一下使用高维映射的思维来解决一下,看看能否找到解决问题的突破口。
接下来,我们将深蓝色的数据点全部映射到一个三维空间内,使之与浅蓝色的数据点形成高度差,这样就可以使用线性函数完成不同样本点的分类了,就如同倒扣的漏斗,深蓝色的数据点全部集中与上方,而浅蓝色的则分布在漏斗底部,此时可以用一个平面(此处平面就是超平面)将它们分开,如图 3 所示中间的分割线。

图3:SVM高维映射
上述高维映射过程是通过核函数(或称映射函数)来实现的,通过这个函数就可以找到一个三维空间,并确定数据点分布,至于能否保证样本点完全分开,这也是由核函数决定的。那么这个核函数要怎么确定呢,这就要通过实际案例的分析、运算才能得到。
在 Pyhthon Sklearn 库提供了多种核函数,使用不同的核函数会对最终的分类效果带来不同程度影响,因此要选择使得分类效果最优的核函数。
因此高维映射和核函数看似是两个分开的部件,其实是一个整体,高维映射的核心就是“核函数”。更通俗地讲,高维映射只是一种指导思想,而核函数才是具体实践者。
4、总结
通过这两节的学习,我们认识了 SVM 重要组部分间隔最大化和高维映射(将它与核函数看做一体),下面对已经学习的知识做简单总结:
SVM 算法是用来解决线性不可分的“非线性”问题, 从而突破线性分类的局限性,使得线性分类器依然可以适用于“非线性”问题。在这个过程中起到关键作用的就是“高维映射”。而“间隔最大化”可以看做支持向量机的损失函数,它衡量分类效果是否最佳的“标尺”,让间隔达到最大就是 SVM 追求的至臻境界,要实现这个目标就要不断地训练模型,使模型的泛化能力最佳。
最后对 SVM 算法进行分类的大致过程进行总结,大致分为以下三步:
- 选取一个合适的数学函数作为核函数;
- 使用核函数进行高维映射,解决样本点线性不可分的问题;
- 最后用间隔作为度量分类效果的损失函数,找到使间隔最大的超平面,最终完成分类的任务。
二十四、从数学角度理解SVM分类算法
本节将从数学角度讲解支持向量机(SVM)相关知识,掌握这些有利用加深对 SVM 算法原理的理解,对于学习任何一款机器学习算法都是非常有帮助的,虽然各种数学公式很难懂,但本人会尽最大努力去讲明白。尽管如此由于每位读者的数学基础不一样,如有表达不到位的地方,还请海涵。
1、再谈间隔最大化
我们知道,支持向量机是以“间隔”作为损失函数的,支持向量机的学习过程就是使得间隔最大化的过程,若想要了解支持向量机的运转机制,首先就得知道间隔怎么计算。
“间隔大小”是由距离分类“界限”最近的两个数据点(即支持向量)决定的。支持向量机对“间隔”的定义非常简单,即处于最边缘的支持向量(样本点)到超平面距离的总和,这里所说的距离就是最常见的几何距离。如果我们用 wx+b 来表示超平面,那么点到三维平面的距离公式如下:
![]()
由此也可以推断出点到 N 平面的通式,如下所示:
![]()
注意:上述公式中被除数是分子,除数是 L2 范式的简要写法,当 i = 3 时,与上述点到三维平面的距离公式相同。
支持向量机算法使用 y =1 来表示正类的分类结果;使用 y = -1 来表示负类结果,所以 y = wx+b 要么是大于或者等于 1,要么小于或等于 -1,由此得出间隔距离也可以表示如下:
![]()
上述距离公式中被除数是 2 (常数),而我们的目的是要求间隔最大化距离,因此式子转换如下:
![]()
即求 max 1/||w|| 的最大值。此处需要注意,其中 s.t. 表示受约束的(即在某种条件下),上述公式要使左边式子最大,就要使分母越小,因为此处的分子是不变(常数),所以可将上述表达式转换为下列式子:
![]()
下面使用“拉格朗日乘子法”对上述表达式进一步转换:
![]()
上述公式中,α 被称为“拉格朗日乘子”,然后分别对上式子中的 w 和 b 求导,并令导数为 0,右侧的公式可表示为:
![]()
这时就转变成如何求极值的问题:
![]()
注意上式中的 xiTxj 是一组向量的内积运算,该式子的约束条件为:
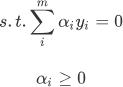
通过拉格朗日乘子法和 SMO(二次规划算法)算法,求出的最大间隔。
注意:拉格朗日乘子算法(以数学家 Joseph-Louis Lagrange 的名字命名)是一种多元函数在其变量受到一个或多个条件的约束时求极值方法。 这种方法可以将一个有 n 个变量与 k 个约束条件的最优化问题转换为一个解有 n + k 个变量的方程组的解的问题。关于拉格朗日乘子算法不做过多介绍,如感兴起可点击前往进行了解。
上述过程中涉及了大量数学概念和的数学运算,这些知识理解起来会比较繁琐,需要慢慢消化,甚至需要您恶补一些数学知识。如果实在看不懂,建议跳过,毕竟这些知识不会影响您使用支持向量机算法。
2、再谈核函数
高维映射说白了就是一种函数映射,在支持向量机中通常采用符号φ来表示这个函数,比如向量 xi 经过高维映射后就变成了 φ(xi),依次类推超平面的表达式如下所示:
![]()
在求解间隔最大化时,我们使用了拉格朗日函数,转化后的式子涉及了向量的内积运算,那么经过核函数映射后的内积运算为:
![]()
映射后向量变成高维向量,运算量将明显增加,直接运算会导致效率明显下降。不过,在间隔最大化的运算中只使用了高维向量内积运算的结果,并没有单独使用高维向量,也就是说,如果能简单地求出高维向量的内积,那么也可以满足求解间隔最大化的条件。下面假设存在函数 K,能够满足下列条件:
![]()
这里的函数 K 就是我们前面所讲的核函数。有了核函数,所有涉及的内积运算到的表达式,都可以通过 K 函数求解得出。
注意:对于已知的映射函数 φ,核函数是很容易计算的,但在大多数情况下,我们并不知道映射函数 φ 的具体形式,好在伟大的数学家们已经证明,在无法得出 φ 时,只要数学函数满足几个相应条件,同样可以将其作为核函数,因此不用担心找不到核函数。
下一部分将在Python机器学习算法入门教程(第五部分)展开描述。
相关文章:
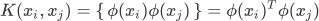
Python机器学习算法入门教程(第四部分)
接着Python机器学习算法入门教程(第三部分),继续展开描述。 十九、信息熵是什么 通过前两节的学习,我们对于决策树算法有了大体的认识,本节我们将从数学角度解析如何选择合适的“特征做为判别条件”,这里…...
Ubuntu中安装rabbitMQ
一、安装 RabbitMQ ①:更新源 sudo apt-get update②:安装Rrlang语言 由于RabbitMq需要erlang语言的支持,在安装RabbitMq之前需要安装erlang sudo apt-get install erlang-nox③:安装rabbitMQ sudo apt-get install rabbitmq-s…...
Langchain-Chatchat实践详解
简介 本质上是在Langchain基础上封装的一层聊天服务,可以对接底层多种离线LLM和在线的LLM(也可以对接自定义的在线LLM)。提供基于知识库聊天功能相关的一系列API。 下载源码 源码地址: https://github.com/chatchat-space/Lang…...

python求解优化问题的几个例子
目录 1、最优化问题 2、线性规划 3、无约束优化 3.1单变量 3.2多变量 1、最优化问题 使用scipy库中的minimize函数来求解最优化问题。在这个例子中,我们定义了一个目标函数 objective,其形式为x1^2 x2^2;以及一个约束条件 constraint&…...

HP惠普暗影精灵9P OMEN 17.3英寸游戏本17-cm2000(70W98AV)原装出厂Windows11-22H2系统镜像
链接:https://pan.baidu.com/s/1gJ4ZwWW2orlGYoPk37M-cg?pwd4mvv 提取码:4mvv 惠普暗影9Plus笔记本电脑原厂系统自带所有驱动、出厂主题壁纸、 Office办公软件、惠普电脑管家、OMEN Command Center游戏控制中心等预装程序 所需要工具:3…...
(组件类型))
❤ Uniapp使用Ucharts(二)(组件类型)
❤ Uniapp使用Ucharts(二)(秋云组件类型) 一、折线图 1、结构 <template><view class"charts-box"><qiun-data-charts type"area":opts"opts":chartData"chartData"/&…...

Linux Vim批量注释和自定义注释
使用 Vim 编辑 Shell 脚本,在进行调试时,需要进行多行的注释,每次都要先切换到输入模式,在行首输入注释符"#"再退回命令模式,非常麻烦。连续行的注释其实可以用替换命令来完成。 换句话说,在指定…...

虚幻C++基础 day3
常见的游戏机制 Actor机关门 创建一个Actor类,添加两个静态网格与一个触发器 UBoxComponentUStaticMeshComponent 头文件: #include “Components/BoxComponent.h”#include “Components/StaticMeshComponent.h” TriggerDoor.h // Fill out your …...

第26期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…...
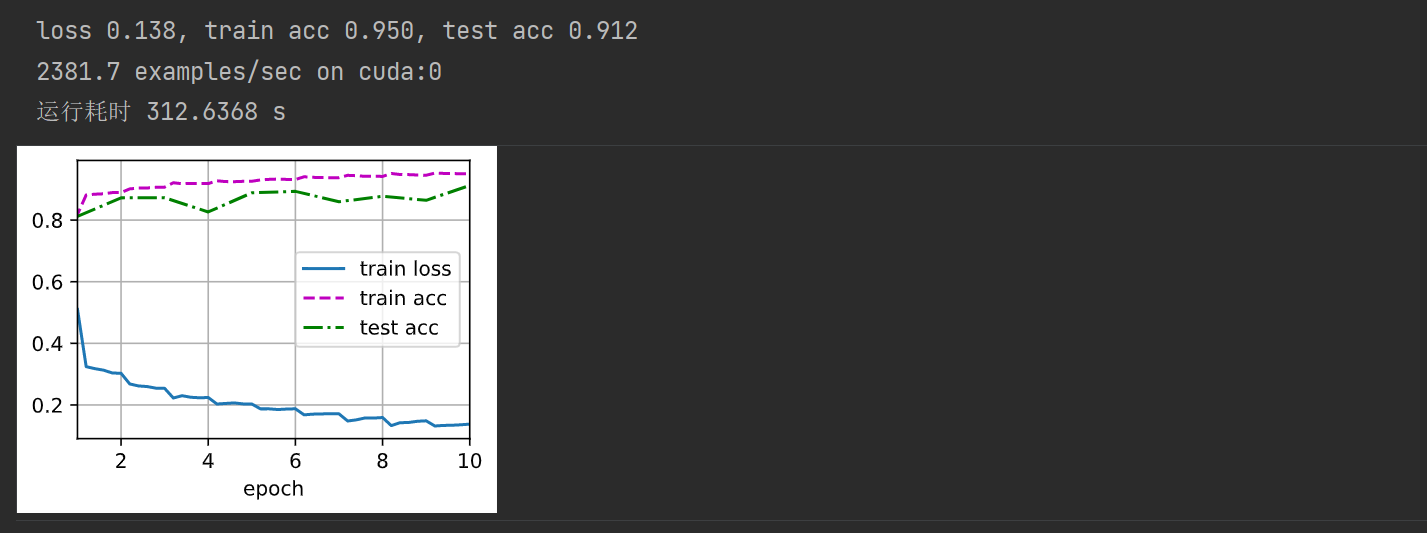
(动手学习深度学习)第7章 稠密连接网络---DenseNet
目录 DenseNetDenseNet的优点:DenseNet的改进思路总结 DenseNet代码实现 DenseNet DenseNet的优点: 省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。对于工业界而言,小模型可以显著…...

UART编程(寄存器)
1. 串口编程步骤 1.1 看原理图确定引脚 有很多串口,使用哪一个?看原理图确定 1.2 配置引脚为UART功能 至少用到发送、接收引脚:txd、rxd 需要把这些引脚配置为UART功能,并使能UART模块 1.3 设置串口参数 有哪些参数…...
事务码增删查改表数据
常用事务码 SE11 SE14 SE16 SE16N SM30 SE11:查看数据库表/修改表中字段数量_类型/查看表中数据/设置表为可维护或不可维护 SE14:查看数据库表的创建日期创建用户名/查看表中字段/删除表中全部数据(只能全部删) SE16:查看数据库表/对可维护数据库表进行数据维护/SE16通过调试…...
vue开发环境搭建部署(mac版)
前言 目前后端工作越来越少了,年底了,为了先过验收。项目负责人、产品、需求制定的方案就是先做假页面,所以前端的活多点。 其实现在不喜欢搞前端,原因很多,但是感觉现在似乎流行的码林绝学又是九九归一的瓶颈期…...
源码分享)
Java【算法 05】通过时间获取8位验证码(每两个小时生成一个)源码分享
通过时间获取验证码 1.需求2.代码实现2.1 依赖2.2 时间参数处理方法2.3 截取验证码方法2.4 验证方法 3.总结 1.需求 要求是很简单的,每个验证码的有效时间是2小时,这个并不是收到验证码开始计时的,而是每个两小时的时间段使用的是相同的验证…...

微服务 Spring Cloud 5,一图说透Spring Cloud微服务架构
目录 一、域名系统DNS二、LVS(Linux Virtual Server),Linux虚拟服务器三、CDN静态资源四、Nginx反向代理服务器1、Nginx的主要作用体现在以下几个方面:2、Nginx静态资源服务和CDN静态资源服务,如何选择? 五、Gateway网…...

conda清华源安装cuda12.1的pytorch
使用pytorch官方提供的conda command奇慢无比,根本装不下来(科学的情况下也这样) 配置一下清华源使用清华源装就好了 清华源:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ 配置方法:conda config --…...

安徽首届道医传承十八绝技发布会在合肥成功举办
近日,在安徽合肥举行了首届道医传承十八绝技发布会,本次会议由安徽渡罗门生物科技有限公司、北京道武易医文化传播有限公司、楼观台道医文化研究院联合举办。现场吸引了来自全国各地民族医学领域的专家学者参与讨论与交流。本次会议旨在促进道医的交流与…...
一款功能强大的web目录扫描器专业版
dirpro 简介 dirpro 是一款由 python 编写的目录扫描器,操作简单,功能强大,高度自动化。 自动根据返回状态码和返回长度,对扫描结果进行二次整理和判断,准确性非常高。 已实现功能 可自定义扫描线程 导入url文件进…...
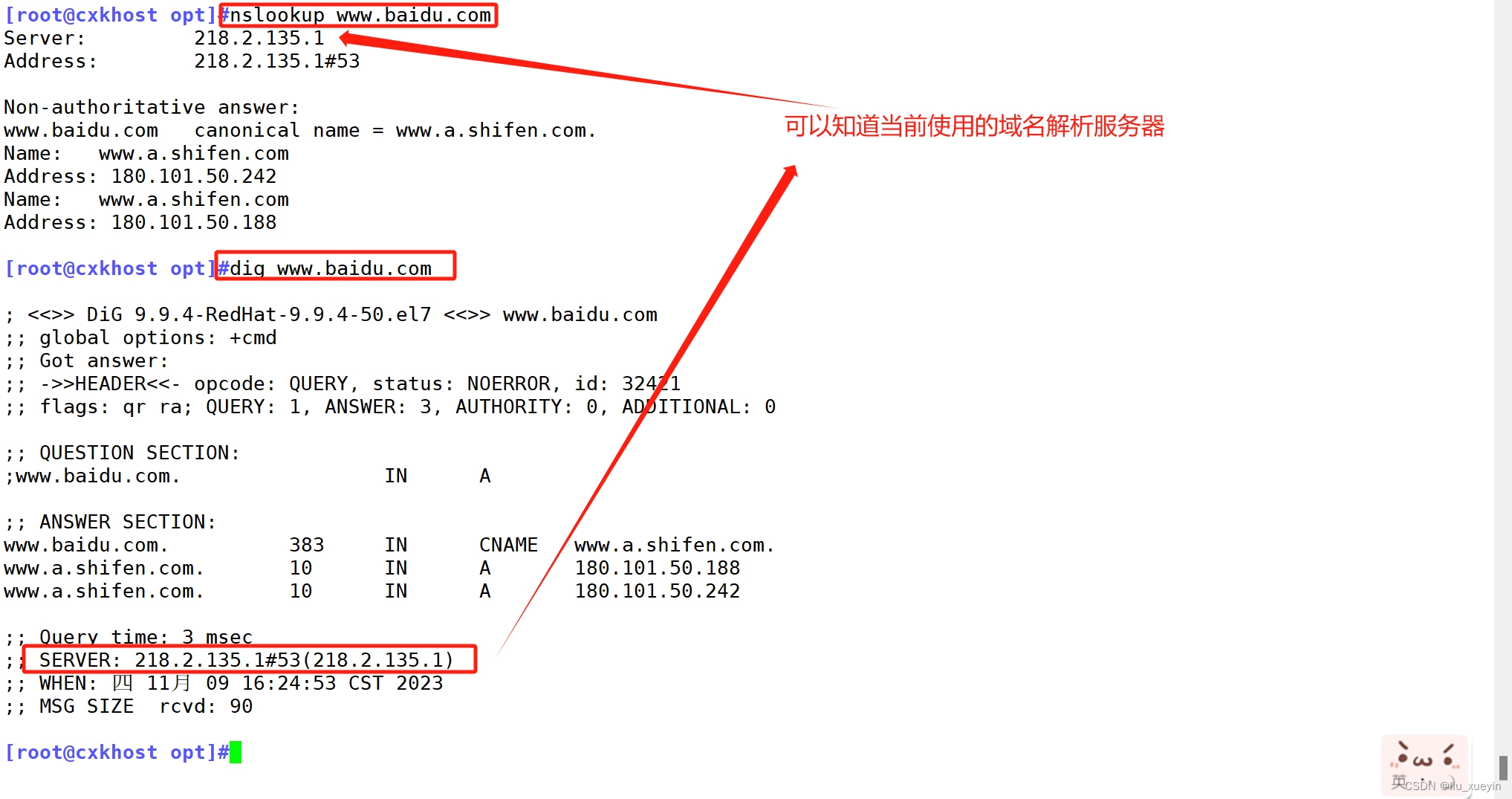
【Linux网络】网卡配置与修改主机名,做好基础系统配置
目录 一、网络配置命令 1、查看网卡信息ifconfig Linux永久修改ip地址 2、主机名修改 ①hostname 临时修改主机名 ②永久修改主机名 第一种,使用命令修改 第二种:修改配置文件 3、路由信息 再来拓展一下,永久修改路由表信息 4、检查…...
三大基础排序 -选择排序、冒泡排序、插入排序
排序算法 文章目录 冒泡排序算法步骤动图代码优化总结 选择排序算法步骤动图代码总结 插入排序算法步骤动图代码总结 排序算法,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。一般默认排序是按照由小到大即…...
)
ESP32 BLE实战:5分钟搞定自定义GATT服务端(附完整代码解析)
ESP32 BLE实战:5分钟搞定自定义GATT服务端(附完整代码解析) 在智能手环、医疗设备等物联网应用中,BLE(低功耗蓝牙)技术因其低功耗特性成为首选通信方案。本文将带你快速实现一个带心率监测功能的BLE服务端&…...
)
用STM32G431玩超级玛丽!CubeMX+HAL库移植NES模拟器保姆级教程(附蓝桥杯板子适配)
用STM32G431玩超级玛丽!CubeMXHAL库移植NES模拟器保姆级教程(附蓝桥杯板子适配) 还记得小时候抱着红白机玩《超级玛丽》的快乐吗?现在,你可以亲手把这份童年回忆"塞进"一块STM32开发板里。本文将带你用STM32…...

Webviz性能优化:5个关键技巧提升渲染速度300%
Webviz性能优化:5个关键技巧提升渲染速度300% 【免费下载链接】webviz web-based visualization libraries 项目地址: https://gitcode.com/gh_mirrors/we/webviz Webviz作为一款强大的web-based visualization库,在处理大规模3D场景和实时数据可…...

从零到一:手把手教你用Doris搭建实时用户行为分析平台
从零到一:手把手教你用Doris搭建实时用户行为分析平台 在数字化运营时代,用户行为数据已成为企业决策的黄金矿藏。想象一下:当用户在你的电商平台完成一次点击后,30秒内就能在仪表盘看到这个行为对转化率的影响;当凌晨…...

数据安全优先:企业级智能体私有化部署完整方案与最佳实践
摘要: 站在2026年4月的技术节点回望,企业级智能体(AI Agent)已完成从“对话助手”到“数字员工”的代际跨越。然而,在规模化落地过程中,数据主权与复杂系统的非侵入式集成成为架构师面临的首要挑战。本文从…...

别再只用周长面积比了!PostGIS + JTS 实战:精准揪出矢量图斑里的‘细脖子’
突破传统局限:PostGIS与JTS联合实现矢量图斑狭长结构精准检测 在地理信息系统(GIS)数据处理领域,矢量图斑的质量控制一直是测绘和遥感应用中的关键环节。特别是在地图符号化过程中,那些"细脖子"般的局部狭长…...

Qt网络编程避坑指南:从QAbstractSocket的error和stateChanged信号说起
Qt网络编程实战:QAbstractSocket信号机制与错误处理精要 在跨平台应用开发领域,Qt的网络模块因其优雅的抽象和强大的功能而备受推崇。但当真正投入生产环境时,开发者往往会遇到各种棘手的网络异常——连接意外断开、主机不可达、SSL握手失败…...

如何快速安装APA第7版格式:面向Word用户的完整指南
如何快速安装APA第7版格式:面向Word用户的完整指南 【免费下载链接】APA-7th-Edition Microsoft Word XSD for generating APA 7th edition references 项目地址: https://gitcode.com/gh_mirrors/ap/APA-7th-Edition 还在为学术论文的参考文献格式问题而烦恼…...

TTS-Vue离线语音合成终极配置方案:从零搭建到高效应用
TTS-Vue离线语音合成终极配置方案:从零搭建到高效应用 【免费下载链接】tts-vue 🎤 微软语音合成工具,使用 Electron Vue ElementPlus Vite 构建。 项目地址: https://gitcode.com/gh_mirrors/tt/tts-vue TTS-Vue是一款基于微软语音…...

Qwen3-4B-Thinking效果展示:编程题自动解题+错误定位+修复建议
Qwen3-4B-Thinking效果展示:编程题自动解题错误定位修复建议 1. 模型概述 Qwen3-4B-Thinking-2507-Gemini-2.5-Flash-Distill是基于通义千问Qwen3-4B官方模型的改进版本,专门针对编程问题解决场景进行了优化。这个模型最显著的特点是能够展示完整的思考…...