stable diffusion为什么能用于文本到图像的生成

推荐基于稳定扩散(stable diffusion) AI 模型开发的自动纹理工具: DreamTexture.js自动纹理化开发包 - NSDT
稳定扩散获得如此多关注的原因
如果你还没有看过它:稳定扩散是一个文本到图像的生成模型,你可以输入一个文本提示,比如“一个人一半尤达一半甘道夫”,然后接收一个图像(512x512像素)作为输出,如下所示:

提示:一个人一半尤达一半甘道夫,幻想绘画在artstation上流行
结果看起来像 DALL-E 2 甚至更好,这本身已经很棒了,但它变得更好:它的计算效率非常高,可以在只需要大约 8-10GB 内存的消费级 GPU 卡上运行。它的训练效率也比过去的模型更高(唉,如果你不能使用很多GPU,它仍然太贵了)。
除了计算效率之外,结果看起来也很棒。事实上,正如上面引用的论文所解释的那样,它们在图像基准测试中达到了几个新的高分,例如图像修复和类条件图像合成。
最好的部分是:这是完全开源的。这包括代码、模型权重以及将其用于任何人的权利,目的是使任何人的创造力民主化。
关于它的名字 stable diffusion 的稳定部分是,名为 Stability 的赞助商提供了大量的 GPU 计算来将该模型训练到当前状态(在 512x512px 图像上进行了微调),然后将其开源。
深入了解:稳定扩散是如何工作的?
我非常喜欢分层学习,所以我们将从高级视图开始,然后深入研究各个部分。
高级视图
该系统分为三个部分:
- 一种语言模型,它将您输入的文本提示转换为一种表示形式,该表示形式可以馈送到扩散模型并通过交叉注意力机制使用。他们使用带有转换器的“现成”BERT 分词器来处理这部分,所以我不会更深入地介绍它。
- 扩散模型基本上是一个时间条件 U-Net(有关 U-Net 的详细信息,请查看此处),它采用一些高斯噪声和文本提示的表示作为输入,并对高斯噪声进行去噪以更接近您的文本表示。这重复了好几次,这就是为什么它被称为时间条件。
- 一种解码器,用于获取扩散模型的输出并将其放大为完整图像。扩散模型在 64x64px 上运行,解码器将其带到 512x512px。
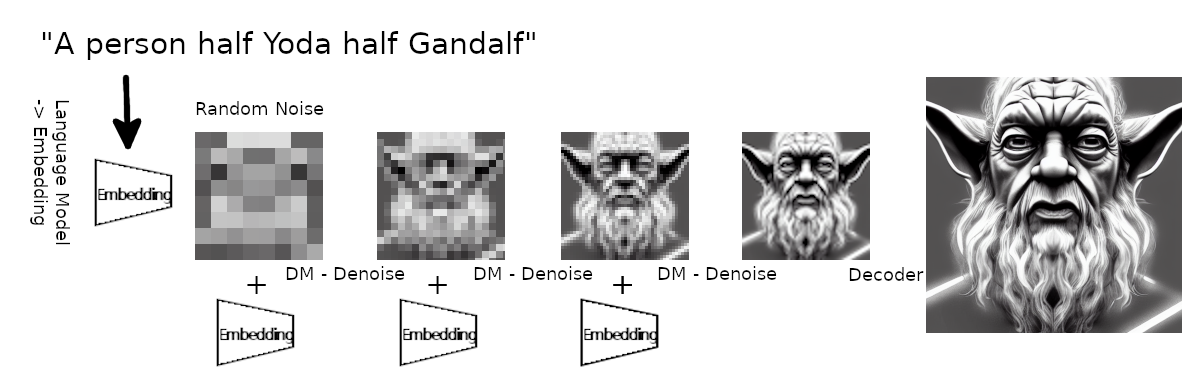
文本到图像生成的插图(由作者制作)。语言模型创建文本提示的嵌入。它与一些随机噪声一起输入扩散模型。扩散模型将其向嵌入方向去噪。这重复了几次。最后,解码器将图像放大到更大的尺寸。
扩散模型的高级视图
扩散模型的想法是拍摄图像并添加一点高斯噪声,从而获得略带噪点的图像。 然后重复该过程,因此在略微嘈杂的图像中,您再次添加一点高斯噪声以获得更嘈杂的图像。 重复此操作数次(最多 ~1000 次)以获得完全嘈杂的图像。
在这样做时,您知道每个步骤的原始图像(或略带噪点的图像)及其嘈杂的版本。
然后,你训练一个神经网络,该神经网络获取噪声较大的示例作为输入,并具有预测图像的降噪版本的任务。

扩散过程的图示(由作者制作):从左到右,您不断向图像添加高斯噪声。然后,模型从右到左学习以对其进行降噪。
在许多不同的步骤中,神经网络学习以重复的方式对非常嘈杂的图像进行降噪以获得原始图像。
高水平培训
在训练过程中,还存在一个编码器,它是上述解码器的对应部分。
编码器和解码器共同构成一个自动编码器。
编码器的目标是将输入图像转换为具有高度语义的下采样表示,但去除了与手头图像不太相关的高频视觉噪声。
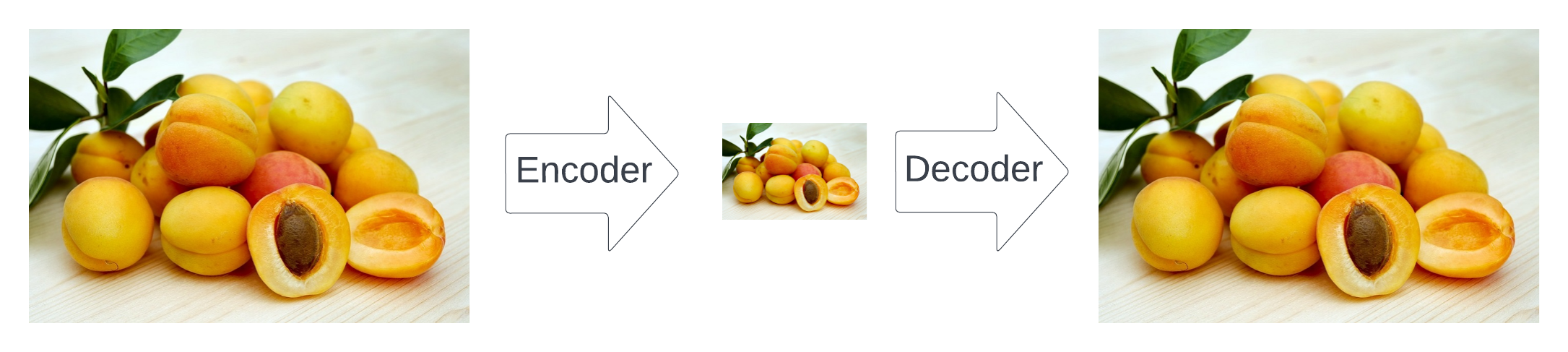
自动编码器的插图(由作者制作):编码器找到图像的更小的表示形式,但保留了语义含义。解码器以尽可能少的损失从有效表示中重新获得图像的原始版本。
这里的诀窍是,他们将编码与训练扩散模型解耦。这样,可以训练自动编码器以获得最佳图像表示,然后可以在下游的几个扩散模型上进行所谓的潜在表示(这只是以语义上有意义的方式表示的图像,但像素少 64 倍)。
这样一来,在像素空间上训练扩散模型时,在原始图像空间上的计算量需要比以前少 64 倍。这是完全相关的,因为正如我们稍后将看到的,扩散模型的训练和推理是最昂贵的部分。
因此,培训分两个阶段进行:
- 训练自动编码器,用于处理图像表示的压缩和解压缩
- 在自动编码器的编码器生成的潜在因素上训练扩散模型(这与文本表示/注意力部分相结合)
组件的详细视图
训练自动编码器
自动编码器的训练有两个损失:
- 像素空间上的感知损失
- 基于补丁的对抗性损失,可强制执行局部真实感并避免模糊
它通过一个因子对图像进行下采样,该因子已在论文中使用许多不同的值进行了测试,并且权衡了 OR 是好的。ff=4f=8
除了损耗之外,正则化还应用于自动编码器。这里可以使用两种不同的形式:
- Kullback-Leibler 惩罚,用于将学习到的潜伏子与过去潜伏子的标准正态对齐,以确保潜伏子的方差不会太高
- 解码器中的矢量量化层;这就像定义原型一样
N
有时他们使用KL惩罚,有时在训练不同的扩散模型时使用向量量化。对我来说,尚不完全清楚何时一个或另一个更好。 似乎对于文本到图像合成模型,使用了KL惩罚。
扩散模型的训练
考虑到使图像产生噪声或在逆过程中对其进行降噪的连续步骤数,这可以描述为马尔可夫链,因为每个时间步骤仅取决于直接后继者,而没有其他任何内容。

扩散模型的训练过程图示(由作者制作)。具有现有标题的图像用于训练。噪声在连续的时间步长中添加到编码图像中。文本标题由语言模型嵌入。扩散模型接收图像的噪声版本和文本嵌入,并需要预测图像的上一个时间步长。梯度下降用于预期图像与扩散模型预测之间的像素差。
为了训练它,幸运的是,你有可以有效地生成的前向步骤,所以你可以确切地知道给定图像在时间步长和时间步长上看起来如何。NN+1
然后,将时间步长的图像传递到网络,并期望它返回时间步长的图像。对于损失,您考虑了网络预测与时间步长图像之间的像素差异。N+1NN
图像上的噪声越多,网络在不太相关的视觉特征上花费的就越多,因此通常在较早的时间步长比在较晚的时间步长采样的示例更多。
等等,但为什么这会产生所有这些创造性的艺术?!
所以,你们问自己的真正问题当然是:魔法从何而来?
正如我所描述的,它是一个复杂的系统,由三部分组成——自动编码器、文本嵌入的语言模型和潜在扩散模型。
所有这些部分都是在大量图像或图像/文本对上训练的,因此自动编码器和语言模型的嵌入非常复杂,涵盖了我们人类的大部分语义空间。然后,当通过新的文本提示将概念组合在一起时,这些概念会组合成一个涵盖这一点的嵌入。潜在扩散模型本身经过训练,可以从噪声中发现图像,但受这种嵌入的引导,因此它将创造性的嵌入概念推向图像表示。最后,解码器有助于将潜在表示带入更放大和人类可见的版本(并且它还在数百万张图像上进行了训练!
我认为魔力在于在培训期间学到的概念的重叠/可组合性。例如,有些图像是半男半女或类似的东西,所以学习了一半/一半的概念。许多其他图像都包含《星球大战》/尤达的部分内容,因此学习了尤达的概念。然后其他图像了解了甘道夫。当最终将所有这些组合到一个提示中时,系统会尝试将所有这些知识集成到最有可能看起来像这样的图像中。因此,创建了本文中的图像。
总结
意识到要加速扩散模型,您应该减少像素空间,因为它被反复使用(在马尔可夫链方法中),因此变得昂贵,这是向前迈出的一大步。事实上,它不仅减少了像素空间,而且通过预先的自动编码器学习了良好的表示/嵌入,它仍然具有所有语义和语义的视觉表示。
以单独的方式进行,以便单独训练自动编码器,从而可以灵活地训练多个不同的扩散模型,这些模型针对特殊任务进行了调整。
将其与交叉注意力步骤中的其他输入相结合,对于实现快速且具有视觉吸引力的文本到图像生成模型的惊人效果至关重要。
但是,除了使用文本提示之外,还可以使用其他输入/嵌入。例如,作者展示了如何使用粗略的分割草图,然后通过模型将其转换为美丽的图像,以及更多诸如从图像中删除人物之类的东西(想想Photoshop魔杖超级高级工具):

摘自论文的图 22:从图像中去除物体的潜在扩散模型。
希望这篇关于稳定扩散的博客文章能让你对所使用的概念有一个很好的概述。
转载:stable diffusion为什么能用于文本到图像的生成 (mvrlink.com)
相关文章:
stable diffusion为什么能用于文本到图像的生成
推荐基于稳定扩散(stable diffusion) AI 模型开发的自动纹理工具: DreamTexture.js自动纹理化开发包 - NSDT 稳定扩散获得如此多关注的原因 如果你还没有看过它:稳定扩散是一个文本到图像的生成模型,你可以输入一个文本提示,比如…...
c语言刷题第10周(16~20)
规律: 若多个次数最多按ASCII码顺序输出。 用for循环i取(0~26) 则输出满足条件的字符串中位置最靠前的那个。 用while循环遍历(while(a[i]!\0)) 从键盘输入任意只含有大小写字母的串s&…...

Vue.js 响应式系统深度剖析
Vue.js 是当前最流行的 JavaScript 前端框架之一,其核心特性之一就是响应式系统。Vue.js 响应式系统的设计允许开发者以声明式的方式更新 DOM,随着数据变化自动更新相关组件。本文将详细介绍 Vue.js 响应式系统的工作原理,并通过示例来展示其…...
LabVIEW如何才能得到共享变量的引用
LabVIEW如何才能得到共享变量的引用 有一个LabVIEW 库文件 (.lvlib) ,其中有一些定义好的共享变量。但需要得到每个共享变量的引用以便在程序运行时访问其属性。 共享变量的属性定义在“变量”类属性节点中。为了访问变量类,共享变量的引用必须连接到变…...
界面控件DevExtreme图表和仪表(v23.1) - 新功能(Angular,React,Vue,jQuery)
本文将为大家总结下DevExtreme在v23.1版本中发布的一些与图表和仪表盘相关的功能。 DevExtreme拥有高性能的HTML5 / JavaScript小部件集合,使您可以利用现代Web开发堆栈(包括React,Angular,ASP.NET Core,jQuery&#…...

Rust和isahc库编写代码示例
Rust和isahc库编写的图像爬虫程序的代码: rust use isahc::{Client, Response}; fn main() { let client Client::new() .with_proxy("") .finish(); let url ""; let response client.get(url) .send() …...
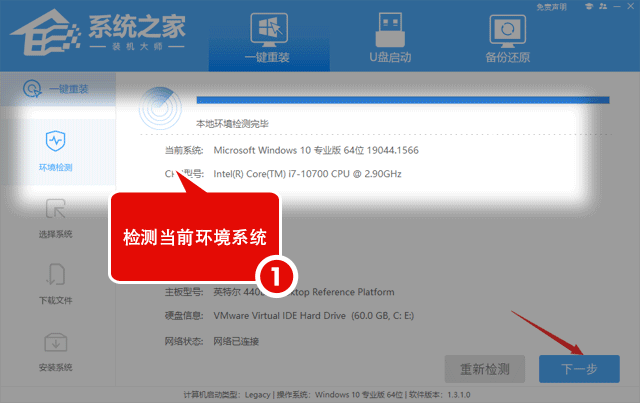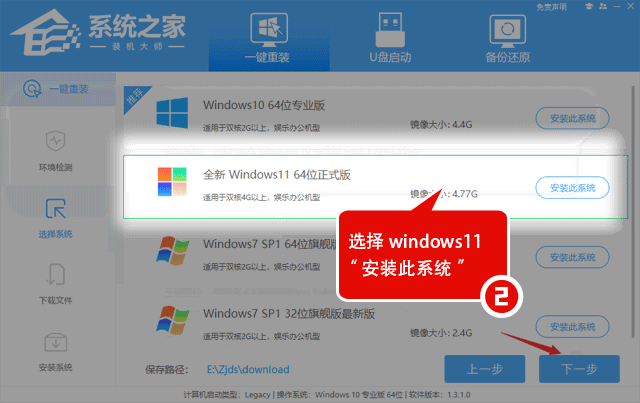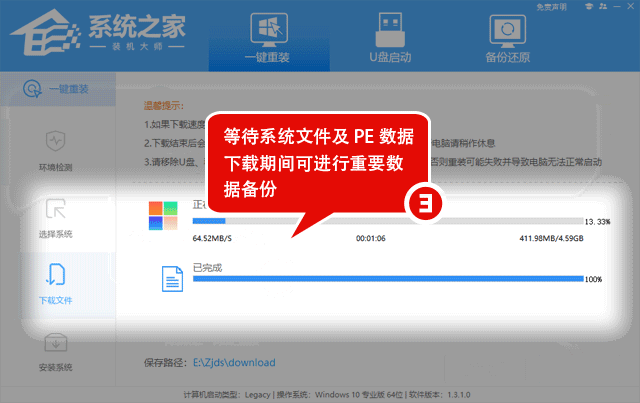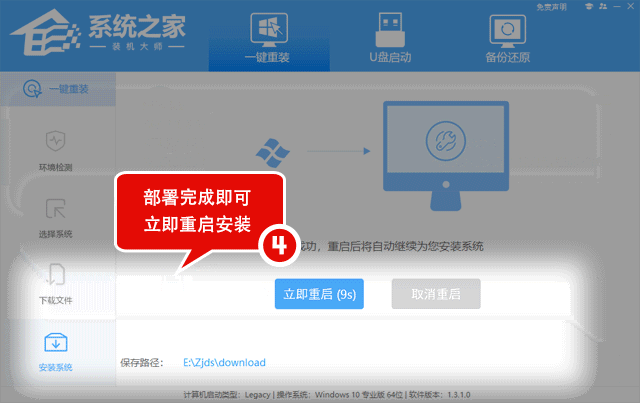
Win10笔记本开热点后电脑断网的解决方法
在Win10笔记本电脑中用户可以随时打开热点,但是发现热点开启后电脑就会断网,网络不稳定就会影响到用户的正常使用。下面小编给大家介绍两种简单的解决方法,解决后用户在Win10笔记本电脑开热点就不会有断网的问题出现了。 具体解决方法如下&am…...
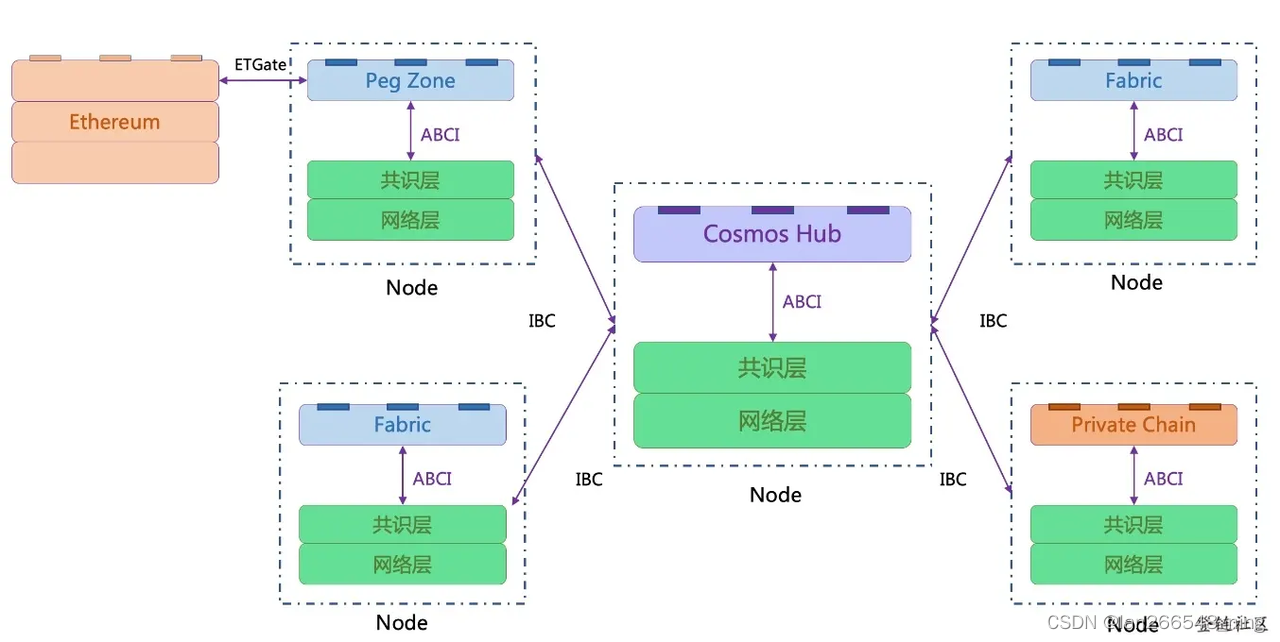
跨链知识指南
跨链知识指南 什么是跨链 跨链就是能够让两个不同的链产生某种关联的技术,或者说能把链A的东西搬到链B,跨链是一个复杂的过程,需要链对链外的信息的获取与验证,需要节点有单独的验证能力等等 什么是跨链桥? 跨链桥…...
字符编码转换时发生内存越界引发的摄像头切换失败问题的排查
目录 1、问题说明 2、初步分析 3、字符串字符编码说明 4、进一步分析 5、为啥在日常测试时没有遇到切换摄像头失败的问题呢? 6、华为MateBook笔记本使用高通的CPU 7、最后 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更…...

git修改之前的commit提交的作者信息和邮箱信息
更改之前提交的作者信息和邮箱信息需要进行两步操作。首先,使用 git filter-branch 命令进行历史重写,然后使用 git push --force 将更改推送到远程仓库。 步骤 1: 使用 git filter-branch 进行历史重写 在终端或命令行中执行以下命令: gi…...
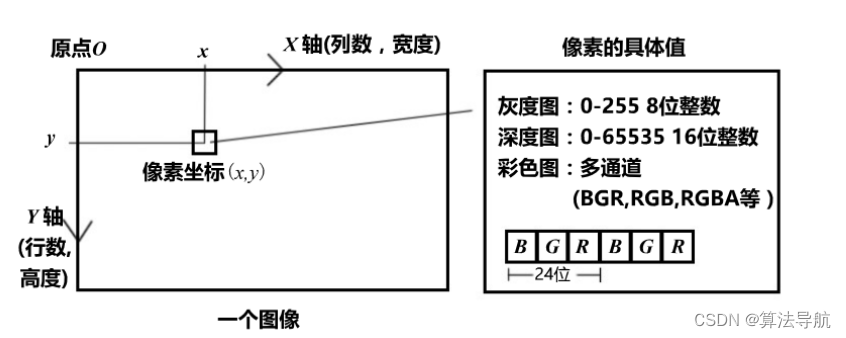
《视觉SLAM十四讲》-- 相机与图像
04 相机与图像 4.1 相机模型 4.1.1 针孔相机模型 针孔模型描述了一束光线通过针孔后,在针孔背面投影成像的关系(类似小孔成像原理)。 根据相似三角关系 Z f − X X ′ − Y Y ′ (3-1) \frac{Z}{f}-\frac{X}{X^{\prime}}-\frac{Y}{Y^{\p…...

欧科云链:成本与规模之辨——合规科技如何赋能香港Web3生态?
作为国际金融中心,香港近两年来在虚拟资产及Web3领域频频发力。秉持着“稳步创新”的基本逻辑,香港在虚拟资产与Web3领域已建立一定优势,但近期各类风险事件的发生则让业界的关注焦点再次转向“安全”与“合规”。 在香港FinTech Week前夕&a…...

【文献分享】NASA JPL团队CoSTAR一大力作:直接激光雷达里程计:利用密集点云快速定位
论文题目:Direct LiDAR Odometry: Fast Localization With Dense Point Clouds 中文题目:直接激光雷达里程计:利用密集点云快速定位 作者:Kenny Chen, Brett T.Lopez, Ali-akbar Agha-mohammadi 论文链接:https://arxiv.org/pd…...
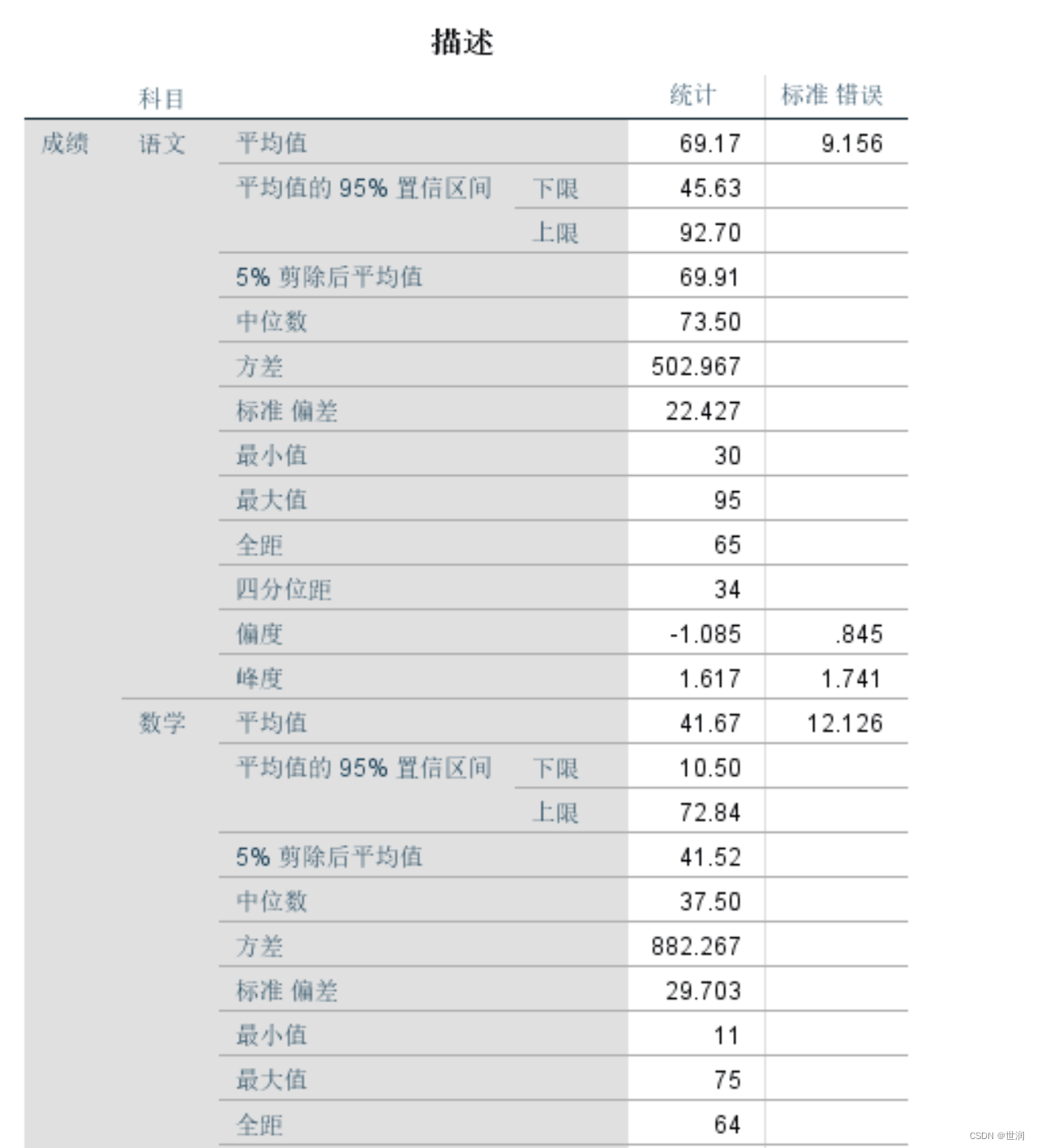
SPASS-探索性分析
探索性分析的意义 探索性分析更加强大,它是一种在对资料的性质、分布特点等完全不清楚的情况下,对变量进行更深入研究的描述性统计方法。在进行统计分析前,通常需要寻求和确定适合所研究的问题的统计方法, SPSS提供的探索性分析是解决此类问题的有效办法 探索性分析提供了很…...

电子印章怎么弄?三步教你电子印章在线生成免费教程!
在这个数字化快速发展的时代,电子印章已经成为日常商务活动中不可或缺的一部分。相对于传统的实体印章,电子印章具有更高的便捷性和安全性,更是无纸化办公中必不可少的一环。那么,电子印章怎么弄呢?跟着下面这三步来操…...

以技术创新引领行业发展,飞凌嵌入式获双项省级荣誉
近日,飞凌嵌入式荣获「2023年河北省专精特新示范企业」以及「第五批省级制造业单项冠军企业」两项殊荣。这两项荣誉的获得,是对飞凌嵌入式在专业技术领域与创新能力的高度认可,荣誉的背后,凝聚着飞凌嵌入式无数次的研发探索与对创…...

在Google Kubernetes集群创建分布式Jenkins(二)
上一篇博客在Google Kubernetes集群创建分布式Jenkins(一)-CSDN博客我介绍了如何在GCP的K8S集群上部署一个分布式的Jenkins,并实现了一个简单的Pipeline的运行。 在实际的开发中,我们通常都会按照以下的CICD流程来设置Pipeline 在我司的实际实践中&…...

GEE:GEE中调用 Math.js 教程
作者:CSDN @ _养乐多_ Math.js 是一个强大的 JavaScript 数学库,它提供了大量用于数学计算的函数和工具。这个库可用于解决各种数学问题,从基本的算术运算到高级数学和线性代数等领域。本文将介绍在 Google Earth Engine(GEE)云平台中调用 Math.js 第三方库做一些事情的方…...
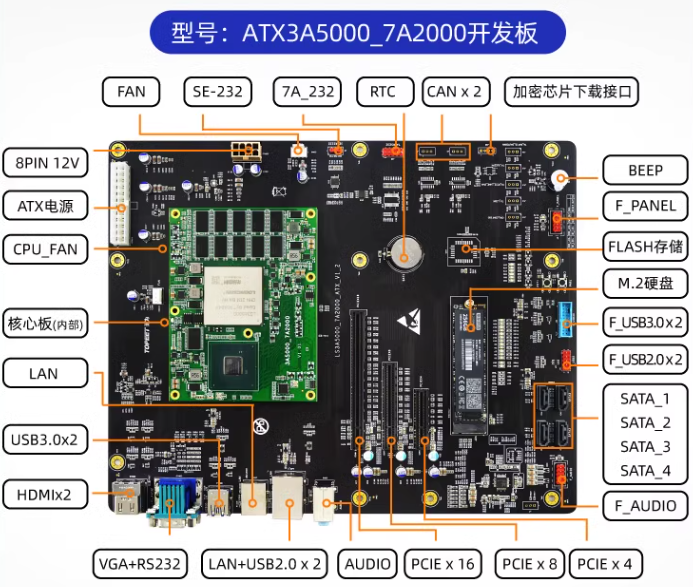
迅为龙芯3A5000主板,支持PCIE 3.0、USB 3.0和 SATA 3.0显示接口2 路、HDMI 和1路 VGA,可直连显示器
性能强 采用全国产龙芯3A5000处理器,基于龙芯自主指令系统 (LoongArch)的LA464微结构,并进一步提升频率,降低功耗,优化性能。 桥片 桥片采用龙芯 7A2000,支持PCIE 3.0、USB 3.0和 SATA 3.0显示接口2 路、HDMI 和1路 …...
Opencv for unity 下载
GitHub - EnoxSoftware/VideoPlayerWithOpenCVForUnityExample: This example shows how to convert VideoPlayer texture to OpenCV Mat using AsyncGPUReadback. OpenCV for Unity | Integration | Unity Asset Store...

Fan Control:Windows系统风扇控制软件全解析,轻松实现精准散热管理
Fan Control:Windows系统风扇控制软件全解析,轻松实现精准散热管理 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...

3PEAK思瑞浦 TPA8003-SOAR WSOP8 隔离式放大器
特性 CMTI:100 kV/us 输入电压范围:2.2V 固定增益:1 低偏移误差:25C时最大为1.5mV 极低增益误差:25C时最大0.3% 宽温度范围:-40C至125C TPA800x-SOAR-S 已通过AEC-Q100可靠性测试,适用于汽车应用 已完成的安全相关认证: -符合UL1577标准的5000-VRMS隔离等级 -CQC认证…...

终极Photoshop AI插件SD-PPP完整指南:如何让AI绘图与设计完美融合
终极Photoshop AI插件SD-PPP完整指南:如何让AI绘图与设计完美融合 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP是一款革命性的Photoshop AI插件,它彻底改变了设计师与AI协作的工作…...

告别内存焦虑!ESP32+LVGL加载PNG图片的实战优化与内存管理技巧
ESP32LVGL深度优化:PNG图片加载与内存管理的实战艺术 在物联网设备的图形界面开发中,ESP32搭配LVGL已成为许多开发者的首选方案。但当涉及到PNG图片加载时,内存限制往往成为最棘手的瓶颈。我曾在一个智能家居面板项目中被这个问题困扰数周——…...

实战踩坑记录:从生成SM2私钥到吉大正元下载双证书的全流程解析
SM2双证书申请全流程实战指南:从密钥生成到吉大正元系统对接 第一次在吉大正元系统上申请SM2双证书时,我盯着屏幕上那个格式错误的P10文件提示,意识到国密证书的申请流程远比想象中复杂。这不是简单的RSA证书申请流程换套算法就能解决的问题—…...
)
保姆级教程:用IDEA和VSCode搞定RuoYi-Vue 3.7.0的War包部署(含JDK1.8+MySQL5.7环境)
从零构建RuoYi-Vue 3.7.0生产环境:IDE高效部署实战手册 在前后端分离架构成为主流的今天,RuoYi-Vue作为基于Spring BootVue的快速开发框架,凭借其丰富的功能模块和清晰的代码结构,已成为企业级应用开发的热门选择。但许多开发者在…...
)
保姆级教程:在Ubuntu 22.04上源码编译安装Wine 7.x(附常见编译错误解决)
从零构建:Ubuntu 22.04源码编译Wine 7.x全流程与深度调优指南 在Linux生态中运行Windows应用的需求从未消退,而Wine作为这一领域的核心技术,其源码编译方式能为开发者带来最新特性支持与深度定制能力。不同于简单的包管理器安装,手…...

【5G Modem】从协议栈到天线阵列:揭秘5G Modem的完整架构与协同设计
1. 5G Modem的架构全景图 当你用手机刷视频、打游戏时,背后有个"隐形交通指挥官"在默默工作——它就是5G Modem。这个比硬币还小的芯片,内部却像一座精密的现代城市:协议栈是交通法规,基带处理器是调度中心,…...

别再手动改配置了!用FRP v0.61.0的Web仪表盘,图形化搞定内网穿透
FRP v0.61.0 Web仪表盘:可视化内网穿透管理新体验 每次修改配置文件都要重启服务?还在用命令行查看连接状态?FRP v0.61.0的Web仪表盘功能将彻底改变你的内网穿透管理方式。这个被许多用户忽略的"隐藏功能",实际上能大幅…...

WanVideo_Cofy:AI 驱动的开源专业级视频生成平台全解析
一、平台简介 WanVideo_Cofy(全称 WanVideo ComfyUI,常简称为 WanVideo_Cofy)是基于阿里云通义万相 Wan 2 系列视频生成模型(核心为 Wan 2.2)深度定制、依托 ComfyUI 可视化节点编辑器打造的开源 AI 视频生成一体化解…...