Elastic Stack 8.11:引入一种新的强大查询语言 ES|QL
作者:Tyler Perkins, Ninoslav Miskovic, Gilad Gal, Teresa Soler, Shani Sagiv, Jason Burns

Elastic® Stack 8.11 引入了数据流生命周期、一种配置数据流保留和降采样(downsampling) 的简单方法(技术预览版),以及有关 Kibana® Inspector 中跨集群搜索响应的详细信息以及重新路由摄取处理器(reroute ingest processor)的正式发布。
这些新功能使客户能够:
- 直接在数据流中管理数据流保留,无需 ILM 策略
- 查看有关远程搜索的更多信息,以便他们可以对任何潜在问题进行分类
- 根据字段中的值将文档路由到正确的索引
Elastic Stack 8.11 现已在 Elastic Cloud 上推出,这是唯一包含最新版本中所有新功能的托管 Elasticsearch® 产品。 你还可以下载 Elastic Stack 和我们的云编排产品 Elastic Cloud Enterprise 和 Elastic Cloud for Kubernetes,以获得自我管理的体验。
Elastic 8.11 中还有哪些新功能? 查看 8.11公告帖子了解更多>>
Discover 中的 ES|QL:直接从 Discover 中通过聚合和可视化缩短获得见解的时间
在 8.11 中,我们引入了 Elasticsearch 查询语言 (ES|QL),这是 Elastic 用于数据探索和调查的新管道语言。 ES|QL 转变、丰富并简化了你的数据探索过程。
以下是你可以期待的:
- 轻松开始:要开始在 Discover 中使用 ES|QL,只需从数据视图选择器中选择 “Try ES|QL”。 它用户友好且简单。
- 高效、简单的查询构建:Discover 中的 ES|QL 提供自动完成和 in-app 文档,使你可以轻松地从查询栏创建强大的查询。
- 全面而强大的数据探索:在 Discover 中进行临时数据探索。 直接从查询生成器创建聚合、转换数据、丰富数据集等。 结果以表格格式或可视化形式呈现; 这取决于你正在执行的查询。
- 上下文可视化:在 Discover 中编写 ES|QL 查询时,你将收到由 Lens 建议引擎提供支持的视觉表示。 你的查询的性质决定了你获得的可视化类型(例如,指标、直方图热图)。
- 丰富:使用丰富命令使用另一个数据集中的字段来增强查询数据集,并为所选策略提供上下文建议(即提示匹配字段和丰富列)。
- 内联可视化编辑:直接在 Discover 和仪表板中编辑 ES|QL 可视化。 无需导航到 Lens 即可进行快速编辑; 你可以无缝地进行更改。
- 仪表板集成:一旦你对结果感到满意,就可以直接从 Discover 将 ES|QL 可视化保存到仪表板。
- 警报:使用 ES|QL 进行可观察性和安全警报,将聚合值设置为阈值。 通过强调有意义的趋势而非孤立事件,减少误报,提高检测准确性并接收可操作的通知。
Discover 中的 ES|QL 为你的数据调查带来效率和力量,简化你获得见解的路径。

具有可观察性用例的 ES|QL 查询示例:
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), avg_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10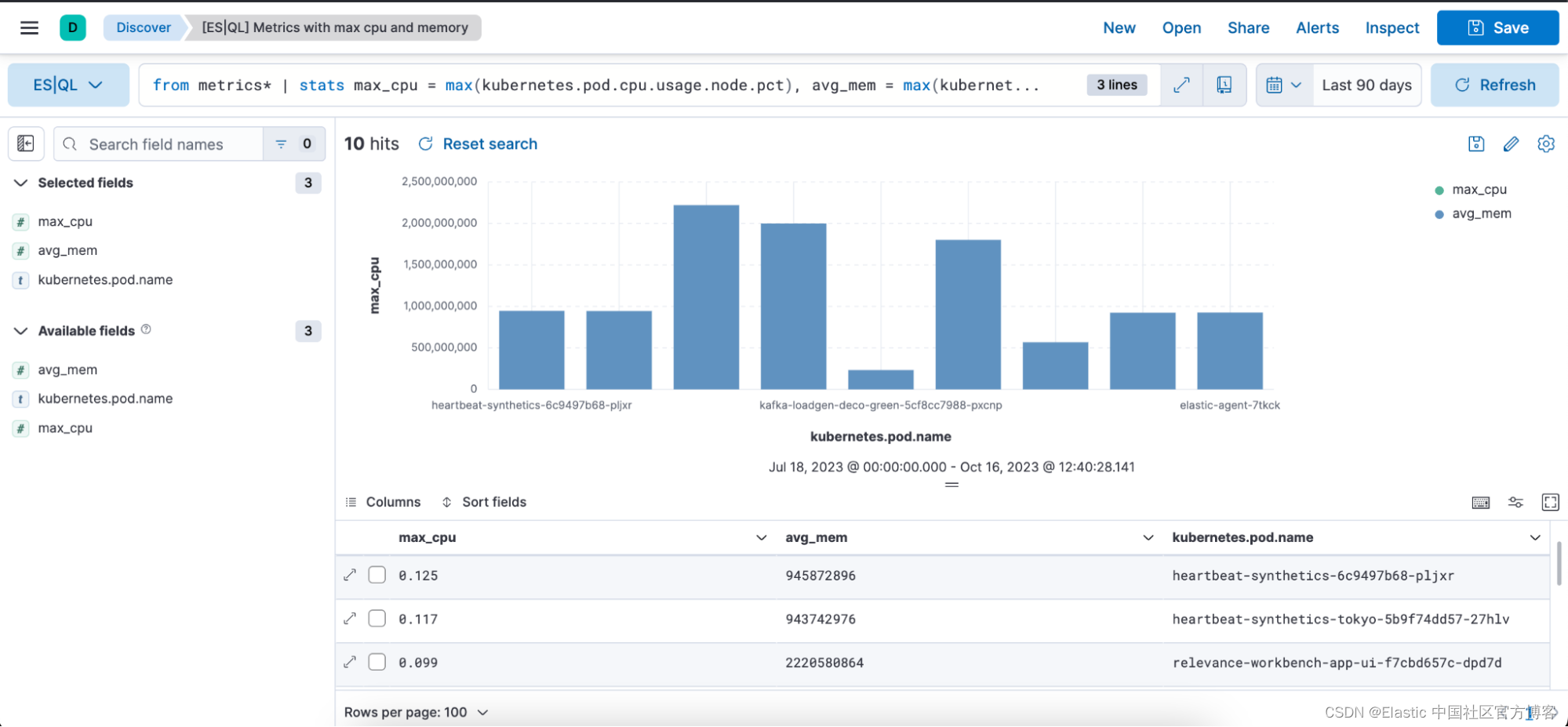
具有可观察性用例并使用 GROK 的 ES|QL 查询示例:
from logstash-* |
limit 100 |
keep @message |
grok @message """%{IPORHOST:source.address} (?:-|%{HTTPDUSER:apache.access.user.identity}) (?:-|%{HTTPDUSER:user.name}) \[%{TIMESTAMP_ISO8601:timestamp}\] "(?:%{WORD:http.request.method} %{NOTSPACE:url.original}(?: HTTP/%{NUMBER:http.version})?|%{DATA})" (?:-|%{INT:http.response.status_code:int}) (?:-|%{INT:http.response.body.bytes:int}) "(?:-|%{DATA:http.request.referrer})" "(?:-|%{DATA:user_agent.original})""""
| keep @message, source.address, timestamp, http.response.body.bytes, url.original
| stats max_bytes = max(http.response.body.bytes) by source.address
|sort max_bytes desc
| limit 20ES|QL 演示
在文档中了解有关 ES|QL 功能的更多信息。
新的 ES|QL 规则类型
现在,现有 Elasticsearch 规则类型下提供了新的 ES|QL 警报规则类型。 此规则类型将新的强大语言(ES|QL)中可用的所有新功能引入 Kibana Alerting,以允许和解锁新的警报用例。
使用新类型,用户将能够根据定义的 ES|QL 查询生成单个警报,并在保存规则之前预览查询结果。 当查询返回空结果时,不会生成警报。
创建和管理 ES|QL 丰富索引策略
为了支持我们新的 ES|QL 功能,我们在索引管理体验中添加了丰富策略(enrich policies)。 用户现在可以从这里创建他们的丰富策略并立即开始使用它。 配置完成后,所有丰富策略都可在 “Enrich Policies” 选项卡中使用。 可以直接从 Index Management 中的 Enrich Policies 选项卡管理现有策略。
使用 ENRICH 丰富策略的 ES|QL 查询示例:
from projects* |limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost descUI 中显示的丰富策略示例:



改进的 ELSER 模型现已正式发布
在 8.8 中,我们在技术预览版中引入了 Elastic Learned Sparse EncodeR。 ELSER 是 Elastic 用于人工智能搜索的文本扩展语言模型。 它提供开箱即用的卓越相关性(即无需对域内数据进行再训练或任何其他 ML 或 MLOps 工作)。 只需从 Elastic 的 UI 中点击几下即可部署它,然后开始在搜索中利用 AI 的力量。
在 8.11 中,我们发布了普遍可用的第二个版本:ELSER model-2 有两个版本:
- 优化后的模型,运行在 linux-x86_64 平台上
- 跨平台模型
根据 BEIR 基准进行衡量,与原始 ELSER 版本相比,两个 ELSER model-2 版本(平台优化和跨平台)都显示出更高的相关性。 重要的是,优化版本还显示出显着提高的性能,因为它减少了推理延迟。 Elastic Cloud 支持优化版本,因此 Elastic Cloud 用户将受益于优化后的 ELSER model-2 性能的大幅提升。

请注意,ELSER 的原始版本(8.11 之前可用的模型)将保留在技术预览版中。
机器学习推理 API
我们正在努力引入一个统一的推理 API,该 API 可以抽象化在针对不同任务训练的不同模型上执行推理的复杂性。 该 API 引入了一种简单、直观的语法,格式如下:
POST /_inference/<task_type>/<model_id>在 8.11 中,我们将发布该框架的第一个 MVP 迭代。 该 MVP 处于技术预览阶段,最初仅支持 ELSER。 这极大地简化了创建推理管道的语法。
更重要的是,未来新的推理 API 将支持内部和外部模型,并将与 LLM 生态系统集成,让我们的用户通过统一、不言自明的 API,轻松、无缝地拥有最强大的 AI。
仪表板中的 Lens 内联编辑
现在, 你可以在不离开仪表板的情况下编辑 Lens 可视化,而无需来回导航到 Lens 编辑器。 仪表板中将打开一个弹出窗口,你可以在其中对 Lens 面板进行任何编辑。 这种新的编辑体验更加方便,并且可以节省你的时间,因为保存更改时不需要重新加载仪表板。
Kibana 的 Lens 内联编辑
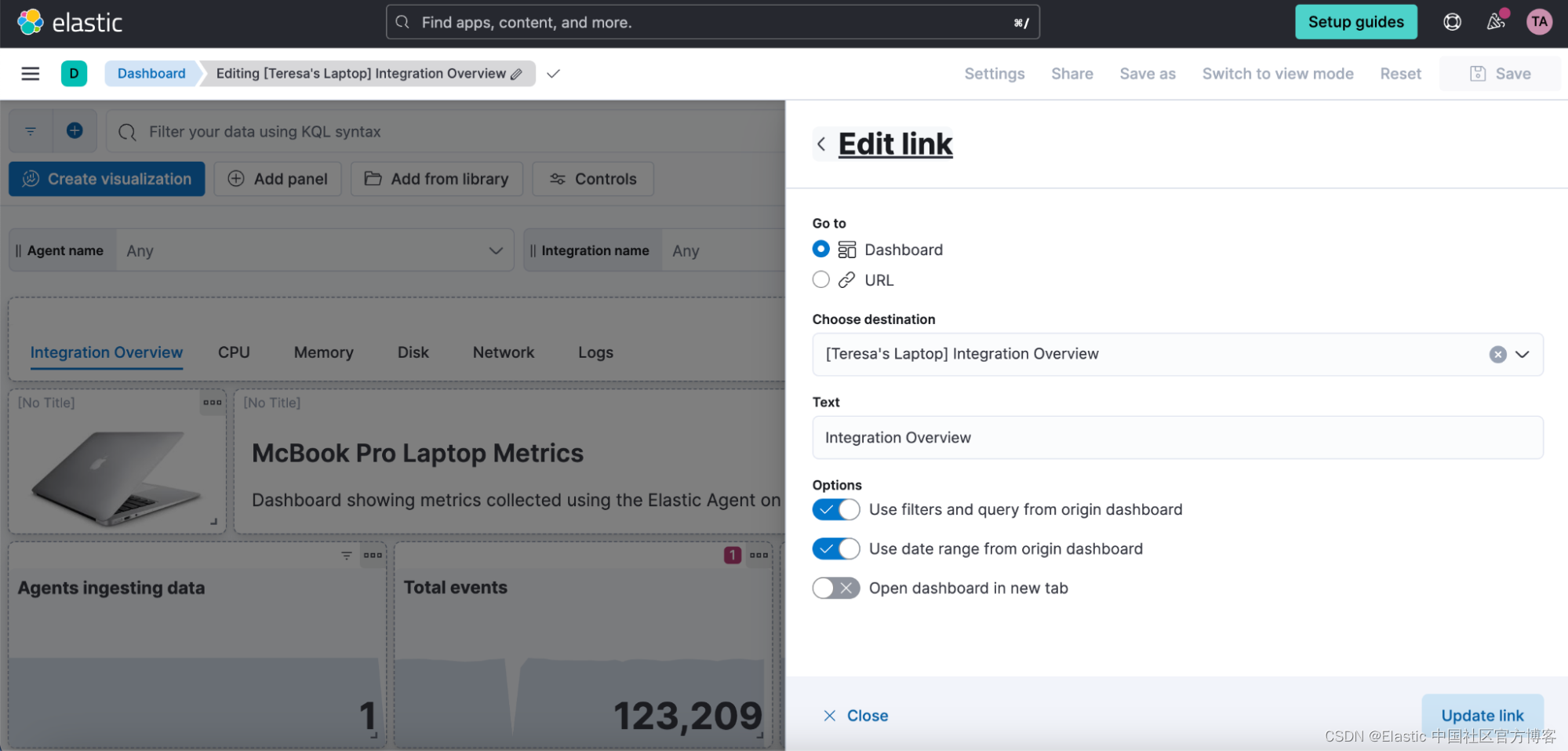
链接面板
现在,你可以使用链接面板轻松从一个仪表板导航到另一个仪表板。 通过将仪表板分成多个可视化较少的仪表板并将它们链接在一起,可以更好地组织仪表板并提高其性能。 导航到其他仪表板时,你可以继承过滤器、查询和时间范围。 水平或垂直显示链接,因为它更适合你的仪表板布局。
你还可以使用链接面板在仪表板中包含外部链接(例如,指向你的 wiki 页面或其他应用程序)。 决定是要在同一浏览器选项卡中还是在新选项卡中打开链接。
Kibana 中的链接面板 - links panel

引入颜色映射以增强数据可视化

我们很高兴地宣布我们最新的 Kibana 功能,它为你的数据可视化体验带来了显着的好处。 颜色与位置和形状一样是基本的视觉元素,在有效传达信息方面发挥着至关重要的作用。
以下是我们的新功能:
- 轻松分类:轻松将一个或多个字段类别分配给特定颜色。 这使得组织和理解数据变得比以往更加简单。
- 引导颜色选择:我们直观的颜色选择器为你提供预定义的调色板,确保你的图表不仅看起来很棒,而且与不同的 Kibana 主题无缝匹配。
- 增强的调色板:我们重新引入了清晰的调色板概念,使你可以更轻松地选择和应用渐变,从而提高可视化的整体美感。
无论你使用的是笛卡尔图表、分区图表还是标签云图表,这些增强功能都旨在帮助你充分利用数据。 借助此功能,你可以提高对图表上的数据点进行分类、区分和强调的能力,最终获得更好的见解和更具视觉吸引力的仪表板。
介绍数据流生命周期(技术预览)
要管理 Elastic 数据的生命周期,你可以使用索引生命周期管理,它提供了强大的功能来完全自定义数据层移动、翻转(rollover)、索引设置、降采样(downsampling) 等。 有很多可能性,也许比某些人需要的更多的可定制性。
我们一直致力于为数据流开发一个内置的简化且有弹性的生命周期实现,该实现现已在 8.11 中提供。 数据流生命周期的主要思想是简单:我们从一开始就将该功能设计为易于配置,因此我们从用户的关注中删除了尽可能多的实现细节,仅公开与你的需求相关的配置。 我们只会询问与你的用例和业务相关的问题:
- 在删除(保留)数据之前,我们应该将数据保留多长时间?
- 对于时间序列数据流,你是否希望随着时间的推移降低指标的粒度以降低存储成本(降采样)?
你可以在 Kibana 的 “Index Management” 页面的 “Data Stream” 下设置保留:

或者通过 _data_stream API:
PUT _data_stream/my-data-stream/_lifecycle
{"data_retention": "90d"
}配置生命周期后,我们将管理该数据流的其他所有内容。 如果你熟悉 ILM,这意味着我们正在处理翻转和强制合并。
没错:配置了生命周期的数据流将自动滚动并进行尾部合并(一种轻量级的强制合并实现,仅合并小段的长尾部而不是整个分片)。 通过自动处理分片和索引维护任务以确保最佳性能,并在索引和搜索之间进行权衡,你将能够专注于你关心的与业务相关的生命周期方面,例如数据保留和降采样。
数据流生命周期当前不管理跨层(热、冷、冻结)的数据移动。 需要数据分层的用例目前应继续使用 ILM。
数据流的此生命周期设置的实现经过非常仔细的设计,考虑了多年来支持 ILM 的经验教训。 ILM 使用有状态的基于步骤的执行,其中索引必须从一个步骤移动到下一个步骤。 有时需要进行干预,以找出 ILM 为何 “陷入困境”,并帮助迫使其逐步前进。 相反,数据流生命周期使用声明式执行方法,每次执行时都会评估索引的当前状态并执行所需的操作,以完成生命周期结束状态配置。
在 8.11 中,此功能处于技术预览版。
跨集群搜索响应信息触手可及
跨集群搜索 (CCS) 是跨多个集群统一数据的好方法,这些集群可以分布在世界各地和不同的环境中。 我们希望它尽可能频繁地提供完整的搜索结果,但也许某些远程集群的日子不好过。 只要有可能,我们仍然会返回部分结果,但是你怎么知道缺少什么,以及哪些集群有什么错误? 8.11 带来了额外的搜索响应计数信息,现在我们可以在 Kibana 的检查器中轻松找到它。
每个具有未 100% 返回没有问题的搜索的可视化都会有一条警告,该警告也直接链接到检查器的 “Clusters and shards” 选项卡。

在那里你可以看到所有远程集群(和本地集群)的列表、它们的搜索状态和响应时间。 展开集群以查看更详细的信息(例如,成功搜索到了多少分片)。
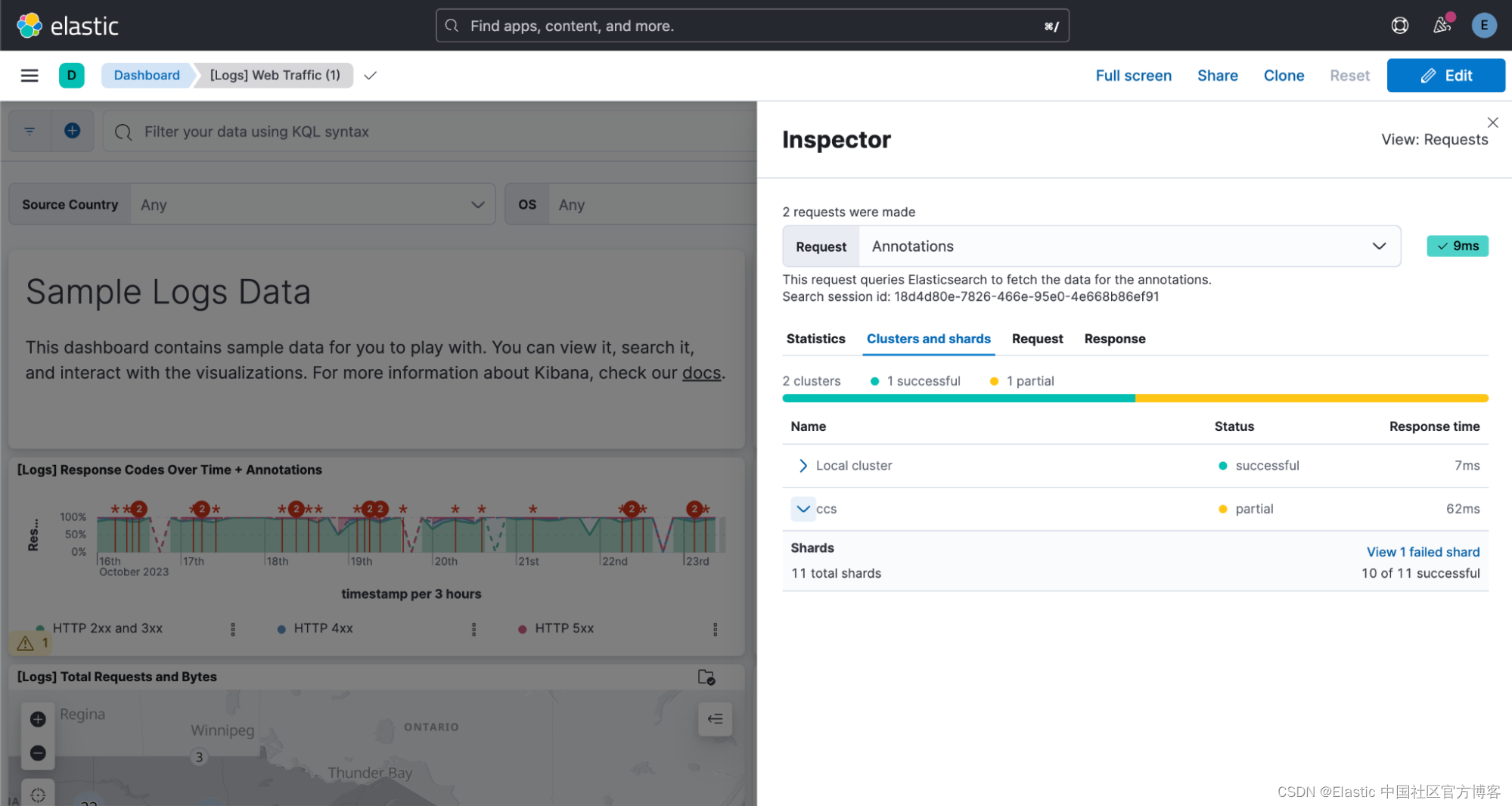
如果你想更深入地了解发生的情况,请单击 “Shards” 部分中的链接以查看分片故障详细信息:

你还可以从每个可视化一角的面板菜单访问检查器:
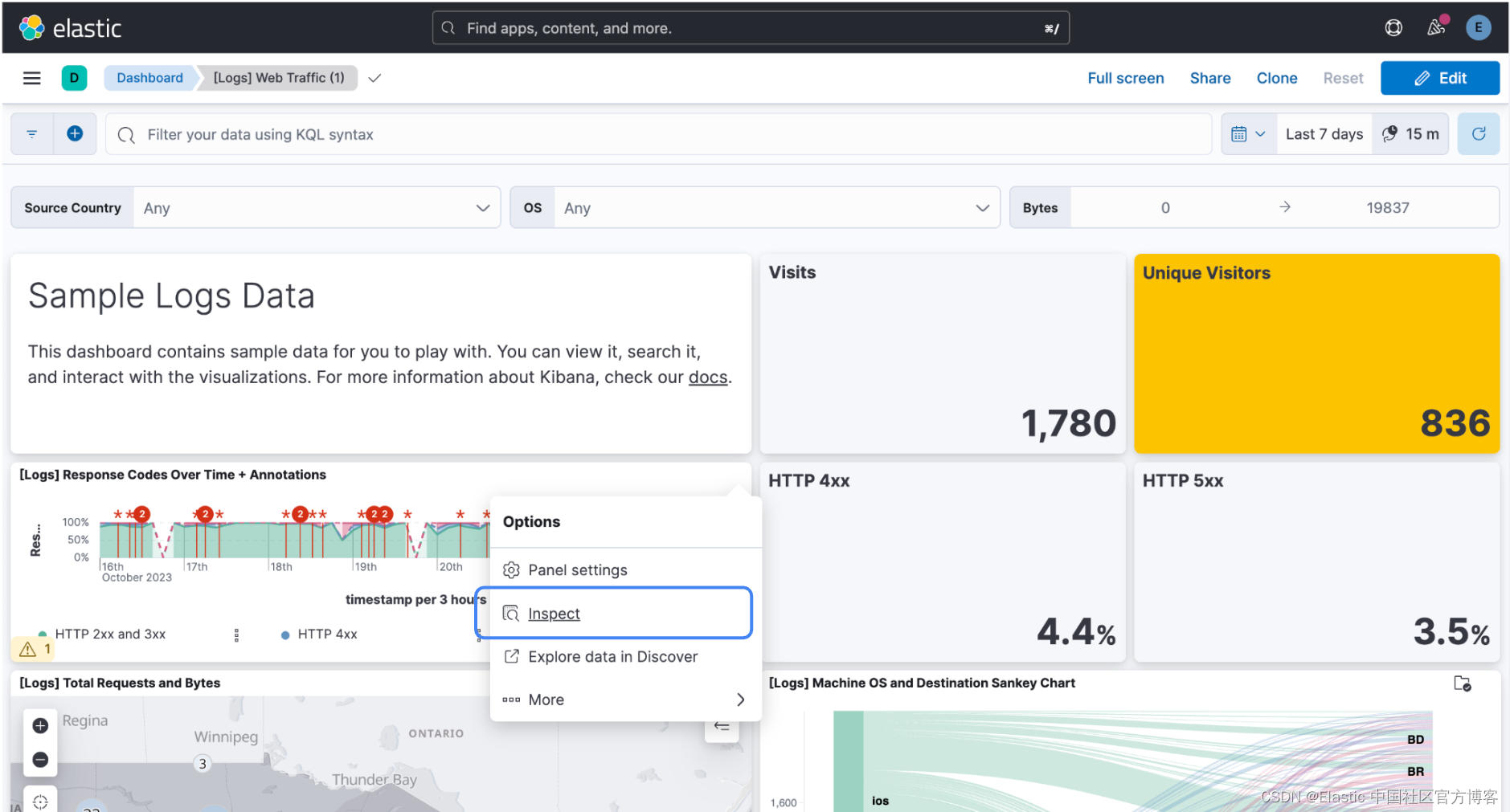
单击 “Inspect”,单击 “View: Requests”,然后单击 “Clusters and shards” 选项卡。
除了 Kibana 中这个方便的新视图之外,Elastic 8.11 还增强了 API 响应级别的搜索响应。 除了搜索响应中已存在的成功和跳过的计数器之外,我们现在还提供每个集群的 partial、failed 和 running 的搜索状态的说明。
8.10 中的搜索响应集群部分:
…"_clusters": {"total": 3,"successful": 2,"skipped": 1,"details": {"(local)": {"status": "successful",…},
…
在8.10中,partial 和 successful 都算作 successful,skipped 和 failed 都算作 skipped。
8.11 中增强的搜索响应集群部分:
…"_clusters": {"total": 6,"successful": 2,"partial": 1,"skipped": 1,"failed"; 1,"running": 1,"details": {"(local)": {"status": "successful",…},
…你可以使用 running 计数器来监视异步搜索的进度。 它可以用于创建进度条或提供正在进行的搜索的实时更新。 将 partial 搜索与 sucessfull 分离可以更轻松地了解搜索的准确性,并且粒度可以帮助用户更有效地识别和解决任何问题。 添加 failed 计数器可确保用户及时获悉在搜索过程中出现故障的任何集群。
最后,我们调整了行为,以便无论你在搜索请求中使用 minimum_roundtrips:true 还是 false,所有这些新信息都可用。
重新路由处理器(reroute processor)已正式发布
我们在 8.8 中以技术预览状态引入了重新路由处理器,从而实现了我们所说的基于文档的路由。 如果你有混合在一起的文档(可能来自 Firehose 或 docker 日志记录驱动程序),你可以设置重新路由处理器,将每种文档定向到更适用的摄取管道,以便可以正确处理它们以实现最佳搜索。 在 Elastic 8.11 中,重新路由现已正式发布。
如果你想了解有关此功能的更多信息并查看示例,请查看我们的可观察性团队撰写的博客。
使用向量搜索查找最相似的段落(paragraph)
我们添加了一个选项,使文档在单个字段中具有多个向量,并按文档中向量中最相似的向量进行排名。 在许多用例中,此功能至关重要,但有两个用例最为流行:
- 分块文本(chunking text):许多嵌入模型将文本的大小限制为 512 个标记(通常意味着大约 512 个单词)。 这大致翻译为段落长度的文本。 用户经常希望搜索包含最相关段落的文本。 为此,用户为每个段落创建一个向量,并希望根据每个文档中最相似的向量对文档进行排名,这是现在支持的。
- 多个图像:一个文档经常包含多个图像(例如,如果文档代表房地产资产,它将包含该资产的多个图像;如果文档代表电子商务中的产品,则会有该产品的不同图像;如果一个文档代表一个人,它将包含该人的多个图像)。 用户想要找到最相关的文档(例如资产、产品或人员)。 卷积神经网络旨在为每个图像生成一个向量,用户希望通过最相似的图像和向量对文档进行排名。
有关这一令人兴奋且非常独特的功能的更多信息,请参阅向 Lucene 添加 4096 维密集向量
我们已将密集向量搜索支持的维数增加到 4096 维。 正如过去所指出的,我们认为进一步提高这一标准没有问题。 我们将限制维持在 4096 维度的原因是,我们目前没有看到需要更高维度的生产就绪模型。 如果需求增加,我们将进一步提高限额。。
最大内积密集向量相似度
Elasticsearch 现在支持使用最大内积 (MIPS) 的密集向量搜索。 此选项已添加到其他支持的向量相似度选项(欧几里得、曼哈顿、点积和余弦)中。 某些向量搜索模型需要最大内积,特别是对于一些用于生成式 AI 和 RAG 应用程序的模型,这些模型在近几个月已成为使用 Elasticsearch 的流行用例。
稀疏向量数据类型
Elasticsearch 现在支持 sparse_vector 数据类型,可供 ELSER 模型使用。 虽然它与 ELSER 迄今为止使用的 rank_features 数据类型没有本质上的不同,但该用例非常重要、流行且不同,足以值得拥有自己的数据类型。 如果不出意外的话,这样就更容易理解了。
Exists 稀疏向量查询
Exists 查询返回在字段中具有特定值的文档。 Exists 查询已得到增强,包含稀疏向量。 这是另一个例子,说明围绕实际向量搜索的服务范围在实践中与搜索本身同样重要。 我们发现用户有时使用 ELSER 模型获取文档,然后只想重新运行一小部分没有填充稀疏向量的文档。 Exists 查询对此会很方便。
波斯语(Persian)词干分析器
用户可以使用 Elasticsearch 支持的语言分析器插件来执行语言分析。 然而,如果 Elasticsearch 已经附带了该插件,那就更容易了,因此我们添加了对波斯语词干分析器插件的支持。
默认情况下,密集向量字段类型被用于建立索引
我们正在采取行动,使密集向量搜索的使用变得更简单、更容易。 作为其中的一部分,我们默认对密集向量字段进行了索引。 这是管理员需要执行的另一项操作,我们可以消除该操作,因为向量很少不需要索引。 此外,我们现在将根据第一个索引向量动态选择正确的维度数。 更少的配置,更少的麻烦。 当然,专家仍然可以利用全套现有选项。
试试看
请在发行说明中了解这些功能以及更多信息。
现有 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问其中许多功能。 没有利用云上的 Elastic? 开始免费试用。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Elastic Stack 8.11 introduces an advanced query language, ES|QL | Elastic Blog
相关文章:
Elastic Stack 8.11:引入一种新的强大查询语言 ES|QL
作者:Tyler Perkins, Ninoslav Miskovic, Gilad Gal, Teresa Soler, Shani Sagiv, Jason Burns Elastic Stack 8.11 引入了数据流生命周期、一种配置数据流保留和降采样(downsampling) 的简单方法(技术预览版)…...

wx:for-item wx:for-index wx:for-key
wx:for-item wx:for-item , 数组当前项的变量名,默认为 item 作用:使用 (当前项变量名.属性名) 取得属性值每一项 <view wx:for"{{array}}"><view>{{item.name item.age }}</view> </view>等同于 &…...

老师还不会评课?这里有你需要的解决方案
优点: 1.课件制作: 老师的PPT设计得很新颖,插入的音乐视频都非常贴合课堂内容,看得出老师非常用心地进行了设计。 2.教师素养:老师的语言丰富、朗读能力很出色、板书设计很工整。 3.教师风格: xx老师上课激情澎湃/非常有亲和力…...

Talk | 马里兰大学博士生吴曦旸:分布式多智能体强化学习在复杂交通轨迹规划中的应用
本期为TechBeat人工智能社区第545期线上Talk! 北京时间11月09日(周四)20:00,马里兰大学博士生—吴曦旸的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “分布式多智能体强化学习在复杂交通轨迹规划中的应用”,介…...
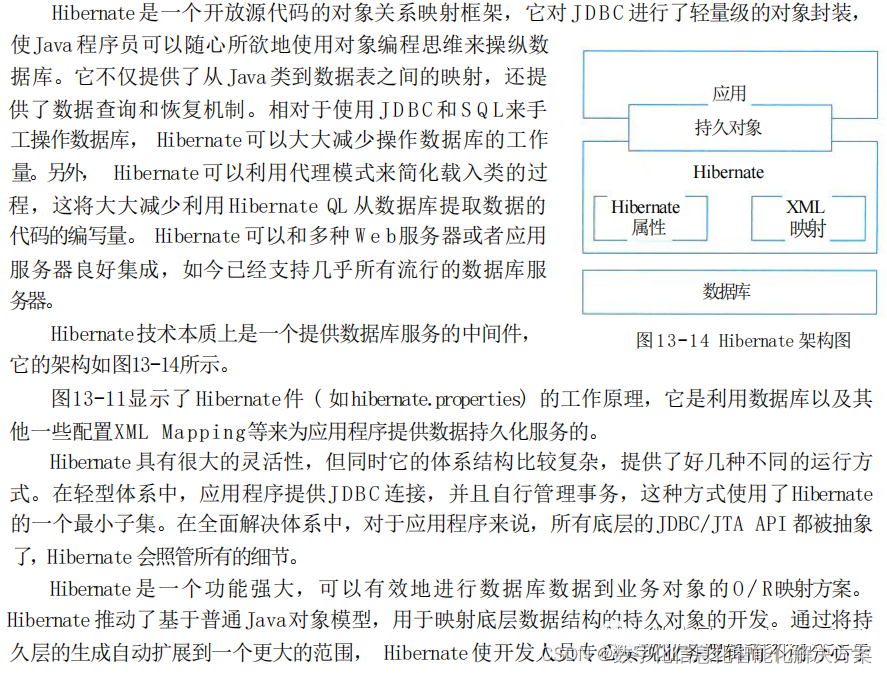
2023年下半年架构案例真题及答案
案例的考点: 大数据架构 Lambda架构和Kappa架构 jwt特点 数据持久层,Redis数据丢失,数据库读写分离方案 Hibernat架构 SysML七个关系,填需求图 大数据的必选题: 某网作为某电视台在互联网上的大型门户入口&#…...
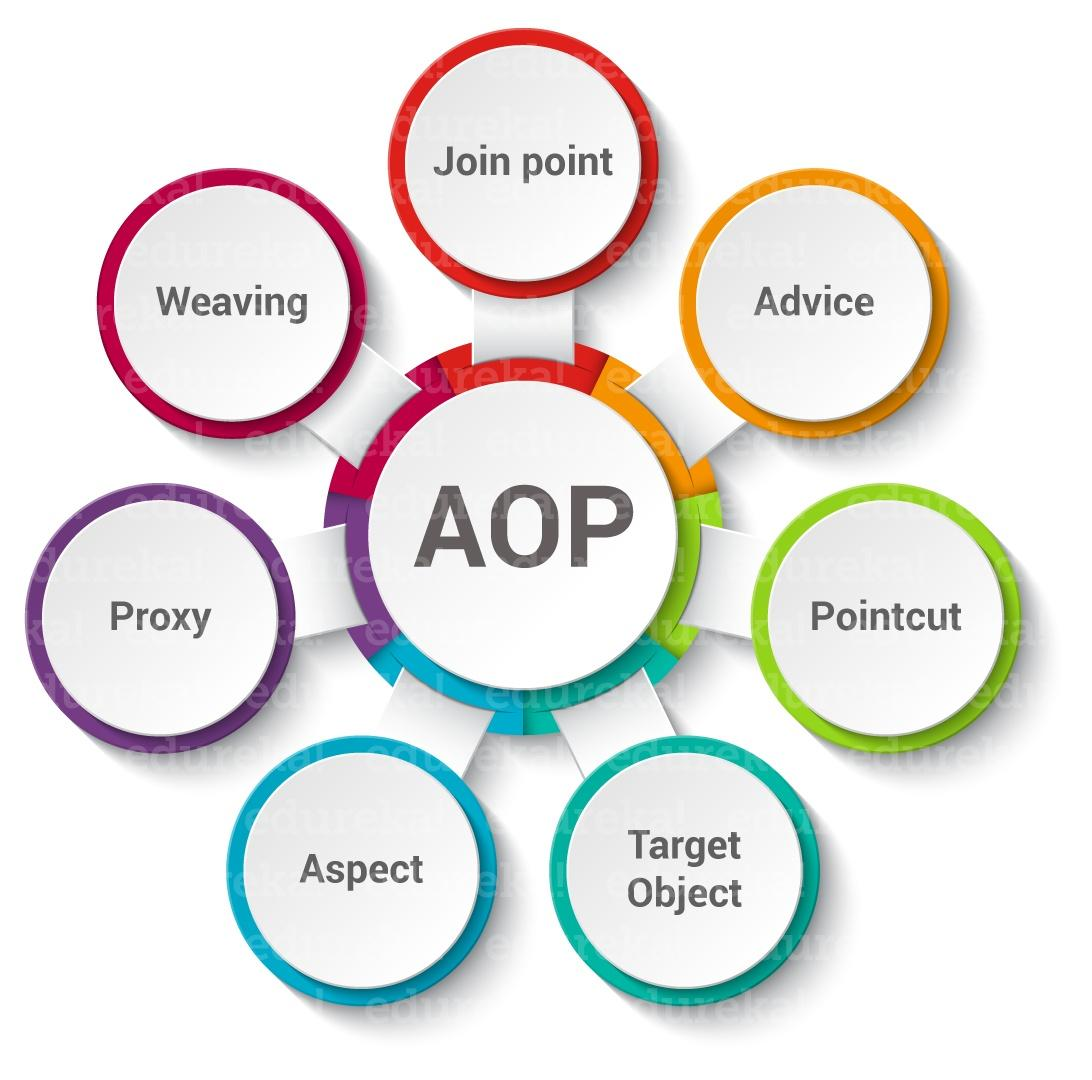
Java必考面试题,谈谈你对 Spring AOP 的理解
大家好,我是伍六七。 今天我们来学习 Spring 框架中最重要的概念之一:AOP。 这是一个 Java 程序员必考的面试题,大家好好理解。我们开始正文。 AOP 的概念 Spring AOP 是 Java 程序员们面试经常被问到的一个问题,但 AOP&#…...

BERT和ChatGPT简单对比
OpenAI发布了第一个版本的GPT(Generative Pretrained Transformer)模型在2018年6月。 谷歌的BERT模型(Bidirectional Encoder Representations from Transformers)是在2018年10月发布的。 BERT和ChatGPT都是由人工智能研究实验室…...

又一重要合作,创邻科技华为云联营产品正式发布
近日,创邻科技旗下的“Galaxybase高性能图平台”正式入驻华为云云商店联营商品,创邻科技成为华为云在数据库与缓存领域的联营联运合作伙伴。通过联营联运模式,双方合作能够深入产品、生态、解决方案等多个领域,助力各行业用户数字…...

PHP+Swoole应用示例
**Swoole是一个C编写的基于异步事件驱动和协程的并行网络通信引擎,为PHP提供高性能网络编程支持** ## ⚙️ 快速启动 可以直接使用 [Docker](https://github.com/swoole/docker-swoole) 来执行Swoole的代码,例如: bash docker run --rm php…...

3线硬件SPI+DMA驱动 HX8347 TFT屏
3线硬件SPIDMA驱动 HX8347 TFT屏,实现用DMA清屏。 参考:基于stm32 标准库spi驱动st7789彩屏TFT(使用DMA)-技术天地-深圳市修德电子有限公司 一、源码 HX8347.h #ifndef USER_HX8347_H_ #define USER_HX8347_H_#define SPI_hardware #define SPI_hardw…...

实验语音学的基本概念
语音学 实验语音学只是语音学的一个分支,那么语音学到底是研究什么的呢?我们先有一个大致了解。 语音学是研究语言声音体系的学科。语音学的任务是研究说明语音的性质,内部结构和单位,语音的分类和组合,语音的产生、…...

市场上ios签名公司做什么的?
iOS签名公司是提供iOS应用程序签名服务的公司。它们为开发者提供了一种简单的方式来将他们的应用程序发布到iOS设备上,同时也为用户提供了一种下载和安装这些应用程序的方法。这些公司提供的签名服务包括苹果企业签名和开发者签名,其中企业签名是为企业开…...

12. 一文快速学懂常用工具——docker 命令
本章讲解知识点 Docker 引擎Docker 常用命令Docker 生命周期详解Containerd 与 Docker 命令对比本专栏适合于软件开发刚入职的学生或人士,有一定的编程基础,帮助大家快速掌握工作中必会的工具和指令。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。如专栏内容有错…...
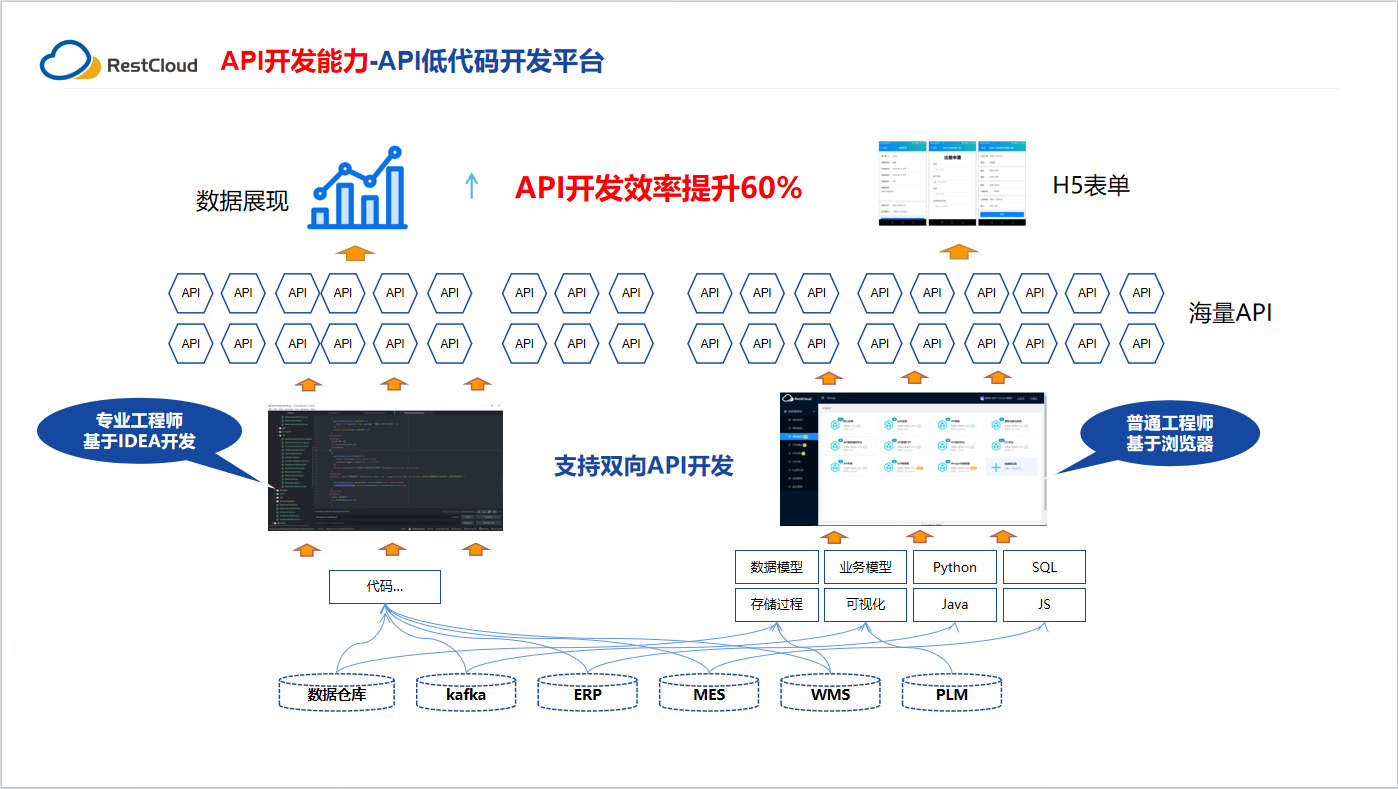
API低代码开发应用场景
什么是API低代码开发平台 API低代码开发平台是一种基于低代码开发的技术平台,它可以帮助企业快速构建和部署API应用程序。该平台通过提供可视化的开发工具、预定义的组件和模板、自动化的代码生成等功能,使得开发者可以在不需要编写大量代码的情况下&am…...

从零开始搭建React+TypeScript+webpack开发环境-性能优化
前言 当我们开发React应用时,性能始终是一个重要的考虑因素。随着应用规模的增长,React组件的数量和复杂性也会相应增加,这可能会导致性能问题的出现。在这篇博文中,我们将探讨如何通过一系列的技巧和最佳实践来优化React应用的性…...

sCrypt 现在支持 Ordinals 了
比特币社区对 1Sat Ordinals 的接受度正在迅速增加,已有超过 4800 万个铭文被铸造,这一新创新令人兴奋不已。 尽管令人兴奋,但 Ordinals 铭文的工具仍然不发达,这使得使用 Ordinals 进行构建具有挑战性。 更具体地说,缺…...

乌班图搭建 LAMP
搭建 LAMP(Linux、Apache、MySQL、PHP)堆栈是在 Ubuntu 上构建 Web 服务器的常见任务。以下是一些步骤,指导如何在 Ubuntu 上搭建 LAMP 环境: 步骤: 更新系统软件包: 在终端中执行以下命令,确…...

【Unity细节】Unity中的Transform.SetParent还有你不知道的细节
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...

php生成个性二维码
本篇引用 QRcode PHP QR Code download | SourceForge.net 无需composer即可生成 下载后的类文件是一个压缩包,里边包含很多文件和演示demo,我们只需要里的phpqrcode.php这一个文件就可以生成二维码了。它是一个多个类的集合文件,我们只用…...

css排版—— 一篇优雅的文章(中英文) vs 聊天框的特别排版
文章 <div class"contentBox"><p>这是一篇范文——仅供测试使用</p><p>With the coming of national day, I have a one week holiday. I reallyexpect to it, because it want to have a short trip during these days. Iwill travel to Ji…...

2026山东大学项目实训4月23日
V7 阶段我主要负责整体版本目标设计、范围收敛和阶段验收把控。到 V6 为止,项目已经能够完成 GitHub OAuth 授权、仓库绑定、Webhook 诊断和基础审查闭环,但如果从真实使用的角度去看,系统还缺少一个很重要的能力,就是“出问题之后…...

从0到1,开启Android音视频开发之旅
从0到1,开启Android音视频开发之旅 音视频开发的 “热” 与 “难” 在当今数字化时代,音视频早已融入我们生活的方方面面。打开手机,短视频 APP 里精彩纷呈的视频内容令人目不暇接;电商直播中,主播们通过音视频实时展示…...

Vmem架构解析:轻量级内存管理的技术突破与实践
1. Vmem架构设计解析:轻量级内存管理的技术突破在云计算环境中,内存管理一直是影响虚拟机性能的关键瓶颈。传统方案如Hugetlb虽然通过大页机制减少了TLB缺失,但依然存在元数据开销大、灵活性不足等固有缺陷。Vmem的创新之处在于彻底重构了内存…...
在跨平台应用中的实践与挑战)
手写笔迹还原算法(InkCanvas)在跨平台应用中的实践与挑战
跨平台手写笔迹还原算法的工程实践与性能优化 在数字化教学与创意设计领域,手写输入体验的质量往往直接影响用户留存率。根据行业调研数据,采用优质笔迹还原技术的应用用户满意度平均提升37%,而渲染延迟超过150毫秒就会导致23%的用户放弃使用…...
)
Python脚本远程执行Windows命令?除了Paramiko,你还可以试试pywinrm(附Win10环境完整避坑指南)
Python远程操控Windows的终极方案:pywinrm实战与避坑指南 作为Python开发者,我们早已习惯用Paramiko优雅地SSH到Linux服务器执行命令。但当场景切换到Windows环境时,这种流畅体验往往会戛然而止。本文将带你探索Windows原生的远程管理协议Win…...

AI批量翻译txt文档工具:功能详解与使用指南
对于需要处理大量外文资料的用户来说,批量翻译文档是个常见需求。本文介绍一款基于AI的文档翻译工具,包含完整功能解析和操作指南。 工具能做什么 一句话总结:用AI批量翻译文件夹内的txt、md、srt文档,支持多语言、术语表、翻译缓…...

数字人视频生成利器:Sonic工作流功能体验与效果测评
数字人视频生成利器:Sonic工作流功能体验与效果测评 1. 引言:数字人视频制作的新选择 在内容创作领域,数字人视频正变得越来越流行。无论是电商直播、在线教育还是企业宣传,都需要大量高质量的视频内容。传统视频制作需要专业设…...
:attitude_estimator_q 中的两个问题讨论)
PX4姿态解算技术详解(七):attitude_estimator_q 中的两个问题讨论
在前面的章节中,我们系统梳理了 attitude_estimator_q 的工作原理——从初始对准、重力校正、磁力计航向校正到统一的闭环更新。本章把注意力集中在两个值得深入讨论的问题上: 水平姿态估计与航向估计是否存在耦合;固定翼无人机协调转弯时&am…...

为什么定义常量要用 static final 修饰,final 表示不可修改,static 表示全局唯一,和在一起表示全局常量
final 表示不可修改,static 表示全局唯一,和在一起表示全局常量。static 修饰的成员变量随着类的加载而创建,可以直接使用类调用,也可以使用类的实例对象调用,多个实例对象共享同一个 static 修饰的静态变量。我的理解…...

别再死记硬背了!用Python+Jupyter Notebook可视化理解元素周期表电子排布
用Python动态解析元素周期表:从电子排布可视化到量子规则编程实践 当化学老师反复强调"铬的电子排布是3d⁵4s而非3d⁴4s"时,你是否好奇这背后的量子力学原理?传统教学往往要求死记硬背这些特殊案例,而今天我们将用Pytho…...