Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取美女图片网下载图片 视频教程作者:小锋老师官网:www.python222.com本课程旨在让大家在网站Python爬虫的基础上,实战巩固Python爬虫技术后期会继续推出进阶,高级课程,敬请期待。, 视频播放量 354、弹幕量 1、点赞数 20、投硬币枚数 8、收藏人数 21、转发人数 5, 视频作者 java1234官方, 作者简介 公众号:java1234 微信:java9266,相关视频:Python爬虫实战-批量爬取下载网易云音乐,爬虫学得好!牢饭吃到饱...全网最全爬虫JS逆向案例!企业级爬虫逆向实战(逆向各种加密、参数、验证码、滑块、算法)建议立刻收藏!,2024 一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium 【无废话版】,Gateway微服务网关视频教程(无废话版),Nacos视频教程(无废话版),打造前后端分离 权限系统 基于SpringBoot2+SpringSecurity+Vue3.2+Element Plus 视频教程 (火爆连载更新中..),2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...,微信小程序(java后端无废话版)视频教程,Java8 Lambda表达式视频教程(无废话版),Docker快速手上视频教程(无废话版)![]() https://www.bilibili.com/video/BV1ue411X7JU/
https://www.bilibili.com/video/BV1ue411X7JU/

爬虫目标网站:
https://pic.netbian.com/4kmeinv/经过分析,第二页,第二页的规律是:

https://pic.netbian.com/4kmeinv/index_N.html复杂问题简单化:先爬取首页,然后再进行多页爬虫代码的实现。
通过开发者工具分析

img的路径是 ul.clearfix li a img
爬虫三步骤,
1,根据请求url地址获取网页源码,用requests库
2,通过bs4解析源码获取需要的数据
3,通过数据处理我们的资源,我们这里是通过图片路径下载到本地
所以我们实现首页图片下载的源码参考如下:具体代码分析,可以学习下帖子开头的视频教程
"""爬取目标:https://pic.netbian.com/ 彼岸图网首页地址:https://pic.netbian.com/4kmeinv/第N页https://pic.netbian.com/4kmeinv/index_N.htmlhttps://pic.netbian.com/uploads/allimg/231101/012250-16987729706d69.jpg作者:小锋老师官网:www.python222.com
"""
import os.pathimport requests
from bs4 import BeautifulSoupurl = "https://pic.netbian.com/4kmeinv/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}# 请求网页
response = requests.get(url=url, headers=headers)
response.encoding = "gbk"
# print(response.text)# 实例化soup
soup = BeautifulSoup(response.text, "lxml")
# 获取所有图片
img_list = soup.select("ul.clearfix li a img")
print(img_list)def download_img(src):"""下载图片:param src: 图片路径:return:"""# 获取图片名称filename = os.path.basename(src)print(filename)# 下载图片try:with open(f"./img/{filename}", "wb") as file:file.write(requests.get("https://pic.netbian.com" + src).content)except:print(src, "下载异常")for img in img_list:print(img["src"])download_img(img["src"])
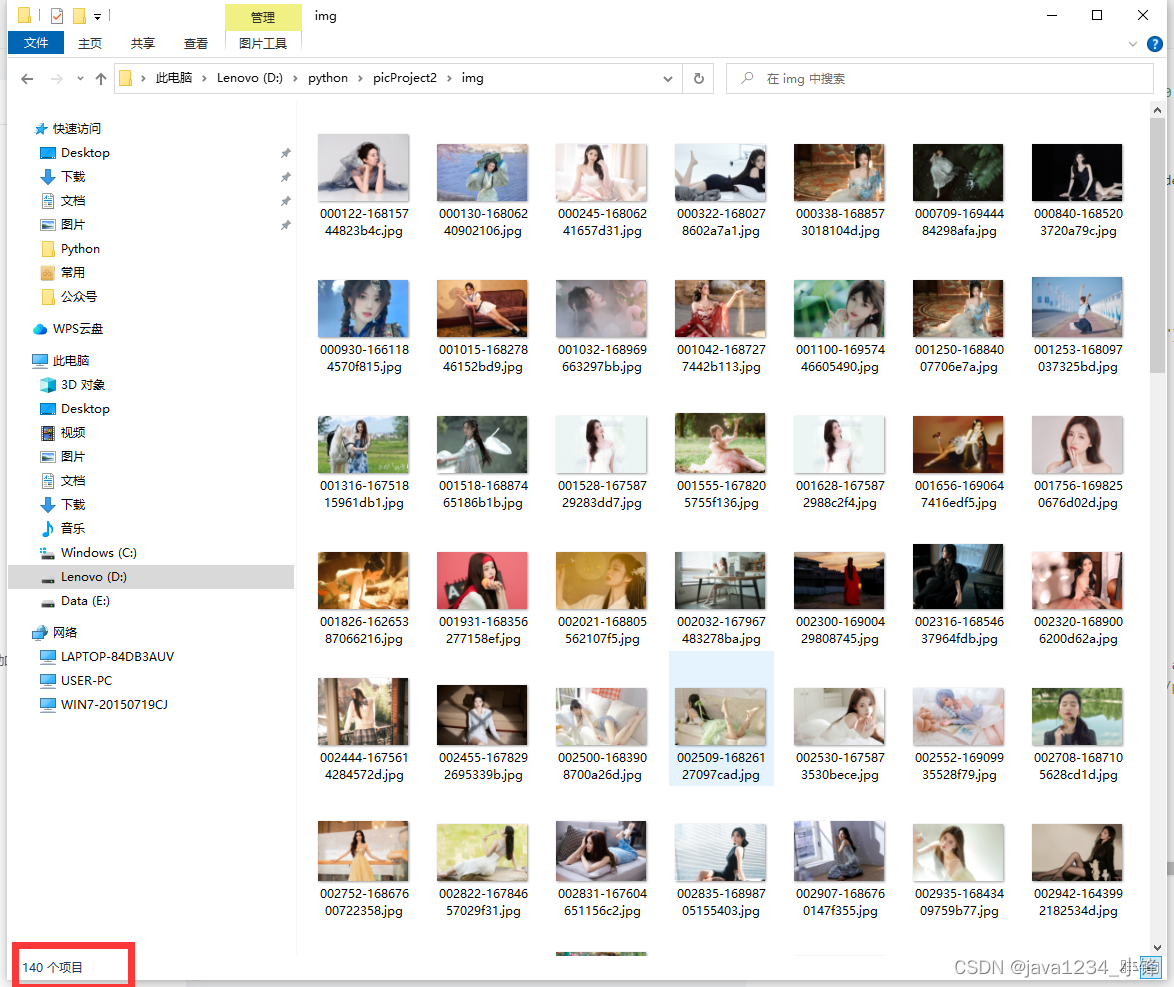
运行代码,一页数据20个。

实现多页的下载的话,我们肯定需要通过遍历所有url,然后实现批次下载;那么对于抓取网页,和解析网页,我们需要进行封装,那才方便调用。
def crawl_html(url):"""解析网页:param url: 请求地址:return: 解析后的网页源码"""# 请求网页response = requests.get(url=url, headers=headers)response.encoding = "gbk"return response.textdef parse_html(html):# 实例化soupsoup = BeautifulSoup(html, "lxml")# 获取所有图片img_list = soup.select("ul.clearfix li a img")print(img_list)for img in img_list:print(img["src"])download_img(img["src"])完整源码参考:具体代码分析,可以学习下帖子开头的视频教程
"""爬取目标:https://pic.netbian.com/ 彼岸图网首页地址:https://pic.netbian.com/4kmeinv/第N页https://pic.netbian.com/4kmeinv/index_N.htmlhttps://pic.netbian.com/uploads/allimg/231101/012250-16987729706d69.jpg作者:小锋老师官网:www.python222.com
"""
import os.pathimport requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}def crawl_html(url):"""解析网页:param url: 请求地址:return: 解析后的网页源码"""# 请求网页response = requests.get(url=url, headers=headers)response.encoding = "gbk"return response.textdef download_img(src):"""下载图片:param src: 图片路径:return:"""# 获取图片名称filename = os.path.basename(src)print(filename)# 下载图片try:with open(f"./img/{filename}", "wb") as file:file.write(requests.get("https://pic.netbian.com" + src).content)except:print(src, "下载异常")def parse_html(html):# 实例化soupsoup = BeautifulSoup(html, "lxml")# 获取所有图片img_list = soup.select("ul.clearfix li a img")print(img_list)for img in img_list:print(img["src"])download_img(img["src"])# # 第一页
# url = "https://pic.netbian.com/4kmeinv/"
# parse_html(crawl_html(url))
# # 第二页到第七页
# for i in range(2, 8):
# parse_html(crawl_html(f"https://pic.netbian.com/4kmeinv/index_{i}.html"))urls = ["https://pic.netbian.com/4kmeinv/"] + [f"https://pic.netbian.com/4kmeinv/index_{i}.html"for i in range(2, 8)
]
print(urls)
for url in urls:parse_html(crawl_html(url))
运行下载,正好7页的图片,140个。
相关文章:
Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。 近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础 视频版教程: Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取…...
uniapp+uview2.0+vuex实现自定义tabbar组件
效果图 1.在components文件夹中新建MyTabbar组件 2.组件代码 <template><view class"myTabbarBox" :style"{ backgroundColor: backgroundColor }"><u-tabbar :placeholder"true" zIndex"0" :value"MyTabbarS…...

opencv 任意两点切割图像
目录 opencv python直线切割图像,把图像分为两个多边形 升级版,把多边形分割抠图出来,取最小外接矩形:...
rust变量绑定、拷贝、转移、引用
目录 一,clone、copy 1,基本类型 2,类型的clone特征 3,显式声明结构体的clone特征 4,类型的copy特征 5,显式声明结构体的clone特征 5,变量和字面量的特征 6,特征总结 二&am…...

Java多种方式向图片添加自定义水印、图片转换及webp图片压缩
给个创建水印的示例: /*** 获取水印** param watermarkText 水印文字* return 水印bufferimage*/public static BufferedImage getWatermark(String watermarkText) {BufferedImage measureBufferdImage new BufferedImage(100, 100, BufferedImage.TYPE_INT_ARGB…...
——多维度单步预测)
基于Pytorch框架的LSTM算法(二)——多维度单步预测
1.项目说明 **选用Close和Low两个特征,使用窗口time_steps窗口的2个特征,然后预测Close这一个特征数据未来一天的数据 当batch_firstTrue,则LSTM的inputs(batch_size,time_steps,input_size) batch_size len(data)-time_steps time_steps 滑动窗口&…...

cnn感受野计算方法
No. Layers Kernel Size Stride 1 Conv1 33 1 2 Pool1 22 2 3 Conv2 33 1 4 Pool2 22 2 5 Conv3 33 1 6 Conv4 33 1 7 Pool3 2*2 2 感受野初始值 l 0 1 l_0 1l 0 1,每层的感受野计算过程如下: l 0 1 l_0 1l 0 1 l 1 1 ( 3 − 1 ) 3 l_1 1…...

百分点科技受邀参加“第五届治理现代化论坛”
11月4日,由北京大学政府管理学院主办的“面向新时代的人才培养——第五届治理现代化论坛”举行,北京大学校党委常委、副校长、教务长王博,政府管理学院院长燕继荣参加开幕式并致辞,百分点科技董事长兼CEO苏萌受邀出席论坛…...

基于Springboot的智慧食堂设计与实现(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的智慧食堂设计与实现(有报告)。Javaee项目,springboot项目。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 项…...

「Verilog学习笔记」多功能数据处理器
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 注意题目要求输入信号为有符号数,另外输出信号可能是输入信号的和,所以需要拓展一位,防止溢出。 timescale 1ns/1ns module data_…...

OpenHarmony 4.0 Release 编译异常处理
一、环境配置 编译环境:Ubuntu 20.04 OpenHarmony 软件版本:4.0 Release 设备平台:rk3568 二、下拉代码 参考官网步骤: OpenHarmony 4.0 Release 源码获取 repo init -u https://gitee.com/openharmony/manifest -b OpenHarmo…...

软件测试|MySQL LIKE:深入了解模糊查询
简介 在数据库查询中,模糊查询是一种强大的技术,可以用来搜索与指定模式匹配的数据。MySQL数据库提供了一个灵活而强大的LIKE操作符,使得模糊查询变得简单和高效。本文将详细介绍MySQL中的LIKE操作符以及它的用法,并通过示例演示…...

linux防火墙设置
#查看firewall的状态 firewall-cmd --state (systemctl status firewalld.service) #安装 yum install firewalld #启动, systemctl start firewalld (systemctl start firewalld.service) #设置开机启动 systemctl enable firewalld #关闭 systemctl stop firewalld #取消…...

http 403
一、什么是HTTP ERROR 403 403 Forbidden 是HTTP协议中的一个状态码(Status Code)。可以简单的理解为没有权限访问此站,服务器受到请求但拒绝提供服务。 二、HTTP 403 状态码解释大全 403.1 -执行访问禁止。 403.2 -读访问禁止。 403.3 -写访问禁止。 403.4要…...
RAW图像处理软件Capture One 23 Enterprise mac中文版功能特点
Capture One 23 Enterprise mac是一款专业的图像处理软件,旨在为企业用户提供高效、快速和灵活的工作流程。 Capture One 23 Enterprise mac软件的特点和功能 强大的图像编辑工具:Capture One 23 Enterprise提供了一系列强大的图像编辑工具,…...

Linux 进程终止和等待
目录 一:进程常见的退出方法 1. main 函数返回值 2.调用 exit 3.调用 _exit 二:异常问题 三:进程等待 1.概念 2.进程等待的必要性 3.进程等待的方法 <1>:wait --- 系统调用 <2>:waitpid 进程…...
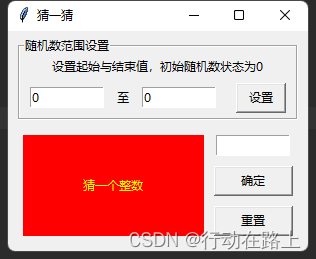
python用tkinter随机数猜数字大小
python用tkinter随机数猜数字大小 没事做,看到好多人用scratch做的猜大小的示例,也用python的tkinter搞一个猜大小的代码玩玩。 猜数字代码 from tkinter import * from random import randint# 定义确定按钮的点击事件 def hit(x,y):global s_Labprint(…...

程序员们保住自己饭碗
在现代社会中,程序员扮演着至关重要的角色。他们不仅仅是编写代码的人,更是保障数字世界安全稳定的守护者。随着科技的迅猛发展,程序员保住自己饭碗的护城河变得愈发重要。本文将探讨程序员如何通过不断学习、技术创新和软实力的发展…...
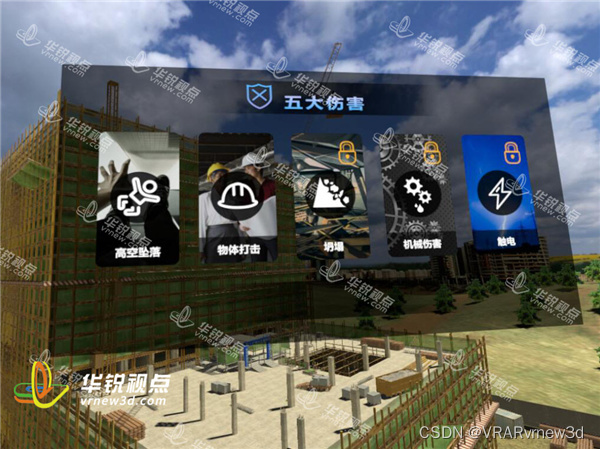
顶板事故防治vr实景交互体验提高操作人员安全防护技能水平
建筑业在我国各行业中属危险性较大且事故多发的行业,在建筑业“八大伤害”(高处坠落、坍塌、物体打击、触电、起重伤害、机械伤害、火灾爆炸及其他伤害)事故中,高处坠落事故的发生率最高、危险性极大。工地现场培训vr坠落体验利用虚拟现实技术还原各种情…...
为什么推荐从Linux开始了解IT技术
IT是什么,是干什么的呢? 说起物联网,云计算,大数据,或许大家听过。但是,你知道,像云计算的底层基座是什么呢?就是我们现在说的Linux操作系统。而云计算就是跑在Linux操作系统上的一个…...
)
告别卡顿!用uni.request的enableChunked实现小程序流式聊天(附完整代码)
告别卡顿!用uni.request的enableChunked实现小程序流式聊天(附完整代码) 在移动应用开发中,流畅的用户体验往往决定了产品的成败。想象一下,当用户在小程序中与AI对话时,如果每次都要等待全部内容加载完成才…...

如何避免爬虫被检测:Python爬虫中的反反爬虫策略
随着网站爬虫的普及,越来越多的网站开始使用反爬虫技术来检测和防止自动化爬虫的访问。这些技术包括 IP 限制、User-Agent 检测、验证码等。为了使 Python 爬虫能够有效地绕过这些反爬虫机制,开发者需要采用一些反反爬虫策略。 本文将讨论如何避免爬虫被检测,并提供一些实用…...

2026年T3出行赴港IPO,AI+出行模式助力成中国第三大智慧出行平台
2026年4月22日,T3出行正式向港交所递交招股说明书。截至2025年底,它在中国194座城市开展业务,服务超2.345亿用户,2025年订单量居中国第三。发展历程与现状2019年7月T3平台上线,截至2025年12月31日,在中国19…...

终极Docker镜像优化指南:如何用Dive解决权限难题并提升存储效率
终极Docker镜像优化指南:如何用Dive解决权限难题并提升存储效率 【免费下载链接】dive A tool for exploring each layer in a docker image 项目地址: https://gitcode.com/GitHub_Trending/di/dive Docker镜像优化是每个开发者必须掌握的技能,而…...

邮件骚扰取证分析:digital-forensics-lab Email_Harassment 案例研究
邮件骚扰取证分析:digital-forensics-lab Email_Harassment 案例研究 【免费下载链接】digital-forensics-lab Free hands-on digital forensics labs for students and faculty 项目地址: https://gitcode.com/gh_mirrors/dig/digital-forensics-lab digita…...
)
别再用错__attribute__了!C语言高手都在用的15个实战技巧(附代码避坑)
别再用错__attribute__了!C语言高手都在用的15个实战技巧(附代码避坑) 在嵌入式开发和系统级编程中,编译器扩展特性往往是区分普通开发者和高手的关键分水岭。GNU C的__attribute__机制就像瑞士军刀中的隐藏工具——90%的开发者只…...
Pixel手机工程模式探秘:一键识别Verizon版本与解锁状态
1. Pixel手机Verizon版本的那些事儿 第一次拿到Pixel手机的时候,你可能和我一样兴奋,但很快就会发现一个头疼的问题:这台手机到底是Verizon版本还是非Verizon版本?这个问题可不仅仅是运营商不同那么简单,它直接关系到你…...

CVAT标注实战:从AI自动标注到导出COCO/VOC数据集,保姆级避坑指南
CVAT标注实战:从AI自动标注到导出COCO/VOC数据集,保姆级避坑指南 在计算机视觉项目的实际开发中,数据标注往往是耗时最长、最容易出错的环节。CVAT(Computer Vision Annotation Tool)作为一款开源的图像标注工具&#…...

AI批量翻译txt文档工具:功能详解与使用指南
对于需要处理大量外文资料的用户来说,批量翻译文档是个常见需求。本文介绍一款基于AI的文档翻译工具,包含完整功能解析和操作指南。 工具能做什么 一句话总结:用AI批量翻译文件夹内的txt、md、srt文档,支持多语言、术语表、翻译缓…...
)
别再只用Matplotlib了!科研论文配图,试试这3个更优雅的Python库(附代码对比)
科研论文配图进阶指南:超越Matplotlib的三大优雅选择 当你在深夜修改论文第N稿时,是否曾被审稿人那句"Figures need improvement"刺痛过?科研图表不仅是数据的载体,更是学术表达的视觉语言。Matplotlib作为Python绘图的…...