Flink(三)【运行时架构】
前言
今天学习 Flink 的一些原理性的东西,比较偏概念,但是十分重要。有人觉得上来框框敲代码才能学到东西,那是狗屁不通的道理(虽然我以前也这么认为)。个人认为,学习 JavaEE那些框架,你上来就敲代码确实也可以,没有太多难理解的东西;但是对于大数据、分布式包括我们学的很多计算机原理、计算机网络这种理论性强的学科,了解原理是十分有必要的,代码终将容易忘记,但是原理只要你能理解,它就不会从你的大脑里失去。就像喜欢的女孩子一样,你能懂她理解她,那她就轻易离不开你。但是用学习的方法再去懂女孩子可不是一件容易的事情啊!知识是死的,它就在那,你学知识就是你的。可人不一样,人不是物,人的认知广,就像你喜欢的人,她不是每天就和你一个交往,她可能和好人学会了好的品行、和坏人学会了坏的品行,从环境受影响又有了别的特质,所以你想了解她并不是一件容易的事情哇。而且还有一条,她给不给你这个了解的机会还另说呢。就像我现在,之前无话不谈的人,因为各种复杂的事情影响下,她再不主动找我,我又不想厚着脸贴人家。知识它越捂越热,但是人之间的心要是离开了,就很难挽回了。害,我应该还没到那个阶段吧,到时候我自己问问。
今天下雪了,难得她记得给我分享,难懂哦。
人与人之间情断义绝,并不需要什么具体的理由。就算表面上有,也很可能只是心已经离开的结果,事后才编造出的借口而已。因为倘若心没有离开,当将会导致关系破裂的事态发生时,理应有人努力去挽救。如果没有,说明其实关係早已破裂。 -《解忧杂货店》
核心组件
1、JobManager
控制 Flink 应用程序执行、任务管理和调度的核心。每一个 Flink 应用程序由唯一的 JobManager 管理控制。
JobManager有三大组件:
JobMaster
- JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(一个 JobMaster 对应一个 Job,因为一个 Flink 应用程序可能有多个作业,所以就可以有多个 JobMaster)。
- 在作业提交时,JobMaster 先就收到要执行的应用(客户端发送来的: Jar包、数据流图(dataflow graph)和作业图(JobGraph))。
- JobMaster 会把作业图(JobGraph)转换成一个物理层面的数据流图,这个图被叫做 “执行图 ” (ExecutionGraph),它包含了所有可以并发执行的任务(可以并行执行多少任务,就分配给几个 TaskManager 的 TaskSlot 去)。JobManager 会向资源管理器(ResourceManager 注意:是Flink的资源管理器不是 YARN)发送请求,申请执行任务所需要的资源(如果资源不足,要么直接挂掉,要么就等待)。获得足够的资源后,就会将执行图(ExecutionGraph)发送给真正运行它们的 TaskManager 上。
- 在运行过程中,JobMaster 会负责所有需要中央协调的操作,比如检查点(checkpoint)的协调(定期做一个存盘,防止发生故障,状态丢失掉)。
ResourceManager
这里的 ResourceManager 指的是 Flink 自带的 ResourceManager ,当然也可以用 YARN 这样的资源管理平台来代替管理。
- 一个 Flink集群中,只有一个 ResourceManager ,所谓的资源,指的就是我们的 任务槽(TaskSlot) 。TaskSlot 是能够执行并行任务的最小单位,它包含了机器用来执行计算的一组 CPU 和 内存资源。每个并行的任务都会分配到一个任务槽上去执行。
- 在有 YARN 做资源提供平台的情况下,当新的作业申请资源时,ResourceManager 会将有空闲槽位的 TaskManager 分配给 JobMaster。如果 ResourceManager 没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源。
Dispatcher
- Dispatcher 主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中并不是必需的,在不同的部署模式下可能会被忽略掉(比如和一些资源管理平台集成起来之后,因为资源管理平台可以接受作业的提交)。
2、TaskManager
每一个 TaskManager 可以看做是一个 JVM 进程。
- 真正的工作者,在一个 Flink 集群中通常有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Task Slot 的数量限制了 TaskManager 能够并行处理的任务数量。
- 启动之后,TaskManager 回向 RsourceManager 注册自己的 TaskSlot (汇报自己有多少可用的资源),收到 RsourceManager 的指令后,TaskManager 就会将一个或多个 TaskSlot 提供给 JobMaster 去调用。JobMaster 就可以向 TaskSlot 分配任务(Tasks)去执行了。
- 在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
Flink 作业提交流程
1、抽象视角
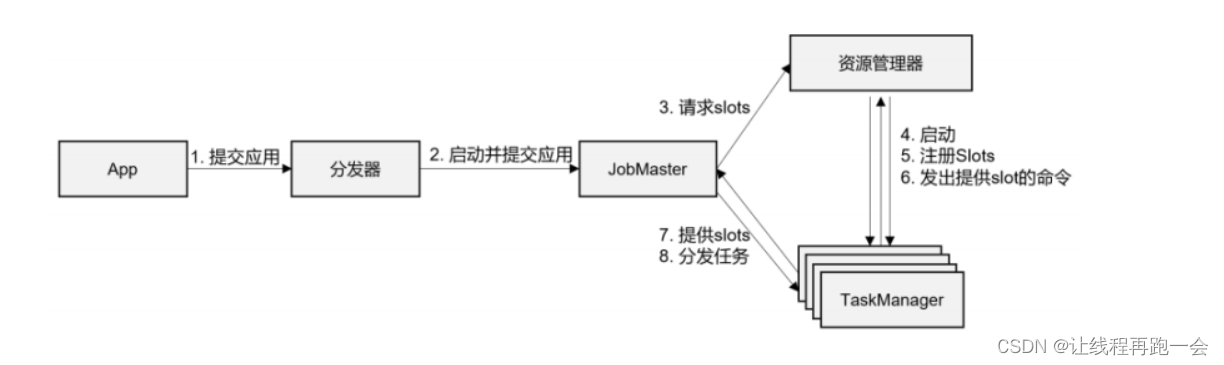
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager(提交给 JobManager 的作业已经被处理过了,代码已经被解析成了作业)。
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器(Flink自带的ResourceManager或者YARN)请求资源(taskslots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5)TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
(6)资源管理器通知 TaskManager 为新的作业提供 slots。
(7)TaskManager 连接到对应的 JobMaster,提供 slots。
(8)JobMaster 将需要执行的任务分发给 TaskManager。
(9)TaskManager 执行任务,互相之间可以交换数据。
2、独立模式(Standalone)
独立模式,就是不借助外部资源管理框架的模式。在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式(单作业模式在Flink中是无法直接运行的,需要借助外部资源管理框架如YARN等)。
会话模式和应用模式的流程是相似的:TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的请求时,会直接要求 TaskManager 提供资源。而 JobMaster 的启动时间点,会话模式是预先启动(集群先启动再等待作业的提交),应用模式则是在作业提交时启动(而且应用模式下,代码是在 JobManager 中运行的,所以客户端只提交代码,真正的作业图是由JobManager执行代码后生成的)。
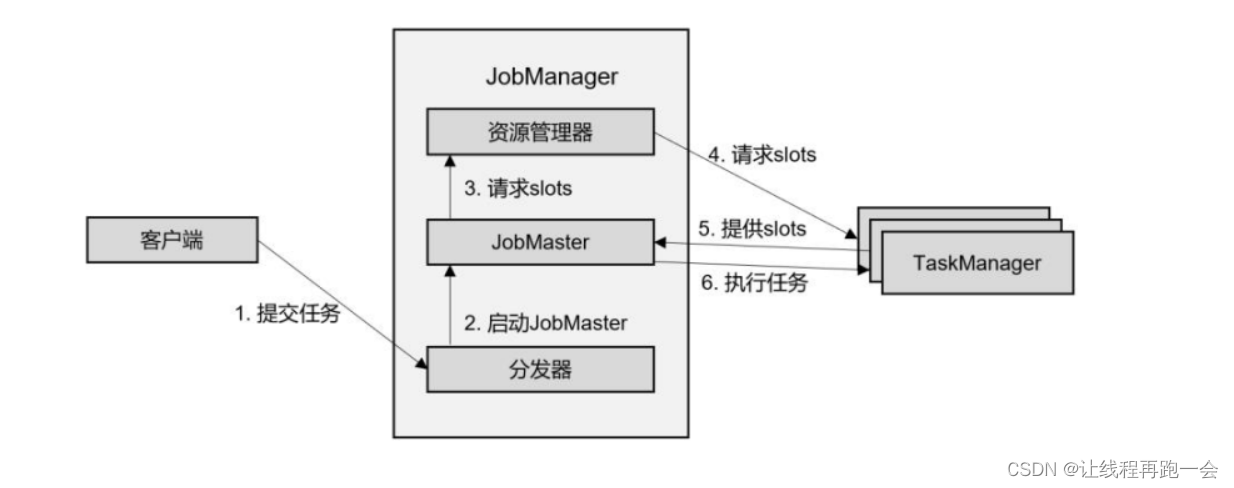
主要注意如果资源不足的情况下,会话模式是无法再去启动 TaskManager 的,因为集群是提前启动好的,资源数量是固定的。
3、YARN 模式
3.1、会话模式(yarn-session)
在会话模式下,我们需要先启动一个 YARN session,这个会话会创建一个 Flink 集群。

这里只启动了 JobManager,而 TaskManager 可以根据需要动态地启动。在 JobManager 内部,由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行(JobMaster 并没有启动,因为我们知道,一个JobMaster 对应一个作业,而一个作业流图中可能包含多个作业,就绪需要启动多个 JobMaster)。

(1)客户端通过 REST 接口,将作业(代码已经被客户端运行,已经生成了作业图和数据流图)提交给分发器。
(2)分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 向资源管理器请求资源(taskslots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器(因为Flink 的资源管理器是没有资源的,所以需要和 YARN 去申请),其他的和上面的抽象流程几乎完全一样。
3.2、单作业模式(per-job)
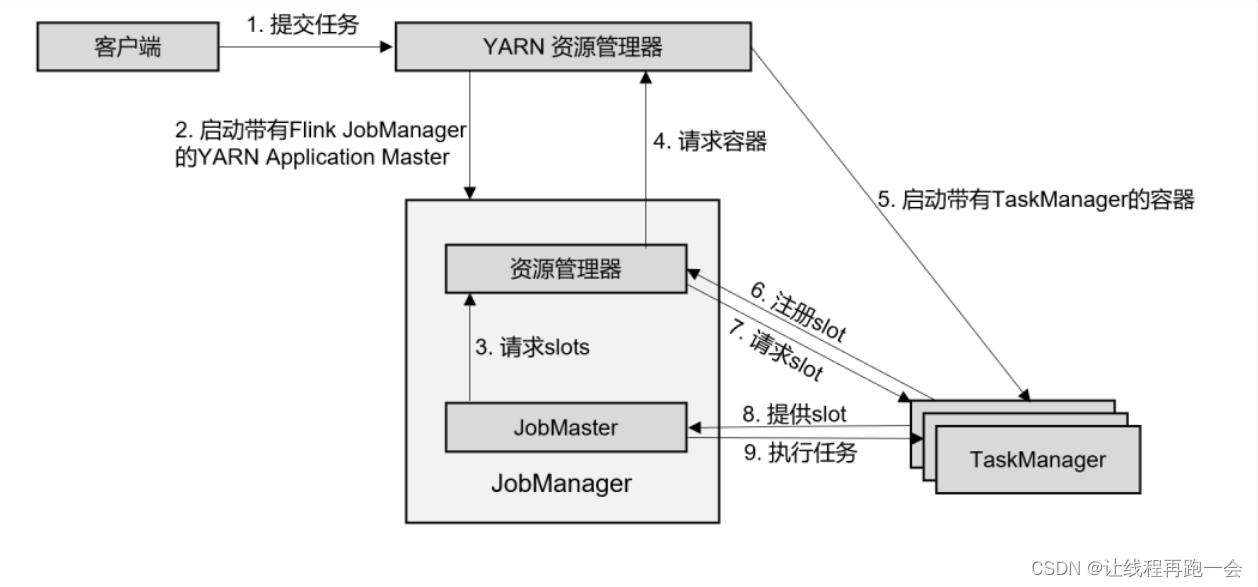
(1)客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
(2)YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件。
(3)JobMaster 向资源管理器请求资源(slots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,JobManager 是由 YARN 来启动的;而 JobMaster是由YARN的ApplicationMaster创建的;在YARN模式下,Flink的JobManager会作为YARN的一个ApplicationMaster运行,并由YARN的ResourceManager管理和调度。
当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
Flink 运行时的重要概念
1、数据流图(DataFlow)
所有的 Flink 程序都是可以由三部分组成的:Source、Transformation 和 Sink 。
其中,Source 负责读取数据,Transformation 负责利用各种算子对数据进行加工处理,而 Sink 负责数据的输出。
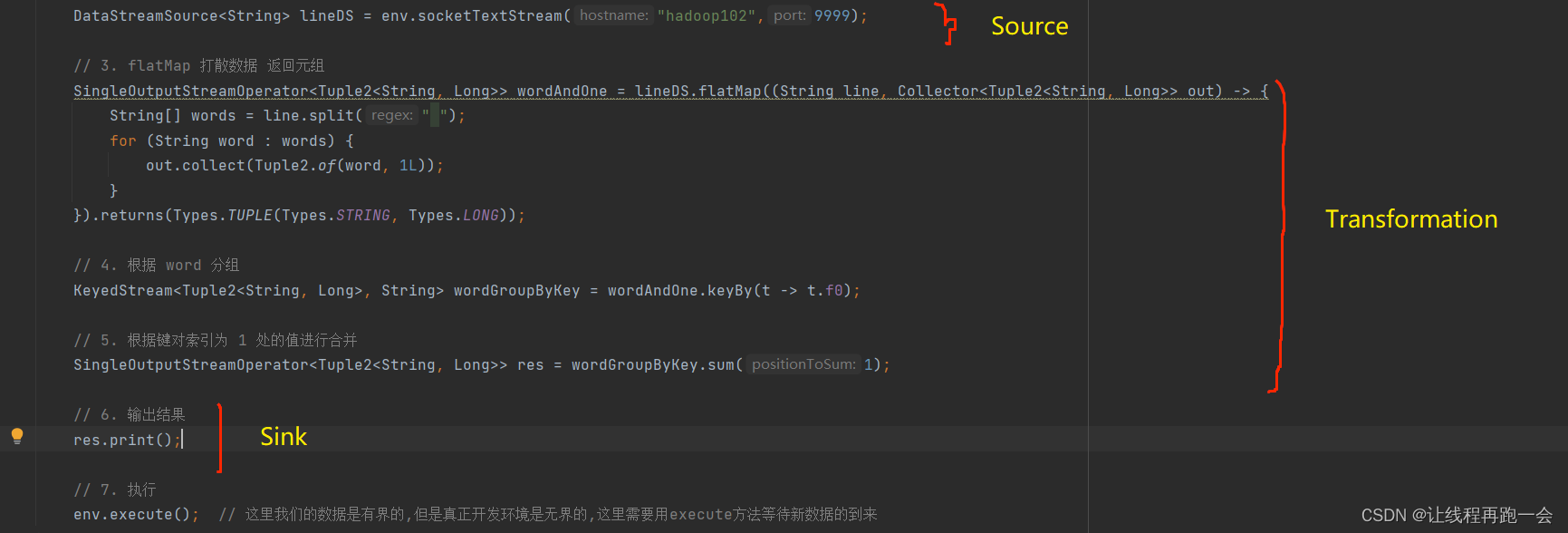
比如上面代码中,Transformation 对应的操作就有:flatMap 和 sum。而 keyBy 并不能算是一个算子(operator),因为 keyBy 的返回值并不是一个 xxxOperator 的类型。
- 在程序运行时,Flink 上运行的应用程序会被映射成“逻辑数据流”(dataflow)
- 每一个 dataflow 以一个或多个 sources 开始,以一个或多个 sinks 结束。dataflow 类似于任意的有向无环图(DAG)
- 在大部分情况下,程序中的转换运算(transformation)跟 dataflow 中的算子(operator)是一一对应的关系
我们以 Standalone 模式启动我们的 Flink 集群(standalone模式提供的 Web UI 是我们 master 的8081端口,也就是hadoop102:8081),提交我们上面的代码。

我们可以看到,keyBy 和 sum 操作被看做一个算子操作(Keyed Aggregation)。
2、并行度(parallelism)
并行度针对的我们的某一个算子的操作而言的,所以不同的操作往往并行度并不相同,比如我们上面数据流图中 source 的并行度就是 1 而 flatMap 、keyed Aggregation 和 sink 操作的并行度都是 2。
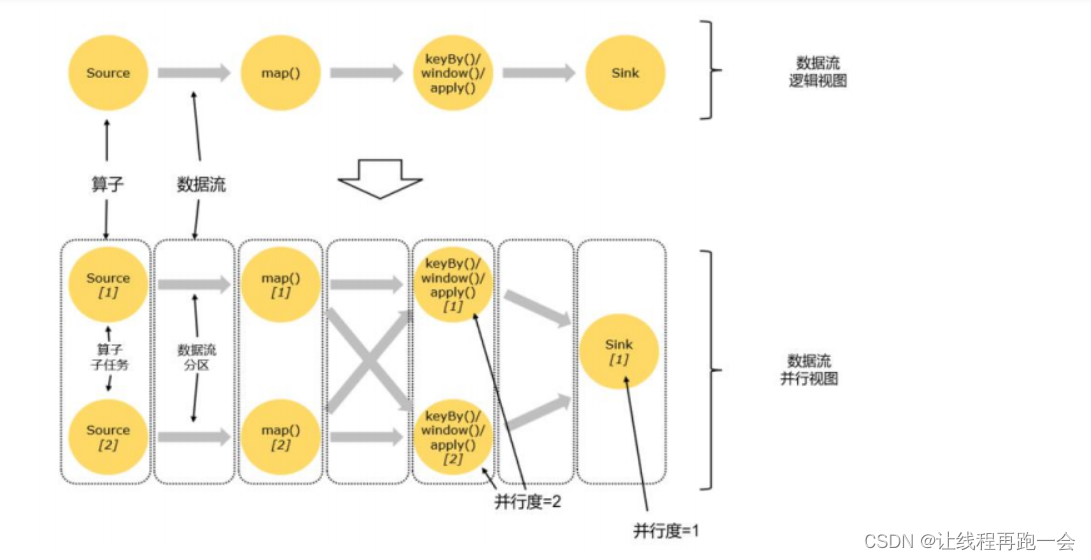
- 每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些算子任务在不同的线程(一个TaskManager 可以看做一个JVM进程)、不同的物理机或者不同的容器中完全独立低运行。
- 一个特定的算子的子任务(subtask)被称之为其并行度。
任务并行
- 比如上面的图中,一共有4个任务:source、map、keyBy-window-aply 和 sink,它们 4 个是完全并行执行的。
如果数据量很大,我们的这些个任务显然是满足不了的,比如来100亿个数,这样不管是 source 读取的时候还是后面的 map 操作,尽管都是并行执行,但面对这么大的数据量还是能力有限的。
数据并行
- 同一个操作(同一个算子,比如 source、map、sink 等)可以复制多份(也就是并行子任务,比如上面复制了多个source),同时来进行数据的处理。
像我们 Spark 的话是按照阶段进行的,所以前后不同阶段的任务没法并行。
而我们也可以在算子的相关代码中进行设置(setParallelism方法)。
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).setParallelism(2).returns(Types.TUPLE(Types.STRING, Types.LONG));另外,我们也可以直接调用执行环境的 setParallelism()方法,全局设定并行度(并不提倡):
env.setParallelism(2);
相当于在 Web UI 端:
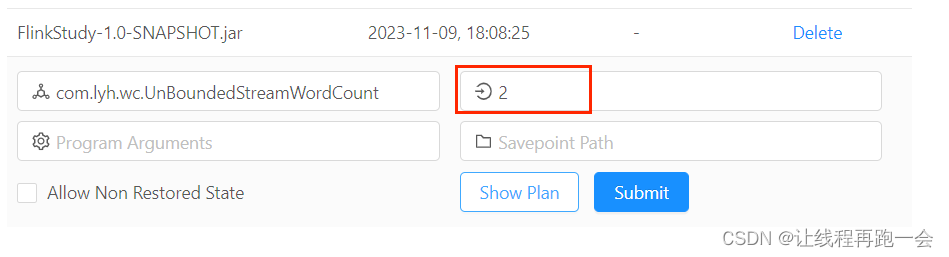
优先级:集群环境conf/flink-conf.yaml中paralleism.default=x 的值 < Web 端 < 全局并行度 < 代码中每个算子设置的并行度
还有一种 特殊的,比如之前我们用到的读取 socket 文本流的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么设置,它在运行时的并行度都是 1,对应在数据流图上就只有一个并行子任务。
3、算子链(Operator Chain)
仔细观察上面Web UI 的这个计划图,可以看到,并不是每个算子单独作为一个任务。很明显,最后一步把两个任务合并成了一个大任务。
算子之间的数据传输
一个程序中,不同的算子可能有不同的并行度。
如上图所示,一个数据流在算子(不同任务)之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing,图中的交叉线)模式,具体是哪一种形式,取决于算子的种类。
1、一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的 source 和 map 算子,source算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap 等算子都是这种 one-to-one的对应关系。这种关系类似于 Spark 中的窄依赖。
2、重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比图中的 map 和后面的 keyBy/window 算子之间(这里的 keyBy 是数据传输算子,后面的 window、apply 方法共同构成了 window 算子),以及 keyBy/window 算子和 Sink 算子之间,都是这样的关系。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。这些传输方式都会引起重分区(redistribute)的过程,这一过程类似于 Spark 中的 shuffle。总体说来,这种算子间的关系类似于 Spark 中的宽依赖。
合并算子链
什么样的算子任务可以合并成一个算子链呢(大的任务)?
在 Flink 中,并行度相同 的 一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分。每个 task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
在上面的图中,Source 和 map 之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为 2,所合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有 5 个任务(source+map * 2,keyBy-window-apply * 2,sink * 1),由 5 个线程并行执行。
Flink 为什么要有算子链这样一个设计呢?
这是因为将算子链接成 task 是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。Flink 默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置
我们说 并行度相同且一对一的算子操作可以合并,但是为什么我们上面的 flatMap 和 keyed Aggregation 并没有合并?
这是因为 flatMap 和 keyBy 这两种算子就不是一个 one to one 的传输方式,所以就不能合并。所以两个任务之间的箭头中间写着 "HASH" ,因为 keyBy 是基于 key 的 hashcode 分区的。
4、执行图(ExecutionGraph)
Flink 中任务调度执行的图,按照生成顺序可以分成四层:逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)
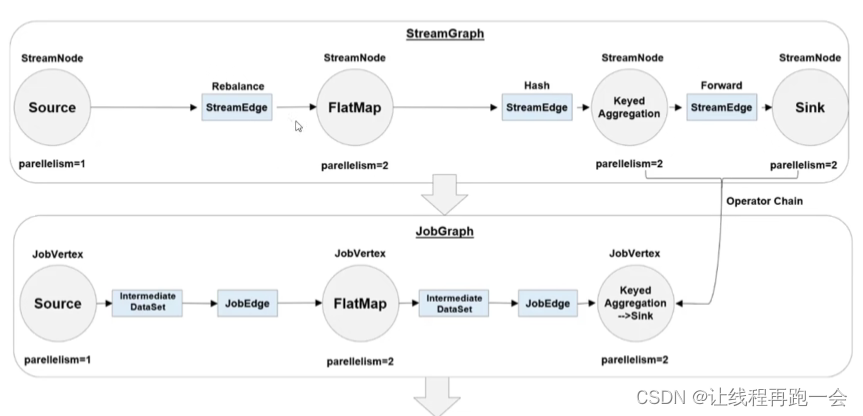
1. 逻辑流图(StreamGraph)
这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图,用来表示程序的拓扑结构。这一步一般在客户端完成(会话模式和单作业模式)。我们可以看到,逻辑流图中的节点,完全对应着代码中的四步算子操作:源算子 Source(socketTextStream())→扁平映射算子 Flat Map(flatMap()) →分组聚合算子Keyed Aggregation(keyBy/sum()) →输出算子 Sink(print())。
2. 作业图(JobGraph)
StreamGraph 经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为: 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph 一般也是在客户端生成的,在作业提交时传递给 JobMaster。
比如我们上面的分组聚合算子(Keyed Aggregation)和输出算子 Sink(print)并行度都为 2,而且是一对一的关系,满足算子链的要求,所以会合并在一起,成为一个任务节点。
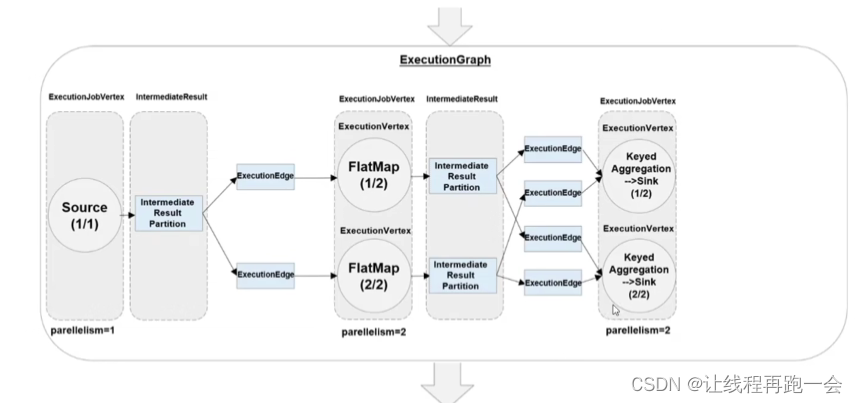
3. 执行图(ExecutionGraph)
JobMaster 收到 JobGraph 后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是 JobGraph 的并行化版本,是调度层最核心的数据结构。与 JobGraph 最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
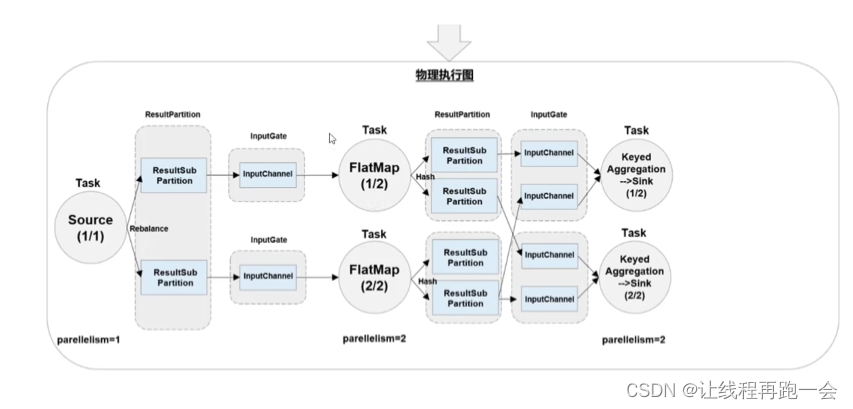
4. 物理图(Physical Graph)
JobMaster 生成执行图后, 会将它分发给 TaskManager;各个 TaskManager 会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager 就可以对传递来的数据进行处理计算了。
5、TaskSlots
上面我们的代码生成的最终作业图是这样的:
作业被划分为 5 个并行子任务(source *1 ,flatMap *2 ,keyed Aggregation+sink *2),需要 5 个线程并行执行。那在我们将应用提交到 Flink集群之后,到底需要占用多少资源呢?是否需要 5 个 TaskSlot 来运行呢?
但事实上,只占用了 2 个Task Slot !
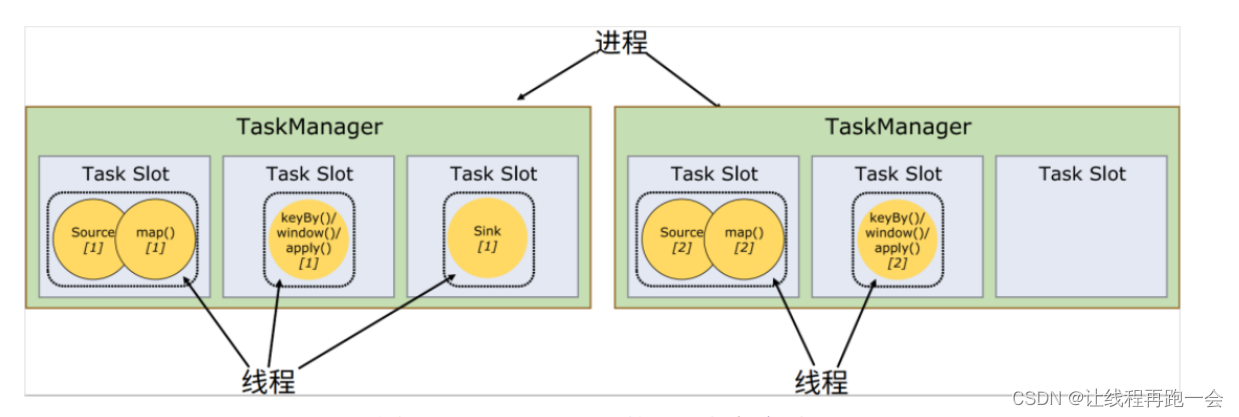
我们知道,Flink 中每一个 worker节点(也就是 TaskManager)都是一个 JVM 进程,它可以启动多个独立的线程(注意:并不是一个TaskSlot就是一个线程,一个TaskSlot也可以是多个线程),来并行执行多个子任务(subtask)。所以如果想要执行 5 个任务,并不一定非要 5 个 TaskManager,我们可以让 TaskManager多线程执行任务。如果可以同时运行 5 个线程,那么只要一个 TaskManager 就可以满足我们之前程序的运行需求了。很显然,TaskManager 的计算资源是有限的,并不是所有任务都可以放在一个 TaskManager上并行执行。并行的任务越多,每个线程的资源就会越少。那一个 TaskManager 到底能并行处理多少个任务呢?为了控制并发量,我们需要在 TaskManager 上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了 TaskManager 拥有计算资源的一个固定大小的子集(主要还是内存,至于cpu主要取决于机器的硬件配置,如果是多核处理器当然最好的分配方式就是一个TaskSlot一个核了)。这些资源就是用来独立执行一个子任务的。
为什么我们 5 个任务只用了 2 个 TaskSlot 就能够跑起来呢?
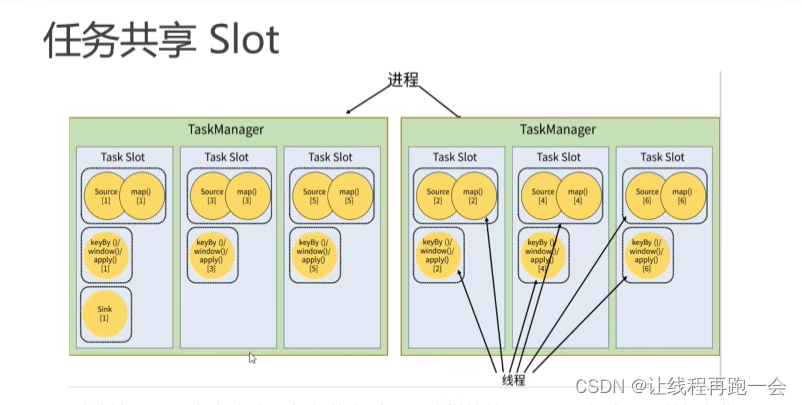
上图是我们假设我们的并行度是 6 ,那对于上面 2 个 TaskManager、每个有 3 个 slot 的集群配置来说,难道就需要 并行度*任务数=6*5 = 30 个TaskSlot 才能正常运行吗?
其实上面的 6 个TaskSlot 就够用了,这是因为默认情况下,Flink 是允许子任务共享 slot 的。这样的结果就是,一个 TaskSlot 可以保存作业的整个管道。
这样的好处就是,当资源密集型(比如 keyby+window+apply)和非密集型(比如source+map)的任务同时放到一个 TaskSlot 中,它们就可以自行分配对资源占用的比例,从而保证最重的活分配给所有的 TaskManager。这样其实反而要比一个任务一个 TaskSlot 的分配方式更好一点,为什么呢?
因为在之前 TaskSlot 不做资源共享的时候,每个任务都平等地占据了一个 TaskSlot ,但是对于非密集型任务,它并不需要多少计算资源,像读取转换这种操作是很快的。但是对于资源密集型任务,比如 window 往往会涉及大量的数据、状态存储和计算,往往需要耗费大量的时间。而上游的 source+map 任务很可能任务轻松的话,早早的忙完就没事干了。这样资源的利用就出现了极大的不平衡,“忙的忙死,闲的闲死”。
解决的办法就是共享 TaskSlot 的计算资源,这样非资源密集型的任务完成之后,就可以也来帮忙完成资源密集型的任务。这样,当我们将资源密集型和非密集型的任务同时放到同一个 TaskSlot 后,它们就可以自行分配资源占用的比例,从而保证最重的活平均分配给每个 TaskSlot 。
还有一个好处就是,当我们每个 TaskSlot 都保存了我们整个作业的所有任务后,即使别的 TaskManager 挂了 导致 TaskSlot 跟着挂了,那由于我们别的 TaskSlot 都包含整个作业的所有任务,这样我们的作业仍然可以完成,无非就是多忙一会罢了。
所以,一个作业的并行度(也就是它占据的 TaskSlot 的数量)取决于我们作业中最大子任务的并行度(因为要保证每个TaskSlot 保存所有任务嘛)。
这就是为什么 2 个 TaskSlot 就可以把我们的任务跑起来,上面我们一共有5个子任务,我们只用了 2 个TaskSlot,其中每个 TaskSlot 的任务如下:
TaskSlot1:SourceFlat MapKeyed Aggregation -> Sink(算子链)TaskSlot2:Flat MapKeyed Aggregation -> Sink(算子链)由于 socket 不支持并行处理,所以对于并行度为 1 的算子任务仍然只在一个TaskSlot 上,但往往这种任务不需要多少的计算资源。
TaskManager 的任务槽数量的设置
vim ./conf/fink-conf.yaml
taskmanager.numberOfTaskSlots: 1建议根据自己的 cpu 核数和虚拟机分配的内存来决定,学习阶段我觉得够用就行。
TaskManager 的并行度设置
vim ./conf/fink-conf.yaml
parallelism.default=1下面举个案例,我们设置集群的每个 TaskManager 的任务槽数为 3,并行度为 1 。
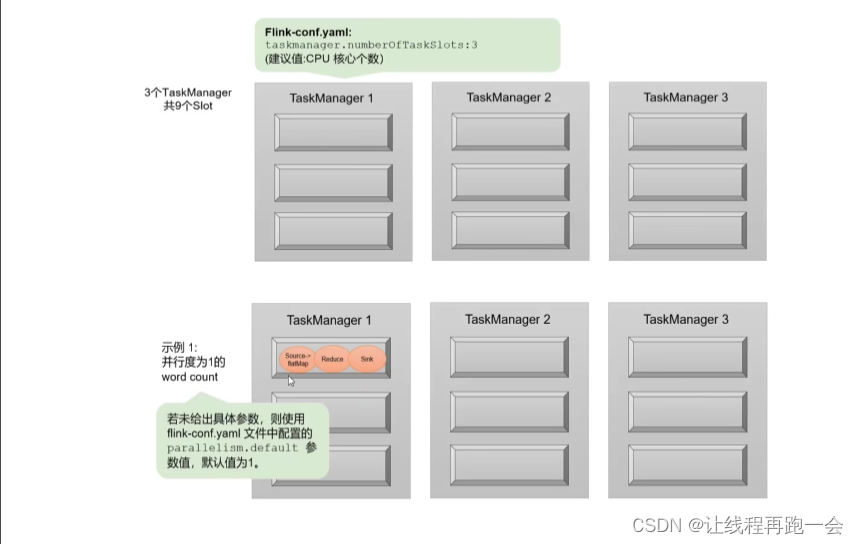
这样当我们提交一个作业上去的时候,因为任务是共享Slot的,而且我们设置的并行度为 1 ,所以只会在一个TaskSlot里执行,这显然不能够发挥我们集群的性能。但是小数据量当然是没有问题的。
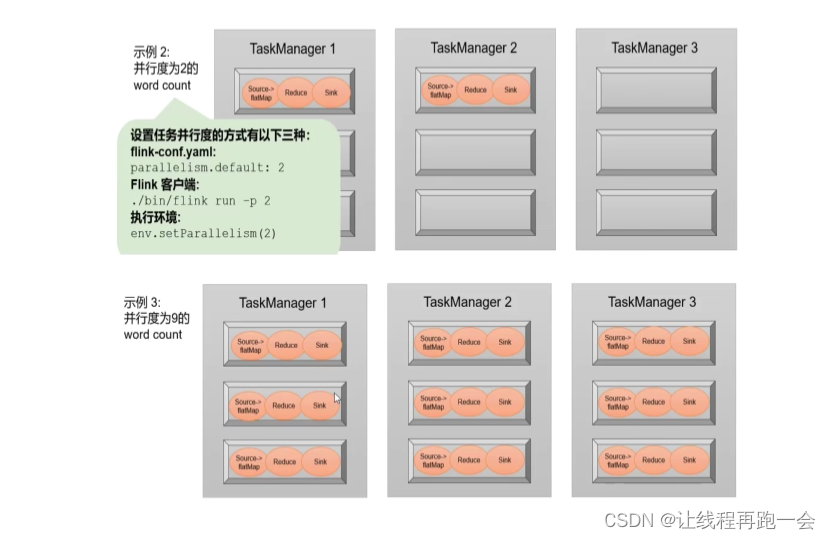
最好的并行度设置就是设置并行度为我们集群的 TaskSlot 的数量,这样的计算效率是最高的。
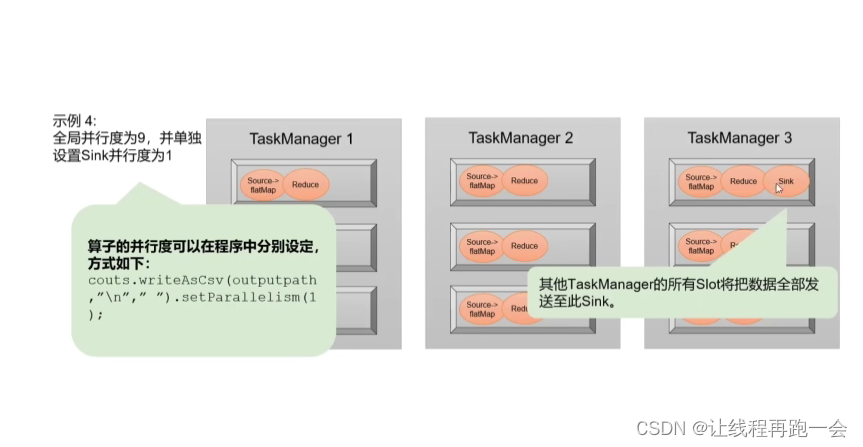
也可以通过上面的代码设置单个算子任务的并行度。
扩展
我们在实际应用的过程中也可以按照我们自己的思路来设置运行时的架构,比如每个TaskSlot就执行一个算子任务,不让它保存整个作业的所有任务;再比如不把可以合并的算子操作合并成一个算子链。
下午更新
相关文章:
Flink(三)【运行时架构】
前言 今天学习 Flink 的一些原理性的东西,比较偏概念,但是十分重要。有人觉得上来框框敲代码才能学到东西,那是狗屁不通的道理(虽然我以前也这么认为)。个人认为,学习 JavaEE那些框架,你上来就敲…...

conda添加清华镜像源
一、conda下载 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 显示所有channel conda config --show channels 二、添加清华镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://…...
「Verilog学习笔记」求两个数的差值
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 timescale 1ns/1ns module data_minus(input clk,input rst_n,input [7:0]a,input [7:0]b,output reg [8:0]c );always (posedge clk or negedge rst_n) begin if (~rst_…...
微头条项目实战:通过postman测试登录验证请求
1、CrosFilter package com.csdn.headline.filters; import jakarta.servlet.*; import jakarta.servlet.http.HttpServletResponse; import java.io.IOException; public class CrosFilter implements Filter {/*** 过滤器方法,用于处理HTTP请求* param servletReq…...

ARCGIS SERVER WMS、WFS服务添加过滤条件
我们知道geoserver中的wms,wfs过滤参数为cql_filter。比如过滤字段“mc”为"恒宇花园"的数据: cql_filtermc‘恒宇花园 但是arcgis server有所不同。具体可以看下它的标准:使用 WMS 请求中的 layerDefs 参数过滤要素—文档 | ArcGIS Enterpris…...

2013年108计网
第33题 在 OSI 参考模型中, 下列功能需由应用层的相邻层实现的是()A. 对话管理B. 数据格式转换C. 路由选择D. 可靠数据传输 很显然,题目所问的应用层的相邻层是表示层。该层实现与数据表示相关的功能。选项a中的对话管理属于会话层。选项c中的路由选择属于网络层。…...

【数据结构】单链表OJ题(一)
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 文章目录 前言一、移除链表元素二、寻找链表中间结点三、输出链表倒数第k个结点四、反转单链表五…...

2023年云计算发展趋势浅析
云计算的概念 云计算是一种通过互联网提供计算资源和服务的模式。它允许用户通过网络访问和使用共享的计算资源,而无需拥有或管理这些资源的物理设备。云计算的核心理念是将计算能力、存储资源和应用程序提供给用户,以便随时随地根据需要…...
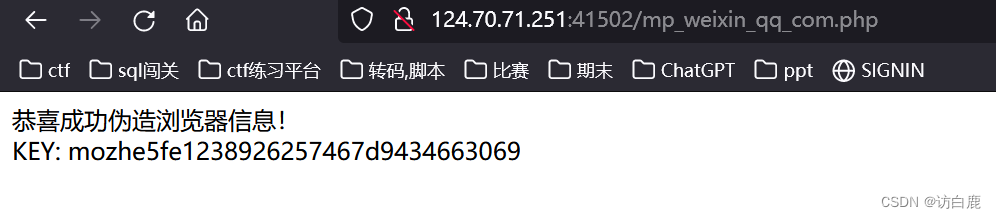
[极客大挑战 2019]Http1
打开题目 没有发现什么,我们查看源代码 在这里我们发现了提示 访问一下页面得到 提示说不能来自于https://Sycsecret.buuoj.cn,我们尝试访问一下这个url 发现访问不了 我们bp抓包一下 伪造个referer头 referer:https://Sycsecret.buuoj.cn 发包过去…...
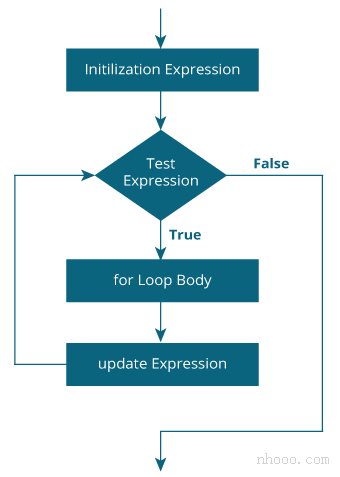
C 语言 for循环
C 语言 for循环 在本教程中,您将借助示例学习在C语言编程中创建for循环。 在编程中,循环用于重复代码块,直到满足指定条件为止。 C语言编程具有三种循环类型: for 循环while 循环do… while 循环 我们将在本教程中学习for循环…...

浅谈数据结构之链表
链表是一种灵活的数据结构,有单向链表、双向链表和循环链表等多种形式。在本文中,我们将深入探讨单向链表、双向链表、循环链表的定义、Java实现方式、使用场景,同时比较它们的不同之处。我们还会介绍链表与队列之间的区别。 单向链表 定义…...

封装一个 虚拟列表渲染 组件
组件代码 <template><div ref"list" class"infinite-list-container" scroll"scrollEvent($event)"><div class"infinite-list-phantom" :style"{ height: listHeight px }"></div><div class…...

Spring中@Bean标注的方法是如何创建对象呢?
Bean 标注的方法如何创建对象呢? 参考文章:https://blog.csdn.net/qq_35971258/article/details/128241353 下边只讲一下 Bean 注解标注的方法,是如何去进行创建 bean,以及流程是怎样的,如果需要看源码具体执行流程&a…...

伦敦金股票代码是什么?
伦敦金是跟踪实时的现货黄金价格走势的差价合约交易,它的代码一般是LLG、GOLD,但也有一些货币交易平台会显示为XAU。伦敦金不是股票交易,因此没有四位数或六位数的股票代码,但伦敦金交易品种单一,投资者不用在数千支股…...

【环境装配】Anaconda在启动时闪现黑框,闪几次后仍能正常使用,解决黑框问题
anaconda闪黑框这个问题遇到好久了,也没找到相关资料来解决,今天做了两个更新,刚好可以不闪黑框了,记录一下。 更新anaconda 在界面右上角的位置点击更新,更新完后再打开时只闪现两个黑框了,之前好像有五…...

【Python】Python爬虫使用代理IP的实现
前言 在爬虫的过程中,我们经常会遇到需要使用代理IP的情况。比如,针对目标网站的反爬机制,需要通过使用代理IP来规避风险。因此,本文主要介绍如何在Python爬虫中使用代理IP。 一、代理IP的作用 代理IP,顾名思义&…...

盘点U-Mail邮件系统安全设计
在当今社会,电子邮件已经成企业沟通和信息传递重要的手段之一,是企业办公中不可或缺的一部分。但是由于企业邮件服务器端口对外开放、企业邮件安全管理能力不足、邮件内容敏感性高等特点,电子邮件也成为了网络攻击者进行网络钓鱼、恶意软件传…...
Webpack--动态 import 原理及源码分析
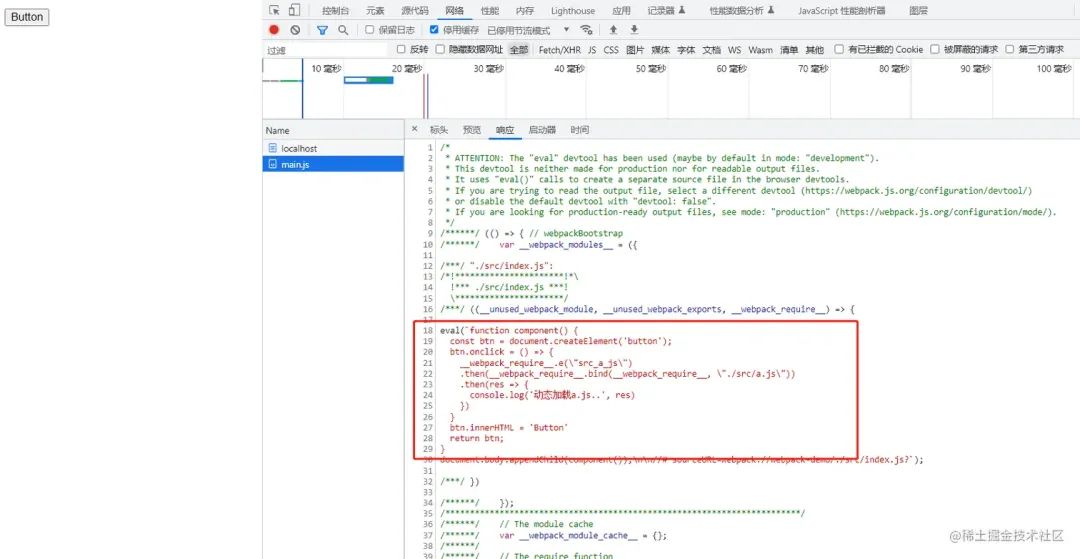
前言 在平时的开发中,我们经常使用 import()实现代码分割和懒加载。在低版本的浏览器中并不支持动态 import(),那 webpack 是如何实现 import() polyfill 的? 原理分析 我们先来看看下面的 demo function component() {const btn docume…...
创新无处不在的便利体验——基于智能视频和语音技术的安防监控系统EasyCVR
随着科技的迅猛发展,基于智能视频和语音技术的EasyCVR智能安防监控系统正以惊人的速度改变我们的生活。EasyCVR通过结合先进的视频分析、人工智能和大数据技术,为用户提供了更加智能、便利的安全保护体验,大大提升了安全性和便利性。本文将介…...

强化IP地址管理措施:确保网络安全与高效性
IP地址管理是网络安全和性能管理的关键组成部分。有效的IP地址管理可以帮助企业确保网络的可用性、安全性和高效性。本文将介绍一些强化IP地址管理的关键措施,以帮助企业提高其网络的安全性和效率。 1. IP地址规划 良好的IP地址规划是强化IP地址管理的基础。它涉及…...

AI抢人大战白热化:年薪百万难求,应届生月薪12万,你被“卷”了吗?
“我们也想要AI高手,但确实要不起。” 说这话的是北京某上市游戏公司的招聘负责人景阳,“应届生中的AI高手非常抢手。往年,招一个应届AI Golang工程师,月薪均值10-15k已经很高了。今年呢?现在这个月份,很多…...

永磁同步电机智能控制技术:模糊逻辑与神经网络应用
1. 永磁同步电机智能控制技术演进永磁同步电机(PMSM)作为现代工业驱动系统的核心部件,其控制性能直接影响着电动汽车、工业机器人等高精度应用场景的能效表现。传统PID控制在面对参数变化和外部扰动时表现出的局限性,促使研究者将目光转向更具鲁棒性的控…...

多类别不平衡分类问题与SMOTE技术实践
1. 多类别不平衡分类问题概述在机器学习实践中,我们经常会遇到类别分布不均衡的分类问题。这类问题中,某些类别的样本数量可能远多于其他类别,导致模型训练时倾向于忽略少数类。虽然大多数关于不平衡分类的研究都集中在二分类问题上ÿ…...

为什么92%的.NET团队在AOT迁移中失败?揭秘C# 14原生AOT部署Dify客户端的7个隐性陷阱
第一章:C# 14 原生 AOT 部署 Dify 客户端架构设计图C# 14 的原生 AOT(Ahead-of-Time)编译能力为构建轻量、安全、跨平台的 Dify 客户端提供了全新范式。该架构摒弃运行时 JIT 编译与完整 .NET 运行时依赖,将客户端代码直接编译为独…...

AixProbe开源AI远程调试器:第1章 硬件讲解
项目简介 AixProbe 是一款开源 AI 远程调试器,专为嵌入式开发者的远程调试场景设计。它集成了 JTAG/SWD 调试、多路串口通信、ADB 调试、USB 扩展等能力,并通过 AI 辅助提升远程调试效率。 本文为系列教程的第一章,带你全面了解 AixProbe 的硬…...
)
第44篇:AI内容审核与安全——平台如何用AI过滤违规信息?(原理解析)
文章目录现象引入:当内容洪流遇上“红线”提出问题:AI内容审核的三大核心挑战原理剖析:多层联动的AI审核技术栈第一层:文本审核——从词法到语义的理解第二层:图像审核——从像素到概念的解析第三层:视频与…...

3步快速上手:N_m3u8DL-CLI-SimpleG图形界面视频下载实战指南
3步快速上手:N_m3u8DL-CLI-SimpleG图形界面视频下载实战指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 想要轻松下载在线视频却苦于复杂的命令行操作?…...

Docker跨架构调试失效的7个致命信号:从qemu-user-static崩溃到buildx缓存错乱,一文定位根因
第一章:Docker跨架构调试失效的典型现象与认知误区当开发者在 x86_64 主机上构建并运行 ARM64 容器镜像(例如为树莓派或 Apple M1/M2 设备准备服务)时,常遭遇看似“正常启动却无法调试”的诡异状态:docker exec -it /…...

3种高效知乎数据采集方案:突破社交平台API限制的技术实现
3种高效知乎数据采集方案:突破社交平台API限制的技术实现 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 知乎作为中文互联网高质量内容平台,积累了海量的问答数据和用户行为信息。对于…...

别再傻傻分不清了!QA、QE、QC到底谁负责啥?一张图帮你理清软件测试岗位分工
软件测试岗位全解析:QA、QE、QC的核心差异与职业选择 刚踏入软件测试领域的新人,面对QA、QE、QC这些缩写时,往往会感到一头雾水。这些看似相似的岗位名称背后,其实隐藏着完全不同的职责边界和发展路径。记得我刚开始接触这个领域时…...