【云栖2023】王峰:开源大数据平台3.0技术解读
本文根据2023云栖大会演讲实录整理而成,演讲信息如下:
演讲人:王峰 | 阿里云研究员,阿里云计算平台事业部开源大数据平台负责人
演讲主题:开源大数据平台3.0技术解读

实时化与Serverless是开源大数据3.0时代的必然选择
阿里云开源大数据平台孵化于阿里巴巴集团内部业务。早在2009年,我们就开始采用开源 Hadoop 技术体系来服务阿里内部快速发展的电商业务。在阿里巴巴内部这套 Hadoop 技术体系,当时叫云梯一,当发展成熟后,开始上云。我们在阿里云上推出了第一款开源大数据产品 E-MapReduce,简称 EMR 。我们把这个定义为开源大数据平台的第一阶段,也就是1.0的时代,从此刻开始,真正跨入云原生时代。

随着大数据技术的演进,大数据处理从离线技术架构向实时化演进,我们开始引入了Apache Flink 流计算技术。阿里巴巴对 Apache Flink 社区进行了非常大的资源投入,逐渐成为最大的用户和社区推动者。到现在,Apache Flink 发展成为了全球范围内流计算、实时计算的标准。同时,我们在阿里云上也推出了实时计算Flink版的实时计算云产品服务。
EMR 也在不断地技术演进,从传统的 Hadoop 数仓架构升级到围绕以数据湖为核心的云原生数据湖的技术架构,因此我们把实时化和数据湖这两个技术演进的趋势,称为开源大数据平台2.0阶段。
从今年开始,我们在思考下一段开源大数据平台如何发展演进,我们做了以下几个3.0架构的技术探索,以此更好地服务我们的客户。
首先,我们尝试把实时化的技术分析和数据湖的架构进行融合,我们推出了新一代的Streaming Lakehouse 架构,也就是实时化的数仓分析架构。
第二,随着 serverless 的架构落地不断深入,我们开始考虑什么才是云原生架构终态。今年我们将开源大数据平台所有核心的计算、存储组件实现了 serverless 化。
第三,现在已经全面进入AI爆发的阶段,各行各业都开始使用AI的技术进行自我的革新。我们开始考虑AI的融合,希望把新的AI技术引入大数据平台体系中,实现大数据AI一体化的能力,帮助平台智能化运维和数据管理。
从今年开始,我们采用了新的数据分析架构、完全云原生的架构,并深度结合AI结合,开启3.0的新架构。接下来我将选择几个3.0平台中最核心的技术架构特点给大家做分享:我们做了哪些事情,取得哪些成果,以及未来会如何发展。
新一代的流式湖仓
首先介绍一下,新一代的数据分析架构——流式湖仓。我相信绝大部分用户意识到传统 Hadoop Hive 数仓架构的局限性以及技术发展的趋势,都开始将传统的Hadoop技术向着新一代的湖仓分析 Lakehouse 架构进行演进。

显而易见,升级到新的 Lakehouse 数据分析架构以后有很多的优势。比如,新Lakehouse 架构是彻底的存算分离,有更好的扩展性、灵活性。同时,新的数据湖格式也带来了更好的实时支持以及查询性能的提升等。Lakehouse 架构带来的收益明显。
但是 Lakehouse 架构是不是已经完美无缺?我觉得还没有到这个地步。现在我们看到Lakehouse 架构在实时化方向还有进一步发展的空间,这也是众多开源用户在使用 Lakehouse 架构时候遇到的痛点:当数据都迁移到 Lakehouse 这个架构上,如何去更加实时化地加速数据处理管道,如何像传统数仓一样去实时分析 Lakehouse 中的数据。

现在的湖仓,做不到完全的实时化甚至准实时化的效果。究其原因,就是数据湖的存储格式限制了实时化的发展。大家可以看到现在数据湖存储格式主要是 Iceberg、Delta、Hudi 三剑客来构建的,不同的用户和厂商会选择不同的数据库格式。但是Iceberg 和 Delta 是面向批处理而设计的数据湖格式,与批处理的计算引擎配合更多一些,在 Lakehouse 上实现批处理,甚至可能是比较大力度的微批处理,通过merge来更新。这个架构无法彻底实现实时化,或者在实时化的力度上也做不到特别细粒度,比如分钟级的粒度甚至十分钟级的粒度都是非常困难的。
Hudi 的初衷是为了解决这个问题,实现实时化的数据湖格式,提升实时更新,加速数据湖的时效性。但是,目前从架构设计和工程实现效果来看,并没有达到预期,很多客户在使用 Hudi 过程中也踩了很多坑,无论是系统稳定性还是系统的运维复杂度上都面临非常大的挑战。
其实我们可以看到,究其根源还是在湖仓架构上没有一款面向数据实时更新或者实时分析而设计的数据湖格式。去年我们在 Flink 社区进行了技术探索,在 Flink 社区里启动了一个新的子项目叫Flink Table Store,其目的是尝试看PMF(市场的接受程度)。通过Flink Table Store,发现设计一款真正面向实时更新的数据湖格式还是非常有必要的,尤其是跟 Flink 这种实时流式计算引擎配合,完全能在数据湖 Lakehouse 架构上,实现实时化数据链路。
为了让这个项目有更好的发展,我们今年决定把这个项目从Flink社区中独立出来,作为一个独立的 Apache 基金会项目去孵化,使其有一个更大的发展空间,命名为Apache Paimon。
Paimon是真正为实时更新而设计的数据湖格式,并且是完全开放的,不仅支持 Flink,也会支持 Spark、Presto、Channel、StrarRocks 等主流计算引擎。
而且由于设计时天生就是为了实时,所以性能和稳定性都是非常好,在我们典型的应用场景下,与开源 Hudi 方案相比,阿里云流式湖仓方案 Upsert 性能提升超过4倍,Scan 性能提升超过10倍。

因此,基于 Flink 和 Paimon,我们推出新一代的流式湖仓的数据分析技术,从整个数据的实时入湖到湖上实时ETL数据更新,采用一整套统一的SQL在Lakehouse来进行全链路的实时数据处理。由于Paimon的开放性,我们完全也可以在这个架构中引入大家用得比较多的 Spark、Presto、StrarRocks 这些开源分析引擎,也包括阿里云自研引擎MaxCompute、Hologres 都可以和 Paimon 数据进行无缝对接,实现完全开放的湖仓体系,从而整个链路实现完整的生态,不仅能够实现数据全链路的实时流动,也能实现数据全链路的实时分析。这是整个3.0中数据分析架构中的演进趋势,推动湖仓的实时化。

全面 Serverless 化
第二个,想介绍一下产品架构,我们的产品和云原生结合也迈出了重要一步,希望开源大数据平台实现全面的 serverless 化。其实 serverless 这个技术已经探索了有好几年,两年前就推出了开源大数据平台的第一款 serverless 产品—— serverless Flink,在阿里云上有非常多的客户使用。

通过serverless Flink得到很多客户的正向反馈,大家都希望使用开箱即用的开源产品。因此今年我们又推出了四款 serverless 开源大数据产品,两款计算、两款存储。计算型选择了用户呼声最高的 Spark 和 StarRocks,这两款引擎推出了 EMR Serverless StrarRocks 和即将发布的 EMR Serverless Spark 两款计算型 serverless 产品。
同时在存储方面,我们也推出了两款 serverless 产品,第一款是和 OSS 对象存储团队联合合作推出的 OSS-HDFS ,全托管的 serverless HDFS 产品。还有一款是数据湖管理构建产品中推出了完全兼容HMS协议的全托管的 serverless 源数据管理的服务。我们通过这几款产品的组合可以实现几乎所有大数据场景的处理和分析。
为什么一年之内快连续推出四款 serverless 大数据产品,完全得益于我们在技术上做的沉淀。把所有对 serverless 的需求沉淀为大数据 serverless 平台底座,这个平台底座可以屏蔽掉阿里云各种异构硬件和资源池,提供一套完整的多租系统的管理,包括网络隔离、资源隔离等,使得我们可以快速孵化出新的 serverless 大数据产品。
Serverless Flink
第一款产品就是 serverless Flink,它可以连通阿里云上下游的存储,不管是数据库、数据湖,还是数据仓库、消息队列,只要是阿里云上主流的存储数据源都可以一键打通,提供一站式的 SQL 开发平台,包括智能化的运维管理服务,实现开箱即用的效果。同时我们在 serverless Flink 产品中对 Flink 的核心引擎做了大量的优化,并且在阿里巴巴内部大量使用,相对于开源 Flink 引擎有两到三倍的性能提升,所以使用serverless Flink产品不仅是方便提升开发效率,在运行效率上也会大幅节省成本。
今年上半年新推出来另外一个新的 serverless 数据产品就是 serverless StarRocks,主要是解决实时交互式分析 OLAP 场景用户的需求,现在 OLAP 或者实时分析也是热点。我们评估下来目前在开源界内最主流的或者最优秀的 OLAP 引擎是 StarRocks,所以我们选择了 StarRocks 在 EMR 上开通了第一款 serverless OLAP 产品,因为StarRocks 是一个完全向量化的 C++ 引擎,所以性能非常优秀,支持数万的并发。
Serverless StarRocks
同时在最新版本的 StarRocks 中其实也支持存算分离的架构,结合整个产品的云原生能力推出了 Virtual Warehouse 的功能可以兼顾弹性和用户业务之间的隔离性。有了这个存算分离之后,可以将 StarRocks 和数据湖进行打通。流式湖仓会在湖上沉淀出非常多实时更新的数据,这个时候利用 serverless StarRocks 就可以去查询湖上的实时更新数据,即时查询得到一个很好的湖仓一体的效果,称之为大湖小仓的布局。
Serverless Spark
今年还有一款重磅级产品的 serverless 产品就是 serverless Spark。相信 Spark 在开源大数据体系中用得最多的计算引擎,也是现在 EMR 中看到最重要的一款计算引擎。
最近几年,我们不断听到用户的呼声,希望有一款真正全托管免运维 serverless 的Spark 产品,能够帮助客户减轻运维的负担,提升开发的效率,甚至提升运行的效率。因此今年在全面 serverless 化的目标下投入了非常大的资源,做出了 serverless Spark 产品,很快将进行公测和商业化。
Serverless Spark 产品其实是集成了前面两款 Flink 和 StarRocks Serverless 产品的优势,一站式开发和智能化运维都可以实现开箱即用,按量付费完全弹性,包括和数据湖的打通等等。此外我们在Serverless Spark里面还内置了基于 Celeborn 做的一个Serverless 数据服务,这样就可以免除对本地盘的依赖,完全实现整个数据计算的Serverless 化。
Serverless HDFS(OSS-HDFS)
刚才讲了几款 serverless 计算的产品,接下来还有一款产品是非常重要,就是存储的serverless 产品。我们叫 serverless HDFS,官方产品名字是 OSS-HDFS,这是和 OSS 团队一起共建出来的产品形态。
大家都知道 HDFS 已经在大数据业界被大家认为是一款事实标准的文件系统协议,随着越来越多用户把数据搬到数据湖上,同时希望继续使用HDFS协议来访问数据湖上的数据,这样计算都是兼容的。
因此,我们把 OSS 的数据也可以包装成一个看上去像无限大的云 HDFS,这样就可以满足很多用户的需求。所以今年联合 OSS 团队发布了 OSS-HDFS 的 serverless 文件系统,完全兼容 HDFS 。有了这个后,很多用户就不必自己去维护本地HDFS集群,免除了运维的复杂度,而且完全按量付费,有非常好的弹性,结合我们计算的原仓数据可以做智能的数据分析、冷热数据分层,帮助用户更好地降本增效。
刚才也讲了 serverless 是开源大数据3.0中在云原生架构上的进展,未来在 serverless端上会继续推出更多的产品。
更智能的开源大数据
当前 AI 全面爆发,阿里云开源大数据平台也将 AI 技术引入大数据平台体系中,帮助我们做智能化平台运维或者数据管理等。今年,我们升级了智能化运维工具 EMR Doctor、Flink Advisor,并已广泛应用于客户和阿里云内部平台运维,平均集群问题识别时间减少30%,集群资源有效利用率提升75%。
大家知道在 EMR 产品中运维是非常有挑战性的事情,因为 EMR 上有非常多的组件,Hadoop、Hive、Kafka、Spark、Flink、Presto 等,一旦系统出现问题怎么快速地定位问题,是一个非常让用户头疼的事情。甚至有时候即使没有出现问题,用户也希望对整个集群的资源利用率、存储效率进行提升。
之前完全都是靠人肉经验的去沉淀。前些年,我们也投入了很多的工程师帮助客户人肉解决这些问题,但近些年我们都把这些经验和知识沉淀成AI中的知识库、规则库,再结合一些传统机器学习算法和数据分析的方法,进行智能化定位问题,给用户建议,让用户优化集群,解决问题。

此外。在Flink产品中也做了大量的实践,推出了智能诊断的服务 Flink Advisor。可以在开发运维的全生命周期中帮助用户定位,你的任务为什么出错了,出错在哪里,怎么修正、改进。即使在你的任务没有问题的时候也依然对你的任务做健康检测,判断潜在可能出现的风险,类似于健康分这种能力,帮助用户防范于未然,给用户一些智能化的提议,让用户去优化任务。其实这背后都是采用了大数据AI相结合的分析技术做到的。

最后提到AI,我觉得有一个词首先进入开发者的视线,就是向量检索。在AI时代,所有非结构化的数据都可以用向量来表示,关于向量检索的技术也如雨后春笋般层出不穷。目前业界各种开源向量检索技术,经过我们评估后认为 Milvus 这个技术是目前最流行的,也是用户需求量最大的向量检索技术,因此开源大数据平台也将推出全托管 serverless 向量检索服务,基于开源的Milvus生态、阿里云的PAI机器学习平台和各种大模型组成完整的大数据AI一体化的技术解决方案去服务在AI场景下对向量检索有需求的客户。
以上就是关于开源大数据平台3.0的核心技术架构以及技术发展趋势的分享。我们希望这些新技术能够在产品中落地,服务客户,得到客户的反馈。谢谢大家的聆听。
相关文章:
【云栖2023】王峰:开源大数据平台3.0技术解读
本文根据2023云栖大会演讲实录整理而成,演讲信息如下: 演讲人:王峰 | 阿里云研究员,阿里云计算平台事业部开源大数据平台负责人 演讲主题:开源大数据平台3.0技术解读 实时化与Serverless是开源大数据3.0时代的必然选…...

如何改变Wi-Fi的IP地址,提高网络连接稳定性和速度
Wi-Fi已经成为我们日常生活中必不可少的一部分。大多数家庭和办公室都依赖于Wi-Fi来连接网络和进行各种在线活动。然而,有时我们可能会遇到网络连接不稳定或速度较慢的问题。这可能是由于IP地址的设置不当所导致的。虎观代理小二二将向您介绍如何改变Wi-Fi的IP地址&…...
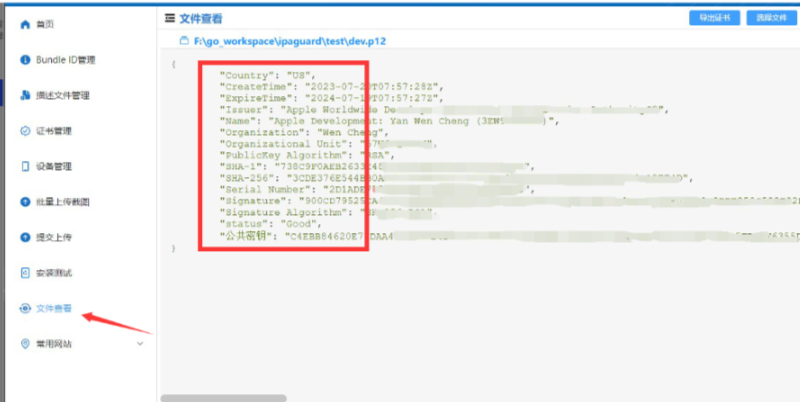
APP 备案公钥、签名 MD5、SHA-1、SHA-256获取方法。
公钥和 MD5 值可以通过安卓开发工具、Keytool、Jadx-GUI 等多种工具获取,最简单的就是以 appuploader为例。 1.下载 appuploader工具 ,点击此处 下载 appuploader 工具。 2.下载完成后,解压压缩包,双击 appuploder 运行。 3.运…...
屏幕提词软件Presentation Prompter mac中文版使用方法
Presentation Prompter for mac是一款屏幕提词器软件,它可以将您的Mac电脑快速变成提词器,支持编写或导入,可以在一个或多个屏幕上平滑地滚动,Presentation Prompter 下载是为适用于现场表演者,新闻广播员,…...

Rc与Arc实现1vN所有权机制
Rc与Arc实现1vN所有权机制 观察引用计数的变化一个例子多线程无力的Rc< T >Arc Rust所有权机制要求一个值只能有一个所有者,在大多数情况下,都没有问题,但是考虑以下情况: 在图数据结构中,多个边可能会拥有同一个…...
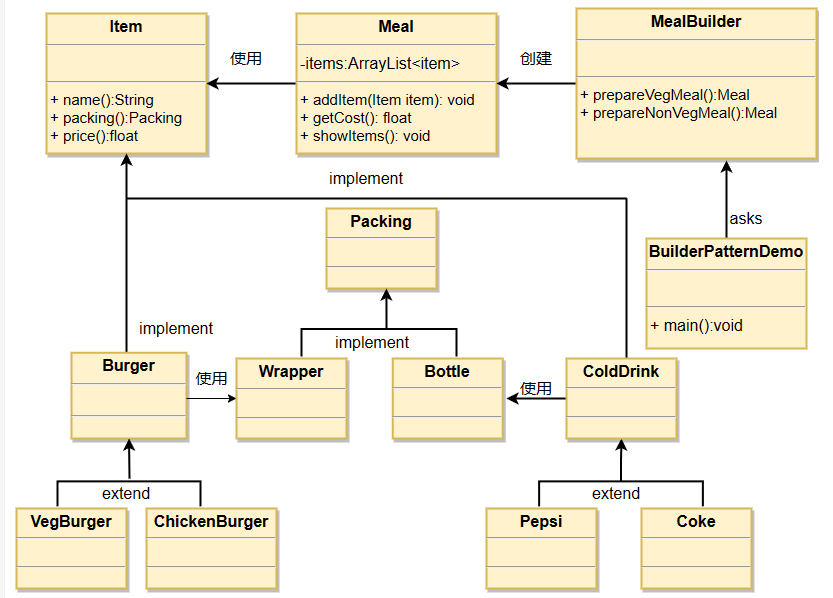
建造者模式 rust和java的实现
文章目录 建造者模式介绍优点缺点使用场景 实现javarust rust代码仓库 建造者模式 建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。 一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。 介绍…...

书写Prompt的经验总结
首先最重要的一点是Prompt无法全部模型都通用,可能你的Prompt在ChatGPT中使用很好,迁移到ChatGLM就不行了。不知道未来是否会出现Prompt的跨平台。 首先书写Prompt要明确告诉模型要做什么,而不是告诉它不要做什么。还要保证精简,…...

WebSocket实时应用
在开发一些前端页面的时候,总是能接收到这样的需求:如何保持页面并实现自动更新数据呢?以往的常规做法,是前端使用定时轮询后端接口,获取响应后重新渲染前端页面,这种做法虽然能达到类似的效果,…...

从零开始搭建React+TypeScript+webpack开发环境-基于lerna的webpack项目工程化改造
项目背景 在实际项目中,我们的前端项目往往是一个大型的Webpack项目,结构较为复杂。项目根目录下包含了各种配置文件、源代码、以及静态资源,整体布局相对扁平。Webpack的配置文件分散在不同的部分,包括入口文件、输出目录、加载…...

网络监控系统和防火墙的区别有哪些?
现如今,市面上保护企业网络安全的设备有很多,其中使用最多的当属网络监控系统和防火墙。 网络监控系统就是通过网页内容的自动采集处理、敏感词过滤、智能聚类分类、主题检测、专题聚焦、统计分析等多个环节,实现相关网络舆情监督管理的需要…...
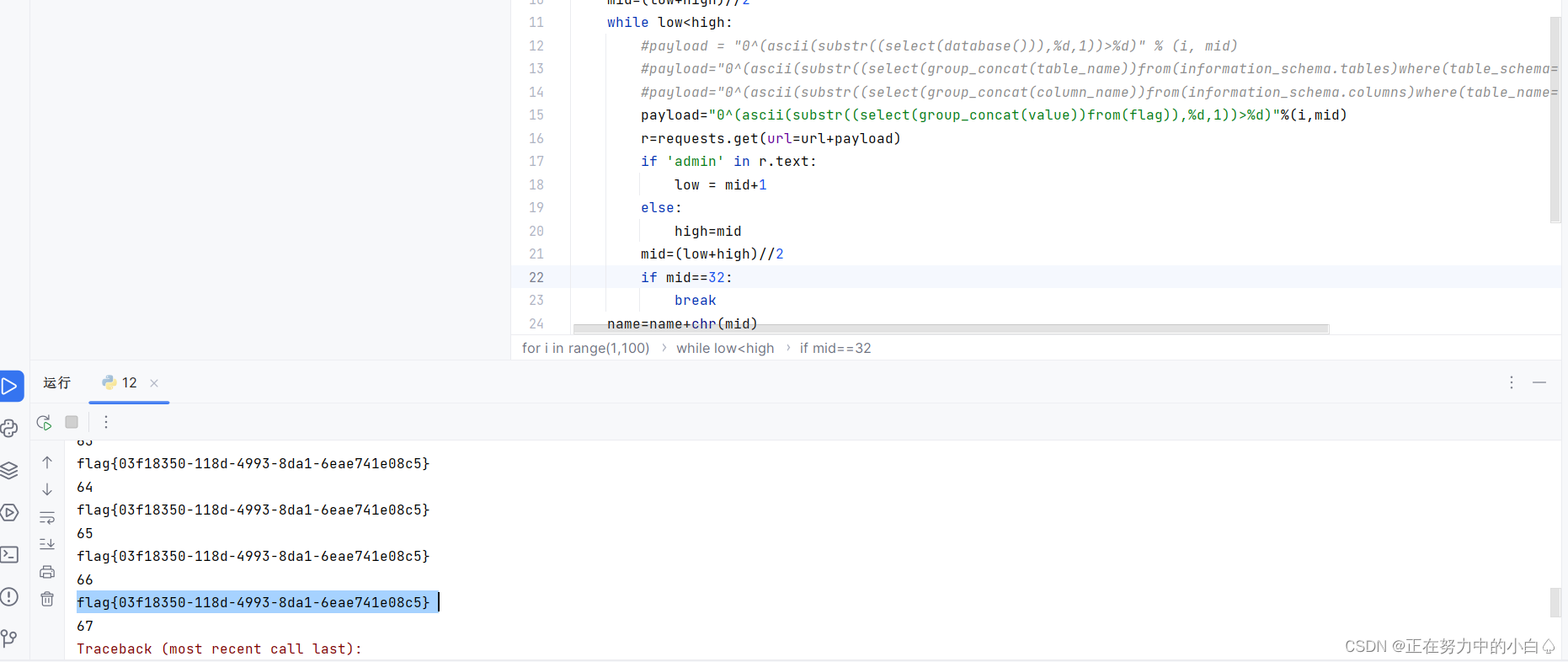
刷题学习记录BUUCTF
[极客大挑战 2019]RCE ME1 进入环境直接就有代码 <?php error_reporting(0); if(isset($_GET[code])){$code$_GET[code];if(strlen($code)>40){die("This is too Long.");}if(preg_match("/[A-Za-z0-9]/",$code)){die("NO.");}eval($co…...

Linux imu6ull驱动- led
一、GPIO模块结构 开始来啃手册了,打开我们的imx6ull手册。本章我们编写的是GPIO的,打开手册的第28章,这一章就有关于IMX6ULL 的 GPIO 模块结构。 mx6ull一共有5 组 GPIO(GPIO1~GPIO5) GPIO1 有 32 个引脚&…...

【 云原生 | K8S 】Kubernetes 概述
Kubernetes 概述 1 K8S 是什么? K8S 的全称为 Kubernetes (K12345678S),PS:“嘛,写全称也太累了吧,不如整个缩写”。 作用: 用于自动部署、扩展和管理“容器化(containerized)应用…...
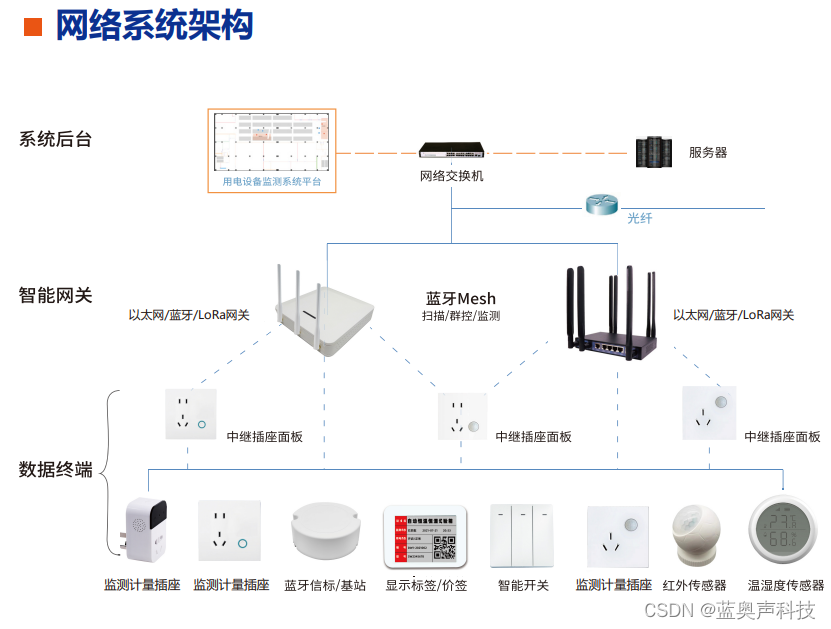
边缘计算多角色智能计量插座:用电监测和资产管理的未来智能化引擎
目前主流的智能插座涵盖了红外遥控(控制空调和电视等带有红外标准的电器),配备着测温、测湿等仓库应用场景,配备了人体红外或者毫米波雷达作为联动控制,但是大家有没有思考一个问题,就是随着对接的深入&…...
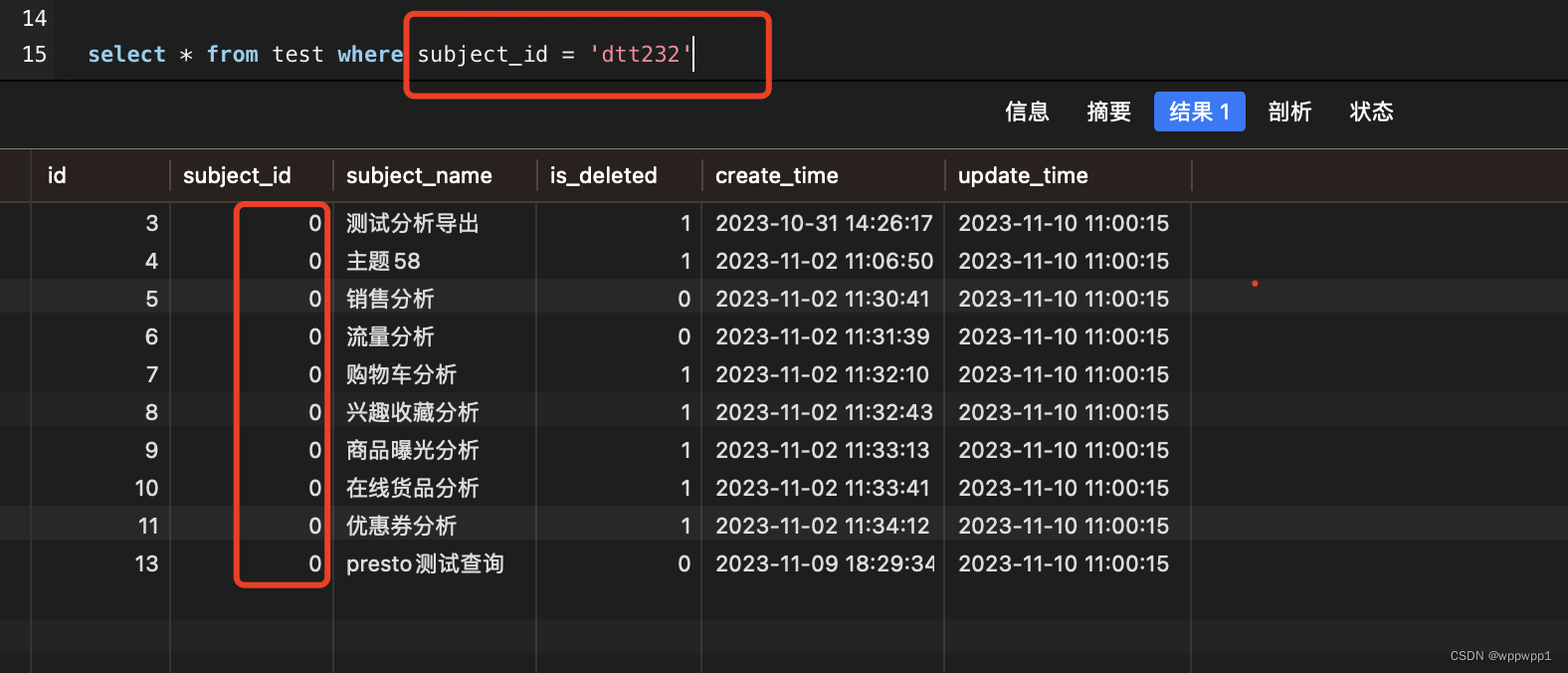
mysql隐式转换转换引起的bug
生产环境中遇到一个情况情况 ,过滤数据发现过滤不掉相关值情况,具体情况如下 原始数据: CREATE TABLE test (id bigint(11) NOT NULL AUTO_INCREMENT COMMENT 自增id,subject_id bigint(11) NOT NULL DEFAULT 0 COMMENT 主题id,subject_nam…...

【Python】gevent模块实现协程模拟高并发
Python中GIL的存在,导致多线程一直不是很好用,相形之下,协程的优势就更加突出了。 Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持。 gevent是第三方库,通过gr…...
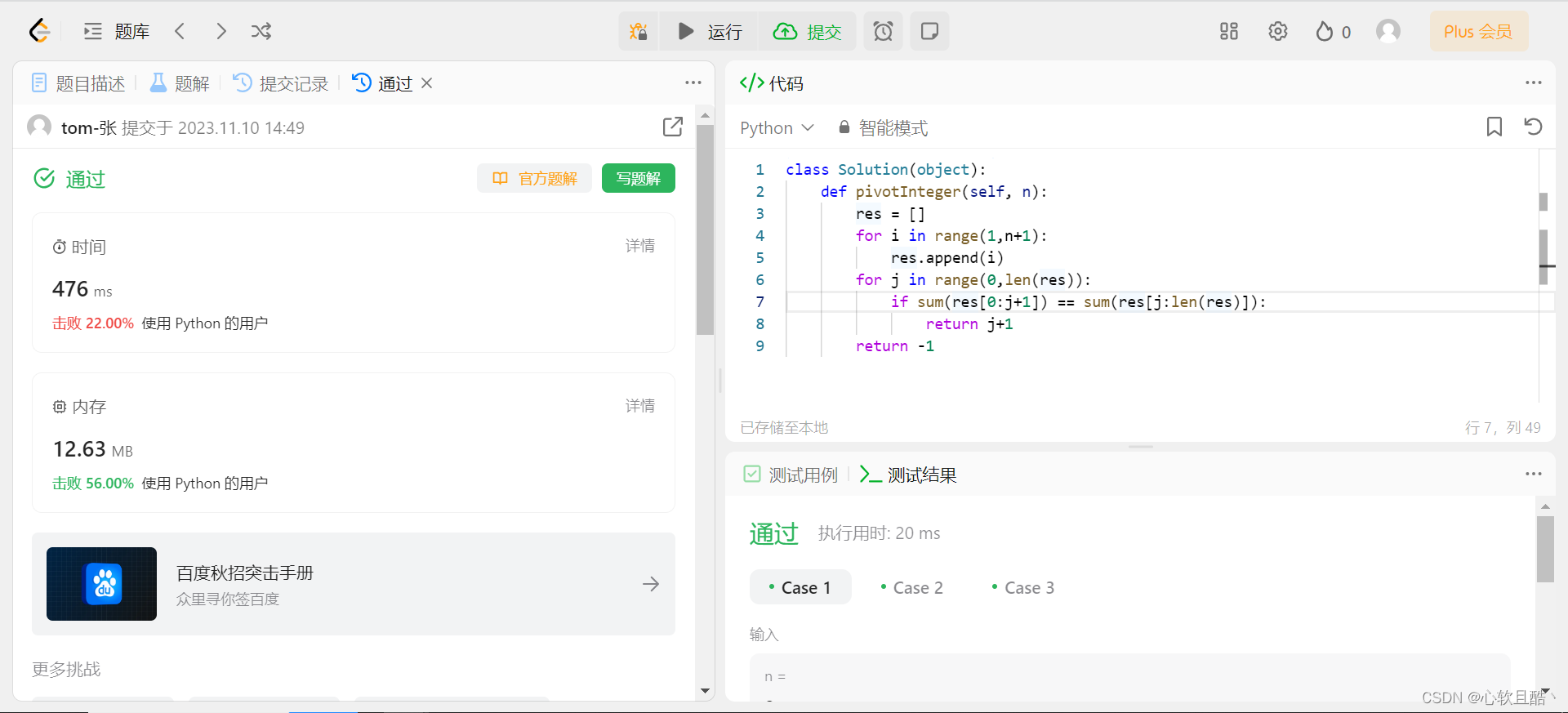
leetcode:2485. 找出中枢整数(python3解法)
难度:简单 给你一个正整数 n ,找出满足下述条件的 中枢整数 x : 1 和 x 之间的所有元素之和等于 x 和 n 之间所有元素之和。 返回中枢整数 x 。如果不存在中枢整数,则返回 -1 。题目保证对于给定的输入,至多存在一个中…...
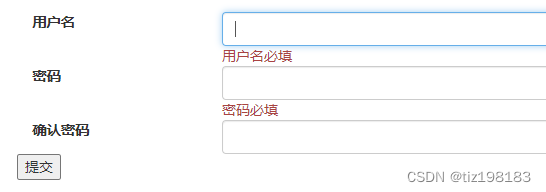
asp.net core mvc之模型绑定、特性约束模型绑定、模型验证(服务器/客户端/远程)
一、不用模型绑定 数据类型都是string 1、UserController.cs public class UserController : Controller {public IActionResult Register(){return View();}[HttpPost]public IActionResult DoRegister(){//不用模型绑定 以前的方法取表单数据或Url的参数//数据类型都是s…...

AI诈骗防范:保护数字社会的安全前线
引言: 在当今数字化的时代,人工智能技术在各个领域都展现了巨大的潜力,然而,正是这些技术的广泛应用也催生了新的安全隐患。近期,AIGC在聊天、写作、绘画、编程等领域表现出色,但也被用于“AI换脸”、“AI换…...

(待完善)python学习参考手册
这里写目录标题 观前浅谈:学习路线 :学习心得笔记:Step1:简单但一问不知怎么的组织语言去回答的小问题:什么是提示符?python解释器是什么?请正在阅读本文的朋友,安装一下PyCharm以及如何进行科学的省钱:Python中的命令行模式和交互模式的区别是什么?请正在阅读本文的朋友安装…...

CANFD数据帧格式详解:从显性/隐性电平到64字节DLC编码,一张图看懂协议升级
CANFD协议深度解码:从电平博弈到64字节数据帧的工程智慧 在汽车电子与工业控制领域,实时可靠的数据传输如同神经系统般重要。传统CAN总线曾是这个领域的王者,但随着智能驾驶、车联网等技术的爆发式发展,500Kbps的带宽逐渐显得捉襟…...

OmenSuperHub终极指南:三步掌控惠普游戏本性能与散热
OmenSuperHub终极指南:三步掌控惠普游戏本性能与散热 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN游戏本设…...

Dify金融问答合规配置实战指南:从0到1通过银保监AI问答备案的7个关键配置项
第一章:Dify金融问答合规配置的监管背景与备案逻辑近年来,金融领域人工智能应用加速落地,监管框架同步趋严。《生成式人工智能服务管理暂行办法》《金融行业大模型应用安全指引(试行)》及《银行保险机构数据安全管理办…...

Claude Code 接入国产大模型实战:GLM / Qwen 配置全解析
文章目录 Claude Code 接入国产大模型(GLM / Qwen)配置说明一、配置示例GLMQwen 二、核心思路三、关键参数说明1. ANTHROPIC_BASE_URL2. ANTHROPIC_API_KEY 四、API Key 正确姿势1. macOS / Linux2. Windows3. settings.json 可以简化4. 临时变量什么时候…...

暗黑2自动化脚本引擎架构设计与像素级识别技术解析
暗黑2自动化脚本引擎架构设计与像素级识别技术解析 【免费下载链接】botty D2R Pixel Bot 项目地址: https://gitcode.com/gh_mirrors/bo/botty 你是否曾因重复刷怪而厌倦,却又渴望高效获取稀有装备?传统手动操作不仅耗时耗力,还容易错…...

从混乱到清晰:TOP课程Git学习资源链接优化全指南
从混乱到清晰:TOP课程Git学习资源链接优化全指南 【免费下载链接】curriculum The open curriculum for learning web development 项目地址: https://gitcode.com/GitHub_Trending/cu/curriculum GitHub推荐项目精选(cu/curriculum)是…...

跨平台局域网通信技术革命:基于Qt的飞秋协议实现深度解析
跨平台局域网通信技术革命:基于Qt的飞秋协议实现深度解析 【免费下载链接】feiq 基于qt实现的mac版飞秋,遵循飞秋协议(飞鸽扩展协议),支持多项飞秋特有功能 项目地址: https://gitcode.com/gh_mirrors/fe/feiq 在混合操作系统办公环境…...

显卡驱动残留如何彻底清除?Display Driver Uninstaller终极解决方案
显卡驱动残留如何彻底清除?Display Driver Uninstaller终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...

Video Station for DSM 7.2.2:解决群晖新版系统视频管理兼容性问题的完整方案
Video Station for DSM 7.2.2:解决群晖新版系统视频管理兼容性问题的完整方案 【免费下载链接】Video_Station_for_DSM_722 Script to install Video Station in DSM 7.2.2 and DSM 7.3 项目地址: https://gitcode.com/gh_mirrors/vi/Video_Station_for_DSM_722 …...

从零到一:基于NUC980DK61YC自制开发板的完整流程与避坑指南
从零到一:基于NUC980DK61YC自制开发板的完整流程与避坑指南 当市面上标准开发板无法满足定制需求时,自制开发板成为嵌入式开发者的终极解决方案。NUC980系列以其ARM926EJ-S核心和丰富外设资源,在工业物联网领域占据独特优势。本文将带你完整走…...