torch DDP多卡训练教程记录
参考
简明教程看这里 --> pytorch分布式训练 和这篇: [PyTorch]> DDP系列第一篇:入门教程 --》 详细解答了pipeline
DDP原理篇 --> DDP系列第二篇:实现原理与源代码解析 --》 主要讲 all_reduce 和 sample 的实现
减少GPU占用看这里 --> Pytorch使用DDP加载模型时出现多进程在GPU0上占用过多显存的问题 --》解答了如何先加载到cpu解决0卡显存占用过多问题
DDP模型加载和保存看这里 – > torch DDP训练-模型保存-加载问题 --》解释和解决ddp模型名被更改后如何保存加载的问题
多机多卡更多看这里 --> Pytorch多机多卡分布式训练 --》有更细致的讲解
基本概念
在16张显卡,16的并行数下,DDP会同时启动16个进程。下面介绍一些分布式的概念。
group
即进程组。默认情况下,只有一个组。这个可以先不管,一直用默认的就行。
world size
表示全局的并行数,简单来讲,就是2x8=16。
# 获取world size,在不同进程里都是一样的,得到16
torch.distributed.get_world_size()
rank
表现当前进程的序号,用于进程间通讯。对于16的world sizel来说,就是0,1,2,…,15。
注意:rank=0的进程就是master进程。
# 获取rank,每个进程都有自己的序号,各不相同
torch.distributed.get_rank()
local_rank
又一个序号。这是每台机子上的进程的序号。机器一上有0,1,2,3,4,5,6,7,机器二上也有0,1,2,3,4,5,6,7
# 获取local_rank。一般情况下,你需要用这个local_rank来手动设置当前模型是跑在当前机器的哪块GPU上面的。
torch.distributed.local_rank()
DDP多卡训练简明Demo
这份是一份能直接跑的简明代码,推荐收藏!
################
## main.py文件
import argparse
from tqdm import tqdm
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
# 新增:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP### 1. 基础模块 ###
# 假设我们的模型是这个,与DDP无关
class ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
# 假设我们的数据是这个
def get_dataset():transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)# DDP:使用DistributedSampler,DDP帮我们把细节都封装起来了。# 用,就完事儿!sampler的原理,第二篇中有介绍。train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)# DDP:需要注意的是,这里的batch_size指的是每个进程下的batch_size。# 也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=16, num_workers=2, sampler=train_sampler)return trainloader### 2. 初始化我们的模型、数据、各种配置 ####
# DDP:从外部得到local_rank参数
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank# DDP:DDP backend初始化
torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端# 准备数据,要在DDP初始化之后进行
trainloader = get_dataset()# 构造模型
model = ToyModel().to(local_rank)
# DDP: Load模型要在构造DDP模型之前,且只需要在master上加载就行了。
ckpt_path = None
if dist.get_rank() == 0 and ckpt_path is not None:model.load_state_dict(torch.load(ckpt_path, map_location='cpu')) # 先加载到cpu
# DDP: 构造DDP model
model = DDP(model, device_ids=[local_rank], output_device=local_rank)# DDP: 要在构造DDP model之后,才能用model初始化optimizer。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)# 假设我们的loss是这个
loss_func = nn.CrossEntropyLoss().to(local_rank)### 3. 网络训练 ###
model.train()
iterator = tqdm(range(100))
for epoch in iterator:# DDP:设置sampler的epoch,# DistributedSampler需要这个来指定shuffle方式,# 通过维持各个进程之间的相同随机数种子使不同进程能获得同样的shuffle效果。trainloader.sampler.set_epoch(epoch)# 后面这部分,则与原来完全一致了。for data, label in trainloader:data, label = data.to(local_rank), label.to(local_rank)optimizer.zero_grad()prediction = model(data)loss = loss_func(prediction, label)loss.backward()iterator.desc = "loss = %0.3f" % lossoptimizer.step()# DDP:# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。# 2. 只需要在进程0上保存一次就行了,避免多次保存重复的东西。if dist.get_rank() == 0:torch.save(model.module.state_dict(), "%d.ckpt" % epoch)################
## Bash运行
# DDP: 使用torch.distributed.launch启动DDP模式
# 使用CUDA_VISIBLE_DEVICES,来决定使用哪些GPU
# CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node 2 main.py
DDP训练-模型保存-加载问题
save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。因为model其实是DDP model,参数是被model=DDP(model)包起来的。
模型保存:无module形式
####方法一
state = {'epoch': epoch,'model': model.state_dict(),'optimizer': optimizer.state_dict(),'scheduler': scheduler.state_dict()}
torch.save(state, 'model_path')####方法二
torch.save(self.model.state_dict(), 'model_path')module形式---建议模式
####方法一
state = {'epoch': epoch,'model': model.module.state_dict(),'optimizer': optimizer.state_dict(),'scheduler': scheduler.state_dict()}
torch.save(state, 'model_path')####方法二
torch.save(self.model.module.state_dict(), 'model_path')#######################################################################################模型加载: 未用含"moduel"方式保存, 导致缺失关键“key”:Missing key(s) in state_dict
############### 方法 1: add
model = torch.nn.DataParallel(model) # 加上module
model.load_state_dict(torch.load("model_path"))############### 方法 2: remove
model.load_state_dict({k.replace('module.', ''): v for k, v in torch.load("model_path").items()})############### 方法 3: remove
from collections import OrderedDict
state_dict = torch.load("model_path")
new_state_dict = OrderedDict() # create new OrderedDict that does not contain `module.`
for k, v in state_dict.items():name = k.replace('module.', '')new_state_dict[name] = v
model.load_state_dict(new_state_dict)含"moduel"方式保存
####方法一
self.model.load_state_dict(torch.load("model_path")['model'])####方法二
self.model.load_state_dict(torch.load('model_path))
其他需要注意的地方
- 保存参数
# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。
# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。
# 2. 我只需要在进程0上保存一次就行了,避免多次保存重复的东西。
if dist.get_rank() == 0:torch.save(model.module, "saved_model.ckpt")
- 要把模型和数据放在进程对应的那张卡上
- 要使用Sampler来分发训练数据,并且shuffle不设置在Dataloder中而是Sampler中,每个epoch还需要调用Sampler的set_epoch()方法。
- 训练和验证区分较大,验证一般在主进程中进行一次验证即可,不需要sampler,操作和单卡一样,之后将数据同步给其他进程。
- 在多卡时要调用模型的其他方法或者使用单卡的模式,需要用model.module来获得原始模型,同样保存参数时也保存的是model.module的参数而不是DDP包裹的
GPU0占用更多问题的解决办法
Pytorch使用DDP加载模型时出现多进程在GPU0上占用过多显存的问题,from: (https://blog.51cto.com/u_15786578/5667478)
如果map_location参数是空的,则torch.load方法会先把模型加载到CPU,然后把模型参数复制到保存它的地方(根据上文,保存模型的位置恰好是GPU 0)。
跑在GPU1上的进程在执行到torch.load方法后,会先加载模型到CPU,之后该进程顺理成章地调用GPU0,把一部分数据复制到GPU0,也就出现了前面图中的问题。
与其说是bug,倒不如说没仔细阅读文档,两种解决方法方法。
1. 将map_location指定为CPU:
def load_checkpoint(path):#加载到CPUcheckpoint = torch.load(path,map_location='cpu')model = Net()model.load_state_dict(checkpoint['model'])model = DDP(model, device_ids=[gpu])return model
2. 将map_location指定为local_rank对应的GPU:
def load_checkpoint(path):#加载到CPUcheckpoint = torch.load(path,map_location='cuda:{}'.format(local_rank))model = Net()model.load_state_dict(checkpoint['model'])model = DDP(model, device_ids=[gpu])return model
多机多卡模式
复习一下,master进程就是rank=0的进程。
在使用多机模式前,需要介绍两个参数:
- 通讯的address
- master_address,也就是master进程的网络地址,默认是:127.0.0.1,只能用于单机。
- 通讯的port
- master_port,也就是master进程的一个端口,要先确认这个端口没有被其他程序占用了哦。一般情况下用默认的就行,默认是:29500
## Bash运行
# 假设我们在2台机器上运行,每台可用卡数是8
# 机器1:
python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 8 \--master_adderss $my_address --master_port $my_port main.py
# 机器2:
python -m torch.distributed.launch --nnodes=2 --node_rank=1 --nproc_per_node 8 \--master_adderss $my_address --master_port $my_port main.py
小技巧
# 假设我们只用4,5,6,7号卡
CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 main.py
# 假如我们还有另外一个实验要跑,也就是同时跑两个不同实验。
# 这时,为避免master_port冲突,我们需要指定一个新的。这里我随便敲了一个。
CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 \--master_port 53453 main.py
为什么DDP比DP要快
来自一个博客评论:
疑问:DDP在每个GPU上参数始终一致,且每次用于更新参数的梯度也一致,那岂不是每个GPU做了重复的工作?
解答:我猜测,虽然反向传播时各GPU做了重复工作,但前向没有重复工作。因为每个GPU分到的训练数据是不一样的,
从而前向计算的梯度不一样,所以最后会有一个梯度汇总平均的操作。但反向传播的梯度一样,只是反向传播
在每个GPU重复计算了,前向计算并没有重复。反向传播重复计算也是为了防止DP中在各GPU之间大量传输模型
参数造成的通信效率问题。并且在DP中只在一个GPU进行反向,其他GPU都空着的,那么虽然DDP在各个GPU重复反向(这也是为什么DDP的GPU利用率高),其实相对于DP并没有增加额外的时间,最主要是减少了各GPU间的通信问题。
总结:DDP相对于DP最根本的速度提升点在于:DDP不用每次将模型参数 broadcast 到其他GPU,以此减少通信提升效率
参数平均
参数平均则直接计算所有模型参数的平均值。参数平均的操作在优化器执行梯度下降后,这意味着其可以作为一个辅助步骤,非常的灵活,但是参数存在一定问题:
- 数学上不等价
- 各批次数据的梯度下降方向不同,不利于收敛
- 计算和通信低效,两个阶段无法重叠,所以Pytorch的DDP设计中放弃了参数平均的方式。
梯度平均
梯度平均是将各个设备的梯度求平均,然后将这个平均梯度在各个节点的模型上作更新,这样的方式一方面在数学上和本地训练完全等价,而且可以实现异步,比参数平均更加高效。
相关文章:

torch DDP多卡训练教程记录
参考 简明教程看这里 --> pytorch分布式训练 和这篇: [PyTorch]> DDP系列第一篇:入门教程 --》 详细解答了pipeline DDP原理篇 --> DDP系列第二篇:实现原理与源代码解析 --》 主要讲 all_reduce 和 sample 的实现 减少GPU占用看这里…...
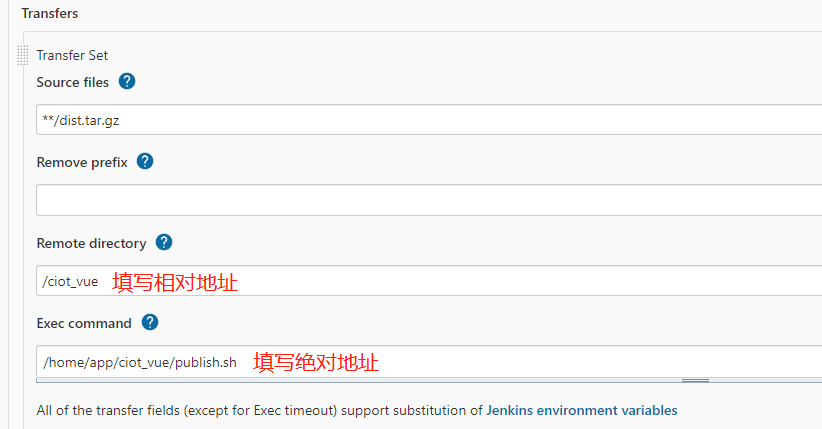
Jenkins CICD过程常见异常
1 Status [126] Exception when publishing, exception message [Exec exit status not zero. Status [126] 1.1 报错日志 SSH: EXEC: STDOUT/STDERR from command [/app/***/publish.sh] ... bash: /app/***/publish.sh: Permission denied SSH: EXEC: completed after 200…...

Java11新增特性
前言 在前面的文章中,我们已经介绍了 Java9的新增特性 和 Java10的新增特性 ,下面我们书接上文,来介绍一下Java11的新增特性 版本简介 Java 11 是 Java 平台的最新版本,于2018年9月25日发布。这个版本是自Java 8以来最重要的更新之一&…...
)
安卓常见设计模式13------过滤器模式(Kotlin版)
W1 是什么,什么是过滤器模式? 过滤器模式(Filter Pattern)是一种常用的结构型设计模式,用于根据特定条件过滤和筛选数据。 2. W2 为什么,为什么需要使用过滤器模式,能给我们编码带来什么好处…...

使用spark进行递归的可行方案
在实际工作中会遇到,最近有需求将产品炸开bom到底层,但是ERP中bom数据在一张表中递归存储的,不循环展开,是无法知道最底层原材料是什么。 在ERP中使用pl/sql甚至sql是可以进行炸BOM的,但是怎么使用spark展开࿰…...
Spring -Spring之依赖注入源码解析(下)--实践(流程图)
IOC依赖注入流程图 注入的顺序及优先级:type-->Qualifier-->Primary-->PriOriry-->name...

前端设计模式之【单例模式】
文章目录 前言介绍实现单例模式优缺点?后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出…...

设备零部件更换ar远程指导系统加强培训效果
随着科技的发展,AR技术已经成为了一种广泛应用的新型技术。AR远程指导系统作为AR技术的一种应用,具有非常广泛的应用前景。 一、应用场景 气象监测AR教学软件适用于多个领域,包括气象、环境、地理等。在教学过程中,软件可以帮助学…...

文本生成高精准3D模型,北京智源AI研究院等出品—3D-GPT
北京智源AI研究院、牛津大学、澳大利亚国立大学联合发布了一项研究—3D-GPT,通过文本问答方式就能创建高精准3D模型。 据悉,3D-GPT使用了大语言模型的多任务推理能力,通过任务调度代理、概念化代理和建模代理三大模块,简化了3D建模的开发流程…...
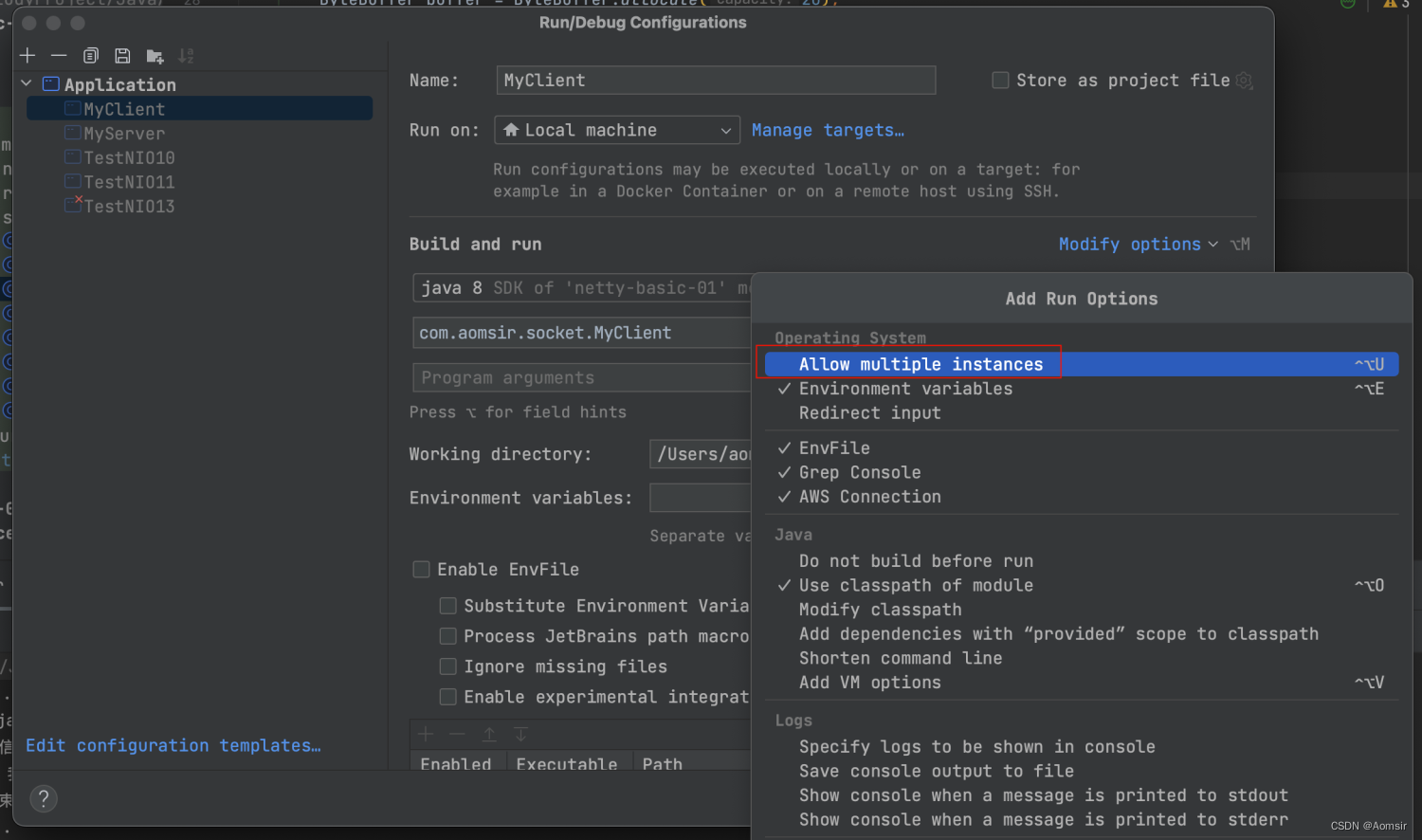
Netty入门指南之NIO 网络编程
作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者! 个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客 当前专栏:Netty应用专栏_Aomsir的博客-CSDN博客 文章目录 参考文献前言基础扫…...
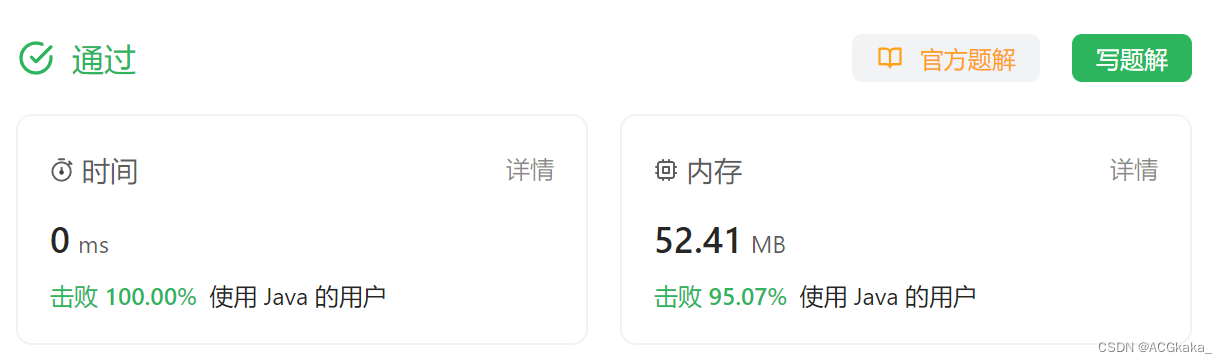
LeetCode(6)轮转数组【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 189. 轮转数组 1.题目 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1…...
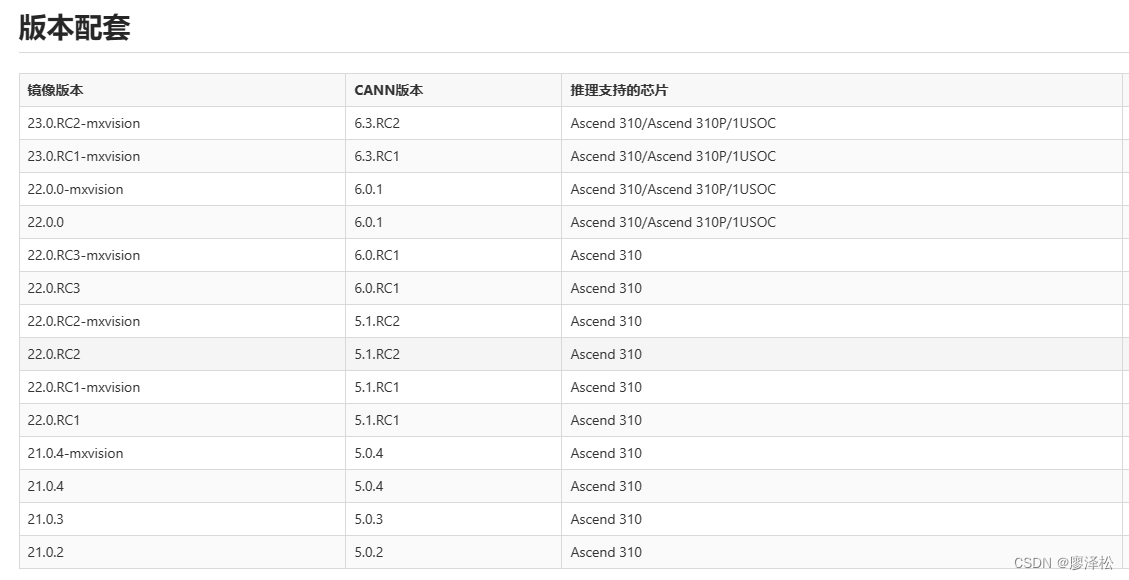
华为云Ascend310服务器使用
使用华为云服务器 cpu: 16vCPUs Kunpeng 920 内存:16GiB gpu:4* HUAWEI Ascend 310 cann: 20.1.rc1 操作系统:Ubuntu aarch64目的 使用该服务器进行docker镜像编译,测试模型。 已知生产环境:mindx版本为3.0.rc3&a…...
【poi导出excel模板——通过建造者模式+策略模式+函数式接口实现】
poi导出excel模板——通过建造者模式策略模式函数式接口实现 poi导出excel示例优化思路代码实现补充建造者模式策略模式 poi导出excel示例 首先我们现看一下poi如何导出excel,这里举个例子:目前想要导出一个Map<sex,List>信息,sex作为…...

自适应模糊PID控制器在热交换器温度控制中的应用
热交换器是一种常见的热能传递设备,广泛应用于各个工业领域。对热交换器温度进行有效控制具有重要意义,可以提高能源利用效率和产品质量。然而,受到热传导特性和外部环境变化等因素的影响,热交换器温度控制难度较大。本文提出一种…...
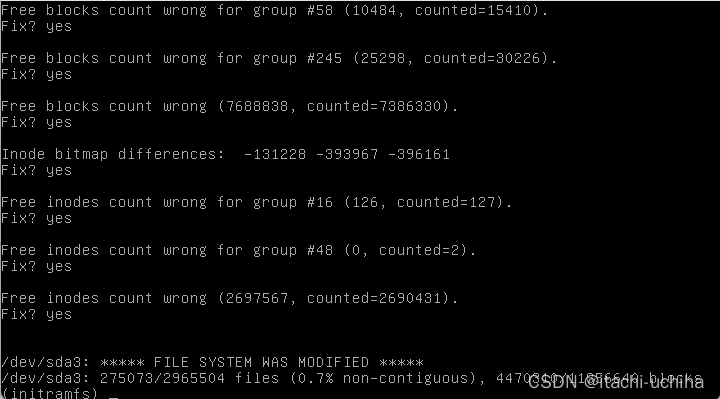
【系统救援】 Ubuntu重启失败,报错:UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY
问题定位及处理 查看错误信息:/dev/sda3 contains a file system with errors, check forced. /dev/sda3: Inodes that were part of a corrupted orphan linked list found. /dev/sda3: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY. (i.e., without -a or -p o…...
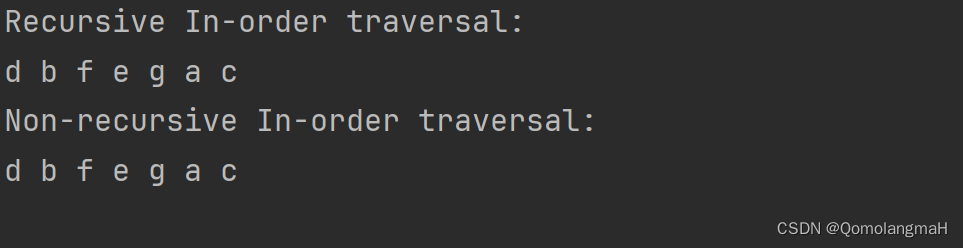
【数据结构】树与二叉树(八):二叉树的中序遍历(非递归算法NIO)
文章目录 5.2.1 二叉树二叉树性质引理5.1:二叉树中层数为i的结点至多有 2 i 2^i 2i个,其中 i ≥ 0 i \geq 0 i≥0。引理5.2:高度为k的二叉树中至多有 2 k 1 − 1 2^{k1}-1 2k1−1个结点,其中 k ≥ 0 k \geq 0 k≥0。引理5.3&…...

第九章 排序【数据结构】【精致版】
第九章 排序【数据结构】【精致版】 前言版权第九章 排序9.1 概述9.2 插入类排序9.2.1 直接插入排序**1-直接插入排序.c** 9.2.2 折半插入排序**2-折半插入排序.c** 9.2.3 希尔排序 9.3 交换类排序9.3.1冒泡排序**4-冒泡排序.c** 9.3.2 快速排序**5-快速排序.c** 9.4 选择类排…...

基于element-plus定义表格行内编辑配置化
文章目录 前言一、新增table组件二、使用步骤 前言 在 基于element-plus定义表单配置化 基础上,封装个Element-plus的table表格 由于表格不同于form组件,需自定义校验器,以下组件配置了单个校验,及提交统一校验方法,且…...
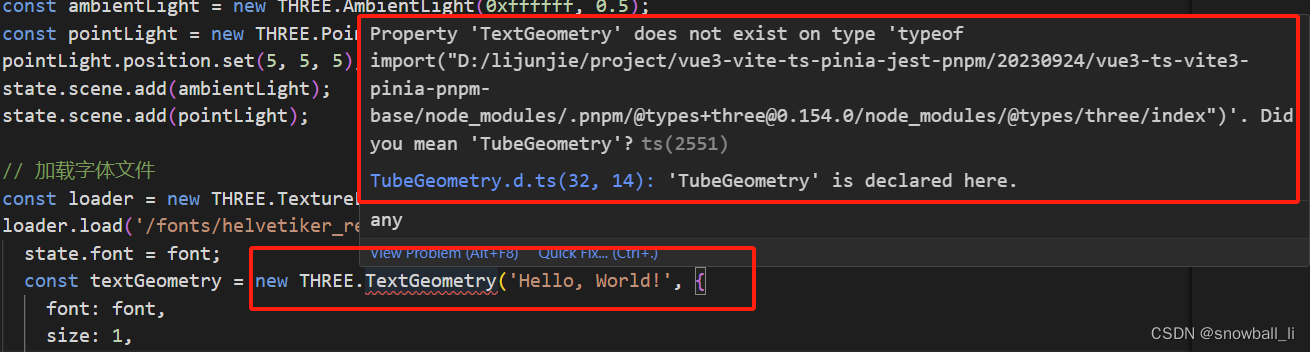
WebGL-Vue3-TS-Threejs:基础练习 / Javascript 3D library / demo
一、理解Three.js Three.js是一个用于WebGL渲染的JavaScript库。它提供了一组工具和类,用于创建和渲染3D图形和动画。简单理解(并不十分准确),Three.js之于WebGL,好比,jQuery.js之于JavaScript。 OpenGL …...

2022年12月 Python(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 有n个按名称排序的商品,使用对分查找法搜索任何一商品,最多查找次数为5次,则n的值可能为?()(2分) A.5 B.15 C.30 D.35 答案:C 答案解析:对分查找最多查找次数m与个数之间n的…...
)
C# Winform项目实战:给你的桌面应用加个‘点赞’悬浮按钮(MaterialFloatingActionButton全解析)
C# Winform项目实战:打造智能悬浮按钮的完整交互方案 在桌面应用开发中,那些看似微小的交互细节往往决定了用户体验的成败。想象一下,当用户完成一项重要操作后,一个精致的悬浮按钮轻轻弹出,邀请他们为内容点赞——这种…...

SQL盲注技术全解析:布尔盲注、时间盲注与DNSLog带外注入
前言 在之前的学习中,我们掌握了 SQL 注入的基本原理,包括联合查询注入和报错注入技术。这些攻击方式都有一个共同点:需要页面能够显示查询结果或通过报错信息泄露数据。但在实际环境中,Web 应用通常会采取多种防护措施ÿ…...
)
复杂表格快速解读(使用千问)
复杂表格通常包含多维度数据(如多产品、多区域、多时间段)、多层级分类,人工解读需先梳理结构,再整合数据,耗时且易遗漏关键信息。千问通过“结构解析数据聚合”的双重逻辑,可快速输出表格核心框架与关键数…...

如何快速实现C++与JavaScript无缝交互?nbind终极指南
如何快速实现C与JavaScript无缝交互?nbind终极指南 【免费下载链接】nbind :sparkles: Magical headers that make your C library accessible from JavaScript :rocket: 项目地址: https://gitcode.com/gh_mirrors/nb/nbind nbind是一个强大的开源工具&…...

ASTRAL 5.7.8:用四重树频率统计构建高精度物种树的实战指南
ASTRAL 5.7.8:用四重树频率统计构建高精度物种树的实战指南 【免费下载链接】ASTRAL Accurate Species TRee ALgorithm 项目地址: https://gitcode.com/gh_mirrors/ast/ASTRAL ASTRAL(Accurate Species TRee ALgorithm)是一个基于多物…...

Matlab科学计算与AI融合:调用Phi-4-mini-reasoning进行数据分析报告生成
Matlab科学计算与AI融合:调用Phi-4-mini-reasoning进行数据分析报告生成 1. 科研数据分析的新思路 科研工作者每天都要面对大量数据计算和可视化工作。传统流程中,完成Matlab计算后,还需要手动分析结果、撰写报告,这个过程既耗时…...

数据驱动战斗:GBFR Logs如何让你的《碧蓝幻想:Relink》输出提升30%
数据驱动战斗:GBFR Logs如何让你的《碧蓝幻想:Relink》输出提升30% 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors…...

Windows 10变身简易服务器:低成本搭建多用户远程开发/测试环境全记录
Windows 10变身简易服务器:低成本搭建多用户远程开发/测试环境全记录 在当今快节奏的开发环境中,团队协作和资源共享变得越来越重要。对于小型团队、学生项目组或个人开发者来说,购买专业服务器设备往往意味着高昂的成本投入。而实际上&#…...

LinkSwift:8大网盘直链下载的终极解决方案,告别限速烦恼
LinkSwift:8大网盘直链下载的终极解决方案,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

为什么选择NHSE:深度解析动物森友会存档编辑器的5大核心功能
为什么选择NHSE:深度解析动物森友会存档编辑器的5大核心功能 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE NHSE存档编辑器为《集合啦!动物森友会》玩家提供了前所未有的游…...