机器学习经典算法——决策树(Decision Tree)
决策树的基本原理
决策树是⼀种分⽽治之的决策过程。⼀个困难的预测问题,通过树的分⽀节点,被划分成两个或多个较为简单的⼦集,从结构上划分为不同的⼦问题。将依规则分割数据集的过程不断递归下去。随着树的深度不断增加,分⽀节点的⼦集越来越⼩,所需要提的问题数也逐渐简化。当分⽀节点的深度或者问题的简单程度满⾜⼀定的停⽌规则时, 该分⽀节点会停⽌分裂。
决策树是一种自上而下,对样本数据进行树形分类的过程,由结点和有向边组成。结点分为内部节点和叶结点,其中内部结点表示一个特征或属性,叶结点表示类别。从顶部根节点开始,所有样本聚在一起。经过根结点的划分,样本别分到不同的子结点中。在根据子结点的特征进一步划分,直至所有样本都被归到某一个类别(即叶结点)中。
- 优点:不需要任何领域知识或参数假设;适合⾼维数据;短时间内处理⼤量数据,得到可⾏且效果较好的结果;能够同时处理数据型和常规性属性。
- 缺点:对于各类别样本数量不⼀致数据,信息增益偏向于那些具有更多数值的特征;易于过拟合;忽略属性之间的相关性;不⽀持在线学习。
决策树的三要素
一般而言,决策树的生成包括特征选择、树的构造、树的剪枝三个过程。
- 特征选择:从训练数据中众多的特征中选择⼀个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从⽽衍⽣出不同的决策树算法。
- 决策树⽣成:根据选择的特征评估标准,从上⾄下递归地⽣成⼦节点,直到数据集不可分则决策树停⽌⽣长。树结构来说,递归结构是最容易理解的⽅式。
- 剪枝:决策树容易过拟合,⼀般来需要剪枝,缩⼩树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
决策树学习基本算法

熵与信息增益
熵
熵可以表⽰样本集合的不确定性,熵越⼤,样本的不确定性就越⼤。
假设随机变量X的可能取值有x1,x2, …, xn,对于每⼀个可能的取值xi,其概率为:
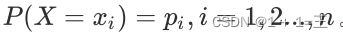
随机变量的熵为:
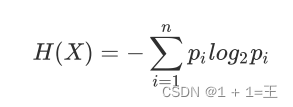
对于样本集合,假设样本有k个类别,每个类别的概率为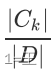 其中|Ck|为类别为k的样本个数, |D| 为样本总数。样本集合D的熵为:
其中|Ck|为类别为k的样本个数, |D| 为样本总数。样本集合D的熵为:
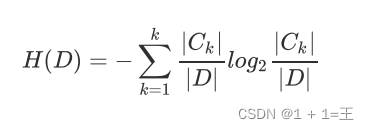
信息增益
假设划分前样本集合D的熵为H(D)。使⽤某个特征A划分数据集D,计算划分后的数据⼦
集的熵为H(D|A),则A特征的信息增益为:
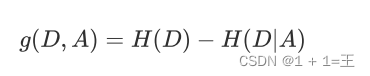
决策树的剪枝方法
剪枝处理是决策树学习算法⽤来解决过拟合问题的⼀种办法。通过对决策树进行剪枝,剪掉一些枝叶,提升模型的泛化能力。决策树的剪枝通常有两种方法:预剪枝(pre-pruning)和后剪枝(post-pruning)。
- 预剪枝:在生成决策树的过程中提前停止树的增长;
- 后剪枝:⽣成决策树以后,再⾃下⽽上对⾮叶结点进⾏剪枝,得到简化版的剪枝决策树。
预剪枝
预剪枝的核心思想是在树中结点进行扩展之前,先计算当前的划分是否能带来模型泛化能力的提升,如果不能,则不再继续生长子树。此时可能存在不同类别的样本同时存于结点中,按照多数投票的原则判断该结点所属类别。预剪枝对于何时停止决策树的生长有以下几种方法。
- 当树到达一定深度的时候,停止树的生长。
- 当到达当前结点的样本数量小于某个阈值的时候,停止树的生长。
- 计算每次分裂对测试集的准确度提升,当小于某个阈值的时候,不再继续扩展。
预剪枝具有思想直接、算法简单、效率高等特点,适合解决大规模问题。但预剪枝存在一定局限性,有欠拟合的风险,虽然当前的划分会导致测试集准确率降低,但在之后的划分中,准确率可能会有显著上升。
后剪枝
后剪枝的核心思想是让算法生成一棵完全生 长的决策树,然后从最底层向上计算是否剪枝。剪枝过程将子树删除,用一个叶子结点替代,该结点的类别同样按照多数投票的原则进行判断。同样地,后剪枝也可以通过在测试集上的准确率进行判断,如果剪枝过后准确率有所提升,则进行剪枝。
相比于预剪枝,后剪枝方法通常可以得到泛化能力更强的决策树,但时间开销会更大。
常见的后剪枝方法包括:错误率降低剪枝( Reduced Error Pruning,REP)、悲观剪枝( Pessimistic Error Pruning, PEP) 、代价复杂度剪枝( Cost Complexity Pruning, CCP )、最小误差剪枝(MinimumEror Pruning, MEP )、CVP(Critical Value Pruning)、OPP (OpttimalPruning)等
相关文章:
机器学习经典算法——决策树(Decision Tree)
决策树的基本原理 决策树是⼀种分⽽治之的决策过程。⼀个困难的预测问题,通过树的分⽀节点,被划分成两个或多个较为简单的⼦集,从结构上划分为不同的⼦问题。将依规则分割数据集的过程不断递归下去。随着树的深度不断增加,分⽀节…...
MySQl总结
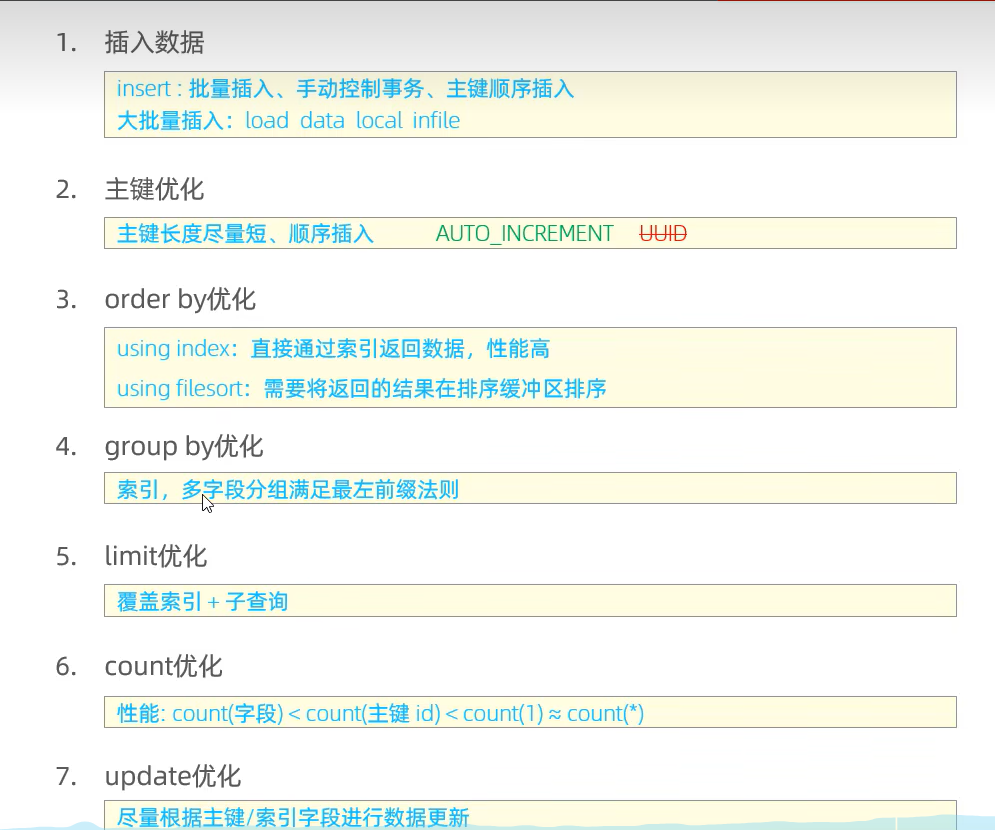
文章目录MySQL数据库的常见考点1、ACID事务原理事务持久性事务原子性MVCC基本概念MVCC基本原理undo logundo log版本链readviewMVCC实现原理RC读已提交RR可重复读MVCC实现原理总结2、并发事务引发的问题3、事务隔离级别4、索引索引结构BTreeHash面试题索引分类思考题语法性能分…...

【学习笔记】NOIP爆零赛7
结论专场,结果被踩暴了 青鱼和序列 赛时的做法是,维护∑aii\sum a_i\times i∑aii的取值,发现只和最后一次操作222的位置有关,于是递推O(n)O(n)O(n)解决。 赛后发现还有更神奇的结论 第二个结论是,第一次进行操作…...

一文读懂账号体系产品设计
一、账号体系的概念及价值账号体系是用户在各平台上的通行证。平台给与用户可持续的服务,用户在平台上获取价值,中间的媒介,便是账号体系。阿境将其理解为维系用户与平台之间的枢纽。注:本文中,账号账户,二…...
从“入门”到“专家”,一份3000字完整的性能测试体系的知识分享
随着科技的飞速发展,软件产品广泛应用于各个行业领域,人们对计算机和网络的依赖性越来越大,对新奇事物也越来越感兴趣,成千上万的用户活跃在庞大的网络系统中,这给提供服务的系统带来严重的负荷,"高并…...

构建对话机器人:Rasa3安装和基础入门
在开源对话机器人中,Rasa社区很活跃,在国内很多企业也在使用Rasa做对话机器人,有rasa开发经验的往往是加分项。 当年实习的时候接触到了Rasa,现在工作中也使用Rasa,因此,写写一些经验文档,有助后…...
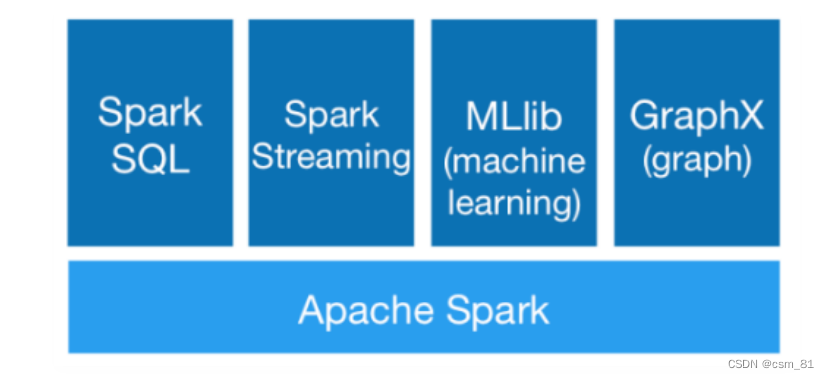
Spark计算框架入门笔记
Spark是一个用于大规模数据处理的统一计算引擎 注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,等等,所以说它是一个统一的计算引擎 既然说到了Spar…...

入职数据分析公认的好书|建议收藏
众所周知,数据分析经常出现在我们的日常生活中,各行各业都需要数据分析。可你知道什么是数据分析?它在企业里到底扮演什么角色?以及如果我们自己也想拥有数据分析的能力,以便更好的满足数据分析的需求,我们…...

Linux查找文件和目录,重定向输出 ,系统默认运行级别的查看和设置理论和练习
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...

Redis源码---键值对中字符串的实现,用char*还是结构体
目录 前言 为什么 Redis 不用 char*? char* 的结构设计 操作函数复杂度 SDS 的设计思想 SDS 结构设计 SDS 操作效率 紧凑型字符串结构的编程技巧 小结 前言 对于 Redis 来说,键值对中的键是字符串,值有时也是字符串在 Redis 中写入一…...

算法 - 剑指Offer 表示数值的字符串
题目 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 …...
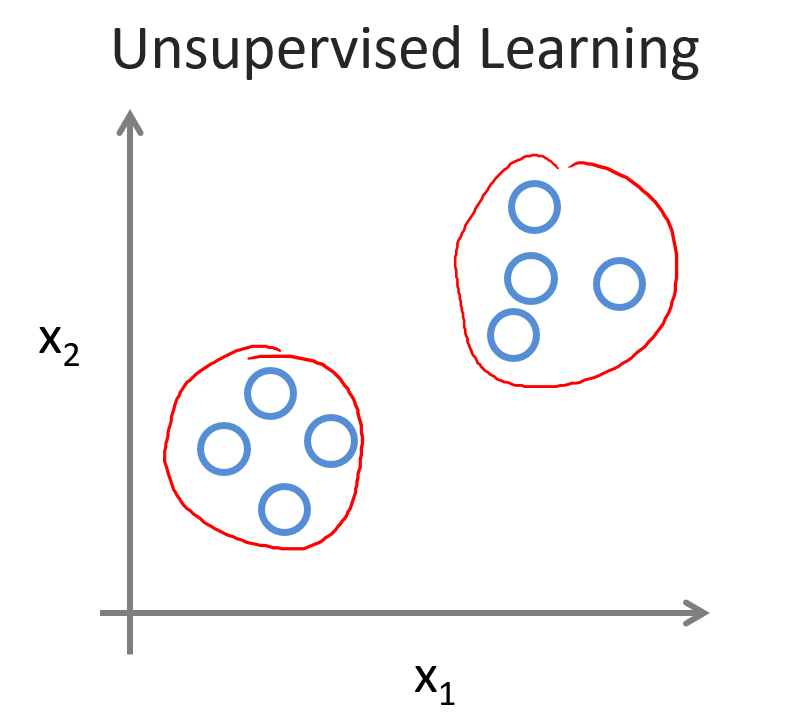
初识机器学习
监督学习与无监督学习supervised learning:监督学习,给出的训练集中有输入也有输出(标签)(也可以说既有特征又有目标),在此基础上让计算机进行学习。学习后通过测试集测试给相应的事物打上标签。…...
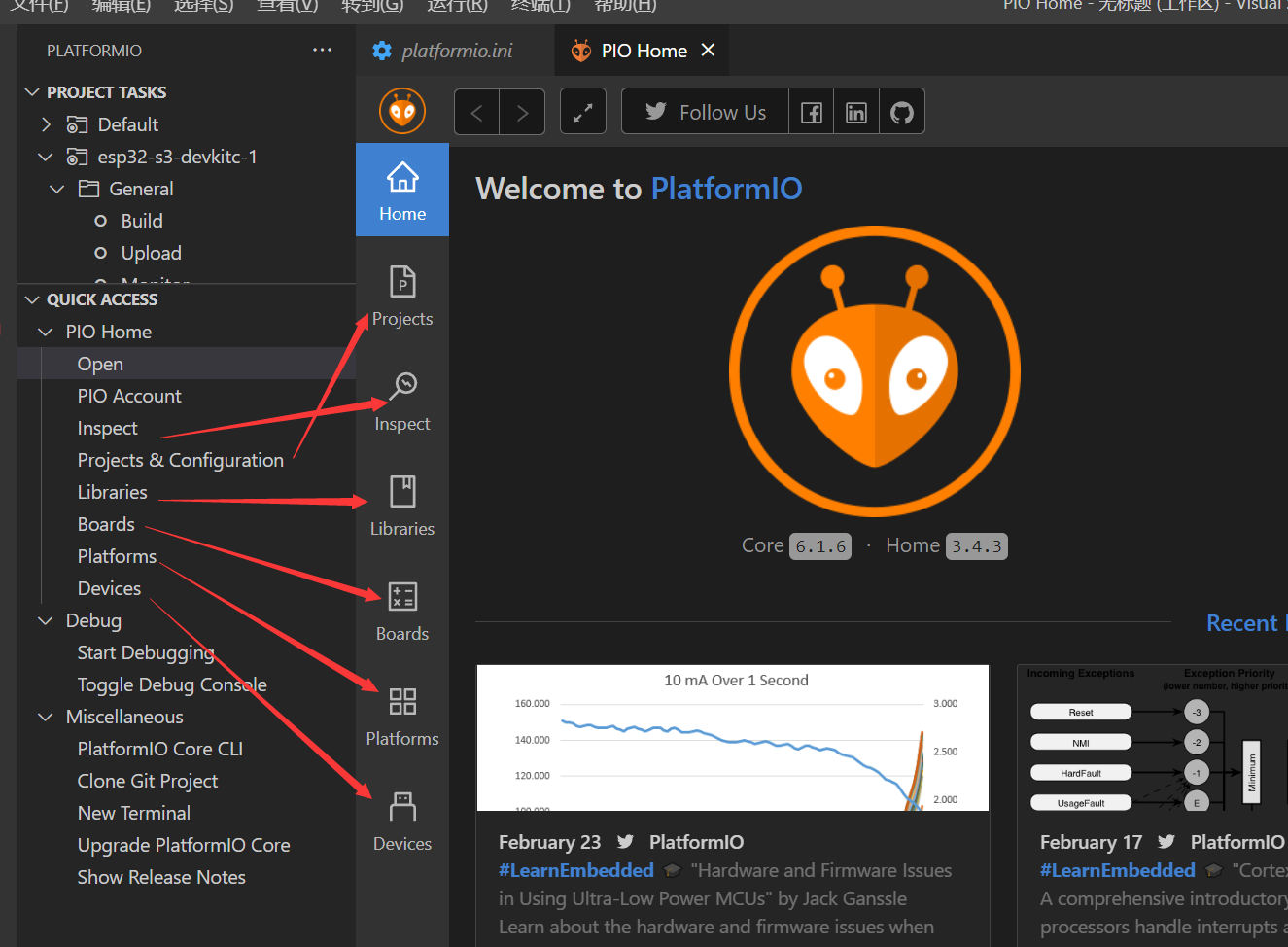
VsCode安装PlatformIO 开发ESP arduino,买的板子或者随便ESP,PlatformIO添加Board(不是自定义Board)
这次主要记录怎么给新建选板子的时候没有的板子下程序 我这里是一块 WiFi Kit 32 (V3) PlatformIO里面只有到V2 先从头开始,安装PlatformIO 安装PlatformIO 直接搜索安装 安装有时候会比较慢,左侧出现蚂蚁图标之后点击会显示 右下角会提示正在安…...

golang 复杂数据结构解析
[{"key":"15275771","pack":{"1":[{"name":"消息配置","id":15275771,"version":1,"createUser":"molaifeng","data":"test"}]},"callback&qu…...

不怕被AirTag跟踪?苹果Find My技术越来越普及
苹果的 AirTag 自推出以来,如何有效遏制用户用其进行非法跟踪,是摆在苹果面前的一大难题。一家为执法部门制造无线扫描设备的公司近日通过 KickStarter 平台,众筹了一款消费级产品,可帮助用户检测周围是否存在追踪的 AirTag 等设备…...
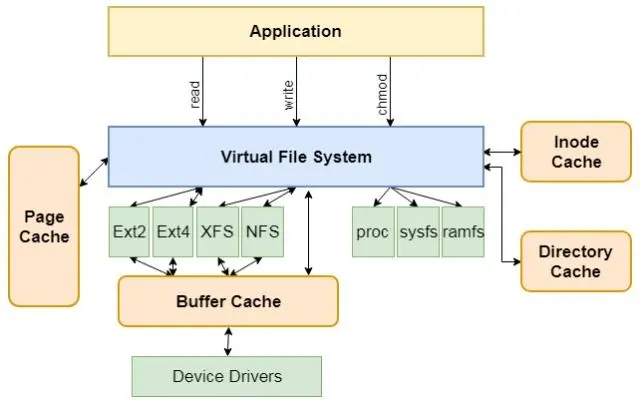
Linux驱动中的open函数是如何从软件打通硬件呢?
一、前言 打开文件是Linux系统中最基本的操作之一,open函数可以实现打开文件的功能。下面我将为您介绍open函数打通上层到底层硬件的详细过程。 二、open函数打通软硬件介绍 open函数是系统调用中的一种,其原型定义在头文件unistd.h中: #…...

Java 基础语法
Java 是一门广泛使用的编程语言,由于其简单易学和可移植性,已成为开发 Web 应用程序、移动应用程序、桌面应用程序以及企业级应用程序的首选语言之一。在本文中,我们将探讨 Java 的基础语法,包括变量、数据类型、运算符、控制流等…...
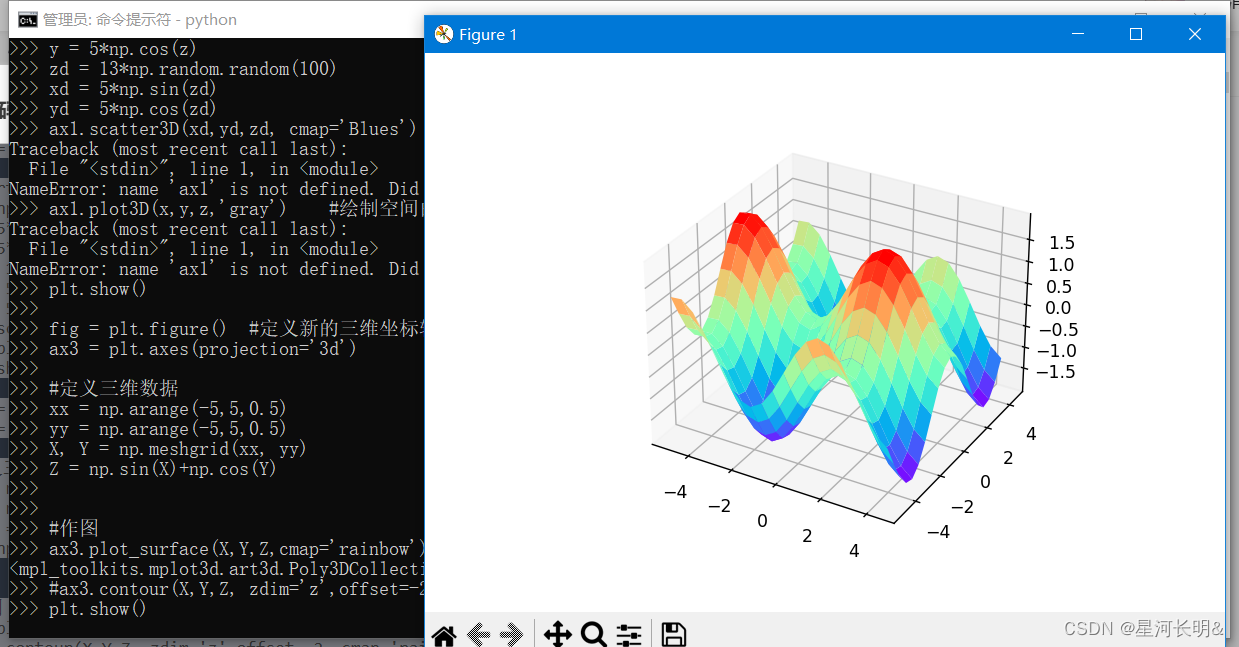
python下如何安装并使用matplotlib(画图模块)
在搜索命令中输入cmd,以管理员身份运行。 输入以下命令,先对pip安装工具进行升级 pip install --upgrade pip 升级完成 之后使用pip安装matplotlib pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple 也可以使用pycharm来安装matp…...

系统分析师---计算机网络思维导图
TCP、IP协议簇(4星) 传输协议:TCP有连接、可靠、有回应机制、三次握手基于TCP的应用层协议:POP3:邮件收取,默认端口110SMTP:邮件发送,默认端口25FTP:文件传输协议&#…...

算法练习(七)数据分类处理
一、数据分类处理 1、题目描述: 信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出…...

【免费下载】 Airplayer:苹果设备投屏的终极解决方案
Airplayer:苹果设备投屏的终极解决方案 【下载地址】Airplayer苹果投屏软件 Airplayer是一款专为苹果设备设计的高效投屏软件,它允许用户轻松地将iPhone或iPad屏幕的内容无线传输到电脑上显示。无论是播放视频、展示照片、进行会议演示还是游戏分享&…...

别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析
别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析 地理空间数据分析中,识别变量间的分异特征和驱动因子一直是研究难点。传统方法依赖复杂公式推导和编程实现,让许多研究者望而却步。而地理探测器(Geod…...

【ElevenLabs企业级克隆部署白皮书】:单模型支持12种语境情绪、延迟<480ms、通过GDPR+CCPA双认证
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs企业级语音克隆技术全景概览 ElevenLabs 企业级语音克隆技术以高保真度、低延迟和强可控性为核心,面向金融客服、跨国培训、无障碍内容生成等关键业务场景提供端到端语音合成解决…...
 张量宇宙学对黑洞奇点的解释——兼论奇点与大爆炸的统一机制)
第5章(补充) 张量宇宙学对黑洞奇点的解释——兼论奇点与大爆炸的统一机制
第5章(补充) 张量宇宙学对黑洞奇点的解释——兼论奇点与大爆炸的统一机制 摘要 黑洞奇点是广义相对论最著名的困境之一。奥本海默和斯奈德从爱因斯坦场方程出发,严格推导出大质量恒星引力塌缩会形成密度无穷大的奇点。然而,奇点的…...

RAG知识库生命周期①【第七篇】:文档新增修改删除,生产级向量同步更新方案
生产级 RAG 避坑实战合集【第七篇】文章简介:前面六篇我们搞定了文档解析、去重、文本清洗、Chunk切块、结构化元数据。绝大多数项目卡在这一关:文档内容变了怎么办?制度修改、数据订正、条款作废、资料更新。Demo可以删库重灌,生…...

解锁Godot游戏宝库:PCK文件解包实战指南
解锁Godot游戏宝库:PCK文件解包实战指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经好奇过Godot游戏中的精美画面和动人音效是如何封装的?那些神秘的PCK文件就…...

告别手动标注!R语言ggplot2+ggannotate高效绘制组间差异柱状图保姆级教程
R语言科研绘图革命:ggplot2ggannotate自动化差异标注全攻略 科研图表的美观程度直接影响论文的第一印象,而统计显著性标注更是数据可视化的灵魂所在。传统手动添加p值和星号的方式不仅效率低下,还容易出错——标注位置偏移、字体大小不一、连…...
)
今日算法(依旧二叉树)
class Solution { public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {//递归进行,加回溯过程if(rootq||rootp||rootNULL) return root;TreeNode*leftlowestCommonAncestor(root->left,p,q);TreeNode*rightlowestCommonAncestor…...

告别卡顿与隐私担忧:用Docker Compose在1核1G VPS上部署高性能RustDesk私有服务器
在1核1G VPS上构建高性能RustDesk私有化服务的完整指南 远程协作已成为现代工作流中不可或缺的一环,而数据隐私和连接稳定性则是技术爱好者最关注的核心问题。开源远程桌面解决方案RustDesk以其轻量级架构和自托管能力,为追求完全控制权的用户提供了理想…...

SISSO 终极指南:数据驱动建模的强大工具
SISSO 终极指南:数据驱动建模的强大工具 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO SISSO…...