Flink SQL -- 命令行的使用
1、启动Flink SQL
首先启动Flink的集群,选择独立集群模式或者是session的模式。此处选择是时session的模式:yarn-session.sh -d 在启动Flink SQL的client:
sql-client.sh2、kafka SQL 连接器
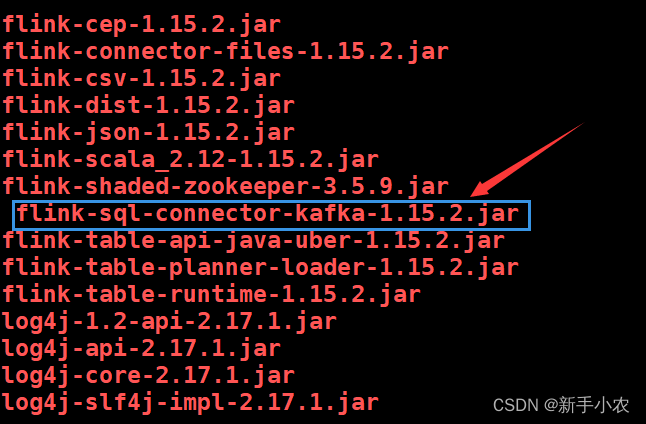
在使用kafka作为数据源的时候需要上传jar包到flnik的lib下:/usr/local/soft/flink-1.15.2/lib可以去官网找对应的版本下载上传。
1、创建表:再流上定义表
再flink中创建表相当于创建一个视图(视图中不存数据,只有查询视图时才会去原表中读取数据)CREATE TABLE students (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'student','properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'csv'
)2、查询数据(连续查询):select clazz,count(1) as c from students group by clazz;3、客户端为维护和可视化结果提供了三种的模式:
1、表格模式(默认使用的模式),(table mode),在内存中实体化结果,并将结果用规则的分页表格可视化展示出来
SET 'sql-client.execution.result-mode' = 'table';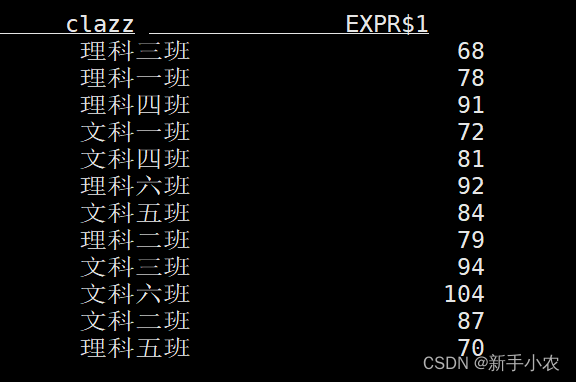
2、变更日志模式,(changelog mode),不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET 'sql-client.execution.result-mode' = 'changelog';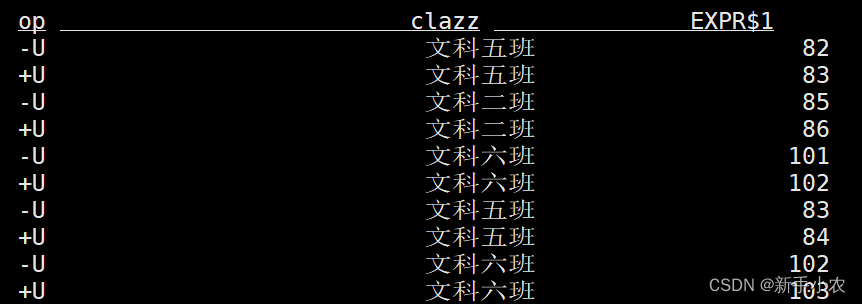
3、Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';
4、 Flink SQL流批一体:
1、流处理:
a、流处理即可以处理有界流也可以处理无界流
b、流处理的输出的结果是连续的结果
c、流处理的底层是持续流的模型,上游的Task和下游的Task同时启动等待数据的到达
SET 'execution.runtime-mode' = 'streaming'; 2、批处理:
a、批处理只能用于处理有界流
b、输出的是最终的结果
c、批处理的底层是MapReduce模型,会先执行上游的Task,在执行下游的Task
SET 'execution.runtime-mode' = 'batch';Flink做批处理,读取一个文件:-- 创建一个有界流的表
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/spark/stu/students.txt', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);select clazz,count(1) as c from
students_hdfs
group by clazz5、Flink SQL的连接器:
1、kafka SQL 连接器
对于一些参数需要从官网进行了解。
1、kafka source
-- 创建kafka 表
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);2、kafka sink
-- 创建kafka 表
CREATE TABLE students_kafka_sink (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students_sink', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 将查询结果保存到kafka中
insert into students_kafka_sink
select * from students_hdfs;kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic students_sink3、将更新的流写入到kafka中
因为在Kafka是一个消息队列,是不会去重的。所以只需要将读取数据的格式改成canal-json。当数据被读取回来还是原来的流模式。
CREATE TABLE clazz_num_kafka (clazz STRING,num BIGINT
) WITH ('connector' = 'kafka','topic' = 'clazz_num', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'canal-json' -- 读取数据的格式
);-- 将更新的数据写入kafka需要使用canal-json格式,数据中会带上操作类型
{"data":[{"clazz":"文科一班","num":71}],"type":"INSERT"}
{"data":[{"clazz":"理科三班","num":67}],"type":"DELETE"}insert into clazz_num_kafka
select clazz,count(1) as num from
students
group by clazz;kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic clazz_num2、 hdfs SQL 连接器
1、hdfs source
Flink读取文件可以使用有界流的方式,也可以是无界流方式。
-- 有界流
CREATE TABLE students_hdfs_batch (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);select * from students_hdfs_batch;-- 无界流
-- 基于hdfs做流处理,读取数据是以文件为单位,延迟比kafka大
CREATE TABLE students_hdfs_stream (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' , -- 必选:文件系统连接器指定 format'source.monitor-interval' = '5000' -- 每隔一段时间扫描目录,生成一个无界流
);select * from students_hdfs_stream;2、hdfs sink
-- 1、批处理模式(使用方式和底层原理和hive类似)
SET 'execution.runtime-mode' = 'batch';-- 创建表
CREATE TABLE clazz_num_hdfs (clazz STRING,num BIGINT
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/clazz_num', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);
-- 将查询结果保存到表中
insert into clazz_num_hdfs
select clazz,count(1) as num
from students_hdfs_batch
group by clazz;-- 2、流处理模式
SET 'execution.runtime-mode' = 'streaming'; -- 创建表,如果查询数据返回的十更新更改的流需要使用canal-json格式
CREATE TABLE clazz_num_hdfs_canal_json (clazz STRING,num BIGINT
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/clazz_num_canal_json', -- 必选:指定路径'format' = 'canal-json' -- 必选:文件系统连接器指定 format
);insert into clazz_num_hdfs_canal_json
select clazz,count(1) as num
from students_hdfs_stream
group by clazz;3、MySQL SQL 连接器
1、整合:
# 1、上传依赖包到flink 的lib目录下/usr/local/soft/flink-1.15.2/lib
flink-connector-jdbc-1.15.2.jar
mysql-connector-java-5.1.49.jar# 2、需要重启flink集群
yarn application -kill [appid]
yarn-session.sh -d# 3、重新进入sql命令行
sql-client.sh![]()
![]() 2、mysql source
2、mysql source
-- 有界流
-- flink中表的字段类型和字段名需要和mysql保持一致
CREATE TABLE students_jdbc (id BIGINT,name STRING,age BIGINT,gender STRING,clazz STRING,PRIMARY KEY (id) NOT ENFORCED -- 主键
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/student','table-name' = 'students','username' ='root','password' ='123456'
);select * from students_jdbc;3、mysql sink
-- 创建kafka 表
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 创建mysql sink表
CREATE TABLE clazz_num_mysql (clazz STRING,num BIGINT,PRIMARY KEY (clazz) NOT ENFORCED -- 主键
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/student','table-name' = 'clazz_num','username' ='root','password' ='123456'
);--- 再mysql创建接收表
CREATE TABLE clazz_num (clazz varchar(10),num BIGINT,PRIMARY KEY (clazz) -- 主键
) ;-- 将sql查询结果实时写入mysql
-- 将更新更改的流写入mysql,flink会自动按照主键更新数据
insert into clazz_num_mysql
select
clazz,
count(1) as num from
students_kafka
group by clazz;kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students 插入一条数据4、DataGen:用于生成随机数据,一般用在高性能测试上
-- 创建包(只能用于source表)
CREATE TABLE students_datagen (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'datagen','rows-per-second'='5', -- 每秒随机生成的数据量'fields.age.min'='1','fields.age.max'='100','fields.sid.length'='10','fields.name.length'='2','fields.sex.length'='1','fields.clazz.length'='4'
);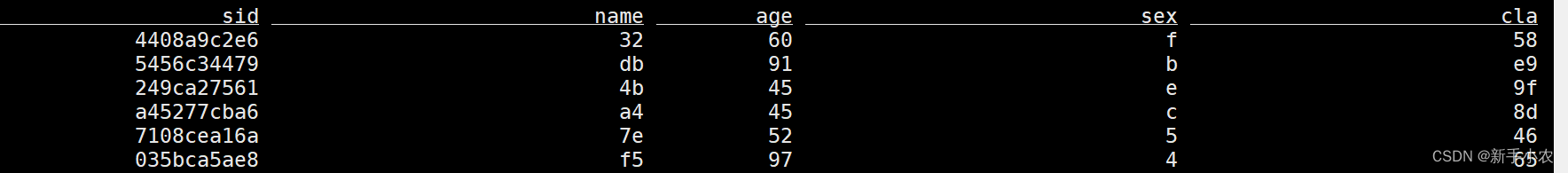
5、print:用于高性能测试 只能用于sink表
CREATE TABLE print_table (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'print'
);insert into print_table
select * from students_datagen;结果需要在提交的任务中查看。6、BlackHole :是用于高性能测试使用,在后面可以用于Flink的反压的测试。
CREATE TABLE blackhole_table (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'blackhole'
);insert into blackhole_table
select * from students_datagen;6、SQL 语法
1、Hints:
用于提示执行,在Flink中可以动态的修改表中的属性,在Spark中可以用于广播。在修改动态表中属性后,不需要在重新建表,就可以读取修改后的需求。
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 动态修改表属性,可以在查询数据时修改读取kafka数据的位置,不需要重新创建表
select * from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */;-- 有界流
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);-- 可以在查询hdfs时,不需要再重新的创建表就可以动态改成无界流
select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */;2、WITH:
当一段SQL语句在被多次使用的时候,就将通过with给这个SQL起一个别名,类似于封装起来,就是为这个SQL创建一个临时的视图(并不是真正的视图),方便下次使用。
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);-- 可以在查询hdfs时,不需要再重新的创建表就可以动态改成无界流
select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */;-- tmp别名代表的时子查询的sql,可以在后面的sql中多次使用
with tmp as (select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */where clazz='文科一班'
)
select * from tmp
union all
select * from tmp;3、DISTINCT:
在flink 的流处理中,使用distinct,flink需要将之前的数据保存在状态中,如果数据一直增加,状态会越来越大 状态越来越大,checkpoint时间会增加,最终会导致flink任务出问题
select
count(distinct sid)
from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */;select count(sid)
from (select distinct *from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */
);注意事项:
1、 当Flink Client客户端退出来以后,里面创建的动态表就不存在了。这些表结构是元数据,是存储在内存中的。
2、当在进行where过滤的时候,字符串会出现三种情况:空的字符串、空格字符串、null的字符串,三者是有区别的:
这三者是不同的概念,在进行where过滤的时候过滤的条件是不同的。
1、过滤空的字符串:where s!= ‘空字符串’2、过滤空格字符串:where s!= ‘空格’3、过滤null字符串:where s!= nullFlink SQL中常见的函数:from_unixtime: 以字符串格式 string 返回数字参数 numberic 的表示形式(默认为 ‘yyyy-MM-dd HH:mm:ss’to_timestamp: 将格式为 string2(默认为:‘yyyy-MM-dd HH:mm:ss’)的字符串 string1 转换为 timestamp相关文章:
Flink SQL -- 命令行的使用
1、启动Flink SQL 首先启动Flink的集群,选择独立集群模式或者是session的模式。此处选择是时session的模式:yarn-session.sh -d 在启动Flink SQL的client: sql-client.sh 2、kafka SQL 连接器 在使用kafka作为数据源的时候需要上传jar包到…...

asp.net core把所有接口和实现类批量注入到容器
要将所有接口和实现类批量注入到容器,可以使用反射和循环来实现自动批量注册。下面是一种示例方法: 创建一个扩展方法,用于批量注册接口和实现类。 public static class ServiceCollectionExtensions {public static IServiceCollection Re…...
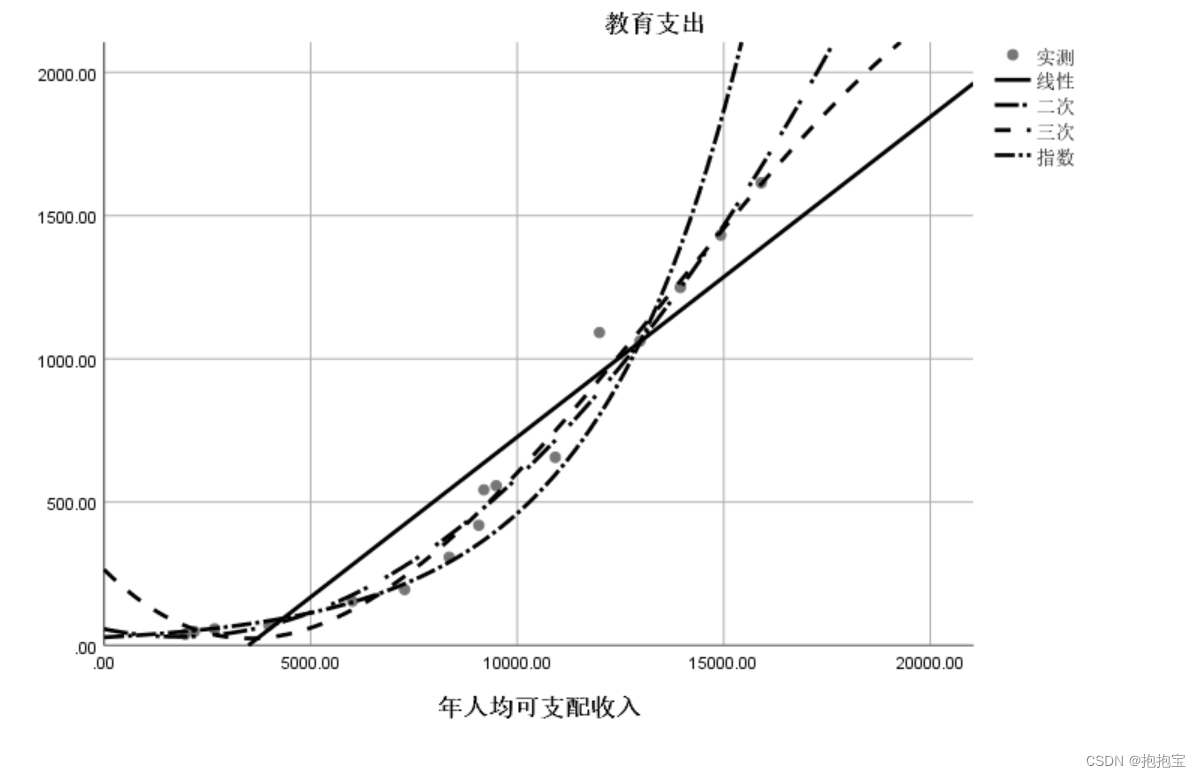
SPSS曲线回归
前言: 本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0 本专栏所有的数据文件请点击此链接下…...
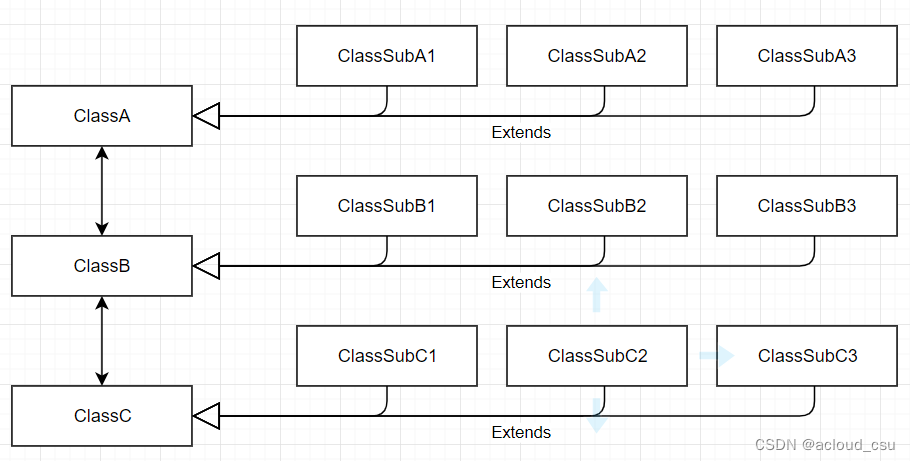
软件之禅(七)面向对象(Object Oriented)
黄国强 2023/11/11 前文提到面向对象构建的模块控制器,根据第一性原理,从图灵机的角度,面向对象不是最基本的元素。那么面向对象是不是不重要呢? 答案是否定的,面向对象非常非常重要。当我们面对一个具体的领域…...

汽车之家车型_车系_配置参数数据抓取
// 导入所需的库 #include <iostream> #include <fstream> #include <string> #include <curl/curl.h> #include <regex>// 声明全局变量 std::string htmlContent; std::regex carModelRegex("\\d{4}-\\d{2}-\\d{2}"); std::regex ca…...
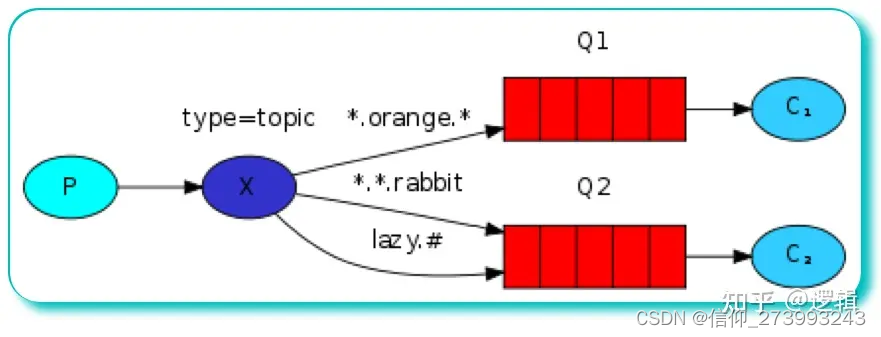
RabbitMQ的 五种工作模型
RabbitMQ 其实一共有六种工作模式: 简单模式(Simple)、工作队列模式(Work Queue)、 发布订阅模式(Publish/Subscribe)、路由模式(Routing)、通配符模式(Topi…...
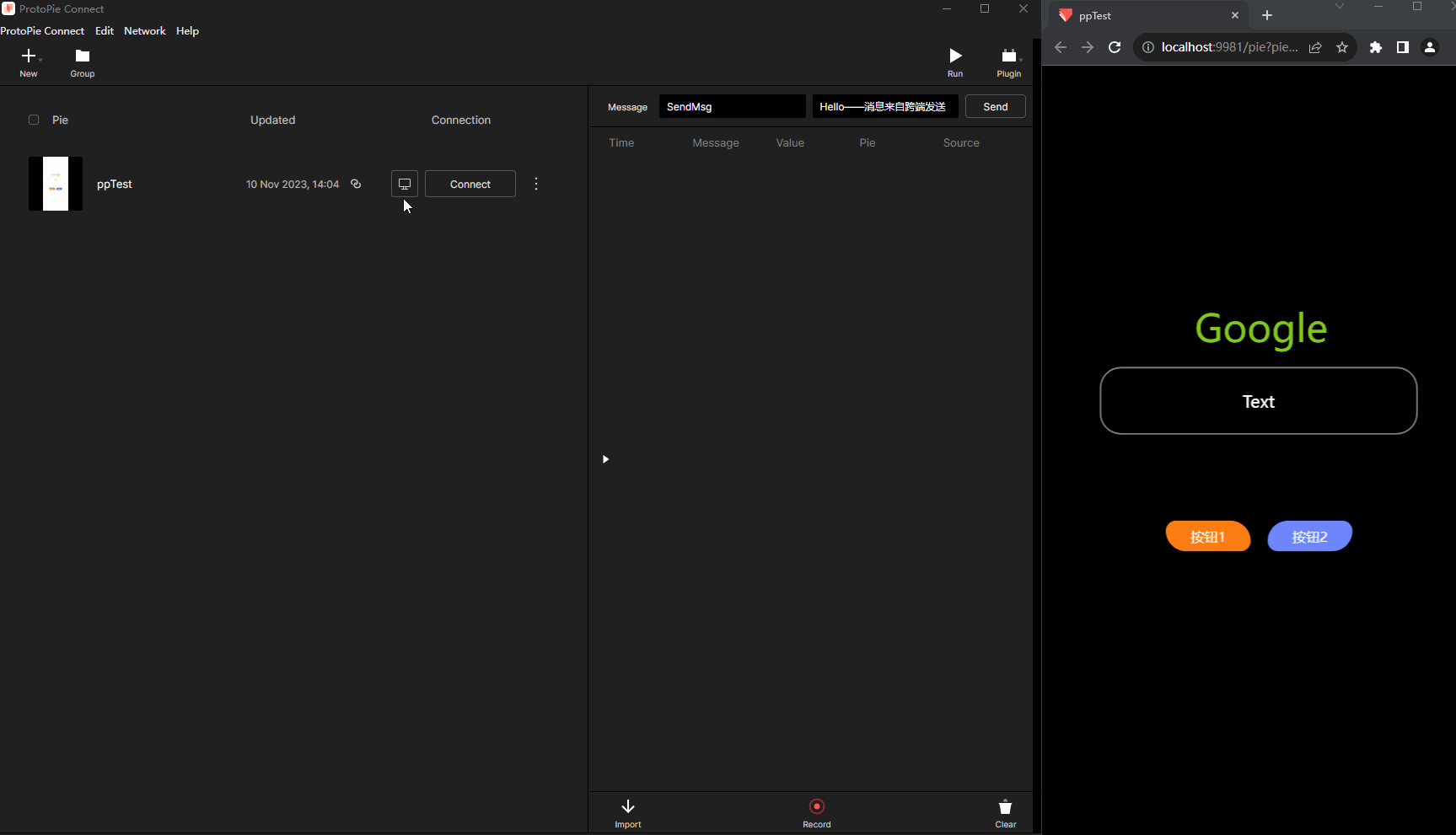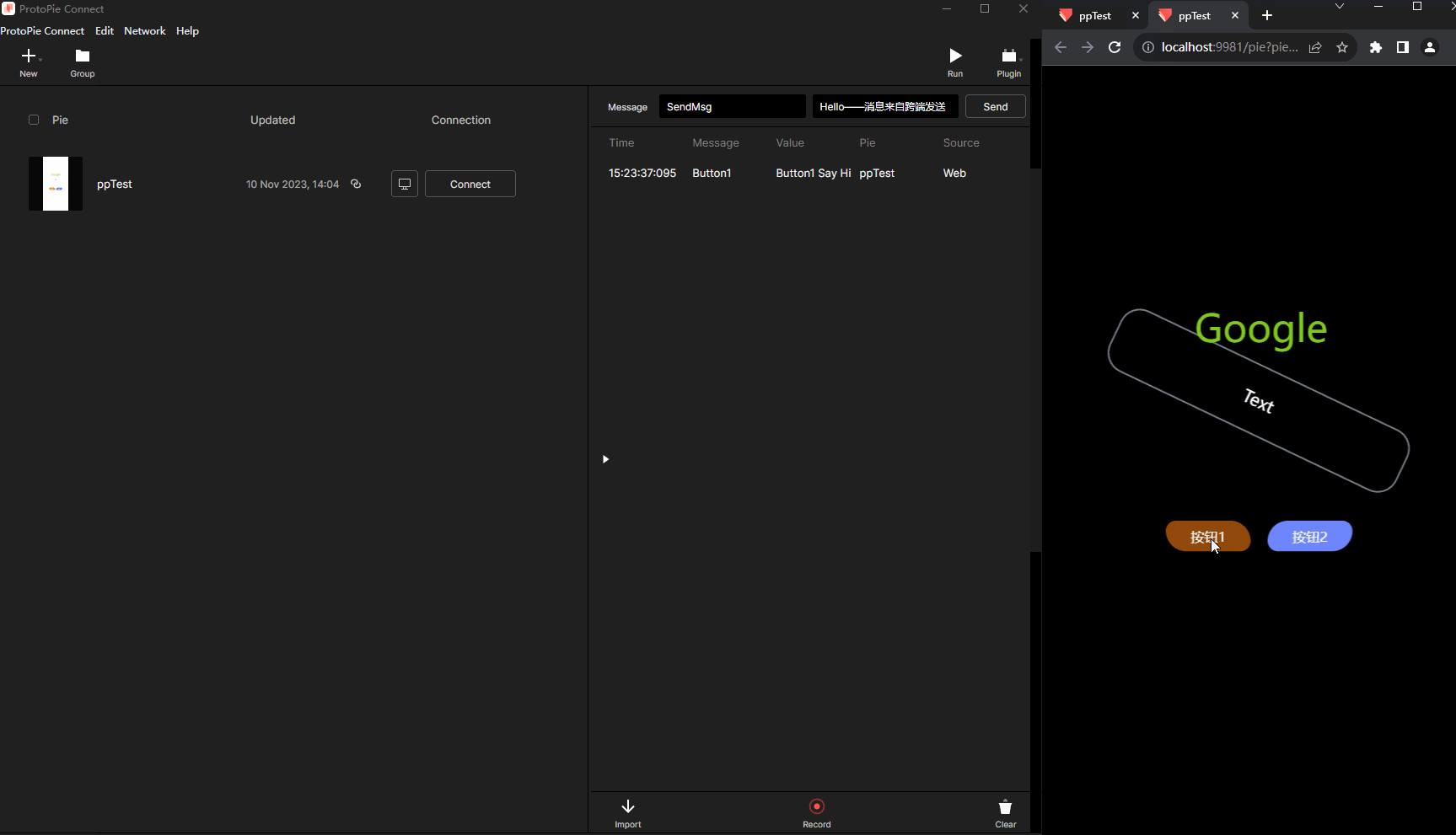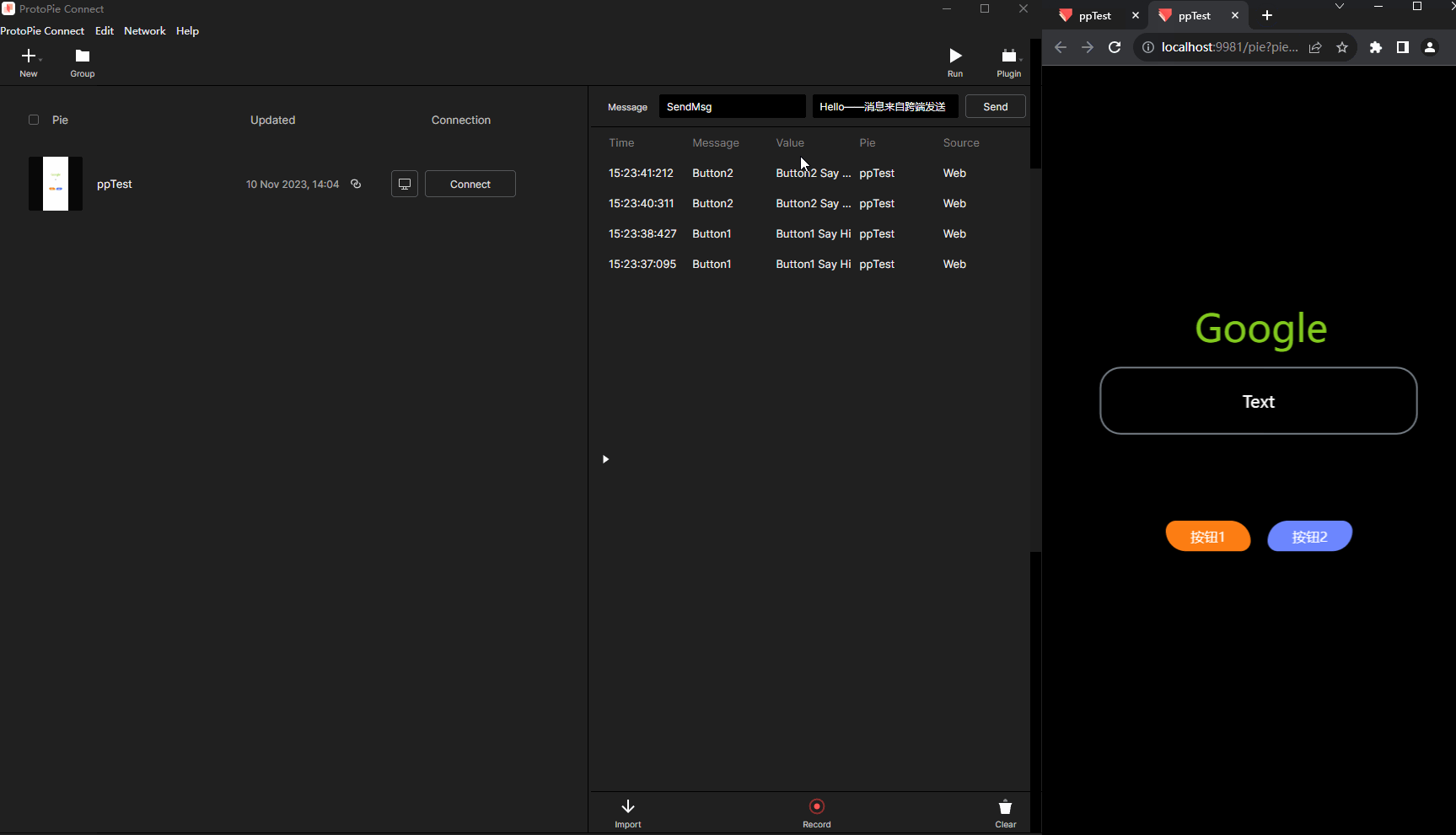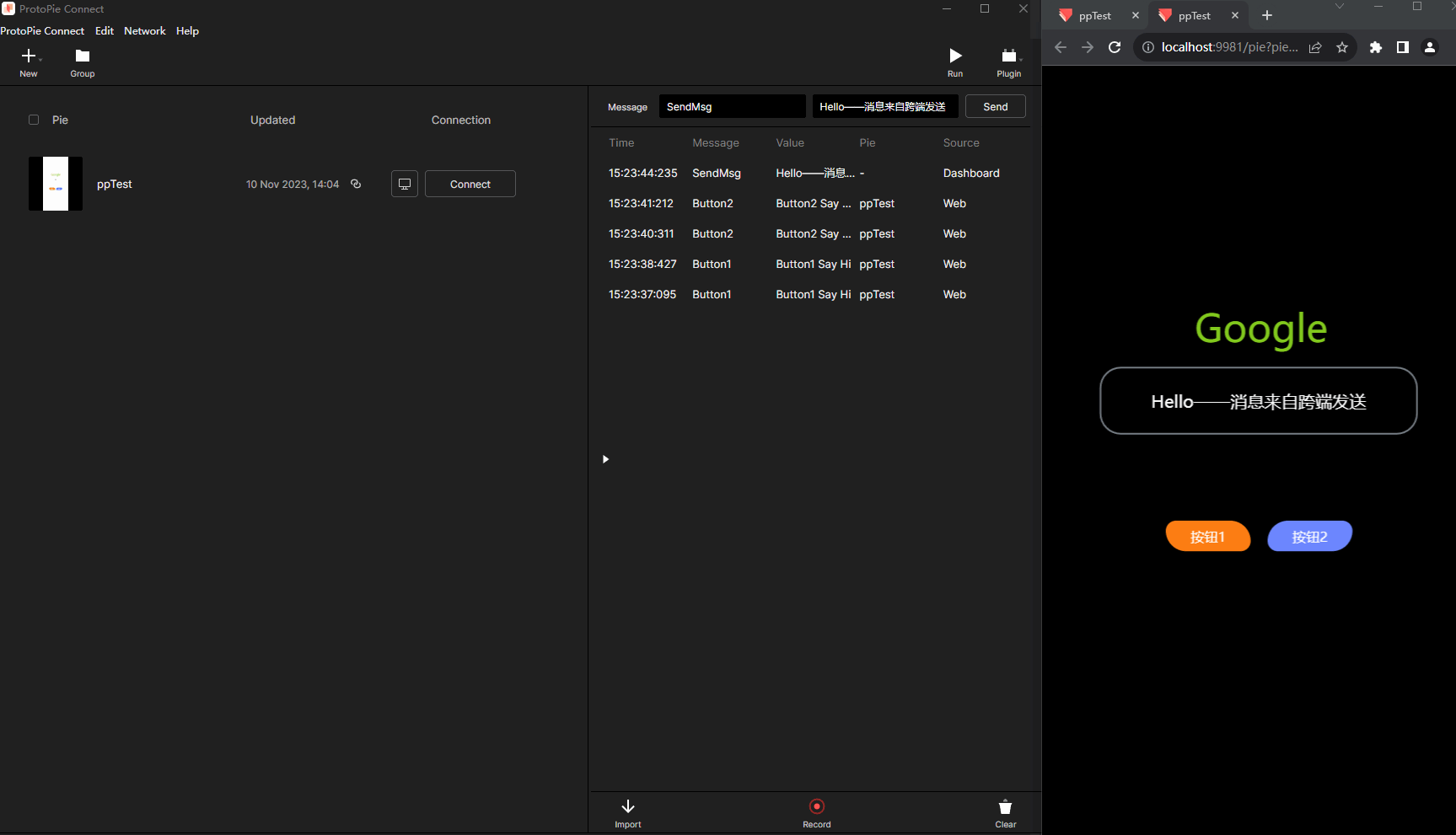
原型制作神器ProtoPie的使用Unity与网页跨端交互
什么是ProtoPie? ProtoPie是一款面向设计师的软件原型设计工具,例如制作App界面交互展示,制作好的原型可以一键发布到Web服务器,就可以浏览器访问。由于其内置了大量常用交互类型,以及"程序化"模块…...
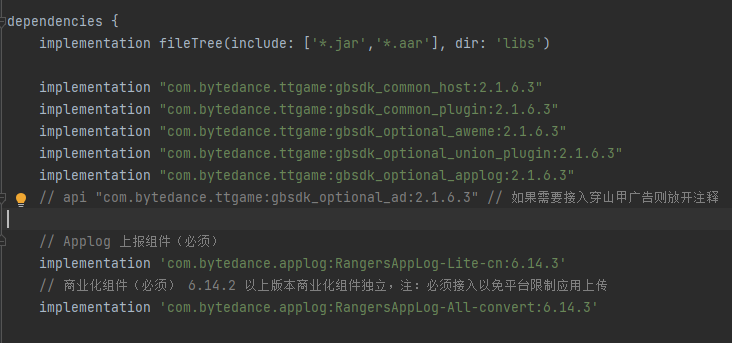
另辟奚径-Android Studio调用Delphi窗体
大家都知道Delphi能调用安卓SDK,比如jar、aar等, 但是反过来,能在Android Studio中调用Delphi开发的窗体吗? 想想不太可能吧, Delphi用的是Pascal,Android Studio用的是Java,这两个怎么能混用…...

SOLID 原则,程序设计五大原则,设计模式
SOLID 是让软件设计更易于理解、更加灵活和更易于维护的五个原则的简称。 单一职责(Single Responsibility Principle):修改一个类的原因只能有一个。开闭原则(Open/Closed Principle):对于扩展,类应该是“开放”的;对于修改&…...
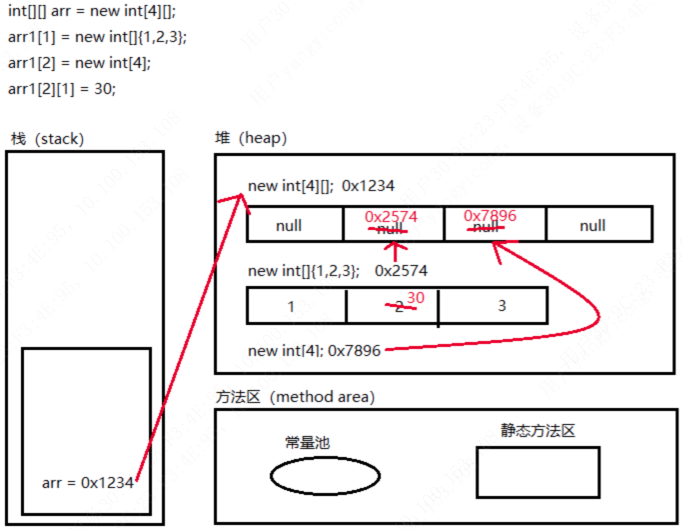
Java基础——数组(一维数组与二维数组)
文章目录 一维数组声明初始化与赋值内存图解 二维数组声明初始化与赋值内存图解 数组练习 数组是多个相同类型的数据按一定顺序排列的集合。 说明: 数组是引用数据类型,数组的元素是同一类型的任何数据类型,包括基本数据类型和引用数据类型…...

Python爬虫抓取微博数据及热度预测
首先我们需要安装 requests 和 BeautifulSoup 库,可以使用以下命令进行安装: pip install requests pip install beautifulsoup4然后,我们需要导入 requests 和 BeautifulSoup 库: import requests from bs4 import BeautifulSou…...
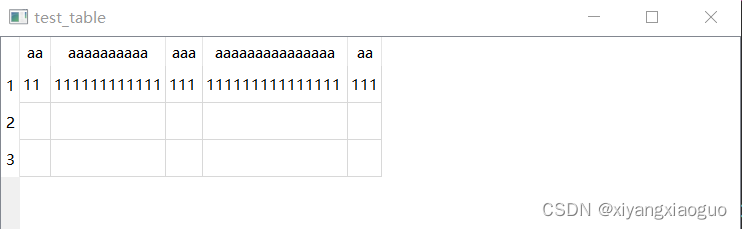
Qt QTableWidget表格的宽度
默认值 QTableWIdget的表格宽度默认是一个给定值,可以手动调整每列的宽度,也不填满父窗口 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent) {this->resize(800,600);QStringList contents{"11","111111111111",&…...

OpenCV(opencv_apps)在ROS中的视频图像的应用(重点讲解哈里斯角点的检测)
1、引言 通过opencv_apps,你可以在ROS中以最简单的方式运行OpenCV提供的许多功能,也就是说,运行一个与功能相对应的launch启动文件,就可以跳过为OpenCV的许多功能编写OpenCV应用程序代码,非常的方便。 对于想熟悉每个…...

常见排序算法之插入排序类
插入排序,是一种简单直观的排序算法,工作原理是将一个记录插入到已经排好序的有序表中,从而形成一个新的、记录数增1的有序表。在实现过程中,它使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循…...

Dubbo服务消费端远程调用过程剖析
1 Dubbo服务消费端远程调用过程概述 (1)当消费方调用远程服务的方法时,会被InvokerInvocationHandler拦截,执行其invoke()方法,创建RpcInvocation对象; (2)接着会选择远程调用的负…...

华硕荣获“EPEAT Climate+ Champion”永续先驱称号
华硕持续深耕永续理念,努力提供低碳排放、高效能产品,并被全球电子委员会授予“EPEAT Climate Champion”称号。这一荣誉再次表明了华硕在永续管理方面的承诺,并凸显了华硕在追求永续发展上的决心。 华硕通过设立“科学基础减碳目标”、“再生…...

基于QT使用OpenGL,加载obj模型,进行鼠标交互
目录 功能分析(需求分析)技术点分析OpenGL立即渲染模式可编程渲染管线模式 QOpenGLWidget派生类 glwidget逻辑glwidget.hglwidget.cpp 鼠标交互功能obj格式介绍 效果bunnyCayman_GT 功能分析(需求分析) 基于QT平台,使…...

三大赛题指南发布!2023 冬季波卡黑客松本周末开启 Workshop
2023 年一众黑客松赛事中,为什么我们建议您选择波卡黑客松大赛?或许答案在于——作为开发者极度友好的技术生态,波卡能够从参赛者的立场出发,为大家提供从 0 到 1 实现项目孵化成长的机会。这里聚集了一线技术专家的资源力量&…...
 | 算法的空间复杂度简介)
数据结构与算法(Java版) | 算法的空间复杂度简介
关于算法的空间复杂度,下面我给大家作一个简单介绍。 类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,同样,它也是问题规模n的一个函数。 其实,…...
)
大数据-之LibrA数据库系统告警处理(ALM-12037 NTP服务器异常)
告警解释 当NTP服务器异常时产生该告警。 当NTP服务器异常消除时,该告警恢复。 告警属性 告警ID 告警级别 可自动清除 12037 严重 是 告警参数 参数名称 参数含义 ServiceName 产生告警的服务名称。 RoleName 产生告警的角色名称。 HostName 异常N…...
)
告别锁总线!用PCIe原子操作在FPGA加速卡上实现高性能数据同步(以FetchAdd为例)
告别锁总线!用PCIe原子操作在FPGA加速卡上实现高性能数据同步(以FetchAdd为例) 当你在FPGA加速卡上处理高并发数据流时,是否遇到过这样的场景:多个处理核心需要频繁更新共享计数器,而传统的锁机制让性能断崖…...

从VS Code老手到鸿蒙新手:DevEco Studio 3.0保姆级上手避坑指南
从VS Code老手到鸿蒙新手:DevEco Studio 3.0保姆级上手避坑指南 如果你已经习惯了VS Code的轻量高效,初次打开DevEco Studio可能会觉得有些"重量级"——就像从自行车换到了全地形车。但别担心,这种"沉重感"背后是华为为…...
:在Vue模板里直接调用全局方法的两种更优雅写法)
告别this.$forceUpdate():在Vue模板里直接调用全局方法的两种更优雅写法
告别this.$forceUpdate():在Vue模板里直接调用全局方法的两种更优雅写法 在Vue开发中,我们经常会遇到需要手动触发视图更新的场景。传统做法是在methods中定义方法并调用this.$forceUpdate(),但这种方式往往显得冗余,尤其是当逻辑…...

PCIE 3.0信号完整性仿真实战:从S参数提取到合规性验证
1. PCIe 3.0信号完整性仿真的核心挑战 当你第一次接触PCIe 3.0设计时,最让人头疼的莫过于那些看似简单的差分对信号在实际布线后变得"面目全非"。我清楚地记得第一次用示波器测量8Gbps信号时的震惊——眼图几乎完全闭合,就像眯成一条缝的眼睛。…...

如何彻底解决RimWorld卡顿:Performance Fish性能优化完整指南
如何彻底解决RimWorld卡顿:Performance Fish性能优化完整指南 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 如果您正在RimWorld中管理大型殖民地时遭遇令人沮丧的游戏卡顿…...

Janus-Pro-7B企业级应用:基于Dify构建智能客服知识库
Janus-Pro-7B企业级应用:基于Dify构建智能客服知识库 很多企业都想用AI来升级客服系统,但一提到大模型,大家的第一反应往往是:技术门槛高、部署复杂、成本难以控制。有没有一种方法,能让企业快速、低成本地搭建一个真…...

域名与DNS解析原理
域名与DNS解析原理:互联网的“导航系统” 在互联网世界中,域名就像是我们熟悉的地址,而DNS(域名系统)则是将这些地址转换为计算机能识别的IP地址的“导航系统”。没有DNS,我们可能需要记住一串复杂的数字&…...

谷歌Brain++液态神经网络实战:5分钟看懂如何用动态权重提升无人机避障性能
谷歌Brain液态神经网络实战:动态权重如何重塑无人机避障逻辑 当无人机在密集的竹林间穿行时,传统神经网络需要消耗大量算力处理每一帧图像,而液态神经网络(LNNs)的神经元连接权重会像液体一样根据气流变化实时调整——…...

5分钟搞定Windows和Office永久激活:KMS智能激活工具完整教程
5分钟搞定Windows和Office永久激活:KMS智能激活工具完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否厌倦了Windows系统不断弹出的激活提醒?是否因为Office…...
深度解析:BitTorrent Tracker服务器列表的技术价值与实践应用
深度解析:BitTorrent Tracker服务器列表的技术价值与实践应用 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 在P2P文件共享生态系统中,Tracker服务…...