Scala中编写多线程爬虫程序并做可视化处理
目录
一、引言
二、Scala爬虫程序的实现
1、引入必要的库
2、定义爬虫类
3、可视化处理
三、案例分析:使用Scala爬取并可视化处理电影数据
1、定义爬虫类
2、实现爬虫程序的控制逻辑
3、可视化处理电影数据
四、总结
一、引言
随着互联网的快速发展,网络爬虫程序已经成为数据采集的重要工具。Scala作为一种高效、强大的编程语言,具有出色的并发处理能力和丰富的库支持,使其成为网络爬虫程序开发的理想选择。此外,为了提高数据处理的效率和准确性,我们还可以使用可视化技术对爬取的数据进行清洗、预处理和展示。

本文将介绍如何使用Scala编写多线程爬虫程序,并利用可视化技术对数据进行处理和展示。通过本文的介绍,读者将了解Scala的并发编程模型、相关库的使用方法以及数据可视化技术的实现细节。
二、Scala爬虫程序的实现
1、引入必要的库
为了实现多线程爬虫程序,我们需要引入Scala中与并发处理和网络请求相关的库。其中,最常用的是Play框架和AsyncHttpClient库。Play框架提供了高效的并发编程模型,而AsyncHttpClient则可以帮助我们轻松地发送HTTP请求。
2、定义爬虫类
在Scala中,我们可以创建一个名为Spider的类来实现爬虫程序。该类需要包含以下几个部分:
- 初始化:设置爬虫需要访问的URL列表和其他必要的参数。
- 爬取数据:定义一个函数来从指定的URL获取数据。该函数应该使用AsyncHttpClient库发送HTTP请求,并使用Play框架的Future对象来处理异步结果。
- 多线程处理:使用Play框架的Actor模型或线程池来创建多个线程,并发地执行爬取任务。可以使用Future对象来处理每个线程的执行结果。
- 数据存储:将爬取到的数据存储到数据库或文件中,以便后续处理和分析。
3、可视化处理
为了更好地理解和分析爬取到的数据,我们可以使用可视化技术对其进行展示。在Scala中,常用的可视化库包括Apache Spark和ScalaPlot。其中,Apache Spark可以帮助我们对大规模数据进行快速处理和分析,而ScalaPlot则可以轻松地生成各种图表和图形。
三、案例分析:使用Scala爬取并可视化处理电影数据
为了更好地说明Scala爬虫程序和可视化处理的具体实现过程,我们将以爬取IMDb电影数据为例进行详细介绍。本案例将分为以下几个步骤:
1、定义爬虫类
首先,我们需要创建一个名为MovieSpider的类来实现电影数据的爬取任务。在该类中,我们需要定义初始化函数来设置需要访问的URL和其他必要的参数。此外,还需要定义一个函数来从指定的URL获取电影数据。该函数将使用AsyncHttpClient库发送HTTP请求,并使用Play框架的Future对象来处理异步结果。最后,我们需要使用Play框架的Actor模型或线程池来创建多个线程,并发地执行爬取任务。可以使用Future对象来处理每个线程的执行结果,并将爬取到的数据存储到数据库或文件中。
2、实现爬虫程序的控制逻辑
在MovieSpider类中,我们需要实现爬虫程序的控制逻辑。具体来说,我们需要定义一个函数来启动爬虫程序,并指定需要访问的URL列表和其他必要的参数。在该函数中,我们需要创建一个Actor对象或线程池来执行爬取任务。对于每个URL,我们可以创建一个新的Future对象来处理异步结果,并在Actor对象或线程池中执行该任务。当所有任务执行完毕后,我们需要关闭Actor对象或线程池,并输出爬取到的数据。
3、可视化处理电影数据
为了更好地理解和分析爬取到的电影数据,我们可以使用可视化技术对其进行展示。在Scala中,我们可以使用Apache Spark对数据进行快速处理和分析,并使用ScalaPlot生成各种图表和图形来展示数据。例如,我们可以使用Apache Spark对电影数据进行聚类分析,并根据分析结果生成柱状图或饼图等可视化图表。
import scala.concurrent.{Await, Future}
import scala.concurrent.duration._
import play.api.libs.ws.WSClient object Spider { def main(args: Array[String]): Unit = { val urls = List("http://example.com/page1", "http://example.com/page2", "http://example.com/page3") val concurrentRequests = 5 val client = WSClient.fromRequestConfig(ws.DefaultRequestConfig(maxConnections = concurrentRequests)) val futures: List[Future[String]] = urls.map { url => client.url(url).get() map { response => response.body } } val results: List[String] = Await.result(Future.sequence(futures), 10.seconds) // 处理爬取到的数据 results.foreach { result => println(result) } }
}在上面的示例代码中,我们使用了Scala的Play框架中的WSClient库来发送HTTP请求。我们定义了一个包含三个URL的列表,每个URL对应一个需要爬取的网页。然后,我们创建了一个WSClient对象,并指定了最大连接数为5,这意味着可以同时发送5个HTTP请求。
接下来,我们将URL列表转换为Future对象的列表。对于每个URL,我们使用WSClient对象发送GET请求,并使用map方法将响应的主体内容提取出来。这样,我们就得到了一个包含Future对象的列表,每个Future对象表示一个爬取任务的执行结果。
为了等待所有爬取任务完成并获取执行结果,我们使用Future.sequence方法将所有Future对象转换为一个单一的Future对象。然后,我们使用Await.result方法等待10秒钟,以获取最终的执行结果。在这个例子中,我们只是简单地将每个执行结果打印出来,但你可以根据需要对数据进行处理和分析。
四、总结
通过以上案例分析,我们可以看到使用Scala编写多线程爬虫程序并做可视化处理的可行性和优势。Scala的并发编程模型和丰富的库支持使得编写高效、稳定的爬虫程序变得简单易行。同时,结合可视化技术可以更好地理解和分析爬取到的数据,提高数据处理的效率和准确性。
在实际应用中,我们可以根据具体需求调整爬虫程序的实现细节和可视化处理的方式。例如,可以增加更多的特征提取逻辑来丰富爬取到的数据;可以使用更高级的可视化技术来展示复杂的分析结果;可以结合其他数据处理和分析工具来进一步挖掘数据的价值。
总之,使用Scala编写多线程爬虫程序并做可视化处理是一种高效、实用的方法,可以广泛应用于数据采集和处理领域。希望本文的介绍和案例分析能够对读者有所帮助和启示。
相关文章:
Scala中编写多线程爬虫程序并做可视化处理
目录 一、引言 二、Scala爬虫程序的实现 1、引入必要的库 2、定义爬虫类 3、可视化处理 三、案例分析:使用Scala爬取并可视化处理电影数据 1、定义爬虫类 2、实现爬虫程序的控制逻辑 3、可视化处理电影数据 四、总结 一、引言 随着互联网的快速发展&#…...

使用 huggingface_hub 镜像下载 大模型
download.py 👇 import os # 配置 hf镜像 os.environ[HF_ENDPOINT] https://hf-mirror.com# 设置保存的路径 local_dir "XXXXXX"# 设置仓库id model_id "sensenova/piccolo-large-zh"cmd f"huggingface-cli download --resume-downlo…...
,剑指offer,力扣)
路径加密(替换空格),剑指offer,力扣
目录 我们直接看题解吧: 方法: 审题目事例提示: 解题思路: 法1: 代码(法1): 法2: 代码(法2): 原题解: 【剑指Offer】2、替…...
HarmonyOS开发:UI开展前的阶段总结
前言 关于HarmonyOS,陆陆续续总结了有14篇的文章,大家可以发现,没有一篇是关于UI相关的,不是自己没有分享的打算,而是对于这些UI而言,官方都有着一系列的文档输出,如果我再一一的分享࿰…...

Linux安装Libreoffice
windos安装Libreoffice https://zh-cn.libreoffice.org/ C:\路径\LibreOffice\program\soffice.bin --help 看是否输出帮助命令 Linux安装Libreoffice 1、下载rpm包并解压https://mirrors.cloud.tencent.com/libreoffice/libreoffice/stable/ 2、安装: yum install…...
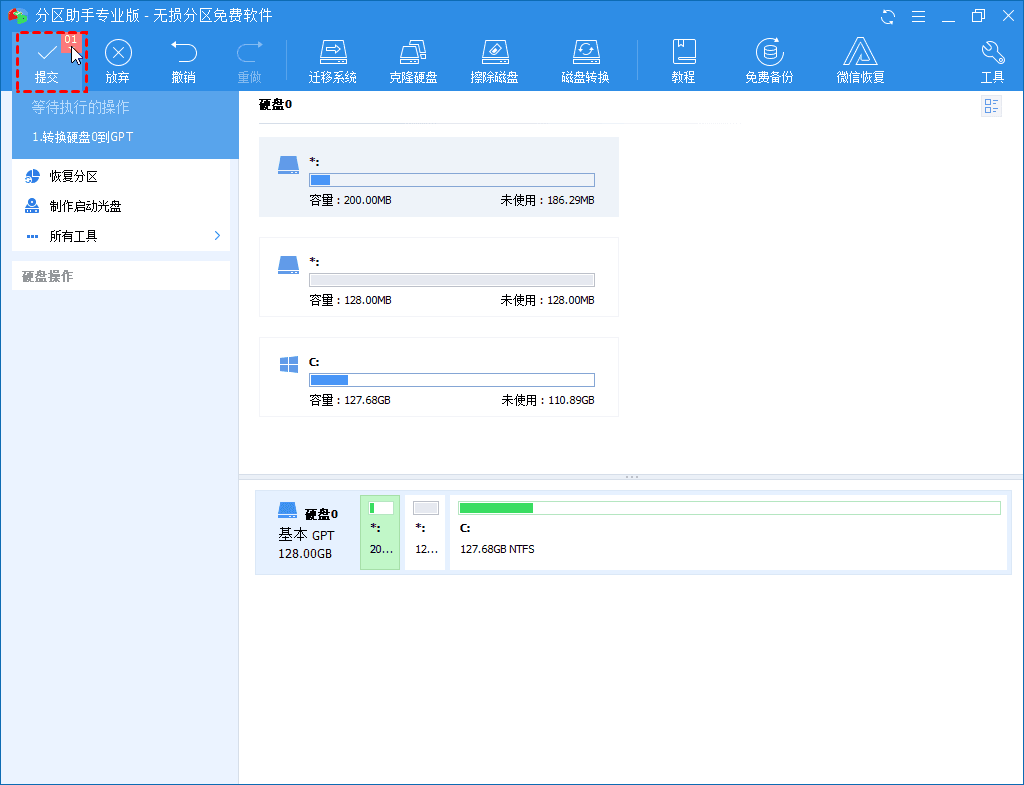
如何将系统盘MBR转GPT?无损教程分享!
什么是MBR和GPT? MBR和GPT是磁盘的两种分区形式:MBR(主引导记录)和GPT(GUID分区表)。 新硬盘不能直接用来保存数据。使用前应将其初始化为MBR或GPT分区形式。但是,如果您在MBR时需…...
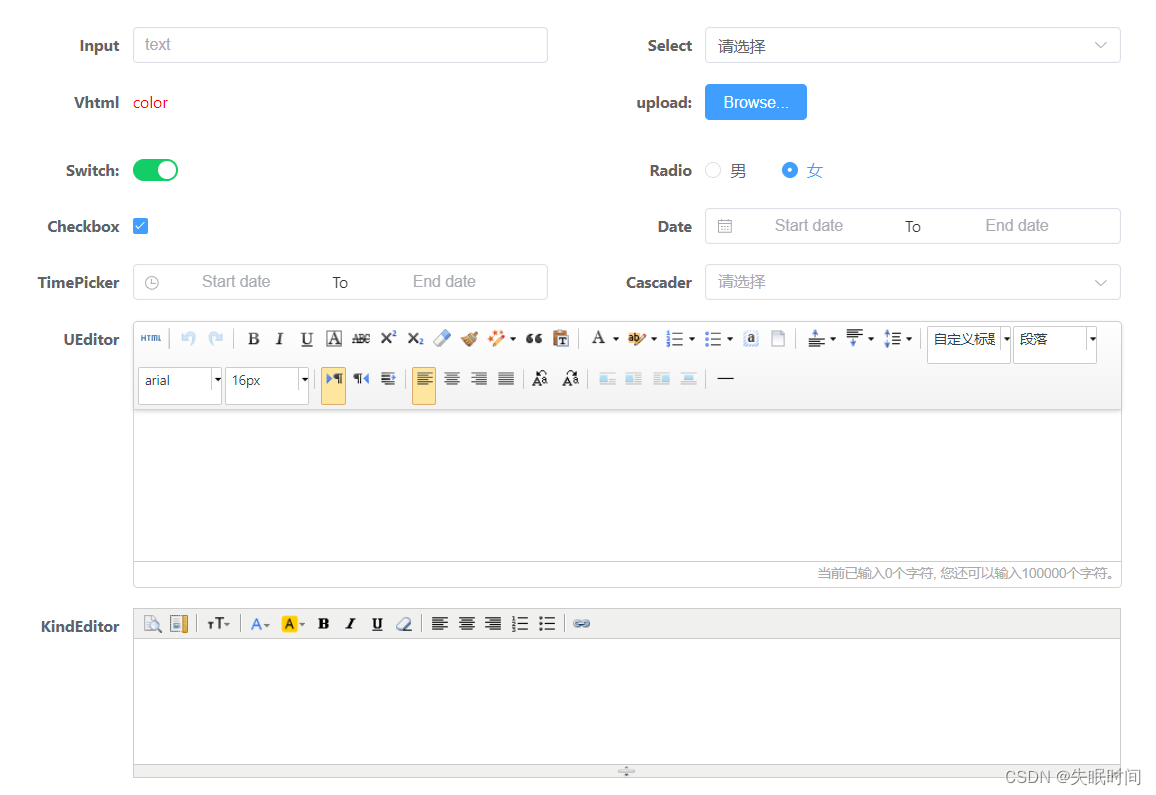
基于element-plus定义表单配置化
文章目录 前言一、配置化的前提二、配置的相关组件1、新建form.vue组件2、新建input.vue组件3、新建select.vue组件4、新建v-html.vue组件5、新建upload.vue组件6、新建switch.vue组件7、新建radio.vue组件8、新建checkbox.vue组件9、新建date.vue组件10、新建time-picker.vue组…...
|LeetCode122. 买卖股票的最佳时机 II、LeetCoed55. 跳跃游戏、LeetCode45. 跳跃游戏 II)
LeetCode算法题解(贪心)|LeetCode122. 买卖股票的最佳时机 II、LeetCoed55. 跳跃游戏、LeetCode45. 跳跃游戏 II
一、LeetCode122. 买卖股票的最佳时机 II 题目链接:122. 买卖股票的最佳时机 II 题目描述: 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 …...

计蒜客详解合集(2)期
目录 T1126——单词倒排 T1617——地瓜烧 T1612——蒜头君的数字游戏 T1488——旋转单词 T1461——校验信用卡号码 T1437——最大值和次大值 T1126——单词倒排 超级水的一道题,和T1122类似但更简单,分割后逆序输出即可~ 编写程序,读入…...
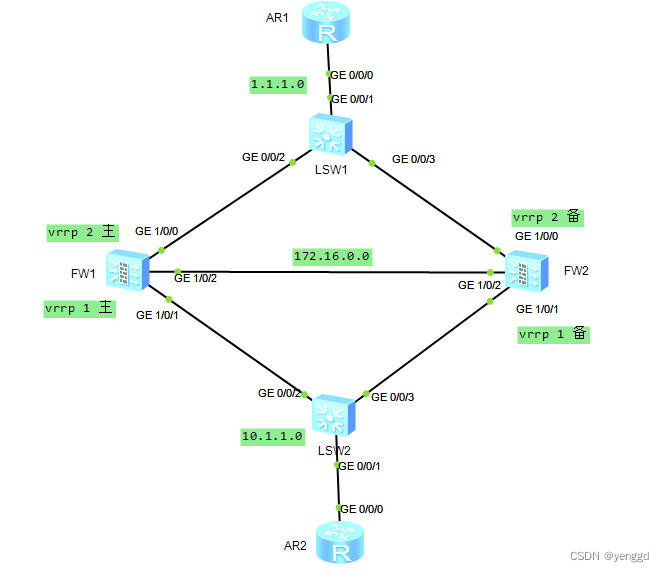
华为防火墙vrrp+hrp双机热备主备备份(两端为交换机)
默认上下来全两个vrrp主都是左边 工作原理: vrrp刚开机都是先initialize状态,然后切成active或standb状态。 hrp使用18514端口,且用的单播,要策略放行,由主设备发hrp心跳报文 如果设备为acitve状态时自动优先级为65…...
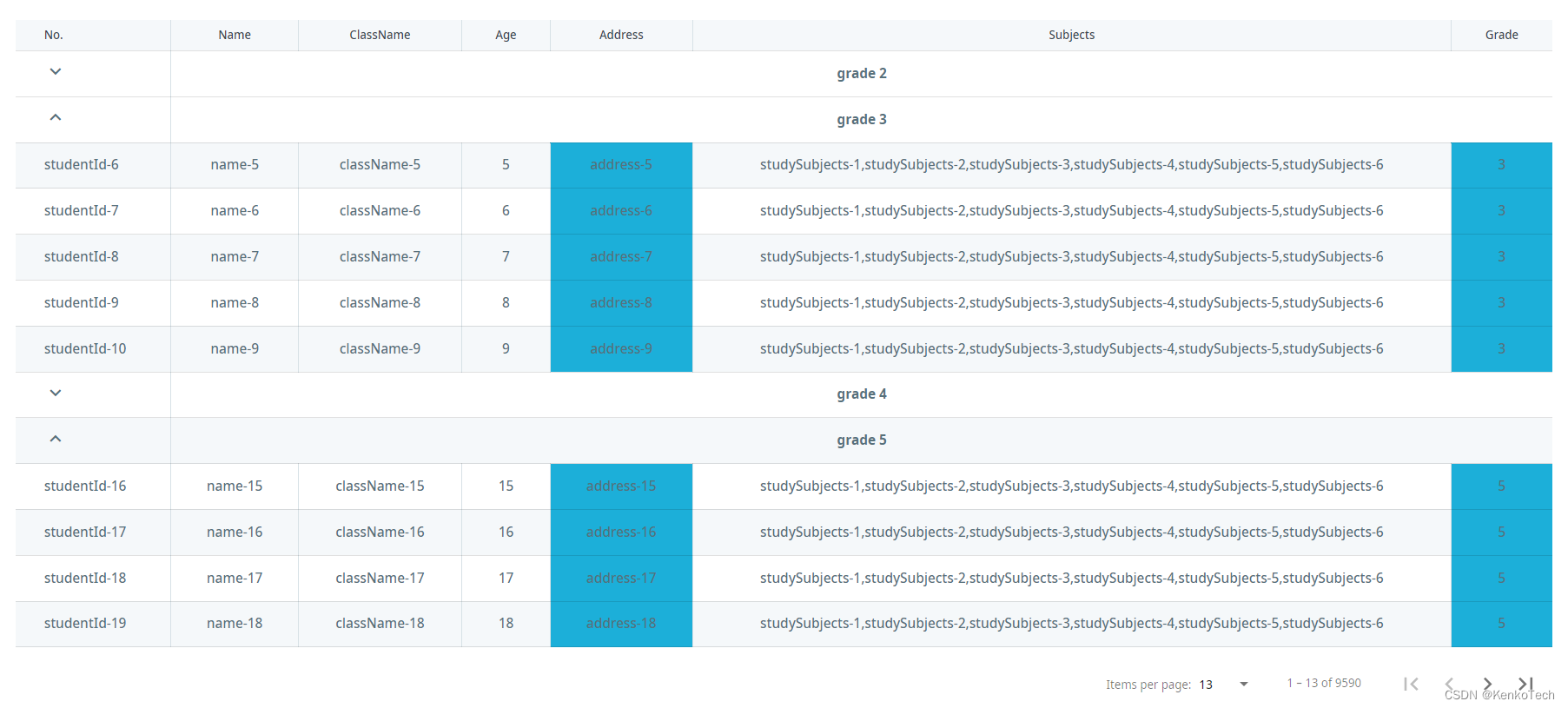
Angular 由一个bug说起之一:List / Grid的性能问题
在angular中,MatTable构建简单,使用范围广。但某些时候会出现卡顿 卡顿情景: 1:一次性请求太多的数据 2:一次性渲染太多数据,这会花费CPU很多时间 3:行内嵌套复杂的元素 4:使用过多的…...
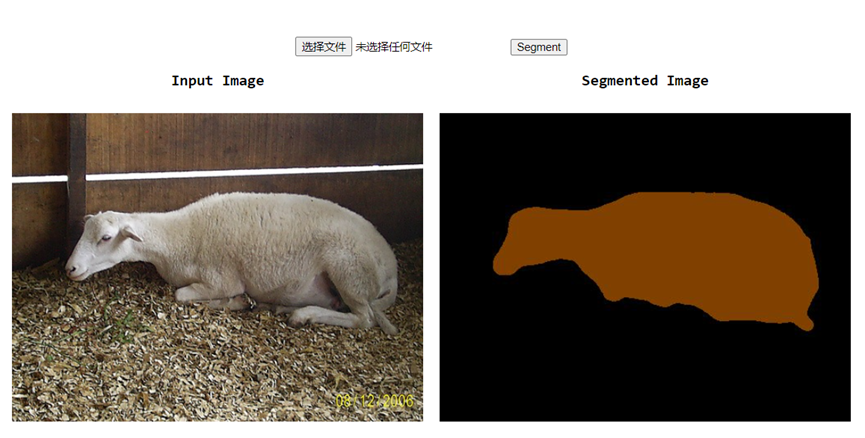
第12章 PyTorch图像分割代码框架-3:推理与部署
推理模块 模型训练完成后,需要单独再写一个推理模块来供用户测试或者使用,该模块可以命名为test.py或者inference.py,导入训练好的模型文件和待测试的图像,输出该图像的分割结果。inference.py主体部分如代码11-7所示。 代码11-7 …...

MYSQL---基础篇
一、数据库操作 1.创建数据库:CREATE DATABASE db_test1; 2.使用数据库:use 数据库名; 3.删除数据库:DROP DATABASE [IF EXISTS] db_name; 4.创建表:CREATE TABLE table_name ( field1 datatype, field2…...
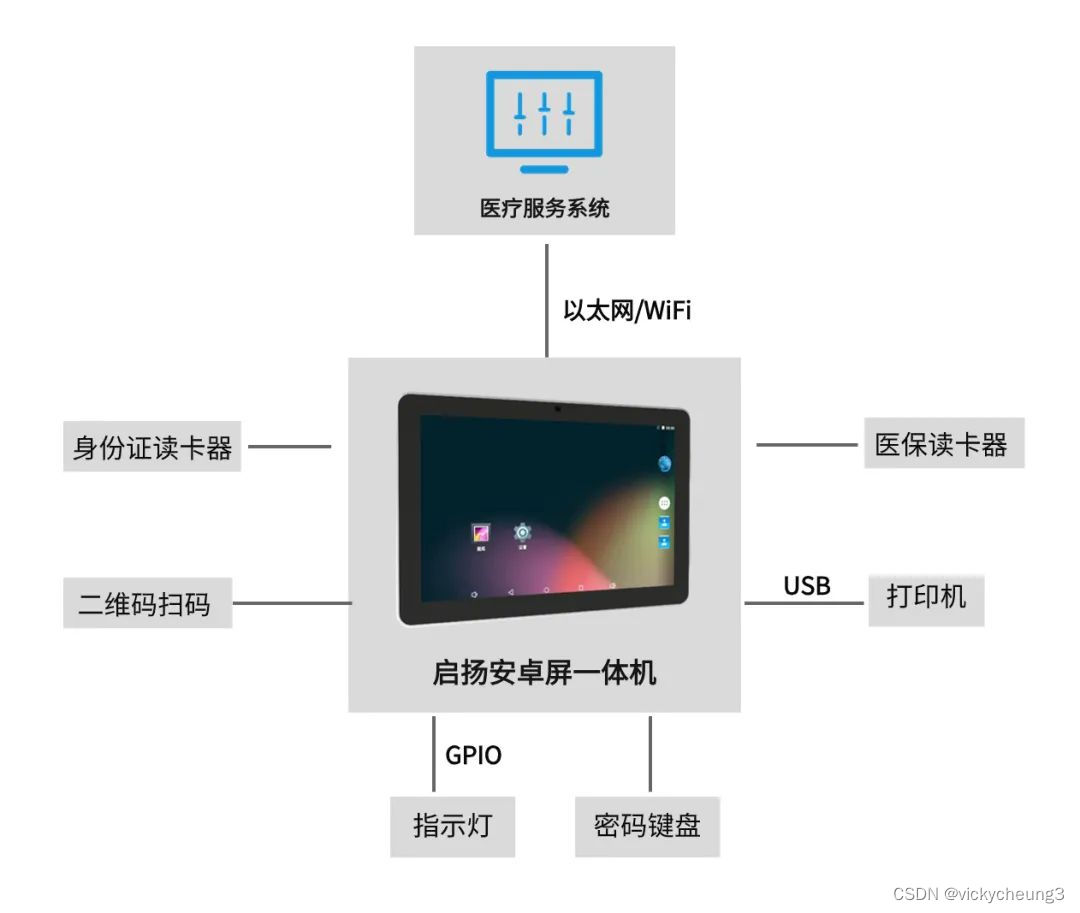
【启扬方案】启扬安卓屏一体机在医疗自助服务终端上的应用解决方案
为了解决传统医疗模式下的“看病难、看病慢”等问题,提高医疗品质、效率与效益,自助服务业务的推广成为智慧医疗领域实现信息化建设、高效运作的重要环节。 医疗自助服务终端是智慧医疗应用场景中最常见的智能设备之一,它通过与医院信息化系统…...

收藏!7个国内「小众」的程序员社区
技术社区是大量开发者的集聚地,在技术社区可以了解到行业的最新进展,学习最前沿的技术,认识有相同爱好的朋友,在一起学习和交流。 国内知名的技术社区有CSDN、博客园、开源中国、51CTO,还有近两年火热的掘金ÿ…...
LeetCode(4)删除有序数组中的重复项 II【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 80. 删除有序数组中的重复项 II 1.题目 给你一个有序数组 nums ,请你** 原地** 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数…...

C++ 同构字符串/ 单词规律
给定两个字符串 s 和 t ,判断它们是否是同构的。 如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。 每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相…...

oracle 中 %TYPE %ROWTYPE
前言 PL/SQL 提供了 %TYPE 和 %ROWTYPE 两种特殊的变量,用于声明与表的列相匹配的变量和用户定义数据类型,前一个表示单属性的数据类型,后一个表示整个属性列表的结构,即元组的类型。 举例: -- 数据表TB_TRANS_RECO…...
-计算机视觉基础)
Pytorch实战教程(五)-计算机视觉基础
0. 前言 计算机视觉是指通过计算机系统对图像和视频进行处理和分析,利用计算机算法和方法,使计算机能够模拟和理解人类的视觉系统。通过计算机视觉技术,计算机可以从图像和视频中提取有用的信息,实现对环境的感知和理解,从而帮助人们解决各种问题和提高效率。本节中,将介…...
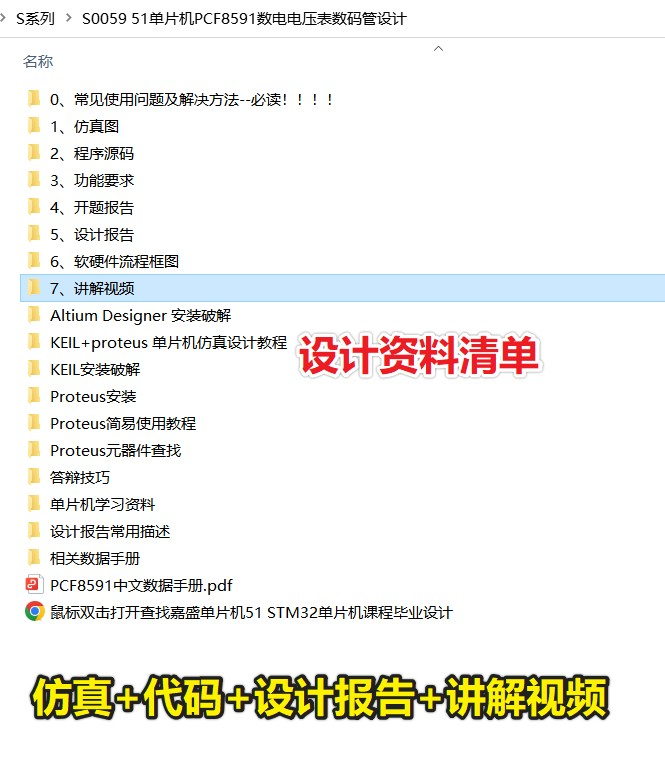
51单片机PCF8591数字电压表数码管显示设计( proteus仿真+程序+设计报告+讲解视频)
PCF8591数字电压表数码管显示 1.主要功能:讲解视频:2.仿真3. 程序代码4. 设计报告5. 设计资料内容清单&&下载链接资料下载链接(可点击): 51单片机PCF8591数字电压表数码管设计( proteus仿真程序设计报告讲解视…...

如何在Windows上完美使用PS4手柄:DS4Windows终极配置指南
如何在Windows上完美使用PS4手柄:DS4Windows终极配置指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 想让你的PlayStation 4手柄在Windows电脑上获得原生游戏体验吗&#…...

如何免费实现专业级电脑风扇智能控制:3步配置你的静音工作站
如何免费实现专业级电脑风扇智能控制:3步配置你的静音工作站 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...
)
保姆级教程:手把手搭建你的第一个ARM AHB+APB+CPU小系统(附仿真环境配置)
从零构建ARM AHBAPBCPU系统的实战指南 在数字IC设计领域,能够独立完成一个完整的SOC系统集成是工程师能力的重要分水岭。本文将带你从零开始,构建一个基于AMBA总线架构的简易SOC系统,包含AHB、APB总线和CPU核心的完整集成方案。不同于理论概述…...

R-CNN系列目标检测的基石:深入理解Selective Search的区域推荐逻辑
R-CNN系列目标检测的基石:深入理解Selective Search的区域推荐逻辑 在计算机视觉领域,目标检测一直是一个核心挑战。想象一下,当你面对一张复杂的街景照片,如何让计算机像人类一样快速识别出其中的行人、车辆和交通标志࿱…...

魔兽争霸3终极助手:WarcraftHelper全版本兼容完整指南
魔兽争霸3终极助手:WarcraftHelper全版本兼容完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3辅助工具WarcraftHelper是…...

储能BMS选型实战:NXP MC33771/74/75 AFE芯片怎么选?看完这篇不再纠结
储能BMS选型实战:NXP MC33771/74/75 AFE芯片深度对比与决策指南 在储能系统设计中,电池管理系统(BMS)的选型直接影响着整个系统的性能、安全性和成本效益。作为BMS的核心组件,模拟前端(AFE)芯片…...

NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率
NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率 1. 认识NaViL-9B多模态模型 NaViL-9B是上海人工智能实验室研发的原生多模态大语言模型,它不仅能处理纯文本问答,还具备强大的图片理解能力。这意味着你可以上传一张图片ÿ…...

保姆级教程:在NRF52840上实现USB虚拟串口,并每秒发送数据到PC和安卓手机
从零构建NRF52840 USB虚拟串口通信系统:跨平台数据收发实战指南 在嵌入式开发中,稳定可靠的通信接口是连接物理设备与数字世界的桥梁。NRF52840作为Nordic Semiconductor旗舰级蓝牙SoC,其内置的USB 2.0全速控制器为开发者提供了除蓝牙之外的…...

Step3-VL-10B模型C盘清理优化:智能存储管理工具开发
Step3-VL-10B模型C盘清理优化:智能存储管理工具开发 用AI技术解决C盘爆满的烦恼,让存储管理变得智能高效 1. 项目背景与需求 你是不是也经常遇到C盘飘红、系统卡顿的困扰?每次手动清理都不知道哪些文件能删、哪些不能动,生怕误删…...

第 28 课:任务页排序偏好与默认工作视图
第 28 课:任务页排序偏好与默认工作视图 这一课,我们继续沿着任务管理页主线往下走,把它再往真实后台系统推进一步: 让用户不只是临时切换排序,还能把当前排序保存成“默认工作视图”。 这件事看起来只是多了一个“记住…...