pytorch代码实现注意力机制之Flatten Attention
Flatten Attention
介绍:最新注意力Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer
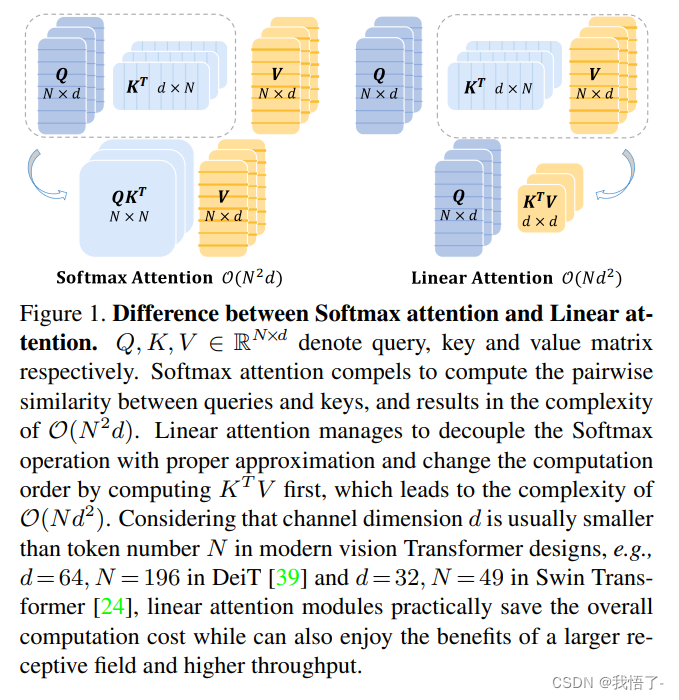
在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系,给视觉任务的应用带来了挑战。各种各样的线性注意力机制 (Linear Attention) 的计算复杂度随序列长度的大小呈线性关系,可以提供一种更有效的替代方案。线性注意力机制通过精心设计的映射函数来替代 Self-Attention 中的 Softmax 操作,但是这种技术路线要么会面临比较严重的性能下降,要么从映射函数中引入额外的计算开销。
本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。作者首先分析了是什么导致了线性注意力机制性能的下降?然后归结为了两个方面:聚焦能力 (Focus Ability) 和特征丰富度 (Feature Diversity),然后提出一个简单而有效的映射函数和一个高效的秩恢复模块来增强自我注意的表达能力,同时保持较低的计算复杂度。
原文地址:FLatten Transformer: Vision Transformer using Focused Linear Attention
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partialfrom timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from einops.layers.torch import Rearrange
import torch.utils.checkpoint as checkpoint
import numpy as np
import time
from einops import rearrangedef _cfg(url='', **kwargs):return {'url': url,'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,'crop_pct': .9, 'interpolation': 'bicubic','mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,'first_conv': 'patch_embed.proj', 'classifier': 'head',**kwargs}default_cfgs = {'cswin_224': _cfg(),'cswin_384': _cfg(crop_pct=1.0),}class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass LePEAttention(nn.Module):def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0.,qk_scale=None):super().__init__()self.dim = dimself.dim_out = dim_out or dimself.resolution = resolutionself.split_size = split_sizeself.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5if idx == -1:H_sp, W_sp = self.resolution, self.resolutionelif idx == 0:H_sp, W_sp = self.resolution, self.split_sizeelif idx == 1:W_sp, H_sp = self.resolution, self.split_sizeelse:print("ERROR MODE", idx)exit(0)self.H_sp = H_spself.W_sp = W_spstride = 1self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim)self.attn_drop = nn.Dropout(attn_drop)def im2cswin(self, x):B, N, C = x.shapeH = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W)x = img2windows(x, self.H_sp, self.W_sp)x = x.reshape(-1, self.H_sp * self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()return xdef get_lepe(self, x, func):B, N, C = x.shapeH = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W)H_sp, W_sp = self.H_sp, self.W_spx = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'lepe = func(x) ### B', C, H', W'lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3, 2).contiguous()x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp * self.W_sp).permute(0, 1, 3, 2).contiguous()return x, lepedef forward(self, qkv):"""x: B L C"""q, k, v = qkv[0], qkv[1], qkv[2]### Img2WindowH = W = self.resolutionB, L, C = q.shapeassert L == H * W, "flatten img_tokens has wrong size"q = self.im2cswin(q)k = self.im2cswin(k)v, lepe = self.get_lepe(v, self.get_v)q = q * self.scaleattn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N Nattn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)attn = self.attn_drop(attn)x = (attn @ v) + lepex = x.transpose(1, 2).reshape(-1, self.H_sp * self.W_sp, C) # B head N N @ B head N C### Window2Imgx = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C) # B H' W' Creturn xclass FocusedLinearAttention(nn.Module):def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0.,qk_scale=None, focusing_factor=3, kernel_size=5):super().__init__()self.dim = dimself.dim_out = dim_out or dimself.resolution = resolutionself.split_size = split_sizeself.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights# self.scale = qk_scale or head_dim ** -0.5if idx == -1:H_sp, W_sp = self.resolution, self.resolutionelif idx == 0:H_sp, W_sp = self.resolution, self.split_sizeelif idx == 1:W_sp, H_sp = self.resolution, self.split_sizeelse:print("ERROR MODE", idx)exit(0)self.H_sp = H_spself.W_sp = W_spstride = 1self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim)self.attn_drop = nn.Dropout(attn_drop)self.focusing_factor = focusing_factorself.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,groups=head_dim, padding=kernel_size // 2)self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))self.positional_encoding = nn.Parameter(torch.zeros(size=(1, self.H_sp * self.W_sp, dim)))print('Linear Attention {}x{} f{} kernel{}'.format(H_sp, W_sp, focusing_factor, kernel_size))def im2cswin(self, x):B, N, C = x.shapeH = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W)x = img2windows(x, self.H_sp, self.W_sp)# x = x.reshape(-1, self.H_sp * self.W_sp, C).contiguous()return xdef get_lepe(self, x, func):B, N, C = x.shapeH = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W)H_sp, W_sp = self.H_sp, self.W_spx = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'lepe = func(x) ### B', C, H', W'lepe = lepe.reshape(-1, C // self.num_heads, H_sp * W_sp).permute(0, 2, 1).contiguous()x = x.reshape(-1, C, self.H_sp * self.W_sp).permute(0, 2, 1).contiguous()return x, lepedef forward(self, qkv):"""x: B L C"""q, k, v = qkv[0], qkv[1], qkv[2]### Img2WindowH = W = self.resolutionB, L, C = q.shapeassert L == H * W, "flatten img_tokens has wrong size"q = self.im2cswin(q)k = self.im2cswin(k)v, lepe = self.get_lepe(v, self.get_v)# q, k, v = (rearrange(x, "b h n c -> b n (h c)", h=self.num_heads) for x in [q, k, v])k = k + self.positional_encodingfocusing_factor = self.focusing_factorkernel_function = nn.ReLU()scale = nn.Softplus()(self.scale)q = kernel_function(q) + 1e-6k = kernel_function(k) + 1e-6q = q / scalek = k / scaleq_norm = q.norm(dim=-1, keepdim=True)k_norm = k.norm(dim=-1, keepdim=True)q = q ** focusing_factork = k ** focusing_factorq = (q / q.norm(dim=-1, keepdim=True)) * q_normk = (k / k.norm(dim=-1, keepdim=True)) * k_normq, k, v = (rearrange(x, "b n (h c) -> (b h) n c", h=self.num_heads) for x in [q, k, v])i, j, c, d = q.shape[-2], k.shape[-2], k.shape[-1], v.shape[-1]z = 1 / (torch.einsum("b i c, b c -> b i", q, k.sum(dim=1)) + 1e-6)if i * j * (c + d) > c * d * (i + j):kv = torch.einsum("b j c, b j d -> b c d", k, v)x = torch.einsum("b i c, b c d, b i -> b i d", q, kv, z)else:qk = torch.einsum("b i c, b j c -> b i j", q, k)x = torch.einsum("b i j, b j d, b i -> b i d", qk, v, z)feature_map = rearrange(v, "b (h w) c -> b c h w", h=self.H_sp, w=self.W_sp)feature_map = rearrange(self.dwc(feature_map), "b c h w -> b (h w) c")x = x + feature_mapx = x + lepex = rearrange(x, "(b h) n c -> b n (h c)", h=self.num_heads)x = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C)return xclass CSWinBlock(nn.Module):def __init__(self, dim, reso, num_heads,split_size=7, mlp_ratio=4., qkv_bias=False, qk_scale=None,drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,last_stage=False,focusing_factor=3, kernel_size=5, attn_type='L'):super().__init__()self.dim = dimself.num_heads = num_headsself.patches_resolution = resoself.split_size = split_sizeself.mlp_ratio = mlp_ratioself.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.norm1 = norm_layer(dim)if self.patches_resolution == split_size:last_stage = Trueif last_stage:self.branch_num = 1else:self.branch_num = 2self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(drop)assert attn_type in ['L', 'S']if attn_type == 'L':if last_stage:self.attns = nn.ModuleList([FocusedLinearAttention(dim, resolution=self.patches_resolution, idx=-1,split_size=split_size, num_heads=num_heads, dim_out=dim,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,focusing_factor=focusing_factor, kernel_size=kernel_size)for i in range(self.branch_num)])else:self.attns = nn.ModuleList([FocusedLinearAttention(dim // 2, resolution=self.patches_resolution, idx=i,split_size=split_size, num_heads=num_heads // 2, dim_out=dim // 2,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,focusing_factor=focusing_factor, kernel_size=kernel_size)for i in range(self.branch_num)])else:if last_stage:self.attns = nn.ModuleList([LePEAttention(dim, resolution=self.patches_resolution, idx=-1,split_size=split_size, num_heads=num_heads, dim_out=dim,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)for i in range(self.branch_num)])else:self.attns = nn.ModuleList([LePEAttention(dim // 2, resolution=self.patches_resolution, idx=i,split_size=split_size, num_heads=num_heads // 2, dim_out=dim // 2,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)for i in range(self.branch_num)])mlp_hidden_dim = int(dim * mlp_ratio)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer,drop=drop)self.norm2 = norm_layer(dim)def forward(self, x):"""x: B, H*W, C"""H = W = self.patches_resolutionB, L, C = x.shapeassert L == H * W, "flatten img_tokens has wrong size"img = self.norm1(x)qkv = self.qkv(img).reshape(B, -1, 3, C).permute(2, 0, 1, 3)if self.branch_num == 2:x1 = self.attns[0](qkv[:, :, :, :C // 2])x2 = self.attns[1](qkv[:, :, :, C // 2:])attened_x = torch.cat([x1, x2], dim=2)else:attened_x = self.attns[0](qkv)attened_x = self.proj(attened_x)x = x + self.drop_path(attened_x)x = x + self.drop_path(self.mlp(self.norm2(x)))return xdef img2windows(img, H_sp, W_sp):"""img: B C H W"""B, C, H, W = img.shapeimg_reshape = img.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)img_perm = img_reshape.permute(0, 2, 4, 3, 5, 1).contiguous().reshape(-1, H_sp * W_sp, C)return img_permdef windows2img(img_splits_hw, H_sp, W_sp, H, W):"""img_splits_hw: B' H W C"""B = int(img_splits_hw.shape[0] / (H * W / H_sp / W_sp))img = img_splits_hw.view(B, H // H_sp, W // W_sp, H_sp, W_sp, -1)img = img.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return imgclass Merge_Block(nn.Module):def __init__(self, dim, dim_out, norm_layer=nn.LayerNorm):super().__init__()self.conv = nn.Conv2d(dim, dim_out, 3, 2, 1)self.norm = norm_layer(dim_out)def forward(self, x):B, new_HW, C = x.shapeH = W = int(np.sqrt(new_HW))x = x.transpose(-2, -1).contiguous().view(B, C, H, W)x = self.conv(x)B, C = x.shape[:2]x = x.view(B, C, -1).transpose(-2, -1).contiguous()x = self.norm(x)return xclass CSWinTransformer(nn.Module):""" Vision Transformer with support for patch or hybrid CNN input stage"""def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=96, depth=[2, 2, 6, 2],split_size=[1, 2, 7, 7], la_split_size='1-2-7-7',num_heads=[2, 4, 8, 16], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, use_chk=False,focusing_factor=3, kernel_size=5, attn_type='LLLL'):super().__init__()# split_size = [1, 2, img_size // 32, img_size // 32]la_split_size = la_split_size.split('-')self.use_chk = use_chkself.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsheads = num_headsself.stage1_conv_embed = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 7, 4, 2),Rearrange('b c h w -> b (h w) c', h=img_size // 4, w=img_size // 4),nn.LayerNorm(embed_dim))curr_dim = embed_dimdpr = [x.item() for x in torch.linspace(0, drop_path_rate, np.sum(depth))] # stochastic depth decay ruleattn_types = [(attn_type[0] if attn_type[0] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[0])]split_sizes = [(int(la_split_size[0]) if attn_types[i] == 'L' else split_size[0]) for i in range(depth[0])]self.stage1 = nn.ModuleList([CSWinBlock(dim=curr_dim, num_heads=heads[0], reso=img_size // 4, mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,split_size=split_sizes[i],drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[i], norm_layer=norm_layer,focusing_factor=focusing_factor, kernel_size=kernel_size,attn_type=attn_types[i])for i in range(depth[0])])self.merge1 = Merge_Block(curr_dim, curr_dim * 2)curr_dim = curr_dim * 2attn_types = [(attn_type[1] if attn_type[1] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[1])]split_sizes = [(int(la_split_size[1]) if attn_types[i] == 'L' else split_size[1]) for i in range(depth[1])]self.stage2 = nn.ModuleList([CSWinBlock(dim=curr_dim, num_heads=heads[1], reso=img_size // 8, mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,split_size=split_sizes[i],drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[np.sum(depth[:1]) + i], norm_layer=norm_layer,focusing_factor=focusing_factor, kernel_size=kernel_size,attn_type=attn_types[i])for i in range(depth[1])])self.merge2 = Merge_Block(curr_dim, curr_dim * 2)curr_dim = curr_dim * 2attn_types = [(attn_type[2] if attn_type[2] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[2])]split_sizes = [(int(la_split_size[2]) if attn_types[i] == 'L' else split_size[2]) for i in range(depth[2])]temp_stage3 = []temp_stage3.extend([CSWinBlock(dim=curr_dim, num_heads=heads[2], reso=img_size // 16, mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,split_size=split_sizes[i],drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[np.sum(depth[:2]) + i], norm_layer=norm_layer,focusing_factor=focusing_factor, kernel_size=kernel_size,attn_type=attn_types[i])for i in range(depth[2])])self.stage3 = nn.ModuleList(temp_stage3)self.merge3 = Merge_Block(curr_dim, curr_dim * 2)curr_dim = curr_dim * 2attn_types = [(attn_type[3] if attn_type[3] != 'M' else ('L' if i < int(attn_type[4:]) else 'S')) for i in range(depth[3])]split_sizes = [(int(la_split_size[3]) if attn_types[i] == 'L' else split_size[3]) for i in range(depth[3])]self.stage4 = nn.ModuleList([CSWinBlock(dim=curr_dim, num_heads=heads[3], reso=img_size // 32, mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,split_size=split_sizes[i],drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[np.sum(depth[:-1]) + i], norm_layer=norm_layer, last_stage=True,focusing_factor=focusing_factor, kernel_size=kernel_size,attn_type=attn_types[i])for i in range(depth[-1])])self.norm = norm_layer(curr_dim)# Classifier headself.head = nn.Linear(curr_dim, num_classes) if num_classes > 0 else nn.Identity()trunc_normal_(self.head.weight, std=0.02)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d)):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {'pos_embed', 'cls_token'}def get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):if self.num_classes != num_classes:print('reset head to', num_classes)self.num_classes = num_classesself.head = nn.Linear(self.out_dim, num_classes) if num_classes > 0 else nn.Identity()self.head = self.head.cuda()trunc_normal_(self.head.weight, std=.02)if self.head.bias is not None:nn.init.constant_(self.head.bias, 0)def forward_features(self, x):B = x.shape[0]x = self.stage1_conv_embed(x)for blk in self.stage1:if self.use_chk:x = checkpoint.checkpoint(blk, x)else:x = blk(x)for pre, blocks in zip([self.merge1, self.merge2, self.merge3],[self.stage2, self.stage3, self.stage4]):x = pre(x)for blk in blocks:if self.use_chk:x = checkpoint.checkpoint(blk, x)else:x = blk(x)x = self.norm(x)return torch.mean(x, dim=1)def forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef _conv_filter(state_dict, patch_size=16):""" convert patch embedding weight from manual patchify + linear proj to conv"""out_dict = {}for k, v in state_dict.items():if 'patch_embed.proj.weight' in k:v = v.reshape((v.shape[0], 3, patch_size, patch_size))out_dict[k] = vreturn out_dict### 224 modelsdef FLatten_CSWin_64_24181_tiny_224(pretrained=False, **kwargs):model = CSWinTransformer(patch_size=4, embed_dim=64, depth=[2, 4, 18, 1],split_size=[1, 2, 7, 7], num_heads=[2, 4, 8, 16], mlp_ratio=4., **kwargs)model.default_cfg = default_cfgs['cswin_224']return modeldef FLatten_CSWin_64_24322_small_224(pretrained=False, **kwargs):model = CSWinTransformer(patch_size=4, embed_dim=64, depth=[2, 4, 32, 2],split_size=[1, 2, 7, 7], num_heads=[2, 4, 8, 16], mlp_ratio=4., **kwargs)model.default_cfg = default_cfgs['cswin_224']return modeldef FLatten_CSWin_96_36292_base_224(pretrained=False, **kwargs):model = CSWinTransformer(patch_size=4, embed_dim=96, depth=[3, 6, 29, 2],split_size=[1, 2, 7, 7], num_heads=[4, 8, 16, 32], mlp_ratio=4., **kwargs)model.default_cfg = default_cfgs['cswin_224']return model### 384 modelsdef FLatten_CSWin_96_36292_base_384(pretrained=False, **kwargs):model = CSWinTransformer(patch_size=4, embed_dim=96, depth=[3, 6, 29, 2],split_size=[1, 2, 12, 12], num_heads=[4, 8, 16, 32], mlp_ratio=4., **kwargs)model.default_cfg = default_cfgs['cswin_384']return model
相关文章:
pytorch代码实现注意力机制之Flatten Attention
Flatten Attention 介绍:最新注意力Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer 在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系,给视觉任务…...

激光雷达和人工智能
几十年来,激光雷达一直是许多行业中非常有用的工具,但直到最近,随着人工智能(AI)解决方案的引入,我们才开始认识到它的真正潜力。激光雷达,又称光探测和测距,是一种遥感技术。它利用…...

【算法练习Day44】最长递增子序列最长连续递增序列最长重复子数组
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 最长递增子序列最长连续递增…...
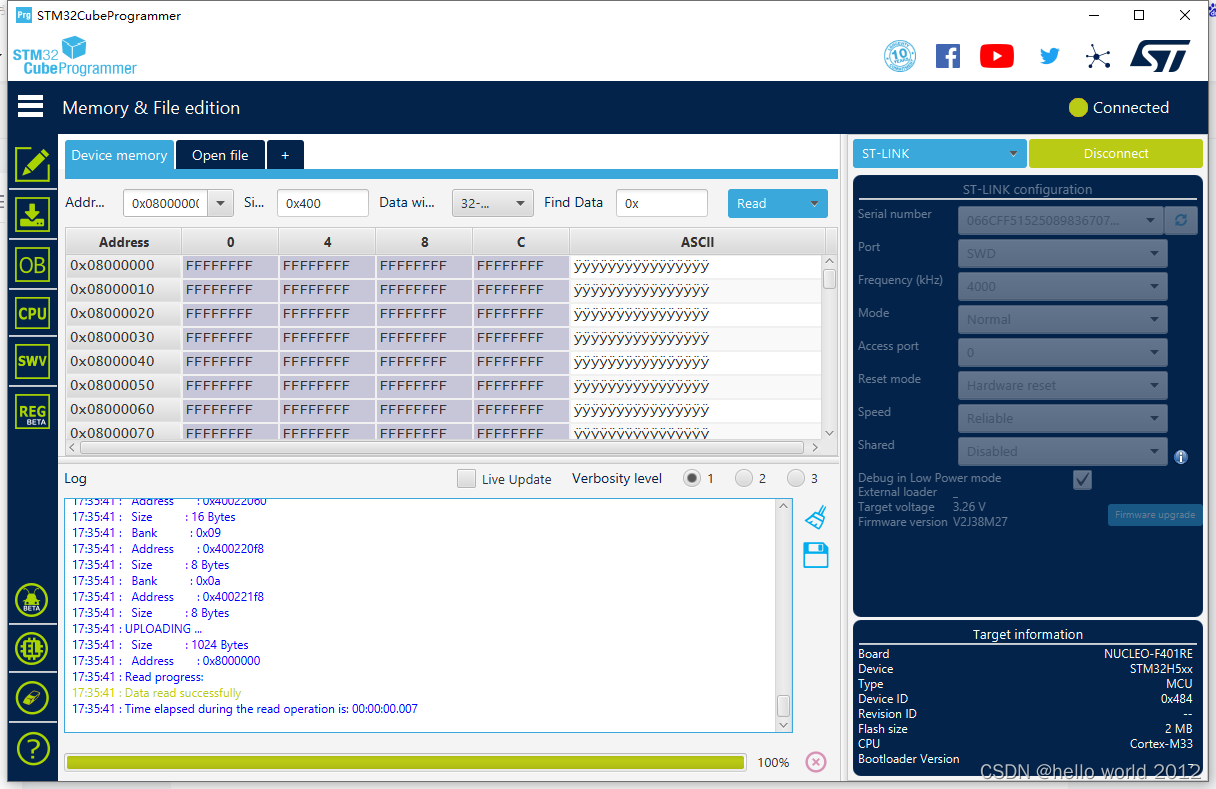
STM32H743XX/STM32H563XX芯片烧录一次后,再次上电无法烧录
近期在使用STM32H563ZIT6这款芯片在开发板上使用正常,烧录到自己打的板子就遇到了芯片烧录一次后,再次上电无法烧录的问题。 遇到问题需要从以下5点进行分析。 首先看下开发板的原理图 1.BOOT0需要拉高。 2.NRST脚在开发板上是悬空的。这里我建议大家…...

21. 合并两个有序链表 --力扣 --JAVA
题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 解题思路 判断特殊情况,如:两个列表中其中一个为空;创建一个初始节点用于返回;通过while循环来逐个遍历链表࿰…...
Linux 基本语句_10_进程
进程和程序的区别: 程序是一段静态的代码,是保存在非易失储存器上的制令和数据的有序集合,没有任何执行的概念;而进程是一个动态的概念,它是程序的一次执行过程,包括了动态创建、调度、执行和消亡的整个过程…...

矩阵起源加入 OpenCloudOS 操作系统开源社区,完成技术兼容互认证
近日,超融合异构云原生数据库 MatrixOne企业版软件 V1.0 完成了与 OpenCloudOS 的相互兼容认证,测试期间,整体运行稳定,在功能、性能及兼容性方面表现良好。 一、产品简介 矩阵起源 MatrixOrigin 致力于建设开放的技术开源社区和…...

3D物理模拟和视觉特效软件SideFX Houdini mac中文介绍
SideFX Houdini for mac是一款3D物理模拟和视觉特效软件,几乎所有好莱坞特效电影里的物理模拟,包括碎裂,烟尘,碰撞,火焰,流体等模拟,都看得到它的身影。其独特的节点式操作方式,尤其…...
GPT-4.0网页平台-ChatYY
ChatYY的优势: 1. 支持大部分AI模型,且支持AI绘画: 2. 问答响应速度极快: 3. 代码解析: 4. 支持文档解读: 5. PC、移动端均支持: 访问直达:ChatYY.com...

mysql,redis导入导出数据库数据
mysql 导出数据 导出整个数据库: mysqldump -u 用户名 -p 数据库名 > 导出文件.sql 例如,如果你的用户名是 root,数据库名是 mydatabase,你可以运行以下命令: mysqldump -u root -p mydatabase > 导出文件.sql…...
conda修改虚拟环境名称
conda 修改虚拟环境名称 conda 不能直接更改名称,但是可以通过克隆环境解决 新建环境(克隆旧环境) conda create --name 新环境名 --clone 旧环境名 删除原环境 conda remove --name 旧环境名 --all 查看现有环境 conda env list conda i…...
c语言,将奇数和偶数分类
题目:输入一个整数数组,实现一个函数,来调整该数组中数字的顺序使得数组中所有的奇数位于数组的前半部分,所有偶数位于数组的后半部分。 思路:像冒泡排序那样,相邻两个数比较,两个都是偶数则不…...

前端设计模式之【观察者模式】
文章目录 前言介绍实现优缺点应用场景后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&#…...

HTTPS安全相关-通信安全的四个特性-ssl/tls
230-TLS是什么 1.http不安全 由于 HTTP 天生“明文”的特点,整个传输过程完全透明,任何人都能够在链路中截获、修改或者伪造请求 / 响应报文,数据不具有可信性 ; “代理服务”。它作为 HTTP 通信的中间人,在数据上下…...

并查集:Leetcode765 情侣牵手
n 对情侣坐在连续排列的 2n 个座位上,想要牵到对方的手。 人和座位由一个整数数组 row 表示,其中 row[i] 是坐在第 i 个座位上的人的 ID。情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后…...
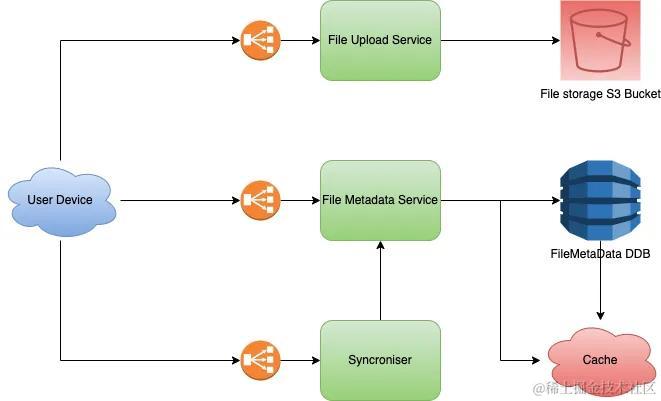
如何设计一个网盘系统的架构
1. 概述 现代生活中已经离不开网盘,比如百度网盘。在使用网盘的过程中,有没有想过它是如何工作的?在本文中,我们将讨论如何设计像百度网盘这样的系统的基础架构。 2. 系统需求 2.1. 功能性需求 用户能够上传照片/文件。用户能…...
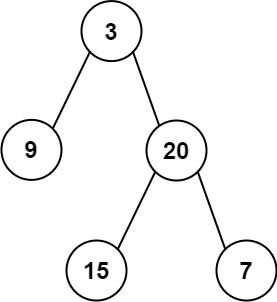
【代码随想录】算法训练计划17
1、 110.平衡二叉树 题目: 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 思路: 经典后序遍历,感…...

“护肤品销售策略:从“免费拼团”到“3人回本大放送”“
有一个销售护肤品的团队,他们家399块钱一套的护肤品,他们在小程序这一个渠道,只用了23天的时间,就卖出去了2000多万的营业额,你敢信吗? 那么23天的时间,他们是怎么卖出去2000多万的呢࿱…...
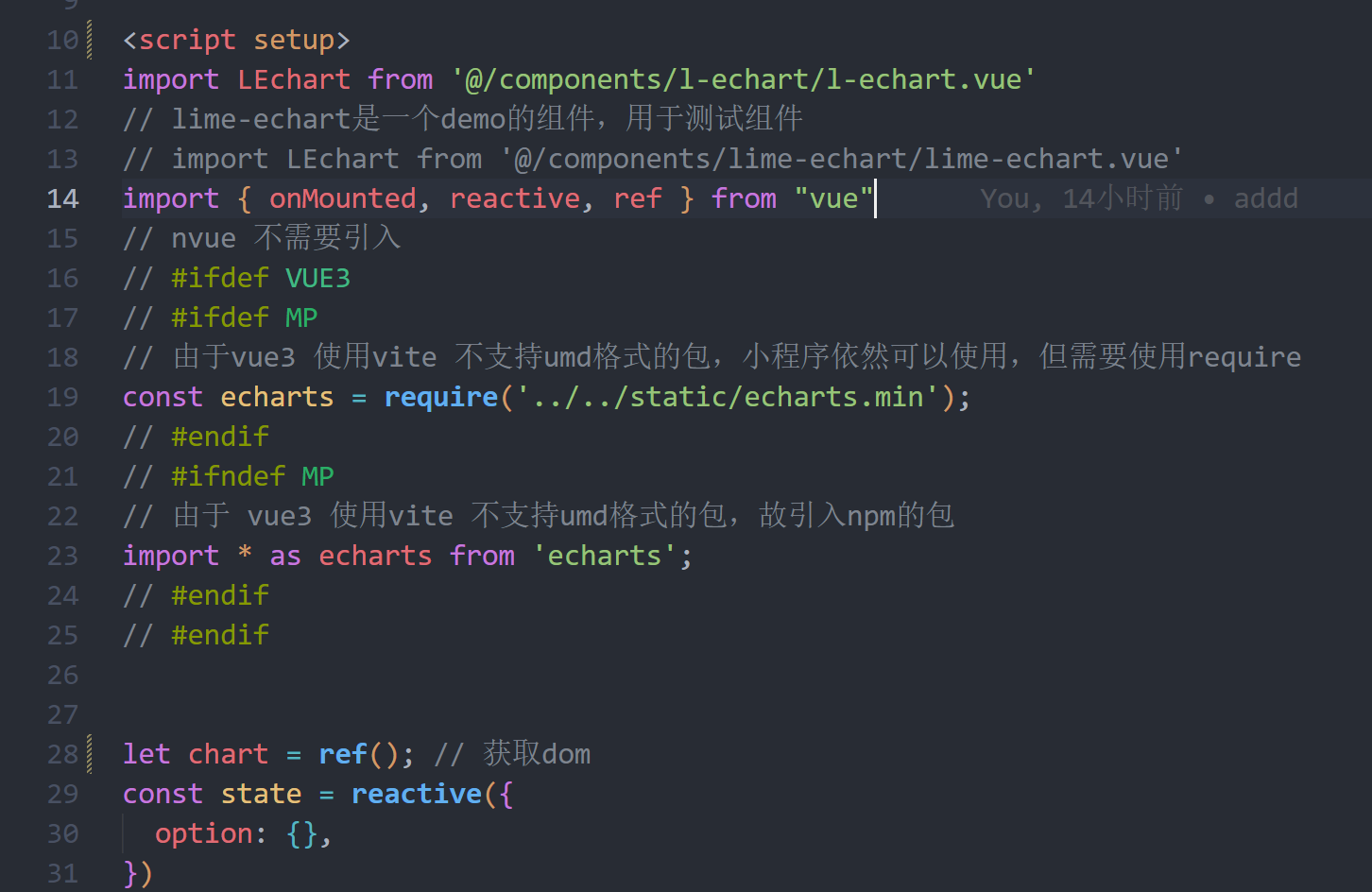
uniapp和vue3+ts开发小程序,使用vscode提示声明变量冲突解决办法
在uniapp中,我们可能经常会遇到需要在不用的环境中使用不同变量的场景,例如在VUE3中的小程序环境使用下面的方式导入echarts: const echarts require(../../static/echarts.min); 如果不是小程序环境则使用下面的方式导入echartsÿ…...

CCLink转Modbus TCP网关_MODBUS报文配置
兴达易控CCLink转Modbus TCP网关是一种功能强大的设备,可实现两个不同通信协议之间的无缝对接。它能够将CCLink协议转换为Modbus TCP协议,并通过报文配置实现灵活的通信设置。兴达易控CCLink转Modbus TCP网关可以轻松实现CCLink和Modbus TCP之间的数据转…...

彻底解决ComfyUI图像细节缺失问题:Impact Pack V8版完整功能解锁指南
彻底解决ComfyUI图像细节缺失问题:Impact Pack V8版完整功能解锁指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目…...

从零到一:用RPO与RTO构建你的企业灾备蓝图
1. 为什么企业需要关注RPO和RTO? 想象一下,你经营着一家24小时营业的连锁超市。某天深夜,收银系统突然崩溃,所有交易记录都消失了。这时候你会面临两个关键问题:第一,丢失了多少笔交易记录(这是…...
风-火-储经济调度模型研究(Matlab代码实现))
计及切负荷和直流潮流(DC-OPF)风-火-储经济调度模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【2024代码安全黄金标准】:基于AST+语义理解的审查自动化框架,已通过CNCF认证,现开放首批50家企业免费接入通道
第一章:智能代码生成与代码审查自动化 2026奇点智能技术大会(https://ml-summit.org) 现代软件开发正经历从“人工编写为主”向“人机协同编程”的范式跃迁。大型语言模型(LLM)在理解语义、生成结构化代码、识别潜在缺陷等方面展现出强大能…...

从数码管显示乱码到稳定驱动:手把手教你用74HC595和STM32CubeMX配置显示译码器
从数码管乱码到工业级显示方案:74HC595与STM32CubeMX实战指南 当你在深夜调试嵌入式项目时,数码管突然开始跳变乱码——这种经历恐怕每个工程师都遇到过。上周三凌晨2点15分,我的第三杯咖啡旁边,一个四位数码管正在循环显示"…...

GD32开发环境快速配置指南--从Pack安装到工程验证
1. GD32开发环境搭建全攻略 第一次接触GD32芯片时,我也被各种开发包和工具链搞得头晕眼花。作为国产MCU的佼佼者,GD32凭借其出色的性价比在嵌入式领域越来越受欢迎。但很多新手在第一步环境搭建就会遇到各种问题——Pack安装失败、设备识别异常、工程配置…...

D2DX终极指南:让暗黑破坏神2在现代PC上焕发新生的完整教程
D2DX终极指南:让暗黑破坏神2在现代PC上焕发新生的完整教程 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为…...

终极Windows风扇控制指南:3步实现智能散热与静音平衡
终极Windows风扇控制指南:3步实现智能散热与静音平衡 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...
)
SpringBoot项目实战:用mysql-binlog-connector-java实现用户行为日志的实时同步(附完整代码)
SpringBoot实战:基于MySQL Binlog的用户行为日志实时同步架构设计 在当今数据驱动的业务环境中,用户行为数据的实时采集与分析已成为企业精细化运营的核心能力。想象这样一个场景:当用户在电商平台完成一笔支付后,风控系统需要在5…...

从Goldschmidt到代码:我如何用Python脚本‘侦探’出钙钛矿论文里的隐藏计算参数
解码钙钛矿论文中的隐藏参数:Python逆向工程实战 在材料科学领域,钙钛矿化合物的稳定性预测一直是个关键课题。Goldschmidt容忍因子(t)作为经典判据已有近百年历史,但鲜少有人讨论一个核心问题:当不同研究团队报告"相同&quo…...