Flink—— Flink Data transformation(转换)
Flink数据算子转换有很多类型,各位看官看好,接下来,演示其中的十八种类型。
1.Map(映射转换)
DataStream → DataStream
将函数作用在集合中的每一个元素上,并返回作用后的结果,其中输入是一个数据流,输出的也是一个数据流:
DataStream<Integer> dataStream = //加载数据源
dataStream.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer age) throws Exception {return 2 + age;}
});
2.Flatmap(扁平映射转换)
DataStream → DataStream
FlatMap 将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果,即采用一条记录并输出零个,一个或多个记录。
//加载数据源dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out)throws Exception {for(String word: value.split(",")){out.collect(word);}}
});
3.Filter(过滤转换)
DataStream → DataStream
按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素。
// 过滤出年龄大于18的数据
dataStream.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer age) throws Exception {return age > 18;}
});
Keyby(分组转换)
DataStream → KeyedStream
按照指定的key来对流中的数据进行分组,在逻辑上是基于 key 对流进行分区。在内部,它使用 hash 函数对流进行分区。它返回 KeyedDataStream 数据流。
KeyedStream<Student, Integer> keyBy = student.keyBy(new KeySelector<Student, Integer>() {@Overridepublic Integer getKey(Student value) throws Exception {return value.age;}
});4.Reduce(归约转换)
KeyedStream → DataStream
对集合中的元素进行聚合,Reduce 返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average, sum, min, max, count,使用 reduce 方法都可实现。
keyedStream.reduce(new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2)throws Exception {return value1 * value2;}
});5.Aggregations(聚合转换)
KeyedStream → DataStream
在分组后的数据集上进行聚合操作,如求和、计数、最大值、最小值等。这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
DataStream<Tuple2<String, Integer>> dataStream = ...; // 加载数据源dataStream.keyBy(0) // 对元组的第一个元素进行分组 .sum(1); // 对元组的第二个元素求和6.Window(分组开窗转换)
KeyedStream → WindowedStream
Flink 定义数据片段以便(可能)处理无限数据流。 这些切片称为窗口,将数据流划分为不重叠的窗口,并在每个窗口上执行转换操作,常用于对时间窗口内的数据进行处理。 此切片有助于通过应用转换处理数据块。 要对流进行窗口化,需要分配一个可以进行分发的键和一个描述要对窗口化流执行哪些转换的函数,
要将流切片到窗口,我们可以使用 Flink 自带的窗口分配器。 我们有选项,如 tumbling windows, sliding windows, global 和 session windows。 Flink 还允许您通过扩展 WindowAssginer 类来编写自定义窗口分配器。
inputStream.keyBy(0).window(Time.seconds(10));
上述案例是数据分组后,是以 10 秒的时间窗口聚合:
7.WindowAll(开窗转换)
DataStream → AllWindowedStream
类似于 Window 操作,但是对整个数据流应用窗口操作而不是对每个 key 分别应用。
windowAll 函数允许对常规数据流进行分组。 通常,这是非并行数据转换,因为它在非分区数据流上运行。 唯一的区别是它们处理窗口数据流。 所以窗口缩小就像 Reduce 函数一样,Window fold 就像 Fold 函数一样,并且还有聚合。
// 创建一个简单的数据流 DataStream<Tuple2<String, Integer>> dataStream = ...; // 请在此处填充你的数据源 // 定义一个 ReduceFunction,用于在每个窗口内进行求和操作 ReduceFunction<Tuple2<String, Integer>> reduceFunction = new ReduceFunction<Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception { return new Tuple2<>(value1.f0, value1.f1 + value2.f1); } }; // 使用 WindowAll 方法,指定时间窗口和 ReduceFunction dataStream.windowAll(Time.of(5, TimeUnit.SECONDS), reduceFunction) .print(); // 输出结果到 stdout (for debugging) 8.Union(合并转换)
DataStream* → DataStream
将多个数据流合并为一个数据流。union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重
//通过一些 key 将同一个 window 的两个数据流 join 起来。inputStream.join(inputStream1).where(0).equalTo(1).window(Time.seconds(5)) .apply (new JoinFunction () {...});
// 以上示例是在 5 秒的窗口中连接两个流,其中第一个流的第一个属性的连接条件等于另一个流的第二个属性。9.Connect / CoMap / CoFlatMap(连接转换)
DataStream,DataStream → DataStream
连接两个数据流,并对连接后的数据流进行转换操作。
-
Connect:Connect 算子用于连接两个数据流,这两个数据流的类型可以不同。Connect 算子会将两个数据流连接成一个 ConnectedStreams 对象,但并不对元素做任何转换操作。Connect 算子通常用于需要将两个不同类型的数据流进行关联处理的场景。
-
CoMap:CoMap 算子用于对 ConnectedStreams 中的每一个数据流应用一个 map 函数,将它们分别转换为另一种类型。CoMap 会将两个数据流中的元素分别转换为不同的类型,因此在使用 CoMap 时需要分别指定两个不同的 map 函数。
-
CoFlatMap:CoFlatMap 算子和 CoMap 类似,也是用于对 ConnectedStreams 中的每一个数据流应用一个 flatMap 函数,将它们分别转换为另一种类型。不同之处在于,CoFlatMap 生成的元素个数可以是 0、1 或多个,因此适用于需要将每个输入元素转换为零个、一个或多个输出元素的情况。
// 创建两个数据流
DataStream<Type1> dataStream1 = ... // 从某个地方获取 Type1 类型的数据流
DataStream<Type2> dataStream2 = ... // 从某个地方获取 Type2 类型的数据流// 使用 Connect 算子连接两个数据流
ConnectedStreams<Type1, Type2> connectedStreams = dataStream1.connect(dataStream2);// 使用 CoMap 对每个数据流进行单独的转换
SingleOutputStreamOperator<ResultType1> resultStream1 = connectedStreams.map(new CoMapFunction<Type1, ResultType1>() {@Overridepublic ResultType1 map1(Type1 value) throws Exception {// 对 Type1 数据流的转换逻辑// ...return transformedResult1;}
});SingleOutputStreamOperator<ResultType2> resultStream2 = connectedStreams.map(new CoMapFunction<Type2, ResultType2>() {@Overridepublic ResultType2 map2(Type2 value) throws Exception {// 对 Type2 数据流的转换逻辑// ...return transformedResult2;}
});// 使用 CoFlatMap 对连接后的数据流进行转换
SingleOutputStreamOperator<ResultType> resultStream = connectedStreams.flatMap(new CoFlatMapFunction<Type1, Type2, ResultType>() {@Overridepublic void flatMap1(Type1 value, Collector<ResultType> out) throws Exception {// 对 Type1 数据流的转换逻辑// 将转换后的结果发射出去out.collect(transformedResult1);}@Overridepublic void flatMap2(Type2 value, Collector<ResultType> out) throws Exception {// 对 Type2 数据流的转换逻辑// 将转换后的结果发射出去out.collect(transformedResult2);}
});// 执行任务
env.execute("Connect and CoMap Example");
10.Join(连接转换)
KeyedStream,KeyedStream → DataStream
可以使用 join 算子来实现两个数据流的连接转换操作
java
// 创建两个数据流
DataStream<Type1> inputStream1 = ... // 从某个地方获取 Type1 类型的数据流
DataStream<Type2> inputStream2 = ... // 从某个地方获取 Type2 类型的数据流// 使用 keyBy 将两个数据流按照相同的字段进行分区
KeyedStream<Type1, KeyType> keyedStream1 = inputStream1.keyBy(<keySelector>);
KeyedStream<Type2, KeyType> keyedStream2 = inputStream2.keyBy(<keySelector>);// 使用 join 进行连接转换
SingleOutputStreamOperator<OutputType> resultStream = keyedStream1.join(keyedStream2).where(<keySelector1>).equalTo(<keySelector2>).window(<windowAssigner>).apply(new JoinFunction<Type1, Type2, OutputType>() {@Overridepublic OutputType join(Type1 value1, Type2 value2) throws Exception {// 执行连接转换逻辑// ...return transformedResult;}});// 执行任务
env.execute("Join Example"); 上述事例有两个输入数据流 inputStream1 和 inputStream2,它们的元素类型分别为 Type1 和 Type2。对这两个数据流进行连接转换操作,并输出连接后的结果。首先使用 keyBy 对两个数据流进行分区,然后使用 join 算子将两个分区后的数据流按照指定的条件进行连接。在 join 方法中,我们需要指定连接条件和窗口分配器,并通过 apply 方法应用一个 JoinFunction 对连接后的数据进行转换操作。在 JoinFunction 的 join 方法中,我们可以编写具体的连接转换逻辑,然后返回转换后的结果。
Split / Select:将一个数据流拆分为多个数据流,然后对不同的数据流进行选择操作。
此功能根据条件将流拆分为两个或多个流。 当您获得混合流并且您可能希望单独处理每个数据流时,可以使用此方法。
11.Apply(窗口中的元素自定义转换)
WindowedStream → DataStream
AllWindowedStream → DataStream
当使用 Flink 的 apply 方法时,将一个自定义的函数应用于流中的每个元素,并生成一个新的流。这个自定义的函数可以是 MapFunction、FlatMapFunction、FilterFunction 等接口的实现。
// 创建输入数据流
DataStream<Type1> inputStream = ... // 从某个地方获取 Type1 类型的数据流// 使用 apply 方法应用自定义函数
SingleOutputStreamOperator<OutputType> resultStream = inputStream.apply(new MyMapFunction());// 定义自定义的 MapFunction
public class MyMapFunction implements MapFunction<Type1, OutputType> {@Overridepublic OutputType map(Type1 value) {// 执行转换操作OutputType transformedValue = ... // 对输入元素进行一些转换操作return transformedValue;}
}// 执行任务
env.execute("Apply Example");12.Iterate(迭代转换)
DataStream → IterativeStream → DataStream
允许在数据流上进行迭代计算,通常用于实现迭代算法。iterate函数允许您定义一个迭代处理的核心逻辑,并通过closeWith方法指定迭代结束的条件。
// 定义迭代逻辑DataSet<Long> iteration = initialInput.iterate(1000) // 指定迭代上限.map(new MapFunction<Long, Long>() {@Overridepublic Long map(Long value) throws Exception {// 迭代处理逻辑,这里简单地加1return value + 1;}});// 指定迭代结束条件DataSet<Long> result = iteration.closeWith(iteration.filter(value -> value >= 10)); 在这个示例中,使用iterate函数来定义迭代逻辑,其中map函数对每个元素进行加1操作。接着,我们使用closeWith方法来指定迭代结束的条件,即当元素的值大于等于10时结束迭代。
需要注意的是,在实际的迭代处理中,需要根据具体业务逻辑来定义迭代的处理过程和结束条件。另外,还需要注意迭代过程中的性能和资源消耗,以及迭代次数的控制,避免出现无限循环等问题。
13.CoGroup(分组连接转换)
DataStream,DataStream → DataStream
将两个或多个数据流中的元素进行连接操作,通常基于相同的键进行连接。
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;import java.util.ArrayList;
import java.util.List;public class CoGroupExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 创建第一个数据集List<Tuple2<Integer, String>> firstDataSet = new ArrayList<>();firstDataSet.add(new Tuple2<>(1, "A"));firstDataSet.add(new Tuple2<>(2, "B"));// 创建第二个数据集List<Tuple2<Integer, String>> secondDataSet = new ArrayList<>();secondDataSet.add(new Tuple2<>(1, "X"));secondDataSet.add(new Tuple2<>(3, "Y"));// 将数据集转化为Flink的DataSetorg.apache.flink.api.java.DataSet<Tuple2<Integer,String>> first = env.fromCollection(firstDataSet);org.apache.flink.api.java.DataSet<Tuple2<Integer,String>> second = env.fromCollection(secondDataSet);// 使用CoGroup算子进行连接first.coGroup(second).where(0) // 第一个数据集的连接字段.equalTo(0) // 第二个数据集的连接字段.with(new MyCoGroupFunction()) // 指定自定义的CoGroupFunction.print();env.execute();}// 自定义CoGroupFunctionpublic static class MyCoGroupFunction implements CoGroupFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, String> {@Overridepublic void coGroup(Iterable<Tuple2<Integer, String>> first, Iterable<Tuple2<Integer, String>> second, Collector<String> out) {List<String> valuesFromFirst = new ArrayList<>();for (Tuple2<Integer, String> t : first) {valuesFromFirst.add(t.f1);}List<String> valuesFromSecond = new ArrayList<>();for (Tuple2<Integer, String> t : second) {valuesFromSecond.add(t.f1);}// 对两个数据集的分组进行连接操作for (String s1 : valuesFromFirst) {for (String s2 : valuesFromSecond) {out.collect(s1 + "-" + s2);}}}}
}
在这个示例中,首先创建了两个简单的数据集firstDataSet和secondDataSet,然后将它们转换为Flink的DataSet对象。接着使用CoGroup算子对这两个数据集进行分组连接操作,其中通过where和equalTo指定了连接字段,通过with方法指定了自定义的CoGroupFunction。最后,在CoGroupFunction中实现了对两个数据集分组的连接逻辑,并通过Collector将结果输出。
14.Cross(笛卡尔积转换)
计算两个数据流的笛卡尔积。
DataStream,DataStream → DataStream
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;import java.util.ArrayList;
import java.util.List;public class CrossExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 创建第一个数据集List<Integer> firstDataSet = new ArrayList<>();firstDataSet.add(1);firstDataSet.add(2);// 创建第二个数据集List<String> secondDataSet = new ArrayList<>();secondDataSet.add("A");secondDataSet.add("B");// 将数据集转化为Flink的DataSetDataSet<Integer> first = env.fromCollection(firstDataSet);DataSet<String> second = env.fromCollection(secondDataSet);// 使用Cross算子进行笛卡尔积操作DataSet<Tuple2<Integer, String>> result = first.cross(second);// 打印结果result.print();env.execute();}
}
在这个示例中,首先创建了两个简单的数据集firstDataSet和secondDataSet,然后将它们转换为Flink的DataSet对象。接着使用Cross算子对这两个数据集进行笛卡尔积操作,得到了一个包含所有可能组合的新数据集。
15.Project(投影转换)
DataStream → DataStream
对数据集进行投影操作,选择特定的字段或属性。Project算子用于从数据集中选择或投影出特定的字段。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple3;import java.util.ArrayList;
import java.util.List;public class ProjectExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 创建数据集List<Tuple3<Integer, String, Double>> inputDataSet = new ArrayList<>();inputDataSet.add(new Tuple3<>(1, "Alice", 1000.0));inputDataSet.add(new Tuple3<>(2, "Bob", 1500.0));inputDataSet.add(new Tuple3<>(3, "Charlie", 2000.0));// 将数据集转化为Flink的DataSetDataSet<Tuple3<Integer, String, Double>> input = env.fromCollection(inputDataSet);// 使用Project算子进行字段投影DataSet<Tuple2<Integer, String>> projectedDataSet = input.project(0, 1); // 选择字段0和字段1// 打印结果projectedDataSet.print();env.execute();}
}
在这个示例中,首先创建了一个包含整数、字符串和双精度浮点数的元组数据集inputDataSet。然后将它们转换为Flink的DataSet对象。接着使用Project算子对数据集进行字段投影,选择了字段0和字段1。最后打印出了字段投影后的结果。
16.Connect(连接转换)
DataStream,DataStream → ConnectedStreams
connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:connect只能连接两个数据流,union可以连接多个数据流。connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;import java.util.ArrayList;
import java.util.List;public class ConnectExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 创建第一个数据集List<Integer> firstDataSet = new ArrayList<>();firstDataSet.add(1);firstDataSet.add(2);firstDataSet.add(3);// 创建第二个数据集List<String> secondDataSet = new ArrayList<>();secondDataSet.add("A");secondDataSet.add("B");secondDataSet.add("C");// 将数据集转化为Flink的DataSetDataSet<Integer> first = env.fromCollection(firstDataSet);DataSet<String> second = env.fromCollection(secondDataSet);// 使用Map将Integer类型转换为Tuple2类型DataSet<Tuple2<Integer, String>> firstMapped = first.map(new MapFunction<Integer, Tuple2<Integer, String>>() {@Overridepublic Tuple2<Integer, String> map(Integer value) {return new Tuple2<>(value, "default");}});// 使用Connect算子将两个数据集连接在一起DataSet<Tuple2<Integer, String>> connectedDataSet = firstMapped.connect(second).map(new MapFunction<Integer, Tuple2<Integer, String>>() {@Overridepublic Tuple2<Integer, String> map(Integer value) {return new Tuple2<>(value, "connected");}});// 打印结果connectedDataSet.print();env.execute();}
}
在这个示例中,首先创建了两个简单的数据集firstDataSet和secondDataSet,然后将它们转换为Flink的DataSet对象。接着使用Map算子将第一个数据集中的整数类型转换为Tuple2类型。然后使用Connect算子将转换后的第一个数据集与第二个数据集连接在一起,最后再对连接后的数据集进行处理。最终打印出了连接后的结果。
17.IntervalJoin(时间窗口连接转换)
KeyedStream,KeyedStream → DataStream
IntervalJoin算子用于在两个数据流之间执行基于时间窗口的连接操作。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.streaming.api.datastream.IntervalJoinOperator;
import org.apache.flink.streaming.api.windowed.TimeWindow;
import org.apache.flink.streaming.api.windowing.time.Time;public class IntervalJoinExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建第一个数据流DataStream<Tuple2<String, Integer>> firstStream = ... // 从数据源获取第一个数据流// 创建第二个数据流DataStream<Tuple2<String, String>> secondStream = ... // 从数据源获取第二个数据流// 定义时间窗口大小Time windowSize = Time.seconds(10);// 使用IntervalJoin算子进行时间窗口连接IntervalJoinOperator<Tuple2<String, Integer>, Tuple2<String, String>, String> joinedStream = firstStream.intervalJoin(secondStream).between(Time.seconds(-3), Time.seconds(3)) // 定义连接窗口范围.upperBoundExclusive() // 指定上界为不包含.lowerBoundExclusive() // 指定下界为不包含.process(new MyIntervalJoinFunction());// 打印结果joinedStream.print();// 执行任务env.execute("Interval Join Example");}// 自定义IntervalJoinFunctionpublic static class MyIntervalJoinFunction implements JoinFunction<Tuple2<String, Integer>, Tuple2<String, String>, String> {@Overridepublic String join(Tuple2<String, Integer> first, Tuple2<String, String> second) {// 在这里实现连接后的处理逻辑return "Joined: " + first.toString() + " and " + second.toString();}}
}
在这个示例中,首先创建了两个数据流firstStream和secondStream,这些数据流可以来自各种数据源(例如Kafka、Socket等)。然后使用IntervalJoin算子将这两个数据流在时间窗口上进行连接操作,通过定义连接窗口的范围来指定两个数据流之间的连接条件。最后定义了自定义的JoinFunction来处理连接后的数据。最终打印出了连接后的结果,并执行Flink任务。
18.Split / Select(拆分和选择转换)
DataStream → DataStream
Split 和 Select 算子用于将单个数据流拆分为多个流,并选择其中的部分流进行处理。
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SplitSelectExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建数据流DataStream<String> inputDataStream = ... // 从数据源获取数据流// 使用 Split 算子将数据流拆分为多个流SplitStream<String> splitStream = inputDataStream.split(new OutputSelector<String>() {@Overridepublic Iterable<String> select(String value) {List<String> output = new ArrayList<>();if (value.contains("category1")) {output.add("category1");} else if (value.contains("category2")) {output.add("category2");} else {output.add("other");}return output;}});// 选择拆分后的流中的部分流进行处理DataStream<String> category1Stream = splitStream.select("category1");DataStream<String> category2Stream = splitStream.select("category2");// 对每个流进行进一步处理DataStream<String> processedCategory1Stream = category1Stream.map(new MyMapperFunction());DataStream<String> processedCategory2Stream = category2Stream.filter(new MyFilterFunction());// 将处理后的结果合并为一个流DataStream<String> resultStream = processedCategory1Stream.union(processedCategory2Stream);// 打印结果resultStream.print();// 执行任务env.execute("Split and Select Example");}// 自定义 Mapper 函数public static class MyMapperFunction implements MapFunction<String, String> {@Overridepublic String map(String value) {// 在这里实现对流中元素的转换操作return "Processed Category1: " + value;}}// 自定义 Filter 函数public static class MyFilterFunction implements FilterFunction<String> {@Overridepublic boolean filter(String value) {// 在这里实现过滤逻辑return value.length() > 10;}}
}
在这个示例中,首先创建了一个输入数据流inputDataStream,然后使用 Split 算子将数据流拆分为三个不同的流:category1、category2 和 other。接着使用 Select 算子选择了category1和category2两个流,并对它们分别应用了自定义的 Mapper 函数和 Filter 函数进行处理。最后将处理后的结果合并为一个流,并打印出来。
更多消息资讯,请访问昂焱数据(https://www.ayshuju.com)
相关文章:
Flink—— Flink Data transformation(转换)
Flink数据算子转换有很多类型,各位看官看好,接下来,演示其中的十八种类型。 1.Map(映射转换) DataStream → DataStream 将函数作用在集合中的每一个元素上,并返回作用后的结果,其中输入是一个数据流&…...

前端读取文件当文件选择相同文件名的文件,内容不会变化
前端读取文件当文件选择相同文件名的文件,内容不会变化 今天遇到个奇怪的bug,使用打开文件,并选择文件时,正常情况会读取文件信息。 但是如果先选择相同的文件名,则内容不会发生变化。 先说结论 只要不使用事件中e…...
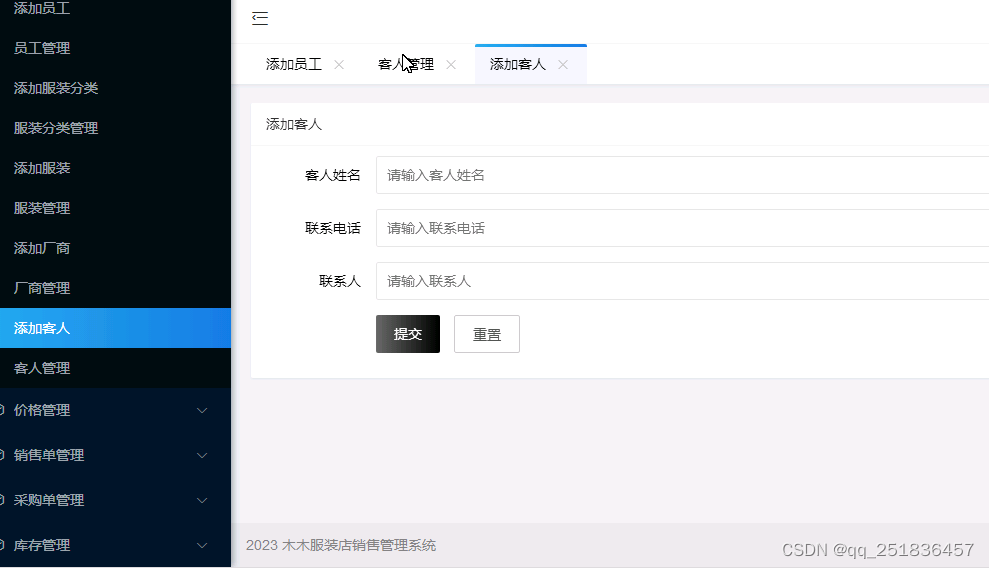
PHP 服装销售管理系统mysql数据库web结构layUI布局apache计算机软件工程网页wamp
一、源码特点 PHP 服装销售管理系统是一套完善的web设计系统mysql数据库 ,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 php服装销售管理系统1 二、功能介绍 (1)员工管理:对员工信息…...

用于图像处理的高斯滤波器 (LoG) 拉普拉斯
一、说明 欢迎来到拉普拉斯和高斯滤波器的拉普拉斯的故事。LoG是先进行高斯处理,继而进行拉普拉斯算子的图像处理算法。用拉普拉斯具有过零功能,实现边缘岭脊提取。 二、LoG算法简述 在这篇博客中,让我们看看拉普拉斯滤波器和高斯滤波器的拉普…...
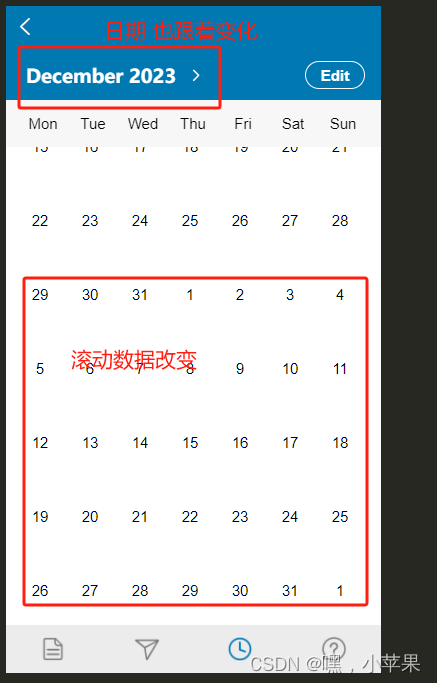
【h5 uniapp】 滚动 滚动条,数据跟着变化
uniapp项目 需求: 向下滑动时,数据增加,上方的日历标题日期也跟着变化 向上滑动时,上方的日历标题日期跟着变化 实现思路: 初次加载目前月份的数据 以及下个月的数据 this.getdate()触底加载 下个月份的数据 onReach…...

ModStartBlog v8.5.0 评论开关布局调整,系统后台全面优化
ModStart 是一个基于 Laravel 模块化极速开发框架。模块市场拥有丰富的功能应用,支持后台一键快速安装,让开发者能快的实现业务功能开发。 系统完全开源,基于 Apache 2.0 开源协议。 功能特性 丰富的模块市场,后台一键快速安装 …...

django|报错SQLite 3.8.3 or later is required的解决方案
迁移原同事写的程序,到新服务器上边。运行报错。解决方案有三种 降低django版本升级sqlite3,不低于3.8.3版本修改django源码 方案一、降低django版本 卸载高版本django pip uninstall django安装低版本,如 pip install django2.1.7注意&…...
通达OA get_datas.php前台sql注入-可获取数据库session登入后台漏洞复现 [附POC]
文章目录 通达OA get_datas.php前台sql注入-可获取数据库session登入后台漏洞复现 [附POC]0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 通达OA get_datas.php前台sql注入-可获取数据库session登入后台漏洞复现…...

苹果官方:所有国行iPhone 15系列都在中国生产!
近几年来,国内供应链逐渐外迁,而拥有庞大劳动力市场的印度却成为了香饽饽,逐渐获得越来越多企业的重视,就连苹果公司也将其视为发展的重要战略要地。 自从苹果扩大印度生产iPhone规模后,很快流言四起,各种负…...

Oracle 安装及 Spring 使用 Oracle
参考内容: docker安装oracle数据库史上最全步骤(带图文) Mac下oracle数据库客户端 Docker安装Oracle docker能安装oracle吗 Batch script for add a auto-increased primary key for exist table with records Docker 安装 Oracle11g 注意&a…...

element-ui 表格 点击选中
element-ui 表格 点击选中 复制element ui 表格 <template><el-table:data"tableData"style"width: 100%"><el-table-columnprop"date"label"日期"width"180"></el-table-column><el-table-col…...
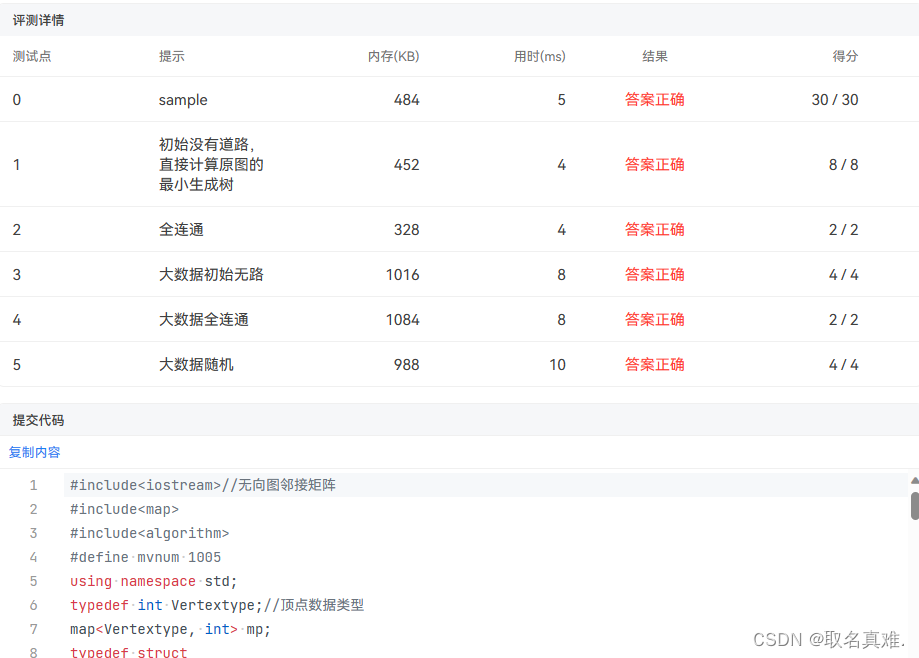
畅通工程之局部最小花费问题 (C++)
目录 题目: 思路: 代码: 结果 题目: 思路: 详细思路都在代码注释里 。 代码: #include<iostream>//无向图邻接矩阵 #include<map> #include<algorithm> #define mvnum 1005 using …...

Sql 异常 + Error
目录 1、Sql 异常 1、SQL Error 1、 Out of sort memory,consider increasing server sort buffer size 2、MySQL排序规则不同关联报错 3、MySQL ....LIMIT 15 4、MySQL:Data truncation: Invalid JSON text 5、MySQL:Duplicate entry ‘xx‘ for key ‘xxxx…...

基于UNI-APP实现适配器并保证适配器和实现的调用一致
概述 前端功能的实现是基于不同的环境采用不同的实现方式的。一种是企业微信小程序,需要基于企业微信框架实现。一种是移动APP,需要基于uni-app的中底层实现。为了调用方便,需要将两种实现统一在一种适配器中,调用者只需要指定环…...
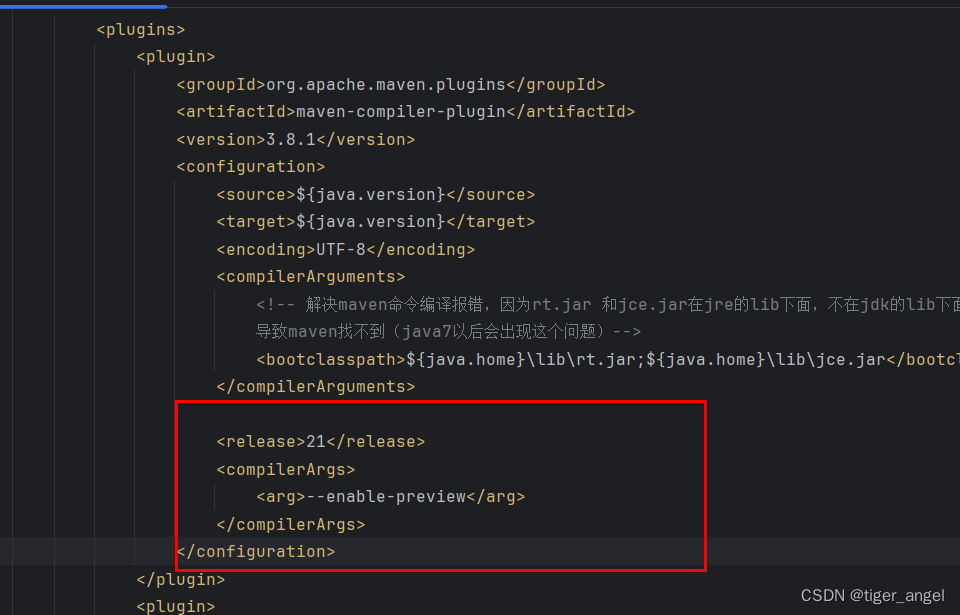
使用jdk21预览版 --enable-preview
异常 [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.10.1:compile (default-compile) on project sb3: Compilation failure [ERROR] --enable-preview 一起使用时无效 [ERROR] (仅发行版 21 支持预览语言功能) 解决…...

js中的跳转都有哪些格式
location.href "URL" :用于在当前窗口中加载其他页面。 例如:location.href "https://www.google.com" location.replace("URL"):用于在当前窗口中加载其他页面,但不保留原页面的历史记录&#…...

无重复字符的最长子串
题目 添加链接描述 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。示例 1:输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2:输入: s "bbbbb" 输出…...
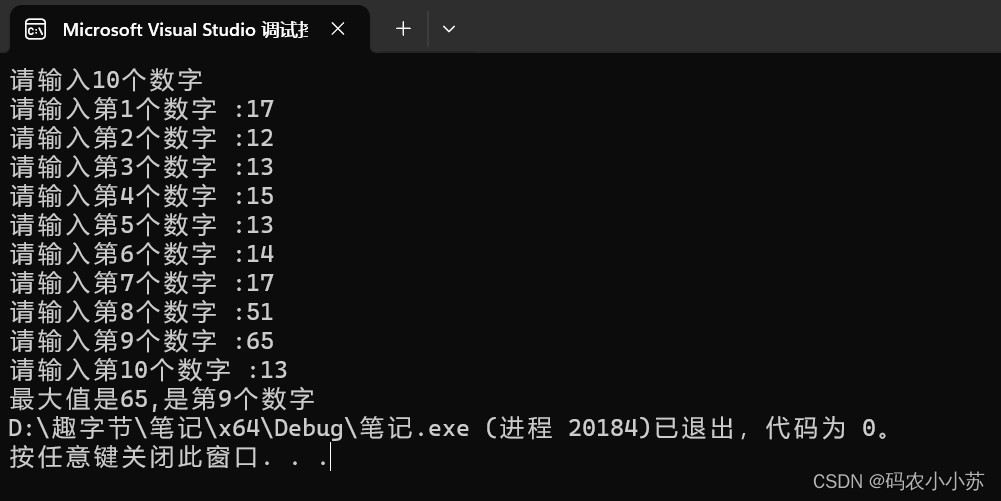
C语言--输入10个数字,要求输出其中值最大的元素和该数字是第几个数
今天小编带大家了解一下什么是“打擂台”算法。 一.思路分析 可以定义一个数组arr,长度为10,用来存放10个数字,设计一个函数Max,用来求两个数中的较大值, 定义一个临时变量tmparr[0],保存临时最大的值,下标…...

如何做好功能测试,提升测试质量和效率?
要做好功能测试并提升测试质量和效率,可以考虑以下几个方面: 1. 明确测试目标和需求 在开始功能测试之前,首先要明确测试的目标和需求,包括测试的范围、重点、预期结果等。这有助于为测试工作提供清晰的方向和指导。 2. 制定详细…...
高德地图添加信息弹窗,信息弹窗是单独的组件
//弹窗组件 <template><el-card class"box-card" ref"boxCard" v-if"showCard"><div slot"header" class"clearfix"><div class"title">{{ model.pointName }}</div><div class…...

如何零代码高效抓取网页数据:Web Scraper Chrome扩展完全指南
如何零代码高效抓取网页数据:Web Scraper Chrome扩展完全指南 【免费下载链接】web-scraper-chrome-extension Web data extraction tool implemented as chrome extension 项目地址: https://gitcode.com/gh_mirrors/we/web-scraper-chrome-extension Web S…...

Windows 10上的Android子系统逆向工程实现:技术深度解析与工程实践
Windows 10上的Android子系统逆向工程实现:技术深度解析与工程实践 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 在微软官方将Windo…...

MySQL 表锁与行锁性能对比
MySQL 表锁与行锁性能对比 在数据库并发控制中,锁机制是保证数据一致性的核心手段。MySQL作为主流关系型数据库,提供了表锁和行锁两种锁定策略,其性能差异直接影响高并发场景下的系统吞吐量。本文将从锁粒度、并发性能、死锁风险、适用场景和…...

Langchain学习笔记1-管道符|构建链路问题初探
Langchain学习笔记1-管道符|构建链路问题初探 问题 学习摘要记忆时,下面一段代码不太理解:变量x就是上一轮的输出吗?那第一次是怎么执行的?| 首先搞清| 的原理,Runnable 重写了__or__,继续点开函数coerce_t…...

OpenIPC:3大技术突破实现网络摄像头固件的完全掌控
OpenIPC:3大技术突破实现网络摄像头固件的完全掌控 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭固件而烦恼吗?想要完全掌控…...
)
别再只测电流了!用INA226模块同时搞定电压、电流、功率的完整配置流程(附STM32代码)
INA226三合一精密测量实战:电压、电流、功率同步采集的工程指南 在嵌入式系统设计中,精确的功率监测往往是项目成败的关键。无论是新能源领域的太阳能充电控制器,还是工业场景中的电机驱动系统,亦或是消费电子产品的电池管理系统…...

如何简单快速地获取网盘直链下载?这款免费开源工具给你完整解决方案
如何简单快速地获取网盘直链下载?这款免费开源工具给你完整解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

如何彻底解决Windows软件残留问题:Bulk Crap Uninstaller深度技术解析
如何彻底解决Windows软件残留问题:Bulk Crap Uninstaller深度技术解析 【免费下载链接】Bulk-Crap-Uninstaller Remove large amounts of unwanted applications quickly. 项目地址: https://gitcode.com/gh_mirrors/bu/Bulk-Crap-Uninstaller Bulk Crap Uni…...

CKS认证-kube-bench CIS 基准测试
3. kube-bench CIS 基准测试问题: Context针对 kubeadm 创建的 cluster 运行 CIS 基准测试工具时,发现了多个必须立即解决的问题。Task通过配置修复所有问题并重新启动受影响的组件以确保新设置生效。修复针对 API服务器发现的所有以下违规行为: 新版…...
)
从手机到Wi-Fi:拆解你身边那些‘看不见’的射频滤波器(SAW/BAW/陶瓷)
从手机到Wi-Fi:拆解你身边那些‘看不见’的射频滤波器(SAW/BAW/陶瓷) 当你用手机刷视频、连Wi-Fi打游戏时,有没有想过这些无线信号是如何在复杂的电磁环境中保持稳定的?答案就藏在那些米粒大小的射频滤波器里。这些不起…...