数据分析实战 | K-means算法——蛋白质消费特征分析
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
编辑 八、模型评价
九、模型调参与预测
一、数据及分析对象
txt文件——“protein.txt”,主要记录了25个国家的9个属性,主要属性如下:
(1)ID:国家的ID。
(2)Country(国家类别):该数据涉及25个欧洲国家肉类和其他食品之间的关系。
(3)关于肉类和其他食品的9个数据包括RedMeat(红肉)、WhiteMeat(白肉)、Eggs(蛋类)、Milk(牛奶)、Fish(鱼类)、Cereals(谷类)、Starch(淀粉类)、Nuts(坚果类)、Fr&Veg(水果和蔬菜)。
二、目的及分析任务
理解机器学习方法在数据分析中的应用——采用k-means方法进行聚类分析。
(1)将数据集导入后,在初始化阶段随机选择k个类簇进行聚类,确定初始聚类中心。
(2)以初始化后的分类模型为基础,通过计算每一簇的中心点重新确定聚类中心。
(3)迭代重复“计算距离——确定聚类中心——聚类”的过程。
(4)通过检验特定的指标来验证k-means模型聚类的正确性和合理性。
三、方法及工具
scikit-learn、pandas和matplotlib等Python工具包。
四、数据读入
import pandas as pd
protein=pd.read_table("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第5章 聚类分析\\protein.txt",sep='\t')
protein.head()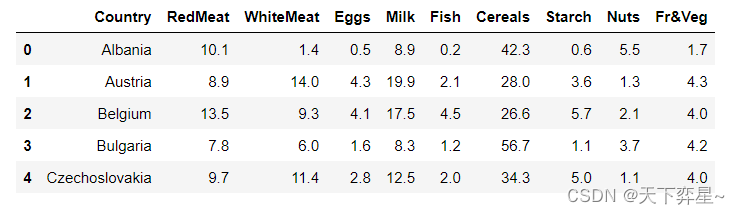
五、数据理解
对数据框protein进行探索性分析,这里采用的实现方式为调用pandas包中数据框(DataFrame)的describe()方法。
protein.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
protein.shape(25, 10)
六、数据准备
在进行不同国家蛋白质消费结果分析时,要把对信息分析有用的数据提取出来,即关于肉类和其他食品的9列。具体实现方式为调用pandas包中数据框的drop()方法,删除列名“Country”的数据。
sprotein=protein.drop(['Country'],axis=1)
sprotein.head()
将待聚类数据提取后,需要对该数据集进行以均值为中心的标准化处理,在此采用的是统计学中的Z-Score标准化方法。
from sklearn import preprocessing
sprotein_scaled=preprocessing.scale(sprotein)
sprotein_scaledarray([[ 0.08294065, -1.79475017, -2.22458425, -1.1795703 , -1.22503282,0.9348045 , -2.29596509, 1.24796771, -1.37825141],[-0.28297397, 1.68644628, 1.24562107, 0.40046785, -0.6551106 ,-0.39505069, -0.42221774, -0.91079027, 0.09278868],[ 1.11969872, 0.38790475, 1.06297868, 0.05573225, 0.06479116,-0.5252463 , 0.88940541, -0.49959828, -0.07694671],[-0.6183957 , -0.52383718, -1.22005113, -1.2657542 , -0.92507375,2.27395937, -1.98367386, 0.32278572, 0.03621022],[-0.03903089, 0.96810416, -0.12419682, -0.6624669 , -0.6851065 ,0.19082957, 0.45219769, -1.01358827, -0.07694671],[ 0.23540507, 0.8023329 , 0.69769391, 1.13303099, 1.68457011,-0.96233157, 0.3272812 , -1.21918427, -0.98220215],[-0.43543839, 1.02336124, 0.69769391, -0.86356267, 0.33475432,-0.71124003, 1.38907137, -1.16778527, -0.30326057],[-0.10001666, -0.82775116, -0.21551801, 2.38269753, 0.45473794,-0.55314536, 0.51465594, -1.06498727, -1.5479868 ],[ 2.49187852, 0.55367601, 0.33240914, 0.34301192, 0.42474204,-0.385751 , 0.3272812 , -0.34540128, 1.33751491],[ 0.11343353, -1.35269348, -0.12419682, 0.07009624, 0.48473385,0.87900638, -1.29663317, 2.4301447 , 1.33751491],[-1.38071781, 1.24438959, -0.03287563, -1.06465843, -1.19503691,0.73021139, -0.17238476, 1.19656871, 0.03621022],[ 1.24167025, 0.58130455, 1.61090584, 1.24794286, -0.62511469,-0.76703815, 1.20169663, -0.75659327, -0.69930983],[-0.25248108, -0.77249407, -0.03287563, -0.49009911, -0.26516381,0.42332173, -1.35909141, 0.63117972, 1.45067184],[-0.10001666, 1.57593211, 0.60637272, 0.90320726, -0.53512697,-0.91583314, -0.04746827, -0.65379528, -0.24668211],[-0.13050955, -0.88300824, -0.21551801, 0.88884328, 1.62457829,-0.86003502, 0.20236471, -0.75659327, -0.81246676],[-0.89283166, 0.63656164, -0.21551801, 0.31428395, -0.38514744,0.35822393, 1.0143219 , -0.55099728, 1.39409338],[-1.10628185, -1.15929368, -1.67665709, -1.75412962, 2.97439408,-0.48804755, 1.0143219 , 0.83677571, 2.12961342],[-1.10628185, -0.44095155, -1.31137232, -0.86356267, -0.98506557,1.61368162, -0.73450896, 1.14516971, -0.75588829],[-0.83184589, -1.24217931, 0.14976676, -1.22266225, 0.81468882,-0.28345445, 0.88940541, 1.45356371, 1.73356417],[ 0.02195488, -0.0265234 , 0.51505153, 1.08993904, 0.96466835,-1.18552405, -0.35975949, -0.85939127, -1.20851601],[ 0.99772718, 0.60893309, 0.14976676, 0.96066319, -0.59511878,-0.61824316, -0.9218837 , -0.34540128, 0.43225947],[ 2.30892121, -0.60672281, 1.61090584, 0.50101573, 0.00479935,-0.73913909, 0.26482296, 0.16858872, -0.47299597],[-0.16100243, -0.91063679, -0.76344517, -0.07354359, -0.38514744,1.05570042, 1.32661312, 0.16858872, -0.69930983],[ 0.47934814, 1.27201813, 1.06297868, 0.24246404, -0.26516381,-1.26922123, 0.57711418, -0.80799227, -0.19010364],[-1.65515377, -0.80012261, -1.5853359 , -1.0933864 , -1.10504919,2.19956187, -0.79696721, 1.35076571, -0.52957443]])
七、模型训练
在使用k-means算法对其数据集进行聚类之前,我们在初始化阶段产生一个随机的k值作为类簇的个数。在scikit-learn框架中,使用“决定系数’作为性能评估的分数(score),该参数可以判断不同分类情况的统计模型对数据的拟合能力。这里采用的实现方式是调用sklearn.cluster模块的k-means.fit().score()方法。
#K值得选择
from sklearn.cluster import KMeans
NumberOfClusters=range(1,20)
kmeans=[KMeans(n_clusters=i) for i in NumberOfClusters]
score=[kmeans[i].fit(sprotein_scaled).score(sprotein_scaled) for i in range(len(kmeans))]
score[-225.00000000000003,-139.5073704483181,-110.40242709032155,-93.99077697163418,-77.34315775475405,-64.22779496320605,-52.68794493054983,-46.148487504020046,-41.95277071693863,-35.72656669867341,-30.429164116494334,-26.430420929243024,-22.402609200395787,-19.80060035995764,-16.86466531666006,-13.979313757304398,-11.450822978023083,-8.61897844282252,-6.704106008601115]
上面的输出结果为每一个kmeans(n_clusters=i)(1<=i<=19)的预测值,为更直观地观察每个值的变化情况,可绘制一个ROC曲线。具体实现方式是调用matplotlib包的pyplot()方法。
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(NumberOfClusters,score)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()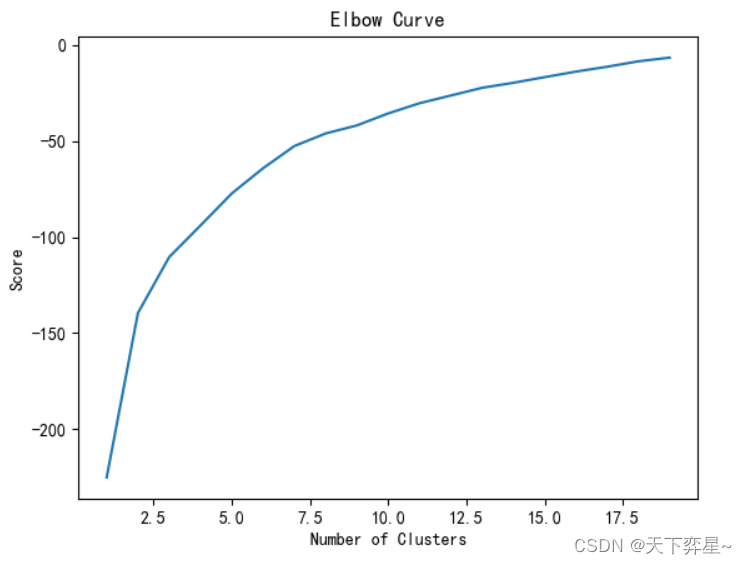
接着,随机设定聚类的数目为5,并以此为基础在数据矩阵上执行均值聚类,并查看模型预测结果,这里的具体实现方式是调用scikit-learn包的KMeans()方法和predict()方法,其中KMeans()方法需要设置的主要参数如下:
(1)algorithm使用默认值"auto",表示使用k-means中的elkan或full算法,由样本数据的稠密程度决定。
(2)n_clusters表示分类簇的数量。
(3)n_init表示运行该算法的尝试初始化次数。
(4)max_iter表示最大的迭代次数。
(5)verbose表示日志信息,这里使用默认“0”值,不输出日志信息。
myKMeans=KMeans(algorithm="auto",n_clusters=5,n_init=10,max_iter=200,verbose=0)
myKMeans.fit(sprotein_scaled)
y_kmeans=myKMeans.predict(sprotein)
print(y_kmeans)[2 4 4 2 4 4 4 3 4 2 2 4 2 4 4 4 0 2 2 4 4 4 2 4 2]
通过以上分析,由确定的k=5,将数据集protein划分成5个类簇,类簇编号为0,1,2,3,4.接下来,显示每个样本所属的类簇编号。
protein["所隶属的类簇"]=y_kmeans
protein
 八、模型评价
八、模型评价
可见,k-means算法可以完成相对应的聚类输出。接下来,引入轮廓系数对宣发聚类结果进行评价。这里采用的实现方式为调用Bio包Cluster模块的kcluster()方法,并调用silhouette_score()方法返回所有样本的轮廓系数,取值范围为[-1,1],轮廓系数值越大越好。
from sklearn.metrics import silhouette_score
silhouette_score(sprotein,y_kmeans)0.2222236683250513
number=range(2,20)
myKMeans_list=[KMeans(algorithm="auto",n_clusters=i,n_init=10,max_iter=200,verbose=0) for i in number]
y_kmeans_list=[myKMeans_list[i].fit(sprotein_scaled).predict(sprotein_scaled) for i in range(len(number))]
score=[silhouette_score(sprotein,y_kmeans_list[i]) for i in range(len(number))]score[0.4049340501486218,0.31777138102456476,0.16996270462188423,0.21041645106099247,0.1943500298289292,0.16862742616667453,0.1868090290661263,0.08996856437394235,0.10531808817576255,0.13528249120860153,0.07381598489593617,0.09675173868153258,0.056460835203354785,0.10871862224667578,0.04670651599769748,0.03724019668260051,0.0074356180520073045,0.013165944671952217]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.plot(number,score)
plt.xlabel("k值")
plt.ylabel("轮廓系数")
九、模型调参与预测
通过轮廓系数的分析,我们可以确定聚类中心的数量为2,并以此为基础在样本数据集protein上执行聚类。
estimator=KMeans(algorithm="auto",n_clusters=2,n_init=10,max_iter=200,verbose=0)
estimator.fit(sprotein_scaled)
y_pred=estimator.predict(sprotein_scaled)
print(y_pred)[1 0 0 1 0 0 0 0 0 1 1 0 1 0 0 0 1 1 1 0 0 0 1 0 1]
绘制聚类图:
x1=[]
y1=[]
x2=[]
y2=[]
for i in range(len(y_pred)):if y_pred[i]==0:x1.append(sprotein['RedMeat'][i])y1.append(sprotein['WhiteMeat'][i])if y_pred[i]==1:x2.append(sprotein['RedMeat'][i])y2.append(sprotein['WhiteMeat'][i])
plt.scatter(x1,y1,c="red")
plt.scatter(x2,y2,c="orange")
plt.show()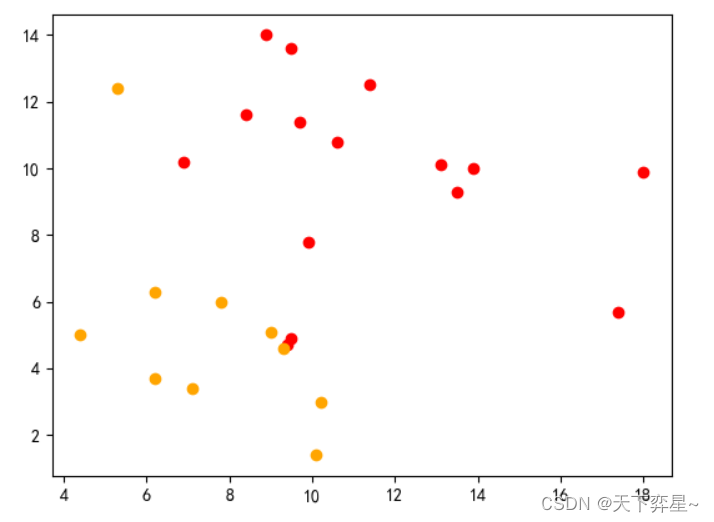
相关文章:
数据分析实战 | K-means算法——蛋白质消费特征分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 编辑 八、模型评价 九、模型调参与预测 一、数据及分析对象 txt文件——“protein.txt”,主要记录了25个国家的9个属性,主…...
HTTP协议详解-下(Tomcat)
如何构造 HTTP 请求 对于 GET 请求 地址栏直接输入点击收藏夹html 里的 link script img a…form 标签 通过 form 标签构造GET请求 <body><!-- 表单标签, 允许用户和服务器之间交互数据 --><!-- 提交的数据报以键值对的结果来组织 --><form action&quo…...

acwing算法基础之搜索与图论--prim算法
目录 1 基础知识2 模板3 工程化 1 基础知识 朴素版prim算法的关键步骤: 初始化距离数组dist,将其内的所有元素都设为正无穷大。定义集合S,表示生成树。循环n次:找到不在集合S中且距离集合S最近的结点t,用它去更新剩余…...

Amazon EC2 Serial Console 现已在其他亚马逊云科技区域推出
即日起,交互式 EC2 Serial Console 现也在以下区域推出:中东(巴林)、亚太地区(雅加达)、非洲(开普敦)、中东(阿联酋)、亚太地区(香港)…...
-39)
hdlbits系列verilog解答(100输入逻辑门)-39
文章目录 一、问题描述二、verilog源码三、仿真结果一、问题描述 构建一个具有 100 个输入in[99:0]的组合电路。 有 3 个输出: out_and: output of a 100-input AND gate. out_or: output of a 100-input OR gate. out_xor: output of a 100-input XOR gate. 二、verilog源…...

Python 中 Selenium 的屏幕截图
文章目录 使用 save_screenshot() 函数在 Python 中使用 selenium 捕获屏幕截图使用 get_screenshot_as_file() 函数在 Python 中使用 selenium 捕获屏幕截图使用 Screenshot-Selenium 包在 Python 中使用 selenium 捕获屏幕截图总结我们可以使用 Selenium 在自动化 Web 浏览器…...

scrapy发json的post请求
一 、scrapy发json的post请求: def start_requests(self):self.headers {Content-Type: application/json}json_data {"productName": "", "currentPage": "1", "recordNumber": "10", "langua…...
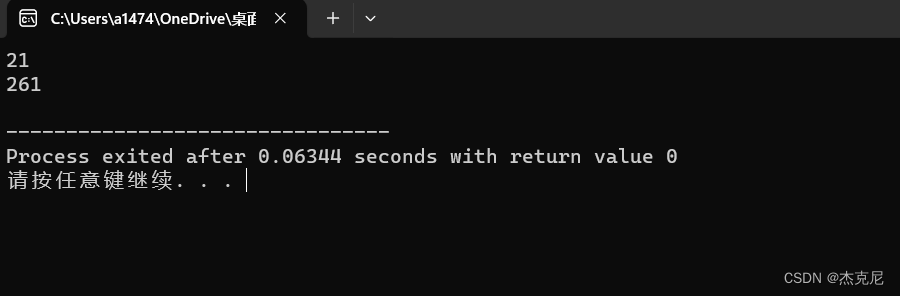
一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?
目录 1解题思路: 2代码如下: 3运行结果: 4总结: 5介绍: 1解题思路: 利用循环(穷举法)来 对 所 需要的数 进行确定 2代码如下: #include <stdio.h>int main() …...
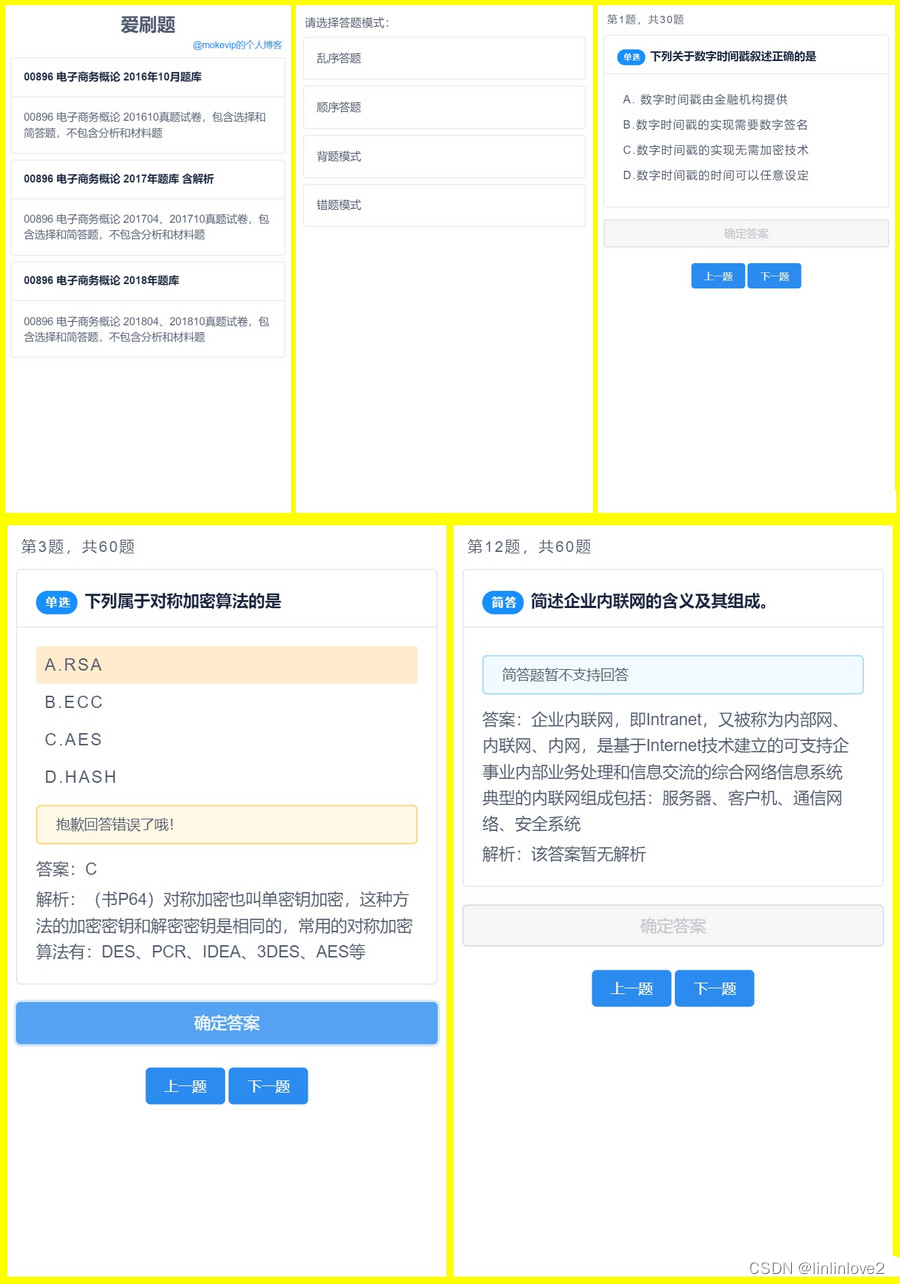
自主开发刷题应用网站H5源码(无需后端无需数据库)
该应用使用JSON作为题库的存储方式,层次清晰、结构简单易懂。 配套的word模板和模板到JSON转换工具可供使用,方便将题库从word格式转换为JSON格式。 四种刷题模式包括顺序刷题、乱序刷题、错题模式和背题模式,可以根据自己的需求选择适合的模…...

java 读取excel/word存入mysql
引入依赖 <!--poi--><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.0.1</version></dependency><dependency><groupId>org.apache.poi</groupId><artif…...

11.(vue3.x+vite)组件间通信方式之ref与$parent、$children
前端技术社区总目录(订阅之前请先查看该博客) 示例效果 注: (1)ref 加在标签(div等)上,是拿到dom 对象 (2)ref加上组件上,拿到的是组件的引用 (3)让父组件获取子组件的数据或者方法需要通过defineExpose对外暴露,另外让父组件获取子组件的数据或者方法需要通过d…...

[工业自动化-12]:西门子S7-15xxx编程 - PLC从站 - ET200 SP系列详解
目录 一、概述 1.1 概述 二、系统组成 2.1 概述 2.2 与主站的通信接口模块 2.3 总线适配器 2.4 基座单元 2.5 电子模块 2.6 服务器模块 一、概述 1.1 概述 PLC ET200 SP 是西门子(Siemens)公司生产的一款模块化可编程逻辑控制器(PL…...

消息队列简介
消息队列 在认识rabbitMQ之前,我们需要先认识下消息队列。 消息队列,一般简称为MQ(Message Queue)。先不管消息(Message)这个词,先看看队列(Queue)。 队列就是一种先进先出的数据结构。 所以消息队列可以简单理解为&a…...

SQL中实现汉字的拼音首字母查询
由于汉语拼音首字母也就23个,该方法利用汉字字符按拼音字母排序的特点来生成对应的拼单首字母,只需找到这23个汉语拼音首字母中分别排序在第一的汉字生成23条临时表数据用于参照,即可简单实现汉字匹配拼音首字母 CREATE FUNCTION f_GetPyAcr…...

今天知道LiveData的ktx是真的香
主要还是认知问题,Android 官网从一开始就在推ktx,现在都已经2. 版本了,但是呢,因为之前没有从0开始写过一个Kotlin的APP,就陷入了一个JAVA 思维,在JAVA 中我们知道要做到像协程这么处理不是不能࿰…...

SpringBoot中的桥接模式
桥接模式是一种结构型设计模式,它的主要目的是通过将抽象部分与实现部分分离,提高系统的灵活性和可扩展性。在桥接模式中,有四个主要参与者:抽象类、具体抽象类、桥接类和具体类。 抽象类是定义了抽象方法的基类,这些…...
AI爆文变现脚本:易用且免费的自动写作脚本更新了
之前给大家分享的AI爆文变现写作脚本 由于时间仓促,加上我对很多东西不熟悉 免费版本对新手小白来说,安装部署起来是非常的困难 于是这几天我加班加点把整个软件的部署简化 现在无需复杂的环境配置安装,下载配置下就可以使用了。 免费版…...

代码随想录算法训练营Day 49 || 123.买卖股票的最佳时机III 、188.买卖股票的最佳时机IV
123.买卖股票的最佳时机III 力扣题目链接(opens new window) 给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。 设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。 注意:你不能同时参与多笔交易(你必须…...

threejs(11)-精通着色器编程(难点)2
一、shader着色器编写高级图案 小日本国旗 precision lowp float; varying vec2 vUv; float strength step(0.5,distance(vUv,vec2(0.5))0.25) ; gl_FragColor vec4(strength,strength,strength,strength);绘制圆 precision lowp float; varying vec2 vUv; float strength 1…...

配置cuda和cudnn出现 libcudnn.so.8 is not a symbolic link问题
cuda版本为11.2 问题如图所示: 解决办法: sudo ln -sf /usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1 /usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8 sudo ln -sf /usr/local/cuda-11.2/targ…...

10分钟训练AI音色模型:RVC变声器终极实战指南
10分钟训练AI音色模型:RVC变声器终极实战指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conversion-WebU…...
)
保姆级教程:在MMSegmentation框架下复现HRNetV2+OCR语义分割(附完整代码与调试技巧)
从零实现HRNetV2OCR语义分割:MMSegmentation实战指南与深度调优 当你在GitHub上搜索"HRNetV2 OCR implementation"时,会发现大多数仓库要么只有论文复现的片段代码,要么存在各种环境兼容性问题。作为计算机视觉领域经典的语义分割方…...

X-AnyLabeling3.2实战:从零部署到自定义模型自动标注
1. X-AnyLabeling3.2安装与环境配置 第一次接触X-AnyLabeling这个开源标注工具时,我就被它的自动标注功能吸引了。相比传统的手动标注,它能节省80%以上的时间。不过安装过程确实有些坑要避开,这里分享我的实战经验。 首先需要准备Anaconda环境…...

如何在 Linux 系统安装 Nginx?附可视化安装与管理教程
很多人在刚接触服务器时,都会遇到一个非常实际的问题:如何在系统安装 Nginx? Nginx 作为目前最常用的 Web 服务软件之一,广泛应用于静态网站部署、反向代理、负载均衡、HTTPS 证书配置以及前后端项目发布。对于运维人员、站长或者…...

解放华硕笔记本性能:GHelper轻量级控制工具完全指南
解放华硕笔记本性能:GHelper轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...

EVA-01企业微信机器人实战:5步打造移动端图片分析助手
EVA-01企业微信机器人实战:5步打造移动端图片分析助手 1. 项目背景与价值 在移动办公场景中,我们经常遇到需要快速分析图片内容的场景:工厂设备巡检、产品设计评审、文档信息提取等。传统方式需要将图片传输到电脑端,再通过专业…...

如何快速构建电商库存扫描系统:QuaggaJS条形码识别终极指南
如何快速构建电商库存扫描系统:QuaggaJS条形码识别终极指南 【免费下载链接】quaggaJS An advanced barcode-scanner written in JavaScript 项目地址: https://gitcode.com/gh_mirrors/qu/quaggaJS 在电商运营中,高效的库存管理是提升效率和降低…...

django-activity-stream扩展开发:自定义活动处理器与信号机制
django-activity-stream扩展开发:自定义活动处理器与信号机制 【免费下载链接】django-activity-stream Generate generic activity streams from the actions on your site. Users can follow any actors activities for personalized streams. 项目地址: https:…...

麒麟服务器系统LVM实战:从物理卷到逻辑卷的完整配置指南
1. LVM基础概念与麒麟服务器系统适配性 在麒麟服务器系统中管理存储空间时,传统分区方式会遇到一个典型问题:当分区空间不足时,往往需要备份数据、重新分区再恢复数据,这个过程不仅耗时还可能影响业务连续性。而LVM(Lo…...

Windows本地AI新玩法:Docker Compose一键部署Ollama与Open WebUI,小白也能玩转私有大模型
1. 为什么要在Windows上部署本地大模型? 最近两年AI技术发展迅猛,各种大语言模型层出不穷。但很多朋友可能都有这样的困扰:每次想用AI都得联网,还得担心隐私问题。其实现在完全可以在自己的Windows电脑上搭建一个私有大模型&#…...