机器学习算法-集成学习
概念
集成学习是一种机器学习方法,它通过构建并结合多个机器学习器(基学习器)来完成学习任务。集成学习的潜在思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成学习通常被视为一种元算法(meta-algorithm),因为它不是单独的机器学习算法,而是一种通用的策略,可以应用于各种不同类型的机器学习算法。
集成学习的特点
- 使用多种兼容的学习算法或模型来执行单个任务,目的是为了得到更佳的预测表现。
- 通过构建并结合多个学习器(基学习器)来完成学习任务,以此来提高整体性能。
- 集成学习的主要方法可以归类为三大类:Bagging、Boosting和Stacking。
- 基于Bagging的算法有例如随机森林,基于Boosting的算法包括Adaboost、GBDT、XGBOOST等。
- 集成学习在各个规模的数据集上都有很好的适应性。对于大型数据集,可以划分成多个小数据集,学习多个模型进行组合;对于小型数据集,可以利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合。
集成学习集成策略
投票法是集成学习中一种常用的策略,主要针对分类问题。它遵循少数服从多数的原则,通过集成多个模型降低方差,从而提高模型的鲁棒性和泛化能力。常见的投票法有绝对多数投票、相对多数投票和加权投票法。
- 绝对多数投票:也称为硬投票,是指所有基分类器中,某一类别得票数最多的类别作为最终预测结果。
- 相对多数投票:与绝对多数投票不同的是,它是基于概率的投票方法。每一个基分类器都会给出各自预测的概率值,最终选择概率最大的类别作为预测结果。
- 加权投票法:每一基分类器的预测结果都会乘以一个权重,最后将各个加权票数求和,得到总票数,选择总票数最高的类别作为预测结果。
集成学习算法类型
集成学习是一种强大的机器学习策略,它通过结合多个独立的模型来提高整体性能。其核心思想是单个分类器可能不好,使用多个分类器可以提高准确性和稳定性。常见的集成算法类型有Bagging、Boosting和Stacking。
- Bagging(Bootstrap Aggregating):也被称为自助集结法,它是一种并行式的集成学习算法。Bagging通过自助采样法生成N个样本数相同的子样本,然后训练出N个基分类器。最后,采用投票法(硬投票或软投票)来决定最终的分类结果。此种方法可以降低模型的方差,因此对防止过拟合有很好的效果。随机森林就是一种基于Bagging的集成学习算法。
- Boosting:这是一种串行式的集成学习算法。在Boosting中,前一个基分类器分错的样本会被赋予更高的权重,使得后续的基分类器更加关注这些难以分类的样本。此外,每一轮的学习过程中,都会根据上一轮的表现来更新样本的权重。最终,同样采用投票法决定最终的分类结果。Adaboost和GBDT等都是基于Boosting的集成学习算法。
- Stacking:也是一种串行式的集成学习算法。与Boosting不同的是,在Stacking中,基分类器的输出被作为输入传给下一个阶段的模型(又称为次级学习器或元分类器),而这个元分类器会基于前面的基分类器的输出来进行最终的预测。Stacking可以结合各种不同类型的基分类器,因此在理论上可以获得非常好的性能。
Bagging 经典代表:随机森林
随机森林是一种基于Bagging的集成学习算法,主要通过结合多个决策树(也称作基分类器)来进行预测,从而提高整体模型的准确性和稳定性。
随机森林的生成过程主要包括两个步骤:自助采样和决策树构建。在自助采样阶段,原始数据集中的数据会被随机抽样出与训练集个数相同的样本,形成若干个子集。这一过程允许同一样本有可能被多次抽取。然后,每一个子集会被用来独立地训练出一个决策树,这样我们就得到了多个基分类器。这些基分类器各自进行学习和预测,他们的预测结果再通过投票或取均值的方式结合起来,得到最终的预测结果。因此随机森林包含了两个随机过程,一个是数据子集的选取,另一个是属性的随机选择。
随机森林也有一些优缺点:
随机森林有很多优点,比如它的表现性能高,准确率极高,并且能够有效地在大数据集上运行。通过引入随机性,随机森林不容易过拟合,而且有很好的抗噪声能力。此外,随机森林能处理很高维度的数据,而无需进行特征选择或降维。它可以处理离散型和连续型数据,不需要对数据集进行规范化。训练速度快是另一个优势,它还能为变量重要性提供排序。随机森林的实现易于并行化,即使面对缺失值问题,也能获得良好的结果。
然而,随机森林也有一些缺点需要注意。例如,当决策树的数量很大时,训练所需的空间和时间可能会非常大,这可能导致模型运行速度减慢。因此,在对实时性有较高要求的场合,可能需要选择其他算法。
Boosting 经典代表(一):AdaBoost
AdaBoost,全称为Adaptive Boosting(自适应增强),是一种迭代算法,通过结合多个弱分类器,形成一个强分类器。其核心思想是针对前一个基本分类器误分类的样本加大权值,并减少正确分类样本的权值,然后再次用来训练下一个基本分类器。
AdaBoost算法的运行过程可以概括为以下几步:
1. 初始化训练数据的权值分布。假设有N个训练样本数据,则每一个训练样本最开始时都被赋予相同的权值:1/N。
2. 训练弱分类器。在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。
3. 计算弱分类器的错误率,即分错样本的概率,并根据错误率更新弱分类器的权重。
4. 进行权值更新。依据上一个分类器的权重调整每一个样本的权重,上一次分对的样本权重降低,分错的样本权重提高。
5. 重复上述步骤,直至达到预设的迭代次数或者满足某个终止条件。最后,所有弱分类器的组合形成强分类器。
AdaBoost算法的优缺点:
总的来说,AdaBoost算法的优势在于它能够自动地、适应性地改变每个样本的权重和每个弱分类器的权重,以达到提升整体性能的目标。同时,该算法也具有较好的鲁棒性,能很好地处理噪声数据和异常数据。
AdaBoost算法的优势主要体现在以下几个方面:首先,该算法能够很好地利用弱分类器进行级联,即通过组合多个性能一般的分类器,形成一个性能优秀的强分类器。其次,AdaBoost的灵活性较高,它可以与不同的分类算法结合,作为弱分类器使用。此外,相对于bagging算法和Random Forest算法,AdaBoost在设计上更加精细,它充分考虑了每个分类器的权重。最后,AdaBoost具有很高的精度,它凭借各个分类器的协同作用,可以有效提高预测的准确性。
然而,AdaBoost算法也存在一些不足之处:首先,AdaBoost对噪声数据和异常数据较为敏感,这可能会影响最后的分类效果。其次,由于AdaBoost算法在训练过程中需要反复调用分类器,因此其训练时间较长。再者,当训练数据不平衡时,即各个类别的样本数量存在较大差异时,AdaBoost算法可能无法得到理想的分类效果。
Boosting 经典代表(二):GBDT
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,主要GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,主要包含三个概念:Regression Decision Tree(即DT),Gradient Boosting(即GB),和Shrinkage。在处理分类或回归问题时,GBDT通过多轮迭代训练一系列的弱分类器,每个分类器都尽可能的去拟合之前所有分类器留下的误差。
而Adaboost和GBDT虽然都是基于加法模型和前向分步算法,但两者在处理错误分类数据的方式上存在较大差异。Adaboost主要是通过提升错分数据点的权重来定位模型的不足,并通过每一次迭代调整样本权重分布使损失函数达到最小。相比之下,GBDT则算梯度(gradient)来定位模型的不足,因此它可以使用更多种类的目标函数。
总的来说,Adaboost和GBDT各有优势和适用场景,但在处理不平衡数据、噪声数据和异常数据时,GBDT通常可以表现得更加鲁棒。
GBDT的训练过程
1. 初始化:首先,确定每个样本的初始值,这个值通常是样本的目标值或者是一个随机数。然后设定树的数量T,学习率α和树的最大深度H。
2. 增加树:对于前面t-1棵树,计算其预测结果与实际值之间的残差。然后,通过拟合残差来训练第t棵树。这一步通常使用CART回归树来实现。值得注意的是,新的树是通过学习之前所有树的残差来构建的,这也是GBDT得名“梯度提升”的原因。
3. 更新模型:每训练完一棵树后,都需要更新当前的模型。对于分类问题,可以使用简单投票法;对于回归问题,则可以计算所有树的预测结果的平均值作为最终预测值。
4. 循环迭代:重复上述步骤T次,即得到T棵完全生长的决策树。需要注意的是,在构建新的树时,需要减小上一次的残差。
GBDT的优缺点
优点:
1. 泛化性能强:GBDT每一次的残差计算都增大了分错样本的权重,而分对的权重都趋近于0,因此其泛化性能比较好。
2. 处理数据类型灵活:可以灵活的处理各种类型的数据。
3. 预测精度高:通过多轮迭代训练一系列的弱分类器,每个分类器都尽可能的去拟合之前所有分类器留下的误差,从而提高预测精度。
缺点:
1. 对异常值敏感:由于GBDT算法在处理数据时会考虑到每一个样本,所以对异常值比较敏感。
2. 并行计算困难:由于分类器之间存在依赖关系,新的树需要基于前面所有树的结果来构建,因此无法进行并行计算,这大大影响了计算效率。
3. 调参复杂、训练时间长:GBDT需要仔细调整参数,而且训练时间可能会比较长。
Boosting 经典代表(三):XGBoost
XGBoost,全称eXtreme Gradient Boosting,是由华盛顿大学研究XGBoost,全称eXtreme Gradient Boosting,是由华盛顿大学研究机器学习的专家陈天奇创建的一种基于Boosting框架的机器学习算法工具包。这种算法既可以用于回归问题,也可以应用于分类和排序问题。
在并行计算效率、缺失值处理、预测性能等方面,XGBoost表现出了非常强大的能力。其基本思想和GBDT相同,但是在实现上做了一系列优化。例如,它采用了二阶导数来使损失函数变得更精确;同时,正则项的使用可以避免模型过拟合的问题。这些优秀的特性使得XGBoost在大规模数据集上运行的效率非常高,并且具有广泛的适用性。
XGBoost的创新之处主要体现在以下几个方面:
首先,目标函数中引入了正则项,降低了模型过拟合的风险。其次,定义了一种新的特征切分指标,该指标利用了损失函数的二阶泰勒展开,提高了模型的准确性。此外,其损失函数变得更为灵活,不再局限于CART的均方误差,只要其二阶可导即可。
在处理大规模数据时,XGBoost表现出了很强的扩展性。它采用sparsity-aware algorithm算法,能够解析稀疏数据。并且,利用加权分位数图作用于有效的树训练和计算。这些特性使得XGBoost在处理大数据时具有很高的效率和准确性。
在工程实现上,XGBoost也做出了一些创新。例如,采用了分块并行(Column Block for Parallel Learning)和缓存访问(Cache-aware Access)的技术,以提高训练速度。同时,还做了特征采样处理,在降低过拟合风险的同时,也提高了模型的训练速度。
总的来说,XGBoost通过以上的一系列创新点,不仅提高了模型的准确性和泛化能力,同时也大大提高了模型的训练速度和效率。这使得XGBoost在各种机器学习任务中都表现出了优秀的性能。
XGBoost VS GBDT
XGBoost和GBDT都是基于Boosting的集成学习算法,它们各自都有一些优点和缺点。
GBDT的优点主要体现在其强大的表达能力,它不需要复杂的特征工程和特征转换,而且能灵活处理各种类型的数据。但是,GBDT也有其明显的缺点。首先,Boosting过程是串行的,难以并行化,这限制了其在大规模数据集上的应用。其次,GBDT在优化时只使用一阶导数信息,这可能会影响模型的准确性。此外,GBDT也不太适合处理高维稀疏特征。
相比之下,XGBoost在许多方面都做出了改进。首先,XGBoost在目标函数中引入了正则项,有效地防止了模型过拟合。其次,XGBoost采用了二阶导数信息来提高模型的准确性。此外,XGBoost还支持线性分类器,相当于带L1和L2正则化项的逻辑斯蒂回归或者线性回归。这使得XGBoost在处理大规模数据集时具有很高的效率和准确性。最后,XGBoost还能够自动利用CPU的多线程进行并行计算,进一步提高了训练速度。
总的来说,虽然GBDT和XGBoost各有优缺点,但是在大多数情况下,由于其高效的训练速度和优秀的预测性能,XGBoost往往被更广泛地应用在各种机器学习任务中。
Stacking 介绍
Stacking,也被称为堆叠,是一种集成学习策略,它主要利用多个不同的基学习器进行模型的集成。其核心思想是,首先将数据集分成训练集和测试集,然后使用训练集训练得到多个初级学习器。接着,让这些初级学习器对测试集进行预测,并将输出值作为下一阶段训练的输入值,最终的标签作为输出值,用于训练次级学习器。
为了尽可能降低过拟合的风险并提高模型的泛化能力,通常在Stacking算法中会采用交叉验证法或留一法来进行训练。同时,为了防止划分训练集和测试集后,测试集比例过小,生成的次级学习器泛化性能不强的问题,我们常常会通过K折交叉验证的方式来确定每个初级学习器的参数。
值得一提的是,Stacking被认为是数据挖掘竞赛中的"大杀器",广泛应用于各种大数据挖掘竞赛中。尽管Stacking严格来说不能称为一种算法,但是它的集成策略却非常精美而复杂。总的来说,Stacking算法的核心就是结合多个简单模型的预测结果来形成一个更强大、更准确的模型。
Stacking算法的优点主要体现在以下几个方面:
首先,它能够结合多个不同的基学习器进行模型的集成,通过这种方式生成了一个新的模型,可以更好地提高预测的准确性。其次,Stacking可以利用多折交叉验证来选择最优的参数,这有助于降低过拟合的风险并提高模型的泛化能力。此外,如果某个一级学习器错误地学习了特征空间的某个区域,那么二级学习器可以通过结合其他一级学习器的学习行为,适当纠正这种错误。
然而,Stacking算法也存在一些缺点。首先,由于Stacking需要使用多折交叉验证,这会使计算过程变得复杂和耗时。其次,Stacking算法要求每个初级学习器都要有一定的准确性,否则次级学习器可能无法很好地纠正初级学习器的错误。此外,如果不合理地设置初级学习和次级学习器的参数,可能会导致模型过拟合。最后,与bagging相比,stacking中的各模型(基分类器)追求的是“准而不同”,过于准确的基学习器可能会使得bagging的集成失去意义。
关于集成学习的更多问题可以提问小策问答
链接:https://pan.baidu.com/s/1quqJQc3AUvcmN0hd_lrCEw?pwd=1234
提取码:1234
--来自百度网盘超级会员V4的分享
相关文章:

机器学习算法-集成学习
概念 集成学习是一种机器学习方法,它通过构建并结合多个机器学习器(基学习器)来完成学习任务。集成学习的潜在思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成学习通常被视为一种元算法&…...

LINUX入门篇【4】开发篇--开发工具vim的使用
前言: 从这一篇开始,我们将正式进入使用LINUX进行写程序和开发的阶段,可以说,由此开始,我们才开始真正去使用LINUX。 介绍工具: 1.LINUX软件包管理器yum: 1.yum的介绍: 在LINUX…...

代码随想录算法训练营Day 50 || 309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费
309.最佳买卖股票时机含冷冻期 力扣题目链接 给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票): 你不能同时…...

【C语言】【数据结构】【环形链表判断是否带环并返回进环节点】有数学推导加图解
1.判断是否带环: 用快慢指针 slow指针一次走一步,fast指针一次走两步 当两个指针相遇时,链表带环;两个指针不能相遇时,当fast走到倒数第一个节点或为空时,跳出循环返回空指针。 那么slow指针一次走一步&a…...
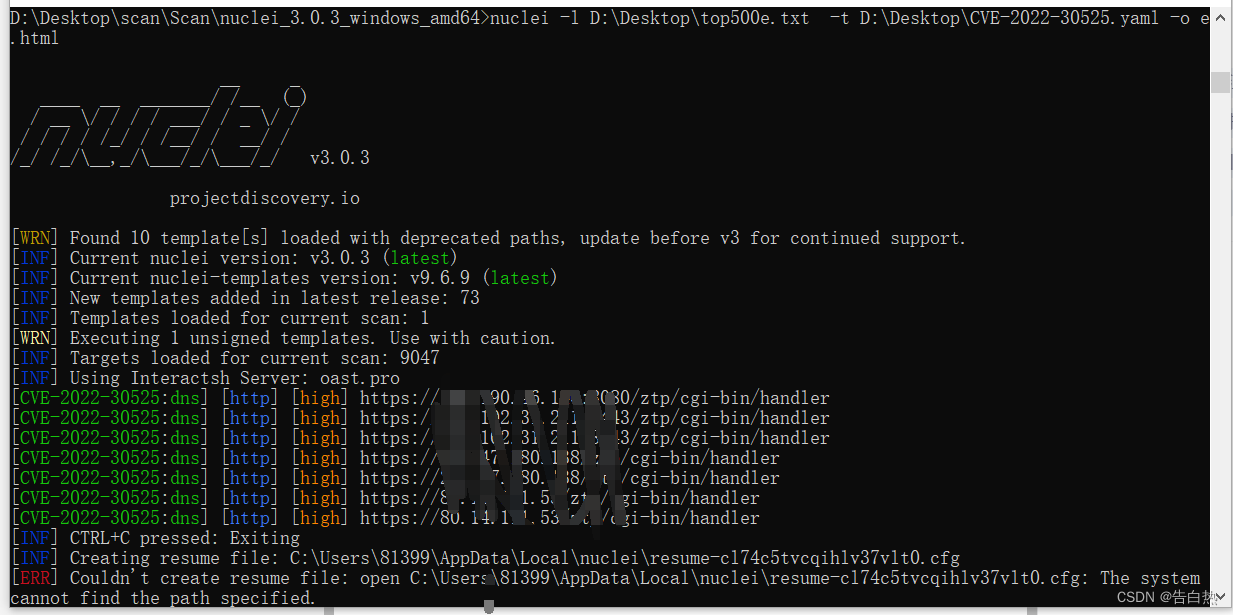
漏洞扫描-nuclei-poc编写
0x00 nuclei Nuclei是一款基于YAML语法模板的开发的定制化快速漏洞扫描器。它使用Go语言开发,具有很强的可配置性、可扩展性和易用性。 提供TCP、DNS、HTTP、FILE 等各类协议的扫描,通过强大且灵活的模板,可以使用Nuclei模拟各种安全检查。 …...

SpringBoot 自动配置
Condition 自定义条件: 定义条件类:自定义类实现Condition接口,重写 matches 方法,在 matches 方法中进行逻辑判断,返回boolean值 。 matches 方法两个参数: context:上下文对象,可…...
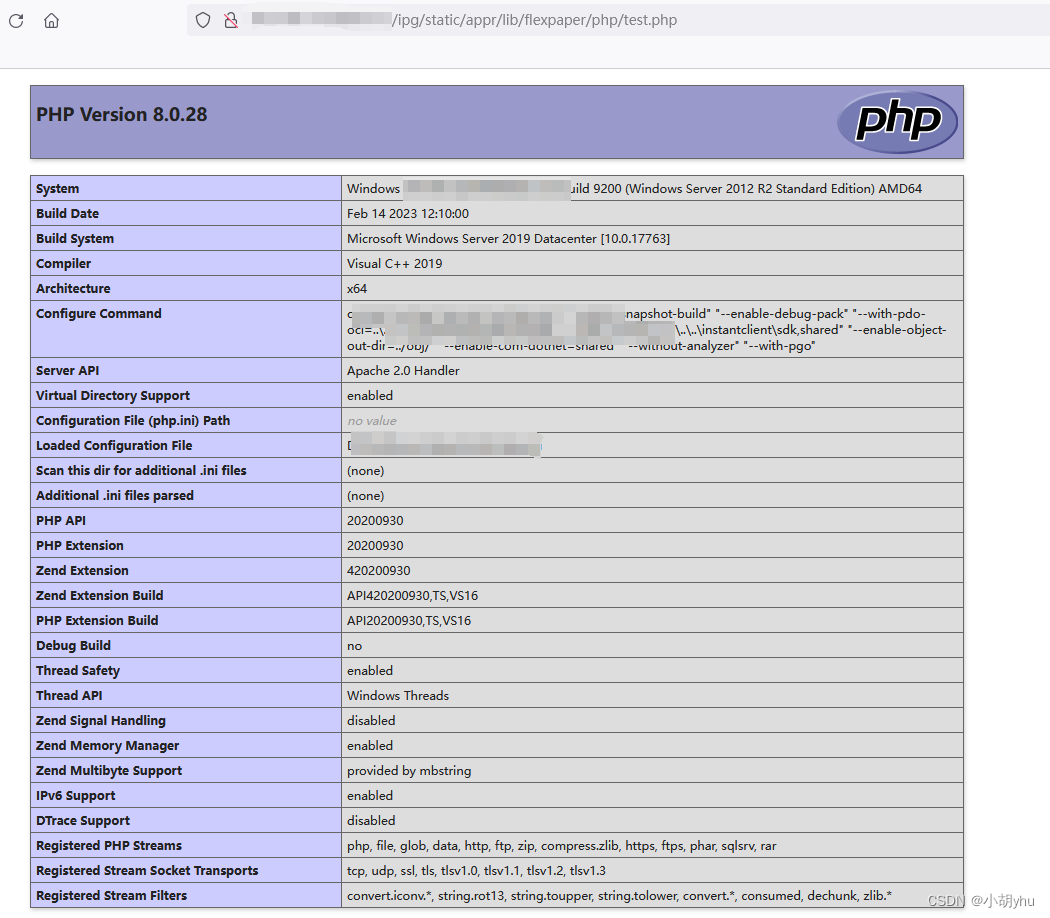
IP-guard WebServer 远程命令执行漏洞
IP-guard WebServer 远程命令执行漏洞 免责声明漏洞描述漏洞影响漏洞危害网络测绘Fofa: app"ip-guard" 漏洞复现1. 构造poc2. 访问文件3. 执行命令 免责声明 仅用于技术交流,目的是向相关安全人员展示漏洞利用方式,以便更好地提高网络安全意识和技术水平。 任何人不…...
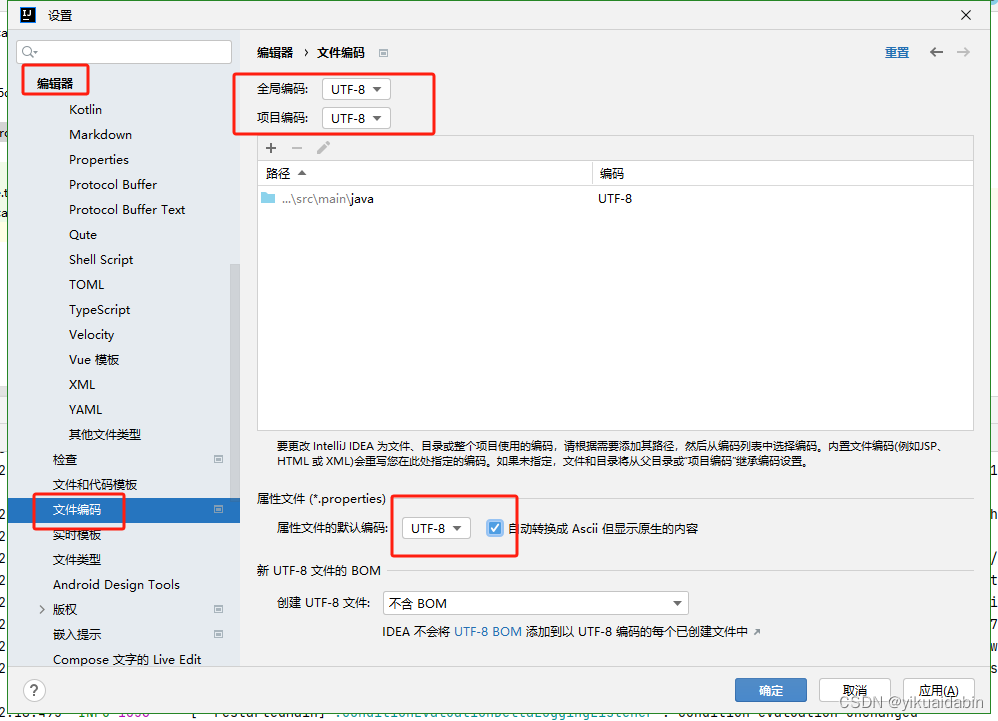
每次重启完IDEA,application.properties文件里的中文变成?
出现这种情况,在IDEA打开Settings-->Editor-->File Encodings 然后,你需要将问号改为你需要的汉字。 重启IDEA,再次查看你的.properties文件就会发现再没有变成问号了...
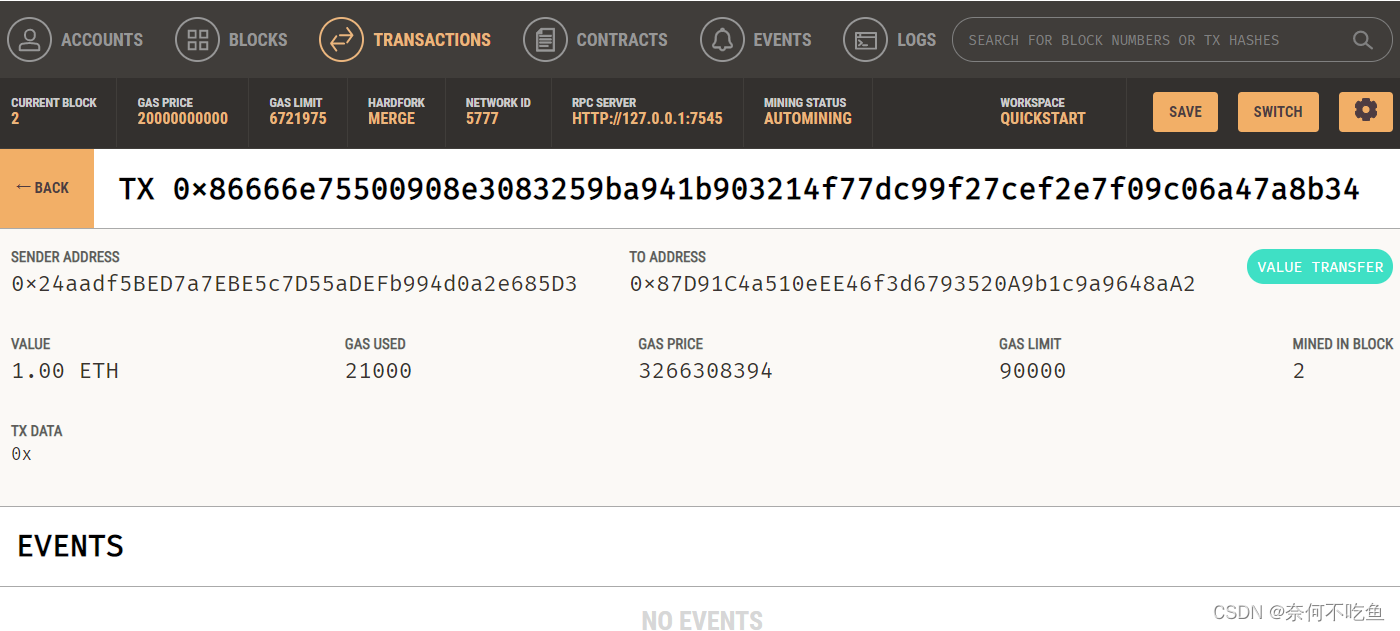
【Truffle】四、通过Ganache部署连接
目录 一、下载安装 Ganache: 二、在本地部署truffle 三、配置ganache连接truffle 四、交易发送 除了用Truffle Develop,还可以选择使用 Ganache, 这是一个桌面应用,他同样会创建一个个人模拟的区块链。 对于刚接触以太坊的同学来说&#x…...
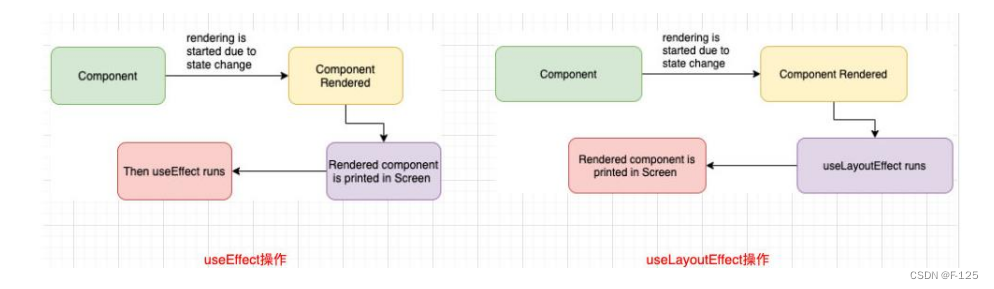
React 其他常用Hooks
1. useImperativeHandle 在react中父组件可以通过forwardRef将ref转发到子组件;子组件拿到父组件创建的ref,绑定到自己的某个元素; forwardRef的做法本身没有什么问题,但是我们是将子组件的DOM直接暴露给了父组件,某下…...
将 ONLYOFFICE 文档编辑器与 С# 群件平台集成
在本文中,我们会向您展示 ONLYOFFICE 文档编辑器与其自有的协作平台集成。 ONLYOFFICE 是一款开源办公套件,包括文本文档、电子表格和演示文稿编辑器。这款套件支持用户通过文档编辑组件扩展第三方 web 应用的功能,可直接在应用的界面中使用。…...

使用电脑时提示msvcp140.dll丢失的5个解决方法
“计算机中msvcp140.dll丢失的5个解决方法”。在我们日常使用电脑的过程中,有时会遇到一些错误提示,其中之一就是“msvcp140.dll丢失”。那么,什么是msvcp140.dll呢?它的作用是什么?丢失它会对电脑产生什么影响呢&…...

VR全景如何应用在房产行业,VR看房有哪些优势
导语: 在如今的数字时代,虚拟现实(VR)技术的迅猛发展为许多行业带来了福音,特别是在房产楼盘行业中。通过利用VR全景技术,开发商和销售人员可以为客户提供沉浸式的楼盘浏览体验,从而带来诸多优…...

11月份 四川汽车托运报价已经上线
中国人不骗中国人!! 国庆小长假的高峰期过后 放假综合症的你还没痊愈吧 今天给大家整理了9条最新线路 广州到四川的托运单价便宜到💥 核算下来不过几毛钱💰 相比起自驾的漫长和疲惫🚗 托运不得不说真的很省事 - 赠送保险 很多客户第一次运车 …...
springcloud图书借阅管理系统源码
开发说明: jdk1.8,mysql5.7,nodejs,idea,nodejs,vscode springcloud springboot mybatis vue elementui 功能介绍: 用户端: 登录注册 首页显示搜索图书,轮播图&…...

主题模型LDA教程:LDA主题数选取:困惑度preplexing
文章目录 LDA主题数困惑度1.概率分布的困惑度2.概率模型的困惑度3.每个分词的困惑度 LDA主题数 LDA作为一种无监督学习方法,类似于k-means聚类算法,需要给定超参数主题数K,但如何评价主题数的优劣并无定论,一般采取人为干预、主题…...

Docker快速入门
Docker是一个用来快速构建、运行和管理应用的工具。 Docker技术能够避免对服务器环境的依赖,减少复杂的部署流程,有了Docker以后,可以实现一键部署,项目的部署如丝般顺滑,大大减少了运维工作量。 即使你对Linux不熟…...
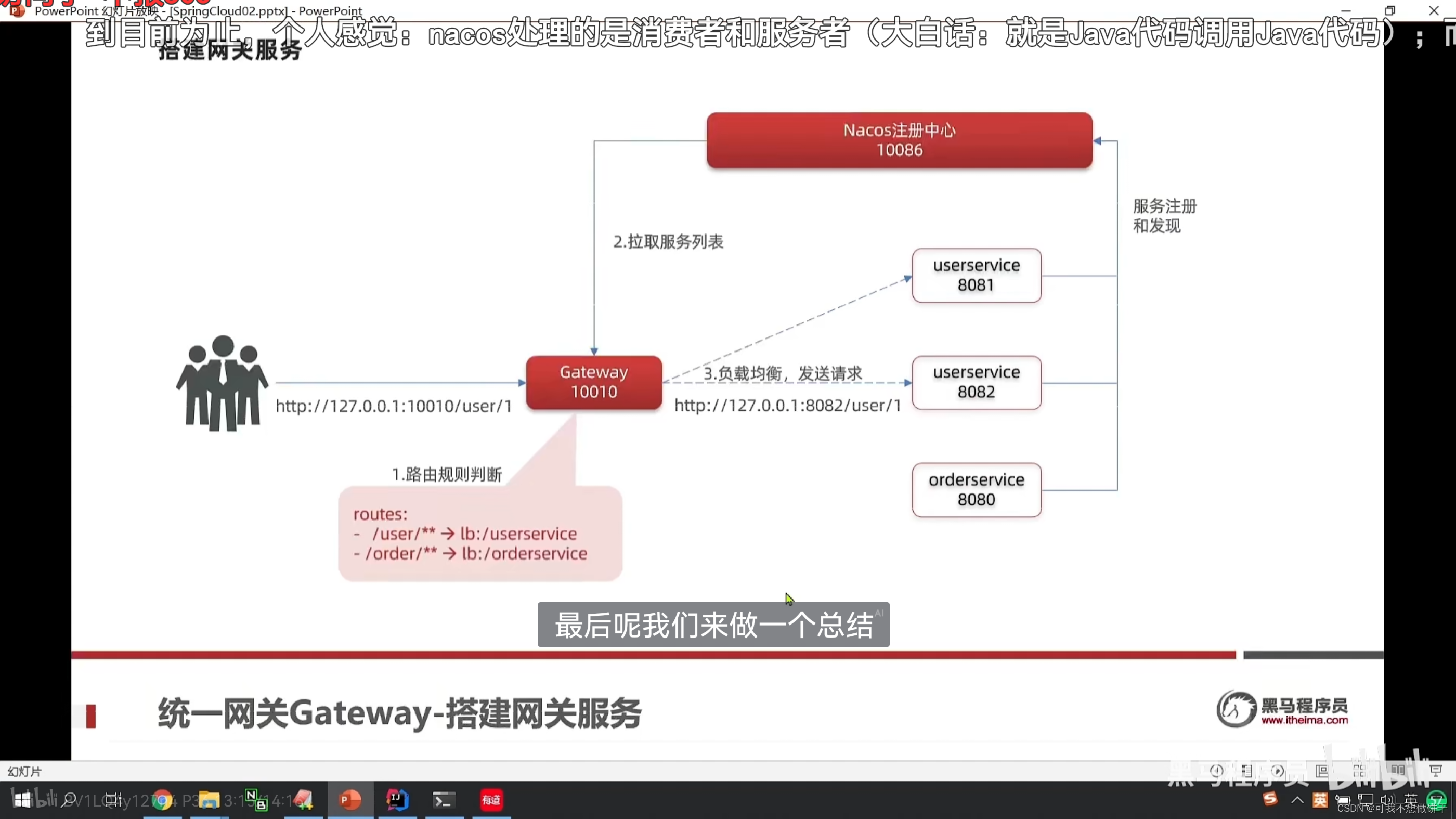
36 Gateway网关 快速入门
3.Gateway服务网关 Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式…...

MyBatis的知识点和简单用法
MyBatis 是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql执…...
转换为点云数据(.pcd文件))
KITTI数据集(.bin数据)转换为点云数据(.pcd文件)
目录 cmake代码 代码 cmake代码 cmake_minimum_required(VERSION 3.17) project(TEST2)set(CMAKE_CXX_STANDARD 14)# Find PCL find_package(PCL 1.8 REQUIRED)# If PCL was found, add its include directories to the project if(PCL_FOUND)include_directories(${PCL_INC…...

【多模态架构避坑指南】:已上线的12个工业级项目中,87%因忽略“模态时序异步性”导致推理延迟飙升300%
第一章:多模态大模型架构设计原理详解 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型的核心目标是实现跨模态语义对齐与联合推理,其架构设计需兼顾异构输入的表征统一性、模态间交互的深度可控性,以及下游任务的泛化适配能力。…...

WaveTools高性能帧率解锁技术解析:突破鸣潮游戏性能瓶颈的完整方案
WaveTools高性能帧率解锁技术解析:突破鸣潮游戏性能瓶颈的完整方案 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools作为一款专为《鸣潮》游戏设计的高性能工具箱,通过动态…...

健康160自动挂号工具终极指南:5分钟掌握全自动抢号技巧
健康160自动挂号工具终极指南:5分钟掌握全自动抢号技巧 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为健康160平台抢号难而烦恼吗?热门医生的号源总是秒光…...

一键解锁蓝奏云高速下载:LanzouAPI直链解析方案深度解析
一键解锁蓝奏云高速下载:LanzouAPI直链解析方案深度解析 【免费下载链接】LanzouAPI 蓝奏云直链,蓝奏api,蓝奏解析,蓝奏云解析API,蓝奏云带密码解析 项目地址: https://gitcode.com/gh_mirrors/la/LanzouAPI 还…...

终极指南:novel-plus安全框架双保险配置,Spring Security与Apache Shiro完美融合
终极指南:novel-plus安全框架双保险配置,Spring Security与Apache Shiro完美融合 【免费下载链接】novel-plus novel-plus 是一个多端(PC、WAP)阅读 、功能完善的小说 CMS 系统。包括小说推荐、小说检索、小说排行、小说阅读、小说…...

终极CrateDB性能监控与调优指南:7个实用工具和技巧
终极CrateDB性能监控与调优指南:7个实用工具和技巧 【免费下载链接】crate CrateDB is a distributed and scalable SQL database for storing and analyzing massive amounts of data in near real-time, even with complex queries. It is PostgreSQL-compatible,…...

wifi热点的防火墙iptables
Chain tetherctrl_FORWARD (1 references)pkts bytes target prot opt in out source destination 94805 59M bw_global_alert all -- * * 0.0.0.0/0 0.0.0.0/0 匹配条件:in* out*&#x…...

如何用MelonLoader实现Unity游戏模组开发的终极跨平台方案
如何用MelonLoader实现Unity游戏模组开发的终极跨平台方案 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 你是否曾为Unity游戏…...

Rust高性能编程:Yi-Coder-1.5B所有权模型解析
Rust高性能编程:Yi-Coder-1.5B所有权模型解析 1. 引言 如果你刚开始学习Rust,可能会被所有权这个概念搞得有点懵。别担心,这很正常。Rust的所有权系统是它最独特的特性,也是保证内存安全的关键所在。今天我们就用Yi-Coder-1.5B这…...

Hermes Agent 工具-周红伟
工具是扩展智能体能力的函数。它们被组织成逻辑上的工具集,可以在每个平台上启用或禁用。Hermes Agent 附带了一个广泛的内置工具注册表,涵盖网页搜索、浏览器自动化、终端执行、文件编辑、记忆、委托、RL 训练、消息投递、Home Assistant 等。可用工具工…...