时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果

官方论文地址->官方论文地址
官方代码地址->官方代码地址
个人修改代码->个人修改的代码已经上传CSDN免费下载
一、本文介绍
本文给大家带来是DLinear模型,DLinear是一种用于时间序列预测(TSF)的简单架构,DLinear的核心思想是将时间序列分解为趋势和剩余序列,并分别使用两个单层线性网络对这两个序列进行建模以进行预测(值得一提的是DLinear的出现是为了挑战Transformer在实现序列预测中有效性)。本文的讲解内容包括:模型原理、数据集介绍、参数讲解、模型训练和预测、结果可视化、训练个人数据集,讲解顺序如下->
预测类型->单元预测、多元预测
适用对象->如果你的配置不是很好这个模型应该很适合你因为参数量很小训练速度很快
二、模型原理
DLinear模型出现是为了调整Transformer的有效性从而存在,Transformer的设计都十分的复杂和需要大量的参数,所以作者提出了一种简单的结构DLinear(参数量我实验过程中确实非常小)。
DLinear的核心思想是将时间序列分解为趋势和剩余序列,并分别使用两个单层线性网络对这两个序列进行建模以进行预测。
具体地,DLinear如何工作的关键点如下:
-
时间序列分解:DLinear将输入的时间序列分解为两部分——趋势部分和剩余部分。这种分解有助于分别处理时间序列中的长期趋势和短期波动。
-
单层线性网络:对于趋势和剩余序列,DLinear分别使用两个单层的线性网络进行建模。这种简单的架构使得DLinear在处理时间序列时既高效又有效。
-
预测任务:在进行预测时,DLinear结合这两个网络的输出来生成最终的时间序列预测。
总结->可以看出DLinear的核心结构真的十分简单就包括一个分解和两个线性网络进行建模最后经过一个简单的相加就输出了结果。
模型的网络结构图如下所示->
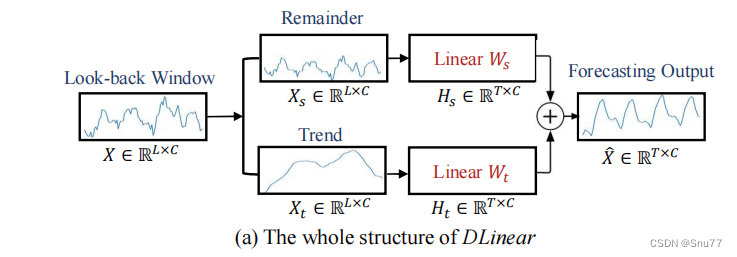
图片分析->可以看到和我们上面讲的一样,数据从输入进来经过两个分支,一个为趋势性一个为剩余序列,然后分别经过一个线性层处理(这里的提到的线性层就是普通的全连接层),然后将结果进行简单的拼接就完成了结果的输出(这就这样的简单模型结果比过程十分复杂的Transformer模型效果要好->我自己实验效果确实要好,我拿2020年的bestpaper和普通的Transformer都进行了对比效果确实要有提升)。
下面的图片是一个简单的线性层(普通的全连接层)提取数据的过程图->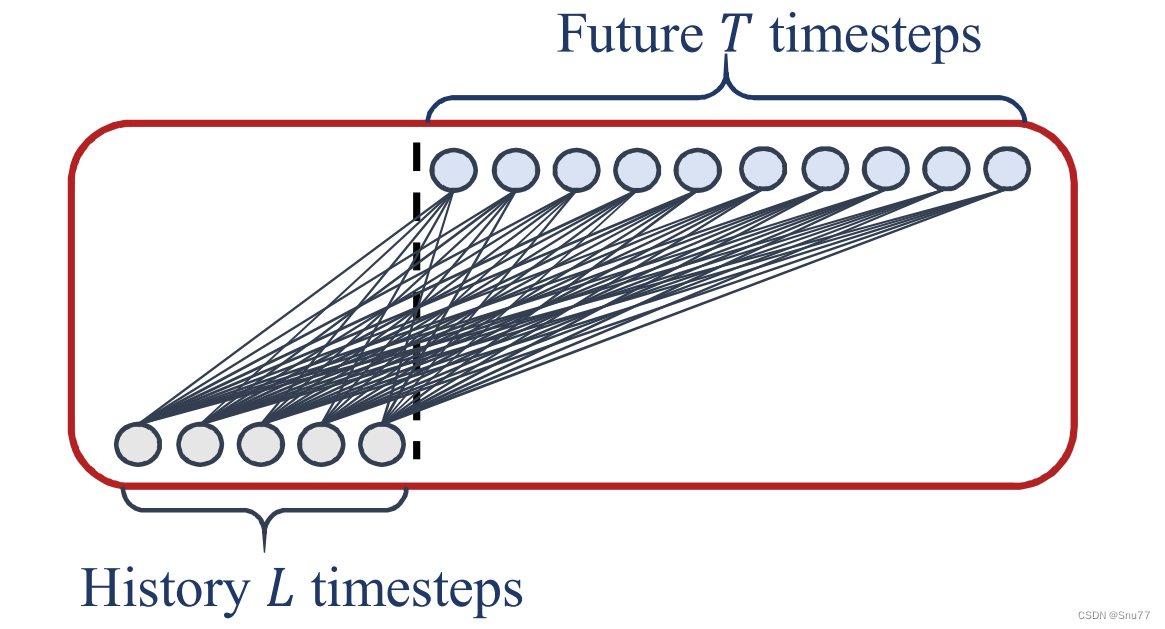
这里把模型的代码结构放出来方便大家根据讲解和代码进行对比。
class moving_avg(nn.Module):"""Moving average block to highlight the trend of time series"""def __init__(self, kernel_size, stride):super(moving_avg, self).__init__()self.kernel_size = kernel_sizeself.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=stride, padding=0)def forward(self, x):# padding on the both ends of time seriesfront = x[:, 0:1, :].repeat(1, (self.kernel_size - 1) // 2, 1)end = x[:, -1:, :].repeat(1, (self.kernel_size - 1) // 2, 1)x = torch.cat([front, x, end], dim=1)x = self.avg(x.permute(0, 2, 1))x = x.permute(0, 2, 1)return xclass series_decomp(nn.Module):"""Series decomposition block"""def __init__(self, kernel_size):super(series_decomp, self).__init__()self.moving_avg = moving_avg(kernel_size, stride=1)def forward(self, x):moving_mean = self.moving_avg(x)res = x - moving_meanreturn res, moving_meanclass Model(nn.Module):"""Decomposition-Linear"""def __init__(self, configs):super(Model, self).__init__()self.seq_len = configs.seq_lenself.pred_len = configs.pred_len# Decompsition Kernel Sizekernel_size = 25self.decompsition = series_decomp(kernel_size)self.individual = configs.individualself.channels = configs.enc_inif self.individual:self.Linear_Seasonal = nn.ModuleList()self.Linear_Trend = nn.ModuleList()for i in range(self.channels):self.Linear_Seasonal.append(nn.Linear(self.seq_len,self.pred_len))self.Linear_Trend.append(nn.Linear(self.seq_len,self.pred_len))# Use this two lines if you want to visualize the weights# self.Linear_Seasonal[i].weight = nn.Parameter((1/self.seq_len)*torch.ones([self.pred_len,self.seq_len]))# self.Linear_Trend[i].weight = nn.Parameter((1/self.seq_len)*torch.ones([self.pred_len,self.seq_len]))else:self.Linear_Seasonal = nn.Linear(self.seq_len,self.pred_len)self.Linear_Trend = nn.Linear(self.seq_len,self.pred_len)# Use this two lines if you want to visualize the weights# self.Linear_Seasonal.weight = nn.Parameter((1/self.seq_len)*torch.ones([self.pred_len,self.seq_len]))# self.Linear_Trend.weight = nn.Parameter((1/self.seq_len)*torch.ones([self.pred_len,self.seq_len]))def forward(self, x):# x: [Batch, Input length, Channel]seasonal_init, trend_init = self.decompsition(x)seasonal_init, trend_init = seasonal_init.permute(0,2,1), trend_init.permute(0,2,1)if self.individual:seasonal_output = torch.zeros([seasonal_init.size(0),seasonal_init.size(1),self.pred_len],dtype=seasonal_init.dtype).to(seasonal_init.device)trend_output = torch.zeros([trend_init.size(0),trend_init.size(1),self.pred_len],dtype=trend_init.dtype).to(trend_init.device)for i in range(self.channels):seasonal_output[:,i,:] = self.Linear_Seasonal[i](seasonal_init[:,i,:])trend_output[:,i,:] = self.Linear_Trend[i](trend_init[:,i,:])else:seasonal_output = self.Linear_Seasonal(seasonal_init)trend_output = self.Linear_Trend(trend_init)x = seasonal_output + trend_outputreturn x.permute(0,2,1) # to [Batch, Output length, Channel]
我看论文的内容大比分都是对比实验,因为DLinear的产生就是为了质疑Transformer所以他和各种Transformer的模型进行对比试验,因为本篇文章就是DLinear的实战案例,对比的部分我就不讲了,大家有兴趣可以看看论文内容在最上面我已经提供了链接。
三、数据集介绍
所用到的数据集为某公司的业务水平评估和其它参数具体的内容我就介绍了估计大家都是想用自己的数据进行训练模型,这里展示部分图片给大家提供参考。
四、参数讲解
模型的参数如下(大部分都是一些公共参数并不涉及模型)->
parser = argparse.ArgumentParser(description='DLinearNet Multivariate Time Series Forecasting')# basic configparser.add_argument('--train', type=bool, default=True, help='Whether to conduct training')parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')parser.add_argument('--show_results', type=bool, default=True, help='Whether show forecast and real results graph')parser.add_argument('--model', type=str, default='SCINet',help='Model name')# data loaderparser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')parser.add_argument('--features', type=str, default='MS',help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')parser.add_argument('--freq', type=str, default='h',help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')parser.add_argument('--checkpoints', type=str, default='./models/', help='location of model models')# forecasting taskparser.add_argument('--seq_len', type=int, default=126, help='input sequence length')parser.add_argument('--label_len', type=int, default=64, help='start token length')parser.add_argument('--pred_len', type=int, default=4, help='prediction sequence length')# modelparser.add_argument('--individual', action='store_true', default=False,help='DLinear: a linear layer for each variate(channel) individually')parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')parser.add_argument('--c_out', type=int, default=1, help='output size')parser.add_argument('--dropout', type=float, default=0.05, help='dropout')parser.add_argument('--embed', type=str, default='timeF',help='time features encoding, options:[timeF, fixed, learned]')parser.add_argument('--activation', type=str, default='gelu', help='activation')# optimizationparser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')parser.add_argument('--train_epochs', type=int, default=10, help='train epochs')parser.add_argument('--batch_size', type=int, default=16, help='batch size of train input data')parser.add_argument('--learning_rate', type=float, default=0.001, help='optimizer learning rate')parser.add_argument('--loss', type=str, default='mse', help='loss function')parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')# GPUparser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')parser.add_argument('--device', type=int, default=0, help='gpu')模型的详细参数讲解如下(如果你想训练你自己的数据集可以仔细看看)->
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 0 | train | bool | 是否进行训练,如果你单纯只想进行预测设置为False即可, |
| 1 | rollingforecast | bool | 是否进行滚动预测,如果是则设置为True,如果不进行滚动预测则进行正常的预测 |
| 2 | rolling-data-path | str | 如果进行滚动预测则需要添加新的和训练文件相同格式的数据 |
| 3 | show_results | bool | 是否保存预测值和真实值的对比 |
| 4 | model | str | 定义的模型名称 |
| 5 | root_path | str | 这个才是你文件的路径,不要到具体的文件,到目录级别即可。 |
| 6 | data_path | str | 这个填写你文件的具体名称。 |
| 7 | features | str | 这个是特征有三个选项M,MS,S。分别是多元预测多元,多元预测单元,单元预测单元。 |
| 8 | target | str | 这个是你数据集中你想要预测那一列数据,假设我预测的是油温OT列就输入OT即可。 |
| 9 | freq | str | 时间的间隔,你数据集每一条数据之间的时间间隔。 |
| 10 | checkpoints | str | 训练出来的模型保存路径 |
| 11 | seq_len | int | 用过去的多少条数据来预测未来的数据 |
| 12 | label_len | int | 可以理解为更高的权重占比的部分要小于seq_len |
| 13 | pred_len | int | 预测未来多少个时间点的数据 |
| 14 | enc_in | int | 你数据有多少列,要减去时间那一列,这里我是输入8列数据但是有一列是时间所以就填写7 |
| 15 | dec_in | int | 同上 |
| 16 | individual | bool | 这个就是我们上面提到的两个线性层,如果为True我们则对每一个通道用单独的线性层处理,False则为所有的通道用一个线性层 |
| 17 | c_out | int | 这里有一些不同如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据。 |
| 18 | dropout | float | 这个应该都理解不说了,丢弃的概率,防止过拟合的。 |
| 19 | embed | str | 时间特征的编码方式,默认为"timeF" |
| 20 | activation | str | 激活函数 |
| 21 | num_workers | int | 线程windows大家最好设置成0否则会报线程错误,linux系统随便设置。 |
| 22 | train_epochs | int | 训练的次数 |
| 23 | batch_size | int | 一次往模型力输入多少条数据 |
| 24 | learning_rate | float | 学习率。 |
| 25 | loss | str | 损失函数,默认为"mse" |
| 26 | lradj | str | 学习率的调整方式,默认为"type1" |
| 27 | use_gpu | bool | 是否使用GPU训练,根据自身来选择 |
| 28 | gpu | int | GPU的编号 |
五、模型训练和预测
1.项目目录结构
项目的目录构造如下->
其中data为训练用的数据放的地方,layers为模型结构存放的地方,models为训练保存的训练模型,results为可视化结果保存的图片和滚动预测的结果,util为一些工具。
2.模型训练
当我们经过上面的参数讲解之后,我们可以开始训练模型了,控制台输出如下->

3.滚动预测
这里进行滚动预测的控制台输出->
4.结果展示
运行结果后,结果保存到同级目录下(下图为预测值和真实值的对比)->
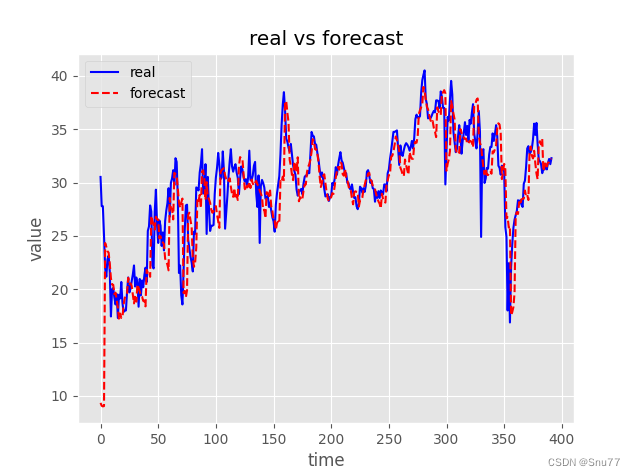
5.结果分析
可以看到预测值和真实值之间的差距还可以,但是这个模型的参数量少得可怜,不得不得质疑Transformer模型的有效性~
六、训练你个人数据集
这个模型我在写的过程中为了节省大家训练自己数据集,我基本上把大部分的参数都写好了,需要大家注意的就是如果要进行滚动预测下面的参数要设置为True。
parser.add_argument('--rollingforecast', type=bool, default=True, help='rolling forecast True or False')如果上面的参数设置为True那么下面就要提供一个进行滚动预测的数据集,该数据集的格式要和你训练模型的数据集格式完全一致(重要!!!),如果没有可以考虑在自己数据的尾部剪切一部分,不要粘贴否则数据模型已经训练过了的话预测就没有效果了。
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='rolling data file')其它的没什么可以讲的了大部分的修改操作在参数讲解的部分我都详细讲过了,这里的滚动预测可能是大家想看的所以摘出来详细讲讲。
总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。
概念理解
15种时间序列预测方法总结(包含多种方法代码实现)
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测

相关文章:
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
官方论文地址->官方论文地址 官方代码地址->官方代码地址 个人修改代码->个人修改的代码已经上传CSDN免费下载 一、本文介绍 本文给大家带来是DLinear模型,DLinear是一种用于时间序列预测(TSF)的简单架构,DLinear的核…...
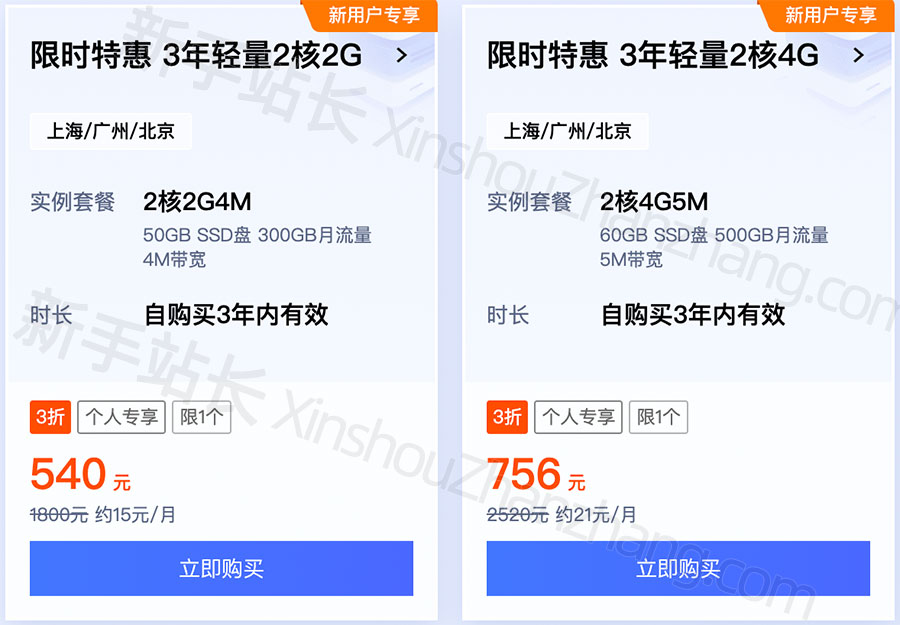
封神教程:腾讯云3年轻量应用服务器老用户购买方法
腾讯云轻量应用服务器特价是有新用户限制的,所以阿腾云建议大家选择3年期轻量应用服务器,一劳永逸,免去续费困扰。腾讯云轻量应用服务器3年优惠可以选择2核2G4M和2核4G5M带宽,3年轻量2核2G4M服务器540元,2核4G5M轻量应…...
 安装最新版的 cmake)
Ubuntu(WSL2) 安装最新版的 cmake
Ubuntu(WSL) 安装最新版的 cmake 具体流程如下: 步骤一:卸载原本的 cmake sudo apt-get remove cmake 步骤二: sudo apt-get update sudo apt-get install apt-transport-https ca-certificates gnupg software-properties-common wget 步…...
Android---内存泄漏的优化
内存泄漏是一个隐形炸弹,其本身并不会造成程序异常,但是随着量的增长会导致其他各种并发症:OOM,UI 卡顿等。 为什么要将 Activity 单独做预防? 因为 Activity 承担了与用户交互的职责,因此内部需要持有大…...
)
C/S架构学习之基于UDP的本地通信(客户机)
基于UDP的本地通信(客户机):创建流程:一、创建数据报式套接字(socket函数): int sock_fd socket(AF_UNIX,SOCK_DGRAM,0);if(-1 sock_fd){perror("socket error");exit(-1);}二、创建…...
【性能测试】服务端中间件docker常用命令解析整理(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、搜索 docker …...

【探索Linux】—— 强大的命令行工具 P.14(进程间通信 | 匿名管道 | |进程池 | pipe() 函数 | mkfifo() 函数)
阅读导航 引言一、进程间通信概念二、进程间通信目的三、进程间通信分类四、管道1. 什么是管道2. 匿名管道(1)创建和关闭⭕pipe() 函数⭕创建匿名管道⭕关闭匿名管道 (2)通信方式(3)用法示例(4&…...
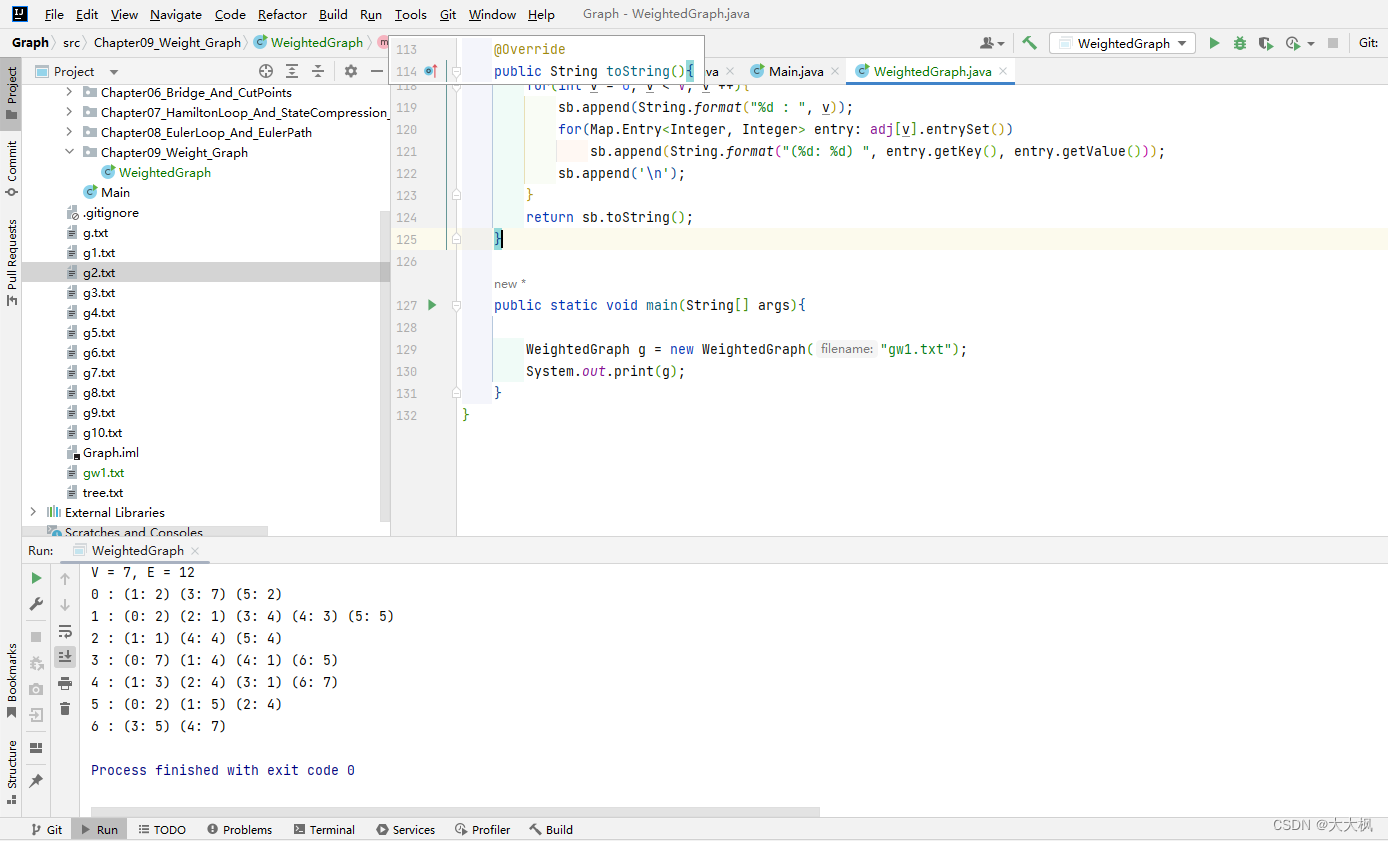
图论12-无向带权图及实现
文章目录 带权图1.1带权图的实现1.2 完整代码 带权图 1.1带权图的实现 在无向无权图的基础上,增加边的权。 使用TreeMap存储边的权重。 遍历输入文件,创建TreeMap adj存储每个节点。每个输入的adj节点链接新的TreeMap,存储相邻的边和权重 …...
----数组--有序数组的平方)
每日一题(LeetCode)----数组--有序数组的平方
每日一题(LeetCode)----数组–有序数组的平方 1.题目([977. 有序数组的平方](https://leetcode.cn/problems/sqrtx/)) 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。…...

SpringCloud微服务:Eureka
目录 提供者与消费者 服务调用关系 eureka的作用 在Eureka架构中,微服务角色有两类 Eureka服务 提供者与消费者 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)服务消费者:一次业务中,调用其它微服务的服务。(调…...

19.删除链表的倒数第N个结点(LeetCode)
想法一 先用tail指针找尾,计算出节点个数,再根据倒数第N个指定删除 想法二 根据进阶的要求,只能遍历一遍链表,那刚刚想法一就做不到 首先,我们要在一遍内找到倒数第N个节点,所以我们设置slow和fast两个指…...

PyTorch技术和深度学习——三、深度学习快速入门
文章目录 1.线性回归1)介绍2)加载自由泳冠军数据集3)从0开始实现线性回归模型4)使用自动求导训练线性回归模型5)使用优化器训练线性回归模型 2.使用torch.nn模块构建线性回归模型1)使用torch.nn.Linear训练…...

360导航恶意修改浏览器启动页!我的chrome和IE均中招,如何解决?
0,关闭360等“安全”软件 1,按下组合键winR 2,输入regedit,回车 3,按下组合键ctrlF 4,输入http://hao.360.cn,查找下一个 5,查到一个注册表键值就删一个,一个不放过…...
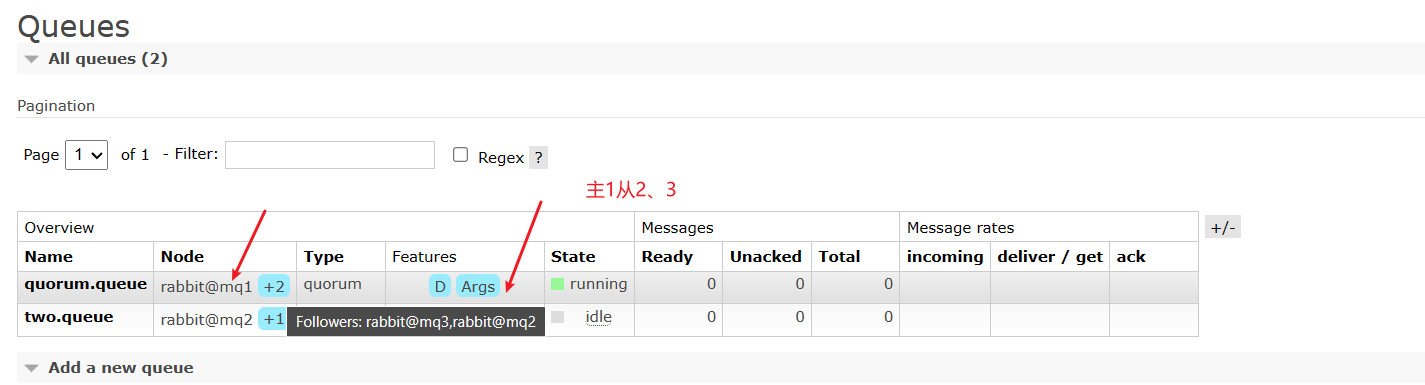
RabbitMQ的高级特性
目录 数据导入 MQ的常见问题 消息可靠性问题 生产者确认机制 SpringAMQP实现生产者确认 消息持久化 消费者消息确认 失败重试机制 消费者失败消息处理策略 死信交换机 TTL 延时队列 安装插件 SpringAMQP使用插件 消息堆积问题 惰性队列 MQ的高可用 普通集群 …...
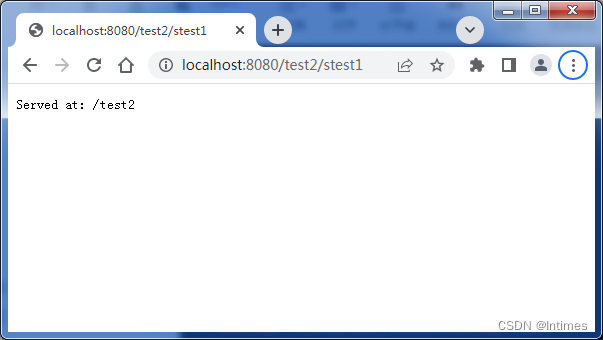
Java自学第10课:JavaBean和servlet基础
目录 目录 1 JavaBean (1)概念 (2)分类 (3)使用 2 servlet (1)代码结构 (2)常用接口 (3)如何开发 1 新建servlet 2 配置 1…...

AR打卡小程序:构建智能办公的新可能
【内容摘要】 随着技术的飞速发展,智能办公已不再是遥不可及的梦想。在这其中,AR打卡小程序以其独特的技术优势,正逐步成为新型办公生态的重要组成部分。本文将探讨AR打卡小程序的设计理念、技术实现以及未来的应用前景,并尝试深…...
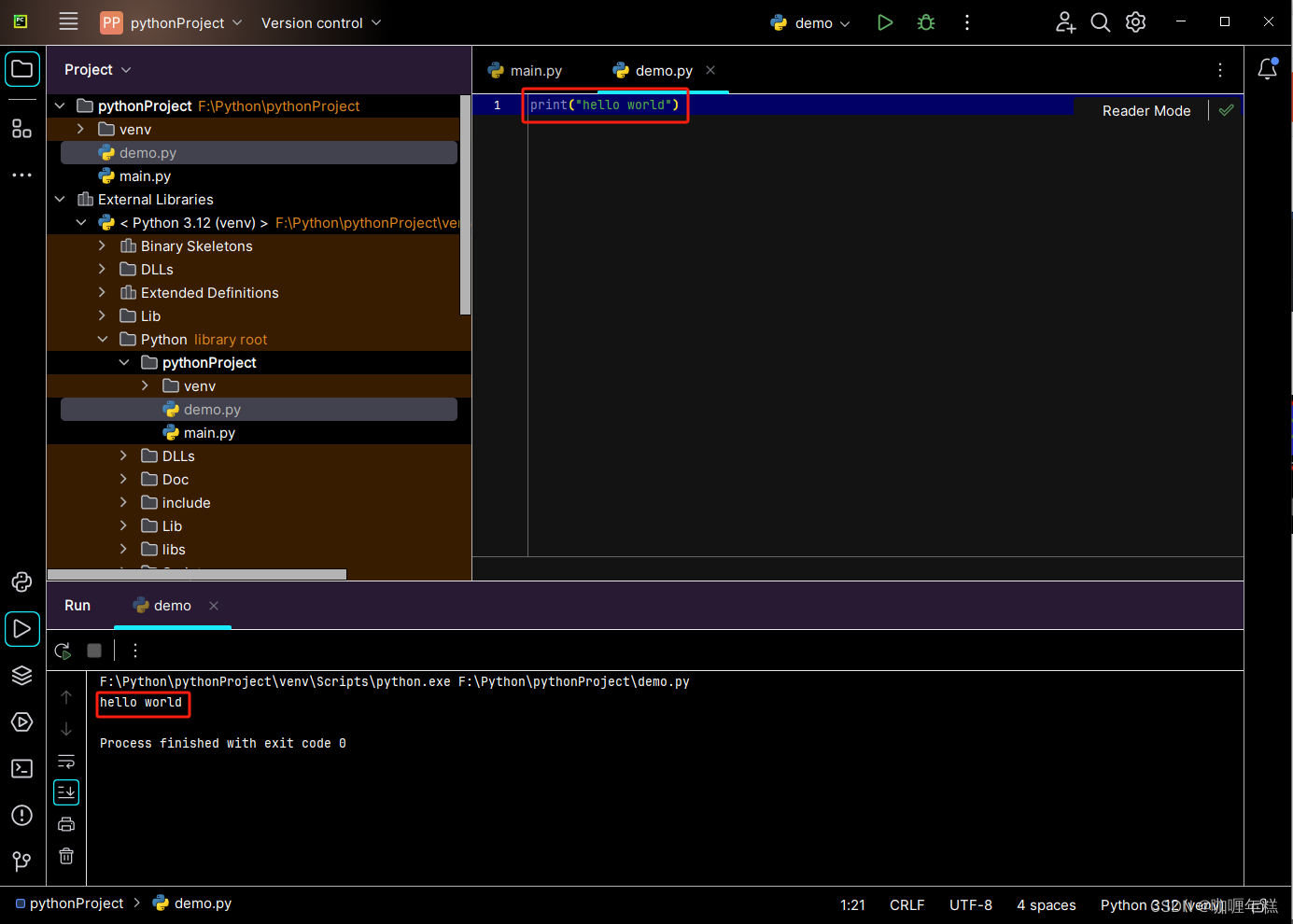
Python环境安装、Pycharm开发工具安装(IDE)
Python下载 Python官网 Python安装 Python安装成功 Pycharm集成开发工具下载(IDE) PC集成开发工具 Pycharm集成开发工具安装(IDE) 安装完成 添加环境变量(前面勾选了Path不用配置) (1&…...
报时机器人的rasa shell执行流程分析
本文以报时机器人为载体,介绍了报时机器人的对话能力范围、配置文件功能和训练和运行命令,重点介绍了rasa shell命令启动后的程序执行过程。 一.报时机器人项目结构 1.对话能力范围 (1)能够识别欢迎语意图(greet)和拜拜意图(goodbye) (2)能够识别时间意…...
)
C#开发的OpenRA游戏之世界存在的属性UpdatesPlayerStatistics(2)
C#开发的OpenRA游戏之世界存在的属性UpdatesPlayerStatistics(2) 在文件OpenRA\mods\cnc\rules\ defaults.yaml里,可以看到这个配置,它的作用就是让这个单元可以被观察者查看到相关的信息。 UpdatesPlayerStatistics属性同样也是有两个类组成,一个叫做信息类UpdatesPlay…...
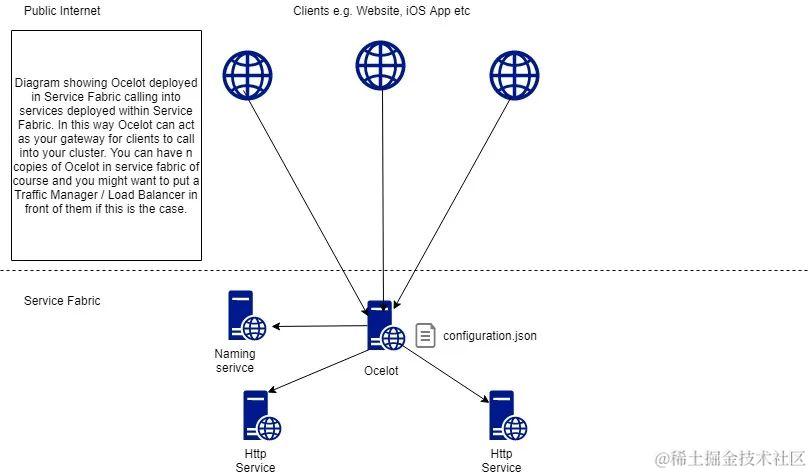
Ocelot:.NET开源API网关提供路由管理、服务发现、鉴权限流等功能
随着微服务的兴起,API网关越来越常见。API网关是连接应用程序和用户之间的桥梁,就像一个交通指挥员,负责处理所有进出应用的数据和请求,确保安全、高效、有序地流通。 今天给大家推荐一个.NET开源API网关。 01 项目简介 Ocelot…...
Transformer视觉模型进化论:从DETR到DINO-X的技术路线图(附性能对比表)
Transformer视觉模型进化论:从DETR到DINO-X的技术路线图 计算机视觉领域正在经历一场由Transformer架构引领的革命。从最初的DETR开始,基于Transformer的目标检测模型通过一系列创新不断突破性能边界。本文将深入剖析这一技术演进路径,揭示关…...

如何优化SQL视图执行计划_强制转换与索引提示应用
CONVERT 和 CAST 在 WHERE 条件中对索引列进行类型转换会导致索引失效,引发 Table Scan 或 Index Scan;应避免在列上转换,改为在参数侧转换或使用范围查询。SQL Server 中 CONVERT 和 CAST 导致索引失效的典型表现视图查询突然变慢࿰…...
)
AIAgent状态机设计实战手册(从单体FSM到分布式Saga-State双模引擎)
第一章:AIAgent状态机设计概览 2026奇点智能技术大会(https://ml-summit.org) AI Agent 的行为稳定性与任务可追溯性高度依赖于其底层状态管理机制。状态机设计为 AI Agent 提供了清晰的生命周期边界、确定性的状态迁移路径以及可观测的执行上下文,是构…...

ESP32-S3单片机入门:点灯
硬件准备 所需硬件:ESP32-S3开发板、LED、电阻、杜邦线、面包板、USB线(可传输数据) 了解硬件 ESP32-S3开发板 ESP32-S3 技术规格书 | 乐鑫科技文档 LED 电阻 作用:把电能转化为热能或其它形式的能量࿰…...

【C++第三十章】线程库
前言 🚀C11 的线程库并不只是“把系统线程 API 换了个写法”,而是在标准库层面,给并发编程提供了一套更统一、更可移植的抽象:线程怎么创建,如何等待结束,如何保护共享资源,线程之间怎么同步通知…...

如何三步搞定macOS安装包下载:Download Full Installer终极指南
如何三步搞定macOS安装包下载:Download Full Installer终极指南 【免费下载链接】DownloadFullInstaller macOS application written in SwiftUI that downloads installer pkgs for the Install macOS Big Sur application. 项目地址: https://gitcode.com/gh_mi…...

第一篇java代码
第一篇java代码 初次接触java,令我印象最深的是# 我写的第一行 Java 代码,不只是 “Hello World”大一新生,刚学 Java几周,尚无大的突破, 可我记得我第一次接触java代码时的思考。所以我将我最初的思考记录,并由此作为…...

Mem Reduct内存管理工具:轻量级实时监控与优化技术深度解析
Mem Reduct内存管理工具:轻量级实时监控与优化技术深度解析 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct …...

玻璃的前世今生,了解一下?
玻璃的前世今生,了解一下? 玻璃的前世今生 改革开放40年,我国基础建设飞速发展。一栋栋高耸入云端的摩天大楼,一片片一望无边的居民住宅,房地产行业为我国的GDP画上了浓墨重彩的一笔。毫无疑问,为建筑物穿上漂亮外衣的玻璃行业也是突飞猛进,为我们建筑表皮的安全节能美…...

Folcolor:终极Windows文件夹色彩管理完整指南,让文件管理效率提升300%
Folcolor:终极Windows文件夹色彩管理完整指南,让文件管理效率提升300% 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 在Windows系统中管理大量文件夹时,…...