数据分析实战 | KNN算法——病例自动诊断分析
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
八、模型评价
九、模型调参
十、模型改进
十一、模型预测
一、数据及分析对象
CSV文件——“bc_data.csv”
数据集链接:https://download.csdn.net/download/m0_70452407/88524905
该数据集主要记录了569个病例的32个属性,主要属性/字段如下:
(1)ID:病例的ID。
(2)Diagnosis(诊断结果):M为恶性,B为良性。该数据集共包含357个良性病例和212个恶性病例。
(3)细胞核的10个特征值,包括radius(半径)、texture(纹理)、perimeter(周长)、面积(area)、平滑度(smoothness)、紧凑度(compactness)、凹面(concavity)、凹点(concave points)、对称性(symmetry)和分形维数(fractal dimension)等。同时,为上述10个特征值分别提供了3种统计量,分别为均值(mean)、标准差(standard error)和最大值(worst or largest)。
二、目的及分析任务
理解机器学习方法在数据分析中的应用——KNN方法进行分类分析。
(1)样本为训练集进行有监督学习,并预测——“诊断结果(diagnosis)”。
(2)以剩余记录为测试集,进行KNN建模。
(3)按KNN模型预测测试集的dignosis类型。
(4)按KNN模型给出的diagnosis“预测类型”与数据集bc_data.csv自带的“实际类型”进行对比分析,验证KNN建模的有效性。
三、方法及工具
Python语言及scikit-learn包
四、数据读入
import pandas as pd
bc_data=pd.read_csv("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第4章 分类分析\\bc_data.csv",header=0)
bc_data.head()
五、数据理解
对数据框bc_data进行探索性分析,这里采用的实现方法为调用pandas包中数据框(DataFrame)的describe()方法。
bc_data.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
bc_data.shape(569, 32)
六、数据准备
在数据框bc_data中,对于乳腺癌诊断分析有用的数据为细胞核的10个特征值,为了将该数据值提取出来,需要在数据框bc_data的基础上删除列名为“id”和“diagnosis”的数据,删除后的数据框命名为“data”,实现方式为调用数据框的drop()方法,并使用该包的head()方法观察数据情况。
data=bc_data.drop(['id'],axis=1)
X_data=data.drop(['diagnosis'],axis=1)
X_data.head()
接着,调用NumPy的ravel()方法对数据框data中命名为“diagnosis”的列信息以视图形式(view)返回,并以一维数组形式输出。
import numpy as np
y_data=np.ravel(data[['diagnosis']])
y_data[0:6]array(['M', 'M', 'M', 'M', 'M', 'M'], dtype=object)
为了实现基于KNN算法乳腺癌自动诊断的目标,先将data数据框信息随机分为训练集和测试集两部分。采用的实现方式为调用scikit-learn包中model_selection模块的train_test_split()方法,设定训练集数据容量占总数居的75%,剩下的为测试集数据,调用pandas包中数据框(DataFrame)的describe()方法。
from sklearn.model_selection import train_test_split
X_trainingSet,X_testSet,y_trainingSet,y_testSet=train_test_split(X_data,y_data,random_state=1,test_size=0.25)
X_trainingSet.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
X_trainingSet.shape(426, 30)
同时,对测试集数据框也对其做相同的处理。
X_testSet.describe()
X_testSet.shape(143, 30)
对训练集数据进行“学习训练”后,自动获取它的均值和方差,再分别对训练集和测试集进行“归一化”处理。采用的实现方式为调用scikit-learn包中的preprocessing模块的StandardScaler()方法。其中,训练集数据的归一化处理如下:
from sklearn.preprocessing import StandardScaler
means_normalization=StandardScaler() #均值归一化处理
means_normalization.fit(X_trainingSet) #进行训练集的“诊断学习”,得到均值和方差
X_train_normalization=means_normalization.transform(X_trainingSet)X_train_normalizationarray([[ 0.30575375, 2.59521918, 0.46246107, ..., 1.81549702,2.10164609, 3.38609913],[ 0.23351721, -0.05334893, 0.20573083, ..., 0.5143837 ,0.14721854, 0.05182385],[ 0.15572401, 0.18345881, 0.11343692, ..., 0.69446859,0.263409 , -0.10011179],...,[ 0.85586279, 1.19276558, 0.89773369, ..., 1.12967374,0.75591781, 2.97065009],[-0.02486734, 0.44095848, -0.08606303, ..., -0.52515632,-1.1291423 , -0.45561747],[-0.30270019, -0.20968802, -0.37543871, ..., -0.967865 ,-1.54361274, -1.31500348]])
对测试集数据也采用相同的方式进行归一化处理。
X_test_normalization=means_normalization.transform(X_testSet)
X_test_normalizationarray([[ 0.15850234, -1.23049032, 0.25369143, ..., -0.05738582,-0.08689656, 0.48863884],[-0.2638036 , -0.15450952, -0.23961754, ..., 1.41330744,1.77388495, 2.02105229],[-0.32492682, -0.76147305, -0.35407811, ..., -0.1354226 ,0.87210827, 0.71179432],...,[ 0.25852216, -0.06024625, 0.21500053, ..., -0.03937733,-1.03202789, -0.84910706],[ 1.46709506, 0.95825694, 1.49824869, ..., 0.62693676,0.07438274, -0.45739797],[-0.61942964, 0.42256565, -0.6261235 , ..., -0.48013509,0.34318156, -0.6134881 ]])
七、模型训练
训练集进行学习概念“诊断结果”,利用测试集进行KNN建模。通过对训练和测试数据进行适当的处理后,接下来进行模型参数的确定。KNN模型类别有暴力法、KD树和球树。暴力法适用于数据较少的形式,而KD树在较多的数据中更有优势,考虑到算法效率问题,结合本项目中数据框的数据量,选择KD树进行建模,首先取得KNN分类器,并使用内置参数调整KNN三要素。
这里采用的模型训练实现方式为scikit-learn包中的neighbors模块的KNeighborsClassifier()方法,其中对于设置的各项参数解释如下:
(1)algorithm表示快速k近邻搜索算法,这里确定的算法模型为KD树。
(2)leaf_size是构造KD树的大小,默认为30。
(3)metric用于距离度量,默认度量是minkowski。
(4)metric_params表示距离公式的其他关键参数,并不是很重要,使用默认的None。
(5)n_jobs是并行处理设置,使用默认的None。
(6)n_neighbors表示初始设定的近邻树,即KNN算法中的k值。
(7)p代表距离度量公式,其中1为哈曼顿距离公式,2为欧氏距离公式,这里使用欧氏距离公式进行距离度量,将p值设置为2。
(8)weights表权重,默认为uniform(均等权重)。
接着,利用训练函数fit()和预测函数predict()实现对训练集已知数据和测试集数据的对比输出。
from sklearn.neighbors import KNeighborsClassifier
myModel=KNeighborsClassifier(algorithm="kd_tree",leaf_size=30,metric="minkowski",metric_params=None,n_jobs=None,n_neighbors=5,p=2,weights="uniform")
myModel.fit(X_trainingSet,y_trainingSet)
y_predictSet=myModel.predict(X_testSet)fit()函数数据训练结果如下:
y_testSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'M', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'M','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'B', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
用predict()函数进行预测的结果如下:
y_predictSetarray(['M', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'M', 'B', 'B', 'M', 'M', 'B'],dtype=object)
最后,使用get_params()方法实现对模型各参数的查询:
myModel.get_params(){'algorithm': 'kd_tree','leaf_size': 30,'metric': 'minkowski','metric_params': None,'n_jobs': None,'n_neighbors': 5,'p': 2,'weights': 'uniform'}
由上述输出结果可以看出,使用get_params()方法查询参数是以字典结构的形式展现,并且可以看到参数结果与之前设置保持一致。
八、模型评价
为了评价所建立模型的性能,采用“预测准确率(Accuracy Score)”参数,具体实现方式是调用scikit-learn包的metrics模块的accuracy_score()方法。
from sklearn.metrics import accuracy_score
accuracy_score(y_testSet,y_predictSet)0.9370629370629371
通过结果输出可知,模型预测结果的准确率约为93.71%,可以考虑尝试进一步优化。
九、模型调参
通过前面分析可知,k值的大小对模型预测结果会产生很多的影响。为此,接下来利用准确率函数score()来实现k值范围在1~22的准确率值计算。
import matplotlib.pyplot as plt
NumberOfNeighbors=range(1,23)
KNNs=[KNeighborsClassifier(n_neighbors=i) for i in NumberOfNeighbors]
range(len(KNNs))
scores=[KNNs[i].fit(X_trainingSet,y_trainingSet).score(X_testSet,y_testSet) for i in range(0,22)]
plt.plot(NumberOfNeighbors,scores)
plt.title("Elbow Curve")
plt.xlabel("Number of Neighbors")
plt.ylabel("Score")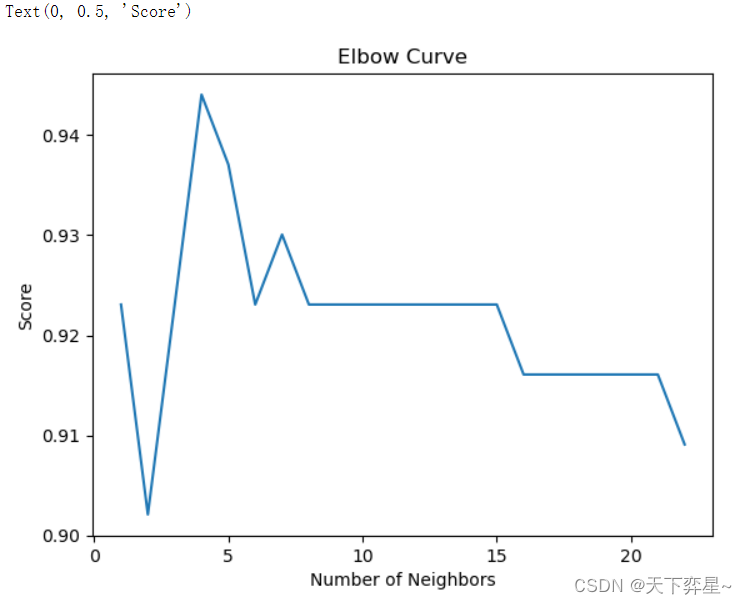
通过图标信息可以看到,当k的值(即n_neighbors)为4时,模型预测得分最高,因此接下来对模型参数进行改进。
十、模型改进
myModel_prove=KNeighborsClassifier(algorithm="kd_tree",leaf_size=30,metric="minkowski",metric_params=None,n_jobs=None,n_neighbors=4,p=2,weights="uniform")
myModel_prove.fit(X_trainingSet,y_trainingSet)
y_predictSet=myModel_prove.predict(X_testSet)十一、模型预测
fit()函数数据训练结果如下:
y_predictSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
用predict()函数进行预测的结果如下:
y_predictSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
为了评价所建立模型的性能,采用“预测准确率(Accuracy Score)”参数,具体实现方式是调用scikit-learn包的metrics模块的accuracy_score()方法。
accuracy_score(y_testSet,y_predictSet)0.9440559440559441
从输出结果可以看出,模型的预测准确率提高了,说明对模型进行了优化。
相关文章:
数据分析实战 | KNN算法——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型改进 十一、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://dow…...
JS实现数据结构与算法
队列 1、普通队列 利用数组push和shif 就可以简单实现 2、利用链表的方式实现队列 class MyQueue {constructor(){this.head nullthis.tail nullthis.length 0}add(value){let node {value}if(this.length 0){this.head nodethis.tail node}else{this.tail.next no…...

计算机毕业设计 基于SpringBoot的驾校管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
S7-1200PLC和SMART PLC开放式以太网通信(UDP双向通信)
S7-1200PLC的以太网通信UDP通信相关介绍还可以参考下面文章链接: 博途PLC开放式以太网通信TRCV_C指令应用编程(运动传感器UDP通信)-CSDN博客文章浏览阅读2.8k次。博途PLC开放式以太网通信TSENG_C指令应用,请参看下面的文章链接:博途PLC 1200/1500PLC开放式以太网通信TSEND_…...

作用域插槽slot-scope
一般用于组件封装,将使用props传入组件的数据再次调出来或者单纯调用组件中的数据。也可用于为组件某个部分自定义样式以及为某次使用组件自定义样式。 直接拿elementui的el-table举例: <template><el-table v-loading"loading&q…...

Redis学习笔记13:基于spring data redis及lua脚本list列表实现环形结构案例
工作过程中需要用到环形结构,确保环上的各个节点数据唯一,如果有新的不同数据到来,则将最早入环的数据移除,每次访问环形结构都自动刷新有效期;可以基于lua 的列表list结构来实现这一功能,lua脚本可以节省网…...

c# 将excel导入 sqlite
nuget 须要加载 EPPlus.Core ExcelDataReader ExcelDataReader.DataSet //需要引用的扩展 using ExcelDataReader; using ExcelPackage OfficeOpenXml.ExcelPackage; public static void CreateZhouPianChaTable(){string tbname "zhou_pian_cha1";//判断表是否存…...

KafkaConsumer 消费逻辑
版本:kafka-clients-2.0.1.jar 之前想写个插件修改 kafkaConsumer 消费者的逻辑,根据 header 过滤一些消息。于是需要了解一下 kafkaConsumer 具体是如何拉取消费消息的,确认在消费之前过滤掉消息是否会有影响。 下面是相关的源码࿰…...
scss 实用教程
变量 $ 定义变量 $link-color: blue;变量名可以与css中的属性名和选择器名称相同 使用变量 a {color: $link_color; }$highlight-border: 1px solid $link_color;中划线和下划线相互兼容,即中划线声明的变量可以使用下划线的方式引用,反之亦然。 $li…...
NO.304 二维区域和检索 - 矩阵不可变
题目 给定一个二维矩阵 matrix,以下类型的多个请求: 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, col1) ,右下角 为 (row2, col2) 。 实现 NumMatrix 类: NumMatrix(int[][] matrix) 给定整数矩阵 …...

牛客---简单密码python
现在有一种密码变换算法。 九键手机键盘上的数字与字母的对应: 1--1, abc--2, def--3, ghi--4, jkl--5, mno--6, pqrs--7, tuv--8 wxyz--9, 0--0,把密码中出现的小写字母都变成九键键盘对应的数字,如:a 变成 2&#x…...
devops完整搭建教程(gitlab、jenkins、harbor、docker)
devops完整搭建教程(gitlab、jenkins、harbor、docker) 文章目录 devops完整搭建教程(gitlab、jenkins、harbor、docker)1.简介:2.工作流程:3.优缺点4.环境说明5.部署前准备工作5.1.所有主机永久关闭防火墙…...

页面上时间显示为数字 后端返回给前端 response java系统
有时候,在一个系统里,会看到,有的页面时间显示正常,有的页面时间显示成数字。像这样: "createTime": 1698706491000 这是因为出参没有做转换,直接将java.util.Date类型的数据返回给前端了。 返…...

idea怎么配置tomcat
要在IntelliJ IDEA中配置Tomcat,请按照以下步骤操作: 打开IntelliJ IDEA,点击File -> Settings(或者使用快捷键CtrlAltS)。 在设置窗口左侧导航栏中,选择Build, Execution, Deployment -> Applicati…...
GoLong的学习之路(二十三)进阶,语法之并发(go最重要的特点)(锁,sync包,原子操作)
这章是我并发系列中最后的一章。这章主要讲的是锁。但是也会讲上一章channl遗留下的一些没有讲到的内容。select关键字的用法,以及错误的一些channl用法。废话不多说。。。 文章目录 select多路复用通道错误示例并发安全和锁问题描述互斥锁读写互斥锁 syncsync.Wait…...

asp.net core 生命周期
在ASP.NET Core中,有三个重要的生命周期阶段: 请求生命周期(Request Lifecycle):请求生命周期从接收到客户端的HTTP请求开始,到响应结果发送给客户端结束。在请求生命周期中,ASP.NET Core会创建…...
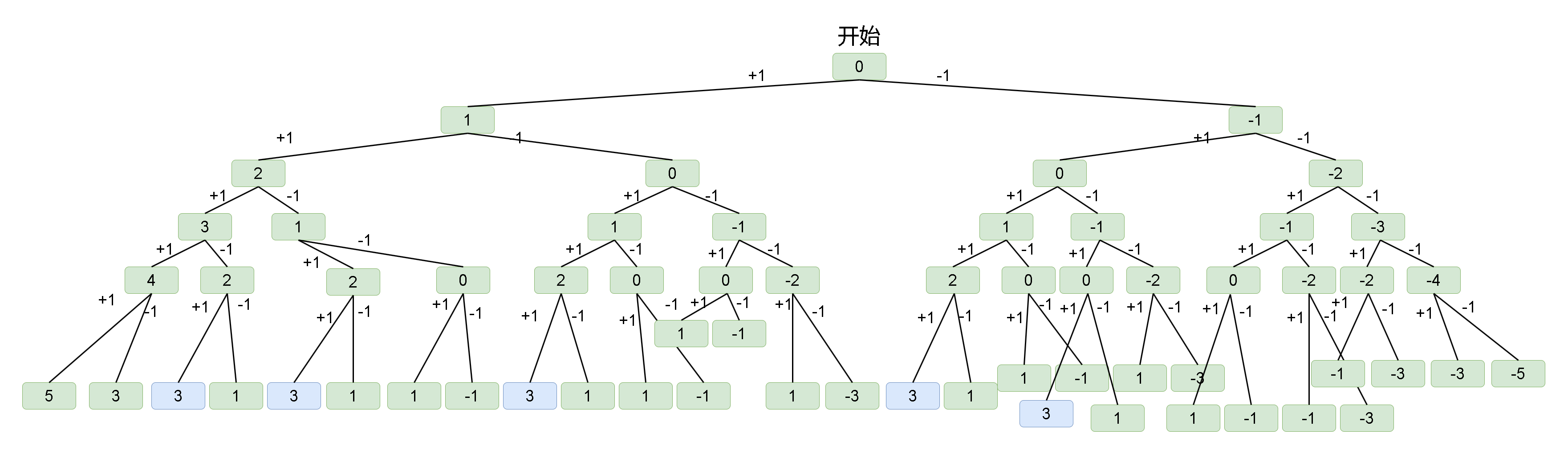
Leetcode刷题详解—— 目标和
1. 题目链接:494. 目标和 2. 题目描述: 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums [2, 1] ,可…...

学习c#的第六天
目录 C# 判断 if 语句 嵌套 if 语句 switch 语句 嵌套 switch 语句 ? : 运算符 C# 循环 循环类型 while 循环 for/foreach 循环 do...while 循环 嵌套循环 循环控制语句 break 语句 continue 语句 无限循环 C# 判断 if 语句 在C#中,if语句用于根…...

第七章 :Spring Boot web开发常用注解(二)
第七章 :Spring Boot web开发常用注解(二) 前言 本章节知识重点:作者结合自身开发经验,以及觉察到的一个现象:Springboot注解全面理解和掌握的并不多,对注解进行了全面总结,共分两个章节,可以作为web开发工程师注解参考手册,SpringBoot常用注解大全,一目了然!。本…...
IOC - Google Guice
Google Guice是一个轻量级的依赖注入框架,专注于依赖注入和IoC,适用于中小型应用。 Spring Framework是一个全面的企业级框架,提供了广泛的功能,适用于大型企业应用。 是吧!IOC 容器不止Spring,还有Google Guice,来体…...
Pixel Dimension Fissioner 集成Codex实战:代码生成与智能补全应用
Pixel Dimension Fissioner 集成Codex实战:代码生成与智能补全应用 1. 引言:当AI代码助手遇上智能维度解析 最近在开发一个电商后台系统时,我发现自己每天要写大量重复的CRUD代码。更头疼的是,每次修改数据库字段后,…...

YOLOv10跨平台部署指南:3分钟极速安装与实战验证
YOLOv10跨平台部署指南:3分钟极速安装与实战验证 【免费下载链接】yolov10 YOLOv10: Real-Time End-to-End Object Detection [NeurIPS 2024] 项目地址: https://gitcode.com/GitHub_Trending/yo/yolov10 还在为深度学习环境配置而头疼吗?CUDA版…...
Beyond CNNs: How Vision Transformers Revolutionize Image Recognition at Scale
1. 视觉Transformer为何能超越CNN? 记得我第一次用ResNet50跑ImageNet分类时,被它的准确率惊艳到了。但当我尝试用ViT-L/16在同样数据集上训练时,测试集top-1准确率直接高出3个百分点——这相当于过去CNN架构迭代两三代的提升幅度。为什么这…...

从EN脚上电到按键消抖:RC延时电路在STM32/GD32项目里的3个实战用法
RC延时电路在嵌入式开发中的三大实战技巧 引言 在嵌入式系统开发中,RC延时电路就像一位默默无闻的后勤保障专家,它不显山露水,却能在关键时刻解决那些让人头疼的时序问题。作为一名长期与STM32和GD32打交道的工程师,我发现RC电路的…...

AI编程实战:从零到一搭建全栈项目朴
1. 核心概念 在 Antigravity 中,技能系统分为两层: Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。 Workflows (项目级):…...

基于Gemma-3-270m的内网穿透方案设计与实现
基于Gemma-3-270m的内网穿透方案设计与实现 1. 引言 在企业级AI服务部署中,我们经常遇到这样的困境:本地部署的AI模型虽然保证了数据安全和响应速度,却难以让外部用户直接访问。传统的云服务部署虽然解决了访问问题,但数据隐私和…...
Qwen-Image-2512-Pixel-Art-LoRA 模型v1.0 版本管理:使用GitHub进行提示词工程与生成作品的协作
Qwen-Image-2512-Pixel-Art-LoRA 模型v1.0 版本管理:使用GitHub进行提示词工程与生成作品的协作 你是不是也遇到过这种情况?和团队一起用AI模型做像素画项目,大家各自尝试不同的提示词,生成了一大堆图片。过几天想找回之前那个效…...

大模型显存占用对比:Qwen2.5-7B推理vs微调,你的显卡够用吗?
Qwen2.5-7B模型显存实战指南:从消费级显卡到专业硬件的适配策略 当你在本地部署一个7B参数的大语言模型时,第一道门槛往往不是算法理解,而是冰冷的硬件现实——显存不足的报错提示。去年团队第一次尝试在RTX 3090上跑Qwen2.5-7B推理时&#…...

3分钟快速上手:免费在线3D模型查看器完整指南
3分钟快速上手:免费在线3D模型查看器完整指南 【免费下载链接】Online3DViewer A solution to visualize and explore 3D models in your browser. 项目地址: https://gitcode.com/gh_mirrors/on/Online3DViewer 想要在浏览器中直接查看3D模型而无需安装任何…...

Qwen3-0.6B-FP8快速上手:无需conda环境直接运行开源大模型
Qwen3-0.6B-FP8快速上手:无需conda环境直接运行开源大模型 想体验最新的大语言模型,但被复杂的Python环境、CUDA版本和依赖冲突劝退?今天,我来带你体验一个完全不同的方式——直接运行一个开箱即用的Web界面,让你在几…...