Clickhouse学习笔记(10)—— 查询优化
单表查询
Prewhere 替代 where
prewhere与where相比,在过滤数据的时候会首先读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性
简单来说就是先过滤再查询,而where过滤是先查询出对应的列字段来,再根据过滤条件过滤数据;因此对比之下,使用prewhere过滤处理的数据量要更少,效率也就更高;
但需注意,prewhere只可适用于mergetree引擎
默认情况下,where 条件会自动优化成 prewhere,通过参数optimize_move_to_prewhere来控制;
参数值为1表示使用怕prewhere
使用where和prewhere的对比:
①使用where:
关闭prewhere自动优化之后,执行语句:
select WatchID, JavaEnable, Title, GoodEvent, EventTime, EventDate, CounterID, ClientIP, ClientIP6, RegionID, UserID, CounterClass, OS, UserAgent, URL, Referer, URLDomain, RefererDomain, Refresh, IsRobot, RefererCategories, URLCategories, URLRegions, RefererRegions, ResolutionWidth, ResolutionHeight, ResolutionDepth, FlashMajor, FlashMinor, FlashMinor2
from datasets.hits_v1 where UserID='3198390223272470366';结果如下,耗时2.467s
![]()
②使用prewhere:
开启优化后执行相同语句,结果如下,耗时仅用0.172s,可以看到效率提升很明显

在一些场景下,自动优化不生效,如下:
- 使用常量表达式
- 使用默认值为 alias 类型的字段
- 包含了 arrayJOIN,globalIn,globalNotIn 或者 indexHint 的查询
- select 查询的列字段和 where 的谓词相同
- 使用了主键字段
例如select 查询的列字段和 where 的谓词相同的情况:
explain syntax select UserID from hits_v1 where UserID='3198390223272470366';结果如下:
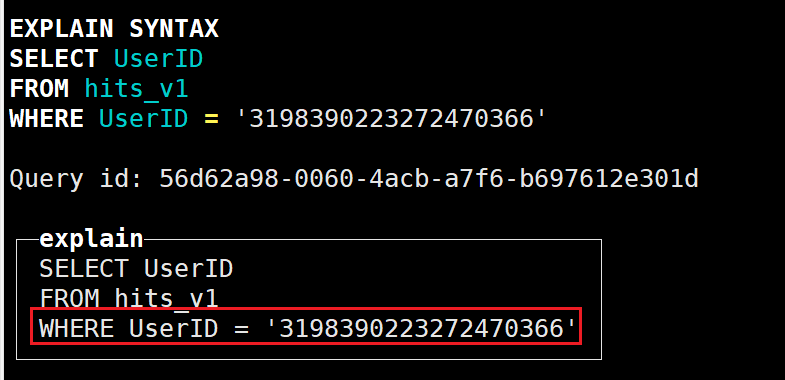
可以看到并没有进行优化;
因此我们在使用prewhere的时候,最好直接在sql中使用prewhere,而不是依赖于自动优化;
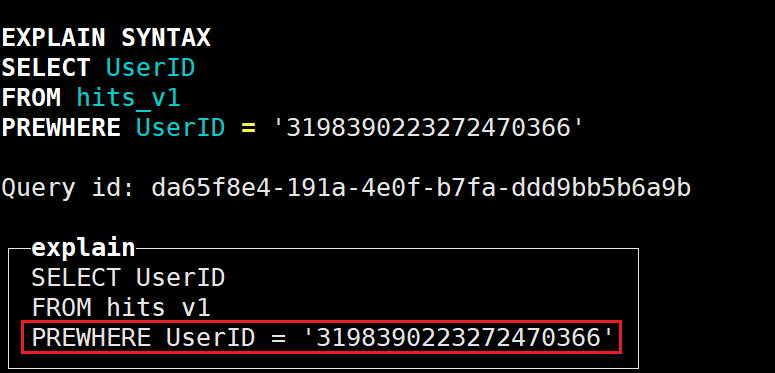
例如:
explain syntax select UserID from hits_v1 prewhere UserID='3198390223272470366';结果如下,是可以生效的:
数据采样 SAMPLE
示例:
SELECT Title,count(*) AS PageViews
FROM hits_v1
SAMPLE 0.1
WHERE CounterID =57
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000采样语法:SAMPLE 样本比例(1代表100%)
SAMPLE Clause | ClickHouse Docs
注意:采样修饰符只有在 MergeTree engine 表中才有效,且在创建表时需要指定采样策略
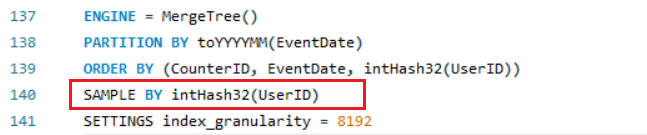
这里的采样策略是在建表时指定的:
表示根据UserID字段的哈希值进行采样
列裁剪与分区裁剪
列裁剪:数据量太大时应避免使用 select * 操作
分区裁剪:就是只读取需要的分区,在过滤条件中指定
例如:
select WatchID, JavaEnable, Title, GoodEvent, EventTime, EventDate, CounterID, ClientIP, ClientIP6, RegionID, UserID
from datasets.hits_v1
where EventDate='2014-03-23';这里的EventDate就是分区字段
orderby 结合 where、limit
千万以上数据集进行 order by 查询时需要搭配 where 条件和 limit 语句一起使用
对比:
①仅使用order by:
SELECT UserID,Age
FROM hits_v1
ORDER BY Age DESC;
②使用where和limit:
SELECT UserID,Age
FROM hits_v1
WHERE CounterID=57
ORDER BY Age DESC LIMIT 1000;![]()
可以看到处理的数据量大幅降低,效率提示十分明显;
③仅使用limit:
SELECT UserID,Age
FROM hits_v1
ORDER BY Age DESC LIMIT 1000;![]()
处理的数据量虽然没有降低,但是效率提升也比较明显
避免构建虚拟列
什么是虚拟列:在select查询的字段中,非建表时指定的字段即为虚拟列
例如:
SELECT Income,Age,Income/Age as IncRate FROM datasets.hits_v1;
这里的Income/Age就是虚拟列,由于每次查一条语句都需要进行一次计算,所以十分影响性能
使用虚拟列:

没有虚拟列:

uniqCombined 替代 distinct
uniqCombined 底层采用类似 HyperLogLog 算法实现,能接收 2%左右的数据误差,可直接使用这种去重方式提升查询性能
而Count(distinct)会使用 uniqExact精确去重
示例:
explain syntax select count(distinct UserID) from hits_v1;

对UserID进行去重:
使用uniqCombined:
SELECT uniqCombined(UserID) from datasets.hits_v1;

使用uniqExact:
select count(distinct UserID) from hits_v1;

其他
查询熔断
为了避免因个别慢查询引起的服务雪崩的问题,除了可以为单个查询设置超时以外,还可以配置周期熔断,在一个查询周期内,如果用户频繁进行慢查询操作超出规定阈值后将无法继续进行查询操作
关闭虚拟内存
物理内存和虚拟内存的数据交换,会导致查询变慢,资源允许的情况下关闭虚拟内存
配置 join_use_nulls
为每一个账户添加 join_use_nulls 配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准 SQL 中的 Null 值
批量写入时先排序
批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致 ClickHouse 无法及时对新导入的数据进行合并,从而影响查询性能
关注 CPU
cpu 一般在 50%左右会出现查询波动,达到 70%会出现大范围的查询超时,cpu 是最关键的指标,要非常关注
使用top命令查看CPU使用情况
参数含义如下:
%us:表示用户空间程序的cpu使用率(没有通过nice调度)
%sy:表示系统空间的cpu使用率,主要是内核程序。
%ni:表示用户空间且通过nice调度过的程序的cpu使用率。
%id:空闲cpu
%wa:cpu运行时在等待io的时间
%hi:cpu处理硬中断的数量
%si:cpu处理软中断的数量
%st:被虚拟机偷走的cpu
注:99.0 id,表示空闲CPU,即CPU未使用率,100%-99.0%=1%,即系统的cpu使用率为1%。
多表关联
准备数据
由于clickhouse的join操作效率很低,因此根据官方提供的数据集准备两张小表
#创建小表CREATE TABLE visits_v2
ENGINE = CollapsingMergeTree(Sign)
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate, intHash32(UserID), VisitID)
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from visits_v1 limit 10000;#创建 join 结果表:避免控制台疯狂打印数据
CREATE TABLE hits_v2
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from hits_v1 where 1=0;这里的visits_v2是一张小表,用于join测试
hits_v2是一张结果表,用于保存join之后的数据;
注意where 1=0这个条件,保留了hits_v1这张表的结构,但里面没有数据
用 IN 代替 JOIN
①使用IN:
insert into hits_v2
select a.* from hits_v1 a where a. CounterID in (select CounterID from visits_v1);
②使用JOIN:
insert into table hits_v2
select a.* from hits_v1 a left join visits_v1 b on a. CounterID=b. CounterID;
对比可知使用IN效率提升很多;
同时在执行join的时候观察CPU使用情况:

发现CPU的占用率接近80%
小表在右原则
多表 join 时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较,ClickHouse 中无论是 Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表
对比以下:
①小表在右
insert into table hits_v2
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID;![]()
②大表在右
insert into table hits_v2
select a.* from visits_v2 b left join hits_v1 a on a. CounterID=b. CounterID;执行没几秒就内存超限了:

谓词下推(join查询无法自动实现)
ClickHouse 在 join 查询时不会主动发起谓词下推的操作,需要每个子查询提前完成过滤操作
需要注意的是,是否执行谓词下推,对性能影响差别很大
子查询不提前过滤:
insert into hits_v2
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID
where a.EventDate = '2014-03-17';![]()
子查询提前过滤:
insert into hits_v2
select a.* from (select * from hits_v1 where EventDate = '2014-03-17'
) a left join visits_v2 b on a. CounterID=b. CounterID;![]()
可以看出效率上有一定差别
所谓谓词下推,就是在join之前根据条件进行过滤,从而筛选出一部分数据来,减少进行join的数据量,从而提升join的效率
查看上面两个select语句的优化计划,分别如下:
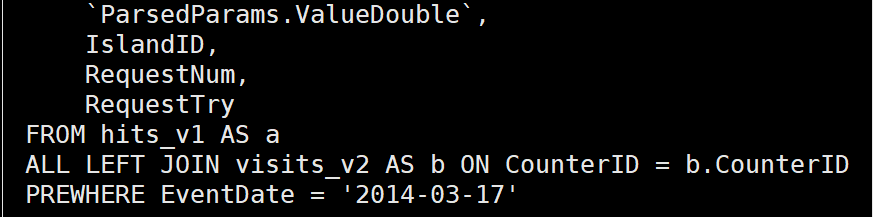

可以看到,如果不手动通过子查询提前完成过滤,是不会自动进行谓词下推的
分布式表使用GLOBAL关键字
两张分布式表上的 IN 和 JOIN 之前必须加上 GLOBAL 关键字,这样的话,右表只会在接收查询请求的那个节点查询一次,并将其分发到其他节点上
如果不加 GLOBAL 关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询 N²次(N是该分布式表的分片数量),这就是查询放大,会带来很大开销
官网相关描述:

详细用法可见:IN Operators | ClickHouse Docs
字典表
将一些需要关联分析的业务创建成字典表进行 join 操作,前提是字典表不宜太大,因为字典表会常驻内存
参考:Dictionaries | ClickHouse Docs
相关文章:
Clickhouse学习笔记(10)—— 查询优化
单表查询 Prewhere 替代 where prewhere与where相比,在过滤数据的时候会首先读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性 简单来说就是先过滤再查询,而where过滤是先查询出对应…...

[量化投资-学习笔记012]Python+TDengine从零开始搭建量化分析平台-策略回测
上一章节《MACD金死叉策略回测》中,对平安银行这只股票,按照金死叉策略进行了回测。 但通常我们的股票池中有许多股票,每完成一个交易策略都需要对整个股票池进行回测。 下面使用简单的轮询,对整个股票池进行回测。 # 计算单只…...

MySQL 查看 event 执行记录
文章目录 1. 查看 EVENT 执行记录2. 示例3. 结论 MySQL 是一款流行的关系型数据库管理系统,它提供了许多功能来帮助用户管理和操作数据库。其中之一就是 EVENT事件,它允许用户在特定的时间间隔内自动执行指定的操作,类似于计划任务。 在使用 …...
开发知识点-Vue-Electron
Electron ElectronVue打包.exe桌面程序 ElectronVue打包.exe桌面程序 为了不报错 卸载以前的脚手架 npm uninstall -g vue-cli安装最新版脚手架 cnpm install -g vue/cli创建一个 vue 随便起个名 vue create electron-vue-example (随便起个名字electron-vue-example)进入 创建…...

【线性代数】反求矩阵A
...

MyBatis 中的 foreach 的用法
本文将介绍 MyBatis 中的 <foreach> 标签的灵活应用,并结合财经领域的数据处理场景,阐述其在财经系统开发中的重要性和应用价值。 MyBatis中的<foreach>标签简介 MyBatis 是一个优秀的持久层框架,它简化了数据库操作的流程&…...

交叉编译 mysql-connector-c
下载 mysql-connector-c $ wget https://downloads.mysql.com/archives/get/p/19/file/mysql-connector-c-6.1.5-src.tar.gz 注意:mysql-connector 的页面有很多版本,在测试过程中发现很多默认编译有问题,其中上面的 6.1.5 的版本呢是经过测…...

企业如何选择正确的存储服务器租用?
数据时代的发展,让越来越多的企业选择使用存储服务器来存储数据,今天小编就带大家了解一下企业应该怎么正确的选择存储服务器吧,要关注哪些方面的问题呢? 第一点肯定是看自己的需求,不论是选择什么服务器最重要的一点就…...

45.跳跃游戏II
45.跳跃游戏II 题目描述:给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i]i …...

css style、css color 转 UIColor
你能看过来,就说明这个问题很好玩!IT开发是一个兴趣,更是一个挑战!兴趣使你工作有热情。挑战使让你工作充满刺激拉满的状态!我们日复一日年复一年的去撸代码,那些普普通通的功能代码,已经厌倦了…...
:typename声明类的子类型的简化)
C++(20):typename声明类的子类型的简化
C++:typename声明类的子类型_风静如云的博客-CSDN博客 介绍了某些时候需要使用typename来告诉编译器,这是一个类的类型。 C++20简化了对typename的需求,对于明显是类型的地方,可以不再使用typename进行说明: #include <iostream> #include <string>using na…...
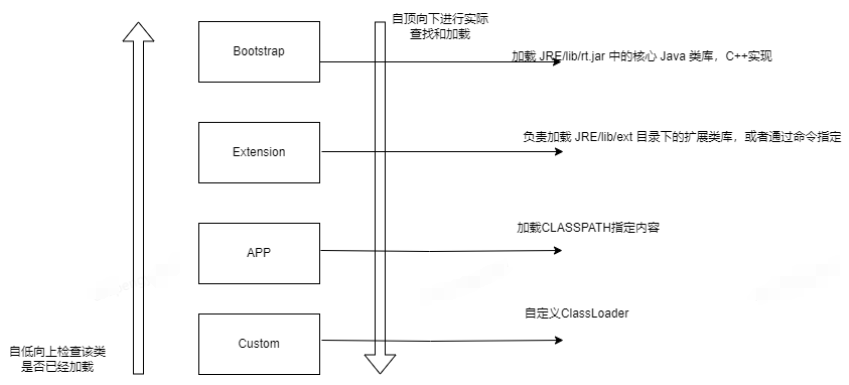
一个java文件的JVM之旅
准备 我是小C同学编写得一个java文件,如何实现我的功能呢?需要去JVM(Java Virtual Machine)这个地方旅行。 变身 我高高兴兴的来到JVM,想要开始JVM之旅,它确说:“现在的我还不能进去,需要做一次转换&#x…...
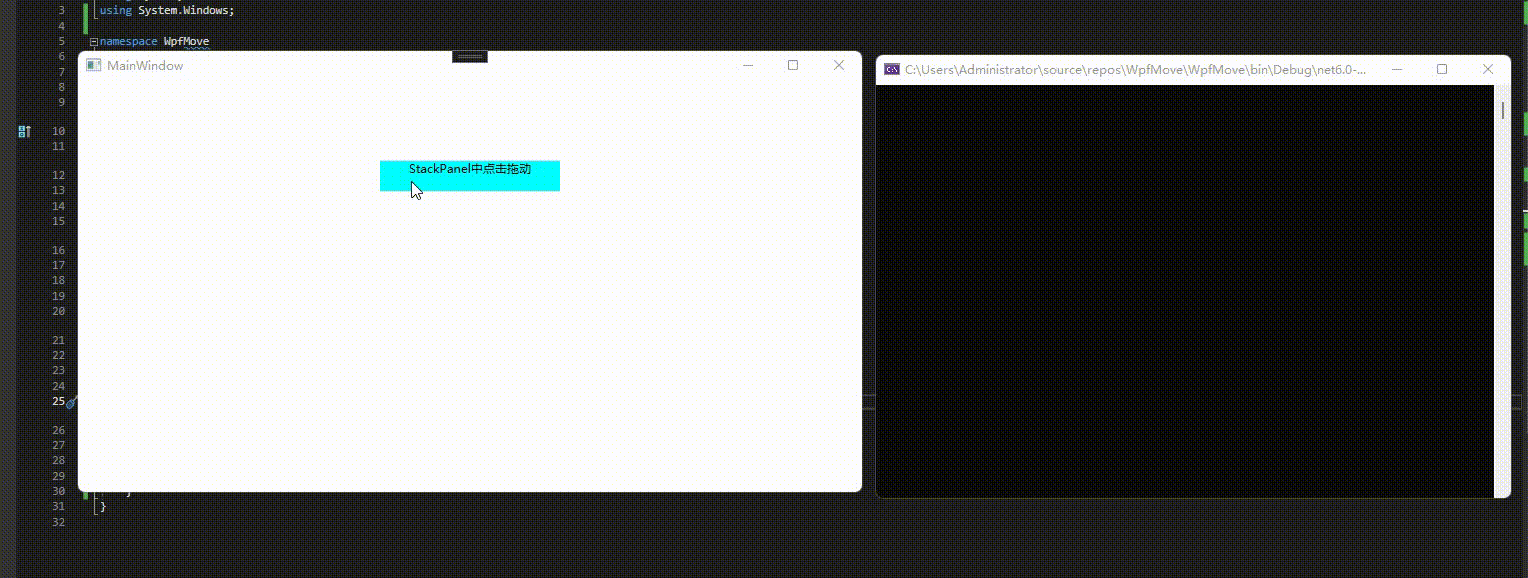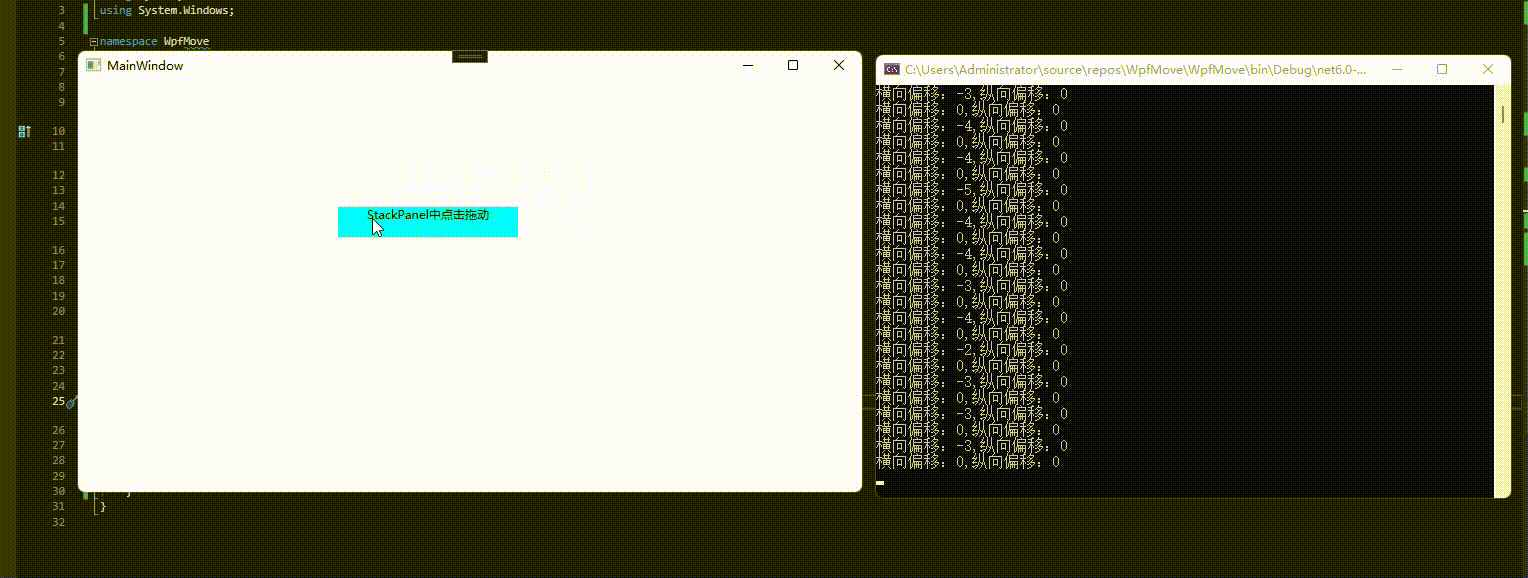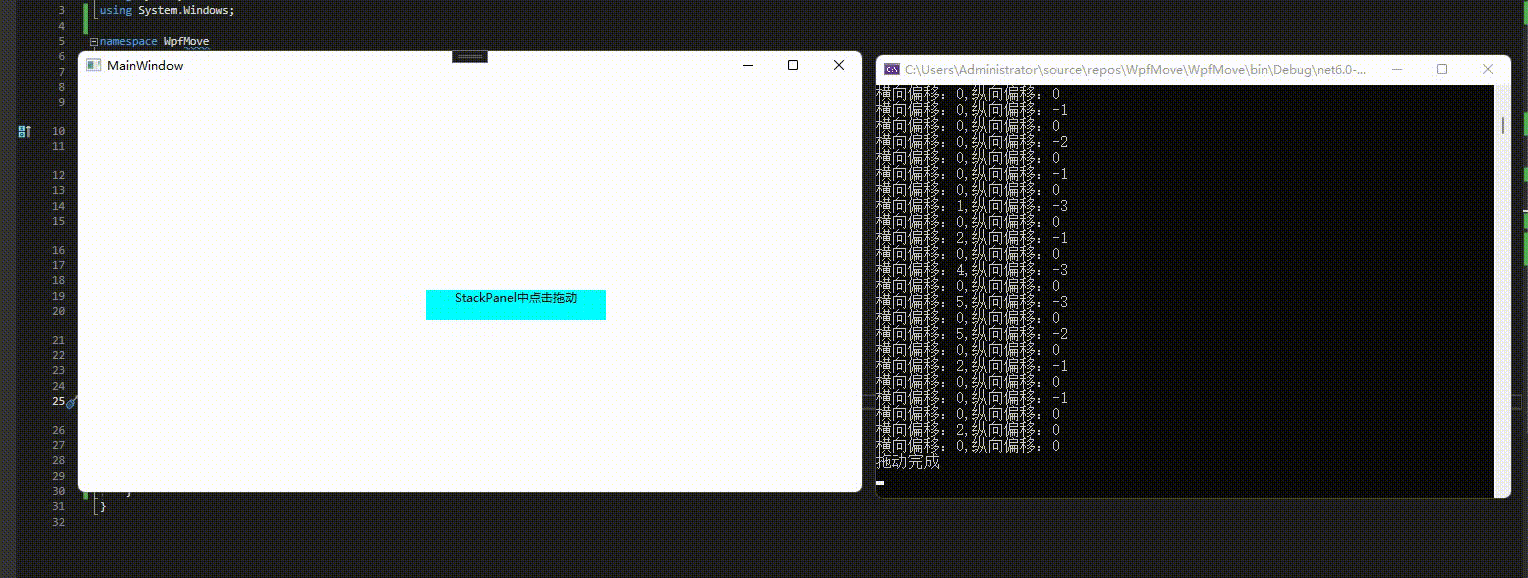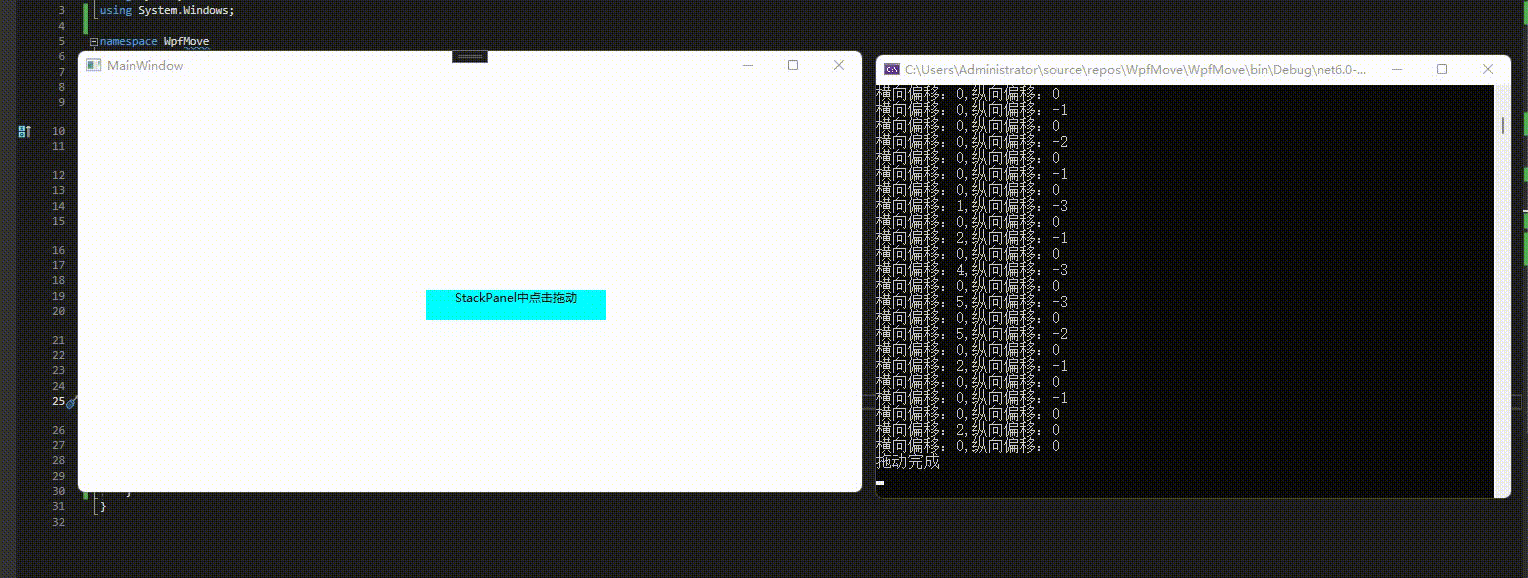
C# wpf 实现任意控件(包括窗口)更多拖动功能
系列文章目录 第一章 Grid内控件拖动 第二章 Canvas内控件拖动 第三章 任意控件拖动 第四章 窗口拖动 第五章 附加属性实现任意拖动 第六章 拓展更多拖动功能(本章) 文章目录 系列文章目录前言一、添加的功能1、任意控件MoveTo2、任意控件DragMove3、边…...

一种ADC采样算法,中位值平均滤波+递推平均滤波
前言 在实际AD采集场景中,会出现周期性变化和偶然脉冲波动干扰对AD采集的影响 这里使用中位值平均滤波递推平均滤波的结合 参考前人写好的代码框架,也参考博主GuYH_下面这篇博客,在此基础上稍作修改,写出这篇博客,能…...
技能培训知识付费服务预约小程序的效果如何
技能、证书往往是很多人生活的基本,行业岗位竞争激烈,每个人都希望有多种技能或工作所需,而需求持续增加下,相关技能培训机构也很多,比如常见的考证、钢琴培训、针灸培训、花艺培训等。 很多行业都需要学习或考证&…...
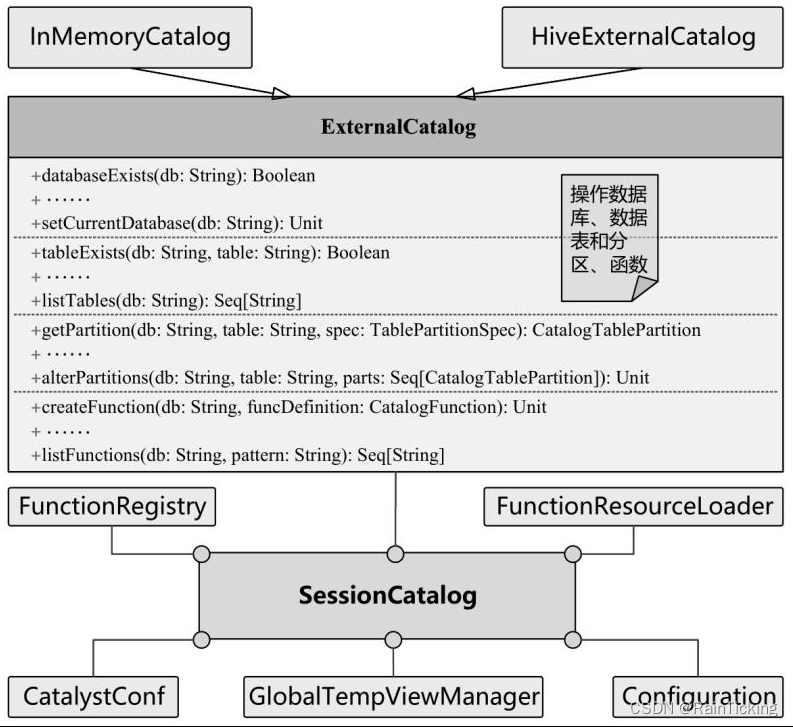
SparkSQL之Catelog体系
按照SQL标准的解释,在SQL环境下Catalog和Schema都属于抽象概念。在关系数据库中,Catalog是一个宽泛的概念,通常可以理解为一个容器或数据库对象命名空间中的一个层次,主要用来解决命名冲突等问题。 在Spark SQL系统中,…...
【操作系统面试题(32道)与面试Linux命令大全】
文章目录 操作系统面试题引论1.什么是操作系统?2.操作系统主要有哪些功能? 操作系统结构3.什么是内核?4.什么是用户态和内核态?5.用户态和内核态是如何切换的? 进程和线程6.并行和并发有什么区别?7.什么是进…...

Qt TCP/IP网络通信
TCP服务器部分: 创建TCP服务器: #include <QTcpServer> QTcpServer *tcpServer; //TCP服务器 tcpServernew QTcpServer(this);TCP服务器来连接的信号与槽: connect(tcpServer,SIGNAL(newConnection()),this,SLOT(onNewConnection()…...

全域旅游“一机游”智慧旅游平台解决方案:PPT全文48页,附下载
关键词:智慧文旅解决方案,智慧旅游解决方案,智慧旅游平台建设方案,智慧文旅综合运营平台,智慧文旅建设方案 一、智慧文旅一机游定义 智慧文旅一机游是一种新型的旅游方式,它通过智能化的设备和系统&#…...
 安装 libssl1.1)
Ubuntu 22.04 (WSL2) 安装 libssl1.1
废话不多说!!! 步骤一: echo "deb http://security.ubuntu.com/ubuntu focal-security main" | sudo tee /etc/apt/sources.list.d/focal-security.list 步骤二: sudo apt-get update 步骤三:…...

三步搞定iOS激活锁绕过:applera1n工具使用全指南
三步搞定iOS激活锁绕过:applera1n工具使用全指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经因为忘记Apple ID密码而无法使用自己的iPhone?或者购买的二手设备被…...
)
2026奇点智能大会前瞻:为什么92%的AI工程团队将在Q3前重构Agent框架?(Gartner未公开预警报告首曝)
第一章:2026奇点智能技术大会:大模型Agent框架 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将大模型Agent框架确立为核心技术范式,聚焦于可推理、可规划、可协作的自主智能体系统设计。与传统微调或提示工程不同,…...

C# SerialPort 类中 Handshake 属性的实战应用与优化策略
1. 理解Handshake属性的核心作用 串口通信就像两个人用对讲机通话,如果一方说得太快,另一方可能根本听不清。这时候就需要一个协调机制,让双方保持同步。在C#的SerialPort类中,Handshake属性就是这个协调员,专门负责管…...

新手必看!霜儿-汉服-造相Z-Turbo保姆级入门:从部署到生成第一张汉服图
新手必看!霜儿-汉服-造相Z-Turbo保姆级入门:从部署到生成第一张汉服图 想用AI生成古风汉服美图却不知从何入手?本文将带你零基础玩转"霜儿-汉服-造相Z-Turbo"模型,从部署到生成第一张汉服图只需10分钟。无需编程基础&a…...

Hunyuan-MT Pro智能助手:支持33语种的科研论文辅助翻译系统
Hunyuan-MT Pro智能助手:支持33语种的科研论文辅助翻译系统 1. 引言:科研翻译的新选择 作为一名经常需要阅读国际期刊的研究人员,你是否曾经为了一篇关键论文的翻译而头疼?那些专业的术语、复杂的句式,以及不同语言间…...

Windows下不同目录Git仓库同步
Windows下不同目录Git仓库同步的核心逻辑与实施方案 在Windows环境中,不同目录的Git仓库同步本质是“分布式版本控制的协作流程”——Git作为分布式系统,没有“直接同步两个本地仓库”的原生命令,必须通过远程仓库(Remote Reposit…...

Phi-3-mini-4k-instruct-gguf新手入门指南:从零开始,3步完成AI文本生成环境搭建
Phi-3-mini-4k-instruct-gguf新手入门指南:从零开始,3步完成AI文本生成环境搭建 1. 为什么选择Phi-3-mini-4k-instruct-gguf Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,特别适合中文场景下的问答、文本改写和摘要生成任务…...

Python爬虫数据赋能:自动收集古风素材训练霜儿-汉服-造相Z-Turbo的LoRA模型
Python爬虫数据赋能:自动收集古风素材训练霜儿-汉服-造相Z-Turbo的LoRA模型 1. 从想法到实现:一个数据驱动的汉服AI项目 最近在玩一个叫“霜儿-汉服-造相Z-Turbo”的AI模型,它生成汉服的效果确实挺惊艳的。但用久了发现一个问题:…...

麦橘超然Flux图像生成控制台:从环境准备到生成测试的完整流程
麦橘超然Flux图像生成控制台:从环境准备到生成测试的完整流程 1. 引言 1.1 项目概述 麦橘超然Flux图像生成控制台是一款基于DiffSynth-Studio框架构建的AI绘画工具,集成了majicflus_v1模型,通过float8量化技术显著降低了显存需求。这个解决…...

在WSL中部署Phi-4-mini-reasoning:Windows开发者的轻量级AI推理环境搭建
在WSL中部署Phi-4-mini-reasoning:Windows开发者的轻量级AI推理环境搭建 1. 为什么选择WSL部署Phi-4-mini-reasoning 对于习惯Windows环境的开发者来说,WSL(Windows Subsystem for Linux)提供了一个完美的折中方案。它让你既能享…...