【2024年11月份--2024精灵云校招C++笔试题】
考试形式
笔试考了三道算法题,笔试形式为阅读题目,然后用中文给出算法思路,最后给出算法例程,分数各占一半,简单,中等,复杂各一道题。我看9月份有人也是考这3道题,一模一样。
第一题:英文句子翻转
1.单词倒转(简单 50) 描述: 将一个句子中的单词全部倒转,如:
i am a programmer.
倒转后为:
programmer a am i.
每句话以.结尾,只倒转每句话内的单词,一个输入可能包含多句话。 输入为Char* 类型. 要求:尽量使用空间复杂度最小的方法实现。 请用中文说明算法思想(30) 请给出算法例程,可使用c++/golang实现(20) C++代码
中文说明算法思想:
这个算法用于翻转句子中的单词,并且保留句子末尾的句点。
逆序整个句子: 首先,计算句子的长度 len,然后使用 std::reverse函数逆序整个句子,但不包括句点。这一步将句子中的字符顺序全部反转。
逆序每个单词: 接下来,通过遍历句子中的字符,找到单词的边界(通过空格或句子末尾),然后对每个单词进行逆序处理。逆序单词后,将单词的起始位置start 更新为当前位置加一。
最后,手动在输出末尾添加句点,以保留原始句子的结尾标点符号。
这个算法通过反转整个句子和逆序每个单词来实现句子翻转,同时保留了句子末尾的句点。
#include <iostream>
#include <cstring> // 包含cstring头文件以使用strlen函数
#include <algorithm>void reverseWords(char* s) {int len = strlen(s); // 计算字符串长度if (len > 1) {std::reverse(s, s + len - 1); // // 逆序整个句子,不包括末尾的句号(.)int start = 0; // 记录单词的起始位置for (int i = 0; i < len - 1; ++i) { // 遍历字符串,不处理句点if (s[i] == ' ' || s[i] == '\0') { // 当遇到空格或字符串结束符时std::reverse(s + start, s + i); // 逆序单词start = i + 1; // 更新单词的起始位置为下一个字符}}}
}int main() {char str[] = "i am a programmer.";reverseWords(str); // 调用翻转单词的函数std::cout << str << std::endl; // 输出翻转后的句子return 0;
}
这个例程的reverseWords函数实现了对单词的倒转。首先,它翻转了整个句子,然后再逐个翻转每个单词,最终得到了所需的结果。
第二题:二分查找
2.给一个非递减排序的数列(非严格递增),请查找最后一个等于给定元素 x的数列元素的下标,不存在则返回-1。 要求:时间复杂度小于O(n), C++代码
中文说明算法思想:
这段代码使用了二分查找算法来找到一个非递减排序的数组中,最后一个等于给定元素 x 的数列元素的下标。具体步骤如下:
初始化左右边界:开始时,将左边界
left设为数组起始位置(0),右边界right设为数组末尾位置(arr.size() - 1)。二分查找:通过
while循环执行二分查找算法。在每一次循环中:a. 计算中间位置
mid:使用左右边界计算出中间位置。b. 对比中间位置元素与给定元素 x:
- 如果中间位置的元素与 x 相等,更新result为当前的中间位置mid,并向右侧继续寻找可能存在的更后面的元素,因为要找最后一个等于 x 的位置。
- 如果中间位置的元素小于 x,则将左边界left更新为mid + 1,因为要在右半边继续寻找。
- 如果中间位置的元素大于 x,则将右边界right更新为mid - 1,因为要在左半边寻找。返回结果:如果找到了等于 x 的元素,则
result中存储的即为最后一个等于 x 的元素下标,如果没有找到,则返回 -1。这个算法的关键在于根据中间值与目标值的大小关系,不断缩小搜索范围直到找到目标值或者确认数组中不存在该值。
#include <iostream>
#include <vector>int lastIndexOfX(const std::vector<int>& arr, int x) {int left = 0;int right = arr.size() - 1;int result = -1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] == x) {result = mid; // 更新结果left = mid + 1; // 继续向右寻找} else if (arr[mid] < x) {left = mid + 1; // 向右边查找} else {right = mid - 1; // 向左边查找}}return result;
}int main() {std::vector<int> arr = {1, 2, 2, 3, 4, 4, 4, 5, 6};int x = 4;int lastIndex = lastIndexOfX(arr, x);if (lastIndex != -1) {std::cout << "最后一个 " << x << " 的下标是: " << lastIndex << std::endl;} else {std::cout << x << " 不存在于数组中" << std::endl;}return 0;
}
第三题:LRU缓存
第三道题是选做题,leetcode上的LRU缓存使用双向链表。https://leetcode.cn/problems/lru-cache-lcci/solutions/491688/lruhuan-cun-by-leetcode-solution/
3.设计缓存(复杂10)(选做) 描述: 设计一个缓存,缓存大小为指定大小n,最近最少使用的值应自动被缓存替换掉。 (类及类的方法已经定义好)
Class Cache {public:explict Cache(int n); bool put(int, int); int get(int);
}
要求: 1. 缓存支持键值对存取,即支持插入键值对put(key, val)及读取某键对应的值 get(key),如果存在该键,则返回其对应的值,否则返回-1; 2. 键值对可以支持整型。 要求:尽量使用时间复杂度最小的方法实现。 请用中文说明算法思想(5) 请给出算法例程,可使用c++/golang实现(5) C++代码
中文说明算法思想:
这个算法使用了哈希表和双向链表来实现LRU缓存。具体思想如下:
哈希表(unordered_map):用于快速查找键值对。键是缓存中的键,值是指向双向链表中节点的指针。
双向链表:用于维护键值对的访问顺序。链表的头部表示最近访问过的节点,尾部表示最久未被访问的节点。
操作过程:
插入操作 (put):当要插入新的键值对时,先查看哈希表中是否已存在该键。如果存在,更新其值,并将该节点移动到链表头部表示最近访问。如果哈希表已满,移除链表尾部节点(最少使用的节点),并在哈希表中删除相应的键值对;然后将新节点插入链表头部,并更新哈希表。
获取操作 (get):当要获取某个键对应的值时,先在哈希表中查找。如果存在该键,表示该节点被访问,将其移动到链表头部,并返回对应的值;否则返回-1。
这种方法保证了对缓存的访问操作(插入和获取)都能在常数时间内完成,因为哈希表的查找是常数时间,而双向链表的插入和移动操作也是常数时间。
最近最少使用(LRU,Least Recently Used)是一种常见的缓存淘汰策略。它的核心思想是当缓存达到其容量上限时,移除最长时间未被使用的数据项来为新数据项腾出空间。这种策略基于一个假设:最近经常使用的数据在不久的将来也很可能再次使用,而长时间未被访问的数据在未来可能也不会被访问。
举例说明
假设我们有一个容量为3的LRU缓存,以下是一系列的操作和缓存的状态变化:
- 放入键值对 (1, ‘A’):
- 缓存状态:1:A
- 放入键值对 (2, ‘B’):
- 缓存状态:1:A, 2:B
- 放入键值对 (3, ‘C’):
- 缓存已满,状态:1:A, 2:B, 3:C
- 访问键为2的数据 (‘B’):
- 由于键2被访问,它成为最近使用的数据,移动到缓存的头部。
- 缓存状态:2:B, 1:A, 3:C
- 放入键值对 (4, ‘D’):
- 缓存已满,需要移除最久未使用的数据(在这个例子中是键3的数据)。
- 新数据 (4, ‘D’) 放入缓存头部。
- 缓存状态:4:D, 2:B, 1:A
在这个例子中,每次访问或添加新数据时,缓存都会根据数据的使用情况进行调整。最近被访问的数据总是被移动到缓存的头部,而最久未被访问的数据则逐渐移动到缓存的尾部,当需要移除数据以腾出空间时,缓存尾部的数据(即最久未使用的数据)将被移除。
使用C++设计一个缓存
当设计一个缓存,你需要考虑一种数据结构能够以常数时间复杂度执行插入、删除和查找操作。一种优秀的选择是使用哈希表和双向链表实现一个LRU(Least Recently Used)缓存。
在这种方法中,哈希表用于快速查找键值对,而双向链表用于维护键值对的访问顺序。当有新的键值对被访问时,它将会被移动到链表的头部,而最近最少使用的元素将会位于链表的尾部,以便于替换。
下面是一个用C++实现LRU缓存的例程:
#include <unordered_map>// 缓存节点类,用于表示LRU缓存中的每个数据项
class CacheNode {
public:int key; // 缓存节点的键int value; // 缓存节点的值CacheNode* prev; // 指向前一个节点的指针CacheNode* next; // 指向后一个节点的指针// 构造函数,用于创建一个新的缓存节点CacheNode(int k, int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};// LRU缓存类,用于实现最近最少使用缓存机制
class Cache {
public:// 构造函数,用于初始化缓存的大小和创建哨兵节点explicit Cache(int n) : capacity(n) {head = new CacheNode(-1, -1); // 创建头哨兵节点tail = new CacheNode(-1, -1); // 创建尾哨兵节点head->next = tail; // 初始化双向链表tail->prev = head;}// 析构函数,用于释放链表中的所有节点~Cache() {CacheNode* current = head;while (current) {CacheNode* next = current->next;delete current;current = next;}}// 从链表中移除一个节点的函数,用于删除最久未使用的节点或移动节点void removeNode(CacheNode* node) {node->prev->next = node->next;node->next->prev = node->prev;}// 将节点添加到链表头部的函数,用于添加新节点或将最近使用的节点移动到头部void addToFront(CacheNode* node) {node->next = head->next;node->prev = head;head->next->prev = node;head->next = node;}// 将节点移动到链表头部的函数,当节点被访问时,通过这个函数将其移动到头部void moveToHead(CacheNode* node) {removeNode(node);addToFront(node);}// 获取方法:如果键存在,返回对应的值,并将该节点移至链表头部int get(int key) {if (cacheMap.find(key) != cacheMap.end()) {CacheNode* node = cacheMap[key];moveToHead(node);return node->value;}return -1;}// 插入方法:将键值对存入缓存,如果键已存在,则更新其值并移动到头部;如果不存在,添加新节点bool put(int key, int value) {if (cacheMap.find(key) != cacheMap.end()) {CacheNode* node = cacheMap[key];node->value = value;moveToHead(node);} else {if (cacheMap.size() >= capacity) {CacheNode* toRemove = tail->prev;removeNode(toRemove);cacheMap.erase(toRemove->key);delete toRemove;}CacheNode* newNode = new CacheNode(key, value);cacheMap[key] = newNode;addToFront(newNode);}return true;}private:int capacity; // 缓存的最大容量std::unordered_map<int, CacheNode*> cacheMap; // 键到节点的映射,用于快速查找CacheNode* head; // 头哨兵节点CacheNode* tail; // 尾哨兵节点
};这段代码实现了一个简单的LRU缓存,其中使用了哈希表和双向链表。这种实现方式在put和get操作中都能以常数时间复杂度运行。
这个问题涉及到设计一个缓存系统,这是计算机科学中常见的任务,特别是在数据处理和系统设计领域。我将逐步解释任务的目的、要求和实现方法。
任务目的
缓存系统的主要目的是提高数据访问速度。当程序频繁访问某些数据时,将这些数据存储在快速访问的缓存中,可以减少从慢速存储(如硬盘)读取数据的次数,从而提高效率。
任务要求
- 大小限制:缓存的大小是固定的(指定大小
n),意味着它只能存储最多n个元素。 - 键值对存储:缓存通过键值对的方式存储数据。每个键对应一个唯一的值。可以使用
put(key, val)方法插入键值对,使用get(key)方法读取值。 - 最近最少使用(LRU)策略:当缓存达到最大容量时,最近最少使用的数据将被新数据替换。这意味着缓存应跟踪数据的使用情况,并且在需要空间时删除最久未使用的数据。
实现方法
数据结构
- 双向链表:用于存储缓存中的数据。每个节点(
CacheNode)包含一个键值对,以及指向前一个和后一个节点的指针。链表的顺序反映了元素的使用情况——最近访问的元素被移到链表的头部,而最久未使用的元素则接近尾部。 - 哈希表:使用一个
unordered_map(cacheMap),以实现快速查找功能。哈希表存储键和指向相应链表节点的指针。
主要操作
- 插入(
put方法):- 如果键已存在,更新其值并将对应节点移动到链表头部(表示最近使用)。
- 如果键不存在,检查缓存是否已满。如果已满,则删除最久未使用的元素(链表尾部的元素),然后将新元素添加到链表头部。
- 获取(
get方法):- 如果键存在,返回对应的值,并将该节点移至链表头部。
- 如果键不存在,返回
-1。
操作细节
- 移动节点至头部(
moveToHead方法):当节点被访问时(通过get或put),将其移动到链表的头部,表示该节点是最近被使用过的。 - 添加节点至头部(
addToFront方法):当插入一个新的元素时,将其添加到链表的头部。 - 移除节点(
removeNode方法):从链表中移除一个节点,通常用于删除最久未使用的元素。
总结
这个缓存系统是一个典型的最近最少使用(LRU)缓存,其通过双向链表和哈希表的结合实现了高效的插入、删除和访问操作。这种设计允许快速地添加和检索数据,同时自动管理缓存的大小,确保最常用的数据始终保留在缓存中。
验证LRU缓存实现
创建一个LRU缓存实例,执行一些基本操作,并验证预期行为。
#include <iostream>
#include <cassert>
#include <unordered_map>// 缓存节点类,用于表示LRU缓存中的每个数据项
class CacheNode {
public:int key; // 缓存节点的键int value; // 缓存节点的值CacheNode* prev; // 指向前一个节点的指针CacheNode* next; // 指向后一个节点的指针// 构造函数,用于创建一个新的缓存节点CacheNode(int k, int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};// LRU缓存类,用于实现最近最少使用缓存机制
class Cache {
public:// 构造函数,用于初始化缓存的大小和创建哨兵节点explicit Cache(int n) : capacity(n) {head = new CacheNode(-1, -1); // 创建头哨兵节点tail = new CacheNode(-1, -1); // 创建尾哨兵节点head->next = tail; // 初始化双向链表tail->prev = head;}// 析构函数,用于释放链表中的所有节点~Cache() {CacheNode* current = head;while (current) {CacheNode* next = current->next;delete current;current = next;}}// 从链表中移除一个节点的函数,用于删除最久未使用的节点或移动节点void removeNode(CacheNode* node) {node->prev->next = node->next;node->next->prev = node->prev;}// 将节点添加到链表头部的函数,用于添加新节点或将最近使用的节点移动到头部void addToFront(CacheNode* node) {node->next = head->next;node->prev = head;head->next->prev = node;head->next = node;}// 将节点移动到链表头部的函数,当节点被访问时,通过这个函数将其移动到头部void moveToHead(CacheNode* node) {removeNode(node);addToFront(node);}// 获取方法:如果键存在,返回对应的值,并将该节点移至链表头部int get(int key) {if (cacheMap.find(key) != cacheMap.end()) {CacheNode* node = cacheMap[key];moveToHead(node);return node->value;}return -1;}// 插入方法:将键值对存入缓存,如果键已存在,则更新其值并移动到头部;如果不存在,添加新节点bool put(int key, int value) {if (cacheMap.find(key) != cacheMap.end()) {CacheNode* node = cacheMap[key];node->value = value;moveToHead(node);}else {if (cacheMap.size() >= capacity) {CacheNode* toRemove = tail->prev;removeNode(toRemove);cacheMap.erase(toRemove->key);delete toRemove;}CacheNode* newNode = new CacheNode(key, value);cacheMap[key] = newNode;addToFront(newNode);}return true;}private:int capacity; // 缓存的最大容量std::unordered_map<int, CacheNode*> cacheMap; // 键到节点的映射,用于快速查找CacheNode* head; // 头哨兵节点CacheNode* tail; // 尾哨兵节点
};int main() {// 创建一个容量为3的LRU缓存Cache lruCache(3);// 插入一些键值对lruCache.put(1, 100);lruCache.put(2, 200);lruCache.put(3, 300);// 测试获取操作assert(lruCache.get(1) == 100); // 应该返回100assert(lruCache.get(2) == 200); // 应该返回200assert(lruCache.get(4) == -1); // 不存在的键,应该返回-1// 测试缓存替换lruCache.put(4, 400); // 这会导致键3被替换assert(lruCache.get(3) == -1); // 键3被替换,应返回-1assert(lruCache.get(4) == 400); // 键4存在,应返回400// 测试更新已存在的键lruCache.put(2, 250);assert(lruCache.get(2) == 250); // 更新后的值应为250std::cout << "所有测试通过!" << std::endl;return 0;
}
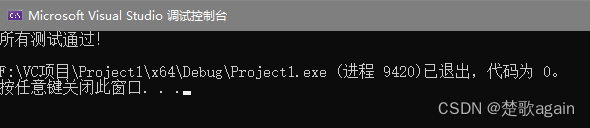
这段测试代码做了以下几件事:
- 创建LRU缓存:初始化一个容量为3的缓存。
- 插入数据:向缓存中插入几个键值对。
- 测试获取操作:验证
get方法能否正确返回值,包括检查不存在的键。 - 测试缓存替换:插入新的数据以触发LRU替换机制,并验证是否正确替换了最久未使用的数据。
- 测试更新操作:更新已存在的键的值,并检查是否正确。
assert 函数用于验证条件是否为真。如果任何 assert 失败,程序将终止执行,这意味着缓存的行为与预期不符。
你可以将这段代码与前面的LRU缓存实现代码结合起来,在C++编译器中编译并运行来测试其功能。
在C++中,explicit 关键字用于构造函数的声明,表明该构造函数是显式的。这意味着它防止了C++中的隐式类型转换或隐式调用构造函数的行为。让我们通过一个例子来解释这一点。
explicit 关键字
explicit 关键字
explicit 关键字
不使用 explicit 关键字
假设有一个类 MyClass,它有一个接受一个整数的构造函数,但没有标记为 explicit:
class MyClass {
public:MyClass(int n) { /*...*/ }
};
在这种情况下,C++编译器允许隐式转换。这意味着你可以这样写代码:
MyClass obj = 5; // 隐式调用 MyClass(int)
编译器会理解这条语句,并且隐式地调用 MyClass 的构造函数。
使用 explicit 关键字
现在,如果我们将构造函数标记为 explicit:
class MyClass {
public:explicit MyClass(int n) { /*...*/ }
};
这时,编译器不再允许隐式转换。以下代码将导致编译错误:
MyClass obj = 5; // 错误: 不能隐式转换
要创建 MyClass 的对象,你必须显式地调用构造函数:
MyClass obj(5); // 正确: 显式调用构造函数
在这个LRU的例子中
在 Cache 类中使用 explicit 关键字意味着,要创建 Cache 类的对象,必须显式地指定其容量。这有助于避免潜在的错误,如意外的隐式类型转换,使代码的意图更加明确和安全。
例如:
Cache myCache = 3; // 错误,如果构造函数是explicit
Cache myCache(3); // 正确,必须这样调用
使用 explicit 是良好的编程实践,特别是对于只接受一个参数的构造函数,以防止可能的隐式类型转换导致的错误。
相关文章:
【2024年11月份--2024精灵云校招C++笔试题】
考试形式 笔试考了三道算法题,笔试形式为阅读题目,然后用中文给出算法思路,最后给出算法例程,分数各占一半,简单,中等,复杂各一道题。我看9月份有人也是考这3道题,一模一样。 第…...
Visual Studio 2019下编译OpenCV 4.7 与OpenCV 4.7 contrib
一、环境 使用的环境是Win10,Visual Studio 2019,Cmake3.28,cdua 11.7,cudnn 8.5,如果只是在CPU环境下使用,则不用安装CUDA。要使用GPU处理,安装好CUDA之后,要测试安装的CUDA是否能用。不能正常使用的话,添加一下系统…...
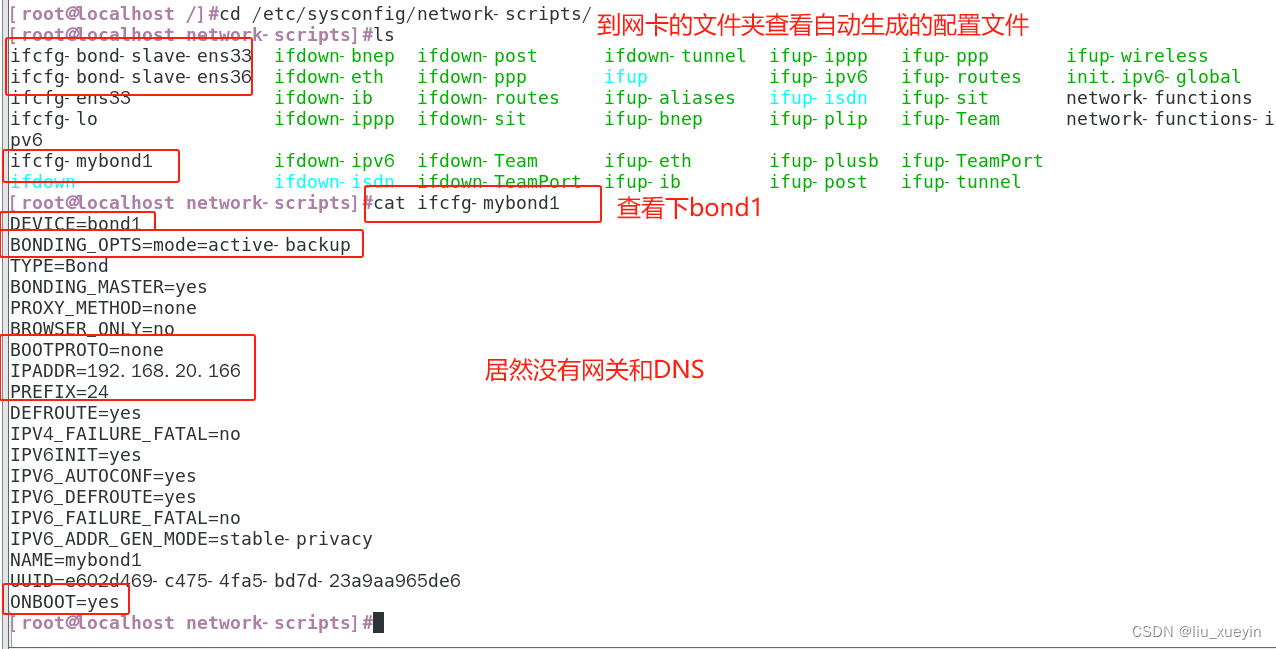
【Linux网络】系统调优之聚合链路bonding,可以实现高可用和负载均衡
一、什么是多网卡绑定 二、聚合链路的工作模式 三、实操创建bonding设备(mode1) 1、实验 2、配置文件解读 3、查看bonding状态,验证bonding的高可用效果 三、nmcli实现bonding 一、什么是多网卡绑定 将多块网卡绑定同一IP地址对外提供服务…...
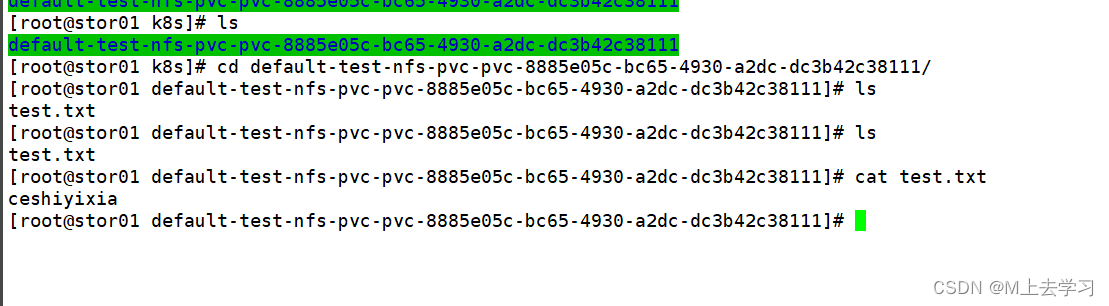
k8s持久化存储PV、PVC
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次&a…...

CocosCreator3.8原生引擎源码研究
1. Cocos Creator引擎架构图 2. 原始引擎源码流程图 下图中包含Android native层引擎到js适配层的启动和主循环的启用流程和必要说明,本猿比较懒,暂时不细述了,各位看官直接看图吧,还在细化扩充,后续逐渐更新。。。 版…...

高二英语上
unit 1 1.yarn三种意思 1.码; 2.庭院,天井; 3.花园;down**down 在这里是介词,也可以作副词,与 down 相对的是 up。请比较下列两句: 1.Look! Hes driving down the street . 2.Look! Hes driving up the street .这两例…...
JavaWeb Day10 案例 准备工作
目录 一、需求说明 二、环境搭建 (一)数据库 (二)后端 ①controller层 1.DeptController.java 2.EmpController.java ②mapper层 1.DeptMapper.java 2.EmpMapper.java ③pojo层 1.Dept.java 2.Emp.jav…...

Nginx:不同域名访问同一台机器的不同项目
Nginx很简单就可以解决同一台机器同时跑两个或者多个项目,而且都通过域名从80端口走。 以Windows环境下nginx服务为例,配置文件nginx.conf中,http中加上 include /setup/nginx-1.20.1/conf/conf.d/*.conf;删除server部分,完整如…...
:new数组时元素个数自动推到)
C++(20):new数组时元素个数自动推到
C20在new数组时可以根据初始化列表,自动推到元素个数: #include <iostream> using namespace std;int main() {int *pd new int[]{1,2,3,4};for(auto i 0; i < 4; i){cout<<pd[i]<<endl;}return 0; }运行程序输出: 1…...
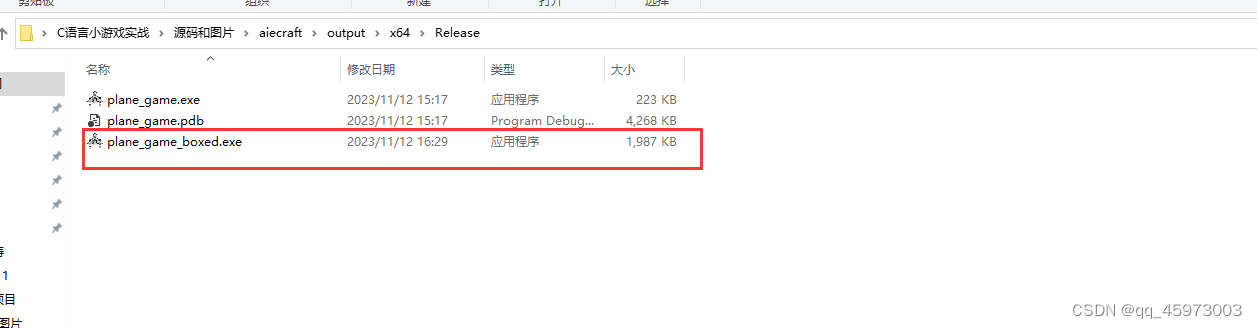
使用visualStudio发布可执行文件
编译成功后会在程序项目的路径下创建一个debug文件夹和一个release文件夹 文件夹中的具体文件入下所示 生成32位的可执行文件 32位的可执行文件可以在64位的计算机中执行,而64位的操作系统程序只能在64位的计算机中执行安装运行库的安装包根据电脑的版本选择合适的…...
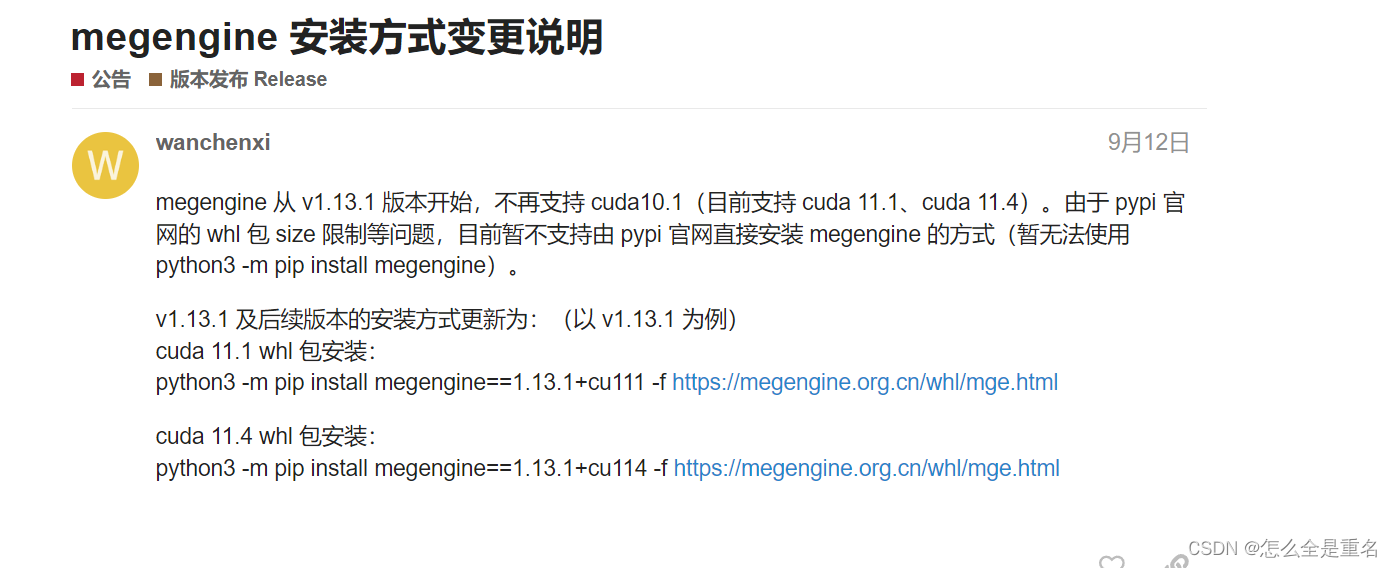
yolo系列报错(持续补充ing)
文章目录 export GIT_PYTHON_REFRESHquiet解决 没有pt权重文件解决 python文件路径报错解决 读取文件列名报错解决 导入不同文件夹出错解决 megengine没有安装解决然后你发现它竟然还没有用 export GIT_PYTHON_REFRESHquiet 设置环境变量 GIT_PYTHON_REFRESH ,这个…...
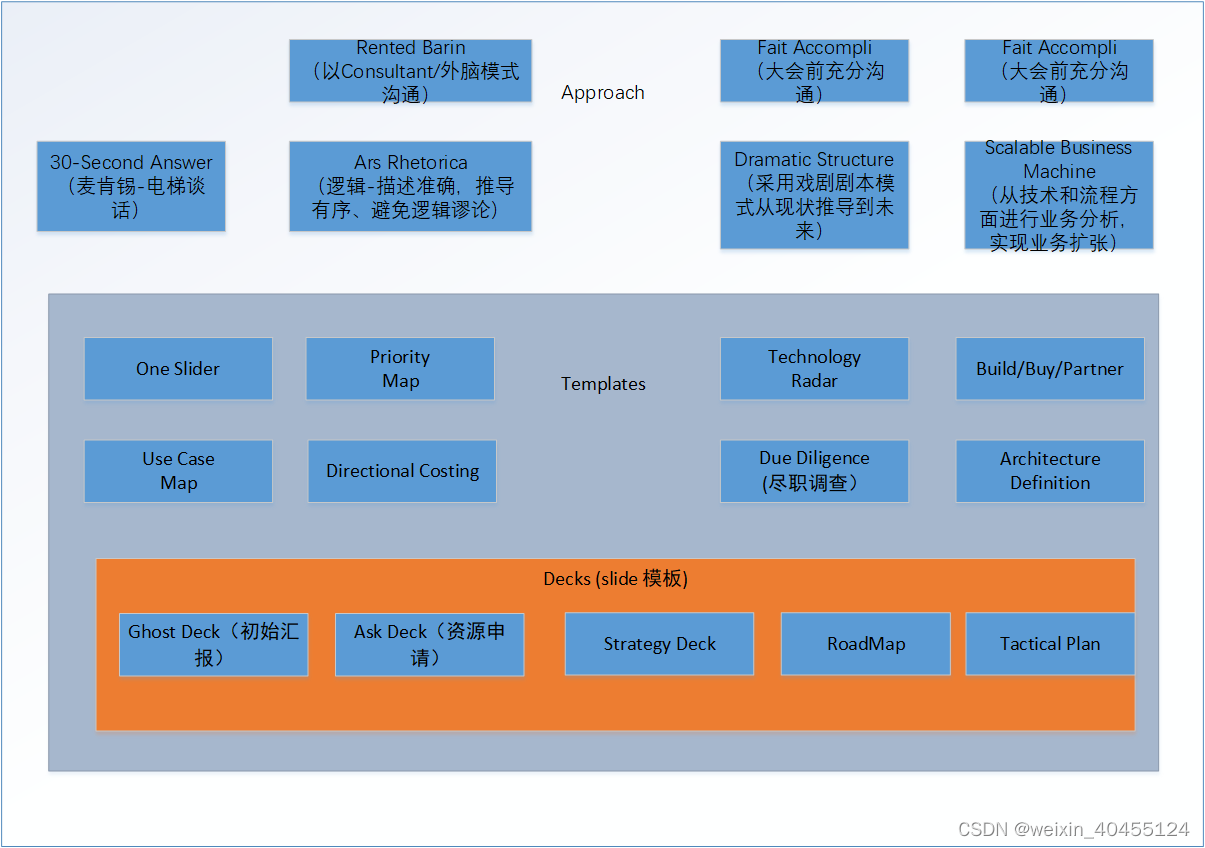
Technology Strategy Patterns 学习笔记9 - bringing it all together
1 Patterns Map 2 Creating the Strategy 2.1 Ansoff Growth Matrix 和owth-share Matrix 区别参见https://fourweekmba.com/bcg-matrix-vs-ansoff-matrix/ 3 Communicating...
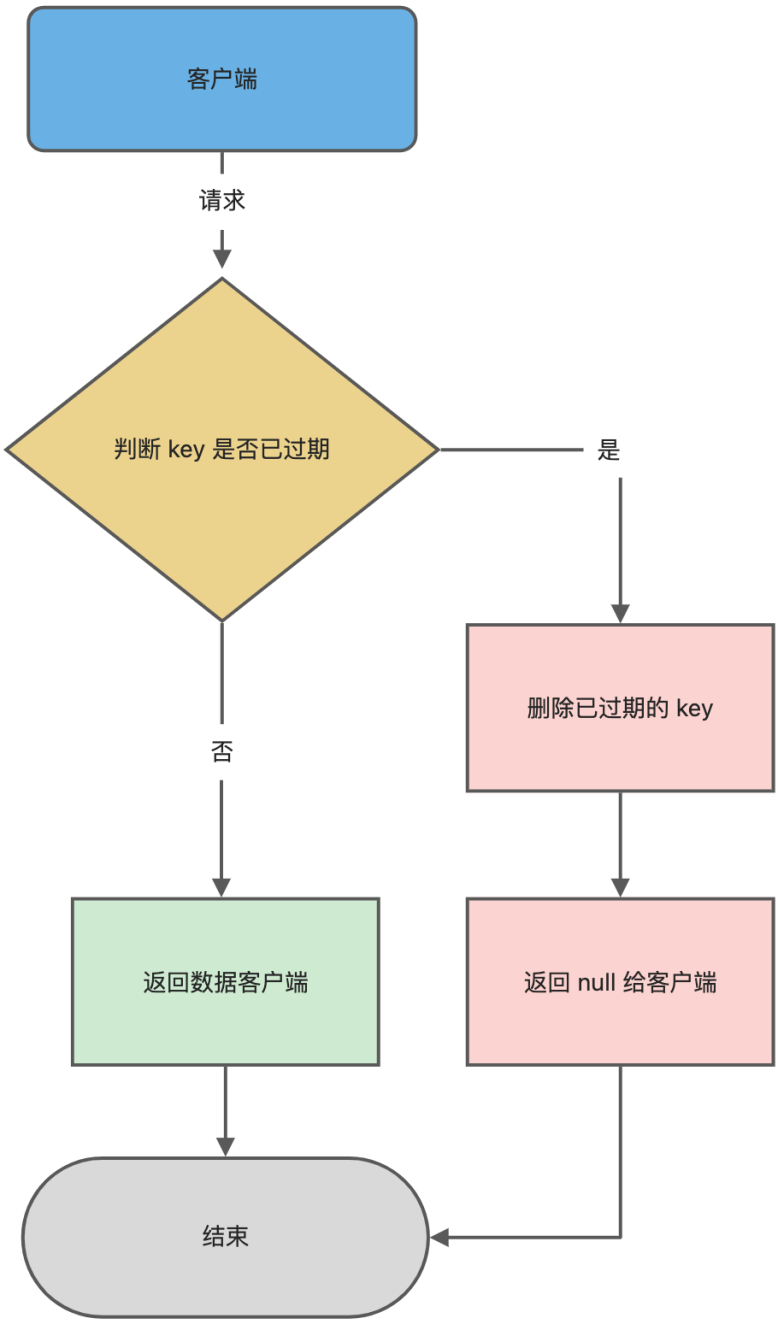
Redis(12)| 过期删除策略和内存淘汰策略
Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略。 如何设置过期时间 先说一下对 key 设置过期时间的命令。 设置 key 过期时间的命令一共有 4 个: expire key n&#x…...
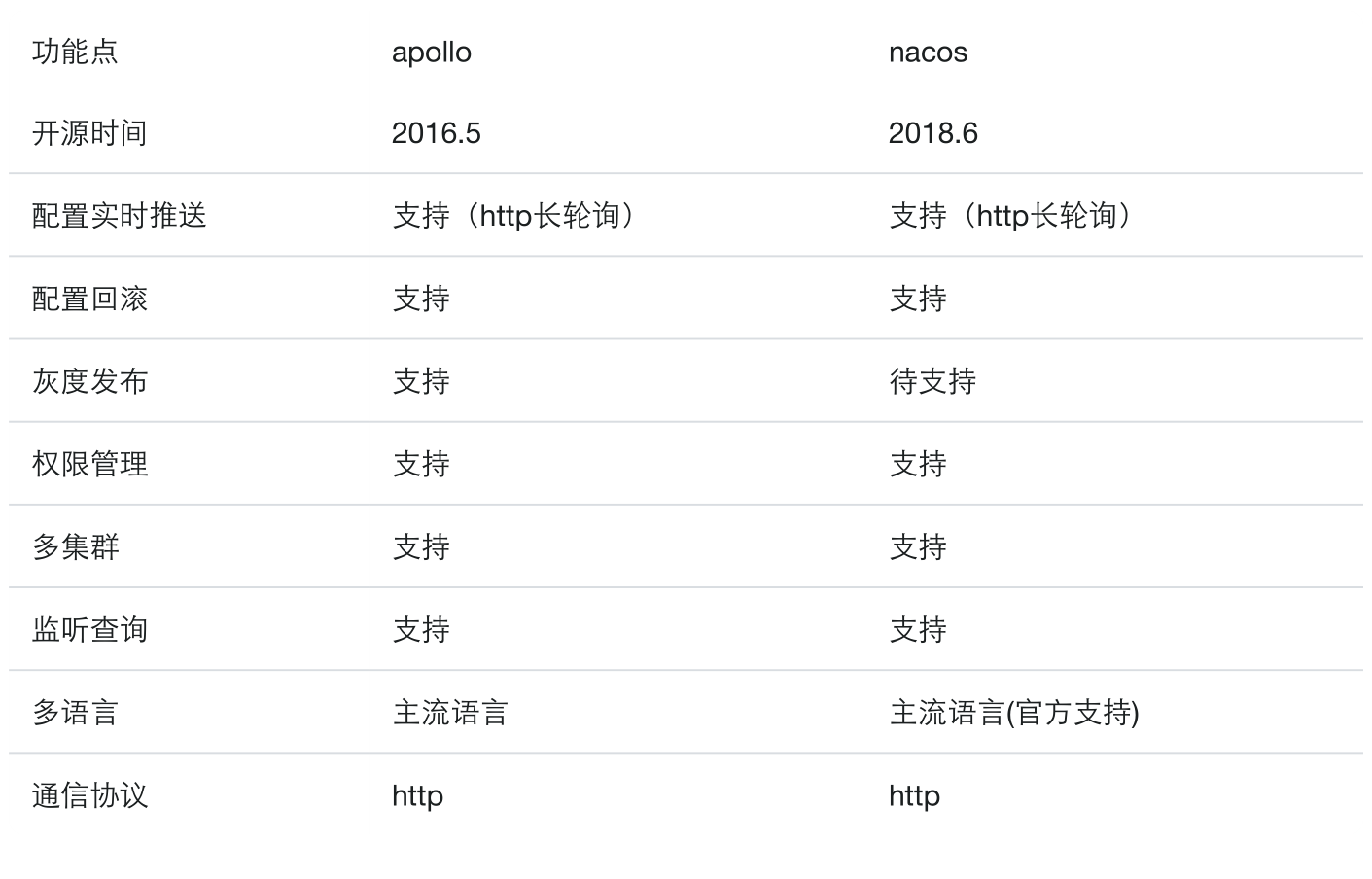
Go-服务注册和发现,负载均衡,配置中心
文章目录 什么是服务注册和发现技术选型 Consul 的安装和配置1. 安装2. 访问3. 访问dns Consul 的api接口go操作consulgrpc下的健康检查grpc的健康检查规范动态获取可用端口号 负载均衡策略1. 什么是负载均衡2. 负载均衡策略1. 集中式load balance2. 进程内load balance3. 独立…...
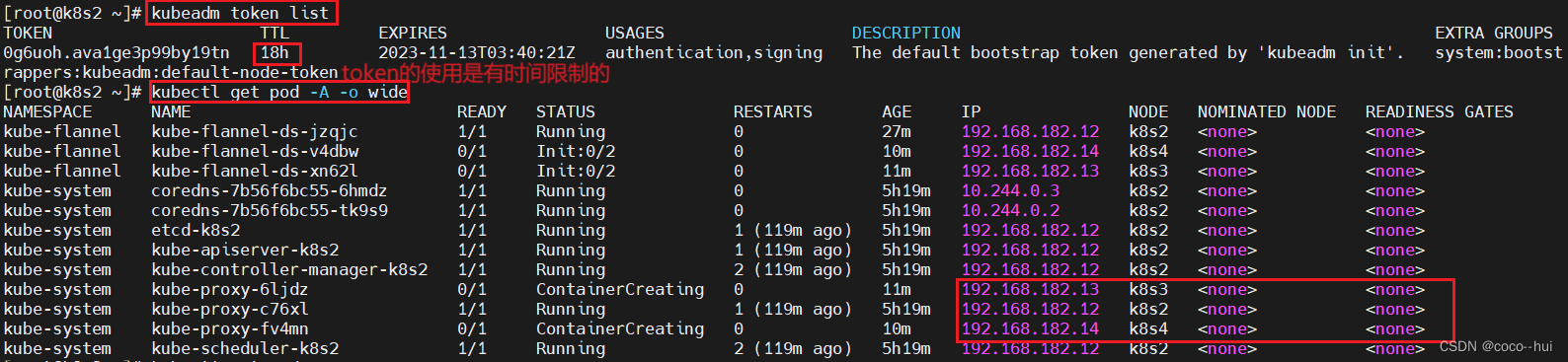
k8s-实验部署 1
1、k8s集群部署 更改所有主机名称和解析 开启四台实验主机,k8s1 仓库;k8s2 集群控制节点; k8s3 和k8s4集群工作节点; 集群环境初始化 使用k8s1作为仓库,将所有的镜像都保存在本地,不要将集群从外部走 仓库…...

Git的原理与使用(一)
目录 Git初始 Git安装 Git基本操作 创建git本地仓库 配置git 工作区,暂存区,版本库 添加文件,提交文件 查看.git文件 修改文件 版本回退 小结 Git初始 git是一个非常强大的版本控制工具.可以快速的将我们的文档和代码等进行版本管理. 下面这个实例看理解下为什么需…...
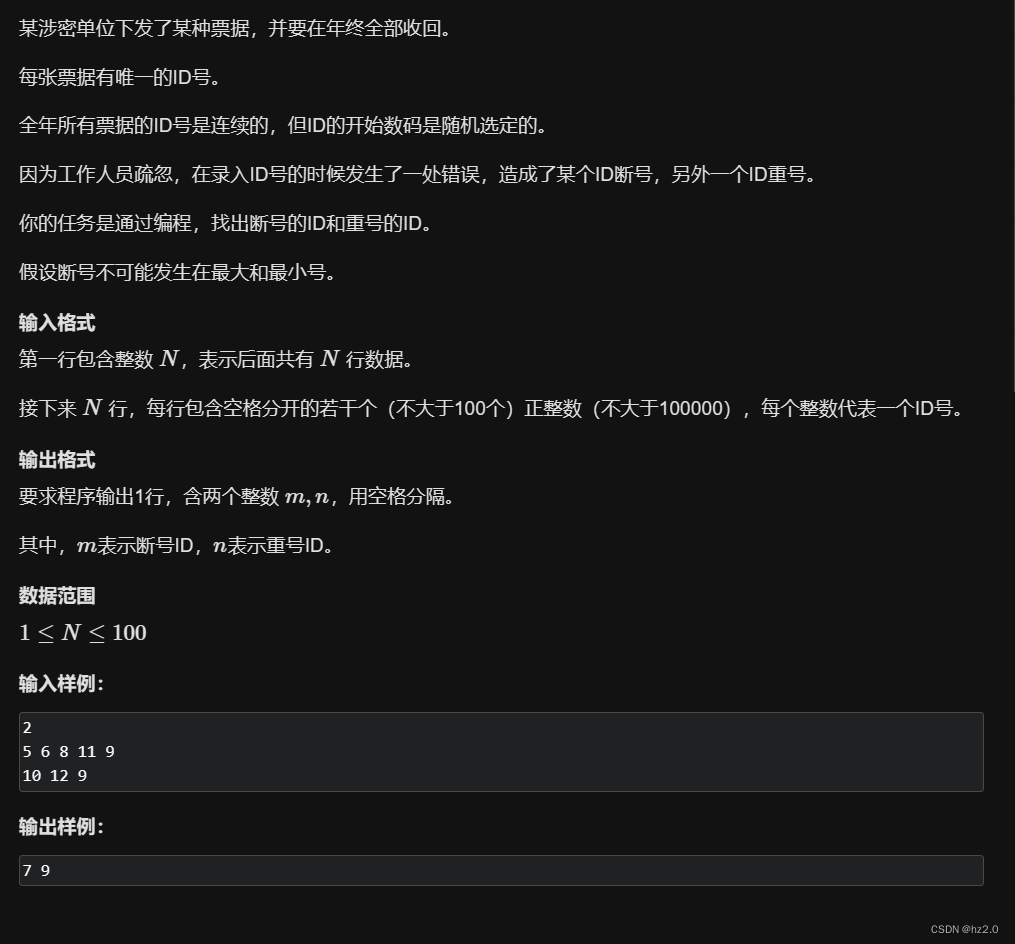
1204. 错误票据
题目: 1204. 错误票据 - AcWing题库 思路: 将输入的数据存入数组,从小到大排序后遍历,若 (a[i] a[i - 1])res1 a[i]--->重号;若(a[i] - a[i - 1] > 2)res2 a[i] - 1--->断号。 难点:题目只告诉我们输入…...

uniapp中在组件中使用被遮挡或层级显示问题
uniapp中在组件中使用或croll-view标签内使用uni-popup在真机环境下会被scroll-view兄弟元素遮挡,在开发环境下和安卓系统中可以正常显示,但在ios中出现了问题 看了许多文章都没有找到问题的原因,最后看到这一个文章http://t.csdnimg.cn/pvQ…...
windows下安装es及logstash、kibna
1、安装包下载 elasticsearch https://www.elastic.co/cn/downloads/past-releases#elasticsearch kibana安装包地址: https://www.elastic.co/cn/downloads/past-releases/kibana-8-10-4 logstash安装包地址: https://www.elastic.co/cn/downloads/past…...
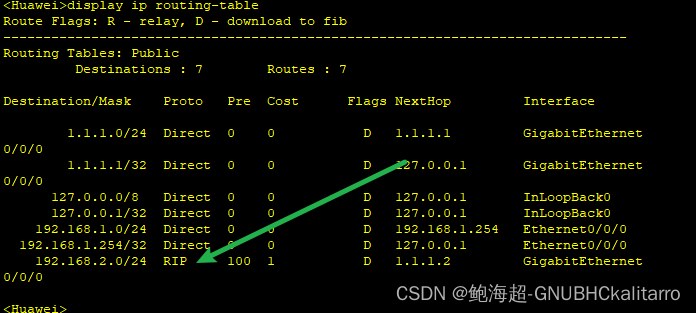
华为ensp:rip宣告
ip全部配置好 R1 进入r1视图模式 rip network 192.168.1.0 network 1.0.0.0 R2 进入r2视图模式 rip network 192.168.2.0 network 1.0.0.0 这样就完成了宣告 display ip routing-table 查看路由表...

根据WFWORKITEM 表的< PROCESSDEFNAME>字段关联WFPROCESSDEFPROPERTIES表获取对应app_code
问题描述: 根据WFWORKITEM 表的< PROCESSDEFNAME>字段关联WFPROCESSDEFPROPERTIES表获取对应app_code 解答: 因为WFPROCESSDEFPROPERTIES表在同一个<tenant_id>(租户)的<PROCESSDEFNAME>值是唯一的, 所以可…...

【AI基建团队紧急通告】:未部署动态采样+语义标注的日志系统,正 silently 丢失83%的幻觉告警信号
第一章:大模型工程化日志与可观测性方案 2026奇点智能技术大会(https://ml-summit.org) 大模型服务在生产环境中面临高并发、长推理链路、多阶段缓存与异构硬件调度等复杂性,传统单体应用的日志范式已无法满足可观测性需求。需构建覆盖输入请求、token…...

从微调到部署:如何通过对话模板对齐确保vLLM与LLaMA-Factory的推理效果一致
1. 为什么你的微调模型在vLLM上效果变差了? 最近帮几个团队排查大模型部署问题,发现一个高频痛点:在LLaMA-Factory微调好的模型,用vLLM部署后生成质量明显下降。比如有个做客服机器人的团队,微调时回答准确率能达到92%…...

LeetCode 最长回文子串:python 题解几
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

如何为MVVM应用编写高质量测试:完整测试策略
如何为MVVM应用编写高质量测试:完整测试策略 【免费下载链接】Android-MVVM-Architecture MVVM Kotlin Retrofit2 Hilt Coroutines Kotlin Flow mockK Espresso Junit5 项目地址: https://gitcode.com/gh_mirrors/mv/Android-MVVM-Architecture 在An…...

终极指南:如何用IDE Eval Resetter轻松重置JetBrains试用期
终极指南:如何用IDE Eval Resetter轻松重置JetBrains试用期 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?想继续使用IntelliJ IDEA、PyCharm或We…...

从FP32到INT4:一次搞懂LLM推理中的KV Cache量化,选对方案省一半显存
从FP32到INT4:KV Cache量化技术选型与工程实践指南 在大型语言模型(LLM)推理部署的实际场景中,GPU显存资源往往是制约服务规模扩展的关键瓶颈。KV Cache作为Transformer架构中的核心优化机制,其显存占用会随着上下文长度的增加呈线性增长&…...

别再死记硬背公式了!用Python模拟动画带你直观理解雷达的瑞利散射与米散射
用Python动画解密雷达散射:从瑞利到米氏的视觉之旅 当我在大学第一次接触雷达气象学时,那些关于散射理论的数学公式让我头疼不已——直到我发现用代码把它们变成会动的图像。本文将带你用Python重现这个"顿悟时刻",通过动态可视化理…...
在系统架构设计中的应用)
从点外卖到银行转账:用生活案例理解数据流图(DFD)在系统架构设计中的应用
从点外卖到银行转账:用生活案例理解数据流图在系统设计中的应用 中午12点,你打开外卖APP选了一份黄焖鸡米饭,点击支付后,商家接单、骑手取餐、最终送达——这个看似简单的流程背后,隐藏着一个精密的数据流动网络。就像…...

别再只用柱状图了!用Origin玩转‘柱状+点线’组合图,轻松应对论文审稿人的图表挑剔
科研图表升级指南:用Origin打造兼具数据对比与趋势分析的组合图表 在学术论文写作中,图表是研究成果最直观的呈现方式。许多研究者习惯使用单一的柱状图展示数据,但当审稿人要求同时体现数值比较和时间趋势时,这种简单图表就显得力…...