windows下安装es及logstash、kibna
1、安装包下载
elasticsearch
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
kibana安装包地址:
https://www.elastic.co/cn/downloads/past-releases/kibana-8-10-4

logstash安装包地址:
https://www.elastic.co/cn/downloads/past-releases/logstash-8-10-4

elasticsearch-analysis-ik包下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
2、解压安装包,并将elasticsearch-analysis-ik-8.10.4目录放到es的plugins目录下
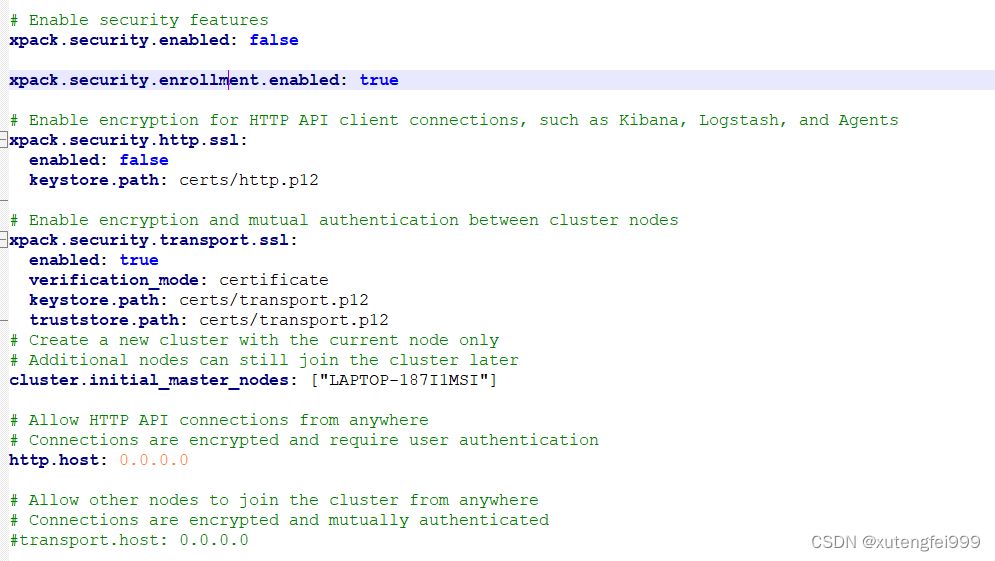
3、修改es的config目录下的elasticsearch.yml
4、在终端启动es,在bin目录下点击elasticsearch.bat
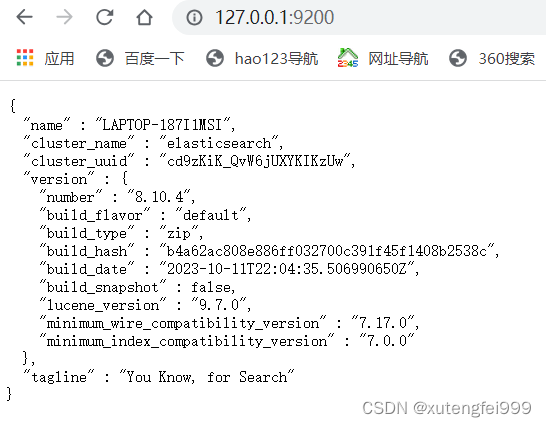
5、在浏览器上查看
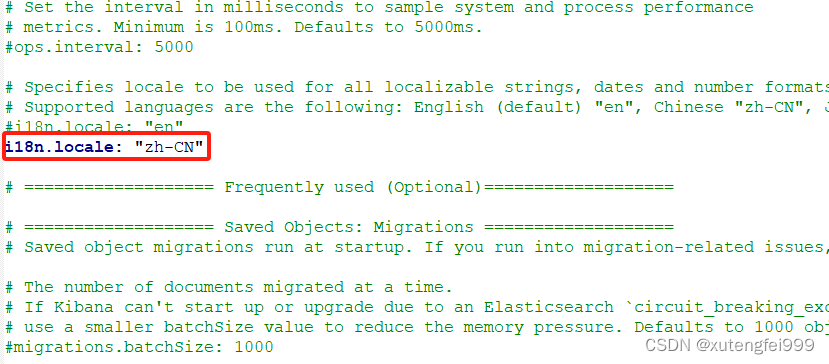
6、设置kibana的中文显示,修改kibana.yml
7、使用logstash进行mysql数据库数据同步到es配置
logstash.conf配置
# 连接到mysql数据库
input {
jdbc {
# MySQL JDBC驱动库的路径
jdbc_driver_library => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\mysql-connector-java-8.0.11.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# MySQL数据库的连接字符串
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/main_literature?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# MySQL数据库的用户名
jdbc_user => "root"
# MySQL数据库的密码
jdbc_password => "****"
# 开启分页
jdbc_paging_enabled => true
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 查询语句
statement => "SELECT * FROM literature_parsing_record WHERE id > :sql_last_value"
# 定时执行的时间间隔,这里设置为每分钟执行一次。含义:分、时、天、月、年
schedule => "* * * * *"
# 定义的类型名称,说明哪个输入到哪个输出类型,与output中的if判断值对应
type => "literature_parsing_record"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到last_run_metadata_path的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\track_id"
# 用于增量同步的字段,如果use_column_value为true,配置本参数,追踪的column名,可以是自增id或时间
tracking_column => "id"
# tracking_colum 对应字段的类型
tracking_column_type => numeric
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 列字段是否都转为小写名称
lowercase_column_names => false
# 设置时区
jdbc_default_timezone =>"Asia/Shanghai"
}
jdbc {
# MySQL JDBC驱动库的路径
jdbc_driver_library => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\mysql-connector-java-8.0.11.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# MySQL数据库的连接字符串
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/main_literature?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# MySQL数据库的用户名
jdbc_user => "root"
# MySQL数据库的密码
jdbc_password => "*****"
# 开启分页
jdbc_paging_enabled => true
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 查询语句
statement => "SELECT * FROM literature_content_record WHERE id > :sql_last_value"
# 定时执行的时间间隔,这里设置为每分钟执行一次。含义:分、时、天、月、年
schedule => "* * * * *"
# 定义的类型名称,说明哪个输入到哪个输出类型,与output中的if判断值对应
type => "literature_content_record"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到last_run_metadata_path的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\literature_content_record_track_id"
# 用于增量同步的字段,如果use_column_value为true,配置本参数,追踪的column名,可以是自增id或时间
tracking_column => "id"
# tracking_colum 对应字段的类型
tracking_column_type => numeric
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 列字段是否都转为小写名称
lowercase_column_names => false
# 设置时区
jdbc_default_timezone =>"Asia/Shanghai"
}
}
# 过滤数据
filter {
mutate {
# 移除Logstash自动生成的字段
remove_field => ["@version", "@timestamp"]
}
}
# 连接到Elasticsearch
output {
if[type]=="literature_parsing_record" {
elasticsearch {
# Elasticsearch的主机和端口
hosts => ["http://localhost:9200"]
# 写入es的索引名称
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "literature_parsing_record"
# es的文档类型名称,6.x版本可以是一个索引对应多个文档类型,不建议这么做。之后版本只支持一个索引对应一个文档类型
document_type => "doc"
# 使用数据中的id字段作为文档id
document_id => "%{id}"
# 如果使用自己配置的模板,必须配置true
# manage_template => true
#
# template_overwrite => true
# 模板名称,与定义的模板名称对应
# template_name => "literature_parsing_record"
# 使用自定义模板的文件路径,模板用于创建es的索引,决定了索引的创建方式
# template => "/opt/elasticsearch/logstash-6.6.1/template/literature_parsing_record_logstash.json"
#user => "elastic"
#password => "changeme"
}
}
if[type]=="literature_content_record" {
elasticsearch {
# Elasticsearch的主机和端口
hosts => ["http://localhost:9200"]
# 写入es的索引名称
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "literature_content_record"
# es的文档类型名称,6.x版本可以是一个索引对应多个文档类型,不建议这么做。之后版本只支持一个索引对应一个文档类型
document_type => "doc"
# 使用数据中的id字段作为文档id
document_id => "%{id}"
# 如果使用自己配置的模板,必须配置true
# manage_template => true
#
# template_overwrite => true
# 模板名称,与定义的模板名称对应
# template_name => "literature_content_record"
# 使用自定义模板的文件路径,模板用于创建es的索引,决定了索引的创建方式
# template => "/opt/elasticsearch/logstash-6.6.1/template/literature_content_record_logstash.json"
#user => "elastic"
#password => "changeme"
}
}
stdout {
codec => json_lines
}
}
8.下载mysql-connector-java-8.0.11.jar,放到配置的路径下
9、在终端启动logstash就可以进行数据同步了
logstash -f D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\logstash.conf
10、在bin目录下启动kibana
11、点击开发工具查看

12、查看es中的数据
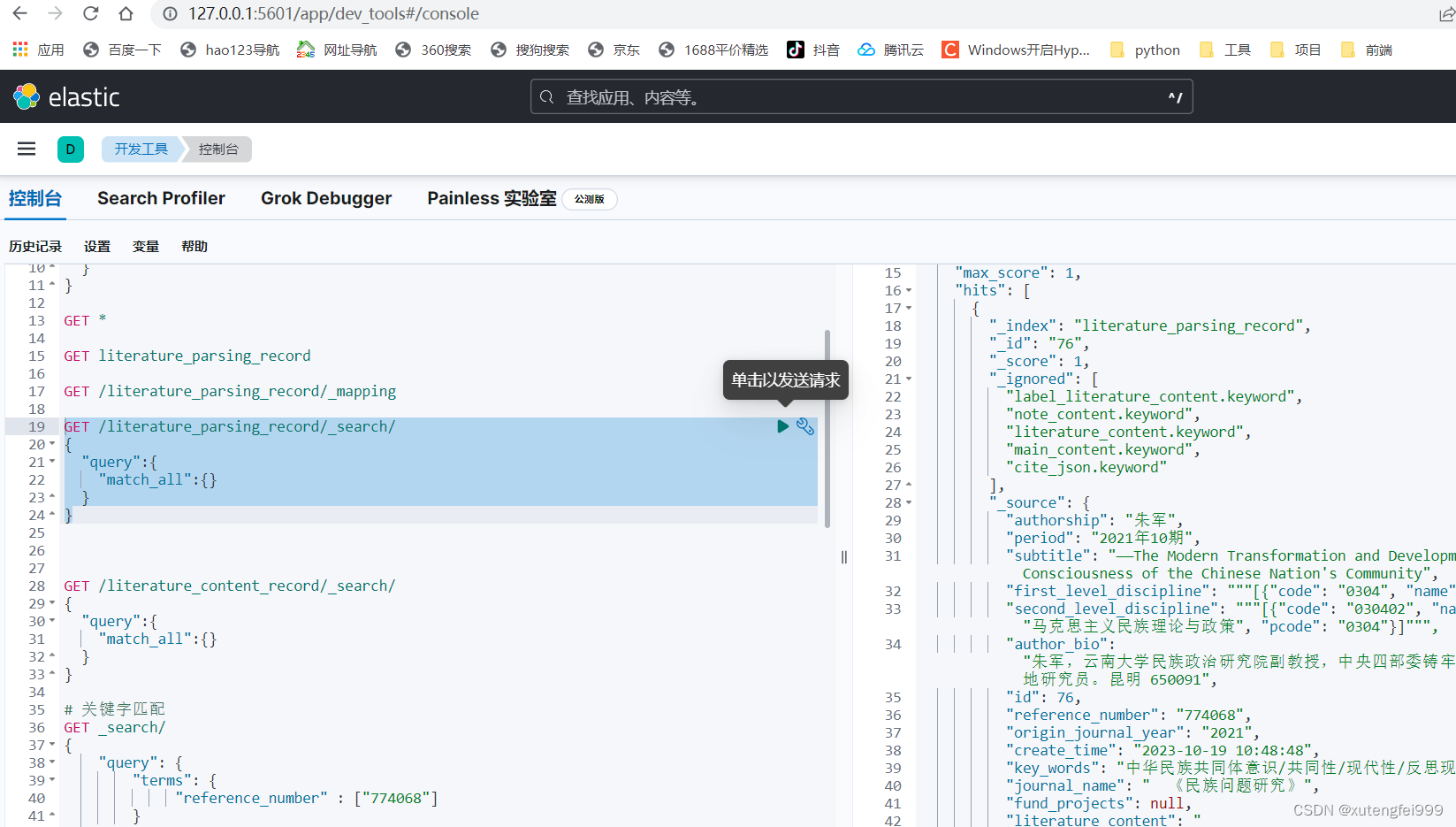
相关文章:
windows下安装es及logstash、kibna
1、安装包下载 elasticsearch https://www.elastic.co/cn/downloads/past-releases#elasticsearch kibana安装包地址: https://www.elastic.co/cn/downloads/past-releases/kibana-8-10-4 logstash安装包地址: https://www.elastic.co/cn/downloads/past…...
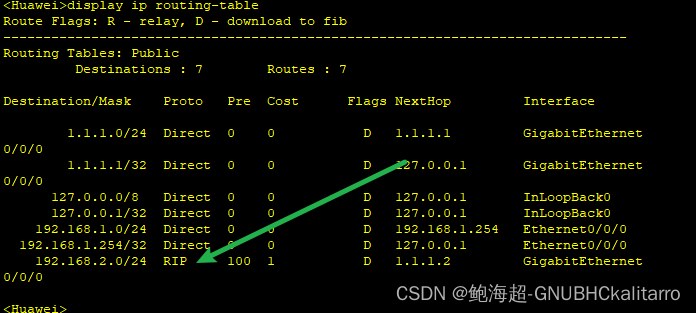
华为ensp:rip宣告
ip全部配置好 R1 进入r1视图模式 rip network 192.168.1.0 network 1.0.0.0 R2 进入r2视图模式 rip network 192.168.2.0 network 1.0.0.0 这样就完成了宣告 display ip routing-table 查看路由表...
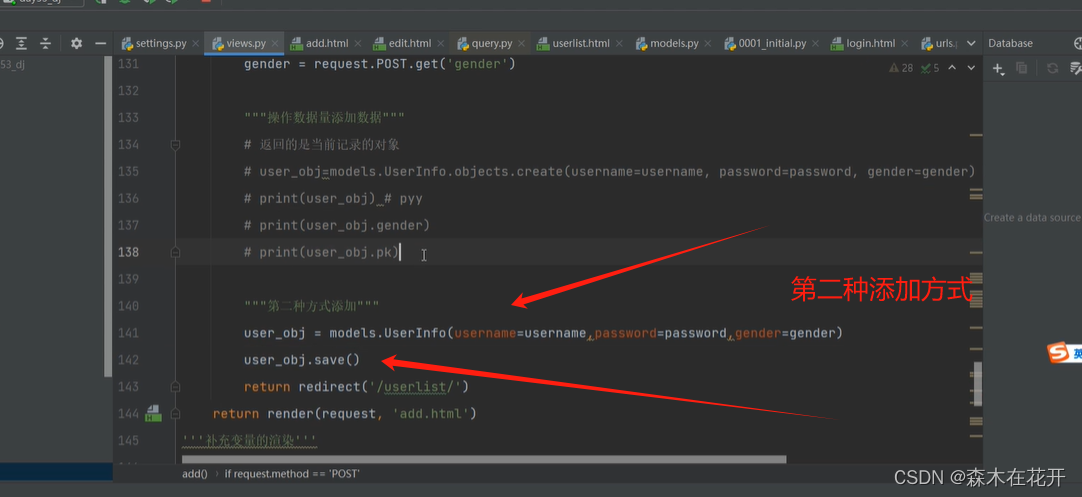
Django中简单的增删改查
用户列表展示 建立列表 views.py def userlist(request):return render(request,userlist.html) urls.py urlpatterns [path(admin/, admin.site.urls),path(userlist/, views.userlist), ]templates----userlist.html <!DOCTYPE html> <html lang"en">…...

HCIE-Rainbow迁移工具
Rainbow迁移工具 Rainbow迁移工具支持p2v(物理机到虚拟机的迁移) v2v(虚拟机到虚拟机的迁移) Rainbow迁移是整机迁移,不会单独迁移上层的业务,也不会单独迁移数据,只会迁移整个虚拟机或者磁盘。…...

AI 绘画 | Stable Diffusion 涂鸦功能与局部重绘
在 StableDiffusion图生图的面板里,除了图生图(img2img)选卡外,还有局部重绘(Inpaint),涂鸦(Sketch),涂鸦重绘(Inpaint Sketch),上传重绘蒙版(Inpaint Uplaod)、批量处理(…...
[LeetCode周赛复盘] 第 371 场周赛20231112
[LeetCode周赛复盘] 第 371 场周赛20231112 一、本周周赛总结100120. 找出强数对的最大异或值 I1. 题目描述2. 思路分析3. 代码实现 100128. 高访问员工1. 题目描述2. 思路分析3. 代码实现 100117. 最大化数组末位元素的最少操作次数1. 题目描述2. 思路分析3. 代码实现 100124…...

Google Guava Cache LoadingCache 基本使用
一. 添加依赖 <dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>27.1-jre</version> </dependency>二. 创建CacheLoader LoadingCache<Long, String> cache CacheBuilder.newB…...
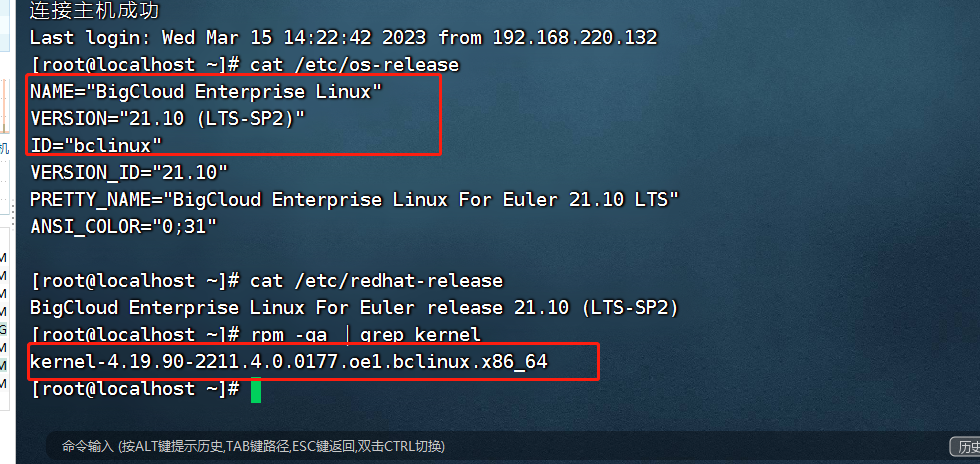
AWS云服务器EC2实例进行操作系统迁移
AWS云服务器EC2实例进行操作系统迁移 文章目录 AWS云服务器EC2实例进行操作系统迁移1. 亚马逊EC2云服务器简介1.2 亚马逊EC2云务器与弹性云服务器区别 2. 亚马逊EC2云服务器配置流程2.1 亚马逊EC2云服务器实例配置2.1.1 EC2实例购买教程2.1.1 EC2实例初始化配置2.1.2 远程登录E…...
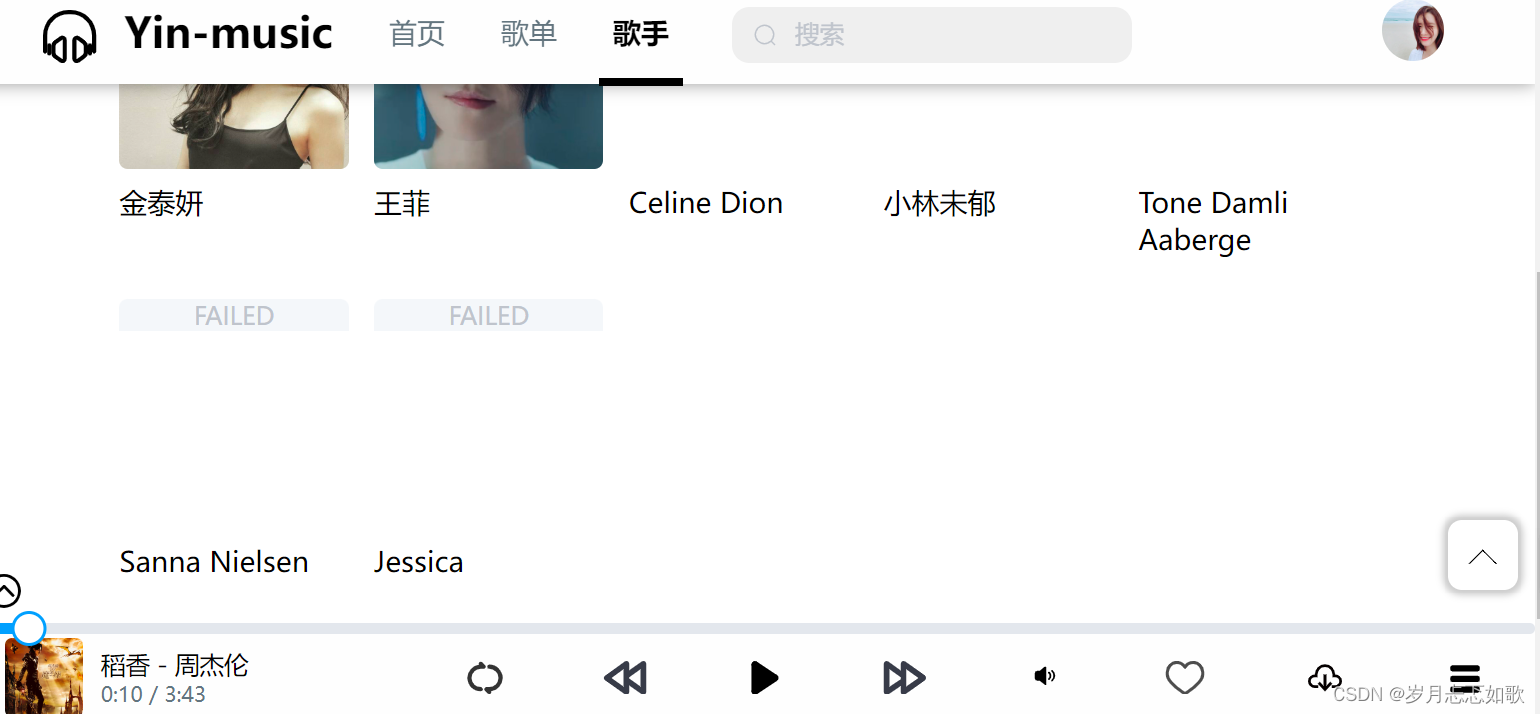
《015.SpringBoot+vue之音乐网》【前后端分离】
《015.SpringBootvue之音乐网》【前后端分离】 项目简介 [1]本系统涉及到的技术主要如下: 推荐环境配置:DEA jdk1.8 Maven MySQL 前后端分离; 后台:SpringBootMybatisMySQL; 前台:Vue3.0 TypeScript Vue-Router Vuex Axios …...

网格算法和穷举法
介绍 网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具 当需要在多个离散的点(比如网格点)…...

【AI】自回归 (AR) 模型使预测和深度学习变得简单
自回归 (AR) 模型是统计和时间序列模型,用于根据数据点的先前值进行分析和预测。这些模型广泛应用于各个领域,包括经济、金融、信号处理和自然语言处理。 自回归模型假设给定时间变量的值与其过去的值线性相关,这使得它们可用于建模和预测时…...
)
安卓常见设计模式14------单例模式(Kotlin版)
1. W1 是什么,什么是单例模式? 单例模式属于创建型模式,旨在确保一个类只有一个实例,并提供一个全局访问点来获取该实例。单例模式的核心思想是限制类的实例化,使得系统中只有一个共享的实例。 2. W2 为什么&#…...
一维卡尔曼滤波编程实践)
卡尔曼家族从零解剖-(06)一维卡尔曼滤波编程实践
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的 卡尔曼家族从零解剖 链接 :卡尔曼家族从零解剖-(00)目录最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/133846882 文末正下方中心提供了本人 联系…...

macOS使用conda初体会
最近在扫盲测序的一些知识 其中需要安装一些软件进行练习,如质控的fastqc,然后需要用conda来配置环境变量和安装软件。记录一下方便后续查阅学习 1.安装miniconda 由于我的电脑之前已经安装了brew,所以我就直接用brew安装了 brew install …...

GetPrivateProfileSection使用
基本语法 GetPrivateProfileSection 是一个 Windows API 函数,用于检索指定 INI 文件中特定节的所有键值对。它可以读取INI文件中指定节所有的键值对并将结果存储在指定的缓冲区中。 以下是 GetPrivateProfileSection 函数的基本语法: DWORD GetPriva…...

Ubuntu20.04 安装 Matlab R2021a
1. 压缩包分卷解压缩 将下载下来的压缩包分卷解压缩 Ubuntu自带的archive会解压出错,不适用于分卷解压。 需要下载7zip (sudo apt-get install 走起) zip -F xxx.zip --out XXX.zip # xxx为主文件名 # XXX.zip为输出路径,上面的…...

让35岁程序员精力充沛的方法
最近重新阅读了《掌控:开启不疲惫、不焦虑的人生》这本书。这本书曾经对我减重20斤产生了巨大的影响。自然入睡、自然醒来,能够高效地工作和享受生活,这才是我们渴望的掌控感。以下是一些笔记: 少吃比多运动更有效地控制体重 每…...
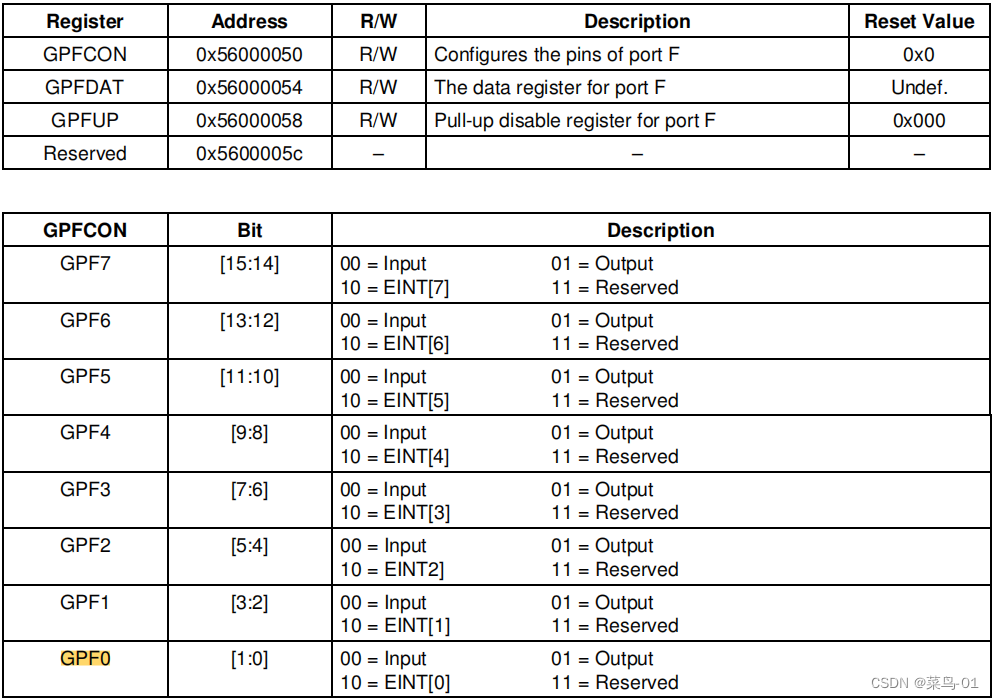
01:2440----点灯大师
目录 一:点亮一个LED 1:原理图 2:寄存器 3:2440的框架和启动过程 A:框架 B:启动过程 4:代码 5:ARM知识补充 6:c语言和汇编的应用 A:代码 B:分析汇编语言 C:内存空间 7:内部机制 二:点亮2个灯 三:流水灯 四:按键控制LED 1:原理图 2:寄存器配置 3:代码 一:点…...
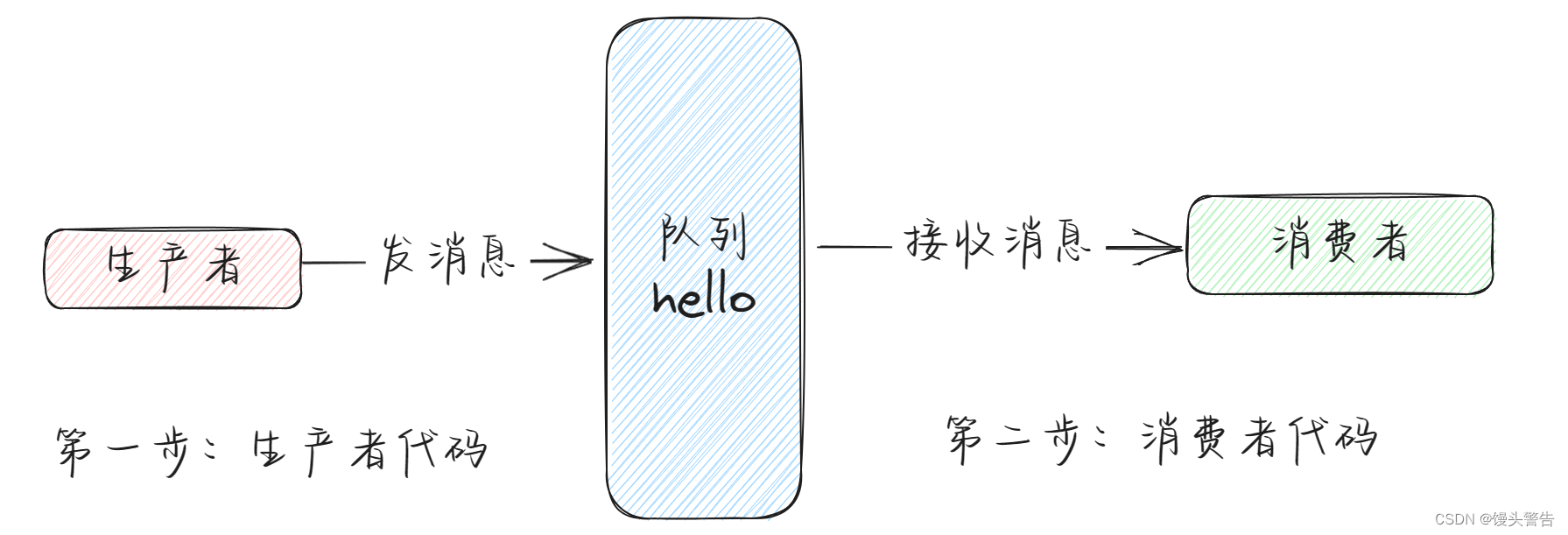
初步了解 RabbitMQ
目录 编辑一、MQ 概述 1、MQ 的简介 2、MQ 的用途 (1)限流削峰 (2)异步解耦 (3)数据收集 二、RabbitMQ 概述 1、RabbitMQ 简介 2、四大核心概念 3、RabbitMQ 的核心部分 编辑 4、名词解释: 三、Hello …...

Faster-RCNN and Mask-RCNN框架解析
由于本人记忆力实在太差,每次学完一个框架没过多久就会忘,而且码文能力不行,人又懒,所以看到了其他人写的不错的两篇框架解析的博文,先来记录一下,就当是我写的喽 Faster-rcnn详解_faster r-cnn-CSDN博客 M…...

PowerToys终极指南:5个技巧解决Windows效率工具常见问题
PowerToys终极指南:5个技巧解决Windows效率工具常见问题 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/PowerTo…...

如何快速掌握PDF差异对比工具:diff-pdf终极指南
如何快速掌握PDF差异对比工具:diff-pdf终极指南 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 你是否曾为PDF文档的版本管理而头疼?面对两份相似的PDF文…...

从R-JPEG到温度热图:手把手教你用大疆TSDK和Pix4D mapper生成红外正射影像
从R-JPEG到温度热图:大疆TSDK与Pix4D mapper红外正射影像全流程解析 在农业病虫害监测、电力设备巡检、建筑热工缺陷检测等领域,红外热成像技术正逐渐成为行业标配。但单张红外照片的温度分析存在视角局限,而传统热像仪又难以实现大范围精准测…...

Nanbeige 4.1-3B极简WebUI惊艳案例:浅灰蓝波点背景下的沉浸对话
Nanbeige 4.1-3B极简WebUI惊艳案例:浅灰蓝波点背景下的沉浸对话 厌倦了千篇一律、布局死板的大模型对话界面吗?今天,我想和你分享一个让我眼前一亮的项目——一个专为Nanbeige 4.1-3B模型打造的本地Web交互界面。它没有复杂的侧边栏…...

WeMos开发板
这是Arduino IDE的提示信息,表示还没有连接开发板。你需要:1. 连接WeMos开发板 到电脑的USB端口 2. 安装CH340G驱动 (如果还没安装) 3. 选择正确的开发板和端口 :- 点击「工具」→「开发板」→选择「LOLIN(WEMOS) D1 R…...

艾尔登法环终极优化指南:解锁帧率与游戏增强的完整教程
艾尔登法环终极优化指南:解锁帧率与游戏增强的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/El…...

bitcoin-arbitrage自动化交易实战:TraderBot和TraderBotSim详解
bitcoin-arbitrage自动化交易实战:TraderBot和TraderBotSim详解 【免费下载链接】bitcoin-arbitrage Bitcoin arbitrage - opportunity detector 项目地址: https://gitcode.com/gh_mirrors/bi/bitcoin-arbitrage 在加密货币交易领域,利用不同交易…...

ARM-驱动-03 Linux 字符设备驱动开发
一、驱动程序基础概念 1. 驱动程序的本质 驱动程序本质上就是操作硬件的程序,和裸机开发中写的 BSP 代码干的是同一件事——直接控制寄存器、管理外设。 区别在于: 裸机开发:驱动和应用代码混在一起写,没有明确的分层,…...

M2LOrder模型.NET Core后端集成实战教程
M2LOrder模型.NET Core后端集成实战教程 如果你是一个.NET开发者,最近想在自己的WebAPI项目里加个情绪识别的功能,比如分析用户评论是正面还是负面,或者看看客服对话里用户的情绪怎么样,那你可能听说过M2LOrder模型。这名字听起来…...

Windows 11硬件限制完全绕过指南:3种方法让老旧电脑焕发新生
Windows 11硬件限制完全绕过指南:3种方法让老旧电脑焕发新生 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...