【数据结构】深度剖析ArrayList
目录
ArrayLIst介绍
ArrayList实现的接口有哪些?
ArrayList的序列化:实现Serializable接口
serialVersionUID 有什么用?
为什么一定要实现Serialzable才能被序列化?
transient关键字
为什么ArrayList中的elementData会被transient修饰?
ArrayList的克隆:实现Cloneable接口(实现的是浅克隆)
modCount的作用
关于对expectedModCount和modCount的说明:
modCount不是可以检查并发操作吗?为什么ArrayList不是线程安全的?
既然ArrayList都让迭代器检查是否存在并发了,为什么不在普通add时候检查?这样不就让ArrayList实现线程安全了吗?
那么在迭代器遍历检查并发修改时候,会不会存在ABA问题?
延申:关于迭代器——Iterator遍历时不可以删除集合中的元素问题
ArrayList的扩容机制
默认不传参时候是怎么扩容的:
当传参时候等于0的时候
当数组长度达到10的时候,是如何扩容的:
ArrayList也不是不限制的扩容
对ArrayList进行排序—— Collections.sort
在探讨ArrayList之前,我们先来看看顺序表和线性表:
① 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列.....
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
② 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
ArrayLIst介绍
ArrayLIst是一种线性表的数据结构,底层是基于动态数组实现,因此提供了一种有效地管理元素序列的方法。您可以根据需要添加、删除或访问列表中的元素。
与顺序表不同,ArrayLIst的底层实现并不是使用连续的内存空间存储元素。它使用动态数组,可以动态调整大小以容纳更多或更少的元素。这使得 ArrayLIst更加灵活,因为它不需要预先分配固定大小的内存,而是根据需要自动扩展或收缩。
ArrayList实现的接口有哪些?
在集合框架中,ArrayList是一个普通的类,实现了List接口,具体框架图如下:

- ArrayList实现了RandomAccess接口,表明ArrayList支持随机访问
- ArrayList实现了Cloneable接口,表明ArrayList是可以clone的
- ArrayList实现了Serializable接口,表明ArrayList是支持序列化的
- 和Vector不同,ArrayList不是线程安全的,在单线程下可以使用,在多线程中可以选择Vector或者CopyOnWriteArrayList
- ArrayList底层是一段连续的空间,并且可以动态扩容,是一个动态类型的顺序表
ArrayList的序列化:实现Serializable接口
可能很多人想问,Java 中如何实现序列化?
其实很简单,只需要通过实现 Serializable 接口来实现序列化即可,Serializable 接口本身并没有定义任何方法,它只是一个标记接口 (marker interface) ,用于告诉编译器和运行时环境这个类可以被序列化和反序列化。
Serializable源码如下:

当然,一般在实现序列话的同时,需要给其添加一个serialVersionUID。
serialVersionUID 有什么用?
答: serialVersionUID 是用来进行版本控制的静态字段,是为了防止不同版本类冲突以及类安全的
具体来说,在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是 InvalidCastException。这样做是为了保证安全,因为文件存储中的内容可能被算改。
为什么一定要实现Serialzable才能被序列化?
① 性能开销:序列化和反席列化操作可能涉及复杂的数据处理和字节转换。如果所有类默认都是可序列化的,会导致在创建对象时会增加额外的开销,包括生成和处理不必要的序列化字节流
a.序列化的流程:
Ⅰ. 创建一个 ObjectOutputStream 对象
Ⅱ. 调用 writeObiect 方法,将对象及其属性序列化成字节流。
Ⅲ. 字节流被写入输出流 (例如文件、网络连接等)
b.反序列化的流程:
Ⅰ. 创建一个 ObjectlnputStream 对象
Ⅱ. 调用 readobject() 方法,从输入流中读取字节流,并将其反序列化为对象。
Ⅲ. 强制转换返回的对象为原始类型.
② 安全性:不是所有类的实例都应该被序列化和传输。一些类可能包合敏感信息,如果默认是可序列化的可能会导致数据泄露的风险。需要开发者明确指定哪些类可以被序列化,以确保安全性。
我们来看看ArrayList里面的序列化

transient关键字
-
transient 关键字的作用: 当一个字段被标记为 transient 时,它不会被包括在对象的序列化表示中。这意味着在将对象序列化为字节流时,该字段的值不会被保存。在对象反序列化时,该字段会被初始化为其默认值(例如,null 对于对象引用,0 对于数值类型)。
-
使用场景: transient 主要用于那些不需要被序列化的字段,通常是因为这些字段包含临时或敏感数据,或者它们的值可以在反序列化后重新计算。一些常见的使用场景包括:
- 缓存字段:避免将缓存字段的内容序列化,因为它们的内容可能在不同的环境中发生变化。
- 敏感信息:避免将包含密码、密钥或敏感数据的字段序列化,以减少安全风险。
- 临时计算结果:避免将可以在反序列化后重新计算的字段序列化,以减小序列化对象的大小。
为什么ArrayList中的elementData会被transient修饰?
ArrayList 中的 Object[] elementData字段被标记为 transient 是因为它是为了优化序列化过程和减小序列化后的对象大小而采取的一种策略。(也就是上述使用场景的第三点)
在序列化时,elementData 数组通常会包含大量的null 值,因为 ArrayList 内部的数组可能会分配比实际元素数量多的空间,以容纳未来的元素。这些额外的 null 值可能会占据大量的存储空间,因此标记 elementData 为 transient 可以避免序列化这些不必要的 null 值,从而减小序列化后对象的大小,提高序列化性能。
当进行反序列化时,ArrayList 的 elementData 数组会根据实际需要自动恢复,因此不需要序列化这个数组的内容。这是由 ArrayList 的反序列化机制来处理的。
ArrayList的克隆:实现Cloneable接口(实现的是浅克隆)
源码如下:

这段代码是ArrayList类中的clone()方法的实现。它用于创建并返回一个ArrayList的浅拷贝副本。
下面对这段代码进行分析:
-
首先,通过调用super.clone()方法创建一个ArrayList对象v,它是当前ArrayList对象的浅拷贝副本。super.clone是Object类中的一个受保护(底层是C++代码实现的:被native修饰)的方法,实现了对象的浅拷贝。
-
接下来,使用Arrays.copyOf()方法将原ArrayList对象的内部数组 elementData 复制到新的ArrayList对象的内部数组中。Arrays.copyOf() 方法会创建一个新的数组,并将原数组的元素复制到新数组中。
-
然后,将新的ArrayList对象的size属性设置为原ArrayList对象的size属性值,以确保新对象具有相同的元素数量。
-
将新的ArrayList对象的modCount属性设置为0。modCount用于记录ArrayList的修改次数,主要用于在迭代器遍历时检测并发修改。
-
最后,返回新创建的ArrayList对象v作为克隆副本。
需要注意的是,这里的拷贝是浅拷贝,即新的ArrayList对象和原对象共享相同的元素引用。如果元素是可变对象,并且在克隆后的ArrayList中进行了修改,那么原始ArrayList中的对应元素也会受到影响。
modCount的作用
前置知识:
在多线程环境中,迭代器通常会对集合进行快照,以避免并发修改引起的问题。这一点在Java的ArrayList等集合类中体现得比较明显:当你创建一个迭代器并开始遍历ArrayList时,迭代器会记录当前的modCount值和元素。在迭代过程中,如果ArrayList的modCount值发生了变化,迭代器会检测到这个变化,并在hasNext()、next()等方法中引发ConcurrentModificationException异常,以防止在并发修改的情况下继续迭代。
modCount是ArrayList类中的一个属性(从父类AbstractList继承的),是用来记录对ArrayList进行结构性修改(进行添加、删除或清空等操作时,会增加modCount的值)的次数的一个计数器。
它的作用主要有两个方面:
- 迭代器的并发修改检测:在ArrayList的迭代器遍历过程中,会记录迭代器创建时的modCount值为expectedModCount。在每次迭代操作期间,都会检查modCount是否与expectedModCount相等。如果不相等,就表示在迭代过程中,有其他线程对ArrayList进行了结构性修改,可能导致迭代结果不准确或出现并发修改的问题。这时,迭代器会抛出ConcurrentModificationException异常,以提醒使用者发生了并发修改。
- 序列化与反序列化:modCount还在ArrayList的序列化和反序列化过程中起到一定的作用。在反序列化时,会使用readObject()方法恢复ArrayList对象,而readObject()方法会检查modCount与反序列化数据中的modCount是否一致,以确保反序列化的对象与序列化时的对象相一致。如果modCount不一致,可能表示反序列化数据与原始数据发生了不匹配,可能导致数据的不一致性。
需要注意的是,modCount只记录结构性修改的次数,即对ArrayList的添加、删除等操作。
它不会记录对元素值的修改,因此如果仅修改ArrayList中元素的属性而不改变结构,modCount的值不会增加。
总结:
- modCount是ArrayList中用于记录结构性修改次数的属性,用于在迭代器遍历过程中检测并发修改。它可以帮助捕获并发修改导致的潜在问题,确保迭代器遍历过程的安全性。
- 因此,在ArrayList中,modCount实际上是从AbstractCollection继承而来的,而expectedModCount是在AbstractList中定义的,用于迭代器的并发修改检测。
关于对expectedModCount和modCount的说明:
在AbstractList 类中,有一个expectedModCount的变量,用于在迭代器遍历过程中记录迭代器创建时的modCount值。这个变量用于与当前的modCount进行比较,以检测并发修改。

modCount 在 ArrayList 的父类 AbstractList 中被定义:

modCount不是可以检查并发操作吗?为什么ArrayList不是线程安全的?
尽管ArrayList内部使用了modCount来检测并发修改,但它并不能确保并发操作的安全性。
ArrayList的modCount机制主要用于在迭代器遍历过程中检测并发修改,并尽早发现潜在的并发修改问题。如果在迭代器遍历过程中,有其他线程对ArrayList进行了结构性修改,就会抛出ConcurrentModificationException异常。这种机制能够帮助迭代器及时发现并发修改,但并不能阻止并发修改的发生。
这是因为,除了迭代器遍历外,其他线程仍然可以直接修改ArrayList的结构,而不会引发异常。这就意味着,在多线程环境下,两个线程通过非迭代器的方式修改结构(例如add,remove等操作),就有可能导致迭代过程中的不确定行为或数据不一致性。
如果需要在多线程环境下使用ArrayList,并确保线程安全,可以采取以下措施之一:
- 使用线程安全的替代类:Java提供了一些线程安全的集合类,例如Vector和CopyOnWriteArrayList,它们可以作为ArrayList的线程安全替代品。
- 手动同步:可以通过在多线程访问ArrayList时使用显式的同步机制(如synchronized关键字或使用锁)来保护共享的ArrayList实例,确保在并发访问时的线程安全性。
小结:尽管ArrayList使用modCount来检测并发修改,但它仍然被认为是线程不安全的数据结构。在多线程环境中,需要采取额外的措施来保证线程安全,如使用线程安全的替代类或手动进行同步操作。
既然ArrayList都让迭代器检查是否存在并发了,为什么不在普通add时候检查?这样不就让ArrayList实现线程安全了吗?
在ArrayList中之所以在迭代器中检查是否存在并发修改,而不在普通add等方法中进行检查,是因为ArrayList的设计是针对性能优化的,它旨在提供高效的随机访问和修改操作。在多线程环境中,要保证线程安全会引入额外的同步开销,可能会降低性能。
因此,通常情况下:ArrayList是用于单线程环境的集合,因此在设计上假设只有一个线程会修改它。
那么在迭代器遍历检查并发修改时候,会不会存在ABA问题?
先说结论:在ArrayList中进行迭代器遍历时,不会存在ABA问题。
首先我们需要明白什么是ABA问题:
ABA问题通常发生在使用CAS(Compare and Swap)等无锁算法时,其中一个线程在某个值从A变为B后再变回A之前,另一个线程可能会将该值误认为未发生变化。这种情况下,线程可能无法察觉到值的变化,导致并发修改的检测失败。
然而,在ArrayList的迭代器遍历过程中,并不涉及CAS操作或类似的无锁算法。ArrayList的迭代器是基于快照(snapshot)的方式实现的,即在迭代器创建时记录了ArrayList的modCount值,并在每次迭代操作时检查modCount是否与期望值一致。
由于modCount是一个简单的计数器,每次进行结构性修改都会增加它的值,不会出现ABA问题。即使在迭代器遍历过程中,如果有其他线程进行了修改,modCount的值也会相应地增加,从而与迭代器记录的期望值不一致,触发并发修改的检测。
延申:关于迭代器——Iterator遍历时不可以删除集合中的元素问题
在使用Iterator的时候禁止对所遍历的容器进行改变其大小结构的操作。例如: 在使用Iterator进行迭代时,如果对集合进行了add、remove操作就会出现ConcurrentModificationException异常。
注:这里是增强for循环,在ArrayList这个集合类中实现了Iterable接口,所以当前增强for循环其实底层是通过迭代器实现的。
public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(6);list.add(12);list.add(2);list.add(8);for(Integer i:list){if(i>10){list.remove(i);}}System.out.println(list);}ArrayList的父类AbstarctList中有一个域modCount,每次对集合进行修改(增添、删除元素)时modCount都会+1。
对于集合而言,增强for循环的实现原理就是迭代器Iterator,在这里,迭代ArrayList的Iterator中有一个变量expectedModCount,该变量会初始化和modCount相等,但当对集合进行插入,删除操作,modCount会改变,就会造成expectedModCount!=modCount,此时就会抛出java.util.ConcurrentModificationException异常,是在checkForComodification方法中,代码如下:
private void checkForComodification() {if (ArrayList.this.modCount != this.modCount)throw new ConcurrentModificationException();}解决方案①:
在使用迭代器遍历时,可使用迭代器的remove方法,因为Iterator的remove方法中 有如下的操作: expectedModCount = modCount;(同步了expectedModCount的值)
使用该机制的主要目的是为了实现ArrayList中的快速失败机制(fail-fast),在Java集合中较大一部分集合是存在快速失败机制的。
快速失败机制产生的条件:当多个线程对Collection进行操作时,若其中某一个线程通过Iterator遍历集合时,该集合的内容被其他线程所改变,则会抛出ConcurrentModificationException异常。
所以要保证在使用Iterator遍历集合的时候不出错误,就应该保证在遍历集合的过程中不会对集合产生结构上的修改。
这样才能避免ConcurrentModificationException的异常。
public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(6);list.add(12);list.add(2);list.add(8);Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()){Integer i =iterator.next();if(i>10){iterator.remove();}}System.out.println(list);}解决方案②:通过下标索引获取。
public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(6);list.add(12);list.add(2);list.add(8);for (int i = list.size(); i > 0; i--) {Integer num = list.get(i-1);if (num > 10) {list.remove(num);}}
// for (int i = 0; i < list.size(); i++) {
// Integer num = list.get(list.size() - 1 - i);
// if(num>10) {
// list.remove(list.size() - 1 - i);
// }
// }System.out.println(list);}ArrayList的扩容机制
ArrayList是一个动态类型的顺序表,即:在插入元素的过程中会自动扩容.
我们先来看看源码,以下是可能涉及到的一些字段:
其中 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 是构造ArrayList时不显示传参时候的容量
而 EMPTY_ELEMENTDATA 是构造ArrayList时显示传参为0时候的容量。
很多属性都被 static final 修饰,意味着它们是属于类的,并且是常量(不可被修改)。
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{private static final long serialVersionUID = 8683452581122892189L;/*** Default initial capacity.*/private static final int DEFAULT_CAPACITY = 10;/*** Shared empty array instance used for empty instances.*/private static final Object[] EMPTY_ELEMENTDATA = {};/*** Shared empty array instance used for default sized empty instances. We* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when* first element is added.*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/*** The array buffer into which the elements of the ArrayList are stored.* The capacity of the ArrayList is the length of this array buffer. Any* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA* will be expanded to DEFAULT_CAPACITY when the first element is added.*/transient Object[] elementData; // non-private to simplify nested class access/*** The size of the ArrayList (the number of elements it contains).** @serial*/private int size;以下是ArrayList的两个构造方法:

我们先来研究当创建ArrayList时,
默认不传参时候是怎么扩容的:
ArrayList<Integer> arr = new ArrayList<>();
arr.add(1);先说结论:默认容量是0,当执行add方法的时候,数组会扩容到10。
以下两个add方法中,其他代码就不作过多介绍,主要来讲下这个ensureCapacityInternal()方法:

ensureCapacityInternal()方法:

接下来我们看看grow内部的实现:

总结:
默认容量是0(默认是空数组),当执行add方法的时候,数组会扩容到10。
当传参时候等于0的时候

grow方法:

可以发现,ArrayList是很智能的,如果你显示的构造其时传入0,那么它就知道应该将容量变得很小,不会一下子就扩容到10,而是会慢慢的对数组长度进行+1操作。
比如以下,当再次进行一次add的时候,它其实会将数组长度进行再次+1,变成2.

当数组长度达到10的时候,是如何扩容的:

grow方法:

ArrayList也不是不限制的扩容
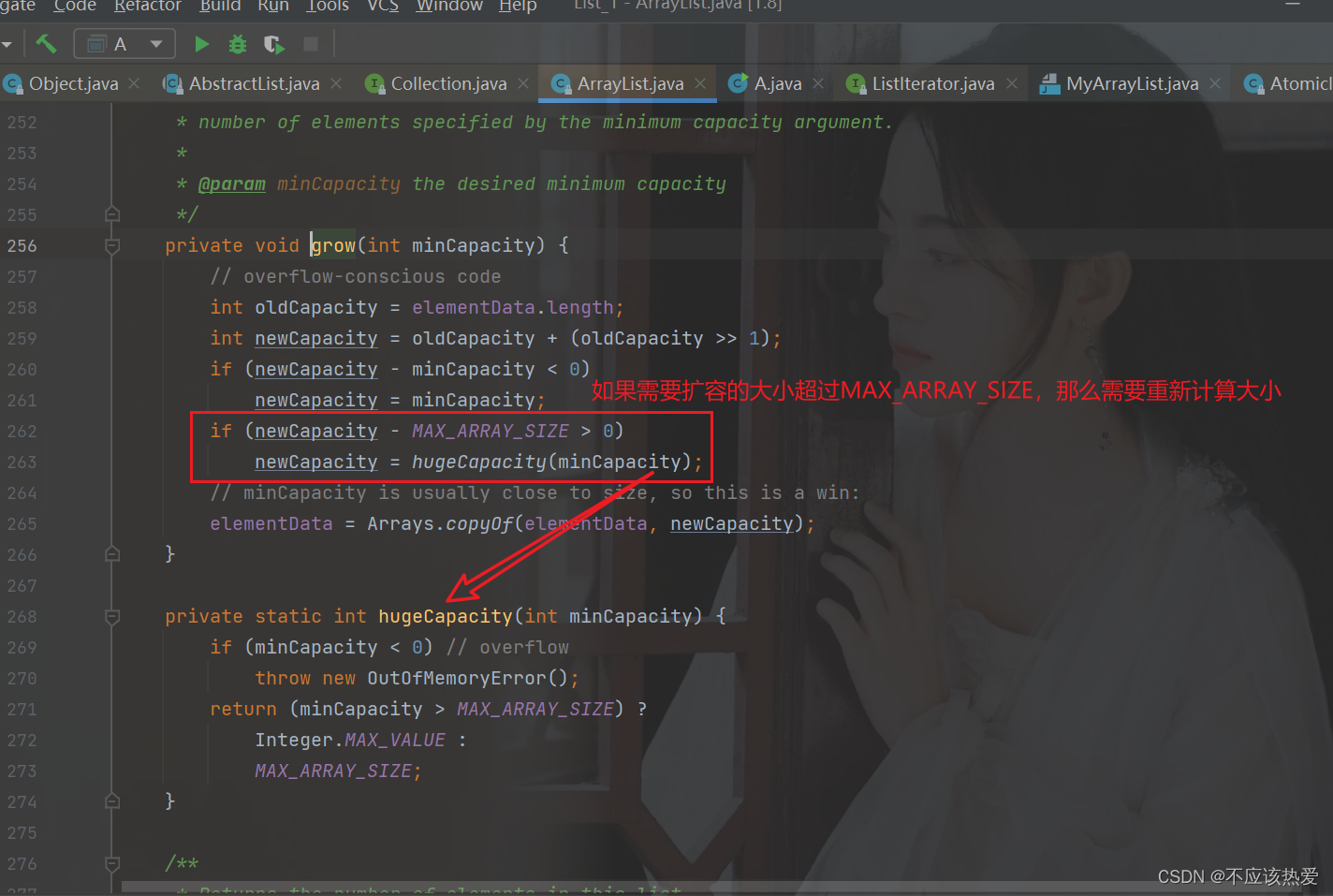
总结:
- 检测是否真正需要扩容,如果是调用grow准备扩容
- 预估需要库容的大小
- 初步预估按照1.5倍大小扩容
- 如果用户所需大小超过预估1.5倍大小,则按照用户所需大小扩容
- 真正扩容之前检测是否能扩容成功,防止太大导致扩容失败
- 使用copyOf进行扩容
对ArrayList进行排序—— Collections.sort
可以在ArrayList中存放自定义类型,并对其实现Comparable接口,重写compareto方法。
最终通过Collections.sort对其进行排序:
import java.util.ArrayList;
import java.util.Collections;class Student implements Comparable<Student>{String name;double score;int age;public Student(String name, double score, int age) {this.name = name;this.score = score;this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", score=" + score +", age=" + age +'}';}@Overridepublic int compareTo(Student o) {return (int) (this.score - o.score);}}
public class Test {public static void main(String[] args) {Student student1 = new Student("zhangsan1",4.6,2);Student student2 = new Student("zhangsan2",1.1,3);Student student3 = new Student("zhangsan2",11.2,4);ArrayList<Student> arrayList = new ArrayList<>();arrayList.add(student1);arrayList.add(student2);arrayList.add(student3);System.out.println(arrayList);System.out.println("=========================");Collections.sort(arrayList);for (Student s: arrayList) {System.out.println(s);}}
}
当然,以上代码是有点小问题的:因为score是double类型,对其进行强转时候可能会出现精度丢失的问题(可能导致排序失败)。
相关文章:
【数据结构】深度剖析ArrayList
目录 ArrayLIst介绍 ArrayList实现的接口有哪些? ArrayList的序列化:实现Serializable接口 serialVersionUID 有什么用? 为什么一定要实现Serialzable才能被序列化? transient关键字 为什么ArrayList中的elementData会被transient修…...
)
离线环境通过脚本实现服务器时钟同步(假同步)
1、背景 最近遇到一个时钟同步问题,是内网多台服务器之间时钟不同步,然后部署在不同服务器间的应用展示得时间戳不能统一,所以用户让做一下内网服务器间得时钟同步。 内网服务器x86和arm都有,而且有得系统是centos有得是ubuntu&…...
等级考试试卷(一级))
2023年9月青少年软件编程(C语言)等级考试试卷(一级)
日期输出 给定两个整数,表示一个日期的月和日。请按照"MM-DD"的格式输出日期,即如果月和日不到2位时,填补0使得满足2位。 时间限制:10000 内存限制:65536 输入 2个整数m,d(0 < m < 12…...
基于若依的ruoyi-nbcio流程管理系统仿钉钉流程json转bpmn的flowable的xml格式(支持并行网关)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 这个章节来完成并行网关,前端无需修改,直接后端修改就可以了。 1、并行网关后端修…...

软件测试面试-银行篇
今天参加了一场比较正式的面试,汇丰银行的视频面试。在这里把面试的流程记录一下,结果还不确定,但是面试也是自我学习和成长的过程,所以记录下来大家也可以互相探讨一下。 请你做一下自我介绍?(汇丰要求英…...

基于Amazon EC2和Amazon Systems Manager Session Manager的堡垒机设计和自动化实现
01 背景 在很多企业的实际应用场景中,特别是金融类的客户,大部分的应用都是部署在私有子网中。为了能够让客户的开发人员和运维人员从本地的数据中心中安全的访问云上资源,堡垒机是一个很好的选择。传统堡垒机的核心实现原理是基于 SSH 协议的…...
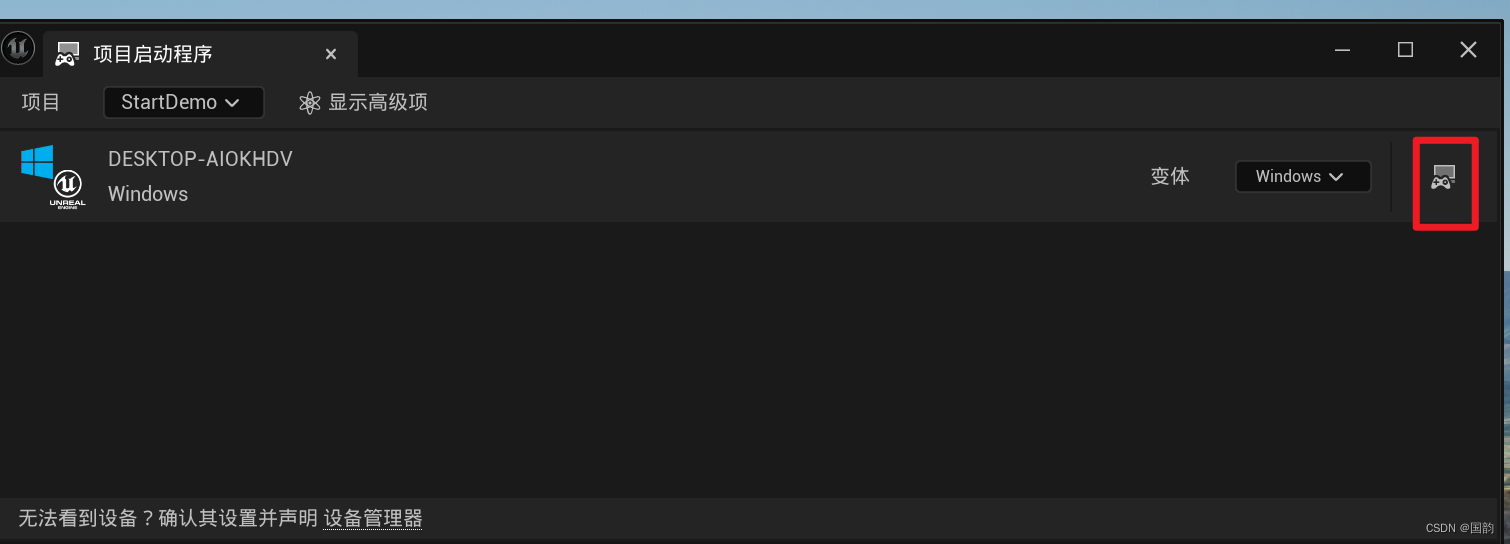
虚幻5.3打包Windows失败
缺失UnrealGame二进制文件。 必须使用集成开发环境编译该UE项目。或者借助虚幻编译工具使用命令行命令进行编译 解决办法: 1.依次点击平台-项目启动程序 2.点击后面的按钮进行设置 3.稍等后,打包后的程序即可运行,之后就可以愉快的打包了...
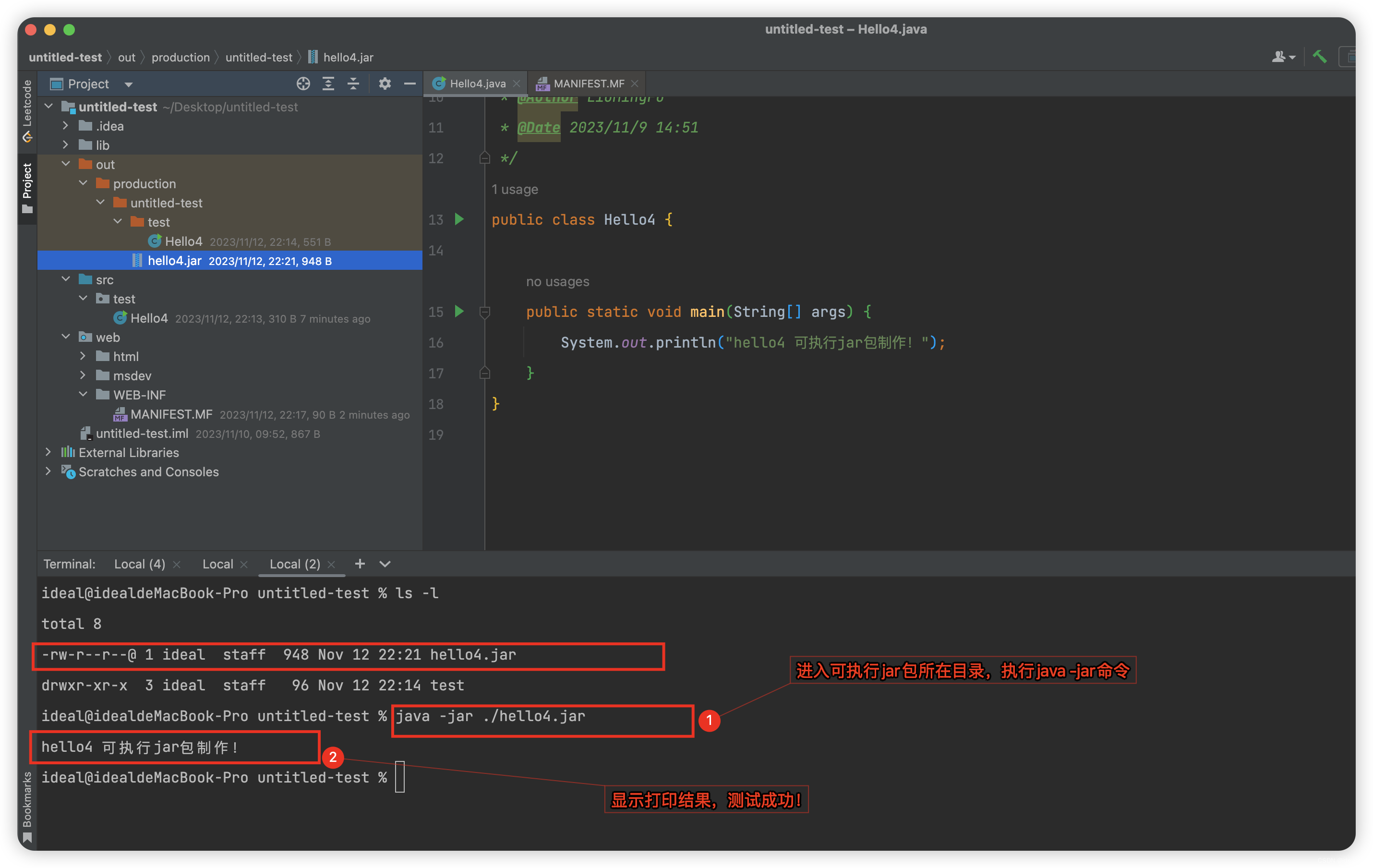
总结:利用JDK原生命令,制作可执行jar包与依赖jar包
总结:利用JDK原生命令,制作可执行jar包与依赖jar包 一什么是jar包?二制作jar包的工具:JDK原生自带的jar命令(1)jar命令注意事项:(2)jar包清单文件创建示例:&a…...
【C++】this指针讲解超详细!!!
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
的用法)
系统讲解java中list.stream()的用法
在Java 8及以后的版本中,引入了新的Stream API,这个API提供了一组新的操作方法,可以便捷 地对Java集合进行过滤、映射、排序、分组等操作。 在Stream API中主要分中间操作,和终止操作 中间操作是对流进行处理但不产生最终结果的…...

字节面试:请说一下DDD的流程,用电商系统为场景
说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业字节、如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的DDD落地经验? 谈谈你对DDD的理解&…...
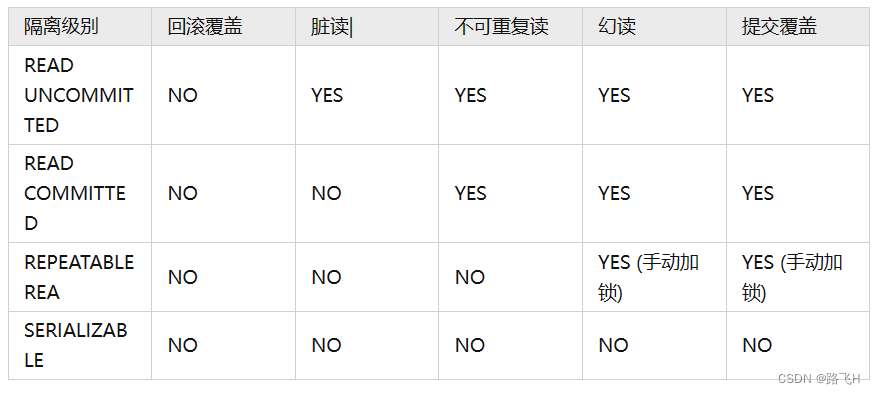
第26章_事务概述与隔离级别
文章目录 事务事务的特征事务的控制语句事务的生命周期事务的执行过程 ACID特性原子性一致性隔离性持久性 隔离级别不同隔离级别并发异常脏读不可重复读幻读区别 总结 事务 (1)事务的前提:并发连接访问。MySQL的事务就是将多条SQL语句作为整…...

合肥工业大学网络安全实验IP-Table
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :hfut实验课设 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付出过多少…...

Docker本地镜像发布到阿里云或私有库
本地镜像发布到阿里云流程 : 1.自己生成个要传的镜像 2.将本地镜像推送到阿里云: 阿里云开发者平台:开放云原生应用-云原生(Cloud Native)-云原生介绍 - 阿里云 2.1.创建仓库镜像: 2.1.1 选择控制台,进入容器镜像服…...
使用openvc进行人脸检测:Haar级联分类器
1 人脸检测介绍 1.1 什么是人脸检测 人脸检测的目标是确定图像或视频中是否存在人脸。如果存在多个面,则每个面都被一个边界框包围,因此我们知道这些面的位置 人脸检测算法的主要目标是准确有效地确定图像或视频中人脸的存在和位置。这些算法分析数据…...

Netty心跳检测
文章目录 一、网络连接假死现象二、服务器端的空闲检测三、客户端的心跳报文 客户端的心跳检测对于任何长连接的应用来说,都是一个非常基础的功能。要理解心跳的重要性,首先需要从网络连接假死的现象说起。 一、网络连接假死现象 什么是连接假死呢&…...
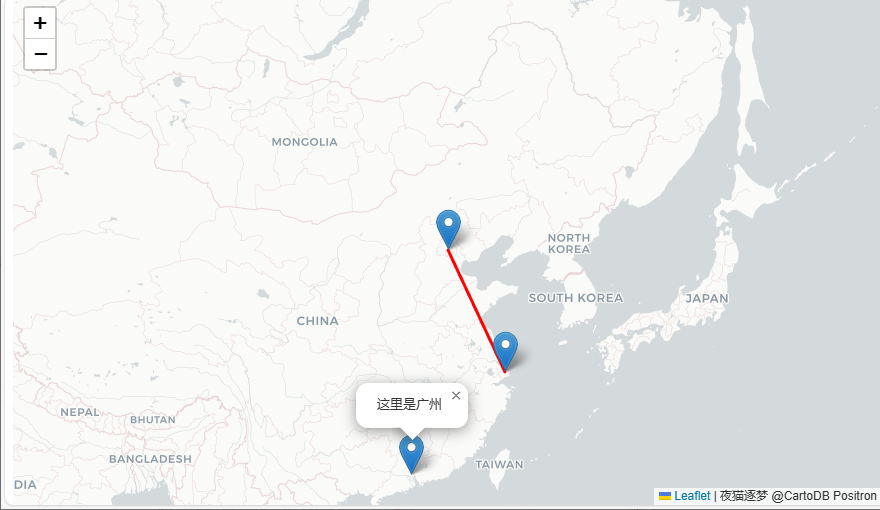
【leaflet】1. 初见
▒ 目录 ▒ 🛫 导读需求开发环境 1️⃣ 概念概念解释特点 2️⃣ 学习路线图3️⃣ html示例🛬 文章小结📖 参考资料 🛫 导读 需求 要做游戏地图了,看到大量产品都使用的leaflet,所以开始学习这个。 开发环境…...
 | 详解十大经典排序算法之一:冒泡排序)
数据结构与算法(Java版) | 详解十大经典排序算法之一:冒泡排序
前面虽然大家已经知道了多种不同的排序算法,但是我一直都没来得及给大家讲,所以,从这一讲起,我就要开始来给大家详细讲解具体的这些排序算法了。 下面,我们先来看第一个最常见的排序,即冒泡排序。 冒泡排…...
)
轻量封装WebGPU渲染系统示例<24>- Rendering Pass Graph基本用法(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/rendering/src/voxgpu/sample/PassNodeGraphTest.ts 此示例基于此渲染系统实现,当前示例TypeScript源码如下: class PassGraph extends WGRPassNodeGraph {constructor() { super();…...
开设自己的网站系类01购买服务器
开始建设自己的网站吧! 编者买了一个服务器打算自己构建一个网站,用于记录生活。网站大概算是一个个人博客吧。记录创建过程的一些步骤 要开设自己的网站,需要执行以下关键步骤 以下只是初步列出了建立自己的网站的大概步骤,后…...

LEGION_Y7000Series_Insyde_Advanced_Settings_Tools终极指南:一键解锁联想拯救者隐藏BIOS选项
LEGION_Y7000Series_Insyde_Advanced_Settings_Tools终极指南:一键解锁联想拯救者隐藏BIOS选项 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目…...

如何高效管理全面战争MOD?虎符台Legion Seal终极指南
如何高效管理全面战争MOD?虎符台Legion Seal终极指南 【免费下载链接】legion-seal 虎符台/Legion Seal,全面战争游戏MOD管理器,技术栈:Tauri 2 Vue TailwindCSS 项目地址: https://gitcode.com/zeyl/legion-seal 前言&a…...

Katran性能优化终极指南:10个从驱动模式到通用XDP的核心技巧
Katran性能优化终极指南:10个从驱动模式到通用XDP的核心技巧 【免费下载链接】katran A high performance layer 4 load balancer 项目地址: https://gitcode.com/gh_mirrors/ka/katran Katran作为一款高性能的四层负载均衡器,基于BPF和XDP技术构…...

如何快速掌握VDA5050协议:AGV通信标准完整指南与实战应用
如何快速掌握VDA5050协议:AGV通信标准完整指南与实战应用 【免费下载链接】VDA5050 Official Specification document for the VDA 5050 项目地址: https://gitcode.com/gh_mirrors/vd/VDA5050 在智能制造和自动化物流领域,不同品牌AGV设备之间的…...

3分钟安装:免费浏览器Markdown阅读器终极指南
3分钟安装:免费浏览器Markdown阅读器终极指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 你是否经常在浏览器中打开Markdown文件,却只能看到枯燥的源代…...

fastMRI技术解析:从k-space到图像重建的完整指南
fastMRI技术解析:从k-space到图像重建的完整指南 【免费下载链接】fastMRI A large-scale dataset of both raw MRI measurements and clinical MRI images. 项目地址: https://gitcode.com/gh_mirrors/fa/fastMRI 1 问题引入:医疗影像的"速…...

7步效率革命:设计批量处理驱动的智能工作流
7步效率革命:设计批量处理驱动的智能工作流 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 副标题:告别重复劳动的设计自动化方案 在现代设计工作流中&…...

Spring框架中多TaskExecutor Bean冲突的自动注入问题及解决方案
1. 当Spring遇到多个TaskExecutor时的烦恼 最近在重构一个老项目时,我遇到了一个典型的Spring自动注入问题。项目启动时突然报错,控制台赫然显示"NoUniqueBeanDefinitionException: expected single matching bean but found 3"。仔细一看&…...

AI日报 · 2026年4月9日
科技类:Anthropic 发布 Claude 4.5:史上最强推理能力,上线"思维链可视化"调试工具 4月8日,Anthropic 发布 Claude 4.5,推理能力大幅提升,尤其在复杂多步推理任务上超越 GPT-6 早期测试版。同时上…...

d2s-editor:暗黑破坏神2存档高效编辑工具全攻略
d2s-editor:暗黑破坏神2存档高效编辑工具全攻略 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 在《暗黑破坏神2》的冒险旅程中,你是否曾因错误的属性分配而懊悔不已?是否希望拥有更强大的装备…...