ElasticSearch文档分析
ElasticSearch文档分析 包含下面的过程:
- 将一块文本分成适合于倒排索引的独立的 词条
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里:
- 字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将 & 转化成 and。
- 分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
- Token过滤器
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)。
1 内置分析器
Elasticsearch还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条:
"Set the shape to semi-transparent by calling set_trans(5)"
- 标准分析器
标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
- 简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set, trans
- 空格分析器
空格分析器在空格的地方划分文本。它会产生:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
- 语言分析器
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。例如, 英语 分析器附带了一组英语无用词(常用单词,例如 and 或者 the ,它们对相关性没有多少影响),它们会被删除。 由于理解英语语法的规则,这个分词器可以提取英语单词的 词干 。
英语 分词器会产生下面的词条:
set, shape, semi, transpar, call, set_tran, 5
注意看 transparent、 calling 和 set_trans 已经变为词根格式
2 分析器使用场景
当我们 索引 一个文档,它的全文域被分析成词条以用来创建倒排索引。 但是,当我们在全文域 搜索 的时候,我们需要将查询字符串通过 相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致。
全文查询,理解每个域是如何定义的,因此它们可以做正确的事:
- 当你查询一个 全文 域时, 会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
- 当你查询一个 精确值 域时,不会分析查询字符串,而是搜索你指定的精确值。
3 测试分析器
有些时候很难理解分词的过程和实际被存储到索引中的词条,特别是你刚接触Elasticsearch。为了理解发生了什么,你可以使用 analyze API 来看文本是如何被分析的。在消息体里,指定分析器和要分析的文本
GET http://localhost:9200/_analyze
{"analyzer": "standard","text": "Text to analyze"
}结果中每个元素代表一个单独的词条:
{"tokens": [{"token": "text","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 1},{"token": "to","start_offset": 5,"end_offset": 7,"type": "<ALPHANUM>","position": 2},{"token": "analyze","start_offset": 8,"end_offset": 15,"type": "<ALPHANUM>","position": 3}]
}token 是实际存储到索引中的词条。 position 指明词条在原始文本中出现的位置。 start_offset 和 end_offset 指明字符在原始字符串中的位置。
4 指定分析器
当Elasticsearch在你的文档中检测到一个新的字符串域,它会自动设置其为一个全文 字符串 域,使用 标准 分析器对它进行分析。你不希望总是这样。可能你想使用一个不同的分析器,适用于你的数据使用的语言。有时候你想要一个字符串域就是一个字符串域—不使用分析,直接索引你传入的精确值,例如用户ID或者一个内部的状态域或标签。要做到这一点,我们必须手动指定这些域的映射。
5 IK分词器
首先我们通过Postman发送GET请求查询分词效果
GET http://localhost:9200/_analyze
{"text":"测试单词"
}ES的默认分词器无法识别中文中测试、单词这样的词汇,而是简单的将每个字拆完分为一个词
{"tokens": [{"token": "测","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "试","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "单","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "词","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3}]
}这样的结果显然不符合我们的使用要求,所以我们需要下载ES对应版本的中文分词器。
我们这里采用IK中文分词器,下载地址为: https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0
将解压后的后的文件夹放入ES根目录下的plugins目录下,重启ES即可使用。
我们这次加入新的查询参数"analyzer":"ik_max_word"
GET http://localhost:9200/_analyze
{"text":"测试单词","analyzer":"ik_max_word"
}- ik_max_word:会将文本做最细粒度的拆分
- ik_smart:会将文本做最粗粒度的拆分
使用中文分词后的结果为:
{"tokens": [{"token": "测试","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "单词","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 1}]
}ES中也可以进行扩展词汇,首先查询
GET http://localhost:9200/_analyze
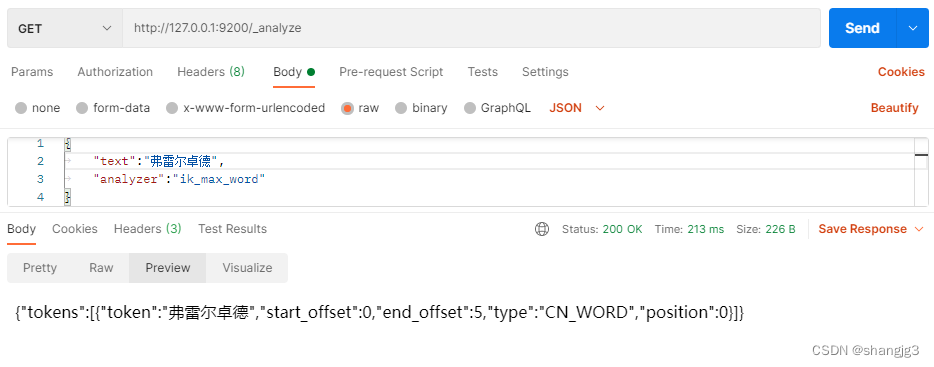
{"text":"弗雷尔卓德","analyzer":"ik_max_word"
}仅仅可以得到每个字的分词结果,我们需要做的就是使分词器识别到弗雷尔卓德也是一个词语
{"tokens": [{"token": "弗","start_offset": 0,"end_offset": 1,"type": "CN_CHAR","position": 0},{"token": "雷","start_offset": 1,"end_offset": 2,"type": "CN_CHAR","position": 1},{"token": "尔","start_offset": 2,"end_offset": 3,"type": "CN_CHAR","position": 2},{"token": "卓","start_offset": 3,"end_offset": 4,"type": "CN_CHAR","position": 3},{"token": "德","start_offset": 4,"end_offset": 5,"type": "CN_CHAR","position": 4}]
}
首先进入ES根目录中的plugins文件夹下的ik文件夹,进入config目录,创建custom.dic文件,写入弗雷尔卓德。同时打开IKAnalyzer.cfg.xml文件,将新建的custom.dic配置其中,重启ES服务器。

6 自定义分析器
虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。在 分析与分析器 我们说过,一个 分析器 就是在一个包里面组合了三种函数的一个包装器, 三种函数按照顺序被执行:
- 字符过滤器
字符过滤器 用来 整理 一个尚未被分词的字符串。例如,如果我们的文本是HTML格式的,它会包含像 <p> 或者 <div> 这样的HTML标签,这些标签是我们不想索引的。我们可以使用 html清除 字符过滤器 来移除掉所有的HTML标签,并且像把 Á 转换为相对应的Unicode字符 Á 这样,转换HTML实体。一个分析器可能有0个或者多个字符过滤器。
- 分词器
一个分析器 必须 有一个唯一的分词器。 分词器把字符串分解成单个词条或者词汇单元。 标准 分析器里使用的 标准 分词器 把一个字符串根据单词边界分解成单个词条,并且移除掉大部分的标点符号,然而还有其他不同行为的分词器存在。
例如, 关键词 分词器 完整地输出 接收到的同样的字符串,并不做任何分词。 空格 分词器 只根据空格分割文本 。 正则 分词器 根据匹配正则表达式来分割文本 。
- 词单元过滤器
经过分词,作为结果的 词单元流 会按照指定的顺序通过指定的词单元过滤器 。
词单元过滤器可以修改、添加或者移除词单元。我们已经提到过 lowercase 和 stop 词过滤器 ,但是在 Elasticsearch 里面还有很多可供选择的词单元过滤器。 词干过滤器 把单词 遏制 为 词干。 ascii_folding 过滤器移除变音符,把一个像 "très" 这样的词转换为 "tres" 。 ngram 和 edge_ngram 词单元过滤器 可以产生 适合用于部分匹配或者自动补全的词单元。
接下来,我们看看如何创建自定义的分析器:
PUT http://localhost:9200/my_index
{"settings": {"analysis": {"char_filter": {"&_to_and": {"type": "mapping","mappings": [ "&=> and "]}},"filter": {"my_stopwords": {"type": "stop","stopwords": [ "the", "a" ]}},"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip", "&_to_and" ],"tokenizer": "standard","filter": [ "lowercase", "my_stopwords" ]}}
}}}索引被创建以后,使用 analyze API 来 测试这个新的分析器
GET http://127.0.0.1:9200/my_index/_analyze
{"text":"The quick & brown fox","analyzer": "my_analyzer"
}下面的缩略结果展示出我们的分析器正在正确地运行
{"tokens": [{"token": "quick","start_offset": 4,"end_offset": 9,"type": "<ALPHANUM>","position": 1},{"token": "and","start_offset": 10,"end_offset": 11,"type": "<ALPHANUM>","position": 2},{"token": "brown","start_offset": 12,"end_offset": 17,"type": "<ALPHANUM>","position": 3},{"token": "fox","start_offset": 18,"end_offset": 21,"type": "<ALPHANUM>","position": 4}]
}相关文章:
ElasticSearch文档分析
ElasticSearch文档分析 包含下面的过程: 将一块文本分成适合于倒排索引的独立的 词条将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall 分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里: 字符过滤器 首先&a…...
Xilinx FPGA平台DDR3设计详解(一):DDR SDRAM系统框架
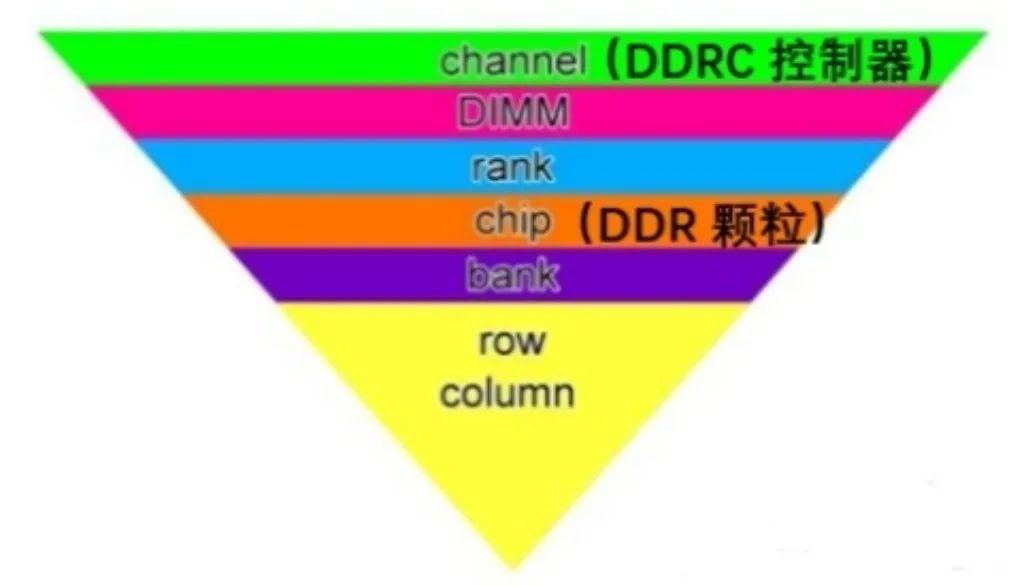
DDR SDRAM(双倍速率同步动态随机存储器)是一种内存技术,它可以在时钟信号的上升沿和下降沿都传输数据,从而提高数据传输的速率。DDR SDRAM已经发展了多代,包括DDR、DDR2、DDR3、DDR4和DDR5,每一代都有不同的…...
Spring Data JPA方法名命名规则
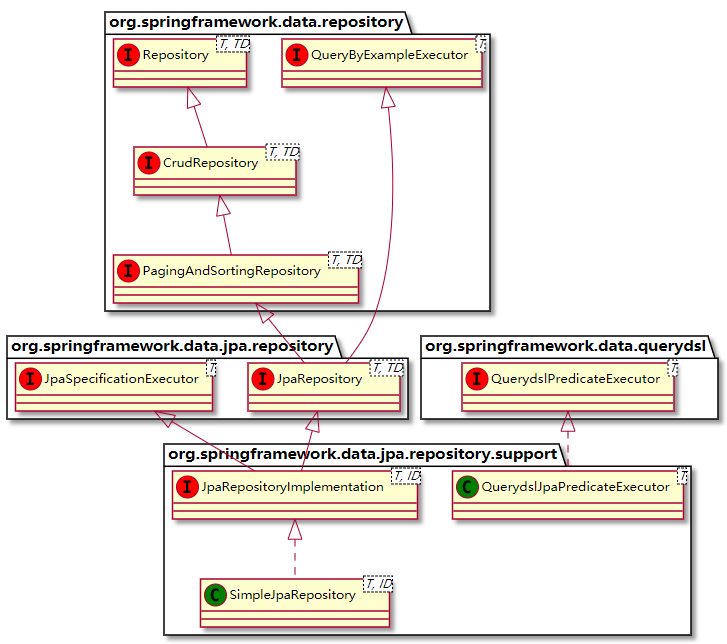
最近巩固一下JPA,网上看到这些资料,这里记录巩固一下。 一、Spring Data Jpa方法定义的规则 简单条件查询 简单条件查询:查询某一个实体类或者集合。 按照Spring Data的规范的规定,查询方法以find | read | get开头&…...

【Leetcode Sheet】Weekly Practice 15
Leetcode Test 2586 统计范围内的元音字符串数(11.7) 给你一个下标从 0 开始的字符串数组 words 和两个整数:left 和 right 。 如果字符串以元音字母开头并以元音字母结尾,那么该字符串就是一个 元音字符串 ,其中元音字母是 a、e、i、o、u…...

人力资源社会保障部办公厅关于推行专业技术人员职业资格电子证书的通知
(人社厅发〔2021〕97号) 各省、自治区、直辖市及新疆生产建设兵团人力资源社会保障厅(局),中共海南省委人才发展局,国务院有关部门、直属机构人事部门,有关协会、学会: 为贯彻落实…...
什么是光电耦合器?如何选择型号及种类
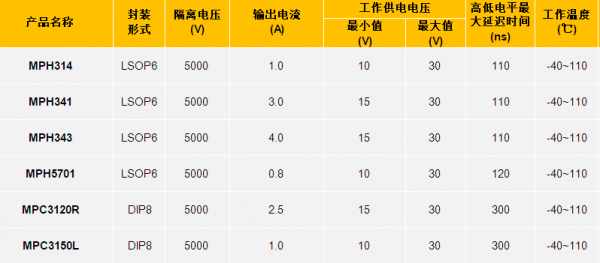
光电耦合器(英文缩写为OC)亦称光电隔离器,简称光耦;以光为媒介传输电信号;它对输入、输出电信号有良好的隔离作用,是目前种类最多、用途最广的光电器件之一;所以,它在各种电路中得到广泛的应用。 光耦合器…...
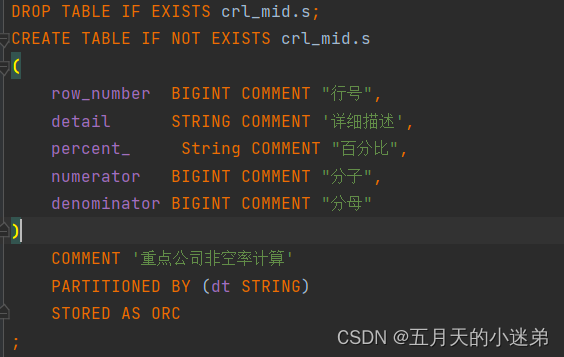
hive里因为列名用了关键字导致建表失败
代码 现象 ParseException line 6:4 cannot recognize input near percent String COMMENT in column name or primary key or foreign key 23/11/13 11:52:57 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 6:4 cannot recognize input near percent …...

MySQL 报错 incorrect datetime value ‘0000-00-00 00:00:00‘ for column
使用navicat导入数据时报错: MySQL 报错 incorrect datetime value ‘0000-00-00 00:00:00’ for column 这是因为当前的MySQL不支持datetime为0的情况。 MySQL报incorrect datetime value ‘0000-00-00 00:00:00’ for column错误原因,是由于在MySQL5.7…...
升级操作)
Jira Data Center(非集群)升级操作
一、升级准备 Jira 管理界面执行升级检查下载升级包,使用原操作方式相同的方式安装。我这里原来的版本是通过./atlassian-jira-software-9.11.2-x64.bin安装的,接下来下载atlassian-jira-software-9.11.3-x64.bin的安装文件停止 Jira,bin/st…...
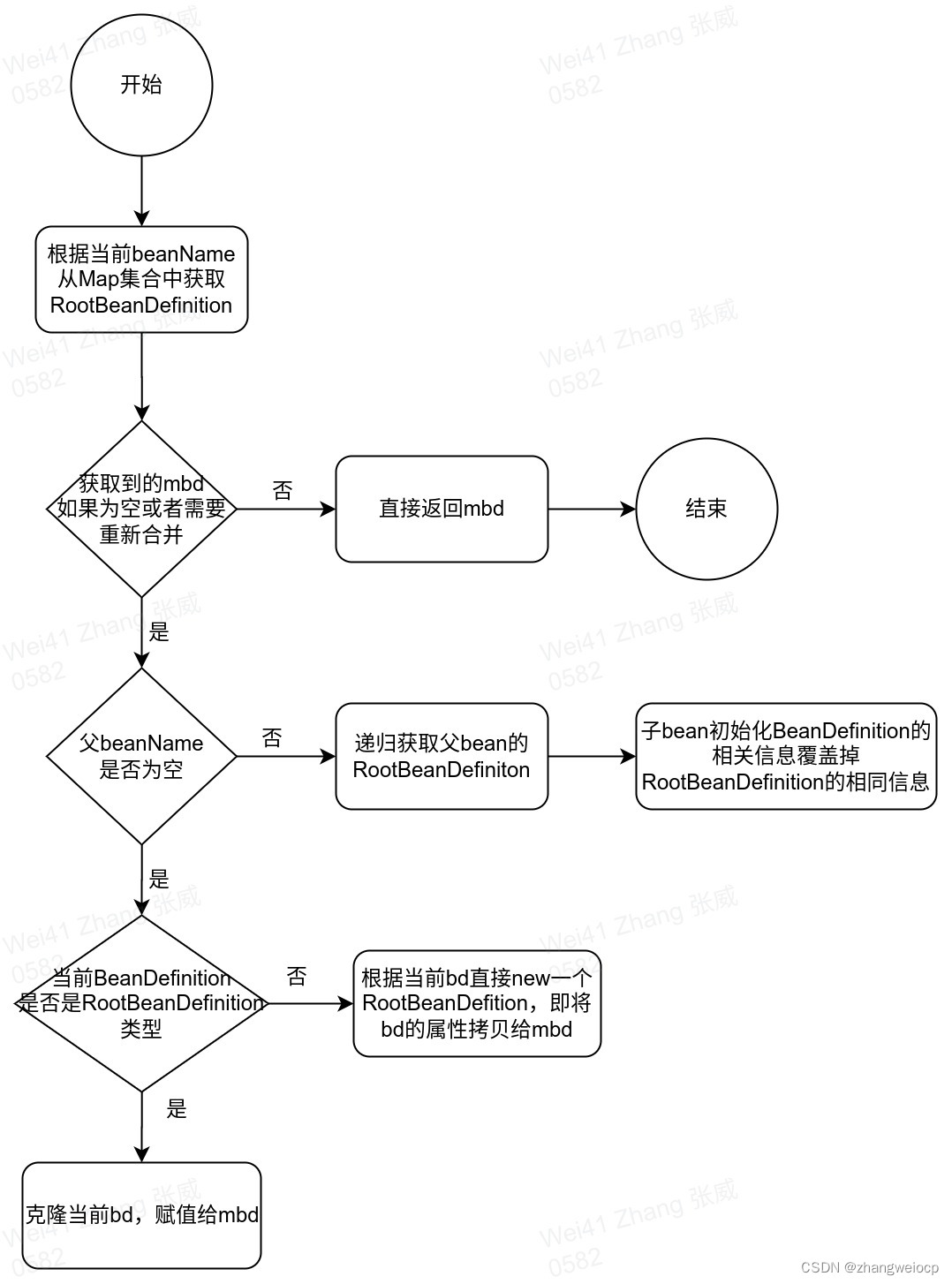
Spring IOC - BeanDefinition解析
1. BeanDefinition的属性 BeanDefinition作为接口定义了属性的get、set方法。这些属性基本定义在其直接实现类AbstractBeanDefinition中,各属性的含义如下表所示: 类型 名称 含义 常量 SCOPE_DEFAULT 默认作用域:单例模式 AUT…...
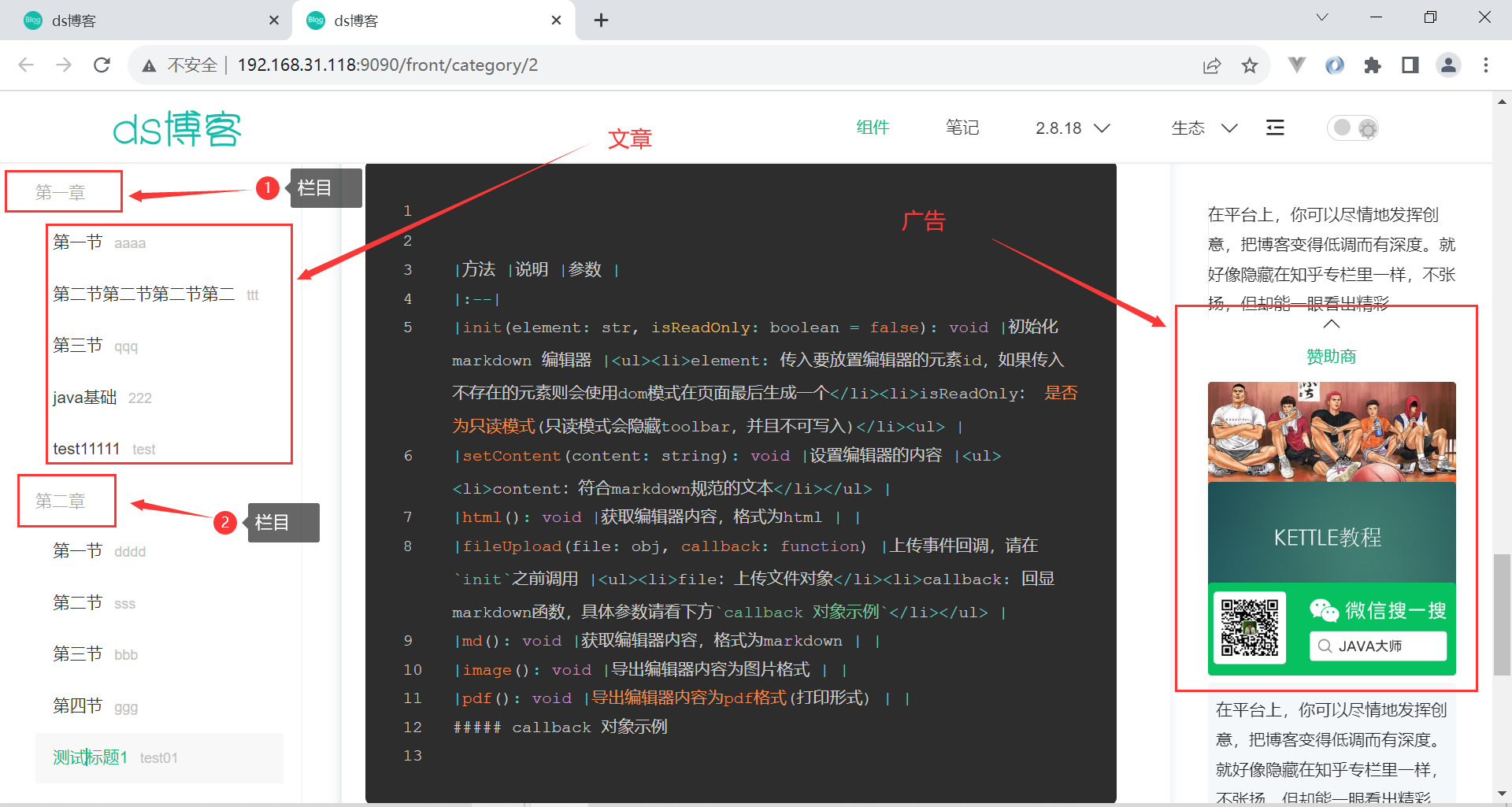
ds前后台博客系统
源码私信或者公众号java大师获取 博客简介:本博客采用Spring Boot LayUI做为基础,进行的博客系统开发,与bootvue相比,更为适合开发简单的系统,并且更容易上手,简单!高效!更易上手&a…...
)
算法leetcode|88. 合并两个有序数组(rust重拳出击)
文章目录 88. 合并两个有序数组:样例 1:样例 2:样例 3:提示: 分析:题解:rust:go:c:python:java: 88. 合并两个有序数组: …...

GoLong的学习之路,进阶,语法之并发(并发错误处理)补充并发三部曲
这篇文章主要讲的是如何去处理并发的错误。 在Go语言中十分便捷地开启goroutine去并发地执行任务,但是如何有效的处理并发过程中的错误则是一个很棘手的问题。 文章目录 recovererrgroup recover 哦对,似乎没写错误处理的文章。后面补上。 首先&…...

猪酒店房价采集
<?php // 设置代理 $proxy_host jshk.com.cn;// 创建一个cURL资源 $ch curl_init();// 设置代理 curl_setopt($ch, CURLOPT_PROXY, $proxy_host.:.$proxy_port);// 连接URL curl_setopt($ch, CURLOPT_URL, "http://www.zujia.com/");// 发送请求并获取HTML文档…...

Java基础知识第四讲:Java 基础 - 深入理解泛型机制
Java 基础 - 深入理解泛型机制 背景:Java泛型这个特性是从JDK 1.5才开始加入的,为了兼容之前的版本,Java泛型的实现采取了“伪泛型”的策略,即Java在语法上支持泛型,但是在编译阶段会进行所谓的“类型擦除”࿰…...

ceph-deploy bclinux aarch64 ceph 14.2.10【2】vdbench rbd 块设备rbd 测试失败
上篇 ceph-deploy bclinux aarch64 ceph 14.2.10-CSDN博客 安装vdbench 下载vdbench 下载页面 Vdbench Downloads (oracle.com) 包下载 需要账号登录,在弹出层点击同意才能继续下载 用户手册 https://download.oracle.com/otn/utilities_drivers/vdbench/vdb…...

split_train_val
# coding:utf-8 import os import random import argparse parser argparse.ArgumentParser() # xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下 parser.add_argument(--xml_path, defaultdata_door_white/xml/train, typestr, helpinput xm…...
Linux Mint 21.3 将搭载 Cinnamon 6.0 和实验性 Wayland 支持
导读Wayland 会话可能在 Linux Mint 23 系列中成为默认选项,预计将在 2026 年实现。 Linux Mint 项目今天在他们的每月新闻通讯中 宣布,他们已经开始着手在未来的 Linux Mint 发行版中实施 Wayland 会话,最初将在 Linux Mint 21.3 中提供。 …...

名师助阵龙讯旷腾PWmat+半导体缺陷培训暨半导体缺陷计算大赛
半导体缺陷计算大赛 选拔赛截止日期:11月23日 参与杭州线下培训直接跳过选拔赛 大赛亮点 线上免费培训、线下限时领取免费名额 线下杭州培训可直通决赛,跳过选拔赛 线上培训有3次机会参与考试进入决赛 已购/未购用户均可参加、无身份限定 使用Mc…...

Kotlin与Java写法的变更
目录 获取类的Java Class属性 类型检查 for循环 switch语句 if判断 获取类的Java Class属性 //Java Intent intent new Intent(this, MainActivity.class);//Kotlin val intent Intent(this, MainActivity::class.java) 类型检查 //Java apple instanceof Fruit !(app…...

电压电流双闭环Vienna整流器SVPWM调制仿真研究
基于电压电流双闭环的vienna整流器的仿真(SVPWM调制)最近在实验室折腾Vienna整流器,双闭环调得我差点把示波器砸了。这玩意儿看着电路拓扑对称美如画,真调起来参数互相打架是常态。今天就结合仿真说说怎么让电压电流双闭环稳住,顺便把SVPWM那…...

如何实现AI到PSD的无损转换?告别矢量信息丢失的终极方案
如何实现AI到PSD的无损转换?告别矢量信息丢失的终极方案 【免费下载链接】ai-to-psd A script for prepare export of vector objects from Adobe Illustrator to Photoshop 项目地址: https://gitcode.com/gh_mirrors/ai/ai-to-psd 你是否曾经因为Adobe Ill…...

ESP32+PHP+MySQL:构建云端物联网数据可视化看板
1. 从零搭建ESP32物联网数据采集系统 第一次接触ESP32时,我被它强大的WiFi和蓝牙功能惊艳到了。这块售价仅几十元的小开发板,居然能轻松实现传感器数据采集和无线传输。今天我要分享的,就是如何用ESP32构建一个完整的物联网数据可视化系统。 …...

清音刻墨Qwen3部署到使用:一条命令搭建,五分钟出成果
清音刻墨Qwen3部署到使用:一条命令搭建,五分钟出成果 1. 引言:重新定义字幕制作体验 在视频内容爆炸式增长的今天,字幕制作成为了许多创作者的心头之痛。传统的手动打字对时间轴不仅耗时耗力,而且很难达到专业级的精…...

KL散度在VAE中的应用:为什么高斯分布假设如此重要?
KL散度在VAE中的工程实践:高斯分布假设的深层逻辑 变分自编码器(VAE)作为生成模型的重要代表,其核心思想是通过学习数据的潜在表示来重构输入。在这个过程中,KL散度扮演着关键角色——它不仅是连接编码器与解码器的桥梁…...

Dify 1.0.1升级后Ollama模型添加失败?手把手教你解决Internal Server Error
Dify 1.0.1升级后Ollama模型集成故障排查指南 最近在升级Dify到1.0.1版本后,不少开发者反馈通过Ollama添加模型时遇到无响应或Internal Server Error的问题。作为一名经历过同样困扰的技术实践者,我将在本文分享完整的排查思路和解决方案。 1. 问题现象与…...

qmd检索结果解释:--explain参数与RRF+rerank评分机制解析
qmd检索结果解释:--explain参数与RRFrerank评分机制解析 【免费下载链接】qmd mini cli search engine for your docs, knowledge bases, meeting notes, whatever. Tracking current sota approaches while being all local 项目地址: https://gitcode.com/GitHu…...

不止是安装:在openEuler 22.03 LTS SP4上快速搭一个可用的开发/测试环境
从裸机到生产力:openEuler 22.03 LTS SP4半小时高效开发环境搭建指南 刚装完openEuler系统,看着空荡荡的终端界面,是不是有种"接下来该干嘛"的迷茫?作为开发者,我们需要的不是一个干净的操作系统,…...

别再死记硬背背包问题公式了!用‘小偷逛博物馆’的故事带你手写递归C++代码
当小偷逛博物馆遇上背包问题:用故事解锁递归思维 推开厚重的博物馆大门,昏暗的灯光下陈列着五件稀世珍宝。作为一名"专业"小偷,你只有一个承重20公斤的背包,每件藏品都有独特的重量和价值。如何在有限负重下最大化收益&…...

解锁毕业论文新姿势:书匠策AI,你的学术写作超级助手!
在学术的浩瀚海洋中,毕业论文无疑是每位学子扬帆远航前必须跨越的一道重要关卡。它不仅是对你多年学习成果的总结,更是通往未来学术或职业道路的一块重要敲门砖。然而,面对堆积如山的资料、错综复杂的逻辑结构,以及那令人头疼的格…...