解决UniAD在高版本CUDA、pytorch下运行遇到的问题
UniADhttps://github.com/OpenDriveLab/UniAD是面向行车规划集感知(目标检测与跟踪)、建图(不是像SLAM那样对环境重建的建图,而是实时全景分割图像里的道路、隔离带等行车需关注的相关物体)、和轨迹规划和占用预测等多任务模块于一体的统一大模型。官网上的安装说明是按作者使用的较低版本的CUDA11.1.1和pytorch1.9.1来的,对应的mmcv也是较低版本的1.4版,我们工作服务器上的nvidia ngc docker环境里使用的这些支持工具软件早已是较高版本的,于是想在我们自己的环境里把UniAD跑起来,安装过程中遇到一些坑,最终都一一解决了,也实测过了,UniAD完全可以正常跑在CUDA11.6+pytorch1.12.0+mmcv1.6+mmseg0.24.0+mmdet2.24+mmdet3d1.0.0rc4组成的环境下。
安装和解决问题的步骤如下:
1.拉取使用CUDA11.6的NVIDIA NGC docker镜像并创建容器作为UniAD的运行环境
2.安装pytorch和torchvision:
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
3.检查CUDA_HOME环境变量是否已设置,如果没有,则设置一下:
export CUDA_HOME=/usr/local/cuda
4.受CUDA和pytorch版本限制,mmcv需要安装比1.4高版本的1.6.0(关于openmmlab的mm序列框架包的安装版本对应关系参见openMMLab的mmcv和mmdet、mmdet3d、mmseg版本对应关系-CSDN博客: )
pip install mmcv-full==1.6.0 -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12.0/index.html
按照下面的对应关系:
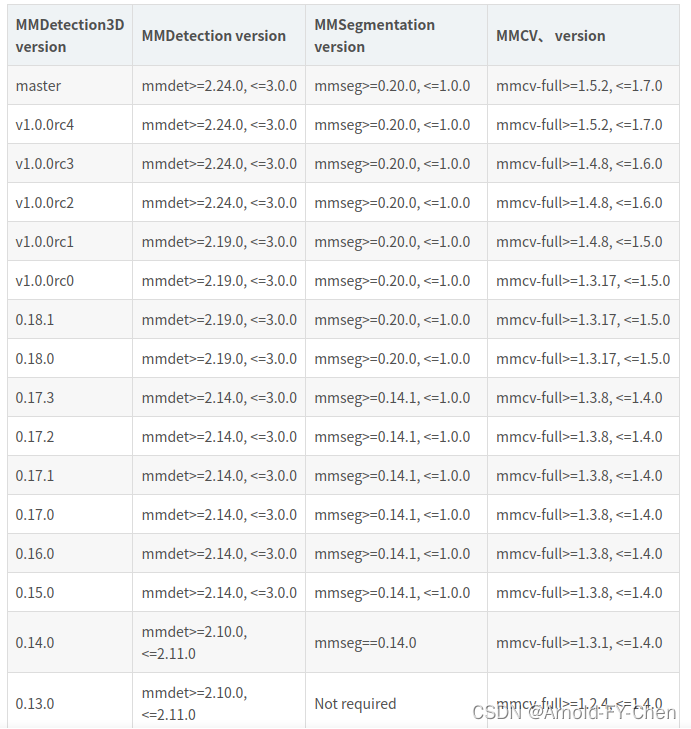
分别安装mmdet2.24.0和mmseg0.24.0
pip install mmdet==2.24.0
pip install mmsegmentation==0.24.0
下载mmdetection3d源码然后切换到v1.0.0rc4版:
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v1.0.0rc4
安装支持包并从源码编译和安装mmdet3d:
pip install scipy==1.7.3
pip install scikit-image==0.20.0
#将requirements/runtime.txt里修改一下numba的版本:
numba==0.53.1
#numba==0.53.0
pip install -v -e .
安装好了支持环境,然后下载和安装UniAD:
git clone https://github.com/OpenDriveLab/UniAD.git
cd UniAD
#修改一下requirements.txt里的numpy版本然后安装相关支持包:
#numpy==1.20.0
numpy==1.22.0
pip install -r requirements.txt
#下载相关预训练权重文件
mkdir ckpts && cd ckpts
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/bevformer_r101_dcn_24ep.pth
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/uniad_base_track_map.pth
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0.1/uniad_base_e2e.pth
按照https://github.com/OpenDriveLab/UniAD/blob/main/docs/DATA_PREP.md说明下载和展开整理NuScenes数据集
下载data infos文件:
cd UniAD/data
mkdir infos && cd infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_train.pkl # train_infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_val.pkl # val_infos假如NuScenes数据集和data infos文件已经下载好并解压存放到 ./data/下了并按照下面的结构存放的:
UniAD
├── projects/
├── tools/
├── ckpts/
│ ├── bevformer_r101_dcn_24ep.pth
│ ├── uniad_base_track_map.pth
| ├── uniad_base_e2e.pth
├── data/
│ ├── nuscenes/
│ │ ├── can_bus/
│ │ ├── maps/
│ │ │ ├──36092f0b03a857c6a3403e25b4b7aab3.png
│ │ │ ├──37819e65e09e5547b8a3ceaefba56bb2.png
│ │ │ ├──53992ee3023e5494b90c316c183be829.png
│ │ │ ├──93406b464a165eaba6d9de76ca09f5da.png
│ │ │ ├──basemap
│ │ │ ├──expansion
│ │ │ ├──prediction
│ │ ├── samples/
│ │ ├── sweeps/
│ │ ├── v1.0-test/
│ │ ├── v1.0-trainval/
│ ├── infos/
│ │ ├── nuscenes_infos_temporal_train.pkl
│ │ ├── nuscenes_infos_temporal_val.pkl
│ ├── others/
│ │ ├── motion_anchor_infos_mode6.pkl注意:map(v1.3) extensions压缩包下载后展开的三个目录basemap、expansion、prediction需要放在maps目录下,而不是和samples、sweeps等目录平级,NuScenes的train所有数据压缩包展开后,samples的最底层的每个子目录下都是34149张图片,sweeps里的子母录下的图片数量则是不等的,例如:163881、164274、164166、161453、160856、164266...等,把没有标注的test数据的压缩包在nuscenes目录下展开后,其里面samples和sweeps目录里子目录下的图片会自动拷贝到nuscenes/samples和nuscenes/sweeps下的对应子目录里去,再次统计会看到samples下的每个子目录里的图片数量变成了40157,而sweeps下的子目录里的图片数量则变成了193153、189171、189905、193082、193168、192699...
执行
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8
运行一下试试看,最后一个参数是GPU个数,我的工作环境和作者的工作环境一样都是8张A100卡,所以照着做,如果卡少,修改这个参数,例如使用1,也是可以跑的,只是比较慢。
第一次运行上面命令可能会遇到下面的问题:
1. partially initialized module 'cv2' has no attribute '_registerMatType' (most likely due to a circular import)
这是因为环境里的opencv-python版本太高了,版本不兼容引起的,我的是4.8.1.78,查了一下网上,需要降到4.5,执行下面的命令重新安装opencv-python4.5即可:
pip install opencv-python==4.5.4.58
2. ImportError: libGL.so.1: cannot open shared object file: No such file or directory
安装libgl即可:
sudo apt-get update && sudo apt-get install libgl1
3. AssertionError: MMCV==1.6.0 is used but incompatible. Please install mmcv>=(1, 3, 13, 0, 0, 0), <=(1, 5, 0, 0, 0, 0)
Traceback (most recent call last):File "tools/create_data.py", line 4, in <module>from data_converter import uniad_nuscenes_converter as nuscenes_converterFile "/workspace/workspace_fychen/UniAD/tools/data_converter/uniad_nuscenes_converter.py", line 13, in <module>from mmdet3d.core.bbox.box_np_ops import points_cam2imgFile "/workspace/workspace_fychen/mmdetection3d/mmdet3d/__init__.py", line 5, in <module>import mmsegFile "/opt/conda/lib/python3.8/site-packages/mmseg/__init__.py", line 58, in <module>assert (mmcv_min_version <= mmcv_version <= mmcv_max_version), \
AssertionError: MMCV==1.6.0 is used but incompatible. Please install mmcv>=(1, 3, 13, 0, 0, 0), <=(1, 5, 0, 0, 0, 0).这错误是python3.8/site-packages/mmseg/__init__.py抛出来的,说明mmseg和mmcv1.6.0版本不兼容,它要求安装mmcv的1.3-1.5版,说明mmseg自身版本低了,原因是开始安装的mmsegmenation版本低了,改安装mmseg0.24.0即可。其它功能框架包遇到版本问题做类似处理。
4.KeyError: 'DiceCost is already registered in Match Cost'
Traceback (most recent call last):File "./tools/test.py", line 16, in <module>from projects.mmdet3d_plugin.datasets.builder import build_dataloaderFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 3, in <module>from .core.bbox.match_costs import BBox3DL1Cost, DiceCostFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/__init__.py", line 2, in <module>from .match_cost import BBox3DL1Cost, DiceCostFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py", line 32, in <module>Traceback (most recent call last):
class DiceCost(object):File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 337, in _registerFile "./tools/test.py", line 16, in <module>from projects.mmdet3d_plugin.datasets.builder import build_dataloaderFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 3, in <module>from .core.bbox.match_costs import BBox3DL1Cost, DiceCostFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/__init__.py", line 2, in <module>from .match_cost import BBox3DL1Cost, DiceCostFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py", line 32, in <module>class DiceCost(object):File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 337, in _registerself._register_module(module=module, module_name=name, force=force)self._register_module(module=module, module_name=name, force=force)File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/misc.py", line 340, in new_funcFile "/opt/conda/lib/python3.8/site-packages/mmcv/utils/misc.py", line 340, in new_funcoutput = old_func(*args, **kwargs)File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 272, in _register_moduleraise KeyError(f'{name} is already registered '
KeyError: 'DiceCost is already registered in Match Cost''这种类注册重复了的问题是因为UniAD的mmdet3d_plugin和我安装的mmdetection的文件python3.8/site-packages/mmdet/core/bbox/match_costs/match_cost.py里有同名的DiceCost类(UniAD作者使用的mmdetection版本较低应该没有这个问题),读mmcv里面python3.8/site-packages/mmcv/utils/registry.py的注册代码可以知道这个问题可以设置参数force=True来解决:
@deprecated_api_warning(name_dict=dict(module_class='module'))def _register_module(self, module, module_name=None, force=False):if not inspect.isclass(module) and not inspect.isfunction(module):raise TypeError('module must be a class or a function, 'f'but got {type(module)}')if module_name is None:module_name = module.__name__if isinstance(module_name, str):module_name = [module_name]for name in module_name:if not force and name in self._module_dict:raise KeyError(f'{name} is already registered 'f'in {self.name}')self._module_dict[name] = module为了保证UniAD代码能正确运行,允许UniAD的DiceCost类强制注册即可,也就是修改UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py里DiceCost类的装饰器语句,增加force=True参数:
@MATCH_COST.register_module(force=True)
class DiceCost(object):
5.TypeError: cannot pickle 'dict_keys' object
File "./tools/test.py", line 261, in <module>main()File "./tools/test.py", line 231, in mainoutputs = custom_multi_gpu_test(model, data_loader, args.tmpdir,File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/apis/test.py", line 88, in custom_multi_gpu_testfor i, data in enumerate(data_loader):File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 438, in __iter__return self._get_iterator()File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 384, in _get_iteratorreturn _MultiProcessingDataLoaderIter(self)File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1048, in __init__w.start()File "/opt/conda/lib/python3.8/multiprocessing/process.py", line 121, in startself._popen = self._Popen(self)File "/opt/conda/lib/python3.8/multiprocessing/context.py", line 224, in _Popenreturn _default_context.get_context().Process._Popen(process_obj)File "/opt/conda/lib/python3.8/multiprocessing/context.py", line 284, in _Popenreturn Popen(process_obj)File "/opt/conda/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 32, in __init__super().__init__(process_obj)File "/opt/conda/lib/python3.8/multiprocessing/popen_fork.py", line 19, in __init__self._launch(process_obj)File "/opt/conda/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 47, in _launchreduction.dump(process_obj, fp)File "/opt/conda/lib/python3.8/multiprocessing/reduction.py", line 60, in dumpForkingPickler(file, protocol).dump(obj)
TypeError: cannot pickle 'dict_keys' object解决办法参见 如何定位TypeError: cannot pickle dict_keys object错误原因及解决NuScenes数据集在多进程并发训练或测试时出现的这个错误-CSDN博客
6.protobuf报错 TypeError: Descriptors cannot not be created directly
Traceback (most recent call last):File "./tools/test.py", line 16, in <module>from projects.mmdet3d_plugin.datasets.builder import build_dataloaderFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 5, in <module>from .datasets.pipelines import (File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/pipelines/__init__.py", line 6, in <module>from .occflow_label import GenerateOccFlowLabelsFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/pipelines/occflow_label.py", line 5, in <module>from projects.mmdet3d_plugin.uniad.dense_heads.occ_head_plugin import calculate_birds_eye_view_parametersFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/__init__.py", line 2, in <module>from .dense_heads import *File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/__init__.py", line 4, in <module>from .occ_head import OccHeadFile "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head.py", line 16, in <module>from .occ_head_plugin import MLP, BevFeatureSlicer, SimpleConv2d, CVT_Decoder, Bottleneck, UpsamplingAdd, \File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head_plugin/__init__.py", line 1, in <module>from .metrics import *File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head_plugin/metrics.py", line 10, in <module>from pytorch_lightning.metrics.metric import MetricFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/__init__.py", line 29, in <module>from pytorch_lightning.callbacks import Callback # noqa: E402File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/callbacks/__init__.py", line 25, in <module>from pytorch_lightning.callbacks.swa import StochasticWeightAveragingFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/callbacks/swa.py", line 26, in <module>from pytorch_lightning.trainer.optimizers import _get_default_scheduler_configFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/__init__.py", line 18, in <module>from pytorch_lightning.trainer.trainer import TrainerFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 30, in <module>from pytorch_lightning.loggers import LightningLoggerBaseFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loggers/__init__.py", line 18, in <module>from pytorch_lightning.loggers.tensorboard import TensorBoardLoggerFile "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loggers/tensorboard.py", line 25, in <module>from torch.utils.tensorboard import SummaryWriterFile "/opt/conda/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py", line 12, in <module>from .writer import FileWriter, SummaryWriter # noqa: F401File "/opt/conda/lib/python3.8/site-packages/torch/utils/tensorboard/writer.py", line 9, in <module>from tensorboard.compat.proto.event_pb2 import SessionLogFile "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/event_pb2.py", line 17, in <module>from tensorboard.compat.proto import summary_pb2 as tensorboard_dot_compat_dot_proto_dot_summary__pb2File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/summary_pb2.py", line 17, in <module>from tensorboard.compat.proto import tensor_pb2 as tensorboard_dot_compat_dot_proto_dot_tensor__pb2File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/tensor_pb2.py", line 16, in <module>from tensorboard.compat.proto import resource_handle_pb2 as tensorboard_dot_compat_dot_proto_dot_resource__handle__pb2File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/resource_handle_pb2.py", line 16, in <module>from tensorboard.compat.proto import tensor_shape_pb2 as tensorboard_dot_compat_dot_proto_dot_tensor__shape__pb2File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/tensor_shape_pb2.py", line 36, in <module>_descriptor.FieldDescriptor(File "/opt/conda/lib/python3.8/site-packages/google/protobuf/descriptor.py", line 561, in __new___message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:1. Downgrade the protobuf package to 3.20.x or lower.2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).我的protobuf版本4.24.4太高了,降为3.20后就可以了:
pip install protobuf==3.20
7. TypeError: expected str, bytes or os.PathLike object, not _io.BufferedReader
Traceback (most recent call last):File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 69, in build_from_cfgreturn obj_cls(**args)File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py", line 78, in __init__super().__init__(*args, **kwargs)File "/workspace/workspace_fychen/mmdetection3d/mmdet3d/datasets/nuscenes_dataset.py", line 131, in __init__super().__init__(File "/workspace/workspace_fychen/mmdetection3d/mmdet3d/datasets/custom_3d.py", line 88, in __init__self.data_infos = self.load_annotations(open(local_path, 'rb'))File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py", line 152, in load_annotationsdata = pickle.loads(self.file_client.get(ann_file))File "/opt/conda/lib/python3.8/site-packages/mmcv/fileio/file_client.py", line 1014, in getreturn self.client.get(filepath)File "/opt/conda/lib/python3.8/site-packages/mmcv/fileio/file_client.py", line 535, in getwith open(filepath, 'rb') as f:
TypeError: expected str, bytes or os.PathLike object, not _io.BufferedReader问题原因出现在高版本的mmdetection3d/mmdet3d/datasets/custom_3d.py里考虑了支持local_path读取文件,传入load_annotations()的就是个io句柄了:
def __init__(self,data_root,ann_file,pipeline=None,classes=None,modality=None,box_type_3d='LiDAR',filter_empty_gt=True,test_mode=False,file_client_args=dict(backend='disk')):super().__init__()self.data_root = data_rootself.ann_file = ann_fileself.test_mode = test_modeself.modality = modalityself.filter_empty_gt = filter_empty_gtself.box_type_3d, self.box_mode_3d = get_box_type(box_type_3d)self.CLASSES = self.get_classes(classes)self.file_client = mmcv.FileClient(**file_client_args)self.cat2id = {name: i for i, name in enumerate(self.CLASSES)}# load annotationsif not hasattr(self.file_client, 'get_local_path'):with self.file_client.get_local_path(self.ann_file) as local_path:self.data_infos = self.load_annotations(open(local_path, 'rb'))else:warnings.warn('The used MMCV version does not have get_local_path. 'f'We treat the {self.ann_file} as local paths and it ''might cause errors if the path is not a local path. ''Please use MMCV>= 1.3.16 if you meet errors.')self.data_infos = self.load_annotations(self.ann_file)根源是UniAD的UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py里
在实现load_annotations()时默认是只支持使用ann_file是字符串类型,所以这里强制修改一下mmdetection3d/mmdet3d/datasets/custom_3d.py改回使用self.data_infos = self.load_annotations(self.ann_file)即可。
8. RuntimeError: DataLoader worker (pid 33959) is killed by signal: Killed
前面的7个问题都解决后,如果NuScenes数据集是完整的且位置正确的话,运行下面的命令应该都可以运行:
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8
./tools/uniad_dist_eval.sh ./projects/configs/stage2_e2e/base_e2e.py ./ckpts/uniad_base_e2e.pth 8
但是可能会在循环读取数据时发生超时错误而导致dataloader所在进程被杀掉:
Traceback (most recent call last):File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1134, in _try_get_datadata = self._data_queue.get(timeout=timeout)File "/opt/conda/lib/python3.8/multiprocessing/queues.py", line 107, in getif not self._poll(timeout):File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 257, in pollreturn self._poll(timeout)File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 424, in _pollr = wait([self], timeout)File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 936, in waittimeout = deadline - time.monotonic()File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 33959) is killed by signal: Killed.查了一下,发现原因是配置文件projects/configs/stage1_track_map/base_track_map.py和projects/configs/stage2_e2e/base_e2e.py里的workers_per_gpu=8的设置对我们的服务器来说太多了,改为2后,再运行上面的命令可以顺利执行完毕。
相关文章:
解决UniAD在高版本CUDA、pytorch下运行遇到的问题
UniADhttps://github.com/OpenDriveLab/UniAD是面向行车规划集感知(目标检测与跟踪)、建图(不是像SLAM那样对环境重建的建图,而是实时全景分割图像里的道路、隔离带等行车需关注的相关物体)、和轨迹规划和占用预测等多任务模块于一体的统一大模型。官网上的安装说明…...

ADC、DMA以及串口之间的联系和区别?
ADC、DMA和串口都是嵌入式系统中常用的模块,它们之间有以下联系和区别: 联系: ADC和DMA都是用于数据采集和传输的模块,ADC可以将模拟信号转换为数字信号,DMA可以在不经过CPU的情况下实现数据的高速传输。而串口则是一…...

jupyter lab配置列表清单
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

爱发电 OAuth 登录 SDK for Remix
目录 概要安装使用配置 Remix Auth配置登录跳转配置 callback 回调配置 Demo 测试页配置注销登录 概要 爱发电 OAuth 文档: https://afdian.net/p/010ff078177211eca44f52540025c377 注意一下这里有两个细节: 这里的 OAuth 非标准化 OAuth,…...

Wpf 使用 Prism 实战开发Day05
首页设计 1.效果图 一.代码现实 根据页面布局,可以将页面设计成3行,每行中分多少列,看需求而定根据页面内容,设计Model 实体类,以及View Model 1.Index.xaml 页面布局设计 RowDefinition 分行(Row…...

性能压测工具:Locust详解
一、Locust介绍 开源性能测试工具https://www.locust.io/,基于Python的性能压测工具,使用Python代码来定义用户行为,模拟百万计的并发用户访问。每个测试用户的行为由您定义,并且通过Web UI实时监控聚集过程。 压力发生器作为性…...
vmware 修改主机名称 hadoop 服务器环境配置(一)
如何在虚拟机配置主机名称: 1. 如图所示在/etc 文件夹下有个hosts文件。追加映射关系: #关系 ip地址 名称 192.168.164.20 hadoop20 2. 保存后,重启reboot即可...
淘宝店铺订单插旗接口(taobao.trade.memo.update淘宝店铺订单交易备注修改接口)
淘宝店铺订单插旗接口是指可以在淘宝店铺的订单系统中进行订单备注的接口。通过该接口,您可以根据用户的身份(买家或卖家),添加相应的交易备注,用于区分不同订单类型等。 具体使用方法可以参考淘宝开放平台的API接口文…...

py文件如何打包成exe?如何压缩文件大小?
打包 要将 Python 文件打包成可执行文件,您可以使用 PyInstaller 这个工具。以下是具体步骤: 首先,确保您已经安装了 PyInstaller。如果没有安装,可以使用以下命令安装: pip install pyinstaller进入您的 Python 程序…...
)
SQL优化相关(持续更新)
常用sql修改 1、LIMIT 语句 在 SQL 查询中,LIMIT 10000, 10 的语句表示从第 10001 行开始,返回 10 行结果。要优化这个查询,可以考虑以下几点: 使用合适的索引:确保涉及到查询条件和排序的列上有适当的索引…...

Linux学习--limits文件配置详解
/etc/security/limits.conf 是一个配置文件,用于限制用户或进程在系统中可以使用的资源。 语法结构: :指定要应用限制的目标对象,可以是用户()、用户组()或进程(、、<…...
Android Studio 代码上传gitLab
1、项目忽略文件 2选择要上传的项目 3、添加 首次提交需要输入url 最后在push...

【避雷选刊】Springer旗下2/3区,2个月录用!发文量激增,还能投吗?
计算机类 • 好刊解读 前段时间小编分析过目前科睿唯安数据库仍有8本期刊处于On Hold状态,其中包括4本SCIE、4本ESCI期刊(👉详情可见:避雷!又有2本期刊被标记“On Hold”!含中科院2区(TOP&…...

Linux常用的压缩命令
笑小枫的专属目录 少整花活,直接干货Linux gzip命令语法功能参数 Linux zip命令语法参数 少整花活,直接干货 本文的来源就是因为上篇文章Linux常用的解压命令,解压整了,顺手整理了一波压缩命令。 Linux gzip命令 减少文件大小有…...
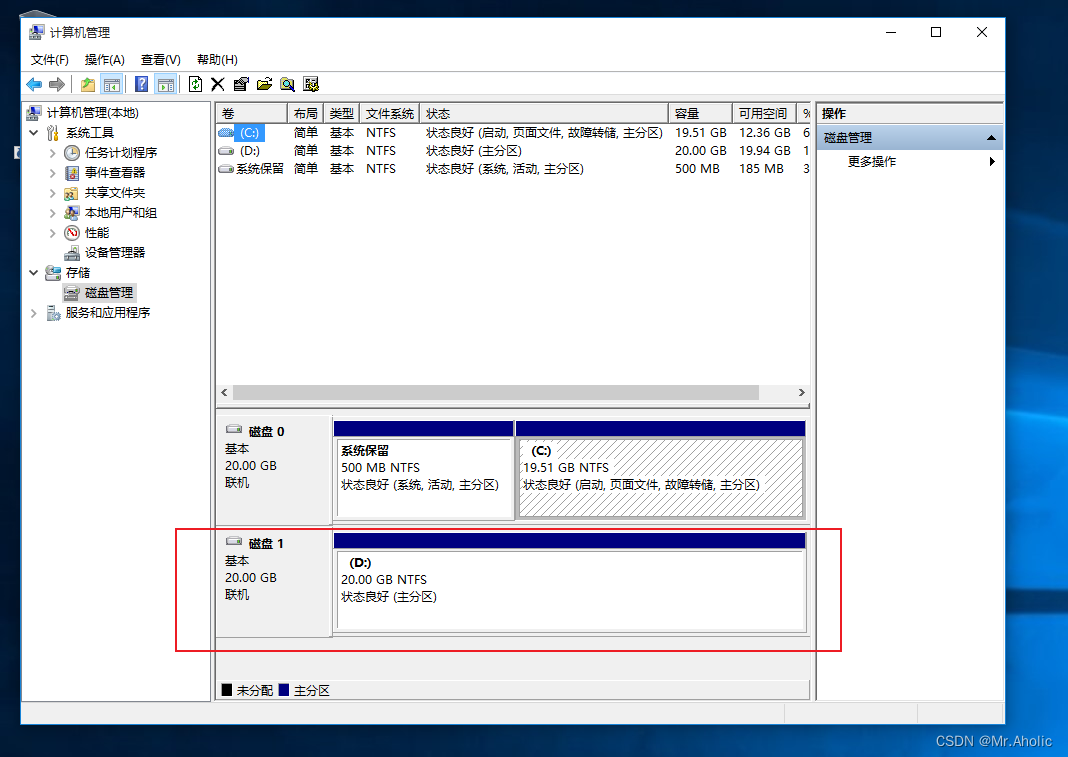
如何为VM虚拟机添加D盘
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 前言 在虚拟机上安装Windows10 系统后&…...

C# 16进制颜色转为RGB颜色
#region [颜色:16进制转成RGB] /// <summary> /// [颜色:16进制转成RGB] /// </summary> /// <param name"strColor">设置16进制颜色 [返回RGB]</param> /// <returns></returns> public static System.D…...

【工具】Java计算图片相似度
【工具】Java图片相似度匹配工具 方案一 通过像素点去匹配 /*** * param file1Url 图片url* param file2Url 图片url* return*/public static double img相似度Url(String file1Url, String file2Url){InputStream inputStream1 HttpUtil.createGet(file1Url).execute().…...

GDB调试
GDB调试程序之运行参数输入 以bash运行如下程序命令为例子: $ ./adapter -c FOTON_ECAN.dbc foton_bcan.dbc 方法1:进入gdb,加载程序,执行run命令的时候,后面加上参数 $ gdb (gdb) file adapter Reading symbols from adapter... (gdb) run -c FOTON_ECAN.dbc foton_b…...
swift和OC混编报错问题
1.‘objc’ instance method in extension of subclass of ‘xxx’ requires iOS 13.0.0 需要把实现从扩展移到主类实现。iOS13一下扩展不支持objc 2.using bridging headers with framework targets is unsupported 报错 这个错误通常指的是在一个框架目标中使用桥接头是不…...

第七章 块为结构建模 P5|系统建模语言SysML实用指南学习
仅供个人学习记录 应用泛化对分类层级建模 继承inherit更通用分类器的公共特性,并包含其他特有的附加特性。通用分类器与特殊分类器之间的关系称为泛化generalization 泛化由两个分类器之间的线条表示,父类端带有空心三角形箭头 块的分类与结构化特性…...

04.Python 循环:while+for详解
1. 循环 while或 for后边都记得加:(英文冒号) 1.1 while 1.1.1 概述 ① 初始化计数器 ② 编写循环条件(判断计数器是否达到了目标位置) ③ 在循环内部更新计数器 1.1.2 猜数字案例 #适用于 循环次数未知的情况, 例如: 猜数字游戏.…...
)
从玩具到工具:用Unity Vuforia给老旧产品手册做个‘AR说明书’(实战案例分享)
从玩具到工具:用Unity Vuforia给老旧产品手册做个‘AR说明书’(实战案例分享) 想象一下,当客户翻阅一本印刷精美的工业设备手册时,只需用手机扫描页面上的产品示意图,就能在屏幕上看到设备内部结构的3D拆解…...

解锁毕业论文新姿势:书匠策AI,你的学术写作超级助手!
在学术的浩瀚海洋中,毕业论文无疑是每位学子扬帆远航前必须跨越的一道重要关卡。它不仅是对你多年学习成果的总结,更是通往未来学术或职业道路的一块重要敲门砖。然而,面对堆积如山的资料、错综复杂的逻辑结构,以及那令人头疼的格…...

未来5年最“钱”景岗位!AI产品经理3步进阶,普通人也能All in!
文章指出AI产品经理是未来5年最有“钱”景的岗位,分为工具型、应用型和专业型三个层次,其中应用型最适合普通人。文章提出了从入门到上手的“三步学习法”:夯实产品基本功、掌握AI项目落地能力、补充AI知识技能,并推荐了起点课堂全…...

Stable Diffusion 3核心技术拆解:手把手带你理解MM-DiT架构与修正流加权
Stable Diffusion 3核心技术拆解:手把手带你理解MM-DiT架构与修正流加权 当你在MidJourney或DALLE 3中输入一段文字描述,几秒内就能得到一张高度匹配的图片时,背后究竟发生了什么?2024年ICML最佳论文给出了答案——Stable Diffusi…...

DFS连通域统计:岛屿数量问题及其变形
0.前言 本文我们来学习一下算法题中颇为著名的岛屿数量问题,我将会从问题本身入手,详细分析解题思路,给出完整代码并进行解析,最后简单了解一下几个岛屿问题的变种题目。 1. 问题描述 题目给出一个只含有 0 和 1 矩阵,…...

bilibili-parse:让B站视频解析变得简单高效的PHP工具
bilibili-parse:让B站视频解析变得简单高效的PHP工具 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 价值定位:为什么选择bilibili-parse 当你需要在自己的项目中集成B站视频…...

leetcode 73
束手无策。题意看起来是简单的,但是实行起来是困难的。matrix 是行的集合,换句话说,就是一个二维数组里面存了行,很多个行,matrix 0 存的是第 0 行。其实有点难。但是我一定可以的。我是可以的。我一遍一遍地告诉自己&…...
)
手机摄影党必看!用Flare7K数据集原理改善夜间拍摄(华为/iPhone实测)
手机摄影党必看!用Flare7K数据集原理改善夜间拍摄(华为/iPhone实测) 夜间拍摄时,你是否经常遇到这样的困扰:路灯变成模糊的光团,霓虹灯周围出现奇怪的彩虹条纹,或是画面中突然多出几条不明来源的…...

ADS124S08高精度数据采集系统实战:从寄存器配置到SPI驱动解析
1. ADS124S08核心功能与工业场景适配 ADS124S08这颗24位Δ-Σ ADC芯片在工业现场堪称"信号放大镜",特别适合处理微弱的传感器信号。我去年在开发热电偶温度监测系统时,实测发现它128倍PGA增益下能稳定捕捉到0.15μV的电压变化,这相…...