SQL优化相关(持续更新)
常用sql修改
1、LIMIT 语句
在 SQL 查询中,LIMIT 10000, 10 的语句表示从第 10001 行开始,返回 10 行结果。要优化这个查询,可以考虑以下几点:
- 使用合适的索引:确保涉及到查询条件和排序的列上有适当的索引,这样可以加快查询的速度。
- 避免全表扫描:如果查询条件允许的话,尽可能添加 WHERE 子句来限制检索的行数,避免扫描整个表。
- 分页缓存:如果该查询是常用的翻页查询,可以考虑将结果缓存在应用程序的内存中,避免每次查询都执行数据库操作。
- 重构查询逻辑:如果可能的话,考虑重构查询逻辑,以减少不必要的计算或连接,从而提高查询性能。
- 合理设置数据库参数:根据具体的数据库系统,调整适当的参数,例如连接池大小、查询缓存等,以提高整体性能。
eg1:
SELECT *
FROM user
WHERE type = 'xxx'AND name = 'xxxxx'
ORDER BY create_time
LIMIT 1000, 10;
一般 在 type、 name、 create_time 字段上加组合索引,
在前端数据浏览翻页,或者大数据分批导出等场景下,是可以将上一页的最大值当成参数作为查询条件的
优化为:
SELECT *
FROM user
WHERE type = 'xxx'
AND name = 'xxxxx'
AND create_time > '2017-03-16 14:00:00'
ORDER BY create_time limit 10;
eg2:
SELECT * FROM user LIMIT 10000, 10;
优化为:
SELECT * FROM user WHERE user_id >= (SELECT user_id FROM user ORDER BY user_id LIMIT 10000, 1) ORDER BY user_id LIMIT 10;
使用子查询来确定起始行的user_id,然后再以它作为过滤条件来获取接下来的10行数据。这样可以避免全表扫描,并且保持了结果的有序性。
2、隐式转换
MySQL中的隐式转换是指在表达式运算过程中,MySQL自动进行的数据类型转换而无需明确指定。隐式转换可以在不同数据类型之间进行,例如将字符串转换为数字、将日期转换为字符串等。
MySQL的隐式转换遵循一定的规则和优先级:
- 当使用不同的数据类型进行比较操作时,MySQL会尝试将其中一个数据类型转换成另一个数据类型,以进行比较。例如,当将一个字符串和一个数字进行比较时,MySQL会尝试将字符串转换为数字。
- MySQL将会自动将较低优先级的数据类型转换为较高优先级的数据类型。数据类型的优先级从低到高依次是:NULL、BIT、DATE、DATETIME、TIMESTAMP、TIME、YEAR、CHAR、VARCHAR、BINARY、VARBINARY、TINYBLOB、TINYTEXT、BLOB、TEXT、MEDIUMBLOB、MEDIUMTEXT、LONGBLOB、LONGTEXT、ENUM、SET、DECIMAL、FLOAT、DOUBLE、INT、SERIAL、BOOL、BOOLEAN。
- 当进行算术运算时,MySQL将会将不同的数据类型转换为相同的数据类型,然后进行计算。例如,将字符串和数字相加时,MySQL会将字符串转换为数字,然后再进行相加操作。
需要注意的是,虽然MySQL可以进行隐式转换,但过多的隐式转换可能会导致性能下降或不准确的结果。因此,建议在编写SQL语句时明确指定数据类型,避免依赖隐式转换。
以下是一个实际的SQL例子:
假设有一个名为products的表,其中包含product_id(INT类型)和product_name(VARCHAR类型)两个字段。我们想查找产品ID为字符串’123’的记录。
SELECT * FROM products WHERE product_id = ‘123’;
在这个例子中,我们将字符串’123’与product_id字段进行比较。由于product_id是一个INT类型的字段,而我们使用的是一个字符串,MySQL会自动将字符串’123’转换为INT类型,然后进行比较。
在上面给出的例子中,将产品ID的字段以字符串形式进行比较是有问题的。主要问题有两个: - 性能问题:使用字符串进行比较会导致MySQL进行字符串到整数的隐式转换,这可能会影响查询的性能。隐式转换需要进行额外的计算和比较操作,而明确指定数据类型可以避免这种开销。
- 可读性问题:将一个整数字段与字符串进行比较可能会使代码难以理解和维护。其他人阅读代码时可能会误解意图或不清楚其背后的隐式转换。明确地指定操作数的数据类型可以增加代码的可读性和可维护性。
- 不准确的结果:隐式转换可能导致不准确的结果。由于MySQL自动进行转换时可能会截断、舍入或改变数据精度,所以结果可能与预期不符。显式地指定数据类型可以确保准确的比较和计算。
为了解决这些问题,建议在编写SQL时明确指定操作数的数据类型。在这个例子中,正确的写法是将产品ID的值作为整数进行比较,而不是以字符串形式比较:
SELECT * FROM products WHERE product_id = 123;
通过明确指定数据类型,可以避免性能问题和提高代码可读性,确保查询的准确性和一致性。
3、关联更新、删除
UPDATE operation o
SET status = 'applying'
WHERE o.id IN (SELECT idFROM (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) t);
优化为:
UPDATE operation oJOIN (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) tON o.id = t.id
SET status = 'applying'
其他:
让我们通过例子来说明关联删除和关联更新对SQL性能的影响。
关联删除的性能影响示例:
假设我们有两个表:orders(订单表)和 order_items(订单详情表),它们之间通过 order_id 进行关联。现在,我们需要删除具有特定条件的订单以及对应的订单详情。我们可以使用关联删除进行操作:
DELETE o, oi
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.status = 'cancelled';
上述语句使用关联删除的方式,在单个操作中删除了符合条件的订单表和订单详情表中的数据。这样的关联删除可以减少与数据库的多次交互,提高性能。
通过使用关联删除,我们可以一次性删除相关的数据,避免了多次独立删除的开销,从而减少了请求和响应的次数,提高了删除操作的性能。
关联更新的性能影响示例:
假设我们有两个表:products(产品表)和 inventory(库存表),它们之间通过 product_id 进行关联。现在,我们需要将产品表中特定条件的产品的库存数量更新为0。我们可以使用关联更新进行操作:
UPDATE products p
JOIN inventory i ON p.product_id = i.product_id
SET p.stock = 0
WHERE i.quantity < 0;
上述语句使用关联更新的方式,在单个操作中更新了产品表和库存表中符合条件的数据。通过关联更新,我们可以一次性更新相关数据,避免了多次独立更新的开销,从而减少了请求和响应的次数,提高了更新操作的性能。
需要注意的是,关联删除和关联更新的性能影响也会受到其他因素的影响,例如表的大小、索引的使用、服务器的配置等。因此,在实际使用中,需要综合考虑并做好性能测试,以获得最佳的性能结果。
4、混合排序
SELECT *
FROM my_order oINNER JOIN my_appraise a ON a.orderid = o.id
ORDER BY a.is_reply ASC,a.appraise_time DESC
LIMIT 0, 20
由于 is_reply 只有0和1两种状态,我们按照下面的方法重写后,执行时间从1.58秒降低到2毫秒。
优化为:
SELECT *
FROM ((SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 0ORDER BY appraise_time DESCLIMIT 0, 20)UNION ALL(SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 1ORDER BY appraise_time DESCLIMIT 0, 20)) t
ORDER BY is_reply ASC,appraisetime DESC
LIMIT 20;
其他:
让我们通过一个例子来说明混合排序对性能的影响:
假设我们有一个名为products的表,其中包含大量产品的信息,包括product_name(产品名称)、price(价格)和stock(库存)。现在,我们需要按照价格升序排序,并在价格相同时,按照库存降序排序。
方法一:使用混合排序
SELECT *
FROM products
ORDER BY price ASC, stock DESC;
上述查询使用混合排序,首先按照价格升序排序,如果价格相同,则按照库存降序排序。
方法二:分步排序
SELECT *
FROM (SELECT *FROM productsORDER BY stock DESC
) AS subquery
ORDER BY price ASC;
上述查询使用两个步骤来实现相同的排序需求。首先,我们按照库存降序排序,然后将结果作为子查询。接下来,在子查询的结果上按照价格升序排序。
这里需要注意的是,具体情况可能因数据集的大小和索引等因素而有所不同。以下是对性能影响的一些可能情况:
-
混合排序性能影响:混合排序在单个查询中同时使用多个排序条件。这样可以避免执行额外的子查询,并减少查询过程中的数据整理。因此,相对而言,混合排序可能在性能方面更有效率。
-
分步排序性能影响:分步排序通过执行多个查询来实现相同的排序需求。这涉及到执行子查询和在子查询结果上执行额外的排序操作。因此,相对而言,分步排序可能会产生更多的开销,特别是在大型数据集上。
总的来说,混合排序在单个查询中同时使用多个排序条件,可以避免额外的查询和数据整理开销,可能在性能方面更优。然而,具体情况仍需根据数据集的大小、索引设计、查询复杂度等因素进行评估和测试,以确定最佳的排序方法。
5、EXISTS语句
SELECT *
FROM my_neighbor nLEFT JOIN my_neighbor_apply sraON n.id = sra.neighbor_idAND sra.user_id = 'xxx'
WHERE n.topic_status < 4AND EXISTS(SELECT 1FROM message_info mWHERE n.id = m.neighbor_idAND m.inuser = 'xxx')AND n.topic_type <> 5
优化为:
SELECT *
FROM my_neighbor nINNER JOIN message_info mON n.id = m.neighbor_idAND m.inuser = 'xxx'LEFT JOIN my_neighbor_apply sraON n.id = sra.neighbor_idAND sra.user_id = 'xxx'
WHERE n.topic_status < 4AND n.topic_type <> 5
其他:
当使用EXISTS语句时,以下是一些真实世界的例子,可以帮助你理解其性能优化的影响:
-
验证关联记录是否存在:假设你有一个订单表和一个订单详情表,你想要检查是否存在至少一个订单有关联的订单详情。你可以使用EXISTS语句来实现:
SELECT order_id FROM orders WHERE EXISTS (SELECT * FROM order_details WHERE order_details.order_id = orders.order_id);通过使用合适的索引和适当的子查询优化,可以帮助加快此查询的执行速度。
-
检查未参加活动的客户:假设你有一个客户表和一个活动表,你想要找出所有未参加任何活动的客户。你可以使用EXISTS语句来实现:
SELECT customer_id, name FROM customers WHERE NOT EXISTS (SELECT * FROM activities WHERE activities.customer_id = customers.customer_id);使用合适的索引和适当的子查询优化可以提高查询性能并减少处理时间。
-
检查关联表中的重复记录:假设你有一个学生表和一个成绩表,你想要检查是否有学生在成绩表中有重复的记录。你可以使用EXISTS语句来实现:
SELECT student_id FROM students WHERE EXISTS (SELECT student_id FROM scores GROUP BY student_id HAVING COUNT(*) > 1);使用适当的索引和合适的子查询优化可以帮助提高查询性能并减少重复记录的处理。
这些是一些使用EXISTS语句的实际例子,其中的性能优化可以通过索引的创建、正确的子查询编写和查询计划的调整来实现。具体的优化方法会根据你的数据库结构和数据量的不同而有所不同,可以根据实际情况进行调整和优化。
性能优化:
当使用EXISTS语句时,以下是一些优化性能的实际例子:
-
创建适当的索引:确保在子查询中的关联字段上创建了适当的索引,这将加速查询的执行。例如,在下面的查询中,对
order_details表的order_id字段创建索引将提高查询性能:SELECT order_id FROM orders WHERE EXISTS (SELECT * FROM order_details WHERE order_details.order_id = orders.order_id); -
使用合适的连接方式:根据实际情况选择合适的连接方式,如使用INNER JOIN或LEFT JOIN代替EXISTS语句。有时候,将EXISTS子查询转换为连接查询可能会更高效。例如,下面的查询使用INNER JOIN代替了EXISTS子查询:
SELECT orders.order_id FROM orders INNER JOIN order_details ON order_details.order_id = orders.order_id;这种方式可以利用连接操作的性能优势。
-
简化和优化子查询:确保子查询是简洁和高效的。避免使用不必要的连接和复杂的表达式。优化子查询的逻辑以减少计算和数据处理。例如,可以使用子查询的查询条件来筛选数据,并仅检查所需的列,而不是检查所有列。
SELECT customer_id, name FROM customers WHERE NOT EXISTS (SELECT 1 FROM activities WHERE activities.customer_id = customers.customer_id);在这个例子中,子查询只使用了
SELECT 1而不是SELECT *,因为我们只关心是否存在匹配的记录。 -
使用LIMIT限制结果集:如果你只关心是否存在匹配的结果,而不是具体的数据,可以使用LIMIT来限制结果集的大小。在子查询中使用LIMIT 1可以告诉MySQL只返回第一条匹配的结果,这样可以减少不必要的计算和开销。
SELECT * FROM orders WHERE EXISTS (SELECT * FROM order_details WHERE order_details.order_id = orders.order_id LIMIT 1);在这个例子中,我们只需要知道是否存在匹配的记录,因此使用LIMIT 1可以提高查询性能。
相关文章:
)
SQL优化相关(持续更新)
常用sql修改 1、LIMIT 语句 在 SQL 查询中,LIMIT 10000, 10 的语句表示从第 10001 行开始,返回 10 行结果。要优化这个查询,可以考虑以下几点: 使用合适的索引:确保涉及到查询条件和排序的列上有适当的索引…...

Linux学习--limits文件配置详解
/etc/security/limits.conf 是一个配置文件,用于限制用户或进程在系统中可以使用的资源。 语法结构: :指定要应用限制的目标对象,可以是用户()、用户组()或进程(、、<…...
Android Studio 代码上传gitLab
1、项目忽略文件 2选择要上传的项目 3、添加 首次提交需要输入url 最后在push...

【避雷选刊】Springer旗下2/3区,2个月录用!发文量激增,还能投吗?
计算机类 • 好刊解读 前段时间小编分析过目前科睿唯安数据库仍有8本期刊处于On Hold状态,其中包括4本SCIE、4本ESCI期刊(👉详情可见:避雷!又有2本期刊被标记“On Hold”!含中科院2区(TOP&…...

Linux常用的压缩命令
笑小枫的专属目录 少整花活,直接干货Linux gzip命令语法功能参数 Linux zip命令语法参数 少整花活,直接干货 本文的来源就是因为上篇文章Linux常用的解压命令,解压整了,顺手整理了一波压缩命令。 Linux gzip命令 减少文件大小有…...
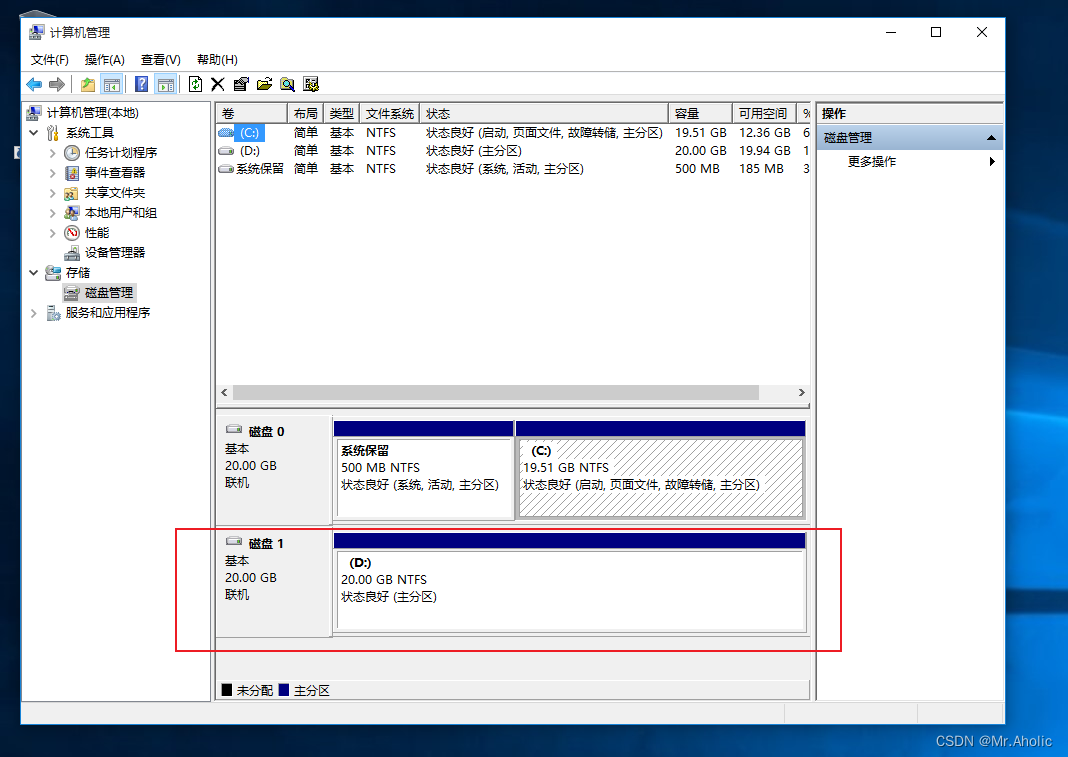
如何为VM虚拟机添加D盘
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 前言 在虚拟机上安装Windows10 系统后&…...

C# 16进制颜色转为RGB颜色
#region [颜色:16进制转成RGB] /// <summary> /// [颜色:16进制转成RGB] /// </summary> /// <param name"strColor">设置16进制颜色 [返回RGB]</param> /// <returns></returns> public static System.D…...

【工具】Java计算图片相似度
【工具】Java图片相似度匹配工具 方案一 通过像素点去匹配 /*** * param file1Url 图片url* param file2Url 图片url* return*/public static double img相似度Url(String file1Url, String file2Url){InputStream inputStream1 HttpUtil.createGet(file1Url).execute().…...

GDB调试
GDB调试程序之运行参数输入 以bash运行如下程序命令为例子: $ ./adapter -c FOTON_ECAN.dbc foton_bcan.dbc 方法1:进入gdb,加载程序,执行run命令的时候,后面加上参数 $ gdb (gdb) file adapter Reading symbols from adapter... (gdb) run -c FOTON_ECAN.dbc foton_b…...
swift和OC混编报错问题
1.‘objc’ instance method in extension of subclass of ‘xxx’ requires iOS 13.0.0 需要把实现从扩展移到主类实现。iOS13一下扩展不支持objc 2.using bridging headers with framework targets is unsupported 报错 这个错误通常指的是在一个框架目标中使用桥接头是不…...

第七章 块为结构建模 P5|系统建模语言SysML实用指南学习
仅供个人学习记录 应用泛化对分类层级建模 继承inherit更通用分类器的公共特性,并包含其他特有的附加特性。通用分类器与特殊分类器之间的关系称为泛化generalization 泛化由两个分类器之间的线条表示,父类端带有空心三角形箭头 块的分类与结构化特性…...

java算法学习索引之动态规划
一 斐波那契数列问题的递归和动态规划 【题目】给定整数N,返回斐波那契数列的第N项。 补充问题 1:给定整数 N,代表台阶数,一次可以跨 2个或者 1个台阶,返回有多少种走法。 【举例】N3,可以三次都跨1个台…...

ChatGPT重磅升级 奢侈品VERTU推出双模型AI手机
2023年11月7日,OpenAI举办了首届开发者大会,CEO Sam Altman(山姆奥尔特曼)展示了号称“史上最强”AI的GPT-4 Turbo。它支持长达约10万汉字的输入,具备前所未有的长文本处理能力,使更复杂的互动成为可能。此外,GPT-4 Turbo还引入了跨模态API支持,可以同时处理图片、视频和声音,从…...
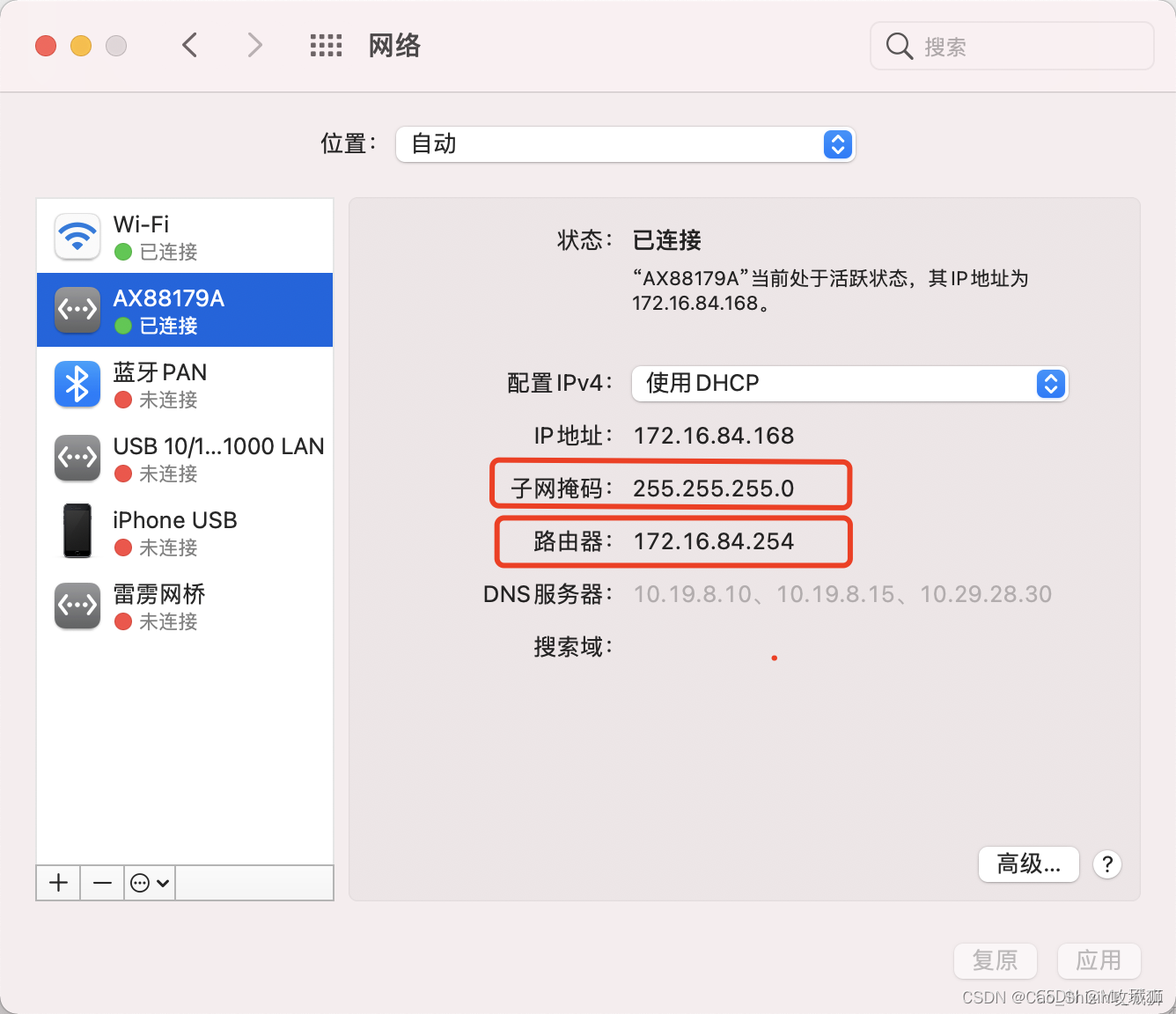
mac配置双网卡 mac同时使用内网和外网
在公司办公通常都会连内网,而连内网最大的限制就是不可以使用外网,那遇到问题也就不能google,而当连接无线的时候,内网的东西就不可以访问,也就不能正常办公,对于我这种小白来说,工作中遇到的问…...

深度探究深度学习常见数据类型INT8 FP32 FP16的区别即优缺点
定点和浮点都是数值的表示(representation),它们区别在于,将整数(integer)部分和小数(fractional)部分分开的点,点在哪里。定点保留特定位数整数和小数,而浮点…...
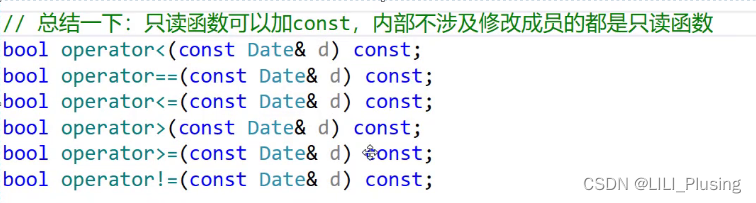
C++——const成员
这里先用队列举例: #define _CRT_SECURE_NO_WARNINGS 1 #include <iostream> #include <assert.h> using namespace std; class SeqList { public:void pushBack(int data){if (_size _capacity){int* tmp (int*)realloc(a, sizeof(int) * 4);if (tm…...
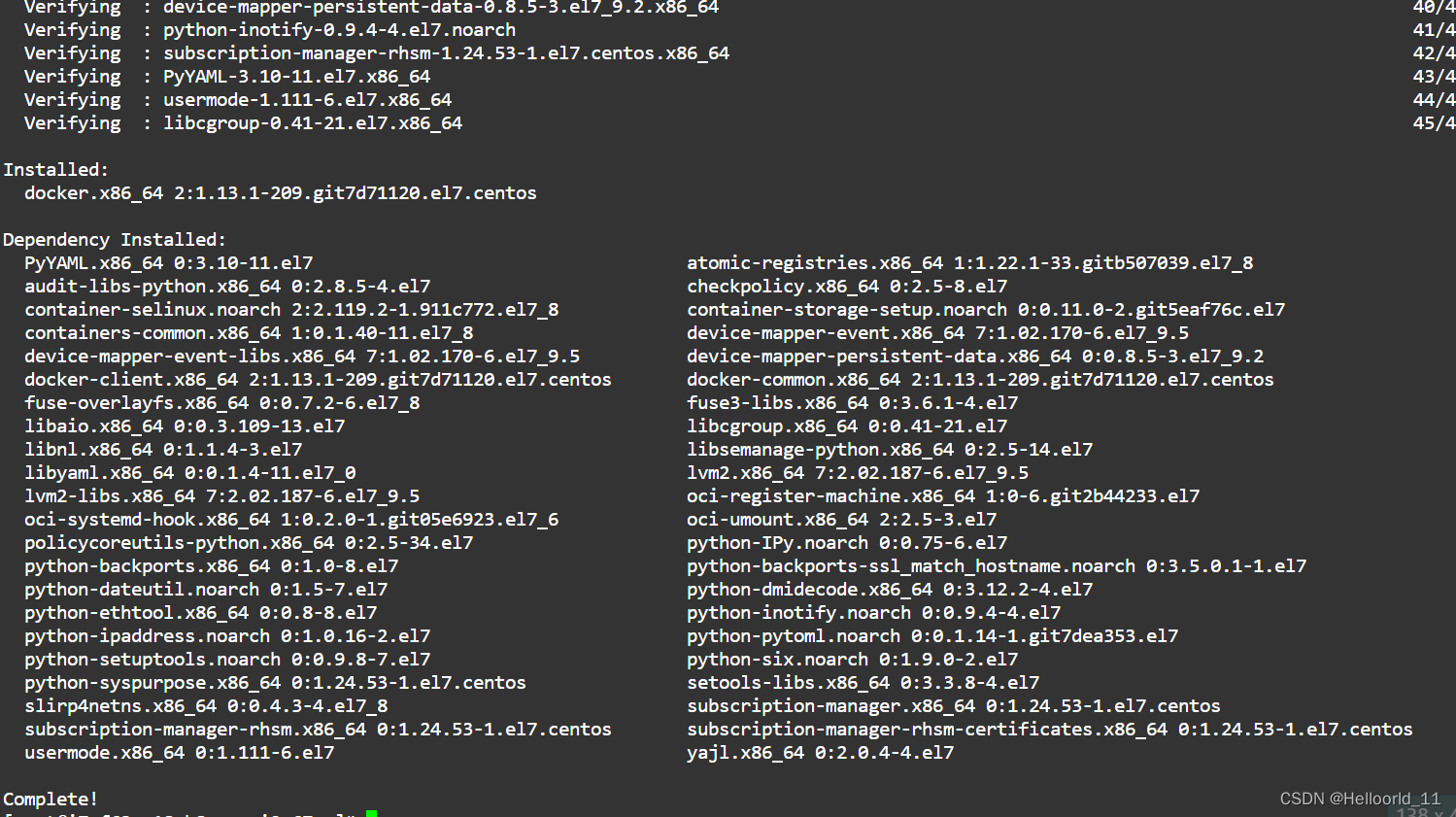
使用阿里云服务器学习Docker
首先我这里选择的系统服务器是CentOS 7.9 64位 因为centos系统里面的安装指令是:yum,而非apt-get. yum install docker -y试着建立一个容器: docker run -d -p 80:80 httpd启动docker的守护进程: sudo systemctl start docker 查看Docke…...

通信原理板块——线性分组码之汉明码
微信公众号上线,搜索公众号小灰灰的FPGA,关注可获取相关源码,定期更新有关FPGA的项目以及开源项目源码,包括但不限于各类检测芯片驱动、低速接口驱动、高速接口驱动、数据信号处理、图像处理以及AXI总线等 1、汉明码 (1)常见概念 代数码&…...
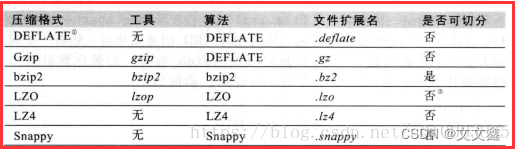
Hive 常用存储、压缩格式
1. Hive常用的存储格式 TEXTFI textfile为默认存储格式 存储方式:行存储 磁盘开销大 数据解析开销大 压缩的text文件 hive 无法进行合拆分 SEQUENCEFILE sequencefile二进制文件,以<key,value>的形式序列到文件中 存储方式:行存储 可…...

搞懂它,就可以把结构体玩活了~
正文 大家周末好,我是bug菌~ 今天主要是跟大家详细聊聊container_of这个宏定义,非常经典的宏,只是一直没有抽时间细细品味,今天就跟大家一起来看看有何神奇之处: 1 offsetof 首先我们需要简单看看offsetof(TYPE, MEMBER) 这个宏定…...

快速搭建AI绘画平台:基于图图的嗨丝造相与阿里云GPU的完整解决方案
快速搭建AI绘画平台:基于图图的嗨丝造相与阿里云GPU的完整解决方案 1. 项目概述与准备工作 1.1 什么是图图的嗨丝造相-Z-Image-Turbo 图图的嗨丝造相-Z-Image-Turbo是一个基于Z-Image-Turbo模型的LoRA变体,专门针对特定服饰风格(如大网渔网…...

IHaskell与Python对比分析:函数式编程在数据科学中的独特价值
IHaskell与Python对比分析:函数式编程在数据科学中的独特价值 【免费下载链接】IHaskell A Haskell kernel for the Jupyter project. 项目地址: https://gitcode.com/gh_mirrors/ih/IHaskell 在数据科学领域,选择合适的编程语言往往直接影响开发…...

CLAP-htsat-fused方言识别效果:中国8大方言区测试
CLAP-htsat-fused方言识别效果:中国8大方言区测试 1. 方言识别的技术挑战 方言识别一直是语音处理领域的难题。不同方言之间不仅词汇差异大,更重要的是声调、音韵、节奏等声学特征的巨大差异。传统语音识别模型在处理方言时往往表现不佳,主…...

从BOM到MES:制造业核心系统全解析,新手也能看懂
从BOM到MES:制造业核心系统全解析,新手也能看懂 走进任何一家现代化制造企业的生产车间,你会看到的不再是传统印象中机器轰鸣、工人忙碌的简单场景,而是由各种数字化系统精密协调运作的智能生态。对于刚接触制造业的新人来说&…...

QML Material项目实战:从零构建一个完整的Material Design应用
QML Material项目实战:从零构建一个完整的Material Design应用 【免费下载链接】qml-material qml-material - 一个在 QtQuick 中实现 Google 材料设计(Material Design)的 QML 部件库,支持跨平台运行。 项目地址: https://gitc…...

Flet跨平台GUI开发:从入门到实战
1. 为什么选择Flet开发跨平台GUI? 最近几年,Python在GUI开发领域一直缺少一个真正意义上的跨平台解决方案。传统的Tkinter功能有限,PyQt虽然强大但商业授权复杂,Kivy的语法又不够直观。直到我发现了Flet这个宝藏框架,它…...

HoRain云--OpenCod安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...
)
STC15单片机入门避坑指南:手把手教你用查询法实现带按键控制的流水灯(附Proteus工程)
STC15单片机实战避坑指南:从按键消抖到精准延时的流水灯设计精要 第一次点亮LED时的兴奋感,往往会被按键失灵、灯光乱跳的现实浇灭。作为STC15单片机入门的第一个综合实验,按键控制流水灯看似简单,却暗藏诸多新手陷阱。本文将用真…...

The Agency:助您改变工作流程的 AI 专家团队
The Agency:助您改变工作流程的 AI 专家团队 触手可及的完整 AI 代理机构——从前端奇才到 Reddit 社区达人,从创意灵感注入师到现实检验员。每位代理都是具备个性、流程和可靠交付成果的专业专家。 repo:https://github.com/msitarzewski/agency-agents…...

基于LabVIEW的纯软件信号发生器功能介绍
基于labview的信号发生器 功能介绍:纯软件方面的信号发生器,没有引入NI外部模块,生成的信号只在示波器中显示。 包括高斯白噪声、正弦波、方波、锯齿波、三角波、均匀白噪声、自定义公式,通过枚举按钮选择生成信号类型,…...