使用LLM-Tuning实现百川和清华ChatGLM的Lora微调
LLM-Tuning项目源码:
GitHub - beyondguo/LLM-Tuning: Tuning LLMs with no tears💦, sharing LLM-tools with love❤️.Tuning LLMs with no tears💦, sharing LLM-tools with love❤️. - GitHub - beyondguo/LLM-Tuning: Tuning LLMs with no tears💦, sharing LLM-tools with love❤️.![]() https://github.com/beyondguo/LLM-Tuning
https://github.com/beyondguo/LLM-Tuning
1、环境准备
训练主机配置:
- NVIDIA A100-PCIE-40GB
- Python 3.8.10
- CUDA: 11.2
安装依赖库:
pip install xformers==0.0.20
pip install torch==2.0.1
pip install transformers==4.29.1
pip install datasets==2.12.0
pip install accelerate==0.19.0
pip install sentencepiece==0.1.99
pip install tensorboard==2.13.0
pip install peft==0.3.02、数据准备
原始文件的准备
指令微调数据一般有输入和输出两部分,输出则是希望模型的回答,统一使用json的格式在整理数据,可以自定义输出输出的字段名。
{"q": "请计算:39 * 0 = 什么?", "a": "这是简单的乘法运算,39乘以0得到的是0"}
{"q": "题目:51/186的答案是什么?", "a": "这是简单的除法运算,51除以186大概为0.274"}
{"q": "鹿妈妈买了24个苹果,她想平均分给她的3只小鹿吃,每只小鹿可以分到几个苹果?", "a": "鹿妈妈买了24个苹果,平均分给3只小鹿吃,那么每只小鹿可以分到的苹果数就是总苹果数除以小鹿的只数。\n24÷3=8\n每只小鹿可以分到8个苹果。所以,答案是每只小鹿可以分到8个苹果。"}
...整理好数据后,保存为.json或者.jsonl文件,然后放入目录中的data/文件夹中。
对数据集进行分词
为了避免每次训练的时候都要重新对数据集分词,先分好词形成特征后保存成可直接用于训练的数据集。
例如:
- 原始指令微调文件为:data/ 文件夹下的 simple_math_4op.json 文件
- 输入字段为q,输出字段为a
- 希望经过 tokenize 之后保存到 data/tokenized_data/ 下名为 simple_math_4op 的文件夹中设定
- 文本最大程度为 2000
则我们可以直接使用下面这段命令(即tokenize.sh文件)进行处理:
CUDA_VISIBLE_DEVICES=0,1 python tokenize_dataset_rows.py \--model_checkpoint THUDM/chatglm-6b \--input_file simple_math_4op.json \--prompt_key q \--target_key a \--save_name simple_math_4op \--max_seq_length 2000 \--skip_overlength False处理完毕之后,在 data/tokenized_data/ 下生成名为 simple_math_4op 的文件夹,这就是下一步中可以直接用于训练的数据。
对比不同的 LLM,需在 tokenize.sh 文件里切换 model_checkpoint 参数。
3、使用 LoRA 微调
得到 tokenize 之后的数据集,就可以直接运行 chatglm_lora_tuning.py 来训练 LoRA 模型了。
对于不同的 LLM,需切换不同的 python 文件来执行:
- ChatGLM-6B 应使用
chatglm_lora_tuning.py - ChatGLM2-6B 应使用
chatglm2_lora_tuning.py - baichuan-7B 应使用
baichuan_lora_tuning.py - baichuan2-7B 应使用
baichuan2_lora_tuning.py - internlm-chat/base-7b 应使用
intermlm_lora_tuning.py - chinese-llama2/alpaca2-7b 应使用
chinese_llama2_alpaca2_lora_tuning.py
具体可设置的主要参数包括:
- tokenized_dataset, 分词后的数据集,即在 data/tokenized_data/ 地址下的文件夹名称
- lora_rank, 设置 LoRA 的秩,推荐为4或8,显存够的话使用8
- per_device_train_batch_size, 每块 GPU 上的 batch size
- gradient_accumulation_steps, 梯度累加,可以在不提升显存占用的情况下增大 batch size
- max_steps, 训练步数
- save_steps, 多少步保存一次
- save_total_limit, 保存多少个checkpoint
- logging_steps, 多少步打印一次训练情况(loss, lr, etc.)
- output_dir, 模型文件保存地址
例如我们的数据集为 simple_math_4op,希望保存到 weights/simple_math_4op ,则执行下面命令(即train.sh文件):
CUDA_VISIBLE_DEVICES=0,1 python chatglm_lora_tuning.py \--tokenized_dataset simple_math_4op \--lora_rank 8 \--per_device_train_batch_size 10 \--gradient_accumulation_steps 1 \--max_steps 100000 \--save_steps 200 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir weights/simple_math_4op训练完之后,可以在 output_dir 中找到 LoRA 的相关模型权重,主要是adapter_model.bin和adapter_config.json两个文件。
如何查看 tensorboard:
- 在 output_dir 中找到 runs 文件夹,复制其中日期最大的文件夹的地址,假设为 your_log_path
- 执行 tensorboard --logdir your_log_path 命令,就会在 http://localhost:6006/ 上开启tensorboard
- 如果是在服务器上开启,则还需要做端口映射到本地。
- 如果要自己手动进行端口映射,具体方式是在使用 ssh 登录时,后面加上 -L 6006:127.0.0.1:6006 参数,将服务器端的6006端口映射到本地的6006端口。
4、在本地大模型上加载LoRA并推理
把上面的 output_dir 打包带走,假设文件夹为 weights/simple_math_4op, 其中(至少)包含 adapter_model.bin 和 adapter_config.json 两个文件,用下面的方式直接加载,并推理
from peft import PeftModel
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation.utils import GenerationConfig
import torchdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 加载原始 LLM
model_path = "baichuan-inc/Baichuan2-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).half().to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)model.generation_config = GenerationConfig.from_pretrained(model_path)
messages = [{"role": "user", "content": "什么是视觉生成艺术"}]
output = model.chat(tokenizer, messages)
print(output)# 给原始 LLM 安装上你的 LoRA tool
model = PeftModel.from_pretrained(model, "weights/chat_messagge_4op").half().to(device)
output = model.chat(tokenizer, messages)
print(output)理论上可以通过多次执行 model = PeftModel.from_pretrained(model, "weights/simple_math_4op").half() 的方式,加载多个 LoRA 模型,从而混合不同Tool的能力,但实际测试的时候,由于暂时还不支持设置不同 LoRA weights的权重,往往效果不太好,存在覆盖或者遗忘的情况。
相关文章:
使用LLM-Tuning实现百川和清华ChatGLM的Lora微调
LLM-Tuning项目源码: GitHub - beyondguo/LLM-Tuning: Tuning LLMs with no tears💦, sharing LLM-tools with love❤️.Tuning LLMs with no tears💦, sharing LLM-tools with love❤️. - GitHub - beyondguo/LLM-Tuning: Tuning LLMs wit…...
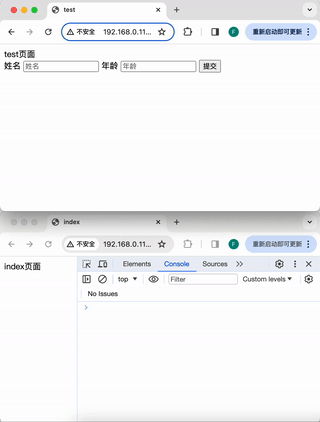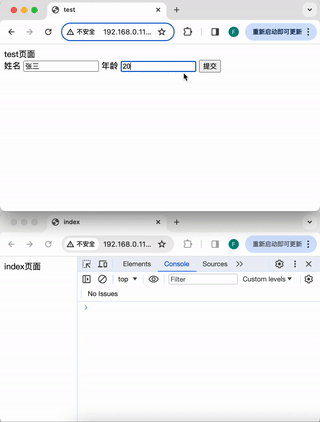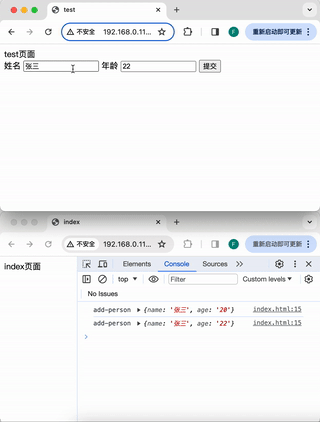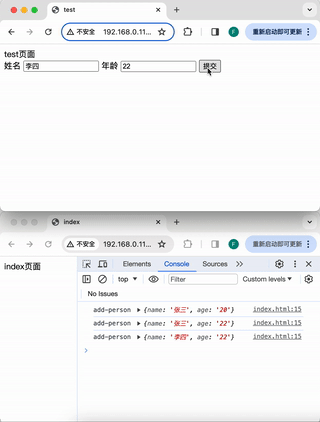
浏览器标签页之间的通信
前言 在开发管理后台页面的时候,会遇到这样一种需求:有一个列表页面,一个新增按钮,一个新增页面,点击新增按钮,在一个新的标签页中打开新增页面。并且,新增后要自动实时的更新列表页面的数据。…...
Semantic Kernel 学习笔记1
1. 挂代理跑通openai API 2. 无需魔法跑通Azure API 下载Semantic Kernel的github代码包到本地,主要用于方便学习python->notebooks文件夹中的内容。 1. Openai API:根据上述文件夹中的.env.example示例创建.env文件,需要填写下方两个内…...

图像二值化阈值调整——Triangle算法,Maxentropy方法
一. Triangle方法 算法描述:三角法求分割阈值最早见于Zack的论文《Automatic measurement of sister chromatid exchange frequency》主要是用于染色体的研究,该方法是使用直方图数据,基于纯几何方法来寻找最佳阈值,它的成立条件…...

监控视频片段合并完整视频|FFmpeg将多个视频片段拼接完整视频|PHP自动批量拼接合并视频
关于环境配置ffmpeg安装使用的看之前文章 哔哩哔哩缓存转码|FFmpeg将m4s文件转为mp4|PHP自动批量转码B站视频 <?php date_default_timezone_set("PRC"); header("Content-type: text/html; charsetutf-8"); set_time_limit(0);// 遍历获取文件 functi…...
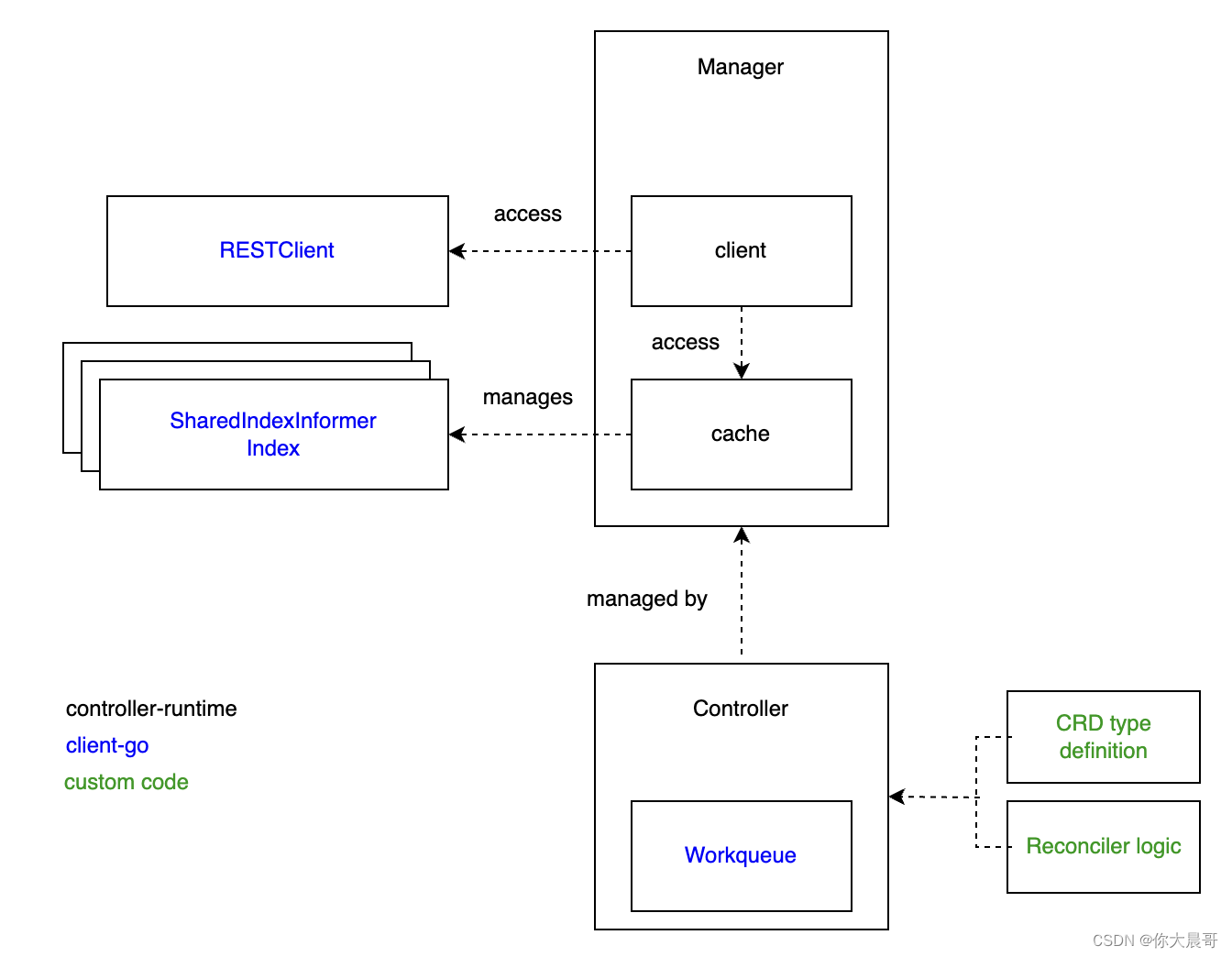
client-go controller-runtime kubebuilder
背景 这半年一直做k8s相关的工作,一直接触client-go controller-runtime kubebuilder,但是很少有文章将这三个的区别说明白,直接用框架是简单,但是出了问题就是黑盒,这不符合我的理念,所以这篇文章从头说起…...

【vue 如何解决响应式丢失】
响应式丢失原因 在 Vue 中,响应式丢失通常是由于以下原因导致的: 1. 使用非响应式对象或属性:在 Vue 中,只有使用 Vue 实例的 data 对象中的属性或使用 Vue.set() 方法添加的属性才是响应式的。如果使用普通对象或属性ÿ…...
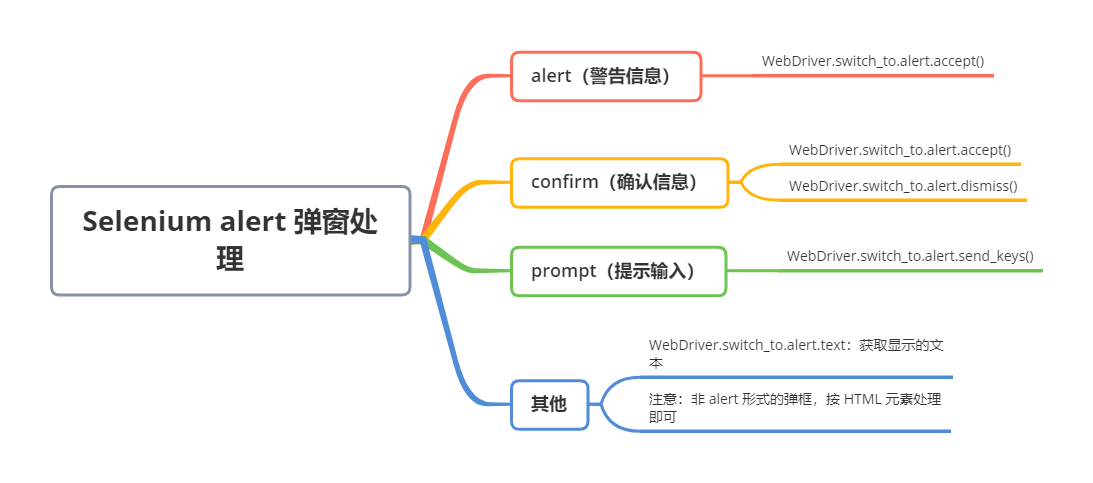
Selenium alert 弹窗处理!
页面弹窗有 3 种类型: alert(警告信息)confirm(确认信息)prompt(提示输入) 对于页面出现的 alert 弹窗,Selenium 提供如下方法: 序号方法/属性描述1accept()接受2dismis…...

有关自动化的脚本思考 python 按键 javascript
start 说来其实挺巧的,去年年中的时候,有一个同组的同事,由于工作流程需要,经常会打开某一网页,填写某些信息,然后上传特定的代码。 他有一次和我闲聊,他吐槽说,他每天的时间会被这…...

CKA认证模块②-K8S企业运维和落地实战-2
CKA认证模块②-K8S企业运维和落地实战-2 K8S常见的存储方案及具体应用场景分析 k8s存储-empty emptyDir类型的Volume是在Pod分配到Node上时被创建,Kubernetes会在Node上自动分配一个目录,因此无需指定宿主机Node上对应的目录文件。 这个目录的初始内容…...
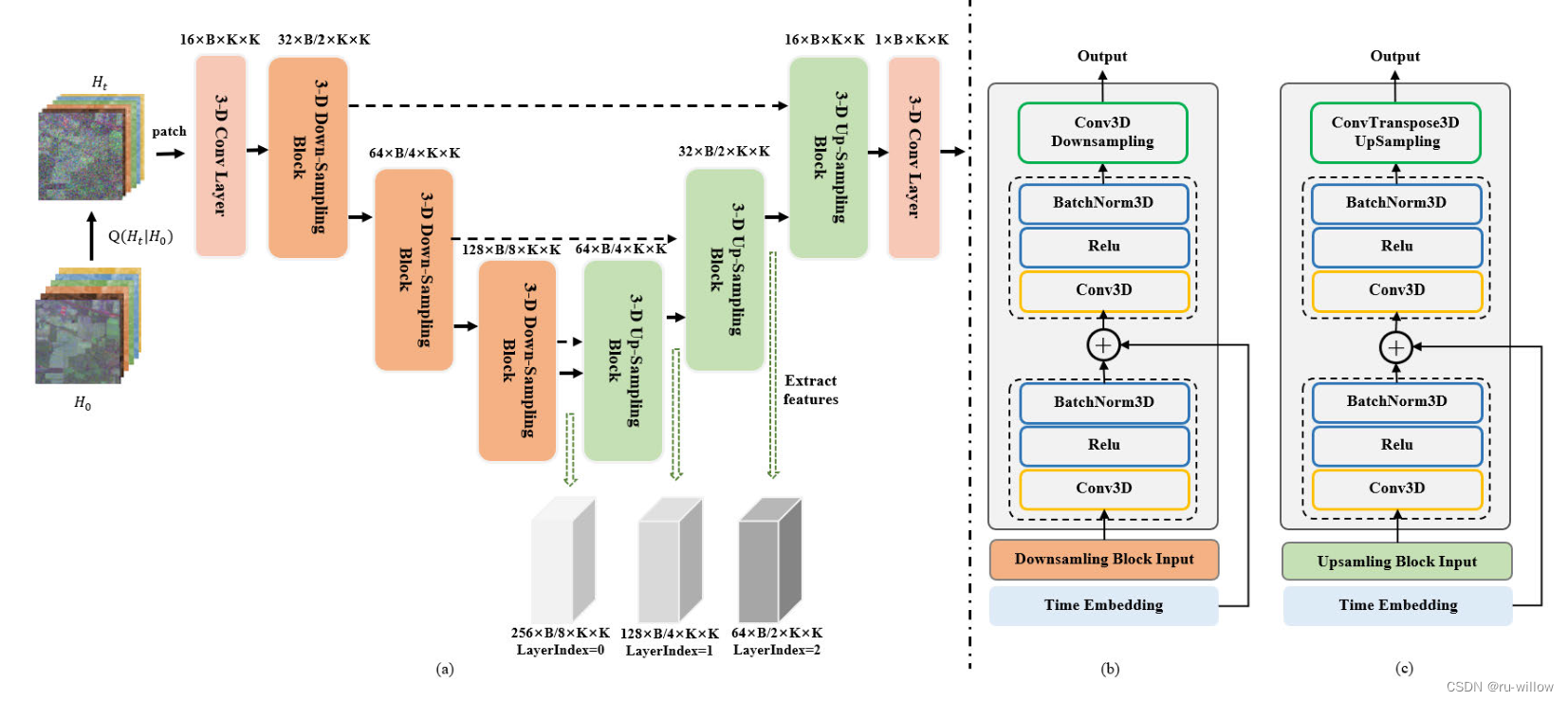
SpectralDiff论文阅读笔记
高光谱图像分类是遥感领域的一个重要问题,在地球科学中有着广泛的应用。近年来,人们提出了大量基于深度学习的HSI分类方法。然而,现有方法处理高维、高冗余和复杂数据的能力有限,这使得捕获数据的光谱空间分布和样本之间的关系具有…...
、搜索标签)
selenium基本使用、无头浏览器(chrome、FireFox)、搜索标签
selenium基本使用 这个模块:既能发请求,又能解析,还能执行js selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行 JavaScript代码的问题 selenium 会做web方向的自动化测试appnium 会做 app方向的自动化…...
Html 引入element UI + vue3 报错Failed to resolve component: el-button
问题:Html 引入element UI vue3 ,el-button效果不出来 <!DOCTYPE html> <html> <head><meta charset"UTF-8"><!-- import Vue before Element --> <!-- <script src"https://unpkg.com/vue2/dist…...

sen2cor安装
Sen2Cor工具安装教程-百度经验 (baidu.com)...

通付盾Web3专题 | SharkTeam:Web3安全实践与创新
在Web3领域,安全漏洞、黑客攻击已愈发成为用户和投资者重点关注的领域。如何保障加密资产的安全,Web3黑暗森林中又有哪些新的攻击模式产生,SharkTeam将从一线进行分享和讨论。 我们先来看一下2023年1月到8月的安全事件数量和损失的数据统计。…...

ARM Linux 基础学习 / Ubuntu 下的包管理 / apt工具
编辑整理 by Staok。 注:在 Github 上的原版文章日后可能会更新,在其它位置发的不会跟进。文章的 Gitee 仓库地址,Gitee 访问更流畅。 Ubuntu 下的包管理 / apt工具 包管理系统的功能和优点大致相同,但打包格式和工具会因平台&a…...
springcloudalibaba入门详细使用教程
目录标题 一、简介二、SpringCloud Alibaba核心组件2-1、Nacos (配置中心与服务注册与发现)2-2、Sentinel (分布式流控)2-3、RocketMQ (消息队列)/RabbitMq/kafka2-4、Seata (分布式事务)2-5、Dubbo (RPC) 三、为什么大家看好 Spring Cloud Alibaba3-1、阿里巴巴强大的技术输出…...

C# DirectoryInfo类的用法
在C#中,DirectoryInfo类是System.IO命名空间中的一个类,用于操作文件夹(目录)。通过DirectoryInfo类,我们可以方便地创建、删除、移动和枚举文件夹。本文将详细介绍DirectoryInfo类的常用方法和属性,并提供…...
)
IDEA常用快捷键大全(详解)
如何在IDEA中进行内容全局查找 在idea中进行全局查找,可以使用快捷键“Ctrl Shift F”或者在菜单栏中选择Edit > Find > Find in Path。在弹出的界面中,输入要查找的内容。如果“Ctrl Shift F”这个快捷键无法实现全局查找,可以尝…...

设计模式之解释器模式
阅读建议 嗨,伙计!刷到这篇文章咱们就是有缘人,在阅读这篇文章前我有一些建议: 本篇文章大概5000多字,预计阅读时间长需要5分钟。本篇文章的实战性、理论性较强,是一篇质量分数较高的技术干货文章&#x…...
 + 动态库(.so))
【Linux】静态库(.a) + 动态库(.so)
Linux 静态库(.a) 动态库(.so) 统一示例: 库名:test → 静态库 libtest.a,动态库 libtest.so源文件:test.c、main.c头文件路径:./include库文件路径:./lib用户家目录路径:/home/youruser/yourl…...

告别‘电音’:用WaveRNN和FFTNet给你的AI语音合成项目选个又快又好的声码器
神经声码器选型实战:从WaveRNN到FFTNet的高效语音合成方案 语音合成技术正在经历一场由深度学习驱动的革命,而声码器(Vocoder)作为将频谱特征转换为自然波形的关键组件,其性能直接影响着合成语音的质量和效率。面对市…...

基于单细胞测序技术的细胞通讯分析方法及其应用
一、细胞通讯与单细胞测序技术的研究意义多细胞生物由不同类型的细胞构成一个开放的社会。在这一社会中,单个细胞之间必须协调其行为,因此建立有效的通讯联络机制至关重要。细胞通讯是指一个细胞发出的信息通过介质传递至另一个细胞,并引发相…...
)
LeetCode刷题笔记:用动态规划一口气搞定6道回文串问题(附Java代码)
动态规划解回文问题:从子串到子序列的通用解法 回文串问题在算法面试中出现的频率居高不下,无论是统计回文子串数量、寻找最长回文子串,还是处理回文子序列,动态规划(DP)都是解决这类问题的利器。本文将带你系统掌握六种经典回文问…...

立创泰山派RK3566开发板串口调试:从1500000到115200的保姆级修改指南
立创泰山派RK3566开发板串口调试:从1500000到115200的保姆级修改指南 刚拿到立创泰山派RK3566开发板时,很多开发者都会遇到一个令人头疼的问题——默认的串口波特率高达1500000bps,而市面上大多数串口调试工具根本不支持这个速率。这就像拿到…...
)
智慧算力枢纽中心建设方案:从“烟囱林立”到“云网融合”的数字化重构(PPT)
摘要:本文基于《智慧算力枢纽中心建设方案》,深度剖析了在数字经济爆发式增长背景下,如何通过“云-网-端”一体化架构解决传统IT基础设施“资源孤岛、运维割裂、安全脆弱”的行业痛点。文章详细阐述了从传统服务器向全栈资源池化演进的技术路…...

CDAN不只是个算法:拆解它在自动驾驶语义分割中的落地挑战与调优心得
CDAN不只是个算法:拆解它在自动驾驶语义分割中的落地挑战与调优心得 清晨的测试场上,一辆自动驾驶汽车正试图识别被暴雨模糊的车道线——这是昨晚刚从仿真环境迁移过来的语义分割模型第一次面对真实世界的挑战。作为算法工程师,我们早已习惯…...

FlowState Lab版本管理与回滚:在星图平台实现平滑升级
FlowState Lab版本管理与回滚:在星图平台实现平滑升级 1. 为什么需要版本管理 在AI模型开发过程中,版本管理就像给代码打标签一样重要。想象一下,你正在使用FlowState Lab开发一个智能客服系统,突然发现最新更新的模型开始给出奇…...

移动端SEO优化有什么技巧
移动端SEO优化有什么技巧 在互联网时代,移动端已经成为人们获取信息和服务的主要途径。因此,如何在移动端上进行SEO优化,成为了每一个网站运营者关注的重点。本文将详细探讨移动端SEO优化的技巧,帮助你提升网站在移动端的搜索引擎…...

Python办公自动化教程 - openpyxl让Excel处理变得轻松
Python办公自动化教程 - openpyxl让Excel处理变得轻松适用人群:零基础办公人员、想提高工作效率的非IT专业人士 学习目标:掌握使用Python处理Excel文件,实现日常办公自动化 前置知识:不需要任何编程基础,只要会操作电脑…...