BEVFormer 论文阅读
论文链接
BEVFormer

- BEVFormer,这是一个将Transformer和时间结构应用于自动驾驶的范式,用于从多相机输入中生成鸟瞰(BEV)特征
- 利用查询来查找空间/时间,并相应地聚合时空信息,从而为感知任务提供更强的表示
0. Abstract
- BEVFormer,通过时空转换器学习统一的BEV表示,以支持多个自动驾驶感知任务
- 过预定义的网格状BEV查询与空间和时间空间相互作用,以利用空间和时间信息
- 为了聚合空间信息,设计了空间交叉注意力,每个BEV查询从不同摄像机视图中提取感兴趣区域的空间特征
- 对于时间信息,提出了时间自注意力,以循环地融合历史BEV信息
1. Abstract
- 相比于基于激光雷达的对应方法,摄像头拥有能够检测远距离物体和识别基于视觉的道路元素(例如,交通信号灯、停车线)的优势
- 基于单目框架和跨摄像头后处理的方法性能和效率较低
- 作为单目框架的替代方案,更统一的框架是从多摄像头图像中提取整体表示
- 鸟瞰图(BEV)是周围场景的常用表示,清楚地呈现了物体的位置和规模
- BEV 是连接时空空间的理想桥梁,利用 BEV 特征循环传递从过去到现在的时间信息,与 RNN 异曲同工
- BEVFormer 包含三个关键设计
- 网格状 BEV 查询,通过注意力机制灵活地融合空间和时间特征
- 空间交叉注意力模块,聚合来自多个维度的空间特征
- 时间自注意力模块,用于从历史 BEV 特征中提取时间信息
该模型可以与不同的特定任务头,进行端到端 3D 对象检测和地图分割
本文的主要贡献
- 提出了 BEVFormer,**一种时空转换器编码器,**可将多摄像机和/或时间戳输入投射到 BEV 表示中。凭借统一的 BEV 特征,可以同时支持多个自动驾驶感知任务,包括 3D 检测和地图分割
- 设计了可学习的 BEV 查询以及空间交叉注意层和时间自注意层,分别从跨摄像机查找空间特征和从历史 BEV 查找时间特征,然后将它们聚合成统一的 BEV 特征
- 在多个具有挑战性的基准上评估了所提出的 BEVFormer。始终实现了改进的性能
2. Related Work
2.1 Transformer-based 2D perception
- DETR 使用一组对象查询直接由交叉注意力解码器生成检测结果,但训练时间长
- Deformable DETR 可变形注意力与局部感兴趣区域交互,仅对每个参考点附近的 K 个点进行采样并计算注意力结果,效率很高并显着缩短了训练时间
2.2 Camera-based 3D Perception
经典方案
- 基于 2D 边界框预测 3D 边界框
- 将图像特征转换为 BEV 特征,并从自上而下的视图预测 3D 边界框
- 利用深度估计或分类深度分布中的深度信息将图像特征转换为 BEV 特征
**多相机生成 BEV **
- 通过逆透视映射 (IPM) 将透视图转换为 BEV
- 根据深度分布生成 BEV 特征
- 通过堆叠来自多个时间戳的BEV特征来考虑时间信息
3. BEVFormer
提出了一种新的基于 Transformer 的 BEV 生成框架,它可以通过注意力机制有效聚合来自多视图相机的时空特征和历史 BEV 特征
3.1 Overall Architecture

-
BEVFormer 有 6 个编码器层,每个编码器层都遵循 Transformer 的传统结构
-
除此之外有三种定制设计,即 BEV 查询、空间交叉注意力和时间自注意力
-
BEV 查询:网格状的可学习参数,旨在通过注意机制从多摄像机视图查询 BEV 空间中的特征
-
空间交叉注意力和时间自注意力:与 BEV 查询一起使用的注意力层,用于根据 BEV 查询查找和聚合多摄像机图像中的空间特征以及历史 BEV 中的时间特征
-
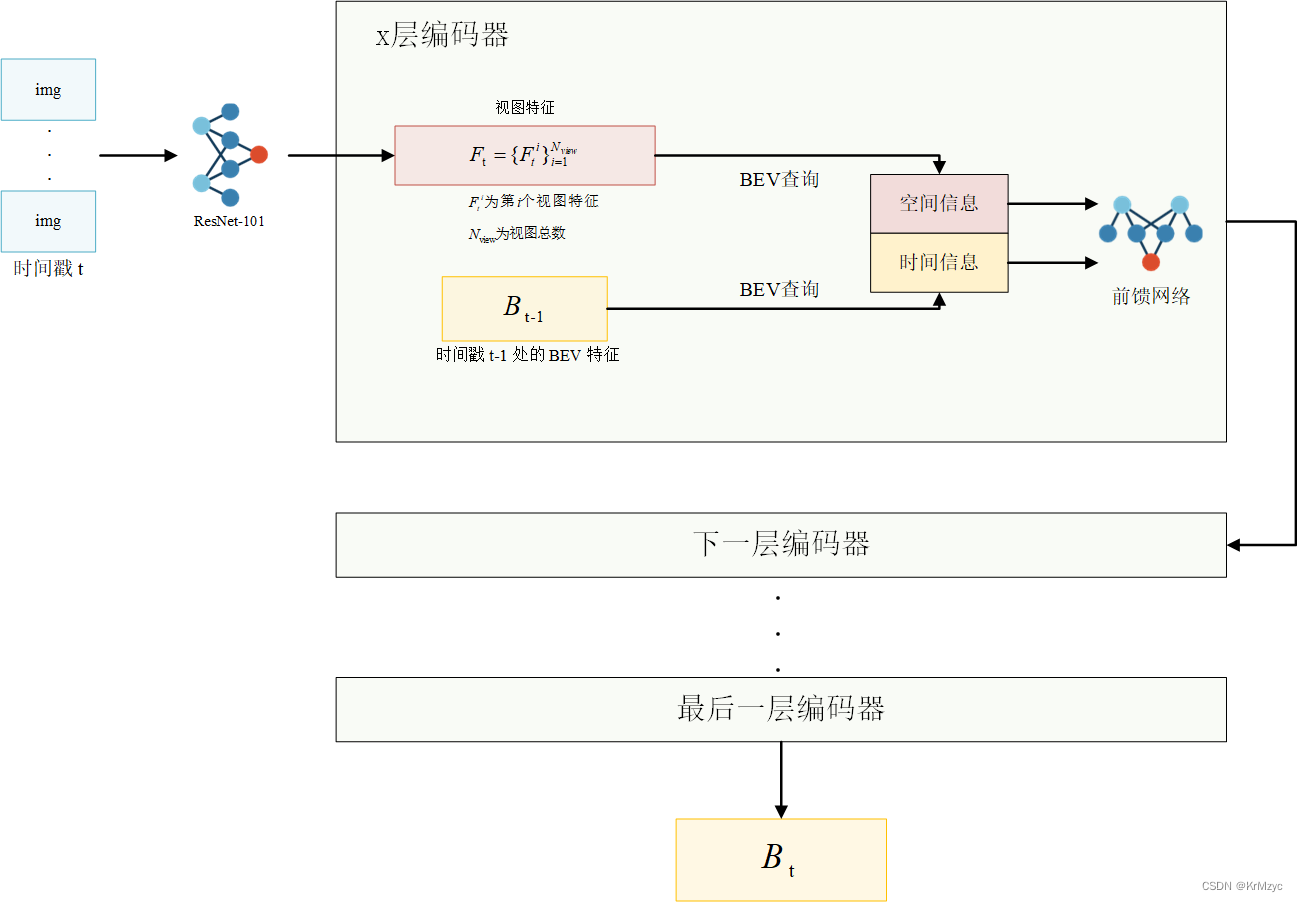
3.2 BEV Queries
- 预先定义一组网格状的可学习参数 Q ∈ R H × W × C Q ∈ \mathbb{R}^{H×W×C} Q∈RH×W×C 作为 BEVFormer 的查询,其中 H、W 是 BEV 平面的空间形状
- 位于 Q 的 p = ( x , y ) p = (x, y) p=(x,y) 处的查询 Q p ∈ R 1 × C Q_p ∈ \mathbb{R}^{1×C} Qp∈R1×C 负责 BEV 平面中相应的网格单元区域
- BEV 平面中的每个网格单元对应于现实世界的 s 米大小。默认情况下,BEV 功能的中心对应于本车的位置
- 将 BEV 查询 Q 输入到 BEVFormer 之前将可学习的位置嵌入添加到其中
3.3 Spatial Cross-Attention
-
多摄像头的 3D 感知输入规模大,故开发了基于可变形注意力的空间交叉注意力
-
每个 BEV 查询 Q p Q_p Qp 仅与其跨摄像机视图的感兴趣区域交互

-
首先将 BEV 平面上的每个查询提升为类似柱子的查询,从柱子中采样 Nref 3D 参考点,然后将这些点投影到 2D 视图。投影的2D点只能落在某些视图上,而其他视图不会命中
-
将点击视图称为 Vhit。将这些 2D 点视为查询 Q p Q_p Qp 的参考点,并从这些参考点周围的命中视图 Vhit 中采样特征
-
对采样特征进行加权求和,作为空间交叉注意力(SCA)的输出
S C A ( Q p , F t ) = 1 ∣ V h i t ∣ ∑ i ∈ V h i t ∑ j = 1 N r e f D e f o r m A t t n ( Q p , P ( p , i , j ) , F t i ) (Eq.2) SCA(Q_p, F_t) = \frac{1}{|V_{hit}|} \underset{i∈Vhit}∑ \sum\limits^{N_{ref}}_{j=1} DeformAttn(Q_p, \mathcal{P}(p,i,j), F^i_t ) \tag{Eq.2} SCA(Qp,Ft)=∣Vhit∣1i∈Vhit∑j=1∑NrefDeformAttn(Qp,P(p,i,j),Fti)(Eq.2)
其中 i 索引相机视图,j 索引参考点,Nref 是每个 BEV 查询的总参考点。 F t i F_t^i Fti 是第 i 个摄像机视图的特征。对于每个 BEV 查询 Q p Q_p Qp,我们使用投影函数 P ( p , i , j ) \mathcal{P}(p,i,j) P(p,i,j) 来获取第 i 个视图图像上的第 j 个参考点对于投影函数:
-
首先计算与位于 Q 的 p = ( x , y ) p=(x,y) p=(x,y) 处的查询 Q p Q_p Qp 对应的现实世界位置 ( x ′ , y ′ ) (x',y') (x′,y′)
x ′ = ( x − W 2 ) × s ; y ′ = ( y − H 2 ) × s (Eq.3) x'=(x-\frac{W}{2})\times s;\ \ \ \ y'=(y-\frac{H}{2})\times s \ \tag{Eq.3} x′=(x−2W)×s; y′=(y−2H)×s (Eq.3)
H,W是BEV查询的空间形状,s 是BEV网格的分辨率大小, ( x ′ , y ′ ) (x',y') (x′,y′) 是本车位置为原点的坐标 -
预先定义了一组锚点高度 { z j ′ } j = 1 N r e f \{z'_j\}^{N_{ref}}_{j=1} {zj′}j=1Nref,以确保我们能够捕获出现在不同高度的线索。这样,对于每个查询 Q p Q_p Qp,我们获得了3D参考点 ( x ′ , y ′ , z j ′ ) j = 1 N r e f (x',y',z'_j)^{N_{ref}}_{j=1} (x′,y′,zj′)j=1Nref 的支柱
P ( p , i , j ) = ( x i j , y i j ) , w h e r e z i j ⋅ [ x i j y i j 1 ] T = T i ⋅ [ x ′ y ′ z j ′ 1 ] T \begin{align} \mathcal{P}(p,i,j)&=(x_{ij},y_{ij}), \\ where\ \ z_{ij} \cdot [x_{ij}\ \ y_{ij}\ \ 1]^T &= T_i\cdot[x'\ \ y'\ \ z'_j\ \ 1]^T \tag{Eq.4} \end{align} P(p,i,j)where zij⋅[xij yij 1]T=(xij,yij),=Ti⋅[x′ y′ zj′ 1]T(Eq.4)
-
-
3.4 Temporal Self-Attention
-
给定当前时间戳 t t t 处的 BEV 查询 Q Q Q 和时间戳 t − 1 t−1 t−1 处保留的历史 BEV 特征 B t − 1 B_{t−1} Bt−1
-
首先根据自我运动将 B t − 1 B_{t−1} Bt−1 与 Q Q Q 对齐,以使同一网格处的特征对应于相同的现实世界位置
-
将对齐的历史 BEV 特征 B t − 1 B_{t−1} Bt−1 表示为 B t − 1 ′ B'_{t−1} Bt−1′
-
时间自注意力(TSA)层对特征之间的时间联系进行建模
T S A ( Q p , { Q , B t − 1 ′ } ) = ∑ V ∈ { Q , B t − 1 ′ } D e f o r m A t t n ( Q p , p , V ) , TSA(Q_p,\{Q, B'_{t−1}\}) = \underset{V ∈\{Q,B'_{t−1}\}}{\sum} DeformAttn(Q_p,p,V), TSA(Qp,{Q,Bt−1′})=V∈{Q,Bt−1′}∑DeformAttn(Qp,p,V),- Q p Q_p Qp 表示位于 p = ( x , y ) p = (x, y) p=(x,y) 处的 BEV 查询
- 时间自注意力中的偏移量 Δ p Δp Δp 是通过 Q Q Q 和 B t − 1 ′ B'_{t−1} Bt−1′ 的串联来预测的
- 对于每个序列的第一个样本,时间自注意力将退化为没有时间信息的自注意力,用重复的 BEV 查询 { Q , Q } \{Q,Q\} {Q,Q} 替换 BEV 特征 { Q , B t − 1 ′ } \{Q,B'_{t−1}\} {Q,Bt−1′}
-
时间自注意力可以更有效地建模长时间依赖性
-
BEVFormer 从之前的 BEV 特征中提取时间信息,而不是多个堆叠 BEV 特征,因此需要更少的计算成本并受到更少的干扰信息
3.5 Applications of BEV Features
3D 目标检测
- 基于 2D 检测器 Deformable DETR 设计了一个端到端 3D 检测头。修改包括使用单尺度 BEV 特征 Bt 作为解码器的输入
- 预测 3D 边界框和速度而不是 2D 边界框,以及仅使用 L1 损失来监督 3D 边界框回归
- 借助检测头,模型可以端到端预测 3D 边界框和速度,无需 NMS 后处理
地图分割
- 基于 2D 分割方法 Panoptic SegFormer 设计了一个地图分割头
- 基于BEV的地图分割与常见的语义分割基本相同
3.6 Implementation Details
训练阶段
- 对于时间戳 t 的每个样本,从过去 2 秒的连续序列中随机采样另外 3 个样本,将这四个样本的时间戳记为 t−3、t−2、t−1 和 t
- 循环生成 BEV 特征 { B t − 3 , B t − 2 , B t − 1 } \{B_{t−3}, B_{t−2}, B_{t−1}\} {Bt−3,Bt−2,Bt−1},并且此阶段不需要梯度
- 对于时间戳 t−3 的第一个样本,没有先前的 BEV 特征,并且时间自注意力退化为自注意力
- 模型基于多相机输入和先验BEV特征 B t − 1 B_{t−1} Bt−1 生成BEV特征 B t B_t Bt,使得 B t B_t Bt包含跨越四个样本的时间和空间线索
- 最后,我们将 BEV 特征 B t B_t Bt 输入到检测和分割头中并计算相应的损失函数
推理阶段
- 在推理阶段,按时间顺序评估视频序列的每一帧
- 前一个时间戳的BEV特征被保存并用于下一个时间戳
4. Experiments
数据集
- nuScenes Dataset
- Waymo Open Dataset
4.1 Experimental Settings
- 两种主干:从 FCOS3D 检查点初始化的 ResNet101-DCN 和从 DD3D 检查点初始化的VoVnet-99
- 利用 FPN 的输出多尺度特征,大小为 1/16、1/32、1/64,维度为 C = 256
- 对于nuScenes上的实验,BEV查询的默认大小为200×200,X轴和Y轴的感知范围为[−51.2m,51.2m],BEV网格的分辨率s的大小为0.512m
- 用 24 个时期训练模型,学习率为 2 × 1 0 − 4 2×10^{−4} 2×10−4
- 对于 Waymo 上的实验,BEV查询的默认空间形状为300×220,X轴的感知范围为[−35.0m,75.0m] Y 轴为 [−75.0m, 75.0m]。每个网格的分辨率 s 的大小为0.5m
Baseline
- 为了消除任务头的影响并公平地比较其他 BEV 生成方法,使用 VPN 和 Lift-Splat 来替换我们的 BEVFormer 并保持任务头和其他设置相同
- 通过将时间自注意力调整为普通自注意力而不使用历史 BEV 特征,将 BEVFormer 改编成名为 BEVFormer-S 的静态模型
4.2 3D Object Detection Results



4.3 Multi-tasks Perception Results

4.4 Ablation Study
空间交叉注意力的有效性

在可比较的模型规模下,可变形注意力明显优于其他注意力机制。全局注意力消耗过多的GPU内存,点交互的感受野有限。稀疏注意力可以实现更好的性能,因为它与先验确定的感兴趣区域交互,平衡感受野和 GPU 消耗
时间自注意力的有效性

时间信息的作用主要有以下几个方面:
- 时间信息的引入极大地有利于速度估计的准确性;
- 利用时间信息,预测物体的位置和方向更加准确;
- 由于时间信息包含过去的对象线索,我们在严重遮挡的对象上获得了更高的召回率
模型规模和延迟

从三个方面消除了 BEVFormer 的尺度,包括是否使用多尺度视图特征、BEV 查询的形状和层数,以验证性能和推理延迟之间的权衡
4.5 Visualization Results

5. Discussion and Conclusion
- 提出了 BEVFormer 从多摄像头输入生成鸟瞰图特征。 BEVFormer 可以有效聚合空间和时间信息并生成强大的 BEV 功能,同时支持 3D 检测和地图分割任务。
局限性:基于相机的方法在效果和效率上与基于激光雷达的方法仍然存在一定的差距。从 2D 信息准确推断 3D 位置仍然是基于相机的方法的长期挑战
更广泛的影响:BEVFormer 所展示的优势,例如更准确的速度估计和对低可见度物体的更高召回率,对于构建更好、更安全的自动驾驶系统及其他系统至关重要
相关文章:
BEVFormer 论文阅读
论文链接 BEVFormer BEVFormer,这是一个将Transformer和时间结构应用于自动驾驶的范式,用于从多相机输入中生成鸟瞰(BEV)特征利用查询来查找空间/时间,并相应地聚合时空信息,从而为感知任务提供更强的表示…...
Centos批量删除系统重复进程
原创作者:运维工程师 谢晋 Centos批量删除系统重复进程 客户一台CENTOS 7系统负载高,top查看有很多sh的进程,输入命令top -c查看可以看到对应的进程命令是/bin/bash 经分析后发现是因为该脚本执行时间太长,导致后续执…...
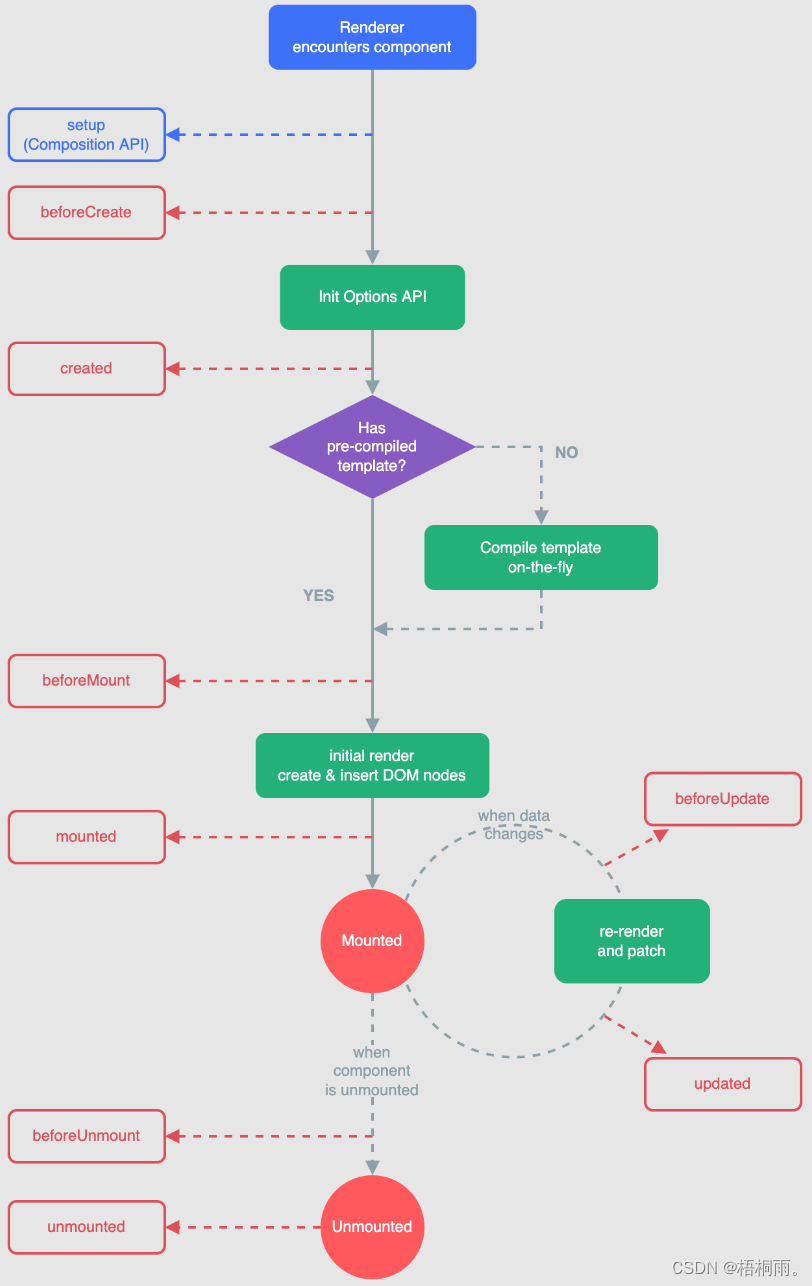
VUE组件的生命周期
每个 Vue 组件实例在创建时都需要经历一系列的初始化步骤,比如设置好数据侦听,编译模板,挂载实例到 DOM,以及在数据改变时更新 DOM。在此过程中,它也会运行被称为生命周期钩子的函数,让开发者有机会在特定阶…...

【Git系列】Github指令搜索
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【OpenCV】用数组给Mat图像赋值,单/双/三通道 Mat赋值
文章目录 5 Mat赋值5.1 Mat(int rows, int cols, int type, const Scalar& s)5.2 数组赋值 或直接赋值5.2.1 3*3 单通道 img5.2.2 3*3 双通道 img5.2.3 3*3 三通道 img5 Mat赋值 5.1 Mat(int rows, int cols, int type, const Scalar& s) Mat m(3, 3, CV_8UC3,Scalar…...
Doris:读取Doris数据的N种方法
目录 1.MySQL Client 2.JDBC 3. 查询计划 4.Spark Doris Connector 5.Flink Doris Connector 1.MySQL Client Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris。登录到doris服务器后&a…...

ceph-deploy bclinux aarch64 ceph 14.2.10
ssh-copy-id,部署机免密登录其他三台主机 所有机器硬盘配置参考如下,计划采用vdb作为ceph数据盘 下载ceph-deploy pip install ceph-deploy 免密登录设置主机名 hostnamectl --static set-hostname ceph-0 .. 3 配置hosts 172.17.163.105 ceph-0 172.…...
:使用lxml抓取相亲信息)
爬虫项目(13):使用lxml抓取相亲信息
文章目录 书籍推荐完整代码效果书籍推荐 如果你对Python网络爬虫感兴趣,强烈推荐你阅读《Python网络爬虫入门到实战》。这本书详细介绍了Python网络爬虫的基础知识和高级技巧,是每位爬虫开发者的必读之作。详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍 完整代码…...

mysql-数据库三大范式是什么、mysql有哪些索引类型,分别有什么作用 、 事务的特性和隔离级别
1. 数据库三大范式是什么? 数据库三大范式是设计关系型数据库时的规范化原则,确保数据库结构的合理性和减少数据冗余。 这三大范式分别是: - **第一范式(1NF):** 数据表中的所有列都是不可分割的原子数据项…...
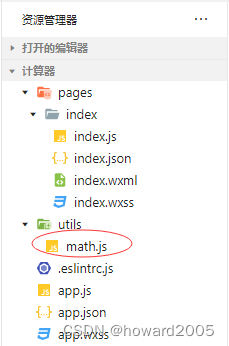
微信小程序案例3-2 计算器
文章目录 一、运行效果二、知识储备(一)data-*自定义属性(二)模块 三、实现步骤(一)准备工作1、创建项目2、设置导航栏 (二)实现页面结构1、编写页面整体结构2、编写结果区域的结构3…...
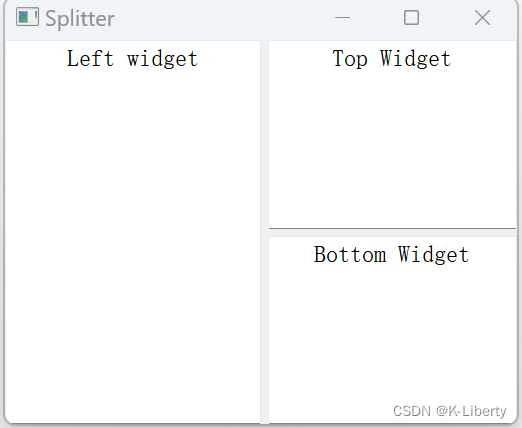
QT QSplitter
分裂器QSplitter类提供了一个分裂器部件。和QBoxLayout类似,可以完成布局管理器的功能,但是包含在它里面的部件,默认是可以随着分裂器的大小变化而变化的。 比如一个按钮放在布局管理器中,它的垂直方向默认是不会被拉伸的,但是放到分裂器中就可以被拉伸。还有一点不…...
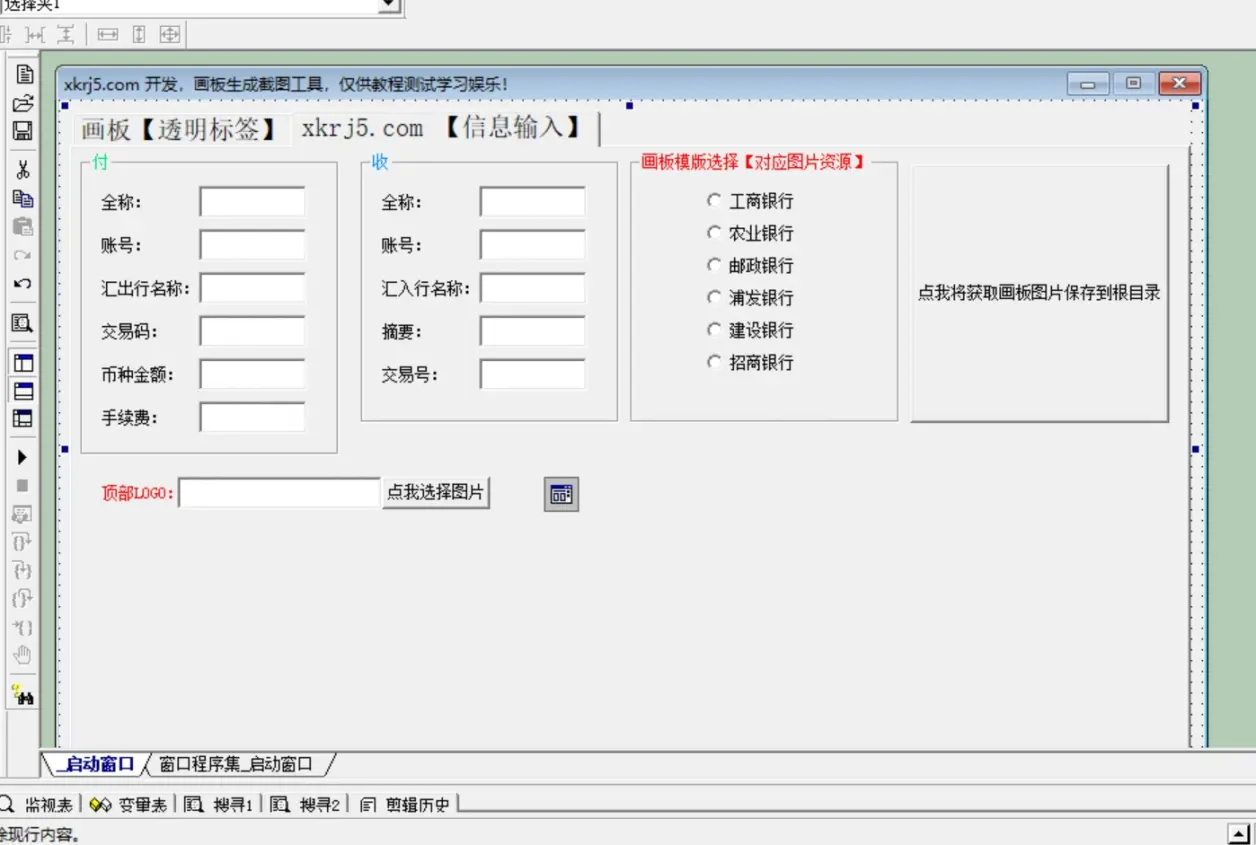
银行支付凭证截图生成器在线,工商邮政农业招商建设,画板+透明标签+图片框
用易语言设计了一个非常牛X的截图生成器,娱乐使用哈,软件我在这里也不会分享,模版网上找的,百度图库搜到的,上面的LOGO用的是一个在线生成器,然后标签用的黑月透明标签,加一个通用对话框读取图片…...

微服务概述
微服务架构是一种软件设计和开发范式,旨在将大型应用程序分解为一组小而独立的服务单元,这些单元可以独立开发、测试、部署和扩展。每个服务都专注于一个明确定义的业务功能,并通过轻量级的通信机制进行交互。以下是微服务架构的一些关键方面…...
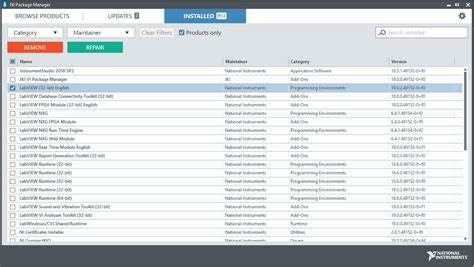
LabVIEW中NIPackageManager功能介绍
LabVIEW中PackageManager功能介绍 使用NIPackage Manager可安装、更新、修复和删除NI软件。 安装NI软件 使用PackageManager浏览和安装NI软件。 1. 在浏览产品选项卡上,单击产品类别以显示该类别中的可用产品。 2. 选择要安装的产品,然后单击…...

【C语言】sem_getvalue
sem_getvalue 是 POSIX 线程库中用于获取信号量当前值的一个函数。信号量(Semaphore)是用于编程中的同步工具,用于管理多个线程或进程对共享资源的并发访问。通常用于限制可以同时访问共享资源的线程数量。函数 sem_getvalue 的声明通常出现在…...

Linux的shell的$# | fi | 说明
$# | fi | 说明 在Linux的Shell脚本中,$# 是一个特殊变量,表示传递给脚本的参数个数。 例如,如果你运行一个脚本并传递了三个参数,那么在脚本内部使用 $# 将会得到 3。这对于确定脚本在执行时接收到了多少个参数是非常有用的。以…...

C //例 7.12 用选择法对数组中10个整数按由小到大排序。
C程序设计 (第四版) 谭浩强 例 7.12 例 7.12 用选择法对数组中10个整数按由小到大排序。 IDE工具:VS2010 Note: 使用不同的IDE工具可能有部分差异。 代码块 方法:使用指针、动态分配内存 #include <stdio.h> #include …...

Spring Bean循环依赖问题及解决
什么是循环依赖 类与类之间的依赖关系形成了闭环,就会导致循环依赖问题的产生。举例来说,假设存在两个服务类A和服务类B,如果A通过依赖注入的方式引用了B,且B通过依赖注入的方式引用了A,那么A和B之间就存在循环依赖。…...

Golang源码分析 | 程序引导过程
环境说明 CentOS Linux release 7.2 (Final) go version go1.16.3 linux/amd64 GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-80.el7使用gdb查看程序入口 编写一个简单的go程序 // main.go package mainfunc main() {print("Hello world") } 编译go …...
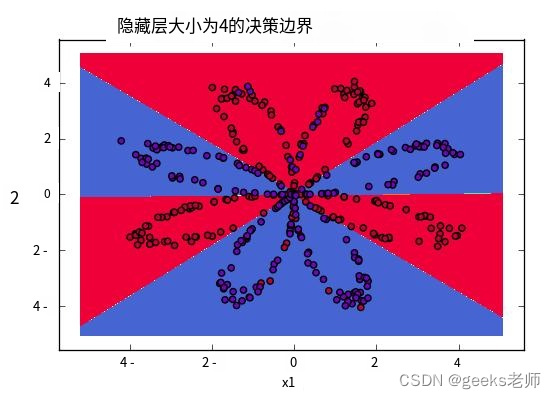
第三章:人工智能深度学习教程-基础神经网络(第四节-从头开始的具有前向和反向传播的深度神经网络 – Python)
本文旨在从头开始实现深度神经网络。我们将实现一个深度神经网络,其中包含一个具有四个单元的隐藏层和一个输出层。实施将从头开始,并实施以下步骤。算法: 1. 可视化输入数据 2. 确定权重和偏置矩阵的形状 3. 初始化矩阵、要使用的函数 4. 前…...

新手零基础入门:借助快马AI轻松理解并创建你的无名小站
作为一个刚入门编程的新手,想要搭建一个属于自己的"无名小站"确实会感到无从下手。最近我在InsCode(快马)平台上尝试了这个项目,整个过程出乎意料地顺利,下面分享我的学习心得。 项目结构规划 首先需要明确网站的基本框架。我的无名…...

如何在浏览器中实现实时人物移除:TensorFlow.js完整指南
如何在浏览器中实现实时人物移除:TensorFlow.js完整指南 【免费下载链接】Real-Time-Person-Removal Removing people from complex backgrounds in real time using TensorFlow.js in the web browser 项目地址: https://gitcode.com/gh_mirrors/re/Real-Time-Pe…...

LiuJuan Z-Image Generator完整指南:宽松加载strict=False适配非标权重
LiuJuan Z-Image Generator完整指南:宽松加载strictFalse适配非标权重 1. 引言:当定制权重遇上标准模型 你有没有遇到过这种情况?好不容易找到一个效果惊艳的定制版模型权重,兴冲冲地下载下来,结果在加载时却报了一堆…...
)
别再只做静态分析了!用DPABI解锁小鼠脑功能动态连接(Temporal Dynamic Analysis详解)
从静态到动态:DPABI在小鼠脑功能时间动态分析中的进阶实践 在神经影像研究领域,静息态功能磁共振成像(rs-fMRI)已成为探索大脑功能组织的强大工具。传统分析方法多聚焦于静态功能连接,将整个扫描时段视为一个整体计算相关性。然而࿰…...

WinThumbsPreloader:让Windows图片预览提速80%的缓存优化工具
WinThumbsPreloader:让Windows图片预览提速80%的缓存优化工具 【免费下载链接】WinThumbsPreloader-V2 WinThumbsPreloader is a powerful open source tool for quickly preloading thumbnails in Windows Explorer. 项目地址: https://gitcode.com/gh_mirrors/w…...

突破魔兽争霸3帧率限制:WarcraftHelper实现180fps流畅游戏体验全攻略
突破魔兽争霸3帧率限制:WarcraftHelper实现180fps流畅游戏体验全攻略 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 在现代高性能电脑上运…...

从零到一:手把手教你用TruckSim搭建你的第一辆虚拟牵引车模型
从零到一:手把手教你用TruckSim搭建你的第一辆虚拟牵引车模型 第一次打开TruckSim时,面对密密麻麻的参数和复杂的界面,很多新手会感到无从下手。作为一款专业的商用车动力学仿真软件,TruckSim确实有一定的学习门槛,但掌…...

【海洋空间信息工程概论 实验报告4】空间数据投影变换
上一篇:【海洋空间信息工程概论 实验报告3】海洋数据矢量化 目录 一、实验目的 二、实验环境 三、实验内容 实验步骤 编辑 实验心得 一、实验目的 由于数据源的多样性,当数据与我们研究、分析问题的空间参考系统(坐标系统、投影方式…...
与UniFlash下载全攻略)
MSPM0G3507开发实战:Keil环境下多款仿真器(CMSIS-DAP/ST-Link/J-Link)与UniFlash下载全攻略
1. 为什么选择Keil开发MSPM0G3507? 对于嵌入式开发者来说,选择一款趁手的开发环境往往能事半功倍。我在多个项目中测试过不同开发环境后,发现Keil MDK在MSPM0G3507开发中确实有不少优势。首先是生态支持完善,TI官方提供的SDK和示例…...

动态库路径配置实战:解决openssl symbol lookup error的深层解析
1. 问题背景:当openssl升级遇上symbol lookup error 上周我在升级服务器上的openssl时,遇到了一个典型的动态库问题。系统原本使用的是Ubuntu 20.04自带的openssl 1.1.1f,但项目需要用到1.1.1k的新特性。像大多数开发者一样,我选择…...