Flink在汽车行业的应用【面试加分系列】
很多同学问我为什么要发这些大数据前沿汇报?
一方面是自己学习完后觉得非常好,然后总结发出来方便大家阅读;另外一方面,看这些汇报对你的面试帮助会很大,特别是面试前可以看看即将面试公司在大数据前沿的发展动向(我曾经就有过一次经历,面试网易云音乐前,我在B站看了一个大佬分享的网易云实时数仓,刚好在面试的时候就碰见他了,最后反问就主动跟他说我看过他的汇报,然后还提出了自己的一些思考,面试官当场就给我通过了)
蔚来汽车
以下内容来自蔚来汽车Flink架构师的分享
用户背景
蔚来是一家全球化的智能电动汽车公司,于2014年11月成立。蔚来致力于通过提供高性能的智能电动汽车与
极致用户体验,为用户创造愉悦的生活方式。
平台建设
![[图片]](https://img-blog.csdnimg.cn/06a09c3cdefd4ddab0001080bbe258e1.png)
实时计算在蔚来汽车的发展主要经历了如下几个阶段:
- 2018年5月份,蔚来汽车开始接触实时计算,并采用Spark Streaming做一些简单的流式计算数据的处理;
- 2019年9月份,蔚来汽车引入了 Flink,通过命令行的方式进行提交,包括管理整个作业的生命周期;
- 2021年1月份,蔚来汽车上线了实时计算平台 1.0,并开始进行 2.0 版本的开发。
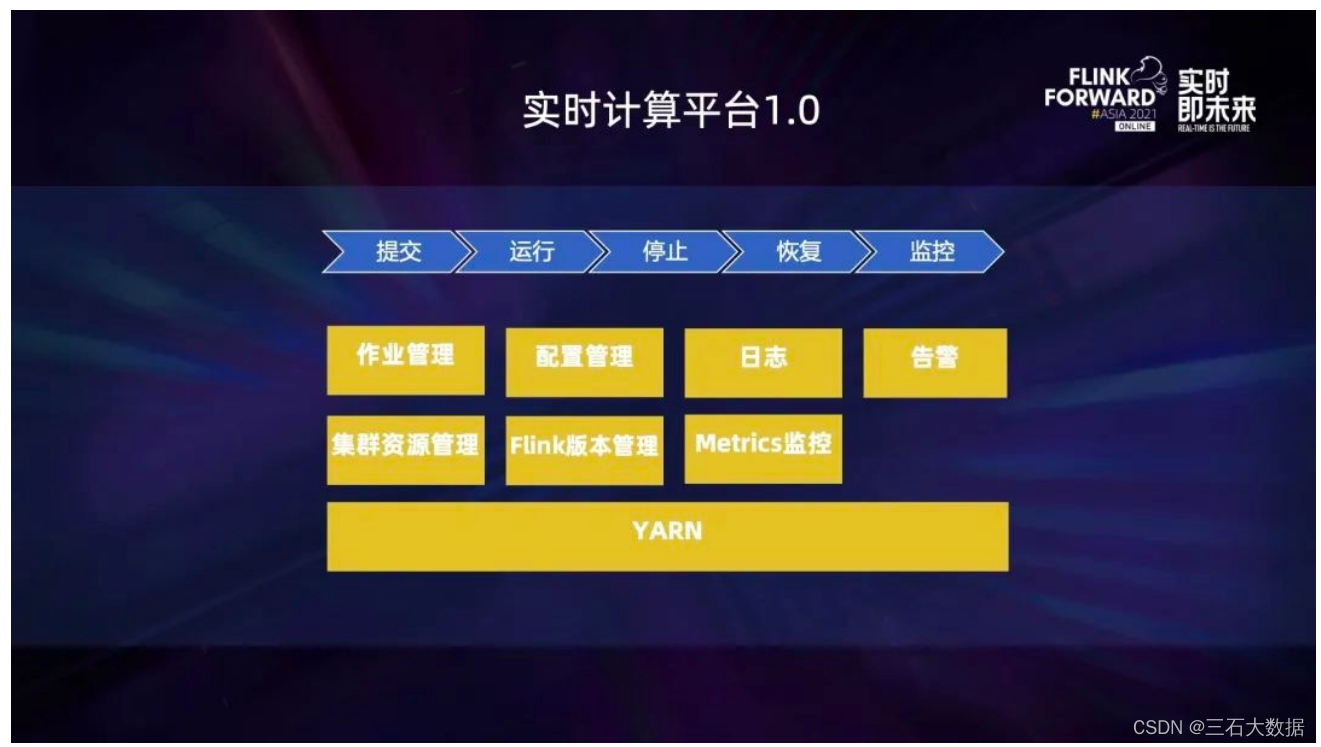 蔚来汽车实时计算平台 1.0 的生命周期如上图。任务写完之后打成 jar 包进行上传提交,后续的开启任务、停止、恢复和监控都能够自动进行。作业管理主要负责作业的创建、运行、停止、恢复和更新。日志主要记录 Flink 任务提交时的一些日志,如果是运行时的日志还是要通过 Yarn 集群里的 log 来查看,稍微有点麻烦。关于监控和告警模块,首先 metrics监控主要是利用Flink内置的指标上传到 Prometheus,然后配置各种监控的界面;告警也 是利用Prometheus 的一些指标进行规则的设置,然后进行告警的设置。Yarn 负责整体集群资源的管理。
蔚来汽车实时计算平台 1.0 的生命周期如上图。任务写完之后打成 jar 包进行上传提交,后续的开启任务、停止、恢复和监控都能够自动进行。作业管理主要负责作业的创建、运行、停止、恢复和更新。日志主要记录 Flink 任务提交时的一些日志,如果是运行时的日志还是要通过 Yarn 集群里的 log 来查看,稍微有点麻烦。关于监控和告警模块,首先 metrics监控主要是利用Flink内置的指标上传到 Prometheus,然后配置各种监控的界面;告警也 是利用Prometheus 的一些指标进行规则的设置,然后进行告警的设置。Yarn 负责整体集群资源的管理。
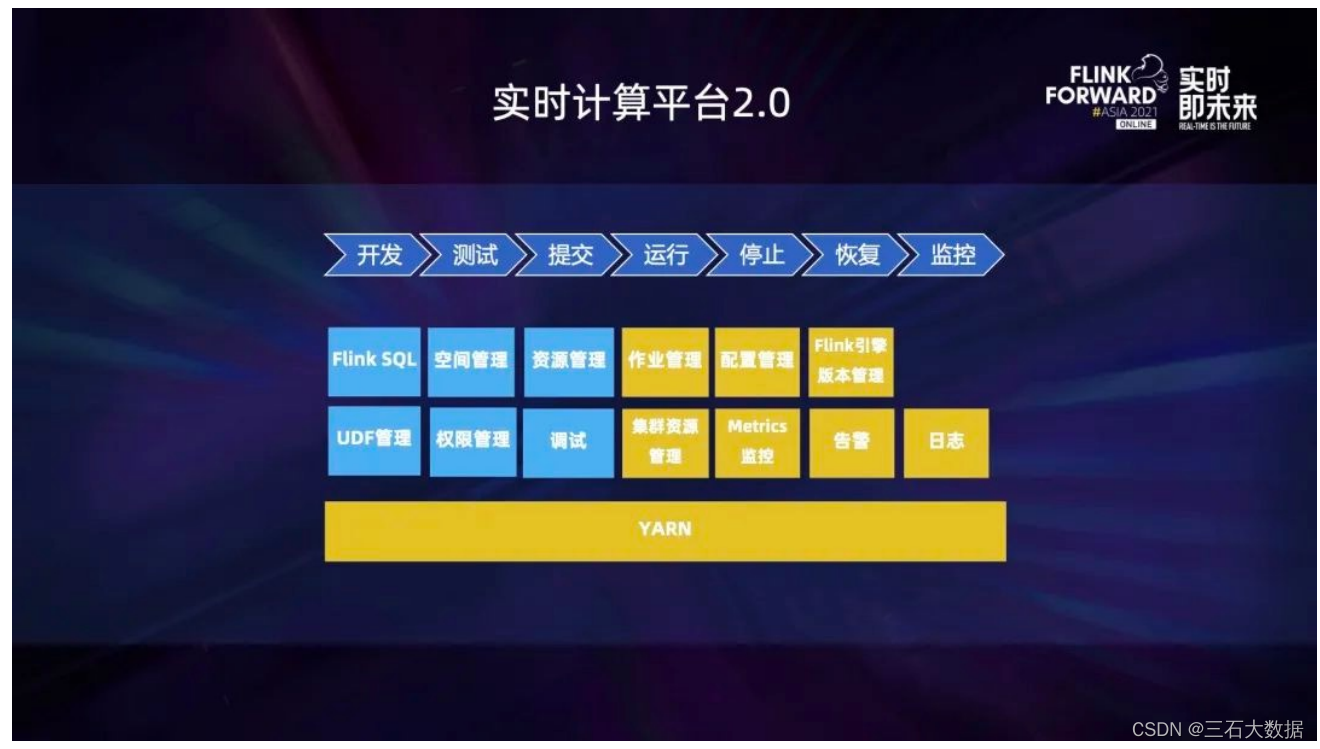
上图是实时计算平台 2.0。相对于 1.0,最大的区别是蓝色的部分。对于实时计算平台的形态,可能并没有一
个统一的标准,它与每个公司本身的情况息息相关,比如公司本身的体量和规模、公司对实时计算平台的资
源投入等,最终还是应该以适用于公司本身的现状为最佳标准。2.0 版本主要增加从开发到测试两个阶段功能
的支持,具体包括:
- FlinkSQL:它是很多公司的实时计算平台都支持的功能,它的优点在于可以降低使用成本,也比较简单易用;
- 空间管理:不同的部门和不同的组可以在自己的空间里进行作业的创建、管理。有了空间的概念之后,可以利用它做一些权限的控制,比如只能在自己有权限的空间里进行一些操作;
- UDF 管理:使用了 FlinkSQL 的前提下,就可以基于 SQL 的语义用 UDF 的方式扩充功能。此外,UDF 还能用于 Java 和 Schema 任务,可以把一些公用的功能包装成 UDF,降低开发成本。它还有一个很重要的功能就是调试,可以简化原有的调试流程,做到用户无感知。
实时计算平台 2.0 的核心目标是减轻数据团队的负担。只要把实时计算平台做得足够完善、易用和简单,数
据中台团队就可以使用 FlinkSQL 完成数据的同步和处理,理想的情况下他们甚至不需要知道 Flink 的相关概
念就可以完成这些工作,并且不需要依赖数据团队,大大降低沟通成本,进度会更快。这样在部门内可以形
成闭环,产品经理的工作也会变得更轻松,在需求的阶段不需要引入太多的团队,效率也会大大提升。
业务场景
1.实时看板
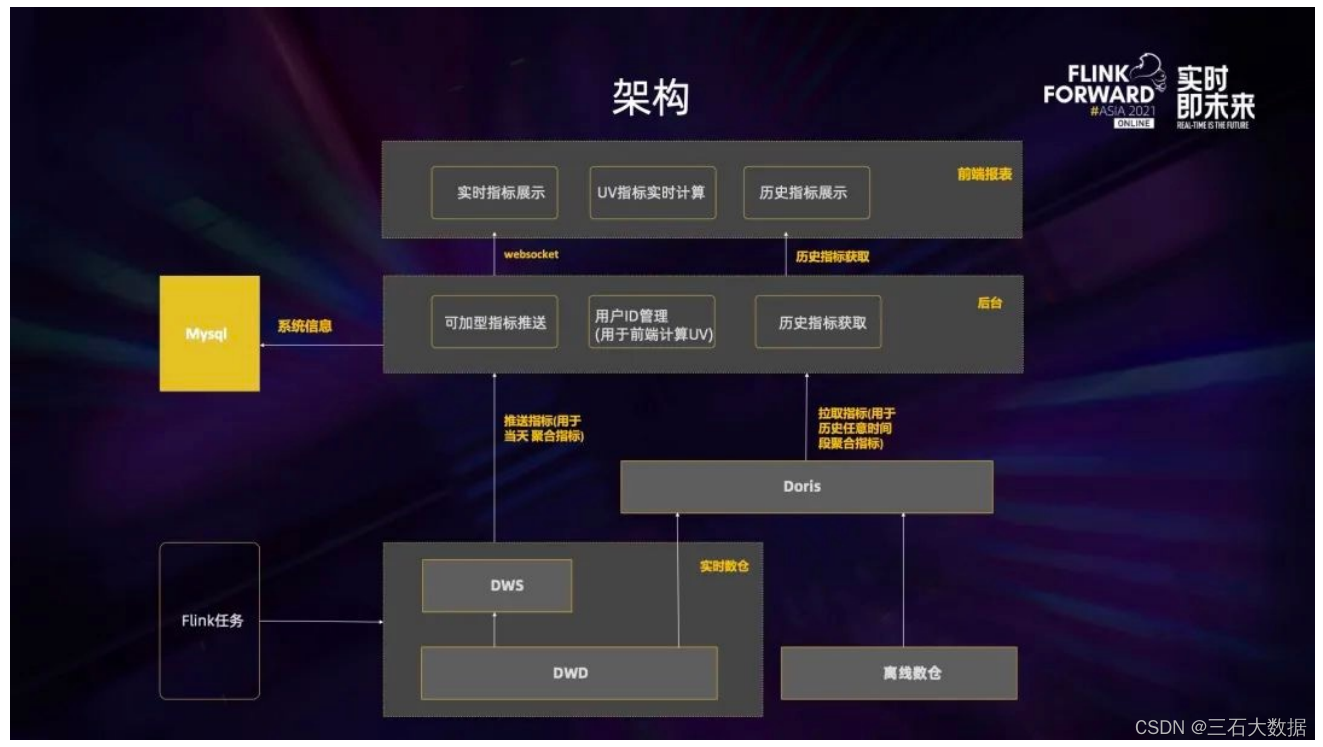
上图是实时看板业务的架构图,主要分为三层。第一层是数据层即 Kafka 的实时数仓,通过 Flink 对这些数据进行处理后将它们实时地推到后台,后台再实时地把它们推到前端。后台与前端的交互是通过 web socket 来实现的,这样就可以做到所有的数据都是实时推送。
2.CDP
![[图片]](https://img-blog.csdnimg.cn/abbe9c064c57408988642c39242cbfb4.png)
CDP 是一个运营平台,负责偏后台的工作。蔚来汽车的 CDP 需要存储一些数据,比如属性的数据存在 ES 里、行为的明细数据包括统计数据存在 Doris 里、任务执行情况存在 TiDB。其中主要有两个实时场景的应用:第一个是属性需要实时更新,否则可能造成运营效果不佳;第二个是行为的聚合数据有时候也需要实时更新。
3.实时数仓
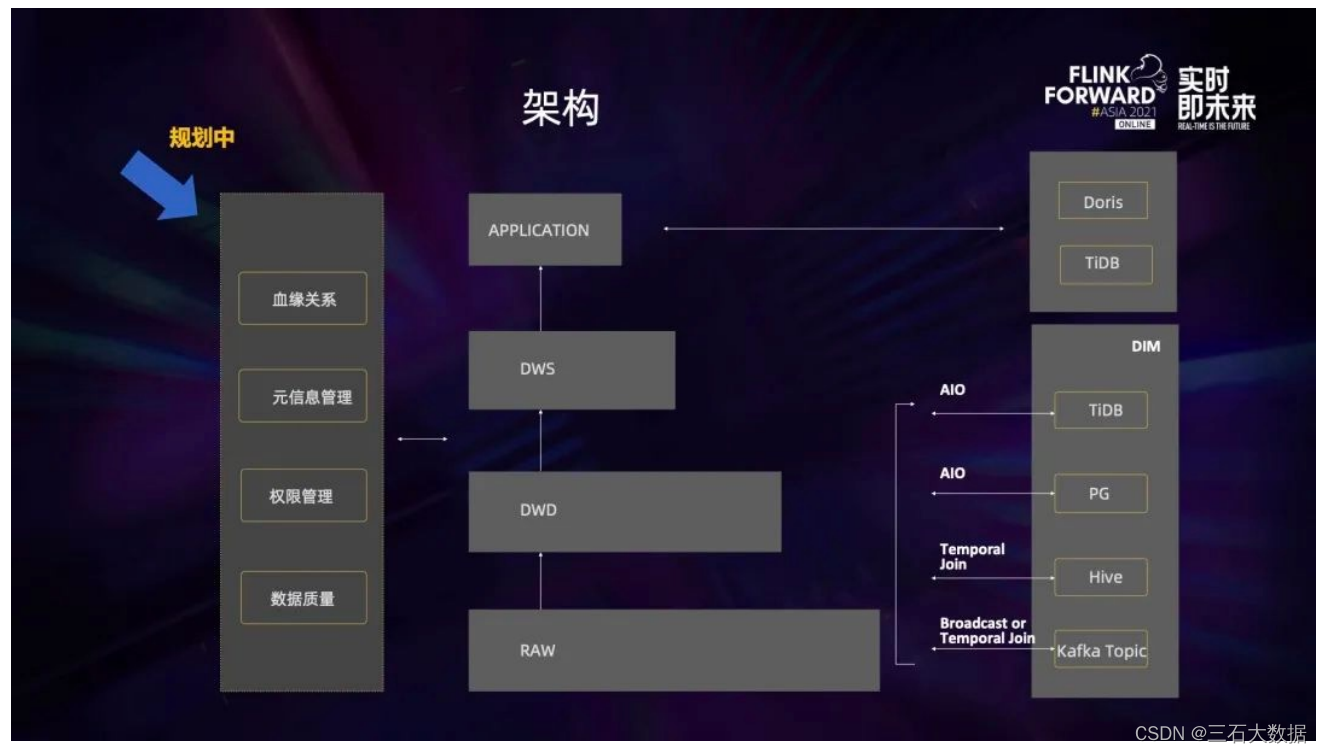
上图是蔚来汽车目前的实时数仓架构图。它整体上与离线数仓非常相似,也是有ODS层、DWD 层、DWS 层和Application 层。不同之处在于它有一个维度层 (DIM 层),里面有很多不同的存储介质,维度信息可以放在TiDB,并通过 AIO 的方式访问维度表;也可以放在 Hive,用 Temporal Join 的方式去进行关联;有一些数据是一直在变化的,或者需要做一些基于时间的关联,可以把数据放到 Kafka 里,然后用 Broadcast 或者Temporal Join 去进行关联。
未来规划
实时数据的场景越来越多,大家对实时数据的需求也越来越多,未来蔚来汽车会继续进行实时数据方面的探索。目前在流批一体的实时和离线存储统一上已经有了一些产出,后续也会在这方面投入更多精力,包括
Flink CDC 是否真的可以减少链路,提高响应效率等。
汽车之家
以下内容来自汽车之家Flink架构师的分享
用户背景
汽车之家成立于2005年,致力于为消费者提供一站式的看车、买车、用车服务,提供优质的汽车消费和汽车生活服务。助力中国汽车产业蓬勃发展。在历经媒体化、平台化、智能化的转型后,全方位服务C端消费者和B1端主机厂、B2端汽车生态各类参与方全面融入平安车生态战略,打造车辆交易的完整闭环。
平台现状
汽车之家实时计算平台的应用场景与其他公司很类似,涵盖了实时指标统计、监控预警、实时数据处理、实时用户行为、实时入湖、实时数据传输这几个方面:
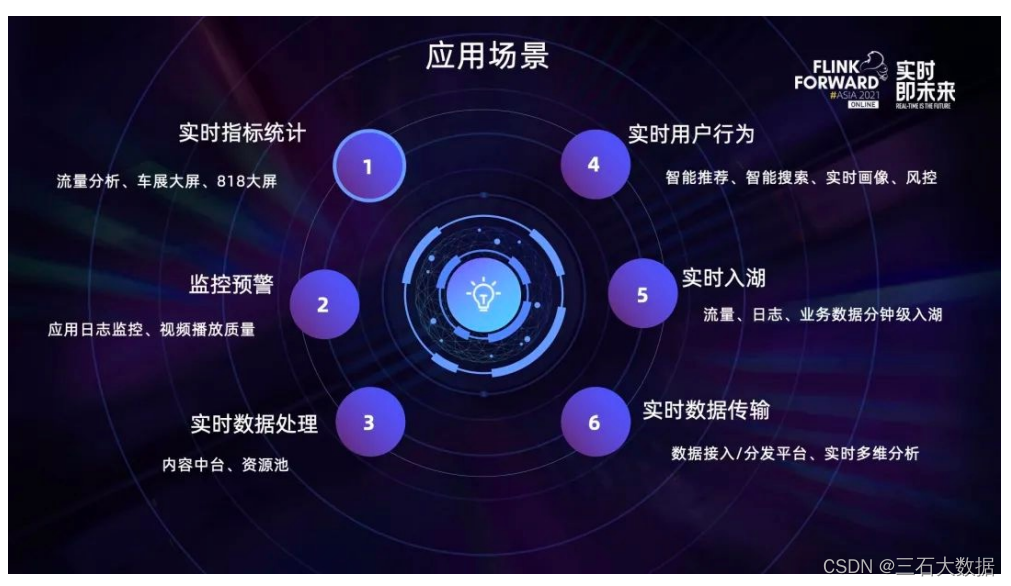
随着业务不断庞大,现有平台升级的需求不断扩大。

首先,由于实时计算离线的存储资源是混用的,离线 Hadoop 集群单独为实时计算拆出了一部分服务器并单 独部署了一套 Yarn 供实时计算使用,这部分服务器的磁盘用来支持离线数据的存储,CPU 内存主要用来支持运行 Flink 任务,所以 Flink 计算资源并没有独占服务器,汽车之家也没有对计算资源作严格的管控,所以导致有很多任务分配的资源是不合理的,通常是申请了过多的 CPU 资源但实际的利用率却比较低。随着公司容器化建设的逐步推进,离线和在线混部并错峰分配资源的方式成为可能,这也就意味着 Hadoop 集群的 CPU内存除了支持 Flink 实时计算,也可以支持在线业务的部署,从而使得对 Flink 计算资源管控的重要性及紧迫程度凸显出来。
其次,推动用户做资源的调优。这部分工作对用户来说存在一定难度。首先要理解 CPU 内存和并行度的调整对任务的影响就是有成本的,而且通常修改任务资源、重启任务就需要几分钟;此外用户还需要持续观察是否对业务产生了影响,比如出现延迟或内存溢出等。简单来说,用户的调优成本是比较高的。
接下来,现有的基于 Hive 的数仓架构需要升级。t+1 或 h+1 的时效性已经无法满足很多业务场景的需求。
最后,早期实时计算平台支持的生态不够完善。汽车之家的人工智能团队主要以 Python 语言为主,基于 SQL+UDF 的方式显然对他们不够友好。
平台建设
![[图片]](https://img-blog.csdnimg.cn/a0fdf6a9d3884b68b0dfdc8f3f7a9594.png)
1.预算资源管控和Flink自动伸缩容
为了提高资源利用率,汽车之家做的第一步就是启用预算的强控机制,与内部的资产云系统做对接并确定团队的可用预算,超出预算后任务将无法启动。同时对此定义了规范,用户需要先优化团队内的低利用率任务来释放预算,原则上资源利用率低的任务数应该控制在 10% 以内。如果无法优化,可以在资产云系统上发起团队间预算调拨的流程,也就是借资源;如果还是失败,则会由平台开白名单临时支持业务。

平台还上线了Flink任务健康评分机制,针对 CPU 使用率、内存使用率和空闲 slot 这几个核心规则来识别低利用率任务,同时会展示出低利用率的原因及解决方案。
![[图片]](https://img-blog.csdnimg.cn/3926a7fab7b54b8eabd0fd51b23ba357.png)
此外,汽车之家通过开发Flink作业自动伸缩容功能来降低用户的调优成本。用户可以指定自动伸缩容的触发时间,比如可以指定在夜里低峰时期执行,降低伸缩容对业务的影响,支持指定 CPU 并行度、内存维度伸缩容的策略,每次执行伸缩容都会通过钉钉和邮件通知任务负责人,并且会记录伸缩容的触发原因和伸缩容之后的最新资源配置。
![[图片]](https://img-blog.csdnimg.cn/a5dd1634ae064498a69a629851d81cf1.png)
总结起来,汽车之家通过引入强控流程来严控计算资源的用量,通过制定规范来提升用户主动优化资源的意
识,通过开发自动伸缩容功能降低用户的调优成本。最终达到的收益是在实时计算业务稳步增长的前提下全
年没有新增服务器。
2.建设湖仓一体

基于 Hive 的数据仓库主要存在以下几个痛点:
- 首先是时效性,目前基于 Hive 的数仓绝大部分是 t+1,数据产生后至少要一个小时才能在数仓中查询到。随着公司整体技术能力的提升,很多场景对数据的时效性要求越来越高,比如需要准实时的样本数据来支持模型训练,需要准实时的多维分析来帮助排查点击率下降的根因;
- 其次是Hive 2.0 无法支持 upsert 需求,业务库数据入仓只能 t+1 全量同步,数据修正成本很高,同时不支持 upsert 意味着存储层面无法实现批流一体;
- 最后Hive的Schema属于写入型,一旦数据写入之后 Schema 就难以变更。
经过一番选型,汽车之家决定选择基于 Iceberg 来构建湖仓一体架构,如下图所示:

最底层是基于 Hive Metastore 来统一 Hive 表和 Iceberg 表的元数据,基于 HDFS 来统一 Hive 表和Iceberg 表的存储,这也是湖仓一体的基础。往上一层是表格式,即 Iceberg 对自身的定位:介于存储引擎和计算引擎之间的开放的表格式。再往上是计算引擎,目前 Flink 主要负责数据的实时入湖工作, Spark 和 Hive 作为主要的产品引擎。最上面是计算平台, Autostream 支持点击流和日志类的数据实时入湖,AutoDTS 支持关系型数据库中的数据实时入湖,离线平台与Iceberg 做了集成,支持像使用 Hive 表一样来使用 Iceberg,在提升数据时效性的同时,尽量避免增加额外的使用成本。
 通过Flink+Iceburg+Hive实现湖仓一体架构,流量、内容、线索主题的数据时效性得到了大幅提升,从之前的
通过Flink+Iceburg+Hive实现湖仓一体架构,流量、内容、线索主题的数据时效性得到了大幅提升,从之前的
天级/小时级提升到 10 分钟以内,数仓核心任务的 SLA 提前两个小时完成;同时特征工程得以提效,在不改
变原先架构的情况下,模型训练的实效性从天级/小时级提升到 10 分钟级;从业务视角来看,大幅提升了数
据分析的效率体验和机器学习推荐的实效。
3.PyFlink实践
引入 PyFlink主要是想把 Flink 强大的实时计算能力输出给人工智能团队。人工智能团队由于技术本身的特点,

大部分开发人员都是基于 Python 语言开发,而 Python 本身的分布式和多线程支持比较弱,他们需要一个能快速上手又具备分布式计算能力的框架,来简化他们日常的程序开发和维护。通过集成 PyFlink 汽车之家实现了对 Python 生态的基础支持,解决了 Python 用户难以开发实时任务的痛点。同时也可以方便地将之前部署的单机程序迁移到实时计算平台上,享受 Flink 强大的分布式计算能力。
未来规划

- 未来,汽车之家会持续优化计算资源,让计算资源的利用更加合理化,进一步降低成本。一方面充分利用自动伸缩容的功能,扩展伸缩容策略,实现实时离线计算资源的混部,利用实时离线错峰计算的优势进一步降低实时计算的服务器成本。同时团队也会尝试优化 Yarn 的细粒度资源调度,比如分配给 jobmanager 和taskmanager 少于一核的资源,做更精细化的优化。
- 在流批一体方面,汽车之家准备利用 Flink 的批处理能力小范围做批处理的应用和 web 场景的试水。同时在数据湖架构的基础上,继续探索存储层面批流一体的可能性。最近汽车之家也在关注 FLIP-188 提案,它提出了一个全新的思路,将流表和批处理表进行一定程度的统一,可以实现一次 insert 就把数据同时写入到Logstore 和 Filestore 中,让下游可以实时消费 Logstore 的数据做实时 Pipeline,也可以使用 Filestore 的批式数据做 ad_hoc 查询。后续团队希望也能做类似的尝试。
相关文章:
Flink在汽车行业的应用【面试加分系列】
很多同学问我为什么要发这些大数据前沿汇报? 一方面是自己学习完后觉得非常好,然后总结发出来方便大家阅读;另外一方面,看这些汇报对你的面试帮助会很大,特别是面试前可以看看即将面试公司在大数据前沿的发展动向&…...
智慧工地源码:助力数字建造、智慧建造、安全建造、绿色建造
智慧工地围绕建设过程管理,建设项目与智能生产、科学管理建设项目信息生态系统集成在一起,该数据在虚拟现实环境中,将物联网收集的工程信息用于数据挖掘和分析,提供过程趋势预测和专家计划,实现工程建设的智能化管理&a…...

Spring Boot(二)
1、运行维护 1.1、打包程序 SpringBoot程序是基于Maven创建的,在Maven中提供有打包的指令,叫做package。本操作可以在Idea环境下执行。 mvn package 打包后会产生一个与工程名类似的jar文件,其名称是由模块名版本号.jar组成的。 1.2、程序…...
上海亚商投顾:沪指缩量调整跌 高位强势股继续退潮
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 三大指数11月10日弱势震荡,上证50盘中跌超1%,以保险为首的权重板块走势较弱。 高位强…...

药理学试卷
1【单选题】关于尼可刹米,错误的是 C A、直接兴奋延脑呼吸中枢 B、刺激颈动脉体化学感受器 C、作用时间较长 D、过量可致惊厥 2【单选题】属于第三代头孢菌素的药物是 C A、头孢克洛 B、头孢噻吩 C、头孢曲松 D、头孢匹罗 3【单选题】不属于β受体阻断药禁…...

SpringBoot3-快速入门
1.前置知识 Java17Spring、SpringMVC、MyBatisMaven、IDEA\ 2. 环境要求 环境&工具 版本(or later) SpringBoot 3.0.5 IDEA 2021.2.1 Java 17 Maven 3.5 Tomcat 10.0 Servlet 5.0 GraalVM Community 22.3 Native Build Tools 0.9…...

具名挂载和匿名挂载
匿名卷挂载 : -v 的时候只指定容器内的路径 如下面这个:/etc/nginx 1.docker run -d -P --name nginx -v /etc/nginx nginx 2.查看所有卷 docker volume ls 这里发现,这就是匿名挂载,只指定容器内的路径,没有指定…...
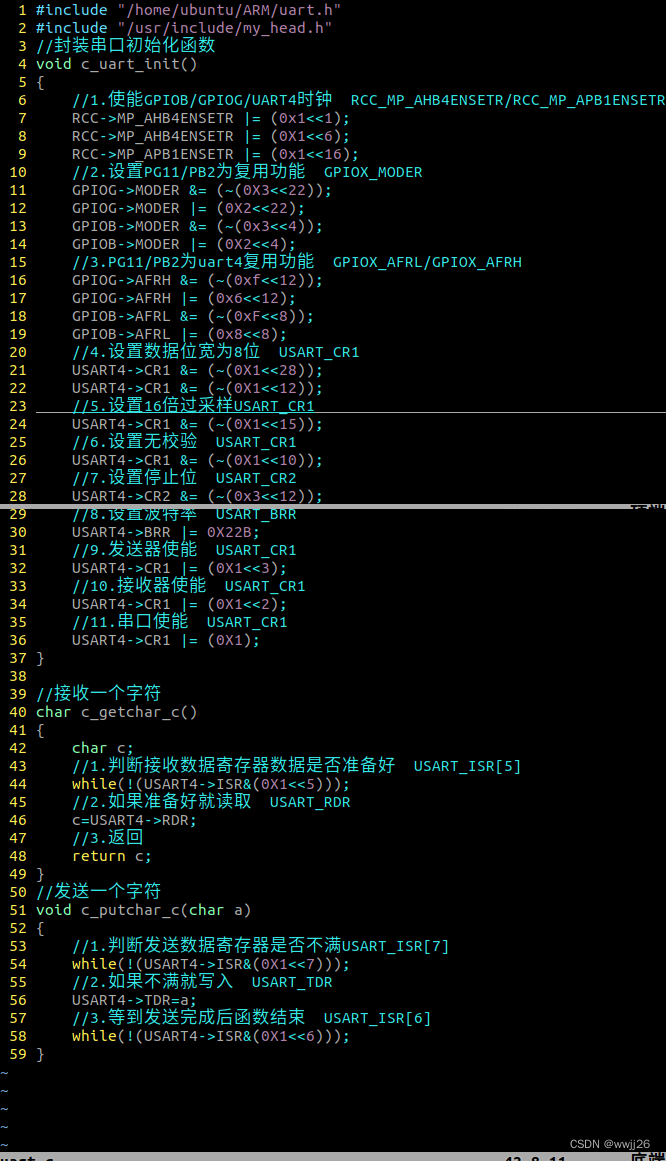
ARM串口
...
)
C++ Qt 学习(文章链接汇总)
C Qt 学习(一):Qt 入门 C Qt 学习(二):常用控件使用与界面布局 C Qt 学习(三):无边框窗口设计 C Qt 学习(四):自定义控件与 qss 应用 …...

2311d9月会议
DLF2023年9月月度会议摘要 Robert Robert,在DConf上做了一些初步的JSON5工作.他还更新了Bugzilla到GitHub的迁移脚本.他使用了"隐藏"API,现在脚本要快得多. 除此外,他在DScanner上做了一些小事,并等待JanJurzitza(Webfreak)合并它们.他指出,沃尔特曾要求他写一篇演…...
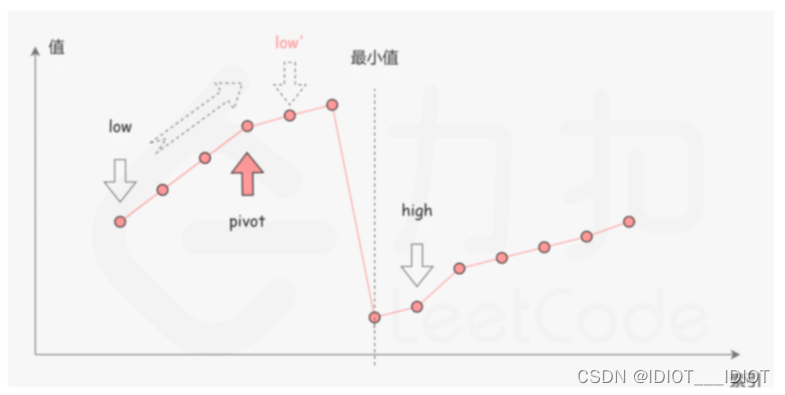
《算法通关村——二分查找在旋转数字中的应用》
《算法通关村——二分查找在旋转数字中的应用》 这里我们直接通过一个题目,来了解二分查找的应用。 153. 寻找旋转排序数组中的最小值 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如&a…...
)
C/S架构学习之基于TCP的本地通信(服务器)
基于TCP的本地通信(服务器):创建流程:一、创建字节流式套接字(socket函数): int sock_fd socket(AF_LOCAL,SOCK_STREAM,0);二、创建服务器和客户机的本地网络信息结构体并填充服务器本地网络信…...
乡镇村污水处理智慧水务智能监管平台,助力污水监管智慧化、高效化
一、背景与需求 随着城市化进程的加速,排放的污水量也日益增加,导致水污染严重。深入打好污染防治攻坚战的重要抓手,对于改善城镇人居环境,推进城市治理体系和治理能力现代化,加快生态文明建设,推动高质量…...

OSPF综合
实验拓扑 实验需求: 1 R4为ISP,其上只能配置IP地址; R4与其他所有直连设备间均使用公有IP 2 R3-R5/6/7为MGRE环境,R3为中心站点 ; 3 整个OSPF环境IP基于172.16.0.0/16划分; 4 所有设备均可访问R4的环回; 5 减少LSA的更新量,加快收…...

vue分片上传视频并转换为m3u8文件并播放
开发环境: 基于若依开源框架的前后端分离版本的实践,后端java的springboot,前端若依的vue2,做一个分片上传视频并分段播放的功能,因为是小项目,并没有专门准备文件服务器和CDN服务,后端也是套用…...

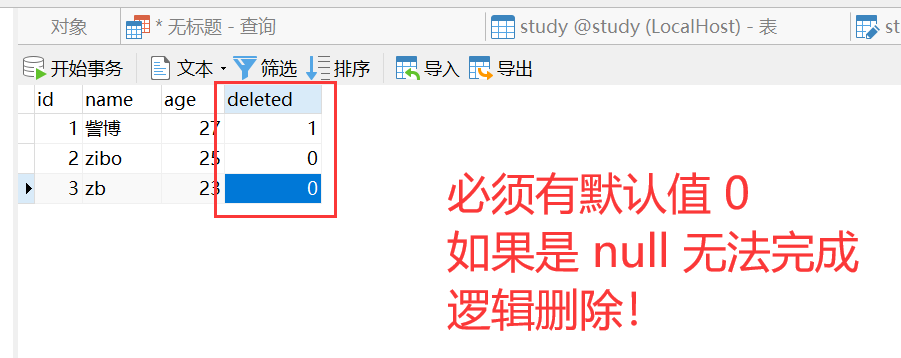
【MySQL】对表结构进行增删查改的操作
表的操作 前言正式开始建表查看表show tables;desc xxx;show create table xxx; 修改表修改表名 rename to对表结构进行修改新增一个列 add 对指定列的属性做修改 modify修改列名 change 删除某列 drop 删除表 drop 前言 前一篇讲了库相关的操作,如果你不太懂&…...
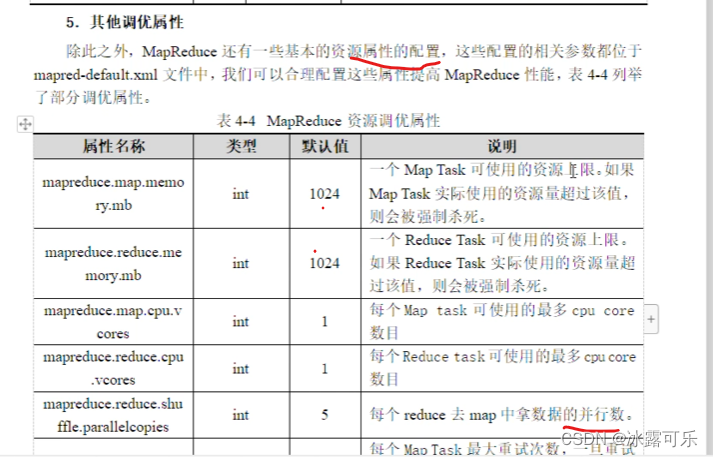
Hadoop原理,HDFS架构,MapReduce原理
Hadoop原理,HDFS架构,MapReduce原理 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,…...
【Spring Boot】035-Spring Boot 整合 MyBatis Plus
【Spring Boot】035-Spring Boot 整合 MyBatis Plus 【Spring Boot】010-Spring Boot整合Mybatis https://blog.csdn.net/qq_29689343/article/details/108621835 文章目录 【Spring Boot】035-Spring Boot 整合 MyBatis Plus一、MyBatis Plus 概述1、简介2、特性3、结构图4、相…...

Hafnium之强制性的接口
安全之安全(security)博客目录导读 目录 一、FFA_VERSION 二、FFA_FEATURES 三、FFA_RXTX_MAP/FFA_RXTX_UNMAP 四、FFA_PARTITION_INFO_GET 五、FFA_PARTITION_INFO_GET_REGS...
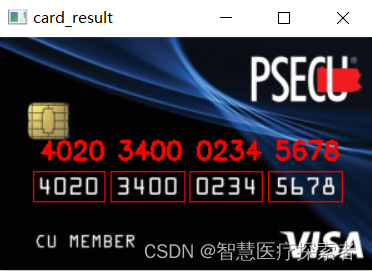
计算机视觉:使用opencv实现银行卡号识别
1 概述 1.1 opencv介绍 OpenCV是Open Source Computer Vision Library(开源计算机视觉库)的简称,由Intel公司在1999年提出建立,现在由Willow Garage提供运行支持,它是一个高度开源发行的计算机视觉库,可以…...

软件驱动与应用开发-RK3588实战
一、RK3588设备树关键配置 1.1 I2C与SPI引脚复用配置 dts // 文件: rk3588-smart-monitor.dts / {// I2C2: 使用GPIO4_B1/B2 (功能3)&i2c2 {status = "okay";clock-frequency = <400000>;pinctrl-0 = <&i2c2m0_xfer>;pinctrl-names = "d…...

PDF补丁丁深度解析:高效PDF文档处理与批量优化完整指南
PDF补丁丁深度解析:高效PDF文档处理与批量优化完整指南 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://g…...

Palworld存档工具终极指南:掌握游戏数据编辑的专业方法
Palworld存档工具终极指南:掌握游戏数据编辑的专业方法 【免费下载链接】palworld-save-tools Tools for converting Palworld .sav files to JSON and back 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-save-tools 你是否曾想过深入Palworld游戏…...

PoeCharm完全攻略:角色构建效率提升与优化指南——解决流放之路玩家的数值困境
PoeCharm完全攻略:角色构建效率提升与优化指南——解决流放之路玩家的数值困境 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 引言:流放之路玩家的三大核心痛点 流放之路作…...

StructBERT语义相似度工具快速体验:输入句子秒出结果
StructBERT语义相似度工具快速体验:输入句子秒出结果 1. 工具简介与核心价值 当你需要快速判断两段中文文字是否表达相同含义时,传统方法往往需要人工逐字比对或依赖复杂的算法配置。现在,基于StructBERT-Large模型的语义相似度工具让这个过…...
)
STM32CubeMX实战:如何用通用定时器精准实现微秒级延时(附DHT11读取示例)
STM32CubeMX实战:通用定时器实现微秒级延时的工程化解决方案 在嵌入式开发中,精确的时序控制往往是项目成功的关键。许多传感器如DHT11温湿度模块、超声波测距模块HC-SR04等,都需要微秒级精度的延时操作。然而,STM32CubeMX默认提…...

tts-vue本地语音合成解决方案:从技术原理到生产实践
tts-vue本地语音合成解决方案:从技术原理到生产实践 【免费下载链接】tts-vue 🎤 微软语音合成工具,使用 Electron Vue ElementPlus Vite 构建。 项目地址: https://gitcode.com/gh_mirrors/tt/tts-vue 一、破解本地化语音合成的技…...

ComfyUI-Impact-Pack终极指南:5大AI图像增强功能完全解析
ComfyUI-Impact-Pack终极指南:5大AI图像增强功能完全解析 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https…...

从FEE到FLS:深入Autosar存储栈底层,搞懂Flash模拟EEPROM的完整流程
从FEE到FLS:深入Autosar存储栈底层,搞懂Flash模拟EEPROM的完整流程 在汽车电子领域,非易失性存储管理一直是嵌入式系统设计的核心挑战之一。当工程师需要在片内Flash上实现类似EEPROM的细粒度数据更新功能时,Autosar存储协议栈提…...

StructBERT文本相似度-中文-通用模型效果展示:电商商品描述语义聚类案例
StructBERT文本相似度-中文-通用模型效果展示:电商商品描述语义聚类案例 1. 项目概述 StructBERT中文文本相似度模型是一个基于百度深度学习技术的高精度语义理解工具,专门用于计算中文句子之间的语义相似度。这个模型能够理解中文语言的深层语义&…...