Linux系统上搭建高可用Kafka集群(使用自带的zookeeper)
本次在CentOS7.6上搭建Kafka集群
Apache Kafka 是一个高吞吐量的分布式消息系统,被广泛应用于大规模数据处理和实时数据管道中。本文将介绍在CentOS操作系统上搭建Kafka集群的过程,以便于构建可靠的消息处理平台。
文件分享(KafkaUI、kafka3.3.2、jdk1.8)
链接:https://pan.baidu.com/s/1dn_mQKc1FnlQvuSgGjBc1w?pwd=t2v9 提取码:t2v9

也可以从官网自己下
Kafka官网
步骤概览
本次使用三台机器 hostname别名分别为res01(10.41.7.41)、res02(10.41.7.42)、res03(10.41.7.43)
在这个教程中,我们将覆盖以下主要步骤:
- 准备环境:安装和配置Java、Zookeeper和Kafka所需的依赖。
- 配置Zookeeper集群:确保Kafka有可靠的分布式协调服务。(本次使用Kafka自带的zookeeper)
- 配置Kafka集群:在每个节点上安装和配置Kafka,设置Kafka集群以实现高性能和高可用性。
步骤详解
步骤1:环境准备 (先对第一台服务器操作 其他的使用scp传输之后进行小修改就好)
安装Java
确保Java安装正确,并设置JAVA_HOME环境变量。
如果对于jdk安装有问题的可以看一下这篇Linux安装MySQL、JDK(含环境变量配置)、Tomcat

步骤2:安装Kafka
下载和解压Kafka
[root@res01 module]# clear
[root@res01 module]# ll
总用量 104124
drwxr-xr-x. 4 root root 40 11月 10 10:07 data
-rw-r--r--. 1 root root 106619987 11月 10 10:33 kafka_2.13-3.3.2.tgz
[root@res01 module]# tar -zxvf kafka_2.13-3.3.2.tgz
解压之后通过mv改名

步骤3:配置zookeeper
进入文件夹kafka3.3.2中找到config
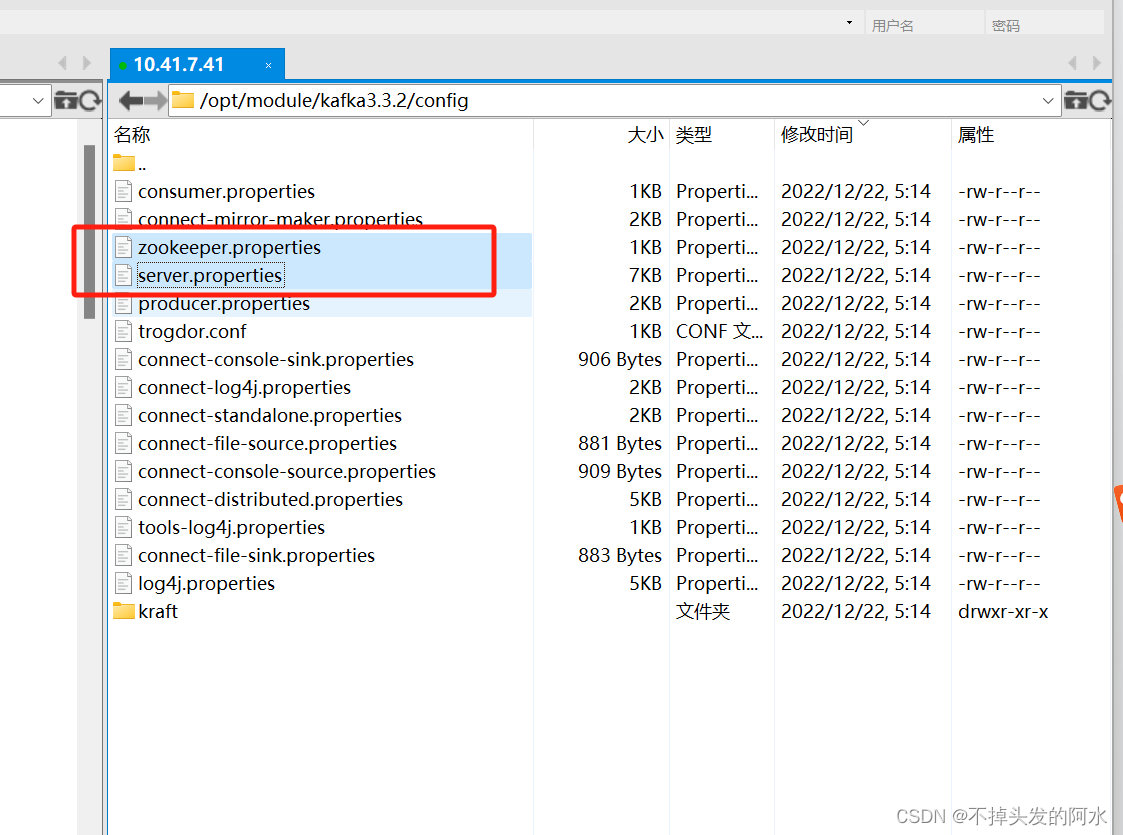
接下来主要修改zookeeper.properties和server.properties这两个文件
zookeeper.properties如下
# 需要去新建/opt/module/data/zookeeper下面这两个文件夹
dataDir=/opt/module/data/zookeeper/data
dataLogDir=/opt/module/data/zookeeper/logs
clientPort=12181
maxClientCnxns=0
admin.enableServer=false
tickTime=2000
initLimit=10
syncLimit=5
# server.X=hostname:peerPort:leaderPort
# peerPort 是服务器之间通信的端口。
# leaderPort 是用于选举 leader 的端口。
server.1=res01:12182:12183
server.2=res02:12182:12183
server.3=res03:12182:12183#res01、res02、res03是我本地设置过的主机名 如果没设置使用ip地址即可
在每个节点上zookeeper的配置文件中dataDir目录下创建一个名为myid的文件,并分别填入相应节点的ID号:1、2、3。

步骤4:配置Kafka
编辑Kafka配置文件config/server.properties,设置broker.id和zookeeper.connect:
# 设置 broker.id 这个是 Kafka 集群区分每个节点的唯一标志符。 对应那个myid即可
broker.id=1
# 将监听端口设置为19091
listeners=PLAINTEXT://res01:19091# 将广告给客户端的地址也设置为19091
advertised.listeners=PLAINTEXT://res01:19091num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## 设置 Kafka 的数据存储路径 这个目录下不能有其他非 Kafka 目录,不然会导致 Kafka 集群无法启动。
log.dirs=/opt/module/data/kafka-log
# 默认的 Partition 的个数。
num.partitions=3
# 设置默认的复制因子为3
default.replication.factor=3num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# Kafka 的数据保留的时间,默认是 7 天 168h。 这里使用24小时
log.retention.hours=24log.retention.check.interval.ms=300000
# Kafka 连接的 ZooKeeper 的地址和连接 Kafka 的超时时间。
zookeeper.connect=res01:12181,res02:12181,res03:12181
zookeeper.connection.timeout.ms=6000group.initial.rebalance.delay.ms=0
# 设置是否可以删除 Topic,默认 Kafka 的 Topic 是不允许删除的 这里打开了
delete.topic.enable=true# 这是用于启用或禁用日志清理的选项,默认值为 true,以确保 Kafka 持续进行日志清理。需要根据实际需求进行设置。
log.cleaner.enable=true
# 这个参数控制日志清理线程的数量。对于你的硬件配置,你可以考虑设置为 4 或 8 来充分利用服务器的性能。
log.cleaner.threads=4
# 这个参数用于控制日志清理线程的 IO 缓冲区大小。对于你的硬件配置,可以设置为 8192 或 16384。
log.cleaner.io.buffer.size=8192
# 这个参数是用来设置主题日志保留的最大字节数。对于控制磁盘空间的使用非常重要。例如,如果你希望限制每个主题的数据量不超过 100GB,可以设置为 107374182400
log.retention.bytes=107374182400
# 这个参数用于控制每个日志段文件的最大大小。对于你的硬件配置,你可以设置为 1073741824(即 1GB)。
log.segment.bytes=1073741824
# 这个参数用于设置 Zookeeper 会话的超时时间。对于较大的集群和连接较慢的网络,你可以考虑将其设置为 10000,即 10 秒。
zookeeper.session.timeout.ms=10000
重点是这个:
# 设置默认的复制因子为3
default.replication.factor=3
在Kafka集群的每个节点上,修改broker.id为对应的节点ID。
配置kafka环境变量
#java环境
export JAVA_HOME=/usr/local/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
#kafka环境
export KAFKA_HOME=/opt/module/kafka3.3.2
export PATH=$PATH:$KAFKA_HOME/bin步骤5:复制虚拟机
(已有其他服务器的直接连网线scp就好 环境变量 配置小改一下就好 还有hosts、ip等等别忘了配置,我这里直接复制虚拟机了 )
配置ip、hostname以及hosts后尝试ping

res02修改kafka的config文件即可(zookeeper配置文件都一样 用res01配置的就好)

res03的kafka配置文件同理

以及各台机器的myid(对应上brokerId即可)

步骤6:配置Kafka集群
确保防火墙或安全组允许Kafka端口通过,通常是9092端口。(我这是修改过的为19091,我直接关防火墙了 方便。)
systemctl stop firewalld.service
#关闭运行的防火墙
systemctl disable firewalld.service
#永久关闭防火墙本次使用的是绝对路径 各位可以到kafka目录下执行命令 去掉前面的绝对路径就好
zookeeper命令
在每个机器上,先启动zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-stop.sh
#停止命令
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh /opt/module/kafka3.3.2/config/zookeeper.properties
#启动命令
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh -daemon /opt/module/kafka3.3.2/config/zookeeper.properties
#后台启动命令 常用~统一启动后jps查看进程

Kafka命令
在每个Kafka节点上,启动Kafka服务器:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh /opt/module/kafka3.3.2/config/server.properties
#kafka启动命令
/opt/module/kafka3.3.2/bin/kafka-server-start.sh -daemon /opt/module/kafka3.3.2/config/server.properties
#kafka后台启动命令 常用~
/opt/module/kafka3.3.2/bin/kafka-server-stop.sh
#停止命令统一启动后jps查看进程
创建主题
使用kafka-topics.sh命令创建一个主题:这里设置的复制因子为3
bin/kafka-topics.sh --create --topic 你的topic--bootstrap-server res01:19091--replication-factor 3 --partitions 3验证Kafka集群
使用生产者和消费者验证Kafka集群的功能:
# 启动生产者
bin/kafka-console-producer.sh --topic myTopic --bootstrap-server res01:19091# 启动消费者
bin/kafka-console-consumer.sh --topic myTopic --bootstrap-server res01:19091--from-beginning停止 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-stop.sh
启动 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh /opt/module/kafka3.3.2/config/zookeeper.properties
后台启动 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh -daemon /opt/module/kafka3.3.2/config/zookeeper.properties
清空 Kafka 日志:
rm -rf //opt/module/data/kafka-logs/*
启动 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh /opt/module/kafka3.3.2/config/server.properties
后台启动 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh -daemon /opt/module/kafka3.3.2/config/server.properties
停止 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-stop.sh
创建 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --create --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT] --partitions [PARTITIONS_SIZE] --replication-factor [REPLICATION_FACTOR]
删除 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --delete --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT]
查看 Topic 信息:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --describe --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT]
列出所有的 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --list --bootstrap-server [SERVER_IP]:[PORT]
控制台生产消息:
/opt/module/kafka3.3.2/bin/kafka-console-producer.sh --bootstrap-server [SERVER_IP]:[PORT] --topic [TOPIC_NAME]
控制台消费信息:
/opt/module/kafka3.3.2/bin/kafka-console-consumer.sh --bootstrap-server [SERVER_IP]:[PORT] --topic [TOPIC_NAME] --from-beginning
查看副本:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --describe --bootstrap-server [SERVER_IP]:[PORT] | grep consumer_offsets
请记住替换 [TOPIC_NAME]、[SERVER_IP]:[PORT]、[PARTITIONS_SIZE]、[REPLICATION_FACTOR] 等位中的值为实际的值。自己的做的总结如上:

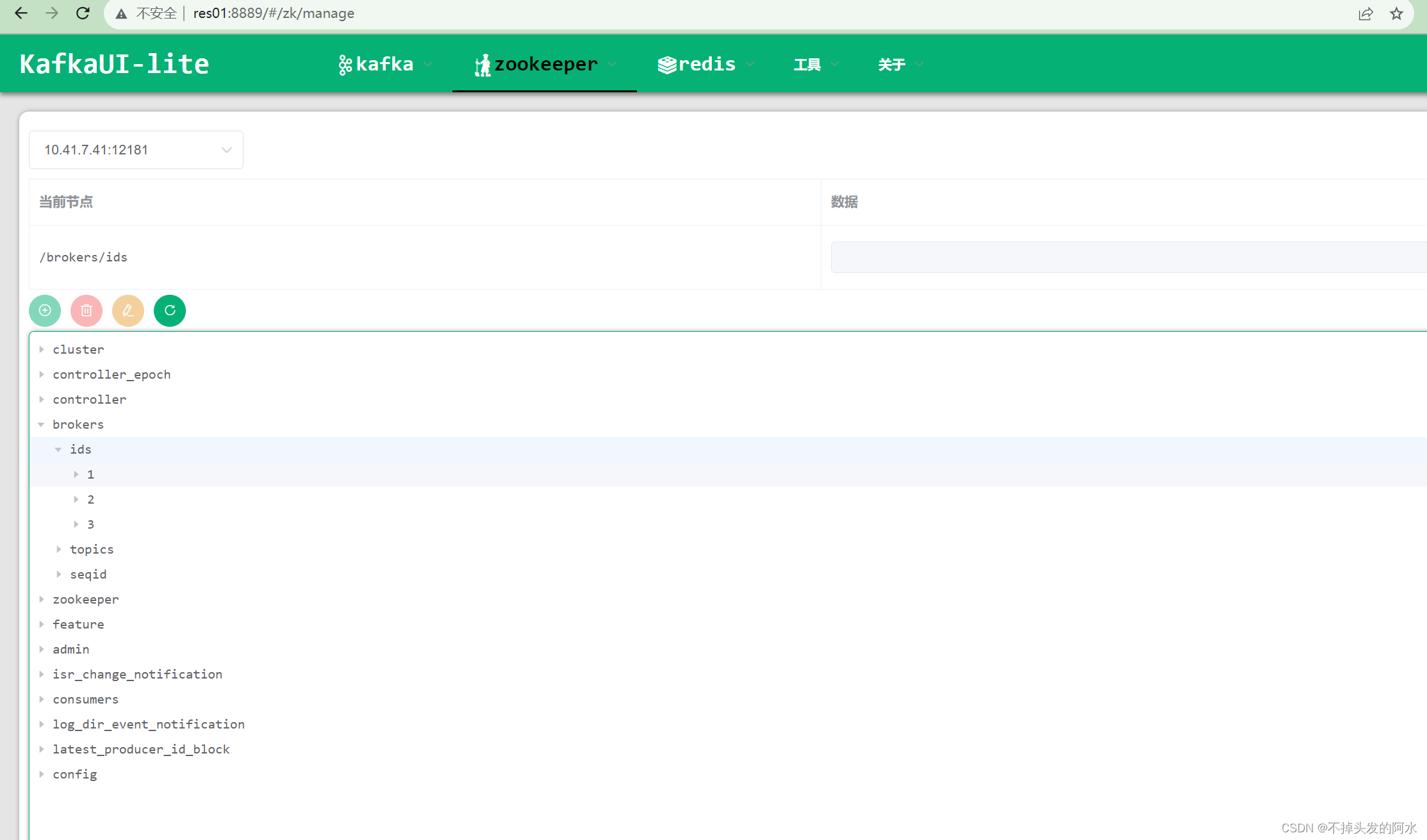
运行Java代码生成topic 可以看到分区都是3符合集群要求

运行kafkaui查看详细情况(百度网盘链接里有,自己输入命令太累了 直接用别人封装好现成的看就好~)
结论
通过这个步骤,我们成功地搭建了一个基本的Kafka集群。在实际生产环境中,您可能需要进一步调整和优化配置,以满足特定需求和性能要求。
希望这个教程可以帮助您成功搭建Kafka集群,为您的数据处理和消息传递架构提供强大的基础设施。
最后温馨提示:如果你远程服务器起了别名,而自己电脑的hosts别名对应其他的服务器 也会发生报错 记得别名对应好ip即可
相关文章:
Linux系统上搭建高可用Kafka集群(使用自带的zookeeper)
本次在CentOS7.6上搭建Kafka集群 Apache Kafka 是一个高吞吐量的分布式消息系统,被广泛应用于大规模数据处理和实时数据管道中。本文将介绍在CentOS操作系统上搭建Kafka集群的过程,以便于构建可靠的消息处理平台。 文件分享(KafkaUI、kafka…...
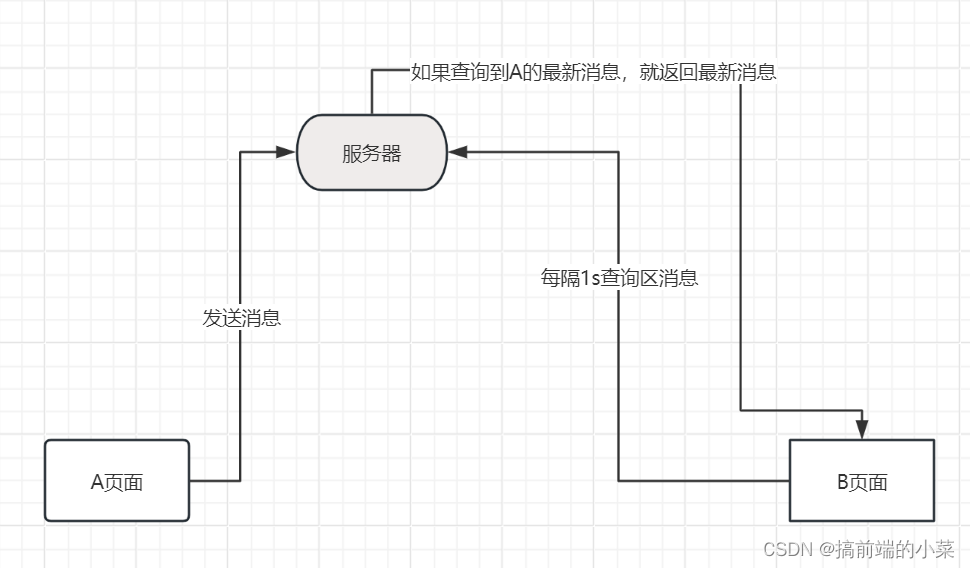
WebSocket在node端和客户端的使用
摘要 如果想要实现一个聊天的功能,就会想到使用WebSocket来搭建。那如果没有WebSocet的时候,我们会以什么样的思路来实现聊天功能呢? 假如有一个A页面 和 B页面进行通信,当A发送信息后,我们可以将信息存储在文件或者…...

ENVI IDL:如何将txt文本文件转化为GeoTIFF文件?
01 前言 此处的文本文件形式如下: 里面包含了众多点位信息(不是站点数据),我们需要依据上述点的经纬度信息放到对应位置的像素点位置,放置完后如下: 可以发现,还存在部分缺失值,我们…...

北邮22级信通院数电:Verilog-FPGA(9)第九周实验(2)实现下降沿触发的JK触发器(带异步复位和置位功能)
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 JK.v module JK (input clk,input J,input K,input…...

pyqt5UI同步加载
问题记录:pyqt5 怎样实现修改ui而不改变py代码,例如一个文件存入ui代码,另一个文件引入ui代码 起因:由于在写一个漏扫工具,由于ui的平频繁改动导致主体代码结构变动,所以先有没有方法能够不改变主题代码&am…...
)
CentOS 7 安装 Redis 5 (单机 6379)
CentOS 7 安装 Redis 5 (单机 6379) 自己准备好 Redis 5 的安装包并上传至 /opt/ 下的 redis 文件夹下: cd /opt mkdir redis cd redis准备好 Redis 所需的编译环境: yum -y install gcc yum -y install gcc-c解压上传的 Redis…...

sqlplus set参数大区
通过设置不同的SET参数,可以定制SQLPlus的行为和输出格式: SET 参数描述SET AUTOTRACE显示SQL语句的执行计划和统计信息,用于性能优化。SET FEEDBACK控制是否显示SQL语句执行的行数,可提高结果可读性。SET LINESIZE设置每行的最大…...

从0到0.01入门React | 006.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

GeoTools实战指南: 处理矢量文件中多多边形的MultiPolygon空洞问题
目录 GeoTools实战指南: 处理矢量文件中多多边形的MultiPolygon空洞问题背景思路分析代码实现引入依赖读取并遍历矢量文件处理并“缝合”一个多边形的内外环结果保存到新的矢量文件中完整代码效果展示仓库代码地址GeoTools实战指南: 处理矢量文件中多多边形的MultiPolygon空洞问…...
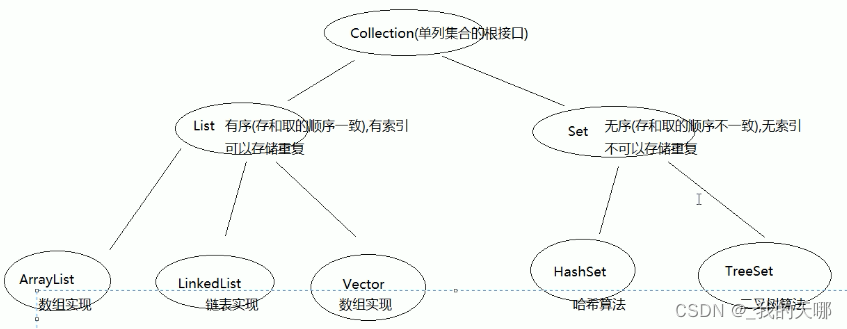
javaSE学习笔记(五)集合框架-Collection,List,Set,Map,HashMap,Hashtable,ConcurrentHashMap
目录 四、集合框架 1.集合概述 集合的作用 集合和数组的区别 集合继承体系 数组和链表 数组集合 链表集合 2.Collection 方法 集合遍历 并发修改异常 3.List List集合的特有功能(核心是索引) 集合遍历 并发修改异常产生解决方案ListItera…...
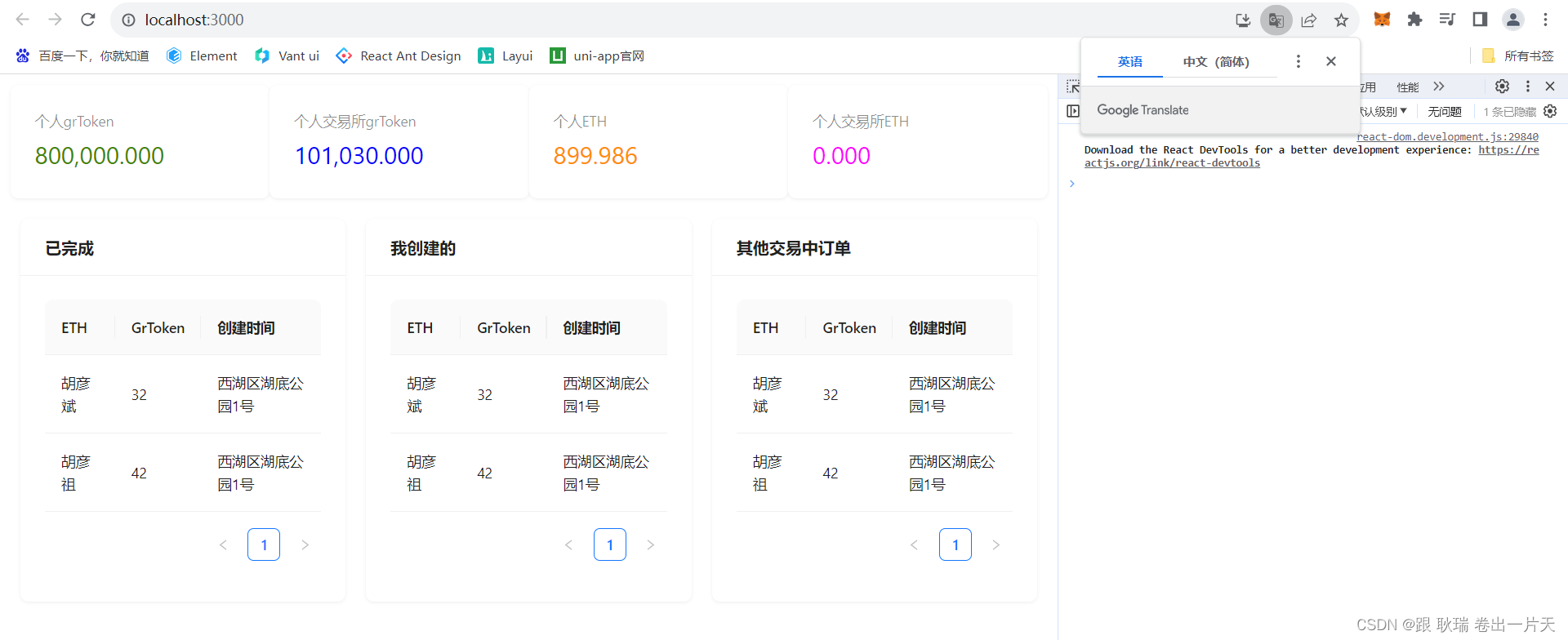
web3 React dapp项目通过事件从区块链中拿到 已取消 已完成 和所有的订单数据 并存入redux中
好 上文web3通过antd 在React dapp中构建订单组件基本结构我们算是把一个基本的订单组件展示做出来了 然后 我们继续 起一下环境先 ganache 终端运行 ganache -dMetaMask 登录一下 然后 打开项目 发布一下合约 truffle migrate --reset然后 运行一下 测试脚本 转入交易所 E…...
)
25、Flink 的table api与sql之函数(自定义函数示例)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

MybatisPlus —注解汇总
本文将介绍 MybatisPlus 注解包相关类详解(更多详细描述可点击查看源码注释) 注解类包源码:👉 mybatis-plus-annotation(opens new window) 一、#TableName(opens new window) 描述:表名注解,标识实体类对…...

flink对状态ttl进行单元测试
背景 在处理键值分区状态时,使用ttl设置过期时间是我们经常使用的,但是任何代码的修改都需要首先进行单元测试,本文就使用单元测试来验证一下状态ttl的设置是否正确 测试状态ttl超时的单元测试 首先看一下处理函数: // 处理函…...

Mac电脑安装打印机驱动
1.在打印机背面找到型号,当想要安装的驱动在官网找不到时可直接搜索该系列:比如MF系列 2.安装完成后需要添加打印机 当打印机和电脑在同一个WiFi下的时候查找打印机IP,输入IP后可以查到对应的打印机,添加后即可使用...
C语言 每日一题 牛客网 11.13 Day17
找零 Z国的货币系统包含面值1元、4元、16元、64元共计4种硬币,以及面值1024元的纸币。 现在小Y使用1024元的纸币购买了一件价值为N(0 < N≤1024)的商品,请问最少他会收到多少硬币? 思路 运用if语句进行判断分类 代码实现 int main() {…...

python读取npy和dat文件信息
前言 python读取.dat 和 .npy 数据 Code import numpy as np def read_dat():print("read data .dat \n")path "./c1_input.dat"data np.fromfile(path, np.float16).reshape(4,38,800)print(fdata :{data}, data shape:{data.shape}, data dtype:{d…...

【Git】第四篇:基本操作(理解工作区、暂存区、版本库)
Git 工作区、暂存区和版本库 工作区:就是我们创建的本地仓库所在的目录暂存区: stage或index,一般放在.git(可隐藏文件)目录下的index文件(.git/index)中,所以我们把暂存区有时候也叫做索引(in…...
Word转PDF简单示例,分别在windows和centos中完成转换
概述 本篇博客以简单的示例代码分别在Windows和Linux环境下完成Word转PDF的文档转换。 文章提供SpringBoot Vue3的示例代码。 文章为什么要分为Windows和Linux环境? 因为在如下提供的Windows后端示例代码中使用documents4j库做转换,此库需要调用命令行…...
)
推荐收藏!大模型算法工程师面试题来了(附答案)
自 ChatGPT 在去年 11 月底横空出世,大模型的风刮了整一年。 历经了百模大战、Llama 2 开源、GPTs 发布等一系列里程碑事件,将大模型技术推至无可争议的 C 位。基于大模型的研究与讨论,也让我们愈发接近这波技术浪潮的核心。 最近大模型相关…...
)
FPGA+CMV4000实战:从零搭建20fps成像系统的5个关键步骤(附避坑指南)
FPGACMV4000实战:从零搭建20fps成像系统的5个关键步骤(附避坑指南) 在嵌入式视觉开发领域,将高性能图像传感器与FPGA相结合构建定制化成像系统,正成为工业检测、科研仪器等专业场景的主流选择。CMV4000作为CMOSIS&…...

实测Qwen3-4B-Instruct-2507:轻量级模型如何搞定复杂问答?
实测Qwen3-4B-Instruct-2507:轻量级模型如何搞定复杂问答? 1. 模型能力实测:从简单到复杂的问答挑战 1.1 基础问答能力测试 我们首先测试模型在常见知识问答中的表现。输入一个简单问题: "中国的首都是哪里?&…...

Z-Image-Turbo_Sugar脸部Lora效果对比:Euler a vs DPM++ 2M SDE生成质量评测
Z-Image-Turbo_Sugar脸部Lora效果对比:Euler a vs DPM 2M SDE生成质量评测 1. 模型介绍与部署准备 Z-Image-Turbo_Sugar脸部Lora是一个专门针对甜美风格人像生成的AI模型,基于Z-Image-Turbo的Lora版本进行优化。这个模型特别擅长生成具有"纯欲甜妹…...

零代码自动化:Gemma-3-12b-it镜像+OpenClaw图形化配置指南
零代码自动化:Gemma-3-12b-it镜像OpenClaw图形化配置指南 1. 为什么选择图形化配置 当我第一次接触自动化工具时,面对密密麻麻的API文档和YAML配置文件,那种"从入门到放弃"的感觉至今记忆犹新。直到发现OpenClaw的图形化配置界面…...

OpenClaw技能开发入门:为Qwen3.5-9B定制图片分类插件
OpenClaw技能开发入门:为Qwen3.5-9B定制图片分类插件 1. 为什么需要开发图片分类技能 上周整理手机相册时,我对着3000多张杂乱无章的照片头疼不已——旅行风景、工作截图、宠物照片全都混在一起。手动分类不仅耗时费力,还经常因为主观判断不…...

嵌入式轻量级日志框架:零堆内存与编译期级别控制
1. Logger库深度解析:面向嵌入式系统的轻量级串口日志框架 1.1 设计定位与工程价值 Logger库虽以“Arduino library”为标签,但其本质是一个面向资源受限嵌入式平台的 轻量级串口日志框架 。在STM32、ESP32、nRF52等主流MCU平台上,日志输出…...

如何结合本地SEO优化来免费提高网站排名
如何结合本地SEO优化来免费提高网站排名 在当前数字化时代,网站排名的提升已经成为了企业和个人网站的重要目标之一。而对于本地企业来说,如何通过本地SEO优化来提高网站排名,是一个非常关键的问题。本文将详细探讨如何结合本地SEO优化来免费…...

OpenClaw跨平台控制:Qwen3-32B同步操作多台设备的配置方法
OpenClaw跨平台控制:Qwen3-32B同步操作多台设备的配置方法 1. 为什么需要分布式OpenClaw控制? 去年冬天,当我需要在三台不同操作系统的设备上同步执行数据清洗任务时,第一次意识到单机OpenClaw的局限性。每台设备需要单独登录、…...

QEi编码器接口原理与工业级抗干扰实战指南
1. 编码器(Encoder)QEi模块技术深度解析1.1 概述:为何QEi是嵌入式运动控制的底层基石在电机驱动、机器人关节反馈、精密定位平台等实时运动控制系统中,正交编码器(Quadrature Encoder)是最核心的位置与速度…...

Thrust安全最佳实践:保护你的桌面应用免受安全威胁
Thrust安全最佳实践:保护你的桌面应用免受安全威胁 【免费下载链接】thrust Chromium-based cross-platform / cross-language application framework 项目地址: https://gitcode.com/gh_mirrors/thru/thrust Thrust作为基于Chromium的跨平台应用框架&#x…...