25、Flink 的table api与sql之函数(自定义函数示例)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、自定义函数
- 1、概述
- 2、标量函数-自定义函数说明及示例
- 3、表值函数-自定义函数说明及示例
- 4、聚合函数
- 5、表值聚合函数
- 1)、示例1- 计算topN
- 2)、示例2 - emitUpdateWithRetract 方法使用(老版本Planner可用)
本文介绍了自定义函数的分类以及四种自定义函数实现的例子。
本文依赖flink、kafka集群能正常使用。
本文分为5个部分,即自定义函数介绍、标量自定义函数、表值自定义函数、标量聚合函数和表值聚合函数的实现示例。
本文的示例如无特殊说明则是在Flink 1.17版本中运行。
一、自定义函数
自定义函数(UDF)是一种扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑。
自定义函数可以用 JVM 语言(例如 Java 或 Scala)或 Python 实现,实现者可以在 UDF 中使用任意第三方库,本文聚焦于使用 JVM 语言开发自定义函数。
1、概述
当前 Flink 有如下几种函数:
- 标量函数,将标量值转换成一个新标量值;
- 表值函数,将标量值转换成新的行数据;
- 聚合函数,将多行数据里的标量值转换成一个新标量值;
- 表值聚合函数,将多行数据里的标量值转换成新的行数据;
- 异步表值函数,是异步查询外部数据系统的特殊函数。
标量和表值函数已经使用了新的基于数据类型的类型系统,聚合函数仍然使用基于 TypeInformation 的旧类型系统。
2、标量函数-自定义函数说明及示例
自定义标量函数可以把 0 到多个标量值映射成 1 个标量值,数据类型里列出的任何数据类型都可作为求值方法的参数和返回值类型。
想要实现自定义标量函数,你需要扩展 org.apache.flink.table.functions 里面的 ScalarFunction 并且实现一个或者多个求值方法。标量函数的行为取决于你写的求值方法。
求值方法必须是 public 的,而且名字必须是 eval。
下面自定义函数是将balance加上(万元)以及求balance/age,仅仅示例如何使用,其运行结果在每次输出的代码后面注释的行。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;import java.util.Arrays;
import java.util.List;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestUDScalarFunctionDemo {@Data@NoArgsConstructor@AllArgsConstructorpublic static class User {private long id;private String name;private int age;private int balance;private Long rowtime;}final static List<User> userList = Arrays.asList(new User(1L, "alan", 18, 20,1698742358391L), new User(2L, "alan", 19, 25,1698742359396L), new User(3L, "alan", 25, 30,1698742360407L),new User(4L, "alanchan", 28,35, 1698742361409L), new User(5L, "alanchan", 29, 35,1698742362424L));public static class TestScalarFunction extends ScalarFunction {// 接受任意类型输入,返回 String 型输出public String eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {return o.toString() + " (万元)";}public double eval(Integer age, Integer balance) {return balance / age *1.0;}}/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);DataStream<User> users = env.fromCollection(userList);Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"),$("balance"), $("rowtime"));//1、 在 Table API 里不经注册直接“内联”调用函数Table result = usersTable.select($("id"), $("name"), call(TestScalarFunction.class, $("balance")));DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
// resultDS.print();
// 11> (true,+I[2, alan, 25 (万元)])
// 12> (true,+I[3, alan, 30 (万元)])
// 13> (true,+I[4, alanchan, 35 (万元)])
// 10> (true,+I[1, alan, 20 (万元)])
// 14> (true,+I[5, alanchan, 35 (万元)])Table result2 = usersTable.select($("id"), $("name"), $("age"), call(TestScalarFunction.class, $("balance")), call(TestScalarFunction.class, $("age"), $("balance")));DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
// result2DS.print();
// 9> (true,+I[2, alan, 19, 25 (万元), 1.0])
// 10> (true,+I[3, alan, 25, 30 (万元), 1.0])
// 12> (true,+I[5, alanchan, 29, 35 (万元), 1.0])
// 11> (true,+I[4, alanchan, 28, 35 (万元), 1.0])
// 8> (true,+I[1, alan, 18, 20 (万元), 1.0])//2、 注册函数tenv.createTemporarySystemFunction("TestScalarFunction", TestScalarFunction.class);// 在 Table API 里调用注册好的函数Table result3 = usersTable.select($("id"), $("name"),call("TestScalarFunction", $("balance")));DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result3, Row.class);
// result3DS.print();
// 2> (true,+I[4, alanchan, 35 (万元)])
// 3> (true,+I[5, alanchan, 35 (万元)])
// 15> (true,+I[1, alan, 20 (万元)])
// 16> (true,+I[2, alan, 25 (万元)])
// 1> (true,+I[3, alan, 30 (万元)])// 在 SQL 里调用注册好的函数tenv.createTemporaryView("user_view", users);Table result4 = tenv.sqlQuery("SELECT id,name,TestScalarFunction(balance) ,TestScalarFunction(age,balance) FROM user_view");DataStream<Tuple2<Boolean, Row>> result4DS = tenv.toRetractStream(result4, Row.class);result4DS.print();
// 14> (true,+I[1, alan, 20 (万元), 1.0])
// 1> (true,+I[4, alanchan, 35 (万元), 1.0])
// 2> (true,+I[5, alanchan, 35 (万元), 1.0])
// 15> (true,+I[2, alan, 25 (万元), 1.0])
// 16> (true,+I[3, alan, 30 (万元), 1.0])env.execute();}}
3、表值函数-自定义函数说明及示例
跟自定义标量函数一样,自定义表值函数的输入参数也可以是 0 到多个标量。但是跟标量函数只能返回一个值不同的是,它可以返回任意多行。返回的每一行可以包含 1 到多列,如果输出行只包含 1 列,会省略结构化信息并生成标量值,这个标量值在运行阶段会隐式地包装进行里。
要定义一个表值函数,你需要扩展 org.apache.flink.table.functions 下的 TableFunction,可以通过实现多个名为 eval 的方法对求值方法进行重载。像其他函数一样,输入和输出类型也可以通过反射自动提取出来。表值函数返回的表的类型取决于 TableFunction 类的泛型参数 T,不同于标量函数,表值函数的求值方法本身不包含返回类型,而是通过 collect(T) 方法来发送要输出的行。
在 Table API 中,表值函数是通过 .joinLateral(…) 或者 .leftOuterJoinLateral(…) 来使用的。joinLateral 算子会把外表(算子左侧的表)的每一行跟跟表值函数返回的所有行(位于算子右侧)进行 (cross)join。leftOuterJoinLateral 算子也是把外表(算子左侧的表)的每一行跟表值函数返回的所有行(位于算子右侧)进行(cross)join,并且如果表值函数返回 0 行也会保留外表的这一行。
在 SQL 里面用 JOIN 或者 以 ON TRUE 为条件的 LEFT JOIN 来配合 LATERAL TABLE() 的使用。
下面示例中包含表值函数的四种应用方式。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;import java.util.Arrays;
import java.util.List;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestUDTableFunctionDemo {@Data@NoArgsConstructor@AllArgsConstructorpublic static class User {private long id;private String name;private int age;private int balance;private Long rowtime;}final static List<User> userList = Arrays.asList(new User(1L, "alan,chen", 18, 20,1698742358391L), new User(2L, "alan,chen", 19, 25,1698742359396L), new User(3L, "alan,chen", 25, 30,1698742360407L),new User(4L, "alan,chan", 28,35, 1698742361409L), new User(5L, "alan,chan", 29, 35,1698742362424L));@FunctionHint(output = @DataTypeHint("ROW<firstName STRING, lastName String>"))public static class SplitFunction extends TableFunction<Row> {public void eval(String str) {String[] names = str.split(",");collect(Row.of(names[0],names[1]));
// for (String s : str.split(", ")) {
// // use collect(...) to emit a row
// collect(Row.of(s, s.length()));
// }}}@FunctionHint(output = @DataTypeHint("ROW<id int, name String, age int, balance int, rowtime string>"))public static class OverloadedFunction extends TableFunction<Row> {public void eval(String str) {String[] user = str.split(",");collect(Row.of(Integer.valueOf(user[0]),user[1],Integer.valueOf(user[2]),Integer.valueOf(user[3]),user[4]));}}/*** @param args* @throws Exception */public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);DataStream<User> users = env.fromCollection(userList);Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"), $("balance"), $("rowtime"));// 1、 在 Table API 里不经注册直接“内联”调用函数Table result = usersTable.joinLateral(call(SplitFunction.class, $("name"))).select($("id"), $("name"),$("firstName"),$("lastName"));DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
// resultDS.print();
// 11> (true,+I[5, alan,chan, alan, chan])
// 7> (true,+I[1, alan,chen, alan, chen])
// 9> (true,+I[3, alan,chen, alan, chen])
// 10> (true,+I[4, alan,chan, alan, chan])
// 8> (true,+I[2, alan,chen, alan, chen])DataStream<String> row = env.fromCollection(//id name age balance rowtimeArrays.asList("11,alan,18,20,1699341167461","12,alan,19,25,1699341168464","13,alan,20,30,1699341169472","14,alanchan,18,22,1699341170479","15,alanchan,19,25,1699341171482"));Table usersTable2 = tenv.fromDataStream(row, $("userString"));Table result2 = usersTable2.joinLateral(call(OverloadedFunction.class, $("userString"))).select($("userString"),$("id"),$("name"),$("age"),$("balance"),$("rowtime")) ; DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
// result2DS.print();
// 15> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 13> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 14> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 11> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 12> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])Table result3 = usersTable2.leftOuterJoinLateral(call(OverloadedFunction.class, $("userString"))).select($("userString"),$("id"),$("name"),$("age"),$("balance"),$("rowtime")) ; DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result3, Row.class);
// result3DS.print();
// 5> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 6> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 3> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 4> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])
// 7> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])// 在 Table API 里重命名函数字段Table result4 = usersTable2.leftOuterJoinLateral(call(OverloadedFunction.class, $("userString")).as("t_id","t_name","t_age","t_balance","t_rowtime")).select($("userString"),$("t_id"),$("t_name"),$("t_age"),$("t_balance"),$("t_rowtime")) ; DataStream<Tuple2<Boolean, Row>> result4DS = tenv.toRetractStream(result4, Row.class);
// result4DS.print();
// 10> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 13> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 14> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 12> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 11> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])//2、 注册函数tenv.createTemporarySystemFunction("OverloadedFunction", OverloadedFunction.class);// 在 Table API 里调用注册好的函数Table result5 = usersTable2.leftOuterJoinLateral(call("OverloadedFunction", $("userString")).as("t_id","t_name","t_age","t_balance","t_rowtime")).select($("userString"),$("t_id"),$("t_name"),$("t_age"),$("t_balance"),$("t_rowtime")) ; DataStream<Tuple2<Boolean, Row>> result5DS = tenv.toRetractStream(result5, Row.class);
// result5DS.print();
// 11> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 14> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 15> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 13> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 12> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])Table result6 = usersTable2.joinLateral(call("OverloadedFunction", $("userString")).as("t_id","t_name","t_age","t_balance","t_rowtime")).select($("userString"),$("t_id"),$("t_name"),$("t_age"),$("t_balance"),$("t_rowtime")) ; DataStream<Tuple2<Boolean, Row>> result6DS = tenv.toRetractStream(result6, Row.class);
// result6DS.print();
// 8> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 9> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 5> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 7> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 6> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])//3、 在 SQL 里调用注册好的函数tenv.createTemporaryView("user_view", usersTable2);Table result7 = tenv.sqlQuery("SELECT userString, id,name,age,balance,rowtime " +"FROM user_view, LATERAL TABLE(OverloadedFunction(userString))");DataStream<Tuple2<Boolean, Row>> result7DS = tenv.toRetractStream(result7, Row.class);
// result7DS.print();
// 15> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 13> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 1> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 14> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])
// 16> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])Table result8 = tenv.sqlQuery("SELECT userString, id,name,age,balance,rowtime " +"FROM user_view "+" LEFT JOIN LATERAL TABLE( OverloadedFunction(userString)) ON TRUE " );DataStream<Tuple2<Boolean, Row>> result8DS = tenv.toRetractStream(result8, Row.class);
// result8DS.print();
// 13> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])
// 1> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 15> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 14> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])
// 16> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])//4、 在 SQL 里重命名函数字段Table result9 = tenv.sqlQuery("SELECT userString, t_id, t_name,t_age,t_balance,t_rowtime " +"FROM user_view "+"LEFT JOIN LATERAL TABLE(OverloadedFunction(userString)) AS T(t_id, t_name,t_age,t_balance,t_rowtime) ON TRUE");DataStream<Tuple2<Boolean, Row>> result9DS = tenv.toRetractStream(result9, Row.class);result9DS.print();
// 7> (true,+I[12,alan,19,25,1699341168464, 12, alan, 19, 25, 1699341168464])
// 10> (true,+I[15,alanchan,19,25,1699341171482, 15, alanchan, 19, 25, 1699341171482])
// 9> (true,+I[14,alanchan,18,22,1699341170479, 14, alanchan, 18, 22, 1699341170479])
// 8> (true,+I[13,alan,20,30,1699341169472, 13, alan, 20, 30, 1699341169472])
// 6> (true,+I[11,alan,18,20,1699341167461, 11, alan, 18, 20, 1699341167461])env.execute();}}
4、聚合函数
自定义聚合函数(UDAGG)是把一个表(一行或者多行,每行可以有一列或者多列)聚合成一个标量值。
该示例包含以下三个功能:
- 定义一个聚合函数来计算某一列的加权平均
- 在 TableEnvironment 中注册函数
- 在查询中使用函数
为了计算加权平均值,accumulator 需要存储加权总和以及数据的条数。
在例子里,定义了一个类 Aalan_WeightedAvgAccum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,在失败时进行恢复,以此来保证精确一次的语义。
例子的WeightedAvgAggregateFunction(自定义聚合函数)的 accumulate 方法有三个输入参数。
第一个是 Aalan_WeightedAvgAccum accumulator
另外两个是用户自定义的输入:输入的值 ivalue(balance) 和 输入的权重 iweight(age)。
尽管 retract()、merge()、resetAccumulator() 这几个方法在大多数聚合类型中都不是必须实现的,样例中提供了他们的实现。
在 Scala 样例中也是用的是 Java 的基础类型,并且定义了 getResultType() 和 getAccumulatorType(),因为 Flink 的类型推导对于 Scala 的类型推导做的不是很好。
import static org.apache.flink.table.api.Expressions.$;import java.util.Arrays;
import java.util.Iterator;
import java.util.List;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;
import org.apache.flink.types.Row;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestUDAGGDemo {// 加权平均累加器bean,加上名称,以示区别,避免混淆public static class Aalan_WeightedAvgAccum {public long sum = 0;public int count = 0;}// 聚合函数的自定义实现,计算加权平均public static class WeightedAvgAggregateFunction extends AggregateFunction<Long, Aalan_WeightedAvgAccum> {/*** 创建和初始化aggregate function 的Accumulator 方法*/@Overridepublic Aalan_WeightedAvgAccum createAccumulator() {return new Aalan_WeightedAvgAccum();}/*** 每次应该具体化(materialized)聚合结果时调用。 返回的值可能是早期且不完整的结果(随着数据的到达而定期发出),也可能是聚合的最终结果。*/@Overridepublic Long getValue(Aalan_WeightedAvgAccum acc) {if (acc.count == 0) {return null;} else {return acc.sum / acc.count;}}/*** 处理输入值并更新提供的累加器实例。方法accumulate 可以用不同的自定义类型和参数重载。聚合函数至少需要一个accumulate()方法。* * @param acc 累加器bean,包含当前汇总结果的累加器* @param iValue 输入的需要的累加值* @param iWeight 输入的需要累加的值的权重*/public void accumulate(Aalan_WeightedAvgAccum acc, long iValue, int iWeight) {acc.sum += iValue * iWeight;acc.count += iWeight;}/*** 收回累加器实例中的输入值。当前设计假设输入是先前累积的值。收回方法可以是重载了不同的自定义类型和参数。 此功能在datastream的有界流基于over* aggregate必须被实现。* * @param acc 累加器bean,包含当前汇总结果的累加器* @param iValue 输入的需要的累加值* @param iWeight 输入的需要累加的值的权重*/public void retract(Aalan_WeightedAvgAccum acc, long iValue, int iWeight) {acc.sum -= iValue * iWeight;acc.count -= iWeight;}/*** 将一组accumulator 实例合并为一个accumulator 实例。 该函数在datastream session window的分组聚合 和* 有界流的分组聚合必须实现。* * @param acc 累加器,用于保存合并后的聚合结果。 应该注意的是,累加器可以包含先前的聚合结果。 因此,用户不应在自定义合并方法中替换或清除此实例。* @param it 指向将被合并的一组累加器的Iterable。*/public void merge(Aalan_WeightedAvgAccum acc, Iterable<Aalan_WeightedAvgAccum> it) {Iterator<Aalan_WeightedAvgAccum> iter = it.iterator();while (iter.hasNext()) {Aalan_WeightedAvgAccum a = iter.next();acc.count += a.count;acc.sum += a.sum;}}/*** 重置此[[AggregateFunction]]的累加器。必须为有界分组聚合实现此函数。* * @param acc*/public void resetAccumulator(Aalan_WeightedAvgAccum acc) {acc.count = 0;acc.sum = 0L;}}@Data@NoArgsConstructor@AllArgsConstructorpublic static class User {private long id;private String name;private int age;private long balance;private Long rowtime;}final static List<User> userList = Arrays.asList(new User(1L, "alan", 18, 20, 1698742358391L), new User(2L, "alan", 19, 25, 1698742359396L),new User(3L, "alan", 25, 30, 1698742360407L), new User(4L, "alanchan", 28, 35, 1698742361409L), new User(5L, "alanchan", 29, 35, 1698742362424L));public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 将聚合函数注册为函数tenv.registerFunction("alan_weightavgAF", new WeightedAvgAggregateFunction());DataStream<User> users = env.fromCollection(userList);Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"), $("balance"), $("rowtime"));tenv.createTemporaryView("user_view", users);// 使用函数String sql = "SELECT name, alan_weightavgAF(balance, age) AS avgPoints FROM user_view GROUP BY name";Table result = tenv.sqlQuery(sql);DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);resultDS.print();
// 16> (true,+I[alanchan, 35])
// 2> (true,+I[alan, 20])
// 2> (false,-U[alan, 20])
// 2> (true,+U[alan, 22])
// 2> (false,-U[alan, 22])
// 2> (true,+U[alan, 25])env.execute();}}
5、表值聚合函数
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
1)、示例1- 计算topN
下面的例子展示了如何
- 定义一个 TableAggregateFunction 来计算给定列的最大的 3 个值
- 在 TableEnvironment 中注册函数
- 在 Table API 查询中使用函数(当前只在 Table API 中支持 TableAggregateFunction)
为了计算最大的 3 个值,accumulator 需要保存当前看到的最大的 3 个值。
在例子中,定义了类 TopAccum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,并且在失败时进行恢复,来保证精确一次的语义。
TopTableAggregateFunction 表值聚合函数(TableAggregateFunction)的 accumulate() 方法有两个输入,
第一个是 TopAccum accumulator,
另一个是用户定义的输入:输入的值 v。
尽管 merge() 方法在大多数聚合类型中不是必须的,也在样例中提供了它的实现。
在 Scala 样例中也使用的是 Java 的基础类型,并且定义了 getResultType() 和 getAccumulatorType() 方法,因为 Flink 的类型推导对于 Scala 的类型推导支持的不是很好。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;import java.util.Arrays;
import java.util.List;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestUDTAGGDemo {/*** Accumulator for Top3**/@Datapublic static class TopAccum {public Integer first;public Integer second;public Integer third;}public static class TopTableAggregateFunction extends TableAggregateFunction<Tuple2<Integer, Integer>, TopAccum> {@Overridepublic TopAccum createAccumulator() {TopAccum acc = new TopAccum();acc.first = Integer.MIN_VALUE;acc.second = Integer.MIN_VALUE;acc.third = Integer.MIN_VALUE;return acc;}public void accumulate(TopAccum acc, Integer v) {if (v > acc.first) {acc.third = acc.second;acc.second = acc.first;acc.first = v;} else if (v > acc.second) {acc.third = acc.second;acc.second = v;} else if (v > acc.third) {acc.third = v;}}public void merge(TopAccum acc, java.lang.Iterable<TopAccum> iterable) {for (TopAccum otherAcc : iterable) {accumulate(acc, otherAcc.first);accumulate(acc, otherAcc.second);accumulate(acc, otherAcc.third);}}public void emitValue(TopAccum acc, Collector<Tuple2<Integer, Integer>> out) {
// System.out.println("acc:"+acc);// emit the value and rankif (acc.first != Integer.MIN_VALUE) {out.collect(Tuple2.of(acc.first, 1));}if (acc.second != Integer.MIN_VALUE) {out.collect(Tuple2.of(acc.second, 2));}if (acc.third != Integer.MIN_VALUE) {out.collect(Tuple2.of(acc.third, 3));}}}@Data@NoArgsConstructor@AllArgsConstructorpublic static class User {private long id;private String name;private int age;private int balance;private Long rowtime;}final static List<User> userList = Arrays.asList(new User(1L, "alan", 18, 20, 1698742358391L), new User(2L, "alan", 19, 25, 1698742359396L),new User(3L, "alan", 25, 30, 1698742360407L), new User(4L, "alanchan", 28, 35, 1698742361409L), new User(5L, "alanchan", 29, 35, 1698742362424L));public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 将聚合函数注册为函数tenv.registerFunction("top", new TopTableAggregateFunction());DataStream<User> users = env.fromCollection(userList);Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"), $("balance"), $("rowtime"));// 使用函数Table result = usersTable.groupBy($("name")).flatAggregate(call("top", $("balance"))).select($("name"), $("f0").as("balance"), $("f1").as("rank"));DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);resultDS.print();
// 2> (true,+I[alan, 20, 1])
// 16> (true,+I[alanchan, 35, 1])
// 2> (false,-D[alan, 20, 1])
// 16> (false,-D[alanchan, 35, 1])
// 2> (true,+I[alan, 25, 1])
// 16> (true,+I[alanchan, 35, 1])
// 2> (true,+I[alan, 20, 2])
// 16> (true,+I[alanchan, 35, 2])
// 2> (false,-D[alan, 25, 1])
// 2> (false,-D[alan, 20, 2])
// 2> (true,+I[alan, 30, 1])
// 2> (true,+I[alan, 25, 2])
// 2> (true,+I[alan, 20, 3])env.execute();}}
2)、示例2 - emitUpdateWithRetract 方法使用(老版本Planner可用)
下面的例子展示了如何使用 emitUpdateWithRetract 方法来只发送更新的数据。
为了只发送更新的结果,accumulator 保存了上一次的最大的3个值,也保存了当前最大的3个值。
如果 TopN 中的 n 非常大,这种既保存上次的结果,也保存当前的结果的方式不太高效。
一种解决这种问题的方式是把输入数据直接存储到 accumulator 中,然后在调用 emitUpdateWithRetract 方法时再进行计算。
需要特别说明的是
下面的示例需要使用到useOldPlanner,对应的planner的maven依赖见下文
<!-- flink执行计划,这是1.9版本之前的--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.11</artifactId><version>1.13.6</version></dependency>
如果flink的版本比较高的话,下面的示例将不能运行,因为新版本的Builder没有useOldPlanner()方法了,已经移除。不能构造EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
//新版本该方法已经被移除@Deprecatedpublic Builder useOldPlanner() {this.plannerClass = OLD_PLANNER_FACTORY;this.executorClass = OLD_EXECUTOR_FACTORY;return this;}
如果使用OldPlanner的话,emitValue和emitUpdateWithRetract仅需定义一个就可以了,并且emitUpdateWithRetract的优先级大于emitValue。但是在Blink Planner里,只看有没有定义emitValue。
也即在Blink Planner中,只能使用emitValue,不能使用emitUpdateWithRetract。
否则会报如下异常
Exception in thread “main” org.apache.flink.table.api.ValidationException: Could not find an implementation method ‘emitValue’ in class ‘org.tablesql.udf.TestUDTAGGDemo2$TopNTableAggregateFunction’ for function ‘TopNTableAggregateFunction’ that matches the following signature:void emitValue(org.tablesql.udf.TestUDTAGGDemo2.TopNAccum, org.apache.flink.util.Collector)
具体示例如下
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;import java.util.Arrays;
import java.util.List;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.types.Row;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
public class TestUDTAGGDemo2 {@Datapublic static class TopNAccum {public Integer first;public Integer second;public Integer third;public Integer oldFirst;public Integer oldSecond;public Integer oldThird;}/*** 自定义聚合函数实现* * @author alanchan**/public static class TopNTableAggregateFunction extends TableAggregateFunction<Tuple2<Integer, Integer>, TopNAccum> {@Overridepublic TopNAccum createAccumulator() {TopNAccum topNAccum = new TopNAccum();topNAccum.first = Integer.MIN_VALUE;topNAccum.second = Integer.MIN_VALUE;topNAccum.third = Integer.MIN_VALUE;topNAccum.oldFirst = Integer.MIN_VALUE;topNAccum.oldSecond = Integer.MIN_VALUE;topNAccum.oldThird = Integer.MIN_VALUE;return topNAccum;}public void accumulate(TopNAccum acc, Integer v) {if (v > acc.first) {acc.third = acc.second;acc.second = acc.first;acc.first = v;} else if (v > acc.second) {acc.third = acc.second;acc.second = v;} else if (v > acc.third) {acc.third = v;}}public void emitUpdateWithRetract(TopNAccum acc, RetractableCollector<Tuple2<Integer, Integer>> out) {System.out.println("emitUpdateWithRetract----acc:" + acc);if (!acc.first.equals(acc.oldFirst)) {// if there is an update, retract old value then emit new value.if (acc.oldFirst != Integer.MIN_VALUE) {out.retract(Tuple2.of(acc.oldFirst, 1));}out.collect(Tuple2.of(acc.first, 1));acc.oldFirst = acc.first;}if (!acc.second.equals(acc.oldSecond)) {// if there is an update, retract old value then emit new value.if (acc.oldSecond != Integer.MIN_VALUE) {out.retract(Tuple2.of(acc.oldSecond, 2));}out.collect(Tuple2.of(acc.second, 2));acc.oldSecond = acc.second;}if (!acc.third.equals(acc.oldThird)) {// if there is an update, retract old value then emit new value.if (acc.oldThird != Integer.MIN_VALUE) {out.retract(Tuple2.of(acc.oldThird, 3));}out.collect(Tuple2.of(acc.third, 3));acc.oldThird = acc.third;}}}@Data@NoArgsConstructor@AllArgsConstructorpublic static class User {private long id;private String name;private int age;private int balance;private Long rowtime;}final static List<User> userList = Arrays.asList(new User(1L, "alan", 18, 20, 1698742358391L), new User(2L, "alan", 19, 25, 1698742359396L),new User(3L, "alan", 25, 30, 1698742360407L), new User(11L, "alan", 28, 31, 1698742358391L), new User(12L, "alan", 29, 32, 1698742359396L),new User(13L, "alan", 35, 35, 1698742360407L), new User(23L, "alan", 45, 36, 1698742360407L), new User(14L, "alanchan", 28, 15, 1698742361409L), new User(15L, "alanchan", 29, 16, 1698742362424L), new User(24L, "alanchan", 30, 20, 1698742361409L),new User(25L, "alanchan", 31, 22, 1698742362424L), new User(34L, "alanchan", 32, 24, 1698742361409L), new User(35L, "alanchan", 33, 26, 1698742362424L),new User(44L, "alanchan", 34, 28, 1698742361409L), new User(55L, "alanchan", 35, 35, 1698742362424L));public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);EnvironmentSettings settings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);// 将聚合函数注册为函数tenv.registerFunction("topN", new TopNTableAggregateFunction());DataStream<User> users = env.fromCollection(userList);Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"), $("balance"), $("rowtime"));// 使用函数Table result = usersTable.groupBy($("name")).flatAggregate(call("topN", $("balance"))).select($("name"), $("f0").as("balance"), $("f1").as("rank"));DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);resultDS.print();env.execute();}}运行结果如下:
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=20, second=-2147483648, third=-2147483648, oldFirst=-2147483648, oldSecond=-2147483648, oldThird=-2147483648)
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=15, second=-2147483648, third=-2147483648, oldFirst=-2147483648, oldSecond=-2147483648, oldThird=-2147483648)
14> (true,+I[alan, 20, 1])
9> (true,+I[alanchan, 15, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=25, second=20, third=-2147483648, oldFirst=20, oldSecond=-2147483648, oldThird=-2147483648)
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=16, second=15, third=-2147483648, oldFirst=15, oldSecond=-2147483648, oldThird=-2147483648)
14> (false,+I[alan, 20, 1])
14> (true,+I[alan, 25, 1])
14> (true,+I[alan, 20, 2])
9> (false,+I[alanchan, 15, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=30, second=25, third=20, oldFirst=25, oldSecond=20, oldThird=-2147483648)
14> (false,+I[alan, 25, 1])
9> (true,+I[alanchan, 16, 1])
14> (true,+I[alan, 30, 1])
14> (false,+I[alan, 20, 2])
9> (true,+I[alanchan, 15, 2])
14> (true,+I[alan, 25, 2])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=20, second=16, third=15, oldFirst=16, oldSecond=15, oldThird=-2147483648)
14> (true,+I[alan, 20, 3])
9> (false,+I[alanchan, 16, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=31, second=30, third=25, oldFirst=30, oldSecond=25, oldThird=20)
9> (true,+I[alanchan, 20, 1])
9> (false,+I[alanchan, 15, 2])
14> (false,+I[alan, 30, 1])
9> (true,+I[alanchan, 16, 2])
14> (true,+I[alan, 31, 1])
9> (true,+I[alanchan, 15, 3])
14> (false,+I[alan, 25, 2])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=22, second=20, third=16, oldFirst=20, oldSecond=16, oldThird=15)
14> (true,+I[alan, 30, 2])
9> (false,+I[alanchan, 20, 1])
14> (false,+I[alan, 20, 3])
9> (true,+I[alanchan, 22, 1])
14> (true,+I[alan, 25, 3])
9> (false,+I[alanchan, 16, 2])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=32, second=31, third=30, oldFirst=31, oldSecond=30, oldThird=25)
9> (true,+I[alanchan, 20, 2])
9> (false,+I[alanchan, 15, 3])
9> (true,+I[alanchan, 16, 3])
14> (false,+I[alan, 31, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=24, second=22, third=20, oldFirst=22, oldSecond=20, oldThird=16)
14> (true,+I[alan, 32, 1])
9> (false,+I[alanchan, 22, 1])
14> (false,+I[alan, 30, 2])
9> (true,+I[alanchan, 24, 1])
9> (false,+I[alanchan, 20, 2])
14> (true,+I[alan, 31, 2])
9> (true,+I[alanchan, 22, 2])
14> (false,+I[alan, 25, 3])
9> (false,+I[alanchan, 16, 3])
14> (true,+I[alan, 30, 3])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=35, second=32, third=31, oldFirst=32, oldSecond=31, oldThird=30)
9> (true,+I[alanchan, 20, 3])
14> (false,+I[alan, 32, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=26, second=24, third=22, oldFirst=24, oldSecond=22, oldThird=20)
14> (true,+I[alan, 35, 1])
9> (false,+I[alanchan, 24, 1])
14> (false,+I[alan, 31, 2])
9> (true,+I[alanchan, 26, 1])
14> (true,+I[alan, 32, 2])
9> (false,+I[alanchan, 22, 2])
14> (false,+I[alan, 30, 3])
9> (true,+I[alanchan, 24, 2])
14> (true,+I[alan, 31, 3])
9> (false,+I[alanchan, 20, 3])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=36, second=35, third=32, oldFirst=35, oldSecond=32, oldThird=31)
9> (true,+I[alanchan, 22, 3])
14> (false,+I[alan, 35, 1])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=28, second=26, third=24, oldFirst=26, oldSecond=24, oldThird=22)
14> (true,+I[alan, 36, 1])
9> (false,+I[alanchan, 26, 1])
14> (false,+I[alan, 32, 2])
9> (true,+I[alanchan, 28, 1])
14> (true,+I[alan, 35, 2])
9> (false,+I[alanchan, 24, 2])
9> (true,+I[alanchan, 26, 2])
14> (false,+I[alan, 31, 3])
9> (false,+I[alanchan, 22, 3])
14> (true,+I[alan, 32, 3])
9> (true,+I[alanchan, 24, 3])
emitUpdateWithRetract----acc:TestUDTAGGDemo2.TopNAccum(first=35, second=28, third=26, oldFirst=28, oldSecond=26, oldThird=24)
9> (false,+I[alanchan, 28, 1])
9> (true,+I[alanchan, 35, 1])
9> (false,+I[alanchan, 26, 2])
9> (true,+I[alanchan, 28, 2])
9> (false,+I[alanchan, 24, 3])
9> (true,+I[alanchan, 26, 3])以上,介绍了自定义函数的分类以及四种自定义函数实现的例子。
相关文章:
)
25、Flink 的table api与sql之函数(自定义函数示例)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

MybatisPlus —注解汇总
本文将介绍 MybatisPlus 注解包相关类详解(更多详细描述可点击查看源码注释) 注解类包源码:👉 mybatis-plus-annotation(opens new window) 一、#TableName(opens new window) 描述:表名注解,标识实体类对…...

flink对状态ttl进行单元测试
背景 在处理键值分区状态时,使用ttl设置过期时间是我们经常使用的,但是任何代码的修改都需要首先进行单元测试,本文就使用单元测试来验证一下状态ttl的设置是否正确 测试状态ttl超时的单元测试 首先看一下处理函数: // 处理函…...

Mac电脑安装打印机驱动
1.在打印机背面找到型号,当想要安装的驱动在官网找不到时可直接搜索该系列:比如MF系列 2.安装完成后需要添加打印机 当打印机和电脑在同一个WiFi下的时候查找打印机IP,输入IP后可以查到对应的打印机,添加后即可使用...
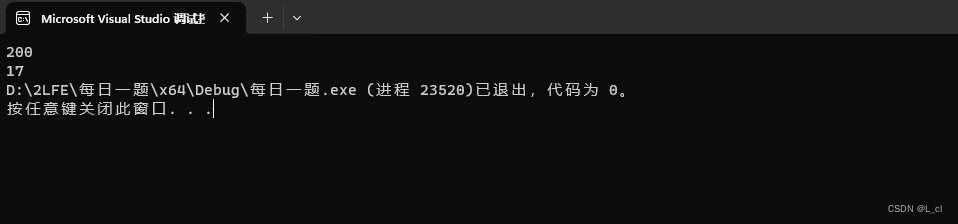
C语言 每日一题 牛客网 11.13 Day17
找零 Z国的货币系统包含面值1元、4元、16元、64元共计4种硬币,以及面值1024元的纸币。 现在小Y使用1024元的纸币购买了一件价值为N(0 < N≤1024)的商品,请问最少他会收到多少硬币? 思路 运用if语句进行判断分类 代码实现 int main() {…...

python读取npy和dat文件信息
前言 python读取.dat 和 .npy 数据 Code import numpy as np def read_dat():print("read data .dat \n")path "./c1_input.dat"data np.fromfile(path, np.float16).reshape(4,38,800)print(fdata :{data}, data shape:{data.shape}, data dtype:{d…...

【Git】第四篇:基本操作(理解工作区、暂存区、版本库)
Git 工作区、暂存区和版本库 工作区:就是我们创建的本地仓库所在的目录暂存区: stage或index,一般放在.git(可隐藏文件)目录下的index文件(.git/index)中,所以我们把暂存区有时候也叫做索引(in…...
Word转PDF简单示例,分别在windows和centos中完成转换
概述 本篇博客以简单的示例代码分别在Windows和Linux环境下完成Word转PDF的文档转换。 文章提供SpringBoot Vue3的示例代码。 文章为什么要分为Windows和Linux环境? 因为在如下提供的Windows后端示例代码中使用documents4j库做转换,此库需要调用命令行…...
)
推荐收藏!大模型算法工程师面试题来了(附答案)
自 ChatGPT 在去年 11 月底横空出世,大模型的风刮了整一年。 历经了百模大战、Llama 2 开源、GPTs 发布等一系列里程碑事件,将大模型技术推至无可争议的 C 位。基于大模型的研究与讨论,也让我们愈发接近这波技术浪潮的核心。 最近大模型相关…...

线程与进程
文章目录 什么是进程?什么是线程?线程、进程的区别多线程编程 什么是进程? 进程(Process)是计算机中的程序关于数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。简单来说,进程就…...
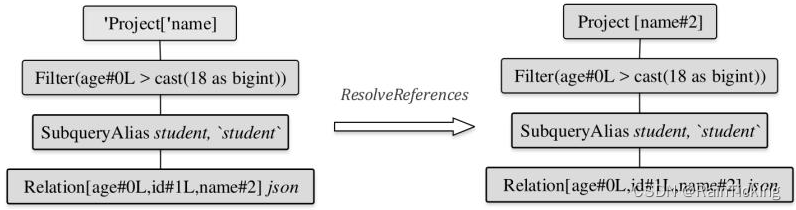
SparkSQL之Analyzed LogicalPlan生成过程
经过AstBuilder的处理,得到了Unresolved LogicalPlan。该逻辑算子树中未被解析的有UnresolvedRelation和UnresolvedAttribute两种对象。Analyzer所起到的主要作用就是将这两种节点或表达式解析成有类型的(Typed)对象。在此过程中,…...

Vue的状态管理有哪些?
在Vue中,有多种方式可以进行状态管理,以下是一些常见的Vue状态管理解决方案: 1:Vuex: Vuex是Vue官方提供的状态管理库,用于管理Vue应用程序中的状态。Vuex使用一个单一的全局状态树(state tre…...

1000道精心打磨的计算机考研题,408小伙伴不可错过
难度高! 知识点多! 复习时间短! 不要怕,计算机考研1000题来了! 不是数学考研1000题! 也不是政治考研1000题! 而是专属计算机考研小伙伴的超精选1000题! 计算机考研专业课需要大…...
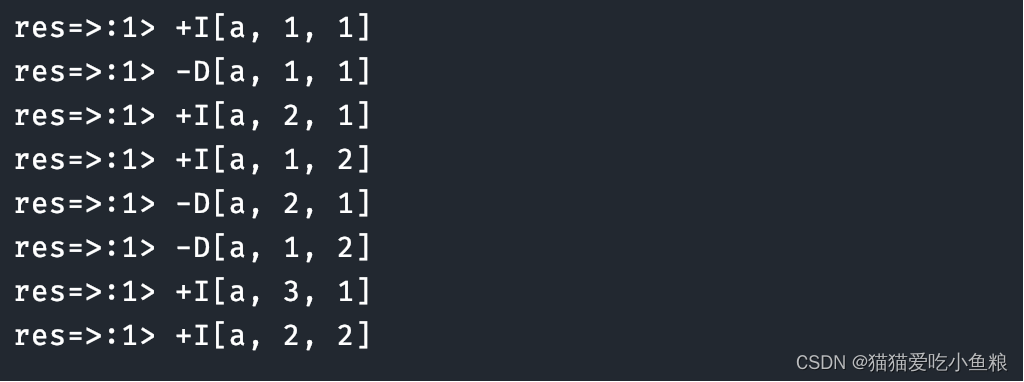
Flink SQL 表值聚合函数(Table Aggregate Function)详解
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。 函数功能: 在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值: select max(xxx) from source_table gr…...

pgsql_全文检索_使用空间换时间的方法支持中文搜索
pgsql_全文检索_使用空间换时间的方法支持中文搜索 一、环境 PostgreSQL 14.2, compiled by Visual C build 1914, 64-bit 二、引言 提到全文检索首先想到的就是ES(ElasticSearch)和Lucene,专业且强大。对于一些小众场景对于搜索要求不高,数据量也不…...

OpenGL_Learn10(颜色)
1. 颜色 我们在现实生活中看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的(Reflected)颜色。换句话说,那些不能被物体所吸收(Absorb)的颜色(被拒绝的颜色)就是我们能够感知到的物体的颜色。例如,太阳光…...

使用Go语言抓取酒店价格数据的技术实现
目录 一、引言 二、准备工作 三、抓取数据 四、数据处理与存储 五、数据分析与可视化 六、结论与展望 一、引言 随着互联网的快速发展,酒店预订已经成为人们出行的重要环节。在选择酒店时,价格是消费者考虑的重要因素之一。因此,抓取酒…...

设计模式1
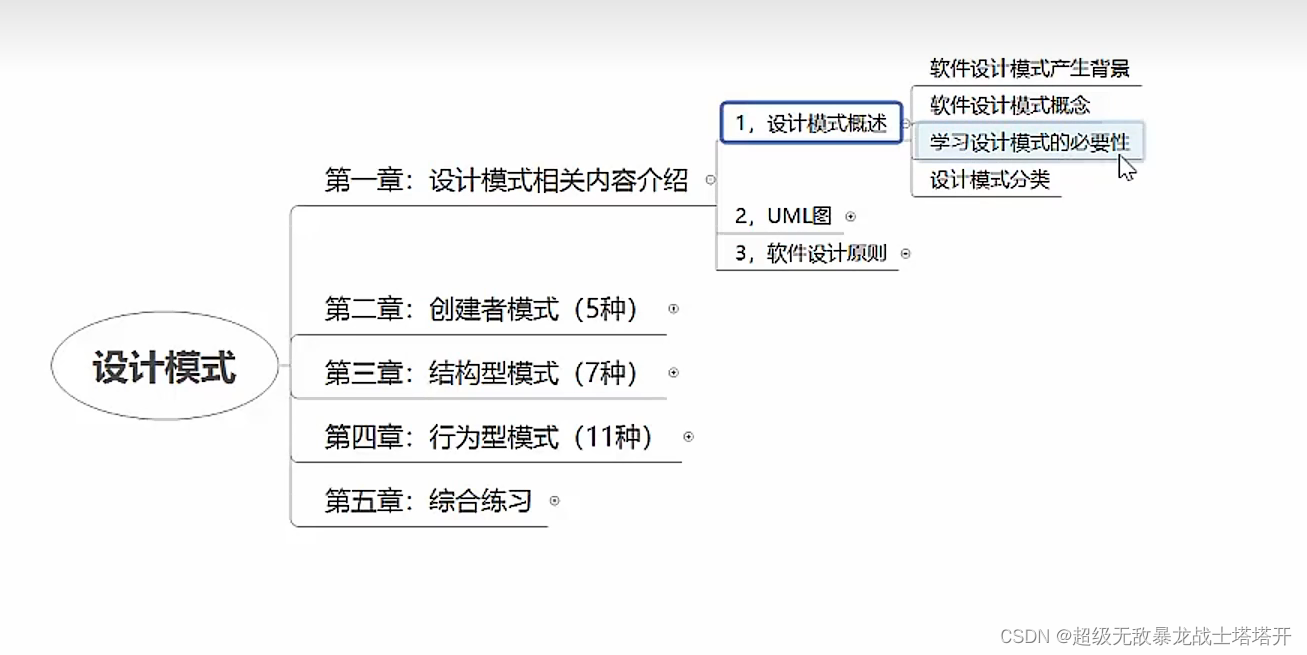一、设计模式分类: 1、创建型模式:创建与使用分离,单例、原型、工厂、抽象、建造者。 2、结构型模式:用于描述如何将对象按某种更大的…...

数字人部署之VITS+Wav2lip数据流转处理问题
一、模型 VITS模型训练教程VITS-从零开始微调(finetune)训练并部署指南-支持本地云端 Wav2lip是2D数字人,可参考训练嘴型同步模型Wav2Lip PS:以上模型都是开源可用。 二. VITS数据处理问题 VITS模型的输出为一维的numpy类型数据ÿ…...
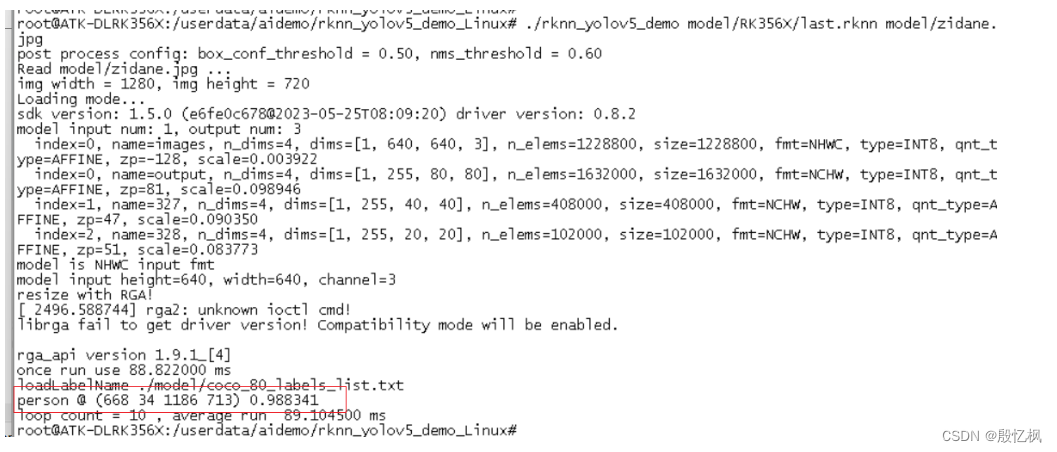
RK3568笔记五:基于Yolov5的训练及部署
若该文为原创文章,转载请注明原文出处。 一. 部署概述 环境:Ubuntu20.04、python3.8 芯片:RK3568 芯片系统:buildroot 开发板:ATK-DLRK3568 开发主要参考文档:《Rockchip_Quick_Start_RKNN_Toolkit2_C…...

夸克网盘自动化助手:告别手动操作,享受智能云存储管理
夸克网盘自动化助手:告别手动操作,享受智能云存储管理 【免费下载链接】quark_auto_save 夸克网盘签到、自动转存、命名整理、发推送提醒和刷新媒体库一条龙 项目地址: https://gitcode.com/gh_mirrors/qu/quark_auto_save 还在为每天重复检查夸克…...

如何一键合并B站缓存视频?HLB站缓存合并工具完全指南
如何一键合并B站缓存视频?HLB站缓存合并工具完全指南 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 你是否曾经遇到过这样的情况:在B站缓存了喜欢的视频,想在离线…...

Flutter微信SDK集成指南 从入门到精通的跨平台解决方案
Flutter微信SDK集成指南 从入门到精通的跨平台解决方案 【免费下载链接】fluwx Flutter版微信SDK.WeChat SDK for flutter. 项目地址: https://gitcode.com/gh_mirrors/fl/fluwx 作为一名Flutter开发者,我深知在应用中集成微信功能的重要性。无论是社交分享、…...

DeepAnalyze舆情分析:社交媒体数据挖掘
DeepAnalyze舆情分析:社交媒体数据挖掘实战指南 1. 引言:社交媒体时代的舆情挑战 每天,社交媒体平台产生着海量的用户内容——从微博的热点讨论到小红书的消费分享,从抖音的短视频评论到专业论坛的技术交流。这些数据中蕴含着宝…...

Unity基础:摄像机Camera的参数设置与视角控制
Unity基础:摄像机Camera的参数设置与视角控制📚 本章学习目标:深入理解摄像机Camera的参数设置与视角控制的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Un…...

灰色关键词排名技术与白帽SEO有什么不同
灰色关键词排名技术与白帽SEO有什么不同 在当前的网络营销环境中,提升网站在搜索引擎上的排名是许多企业和个人的目标。在追求高排名的过程中,有几种不同的方法被采用,其中包括灰色关键词排名技术和白帽SEO。尽管它们都旨在提升网站的搜索引…...

从湖泊到地壳:GNSS与测高数据网站全景导航
1. 为什么需要同时关注水体与地壳数据? 如果你在研究水库蓄水对地面沉降的影响,或是冰川融化导致的地壳回弹现象,就会明白为什么需要同时获取水位变化数据和地壳形变数据。这两类数据看似属于不同领域——一个来自水文监测,一个来…...

Win11Debloat:4步告别系统臃肿,让你的Windows 11焕然一新
Win11Debloat:4步告别系统臃肿,让你的Windows 11焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to de…...

如何用douyin-downloader免费批量下载抖音视频:完整指南
如何用douyin-downloader免费批量下载抖音视频:完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback sup…...

抖音无水印批量下载完整指南:3分钟快速上手免费工具
抖音无水印批量下载完整指南:3分钟快速上手免费工具 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...