Python爬虫所需的常用库
爬虫是指通过程序自动访问互联网上的各种网站,并从网站上抓取所需的数据。Python作为一门强大的编程语言,拥有丰富的库和工具,使得编写爬虫变得更加容易和高效。本文将介绍一些Python爬虫中常用的库,包括网络请求库、解析库、数据存储库等,并提供一些实例来说明它们的用法。
1. 网络请求库
网络请求库是爬虫的基础,它允许我们向目标网站发送HTTP请求、获取网页内容和处理响应。以下是一些常用的网络请求库。
1.1. Requests
Requests是Python中最常用的HTTP库之一,它提供了简洁而优雅的API,用于发送GET、POST和其他类型的HTTP请求。以下是一个使用Requests发送GET请求的例子:
import requestsresponse = requests.get("https://www.example.com")
print(response.text)
Requests还提供了其他功能,如处理会话、处理Cookies、处理代理、处理SSL证书等。它是爬虫中必不可少的一个库。
1.2. Scrapy
Scrapy是一个功能强大的爬虫框架,它基于Twisted异步网络框架,并提供了高效的抓取和解析网页的能力。使用Scrapy可以轻松构建一个完整的爬虫系统,从爬取网页到解析数据再到持久化存储。以下是一个使用Scrapy爬取网页的例子:
import scrapyclass MySpider(scrapy.Spider):name = "example"start_urls = ["https://www.example.com",]def parse(self, response):print(response.body)
Scrapy还提供了更多高级功能,如自动处理Cookies和Sessions、自动处理重定向、自动调度爬虫等。
2. 解析库
解析库用于分析和提取网页中的数据,将复杂的HTML或XML文档转换为易于操作的数据结构。以下是一些常用的解析库。
2.1. Beautiful Soup
Beautiful Soup是一个Python库,用于从HTML或XML文档中提取数据。它提供了一套简单而灵活的API,使得解析网页变得非常容易。以下是一个使用Beautiful Soup解析HTML的例子:
from bs4 import BeautifulSouphtml_doc = """
<html>
<head>
<title>Example</title>
</head>
<body>
<div class="content">
<h1>Welcome to Example</h1>
<p>Some text here</p>
</div>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.title.text)
print(soup.find('div', {'class': 'content'}).h1.text)
Beautiful Soup还提供了其他功能,如查找元素、提取属性、处理文本等。
2.2. lxml
lxml是一个高性能的Python库,用于处理XML和HTML文档。它提供了一个简洁的API,使得解析和修改文档变得容易。以下是一个使用lxml解析HTML的例子:
from lxml import etreehtml_doc = """
<html>
<head>
<title>Example</title>
</head>
<body>
<div class="content">
<h1>Welcome to Example</h1>
<p>Some text here</p>
</div>
</body>
</html>
"""tree = etree.HTML(html_doc)
print(tree.xpath('//title/text()'))
print(tree.xpath('//div[@class="content"]/h1/text()'))
lxml还提供了其他功能,如遍历文档、提取属性、处理命名空间等。
3. 数据存储库
数据存储库用于将爬取的数据存储到本地或远程数据库中,以备后续处理和分析。以下是一些常用的数据存储库。
3.1. SQLite
SQLite是一个轻量级的关系型数据库,它使用单个文件存储整个数据库,非常适合小规模的数据存储和查询。以下是一个使用SQLite存储数据的例子:
import sqlite3conn = sqlite3.connect('example.db')
cursor = conn.cursor()cursor.execute('''CREATE TABLE IF NOT EXISTS data(id INTEGER PRIMARY KEY AUTOINCREMENT,title TEXT,content TEXT)
''')cursor.execute('INSERT INTO data (title, content) VALUES (?, ?)', ('Example', 'Some text here'))conn.commit()
conn.close()
SQLite还提供了其他功能,如查询数据、更新数据、事务处理等。
3.2. MongoDB
MongoDB是一个NoSQL数据库,它使用文档存储数据,非常适合大规模和非结构化的数据存储。以下是一个使用MongoDB存储数据的例子:
from pymongo import MongoClientclient = MongoClient('mongodb://localhost:27017/')
db = client['example']
collection = db['data']data = {'title': 'Example', 'content': 'Some text here'}
collection.insert_one(data)
MongoDB还提供了其他功能,如查询数据、更新数据、索引、聚合操作等。
4. 其他常用库
除了上述的网络请求库、解析库和数据存储库,还有许多其他常用的库可以加强爬虫的功能。
- Scrapy-Redis:一个基于Redis的分布式爬虫框架,可以实现分布式爬虫的调度和队列管理。
- Selenium:一个用于自动化浏览器操作的库,用于处理JavaScript渲染的网页。
- Pandas:一个用于数据分析和处理的库,可以对爬取的数据进行清洗、转换和分析。
- NumPy:一个用于科学计算和数值操作的库,可以用于对爬取的数据进行统计和数值计算。
- Scikit-learn:一个用于机器学习和数据挖掘的库,可以对爬取的数据进行建模和预测。
案例
当然,请看下面的三个案例:
案例1:使用Requests库获取网页内容
import requests# 发送GET请求
response = requests.get("https://www.example.com")
print(response.text)
上述代码使用Requests库发送GET请求,并打印出获取到的网页内容。
案例2:使用Beautiful Soup解析HTML
from bs4 import BeautifulSouphtml_doc = """
<html>
<head>
<title>Example</title>
</head>
<body>
<div class="content">
<h1>Welcome to Example</h1>
<p>Some text here</p>
</div>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.title.text)
print(soup.find('div', {'class': 'content'}).h1.text)
上述代码使用Beautiful Soup解析HTML文档,并提取出标题和内容。
案例3:使用SQLite存储数据
import sqlite3# 连接数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()# 创建表格
cursor.execute('''CREATE TABLE IF NOT EXISTS data(id INTEGER PRIMARY KEY AUTOINCREMENT,title TEXT,content TEXT)
''')# 插入数据
cursor.execute('INSERT INTO data (title, content) VALUES (?, ?)', ('Example', 'Some text here'))# 提交并关闭连接
conn.commit()
conn.close()
上述代码使用SQLite存储数据,首先连接到数据库,然后创建一个名为data的表格,并插入一条数据。最后提交事务并关闭连接。
结论
Python拥有丰富的库和工具,使得编写爬虫变得更加容易和高效。本文介绍了一些Python爬虫中常用的库,包括网络请求库、解析库、数据存储库等,并提供了一些实例来说明它们的用法。通过灵活运用这些库,我们可以轻松构建一个完整的爬虫系统,从爬取网页到解析数据再到存储数据,让我们能够更好地获取和处理互联网上的信息。
相关文章:

Python爬虫所需的常用库
爬虫是指通过程序自动访问互联网上的各种网站,并从网站上抓取所需的数据。Python作为一门强大的编程语言,拥有丰富的库和工具,使得编写爬虫变得更加容易和高效。本文将介绍一些Python爬虫中常用的库,包括网络请求库、解析库、数据…...
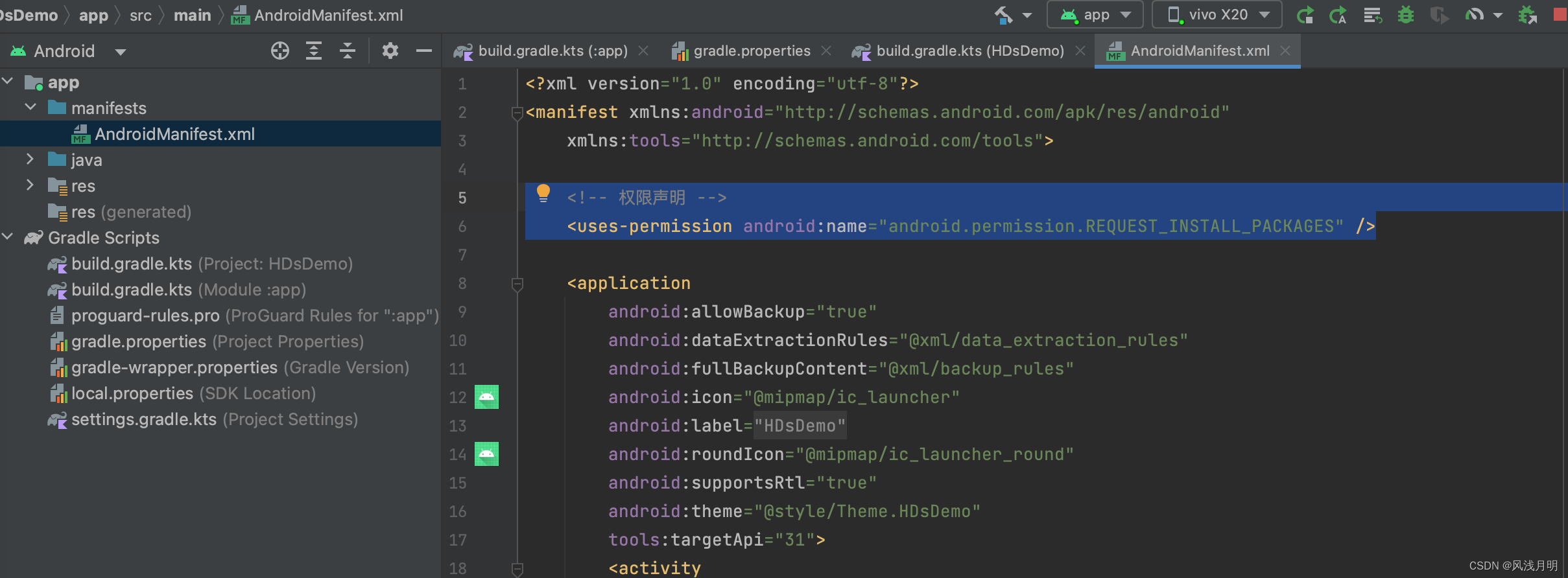
Android Studio真机运行时提示“安装失败”
用中兴手机真机运行没问题,用Vivo运行就提示安装失败。前提,手机已经打开了调试模式。 报错 Android Studio报错提示: Error running app The application could not be installed: INSTALL_FAILED_TEST_ONLY 手机报错提示: 修…...
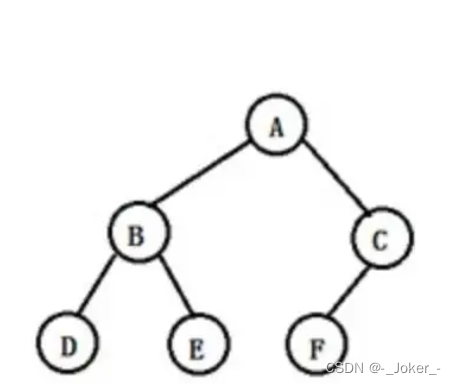
【C语言数据结构————————二叉树】
文章目录 文章目录 一、什么是树 树的定义 树的种类 树的深度 树的基本术语 二、满二叉树 定义 满二叉树的特点 三、完全二叉树 定义 特点 四、二叉树的性质 五、二叉树的存储结构 顺序存储结构 链式存储结构 六、二叉树的基本操作 七、二叉树的创建 八、二叉树…...
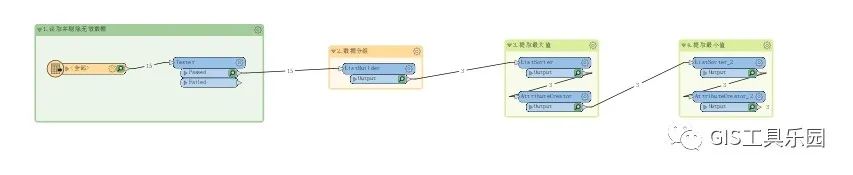
分组取每组数据的最大值和最小值的方法思路,为类似场景的数据分析提取提供思路,例如提取宗地内建筑的最高层数等可参考此方法思路
目录 一、实现效果 二、实现过程 1.读取并剔除无效数据 2.数据分组 3.提取最大值 4.提取最小值 三、总结 使用FME实现批量分组取每组数据的最大值和最小值,为类似场景的数据分析提取提供思路,例如提取宗地内建筑的最高层数等可参考此方法思路。关…...
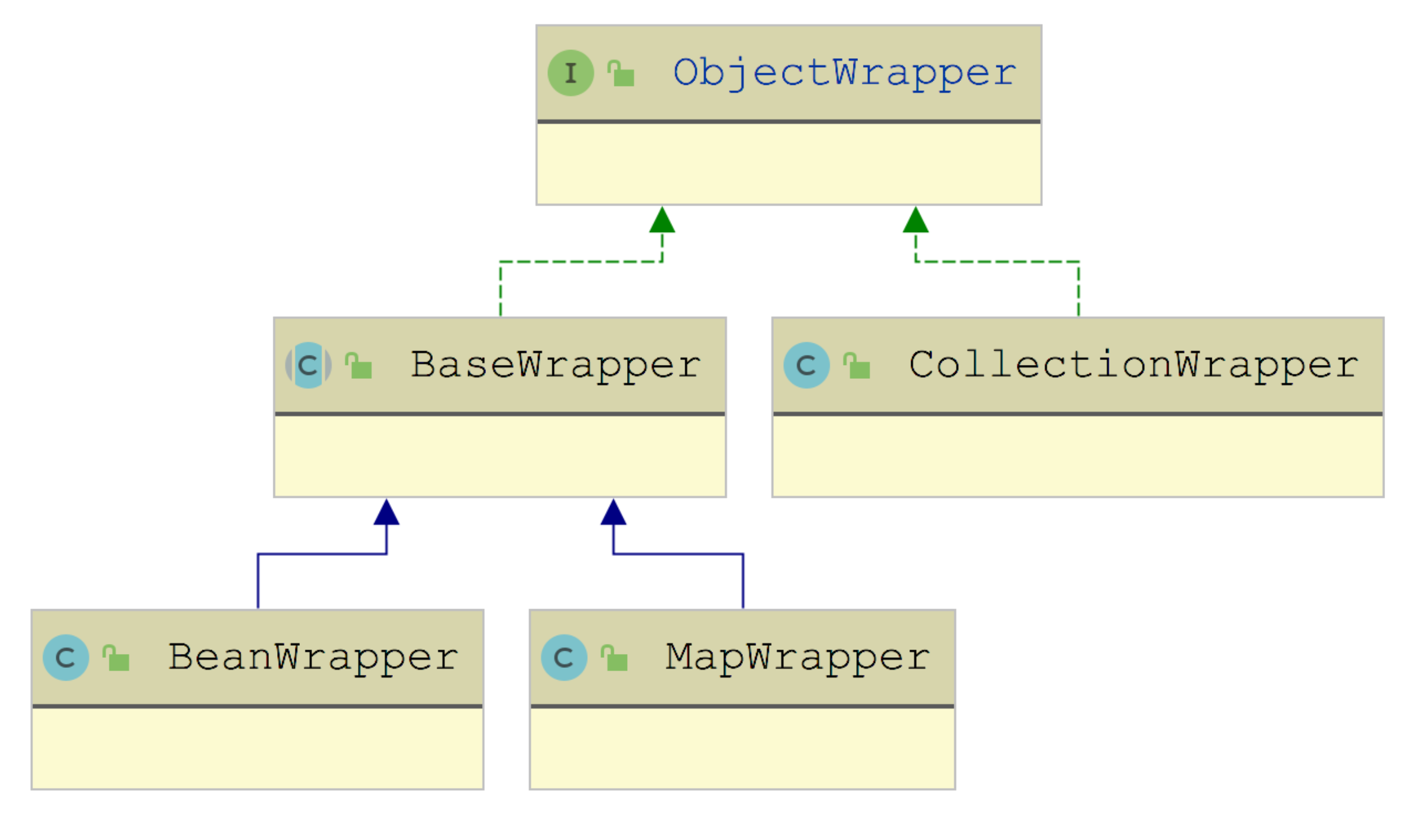
MyBatis 反射工具箱:带你领略不一样的反射设计思路
反射是 Java 世界中非常强大、非常灵活的一种机制。在面向对象的 Java 语言中,我们只能按照 public、private 等关键字的规范去访问一个 Java 对象的属性和方法,但反射机制可以让我们在运行时拿到任何 Java 对象的属性或方法。 有人说反射打破了类的封装…...
Netty第三部
继续Netty第二部的内容 一、ChannelHandler 1、ChannelHandler接口 ChannelHandler是Netty的主要组件,处理所有的入站和出站数据的应用程序逻辑的容器,可以应用在数据的格式转换、异常处理、数据报文统计等 继承ChannelHandler的两个子接口ÿ…...

【C++入门篇】保姆级教程篇【下】
目录 一、运算符重载 1)比较、赋值运算符重载 2) 流插入留提取运算符重载 二、剩下的默认成员函数 1)赋值运算符重载 2)const成员函数 3)取地址及const取地址操作符重载 三、再谈构造函数 1)初始化列表 …...

CCLink转Modbus TCP网关_CCLINK参数配置
CCLink转Modbus TCP网关(XD-ETHCL20),具有CCLINK主从站功能。主要用途是将各种MODBUS-TCP设备接入到CCLINK总线中。它可以作为从站连接到CCLINK总线上,也可以作为主站或从站连接到MODBUS-MTP总线上。 1、 配置网关的CCLINK参数&am…...
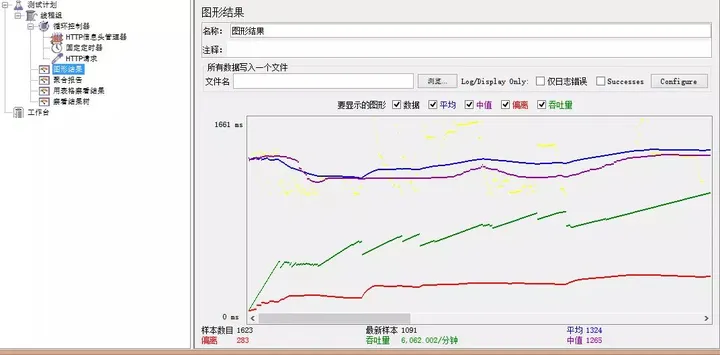
一文2000字从0到1使用压测神器JMeter进行压力测试!
概 述 Apache JMeter 是 Apache组织开发的基于 Java的压力测试工具。用于对软件做压力测试,它最初被设计用于 Web应用测试但后来扩展到其他测试领域。它可以用于测试静态和动态资源例如静态文件、Java 小服务程序、CGI 脚本、Java 对象、数据库, FTP 服…...

极狐GitLab CI 助力 .Net 项目研发效率和质量双提升
目录 .NET nuget 自动生成测试包(prerelease)版本号 .NET 版本号规范 持续集成自动打包 持续集成自动修改版本号 .NET 行级增量代码规范——拯救老项目 本地全量代码规范 行级增量代码规范 很多团队或开发者都会使用 C#、VB 等语言开发 .Net 应用…...
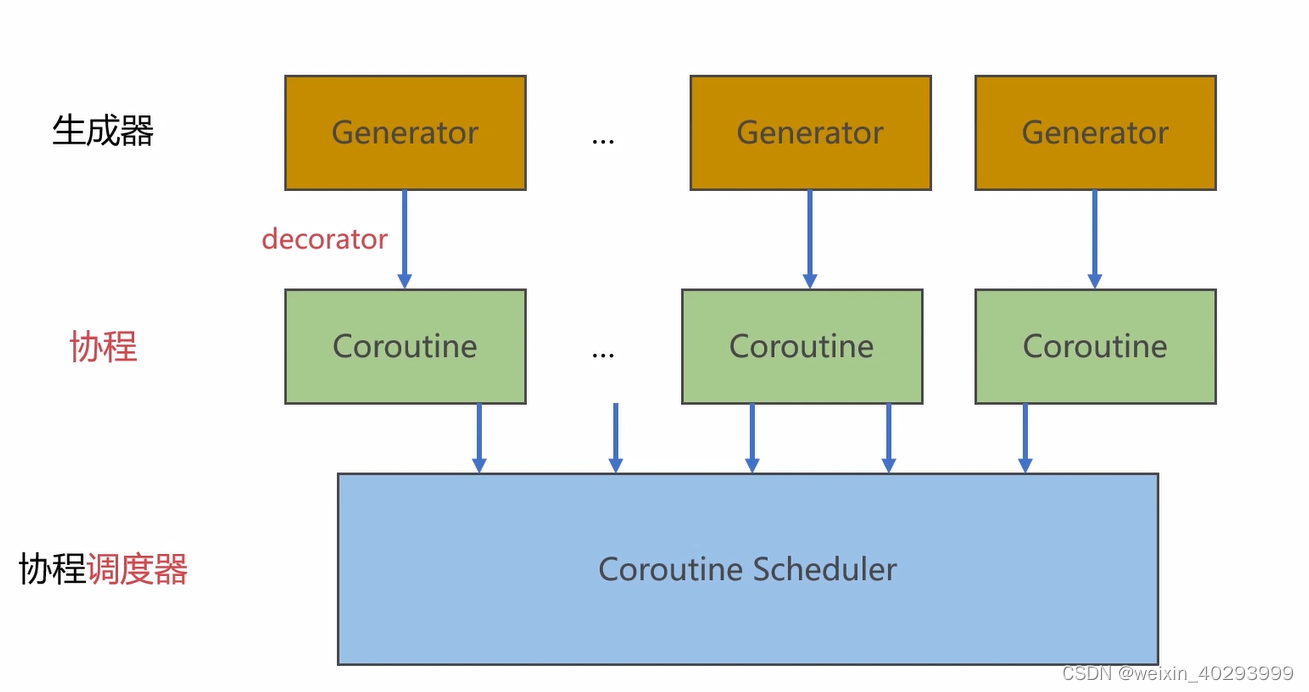
[协程]生成器协程调度器的实现-未完
本章内容的三个层次...
Git之分支与版本->课程目标及知识点的应用场景,分支的场景应用,标签的场景应用
1.课程目标及知识点的应用场景 Git分支和标签的命名规范 分支 dev/test/pre/pro(即master) dev:开发环境--windows (自己的电脑) test:测试环境--windows/linux (公司专门的测试电脑 pre:灰度环境(非常大的公司非常重要的项目) pro:正式环境 灰度环境与正式环境的服务器配置…...

PHP正则提取或替换img标记属性
<?php/*PHP正则提取图片img标记中的任意属性*/ $str <center><img src"/uploads/images/20100516000.jpg" height"120" width"120"><br />PHP正则提取或更改图片img标记中的任意属性</center>;//1、取整个图片代码…...

Git 命令行使用指南
Git 命令行使用指南 第一部分:配置 Git 1.1 设置用户信息1.2 配置换行符处理 第二部分:创建和配置仓库 2.1 初始化仓库2.2 克隆仓库2.3 递归克隆2.4 深度克隆 第三部分:基本操作 3.1 添加文件3.2 提交更改3.3 查看状态和提交历史3.4 创建和切…...

Spring 常见面试题
1、Spring概述 1.1、Spring是什么? Spring是一个轻量级Java开发框架,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。这些功能的底层都依赖于它的两个核心特性,也就是…...

caffe搭建squeezenet网络的整套工程
之前用pytorch构建了squeezenet,个人觉得pytorch是最好用的,但是有的工程就是需要caffe结构的,所以本篇也用caffe构建一个squeezenet网络。 数据处理 首先要对数据进行处理,跟pytorch不同,pytorch读取数据只需要给数据…...

【OWT】梳理构建的webrtc和owt mfc工程
梳理构建的webrtc和owt mfc工程M98 + owtp2p : 发现最终基于m98的owt也可以直接跑通 【owt】p2p client mfc 工程梳理 服务端使用github版本。 本地运行调试即可。 M98 VS2017 构建 :只构建了m98的webrtc.lib 【webrtc】vs2017 重新构建m98 G:\webrtc_m98_yjf\src webrtc本身…...

02 powershell服务器远程执行命令
一、获取服务器登录凭证 $Username myft\xngrq $PWD 123!# #将密码加密成特殊的字符串对象 $pass ConvertTo-SecureString -AsPlainText $PWD -Force #创建一个登录凭证对象 $Cred New-Object System.Management.Automation.PSCredential -ArgumentList $Username,$pass …...

LeetCode257. Binary Tree Paths
文章目录 一、题目二、题解 一、题目 Given the root of a binary tree, return all root-to-leaf paths in any order. A leaf is a node with no children. Example 1: Input: root [1,2,3,null,5] Output: [“1->2->5”,“1->3”] Example 2: Input: root […...
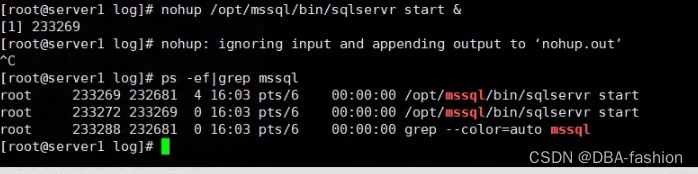
Linux下MSSQL (SQL Server)数据库无法启动故障处理
有同事反馈一套CentOS7下的mssql server2017无法启动需要我帮忙看看,启动报错情况如下 检查日志并没有更新日志信息 乍一看mssql-server服务有问题,检查mssql也确实没有进程 既然服务有问题,那么我们用一种方式直接手工后台启动mssql引擎来…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...