【C++】非类型模板参数 | array容器 | 模板特化 | 模板为什么不能分离编译
目录
一、非类型模板参数
二、array容器
三、模板特化
为什么要对模板进行特化
函数模板特化
补充一个问题
类模板特化
全特化与偏特化
全特化
偏特化
四、模板为什么不能分离编译
为什么
怎么办
五、总结模板的优缺点
一、非类型模板参数
模板参数分两类:类型形参 与 非类型形参。
类型形参:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参:用一个常量作为类 (函数) 模板的一个参数,在类 (函数) 模板中可将该参数当成常量来使用。
为什么需要非类型模板参数呢?我们先来看这样一个场景。
我定义了一个静态栈MyStack:
#define N 100
template<class T>
class MyStack
{
private:int arr[N];int top;
};
int main() {MyStack<int> st;return 0;
}这样实例化出的栈,大小都是100。那假如我想要两个栈,一个大小为100,一个为200,要怎么办呢?
这就是#define所解决不了的问题了。
为此,我们引入了非类型模板参数,来看看它是怎么处理这个问题的:
template<class T,int N> //非类型模板参数N
class MyStack
{
private:int arr[N];int top;
};
int main() {MyStack<int, 100> st1;MyStack<int, 200> st2;return 0;
}这样实例化出的st1,大小为100;st2,大小为200。
注意:
1.整形家族可以作为非类型模板参数,包括char、short、int、long、longlong。最常见的是int。
浮点数、类对象以及字符串是不允许作为非类型模板参数的。
2.非类型的模板参数必须在编译期就能确认结果。
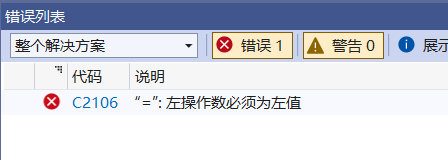
3.非类型模板参数是是常量,是不能修改的。
不信来修改下试试:
template<class T,int N> class MyStack { public:void func() {N = 200; //修改N} private:int arr[N];int top; }; int main() {MyStack<int, 100> st1;st1.func();return 0; }
二、array容器
学习了非类型模板参数,我们就可以了解下array容器。这个容器很少用,了解即可。
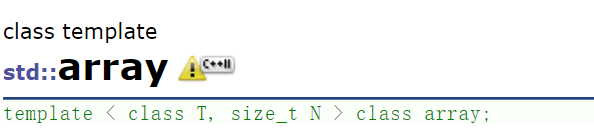
array,大小固定的数组。
相比之前学过的动态数组vector,array的功能就显得有些鸡肋:array有的功能,vector也有;而vector有的功能,array未必有。
一方面,vector是开在堆上的,大小可以变化;而array开在栈上,大小固定。但这也是array的优势,正因为是栈上分配内存,所以比vector的效率更高。
但总的来说,用array的地方,我们往往也能用vector,vector还更好用。所以这个容器很少用。
三、模板特化
模板特化的概念:
在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。
当模板被使用时,编译器会针对特定的类型使用特定的实现,而非使用通用的实现,从而提高代码的效率。
为什么要对模板进行特化
假如我们想要对9和2进行大小比较,现用两种方式比,然而,比较结果却出现了分歧:
template<class T>
bool IfLess(const T& x, const T& y) {return x < y;
}
int main() {int a = 2, b = 9;int* pa = &a, * pb = &b;cout << IfLess(a, b) << endl; cout << IfLess(pa, pb) << endl;return 0;
}
存进a、b变量里,得到的是正确的结果。而通过传指针的方式,得到的是错误的结果。
这是因为,这里直接比较了指针的大小,而无法对指针先解引用 再比较。
此时,就需要对模板进行特化。我们希望达到的效果是:传指针也能比大小。
模板特化中分为函数模板特化与类模板特化。
函数模板特化
函数模板的特化步骤:
1.必须要先有一个基础的函数模板
2.关键字template后面接一对空的尖括号<>
3.函数名后跟一对尖括号,尖括号中指定需要特化的类型
4.函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
如,这里就没有做到完全相同,所以报错了:
应改为:
template<class T> bool IfLess(T& x,T& y) {return x < y; } template<> bool IfLess<int*>(int*& x, int*& y) { //注意形参要和基础参数完全相同!return *x < *y; }

函数模板特化的示例:
#include<iostream>
using namespace std;
template<class T>
bool IfLess(T& x,T& y) {return x < y;
}
template<>
bool IfLess<int*>(int*& x, int*& y) {return *x < *y;
}
int main() {int a = 2, b = 9;int* pa = &a, * pb = &b;cout << IfLess(a, b) << endl;cout << IfLess(pa, pb) << endl;return 0;
}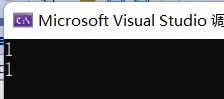
在调用时,函数会根据实参类型,调用对应的函数模板:

补充一个问题
思考:为什么这样写不对?
#include<iostream>
using namespace std;
template<class T>
bool IfLess(const T& x, const T& y) {return x < y;
}
template<>
bool IfLess<int*>(const int*& x,const int*& y) { //明明基础参数类型完全一致,为啥报错?return *x < *y;
}
int main() {……
}编译不通过:
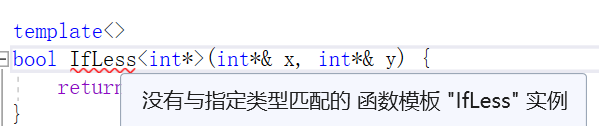
这里看似 和基础参数类型完全一致,实际上只是做到了形式上的一致,内涵上却大相径庭。
在基础函数参数中,const修饰形参x、y,保证它们不被改变;那迁移到 特化的参数中,对应的是:const修饰两个指针x、y,使之不被改变。
而const int*& x,const修饰的是指针x指向的内容不受改变,即const修饰 *x。
正确的写法是:int* const& x,让const直接修饰指针x。
📖如果你还是一头雾水,那说明“指针常量and常量指针”的知识点你没掌握好,现在我予以补充。
指针常量:int* const p。const直接修饰指针p,p自身的值不能改变,即p的指向是不能变的,而*p可以改变。
p就相当于一个常量了,此常量的类型为指针,因而叫指针常量。
常量指针:const int* p或int const* p,const修饰的是*p,即指针指向的内容是不能变的,而指针的指向可以改变。
因为指向的内容不能变,就相当于指向了一个常量,所以叫常量指针。
类模板特化
当我们需要针对某些特定类型进行特殊处理时,就需要对类模板进行特化。
如,我们定义了一个类模板 用于计算两个数的和:
#include <iostream>
using namespace std;
template<class T1,class T2>
class Adder
{
public:T1 add(T1 x, T2 y) {return x + y;}
};
int main() {Adder<int,double> a;int ret1 = a.add(1, 1.1); //我想要ret1是整形,ret2是浮点型double ret2 = a.add(1, 1.1);cout << ret1 << endl;cout << ret2 << endl;
return 0;
}我想要1+1.1的结果,一个取整为2,一个保留小数为2.1。然而,结果却:
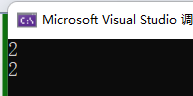
结果都是整形。因为返回类型T1是int,这会直接把2.1截断,返回2,存进ret2里。
来看看 当引入类模板特化,是怎么解决这个问题的吧:
#include <iostream>
using namespace std;
template<class T1,class T2>
class Adder
{
public:T1 add(T1 x, T2 y) {return x + y;}
};
template<>
class Adder<int,double>
{
public:double add(int x, double y) {return x + y;}};
int main() {Adder<int,double> a;int ret1 = a.add(1, 1.1);double ret2 = a.add(1, 1.1);cout << ret1 << endl;cout << ret2 << endl;
return 0;
}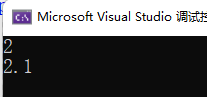
所以说,当需要针对特殊情况做特殊处理时,可以考虑使用类模板特化。
全特化与偏特化
全特化
将所有的模板参数都确定化。(我们刚刚给出的那几个例子,都是全特化的)
例:
template<class T1,class T2>
class Adder
{
public:T1 add(T1 x, T2 y) {return x + y;}
};
template<>
class Adder<int,double>
{
public:double add(int x, double y) {return x + y;}
};注意看,全特化时,template<>尖括号里一定是空的。在尖括号内不添加类型,表示完全特化。
(但不能凭<>是否为空,来区分是全or偏特化。偏特化的<>也可以为空)
偏特化
偏特化又叫半特化。下面这2种情况都属于偏特化:
1.将参数表中一部分参数进行特化。
例:
template<class T1,class T2>
class Adder
{
public:T1 add(T1 x, T2 y) {return x + y;}
};
template<class T1> //只特化了T2,T1还得保留
class Adder<T1,double>
{
public:double add(T1 x, double y) {return x + y;}};2.对参数进行更进一步的限制。
例:如果我们想要 传参时,确保是引用传参,该怎么做呢?
template<class T1, class T2>
class Adder
{
public:T1 add(T1 x, T2 y) {cout << "调用了普通类模板" << endl;return x + y;}
};
template<class T1,class T2>
class Adder<T1& ,T2&> //限制两个参数是引用
{
public:double add(const T1& x, const T2& y) {cout << "调用了特化类模板" << endl;return x + y;}
};
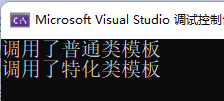
int main() {Adder<int,double> a;a.add(1, 1.1);
Adder<int&, double&> b; //调用特化的类模板,这样的话,就一定是传引用传参b.add(1, 1.1);
return 0;
}
四、模板为什么不能分离编译
为什么
最开始接触模板时,就说过:模板不能分离编译。那为什么呢?我们要知其然,还要知其所以然。现在,我通过一个例子来说明这个原因。
我现在在一个project里创建了三个文件:Add.h、Add.cpp、main.cpp,分别用于声明、定义和测试。
//Add.h
#include<iostream>
using namespace std;
template<class T1,class T2>
T1 Add(T1 x,T2 y);
//Add.cpp
#include"Add.h"
template<class T1, class T2>
T1 Add(T1 x, T2 y) {return x + y;
}
//main.cpp
#include"Add.h"
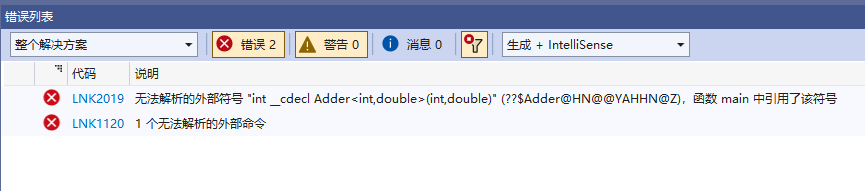
int main() {cout << Add(1, 2.0) << endl;return 0;
}运行报错:
原因说明:
我们先来回顾下,程序是怎么运行的。
程序在运行时,要经历四个阶段:预处理、编译、汇编、链接。
a.在预处理阶段,头文件被展开、宏被替换、注释被删除;
b.在编译阶段,编译器对各个源文件分别进行语法检查,然后将其转化成汇编代码。(注意:此阶段已经没有头文件了)
c.由于机器只能识别0、1串,所以我们的代码要经过汇编,从给人看的字符,变成给机器看的01。在汇编阶段,会形成符号表(用于存放变量、函数的地址)。
d.链接时,计算机遇到不认识的变量、函数,就会去符号表里找它的地址。通过链接,一个项目里的多个文件,才能合成一个关联的整体。
模板之所以不能分离编译,就是在链接阶段出岔子了。
我们说过,模板就像一张图纸。Add.cpp里的函数模板,因为没有确定的类型,所以并未实例化出具体的函数,自然无法在符号表中生成对应的地址。
在mian.cpp中,模板隐式实例化出 函数Add<int,double>,想要调用,却在符号表里找不到地址。所以报错:Add<int,double>为无法解析的外部符号。
怎么办
既然不能分离编译,那一般怎样处理模板呢?这里提供两种方法。
1.(推荐!)用到模板的地方,就不要分离编译~
将声明和定义放到同一个文件 "xxx.hpp" (或者"xxx.h")。
2.(不推荐)模板定义的位置显式实例化。
你要调用的函数,都显式实例化放在Add.cpp中:
template<class T1, class T2>
T1 Add(T1 x, T2 y) {return x + y;
}
//显示实例化
template
int Add(int x, double y);这样写不好,因为如果你要调用好几种不同参数类型的Add,你就都要显式实例化,这就造成了代码的冗余。
五、总结模板的优缺点
优点:
1.模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
2.增强了代码的灵活性
缺点:
1.模板会导致代码膨胀问题,也会导致编译时间变长
2.出现模板编译错误时,错误信息非常凌乱,不易定位错误
相关文章:
【C++】非类型模板参数 | array容器 | 模板特化 | 模板为什么不能分离编译
目录 一、非类型模板参数 二、array容器 三、模板特化 为什么要对模板进行特化 函数模板特化 补充一个问题 类模板特化 全特化与偏特化 全特化 偏特化 四、模板为什么不能分离编译 为什么 怎么办 五、总结模板的优缺点 一、非类型模板参数 模板参数分两类&#x…...

解决 Django 开发中的环境配置问题:Windows 系统下的实战指南20231113
简介: 在本文中,我想分享一下我最近在 Windows 环境下进行 Django 开发时遇到的一系列环境配置问题,以及我是如何一步步解决这些问题的。我的目标是为那些可能遇到类似困难的 Django 开发者提供一些指导和帮助。 问题描述: 最近…...
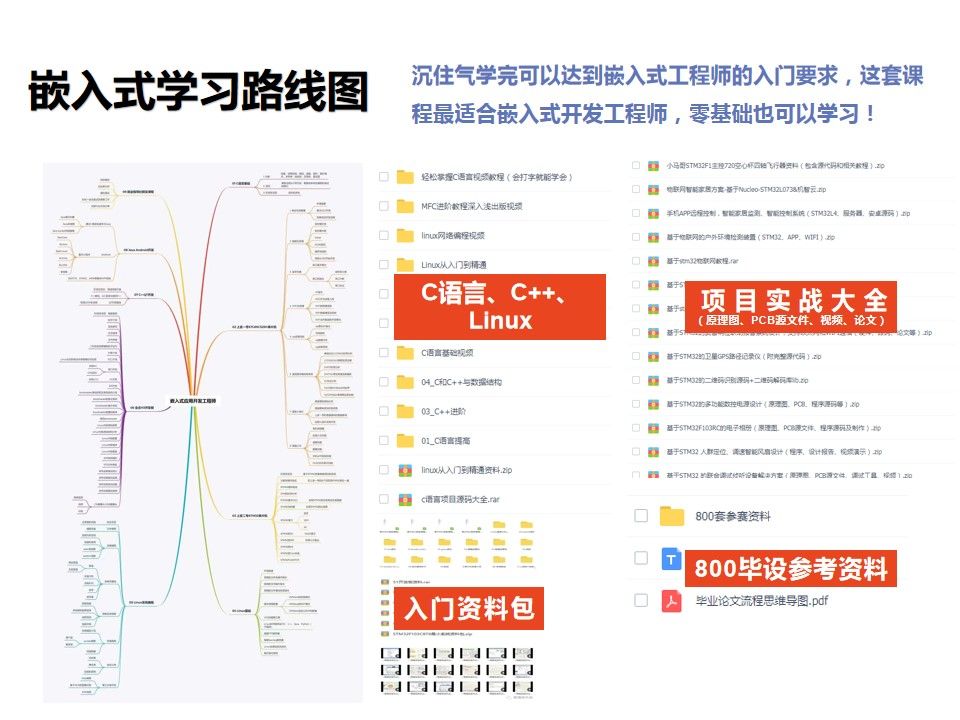
C语言仅凭自学能到什么高度?
今日话题,C语言仅凭自学能到什么高度?学习C语言的决定我确实非常推荐,毕竟它是编程领域的“通用工具”,初学者可以尝试并在发现编程的乐趣后制定长期学习计划。至于能够达到何种高度,这实在无法准确回答。即使是经验丰…...

Python爬虫过程中DNS解析错误解决策略
在Python爬虫开发中,经常会遇到DNS解析错误,这是一个常见且也令人头疼的问题。DNS解析错误可能会导致爬虫失败,但幸运的是,我们可以采取一些策略来处理这些错误,确保爬虫能够正常运行。本文将介绍什么是DNS解析错误&am…...

vue devtools 调试工具安装配置
方式一:在谷歌商店下载安装 打开Google Chrome浏览器 --> 右上角三个点图标 --> 更多工具 --> 扩展程序 --> 在 Chrome 应用商店中查找扩展程序和主题背景 方式二:下载插件安装包自行配置 下载devtools安装包 使用git下载,内含…...
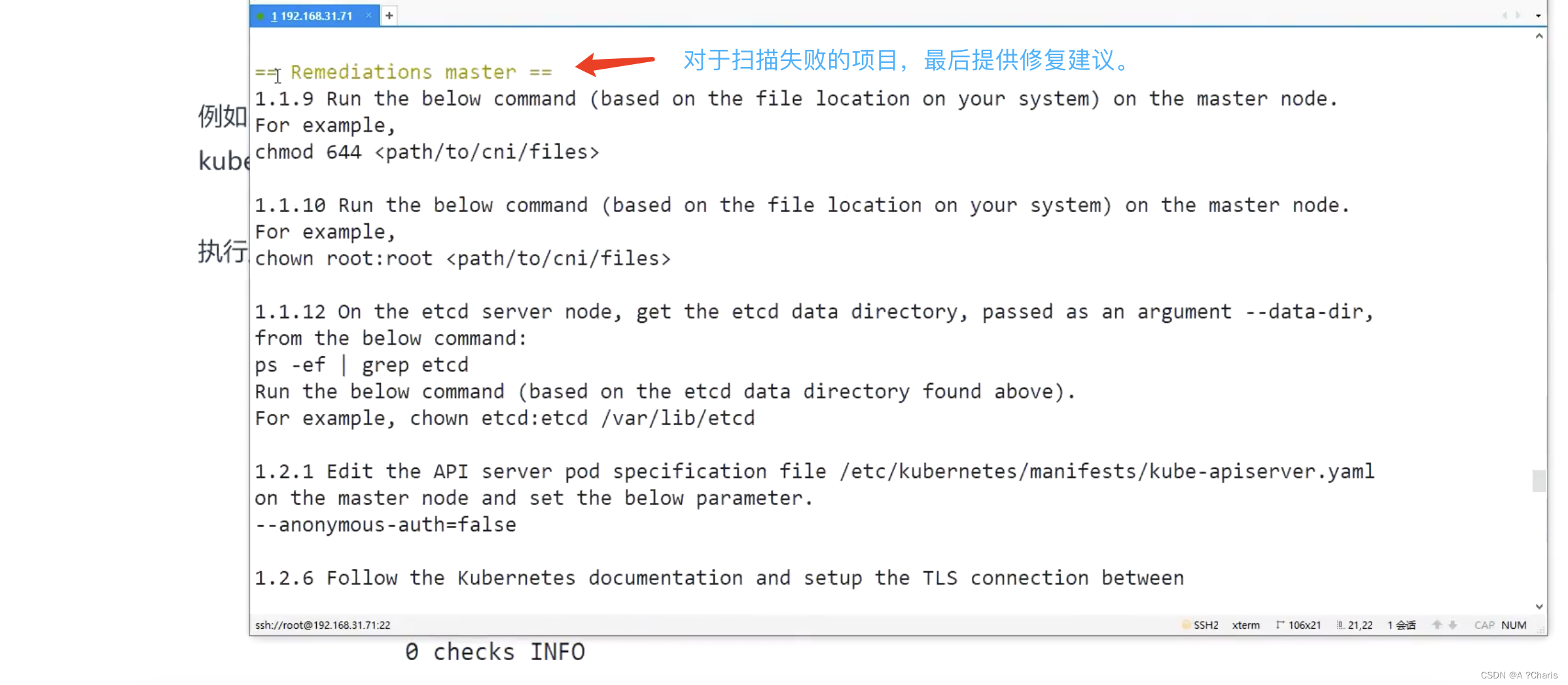
kube-bench-CIS基准的自动化扫描工具学习
仓库地址:GitHub - aquasecurity/kube-bench: Checks whether Kubernetes is deployed according to security best practices as defined in the CIS Kubernetes Benchmark kube-bench,检查 Kubernetes 是否根据 CIS Kubernetes 基准中定义的安全最佳实践部署,下载…...
)
springboot(ssm 拍卖行系统 在线拍卖平台 Java(codeLW)
springboot(ssm 拍卖行系统 在线拍卖平台 Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0)…...

go语言rpc初体验
go语言rpc初体验 package mainimport ("net""net/rpc" )// 注册一个接口进来 type HelloService struct { }func (s *HelloService) Hello(request string, replay *string) error {//返回值是通过修改replay的值*replay "hello " requestret…...
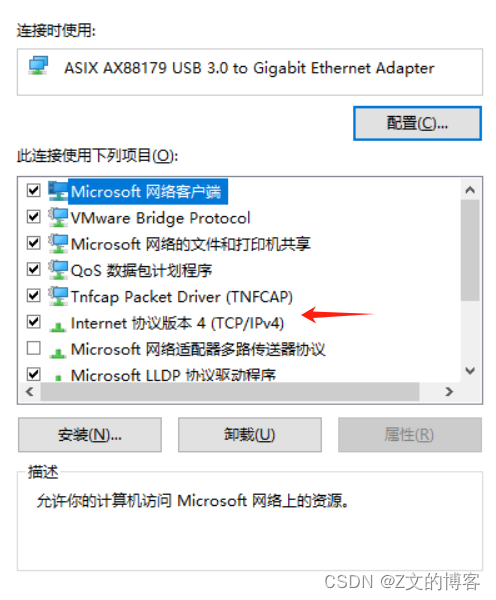
嵌入式LINUX——环境搭建 windows、虚拟机、开发板 互ping
摘要: 本文包含,如果设置linux开发板和虚拟机、windows 互ping成功 以及设置过程中出现的虚拟机、开发板查询不到eth0 windows ping开发板出项丢包等问题的解决方式。 windows端设置 windows端插入USB转网卡 打开windows桌面下右下角的网络标识 打开“更改适配器选项”…...
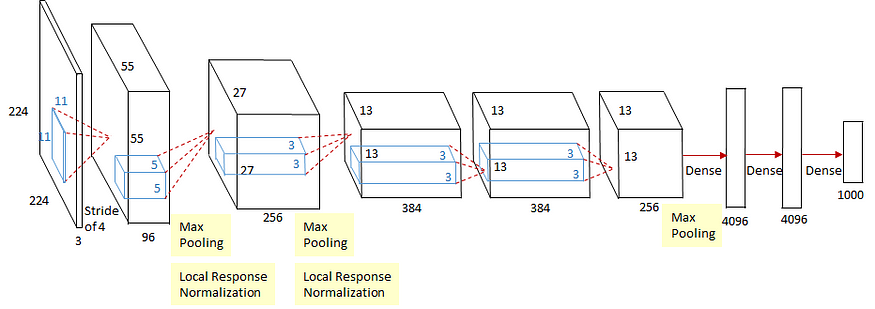
评论:AlexNet和CaffeNet有何区别?
一、说明 在这个故事中,我们回顾了AlexNet和CaffeNet。AlexNet 是2012 年ILSVRC(ImageNet 大规模视觉识别竞赛)的获胜者,这是一项图像分类竞赛。而CaffeNet是AlexNet的单GPU版,因此,我们平时在普通电脑的Al…...

什么是 IT 资产管理(ITAM),以及它如何简化业务
IT 资产管理对任何企业来说都是一项艰巨的任务,但使用适当的工具可以简化这项任务,例如,IT 资产管理软件可以为简化软件和硬件的管理提供巨大的优势。 什么是 IT 资产管理 IT 资产管理(ITAM)是一组业务实践ÿ…...
git快速上传代码
① git init; 初始化git,之后在文件夹里有.git文件,这个需要 勾选才能查看。 ② git remote add test myFisrtTest: 测试专用 这里的test是自定义的,myFisrtTest: 测试专用 是远程仓库 ③ git branch -a 这里是查看分支 ④ …...
stable diffusion comfyui的api使用教程
一、为什么要使用comfyui的api?对比webui的api,它有什么好处? 1、自带队列 2、支持websocket 3、无需关心插件是否有开放api接口,只要插件在浏览器中可以正常使用,接口就一定可以使用 4、开发人员只需关心绘图流程的搭建 5、切换…...

Swift中的strong, weak, unowned
在 Swift 中,strong, weak, 和 unowned 关键词用于管理内存中对象的引用。这些关键词与 Swift 的自动引用计数(ARC)系统紧密相关,用于防止内存泄漏和强引用循环。下面是对这三种引用类型的简要说明: 1. Strong 默认行…...

Linux命令——ssh
Linux命令——ssh 背景 SSH(Secure Shell 的缩写)是一种网络协议,用于加密两台计算机之间的通信,并且支持各种身份验证机制。 历史上,网络主机之间的通信是不加密的,属于明文通信。这使得通信很不安全&a…...

在qml中,text如何左对齐,对齐方式有哪些?如何换行?
在Qt Quick(即QML)中,你可以使用Text组件的horizontalAlignment属性来控制文本的对齐方式。以下是一些常用的对齐方式: Align.Left: 文本左对齐。这是默认的对齐方式。 Align.Center: 文本居中对齐。 Align.Right: 文本右对齐。 …...

【Rust 易学教程】第 1 天:Rust 基础,基本语法
上一节:【Rust 易学教程】学前准备:Cargo, 你好 今天,我们正式进入 Rust 基础的学习。在本文的内容中,我会为大家介绍以下内容: 基本 Rust 语法: 变量、标量和复合类型、枚举、结构、引用、函数和方法。控…...

Linux(命令)——结合实际场景的命令 查找Java安装位置命令
前言 在内卷的时代,作为开发的程序员也需要懂一些Linux相关命令。 本篇博客结合实际应用常见,记录Linux命令相关的使用,持续更新,希望对你有帮助。 目录 前言引出一、查找Java安装位置命令1、使用which命令2、使用find命令3、查…...

C语言基础 -- scanf函数的返回值及其应用
前言、scanf函数有返回值 我们在作PTA上的编程作业时,经常在编译窗口会看到如下的信息: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result] 当时老师一定会告诉你,这个一个&qu…...
mac 安装 selenium + chrome driver
前言 使用 selenium 模拟浏览器渲染数据,需要依赖各浏览器的驱动才能完成,因此需要单独安装chrome driver 查看本地 chrome 浏览器的版本 可以看到我这里已经是 arm 架构下最新的版本了 下载对应的 chrome driver 访问下面的地址: Chrome…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...