深入理解Kafka3.6.0的核心概念,搭建与使用
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,kafka部署包“kafka_2.13-3.6.0”前面的2.13就是scala的版本
1、Kafka的使用场景
日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
2、Kafka基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是并没有完全遵循JMS规范。
首先,让我们来看一下基础的消息(Message)相关术语:
名称 解释
Broker 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
Topic Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
Producer 消息生产者,向Broker发送消息的客户端
Consumer 消息消费者,从Broker读取消息的客户端
ConsumerGroup 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息
Partition 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的
Replica(副本) 一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower
Leader 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader
Follower 每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
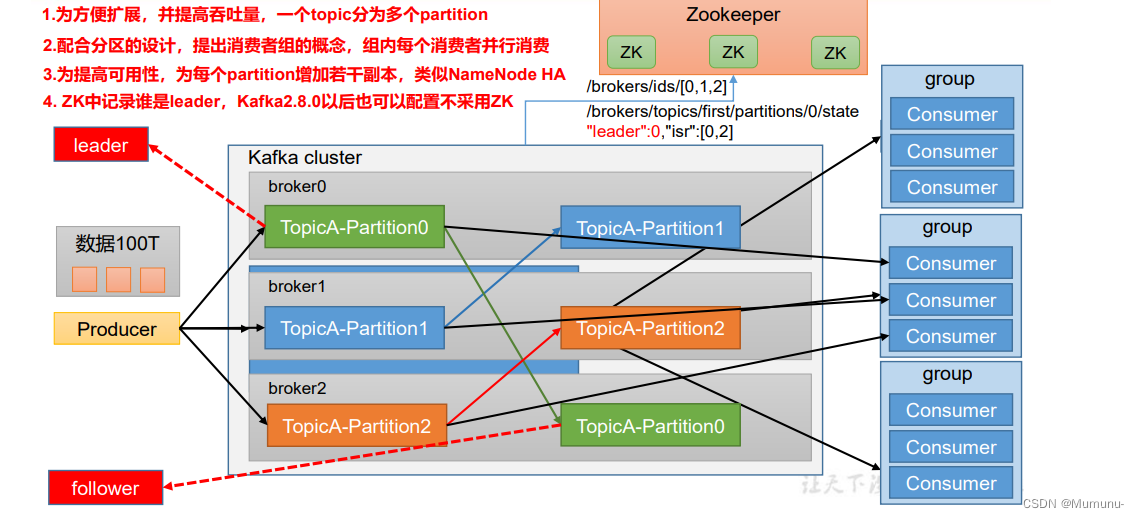
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
3、Topic与Partition
在Kafka中,Topic就是一个主题,生产者往topic里面发送消息,消费者从topic里面捞数据进行消费。
假设现在有一个场景,如果我们现在有100T的数据需要进行消费,但是现在我们一台主机上面并不能存储这么多数据该怎么办呢?
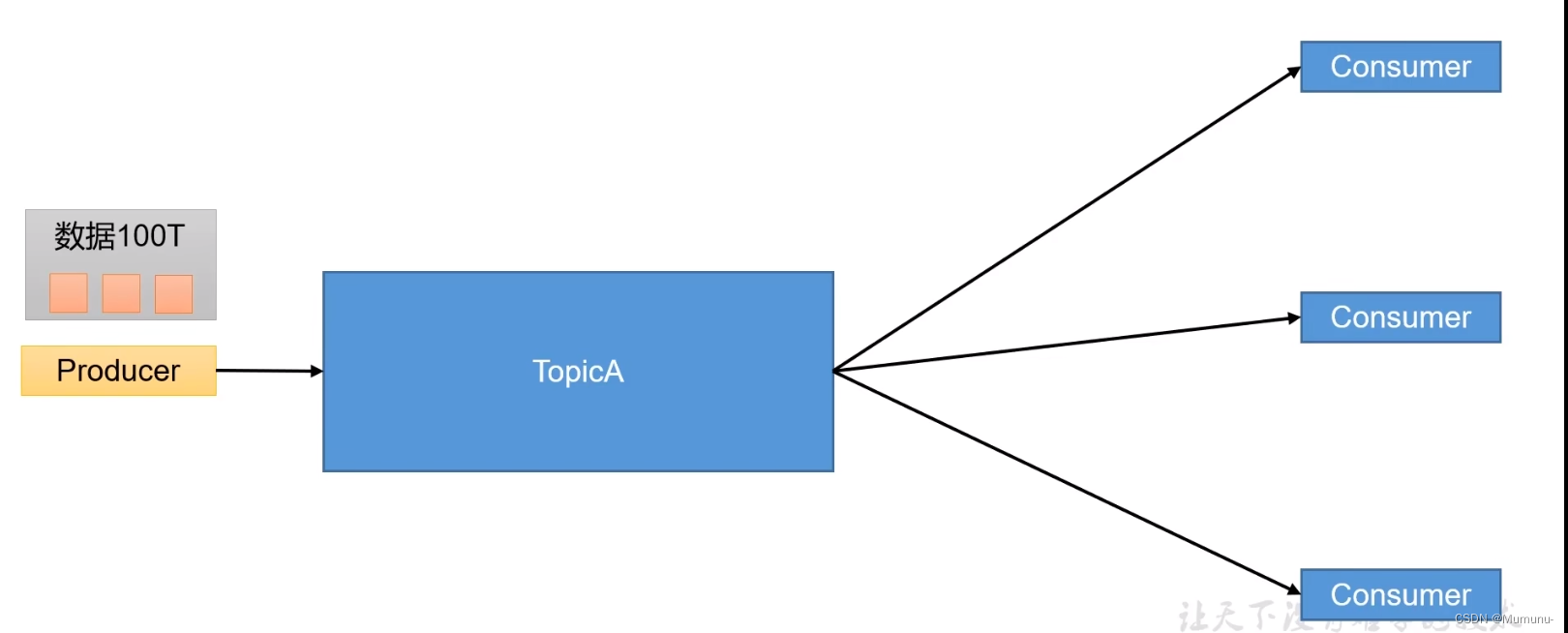
其实做法很简单,就是将海量的数据进行切割,并且在Topic中添加分区的概念,每一个分区都对应一台主机,并且存储切分到的数据
当然为了实现高可用,其实分区可以实现主从架构,这个后面再了解
这样做的好处是:
分区存储,可以解决一个topic中文件过大无法存储的问题
提高了读写的吞吐量,读写可以在多个分区中同时进行
4、搭建部署
首先部署java,不再赘述,很简单,然后去官网下载两个安装包
kafka_2.13-3.6.0
apache-zookeeper-3.9.1-bin.tar
(3.0之后kafka自带zookeeper,也可以省略)
解压后进入conf文件夹
cp zoo_sample.cfg zoo1.cfg#复制一份zk的配置文件
修改配置文件内容tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zkdata #启动之前需要建好
datalogDir=/data/zklog #启动之前需要建好
clientPort=2181
autopurge.purgeInterval=24
autopurge.snapRetainCount=3
server.1=192.168.1.1:2888:3888启动
bin/zkServer.sh start
然后
bin/zkServer.sh status
查看状态。一定要查看。启动的时候不论如何都会输出成功解压kafka文件夹。进入config文件夹
修改 server.propertiesauto.create.topics.enable=true #配置自动创建topic
delete.topic.enable=true #是否允许删除主题
broker.id=0 #集群中唯一
listeners=PLAINTEXT://192.168.1.1:9092 #不要填localhost:9092 ,localhost表示只能通过本机连接,可以设置为0.0.0.0或本地局域网地址,server接受客户端连接的端口
num.network.threads=4 #broker处理消息的最大线程数,一般情况下数量为cpu核数
num.io.threads=8 #broker处理磁盘IO的线程数,数值为cpu核数2倍
socket.send.buffer.bytes=1024000 #socket的发送缓冲区 不要太小 避免频繁操作
socket.receive.buffer.bytes=1024000 # 接收缓冲区 不要太小
socket.request.max.bytes=1048576000 #socket请求的最大数值 message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
log.dirs=/data/kafkalog #kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。
num.partitions=2 #为1的时候不能自动创建topic,创建topic的默认分区数
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000 #和下面的一起,一些日志存储的配置,默认不清理日志
log.flush.interval.ms=1000
log.retention.hours=24 #每个日志文件删除之前保存的时间。默认数据保存时间对所有topic都一样
log.roll.hours=12
log.cleanup.policy=delete
log.retention.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.1:2181#zookeeper如果是集群,连接方式为 hostname1:port1, hostname2:port2, hostname3:port3
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
初次启动可以不后台
bin/kafka-server-start.sh -daemon config/server.properties
没问题就放后台
bin/kafka-server-start.sh -daemon config/server.properties
5、Kafka核心概念之Topic
在Kafka中,Topic是一个非常重要的概念,topic可以实现消息的分类,不同消费者订阅不同的topic
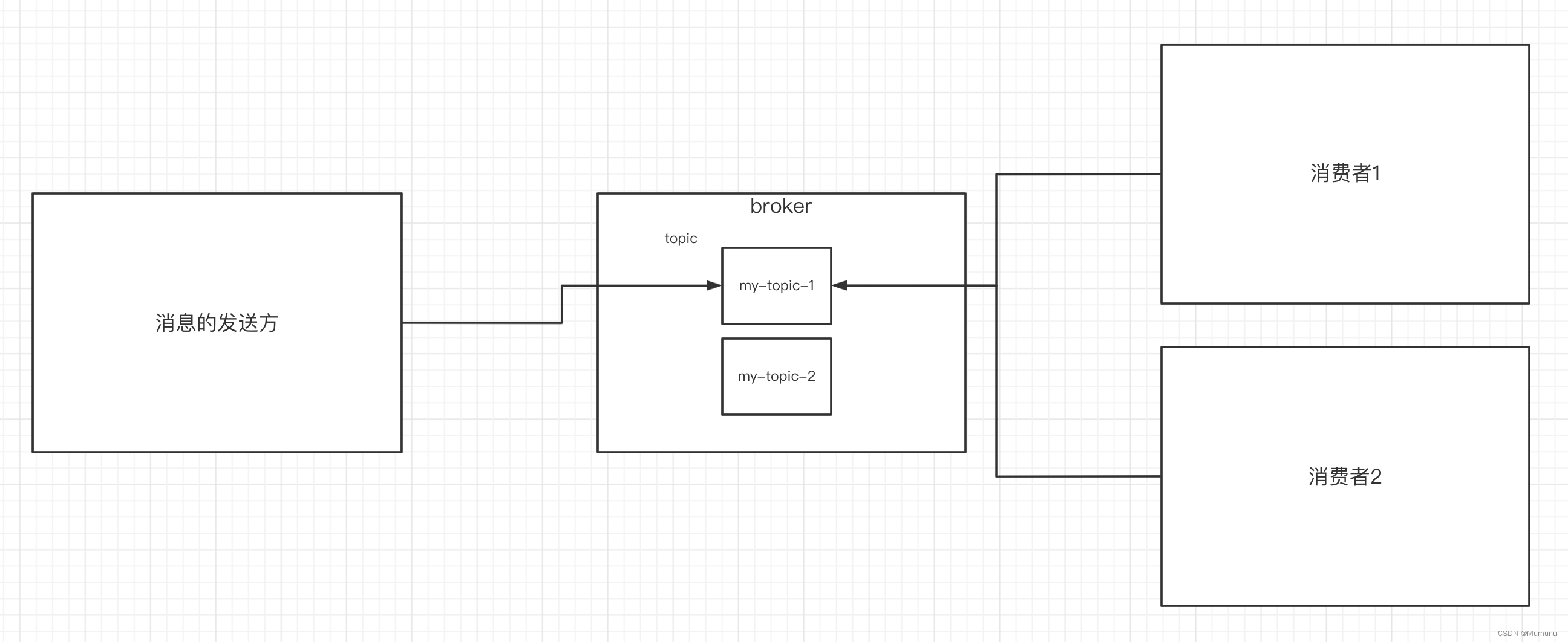
partition(分区)是kafka的一个核心概念,kafka将1个topic分成了一个或多个分区,每个分区在物理上对应一个目录
分区目录下存储的是该分区的日志段(segment),包括日志的数据文件和两个索引文件
执行以下命令创建名为test的topic,这个topic只有一个partition,并且备份因子也设置为1:
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --partitions 1查看当前kafka内有哪些topic
./kafka-topics.sh --bootstrap-server localhost:9092 --list kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。
在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址和topic
./kafka-console-producer.sh --broker-list localhost:9092 --topic test对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输出,默认是消费最新的消息。使用kafka的消费者消息的客户端,从指定kafka服务器的指定topic中消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
方式二:从头开始消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test几个注意点:
- 消息会被存储
- 消息是顺序存储
- 消息是有偏移量的
- 消费时可以指明偏移量进行消费
在上面我们展示了两种不同的消费方式,根据偏移量消费和从头开始消费,其实这个偏移量可以我们自己进行维护
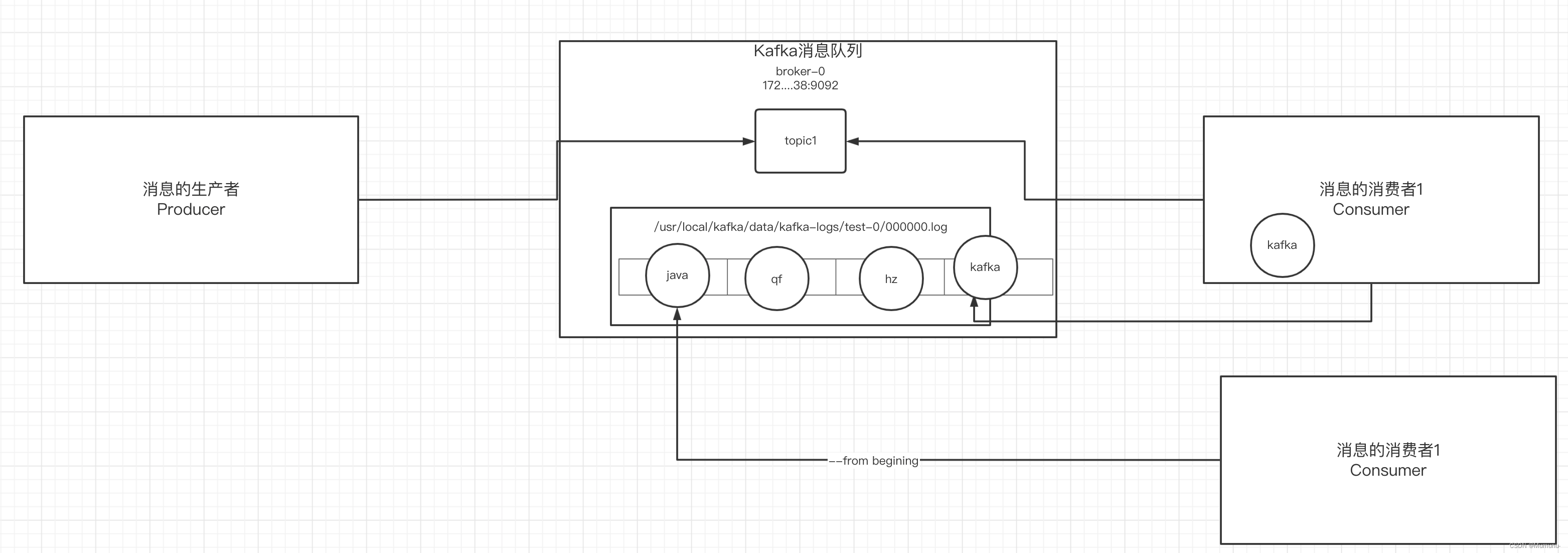
我们进入我们在server.properties里面配置的日志文件地址/data/kafkalog
我们可以看到默认一共有五十个偏移量地址,里面就记录了当前消费的偏移量。
我们先关注test-0这个文件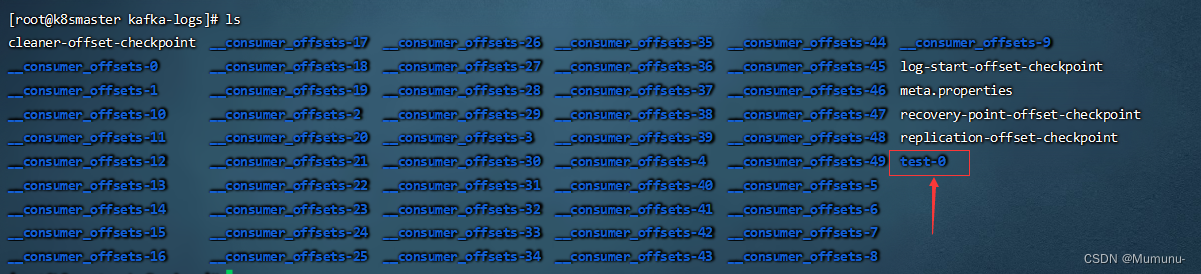
我们进入这个 文件,可以看到其中有个log文件,里面就保存了
文件,可以看到其中有个log文件,里面就保存了Topic发送的数据
生产者将消息发送给broker,broker会将消息保存在本地的日志文件中
/data/kafkalog/主题-分区/00000000.log-
消息的保存是有序的,通过
offset偏移量来描述消息的有序性 -
消费者消费消息时也是通过offset来描述当前要消费的那条消息的位置
6、 单播消息
我们现在假设有一个场景,有一个生产者,两个消费者,问:生产者发送消息,是否会同时被两个消费者消费?
创建一个topic
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test2 --partitions 1
创建一个生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic test2
分别在两个终端上面创建两个消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test2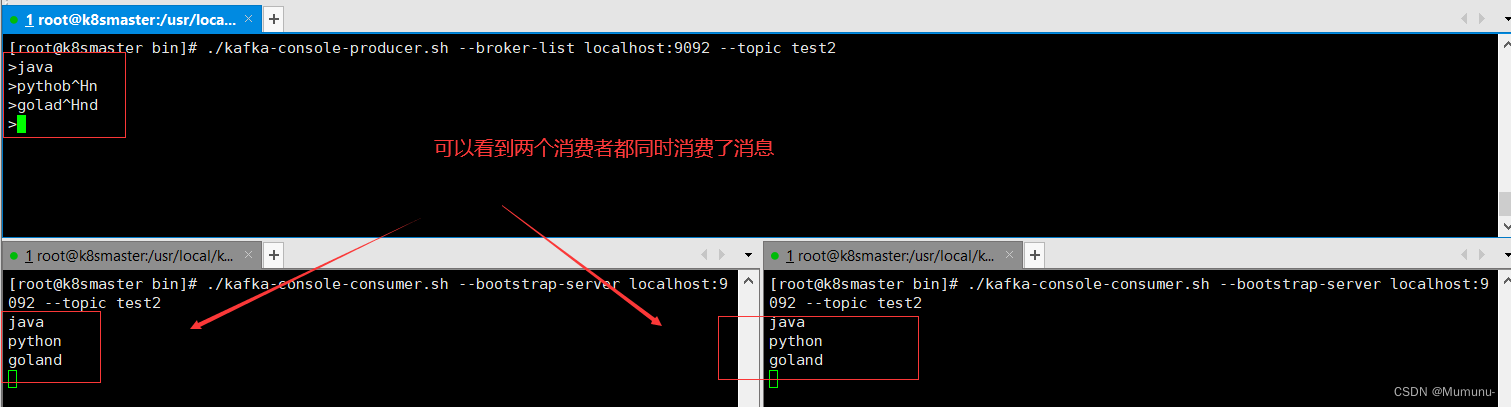
这里就要引申出一个概念:消费组,当我们配置多个消费者在一个消费组里面的时候,其实只会有一个消费者进行消费
这样其实才符合常理,毕竟一条消息被消费一次就够了
我们可以通过命令--consumer-property group.id=testGroup在设置消费者时将其划分到一个消费组里面
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test2
这个时候,如果消费组里面有一个消费者挂掉了,就会由其他消费者来进行消费

小结一下:两个消费者在同一个组,只有一个能接到消息,两个在不同组或者未指定组则都能收到
7、多播消息
当多个消费组同时订阅一个Topic时,那么不同的消费组中只有一个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同一个消息
// 消费组1
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup1 --topic test2
// 消费组2
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup2 --topic test2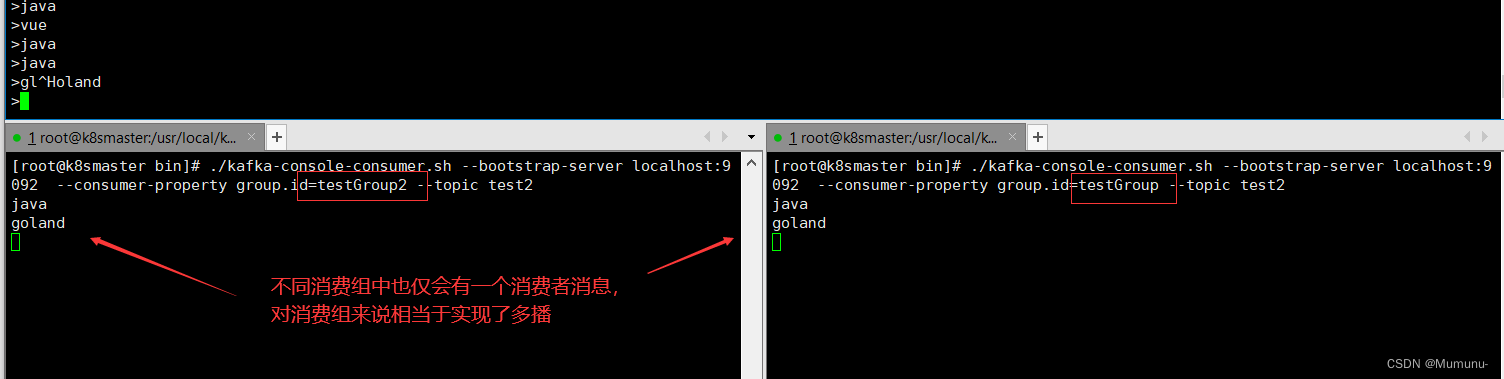

8、查看消费组的详细信息
通过以下命令可以查看到消费组的详细信息:
# 查看当前所有的消费组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 查看指定消费组具体信息,比如当前偏移量、最后一条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup
9、创建分区
我们在上面已经了解了Topic与Partition的概念,现在我们可以通过以下命令给一个topic创建多个分区
# 创建两个分区的主题
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test3 --partitions 2
# 查看下创建的topic
./kafka-topics.sh --bootstrap-server localhost:9092 --list
现在我们再进到日志文件中看一眼,可以看到日志是以分区来命名的

我们知道分区文件中
00000.log: 这个文件中保存的就是消息
__consumer_offsets-49:
kafka内部自己创建了__consumer_offsets主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量。因为每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题:consumer_offsets。
因此kafka为了提升这个主题的并发性,默认设置了50个分区。
提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets主题的分区数
提交到该主题中的内容是:key是consumerGroupId + topic + 分区号,value就是当前offset的值
文件中保存的消息,根据log.retention.hour这个参数确定。到期后消息会被删除。
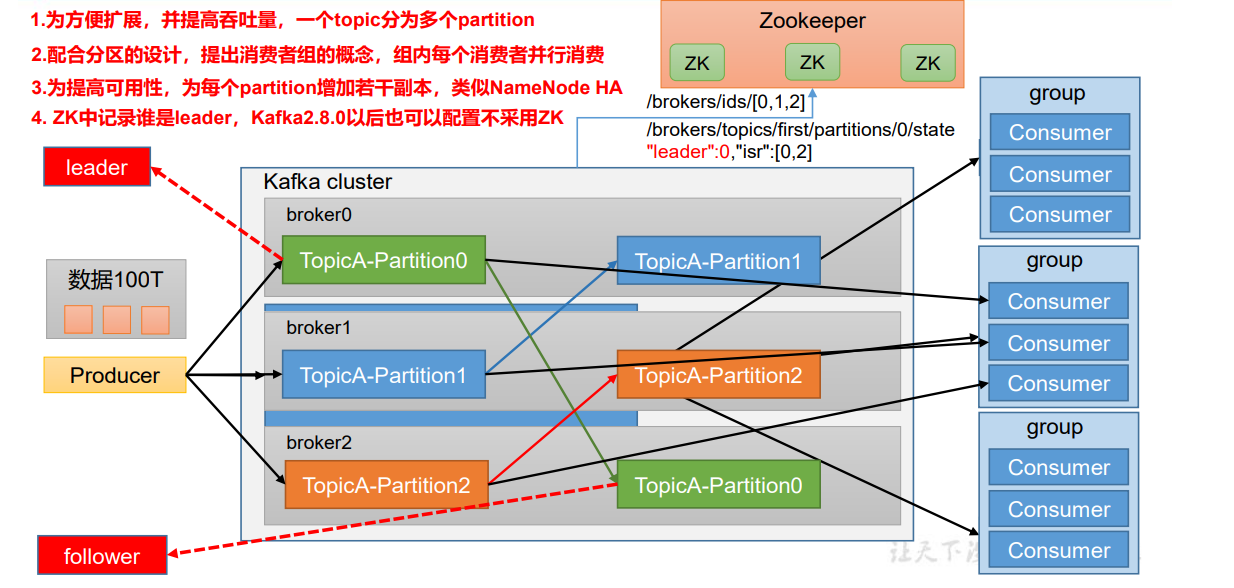
10、副本的概念
在创建主题时,除了指明了主题的分区数以外,还指明了副本数,那么副本是一个什么概念呢?
我们现在创建一个主题、两个分区、三个副本的topic(注意:副本只有在集群下才有意义)
./kafka-topics.sh \
--bootstrap-server localhost:9092 \ # 指定启动的机器
--create --topic my-replicated-topic \ # 创建一个topic
--partitions 2 \ # 设置分区数为2
--replication-factor 3 # 设置副本数为3
# 查看topic情况
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic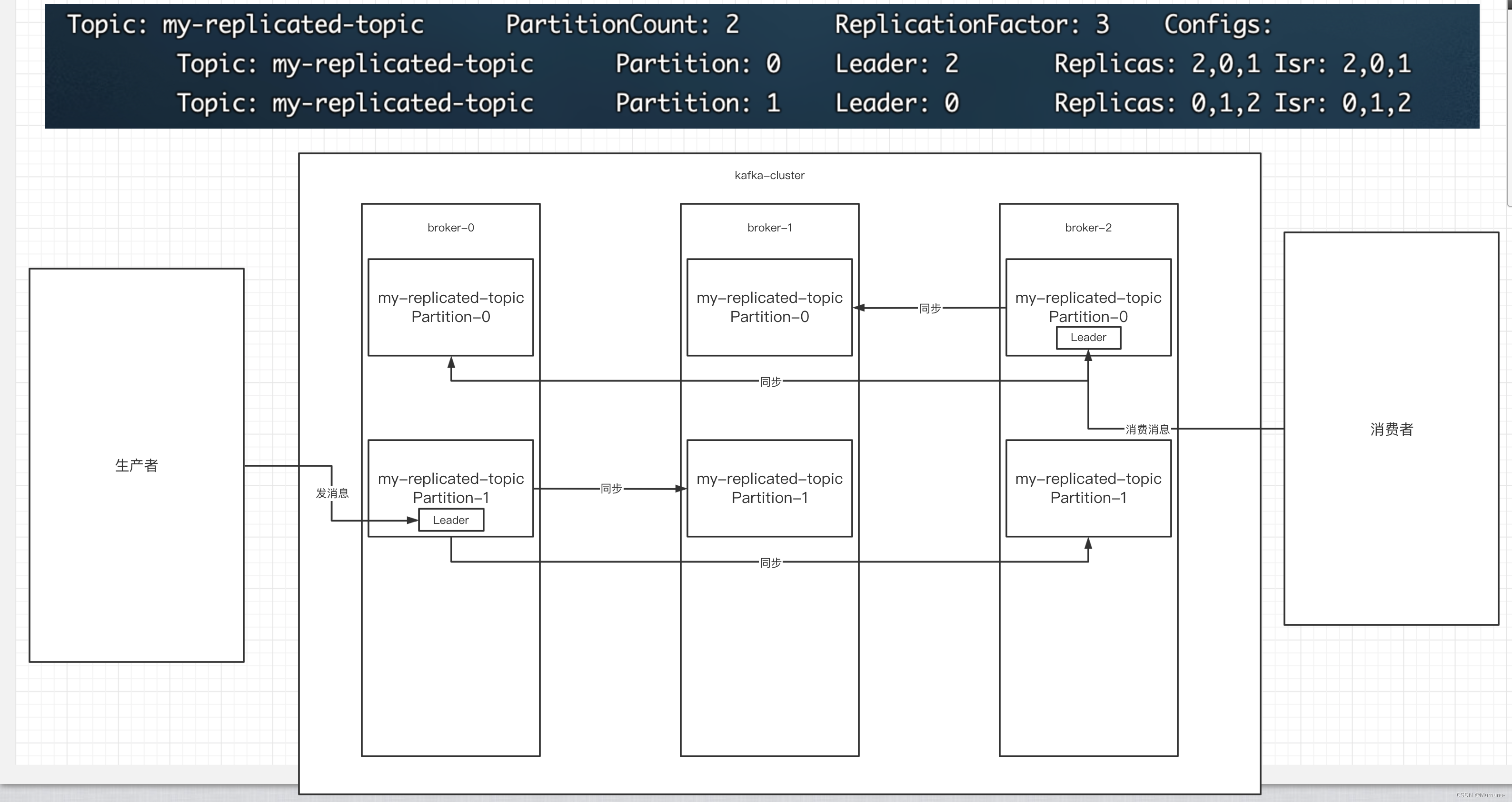
leader
kafka的写和读的操作,都发生在leader上。leader负责把数据同步给follower。当leader挂了,经过主从选举,从多个follower中选举产生一个新的leader
follower
接收leader的同步的数据
isr
可以同步和已同步的节点会被存入到isr集合中。这里有一个细节:如果isr中的节点性能较差,会被提出isr集合。
此时,broker、主题、分区、副本 这些概念就全部展现了
- 集群中有多个broker
- 创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储)
- 可以为分区创建多个副本,不同的副本存放在不同的broker里
11、集群消费
向集群发送消息
./kafka-console-producer.sh --broker-list node1:9092,node1:9093,node1:9094 --topic my-replicated-topic从集群中消费消息
./kafka-console-consumer.sh --bootstrap-server liang:9092,dd1:9092,dd2:9092 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic指定消费组来消费消息
./kafka-console-consumer.sh --bootstrap-server node1:9092,node1:9093,node1:9094 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
这里有一个细节,结合上面的单播消息我们很容易可以想到下面的这种情况,因为一个Partition只能被一个consumer Group里面的一个consumer,所有很容易就可以形成组内单播的现象,即:多Partition与多consumer一一对应
这样的好处是:分区存储,可以解决一个topic中文件过大无法存储的问题
提高了读写的吞吐量,读写可以在多个分区中同时进行
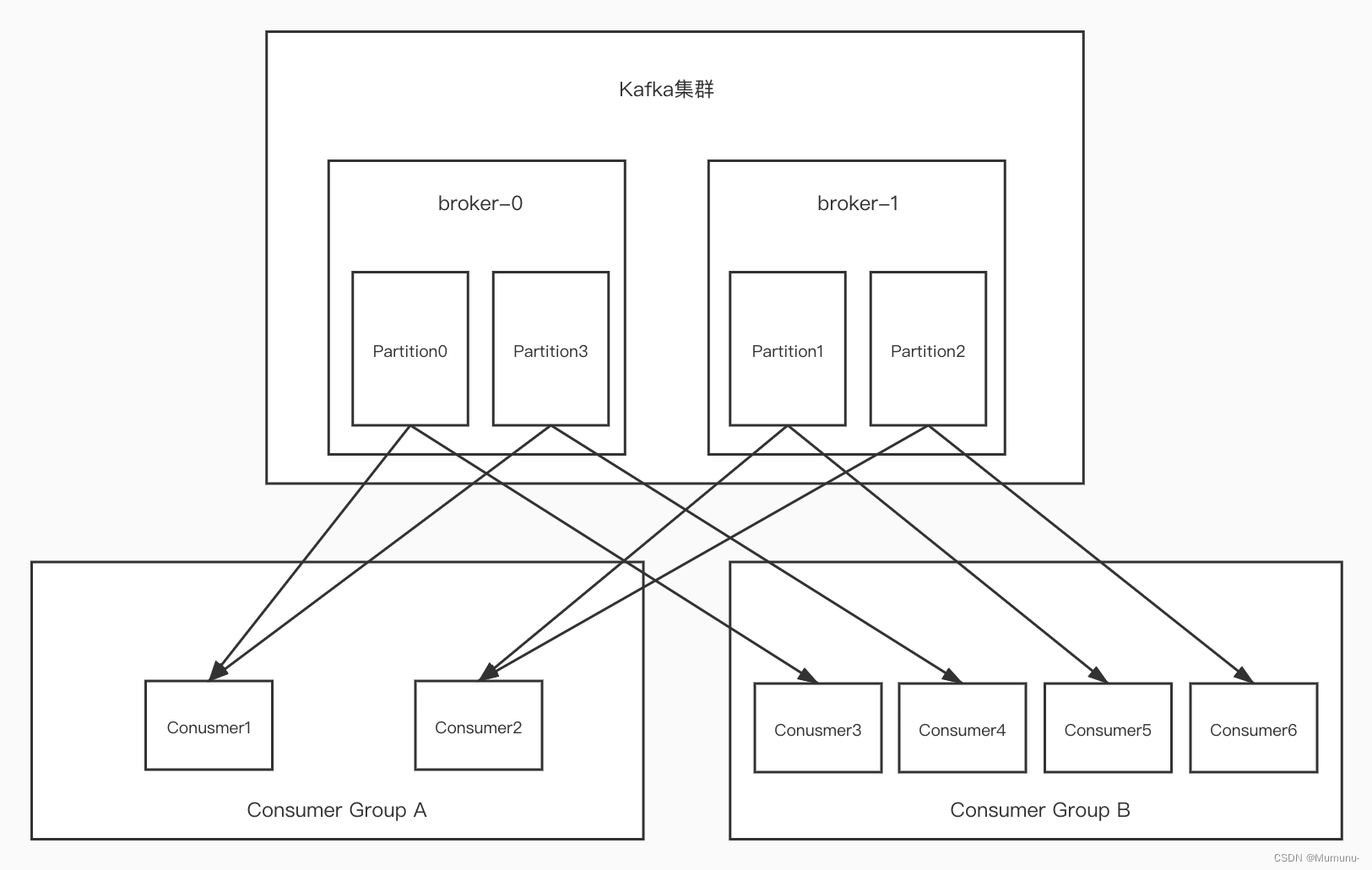
Kafka这种通过分区与分组进行并行消费的方式,让kafka拥有极大的吞吐量
小结一下:
一个partition只能被一个消费组中的一个消费者消费,目的是为了保证消费的顺序性,但是多个partion的多个消费者消费的总的顺序性是得不到保证的,那怎么做到消费的总顺序性呢?这个后面揭晓答案
partition的数量决定了消费组中消费者的数量,建议同一个消费组中消费者的数量不要超过partition的数量,否则多的消费者消费不到消息
如果消费者挂了,那么会触发rebalance机制(后面介绍),会让其他消费者来消费该分区
kafka通过partition 可以保证每条消息的原子性,但是不会保证每条消息的顺序性
12、生产者核心概念
在消息发送的过程中,涉及到了两个线程
main 线程
Sender 线程
在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker
在main线程中,消息的生产,要经历拦截器、序列化器和分区器,其中一个分区就会创建一个队列,这样方便数据的管理
其中队列默认是32M,而存放到队列里面的数据也会经过压缩为16k再发往send线程进行发送,但是这样也会有问题,就是如果只有一条消息,难道就不发送了吗?其实还有一个参数linger.ms,用来表示一条消息如果超过这个时间就会直接发送,不用管大小,其实可以类比坐车的场景,人满或者时间到了 都发车
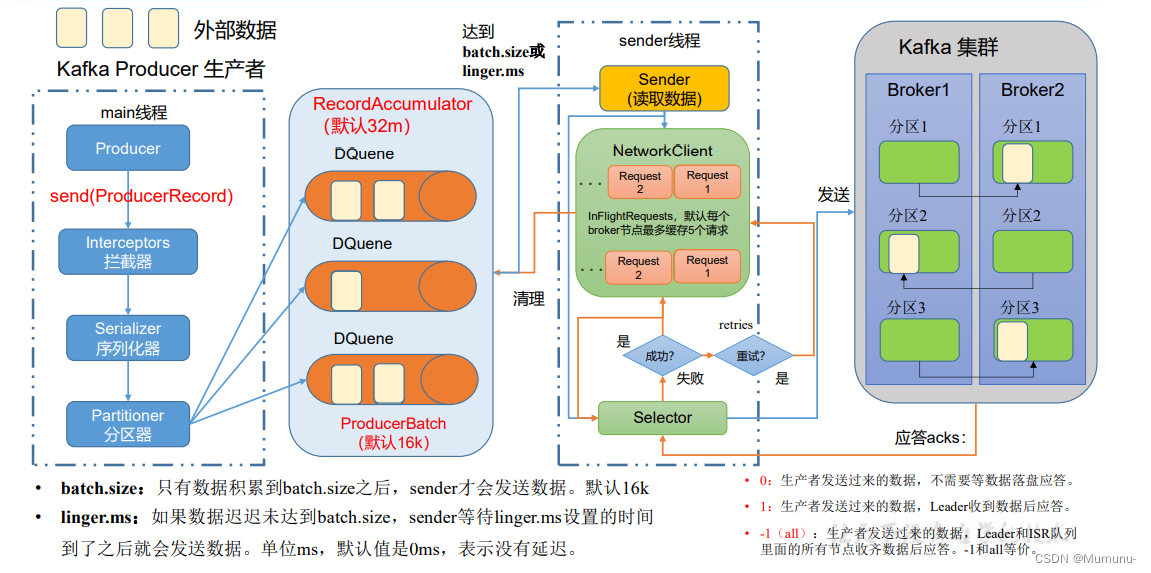
send线程发送给kafka集群的时候,我们需要联系到上面的Topic与Partition已经消费组,形成一个Partition对应consumer Group里面的一个consumer这种组内单播的效果,进行并发读写
13、ack的概念
在同步发送的前提下,生产者在获得集群返回的ack之前会一直阻塞。那么集群什么时候返回ack呢?此时ack有3个配置:
ack = 0 kafka-cluster不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息的,效率是最高的
ack=1(默认): 多副本之间的leader已经收到消息,并把消息写入到本地的log中,才会返回ack给生产者,性能和安全性是最均衡的s
ack=-1/all。里面有默认的配置min.insync.replicas=2(默认为1,推荐配置大于等于2),此时就需要leader和一个follower同步完后,才会返回ack给生产者(此时集群中有2个broker已完成数据的接收),这种方式最安全,但性能最差。
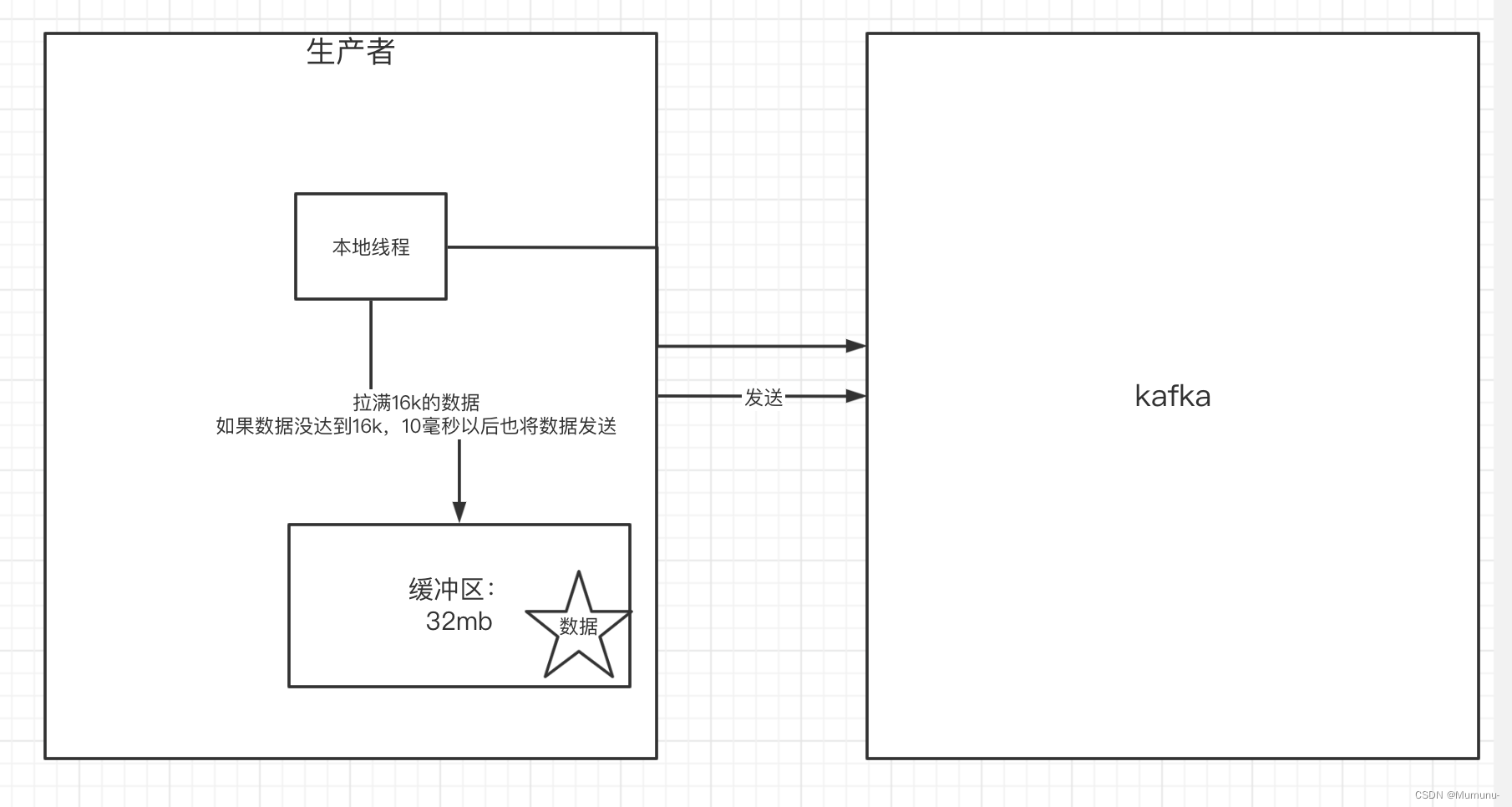
- kafka默认会创建一个消息缓冲区,用来存放要发送的消息,缓冲区是32m
- kafka本地线程会去缓冲区中一次拉16k的数据,发送到broker
- 如果线程拉不到16k的数据,间隔10ms也会将已拉到的数据发到broker
13、kafka集群中的controller、rebalance、HW
什么是controller呢?其实就是集群中的一个broker,当集群中的leader挂掉时需要controller来组织进行选举
那么集群中谁来充当controller呢?
每个broker启动时会向zk创建一个临时序号节点,获得的序号最小的那个broker将会作为集群中的controller,负责这么几件事:
当集群中有一个副本的leader挂掉,需要在集群中选举出一个新的leader,选举的规则是从isr集合中最左边获得
当集群中有broker新增或减少,controller会同步信息给其他broker
当集群中有分区新增或减少,controller会同步信息给其他broker
rebalance机制
前提:消费组中的消费者没有指明分区来消费
触发的条件:当消费组中的消费者和分区的关系发生变化的时候
分区分配的策略:在rebalance之前,分区怎么分配会有这么三种策略
range:根据公式计算得到每个消费者消费哪几个分区:第一个消费者是(分区总数 / 消费者数量 )+1,之后的消费者是分区总数/消费者数量(假设 n=分区数/消费者数量 = 2, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区)
轮询:大家轮着来
sticky:粘合策略,如果需要rebalance,会在之前已分配的基础上调整,不会改变之前的分配情况。如果这个策略没有开,那么就要进行全部的重新分配。建议开启
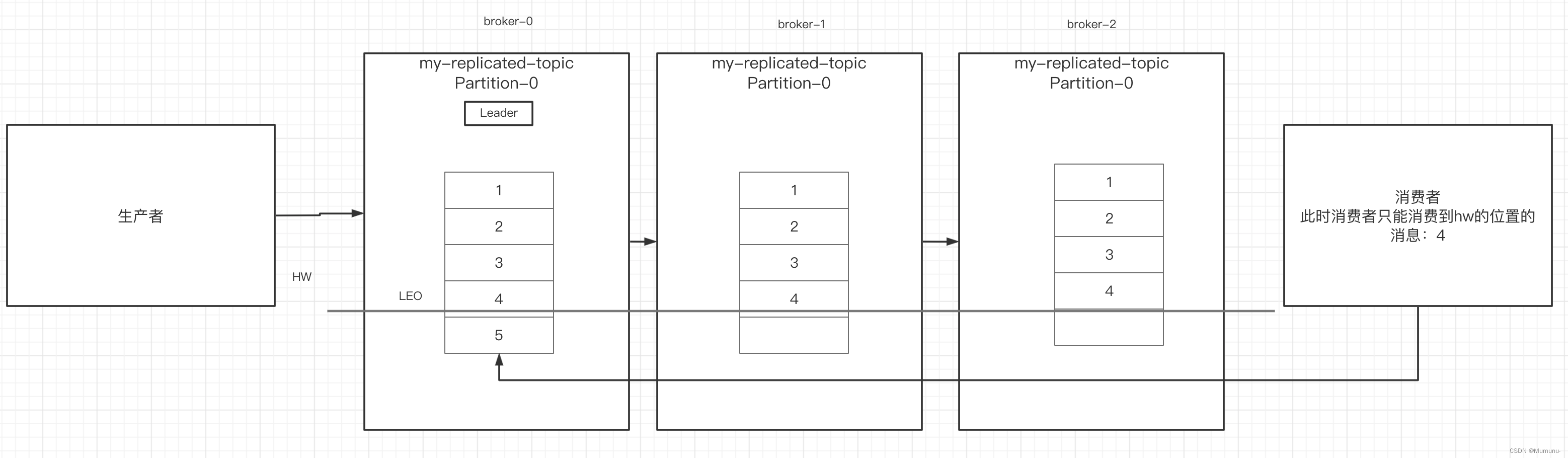
HW和LEO
LEO是某个副本最后消息的消息位置(log-end-offset)
HW是已完成同步的位置。消息在写入broker时,且每个broker完成这条消息的同步后,hw才会变化。在这之前消费者是消费不到这条消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的目的是防止消息的丢失。
14、Kafka中的优化问题
如何防止消息丢失
生产者:
1)使用同步发送
2)把ack设成1或者all,并且设置同步的分区数>=2
消费者:把自动提交改成手动提交
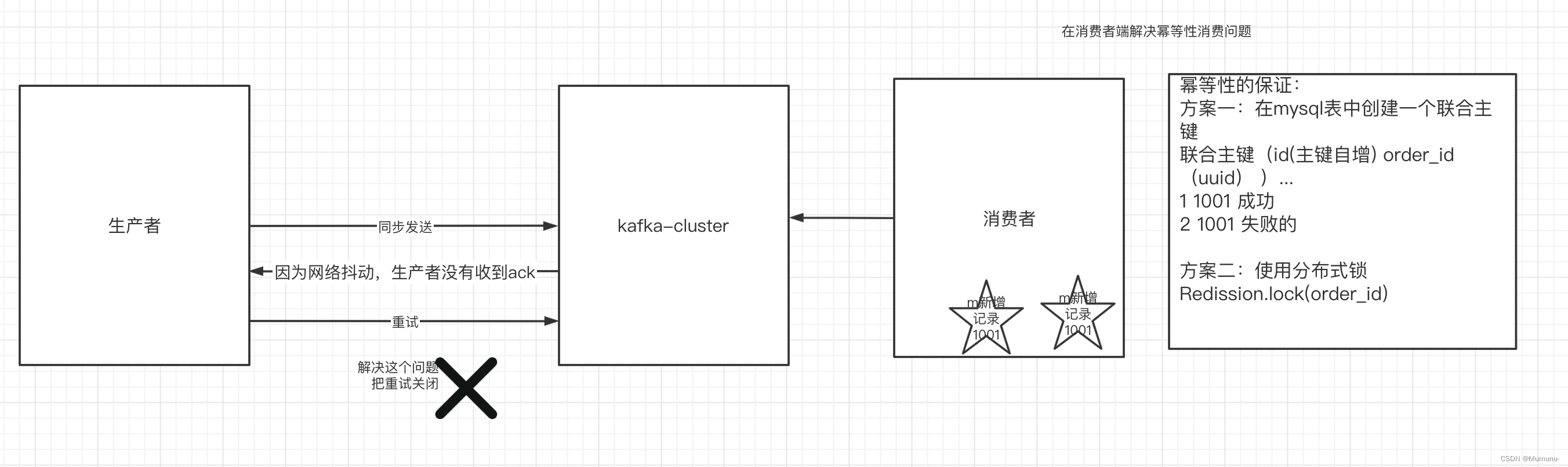
如何防止重复消费
在防止消息丢失的方案中,如果生产者发送完消息后,因为网络抖动,没有收到ack,但实际上broker已经收到了。
此时生产者会进行重试,于是broker就会收到多条相同的消息,而造成消费者的重复消费。
怎么解决:
生产者关闭重试:会造成丢消息(不建议)
消费者解决非幂等性消费问题:
所谓的幂等性:多次访问的结果是一样的。对于rest的请求(get(幂等)、post(非幂等)、put(幂等)、delete(幂等))
解决方案:
在数据库中创建联合主键,防止相同的主键 创建出多条记录
使用分布式锁,以业务id为锁。保证只有一条记录能够创建成功
如何做到消息的顺序消费
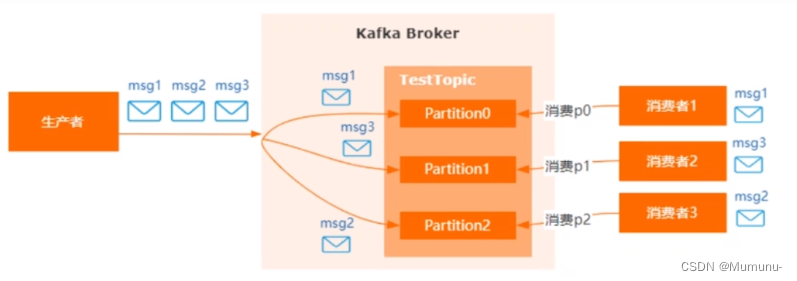
其实我们知道在发送消息的时候我们可以通过设置key来指定发送的分区,所以首先我们一定要指定key然后发到同一个分区
生产者:使用同步的发送,并且通过设置key指定路由策略,只发送到一个分区中;ack设置成非0的值。
消费者:主题只能设置一个分区,消费组中只能有一个消费者;不要设置异步线程防止异步导致的乱序,或者设置一个阻塞队列进行异步消费
kafka的顺序消费使用场景不多,因为牺牲掉了性能,但是比如rocketmq在这一块有专门的功能已设计好。
如何解决消息积压问题
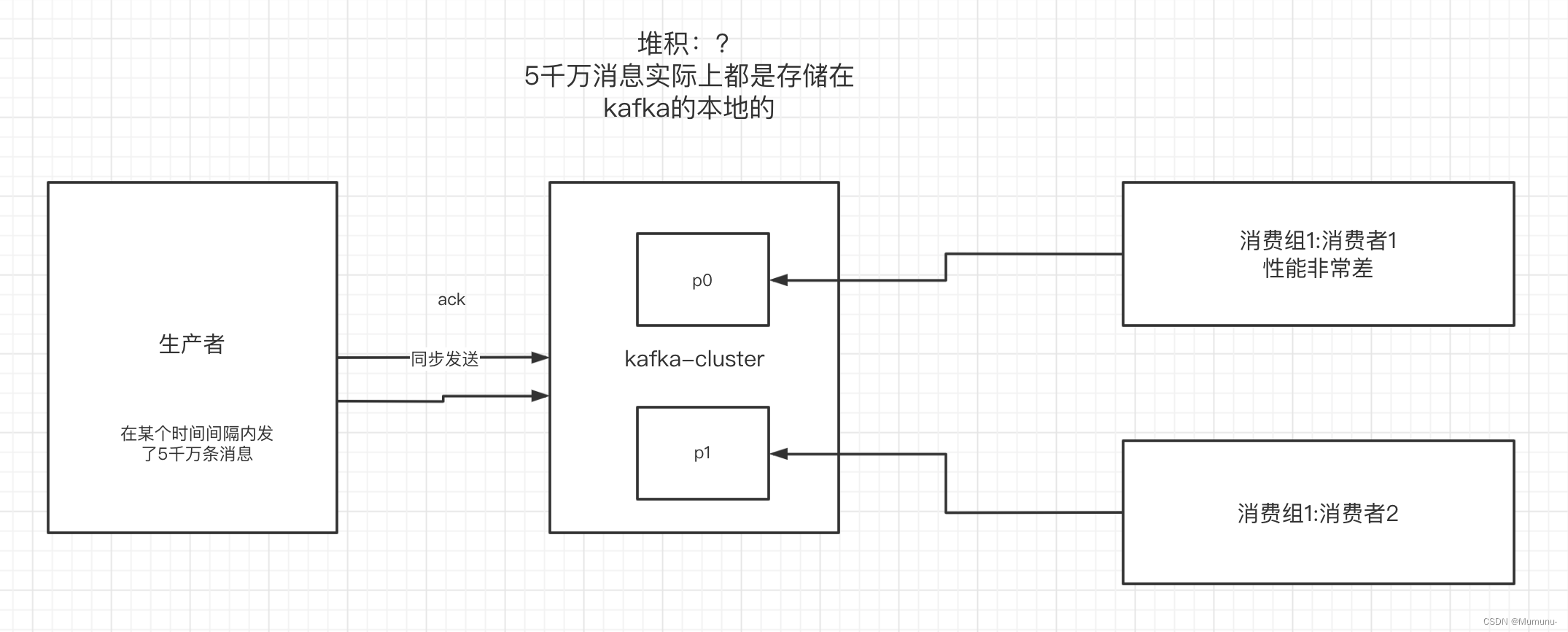
1)消息积压问题的出现
消息的消费者的消费速度远赶不上生产者的生产消息的速度,导致kafka中有大量的数据没有被消费。随着没有被消费的数据堆积越多,消费者寻址的性能会越来越差,最后导致整个kafka对外提供的服务的性能很差,从而造成其他服务也访问速度变慢,造成服务雪崩。
2)消息积压的解决方案
在这个消费者中,使用多线程,充分利用机器的性能进行消费消息。
通过业务的架构设计,提升业务层面消费的性能。
创建多个消费组,多个消费者,部署到其他机器上,一起消费,提高消费者的消费速度
创建一个消费者,该消费者在kafka另建一个主题,配上多个分区,多个分区再配上多个消费者。该消费者将poll下来的消息,不进行消费,直接转发到新建的主题上。此时,新的主题的多个分区的多个消费者就开始一起消费了。——不常用
实现延时队列的效果
1)应用场景
订单创建后,超过30分钟没有支付,则需要取消订单,这种场景可以通过延时队列来实现
2)具体方案
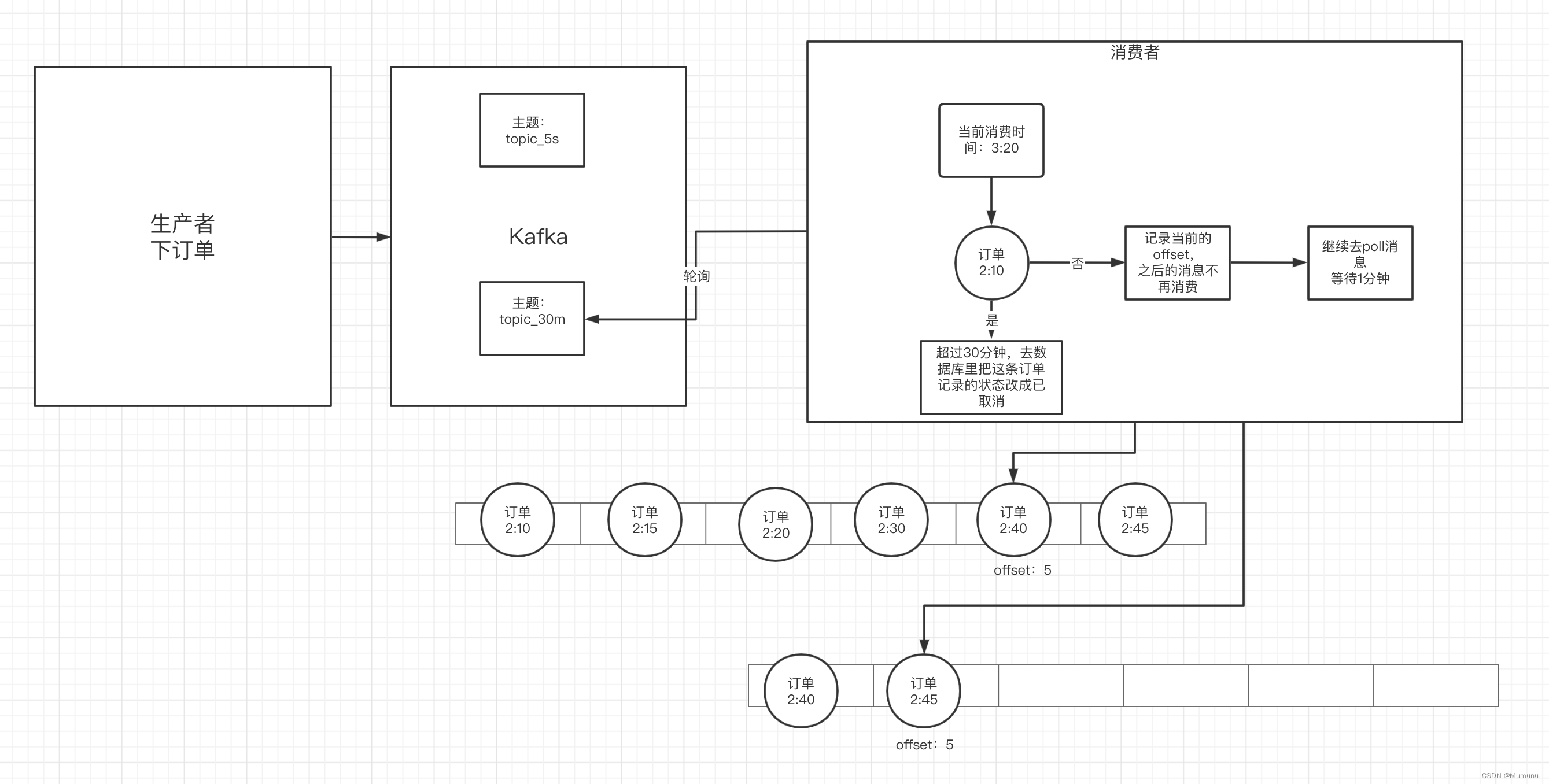
kafka中创建创建相应的主题
消费者消费该主题的消息(轮询)
消费者消费消息时判断消息的创建时间和当前时间是否超过30分钟(前提是订单没支付)
如果是:去数据库中修改订单状态为已取消
如果否:记录当前消息的offset,并不再继续消费之后的消息。等待1分钟后,再次向kafka拉取该offset及之后的消息,继续进行判断,以此反复。
相关文章:
深入理解Kafka3.6.0的核心概念,搭建与使用
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景&a…...

【python】编程题小代码
空心题(平行四边形) layer int(input("请输入你要打印的行数:")) for i in range(1,layer // 2 2): space_num layer - i for j in range(0,space_num): print(" ",end "") star_num 2 * i - 1 for j in range(0,sta…...

抖音小程序开发全攻略:如何规划项目和选择合适的开发团队
在数字化时代,抖音小程序成为企业推广和服务的重要渠道。本文将为您提供抖音小程序开发的全面攻略,重点介绍如何规划项目和选择合适的开发团队,并附有一些关键的技术代码示例。 1. 项目规划 在开始抖音小程序开发之前,详细的项…...
PSP - 蛋白质复合物结构预测 模版配对(Template Pair) 逻辑的特征分析
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134328447 在 蛋白质复合物结构预测 的过程中,模版 (Template) 起到重要作用,提供预测结果的关于三维结构的先验信息&…...

喜报不断!箱讯平台获评2023年上海市促进现代航运服务业创新示范项目
近期,可谓捷报频传!在箱讯科技子公司苏州箱讯获评苏州市软件和信息服务业 “头雁”培育企业没过多久,就又迎来好消息! 日前,上海市交通委发布“2023年上海市促进现代航运服务业创新项目”评选结果,箱讯An…...
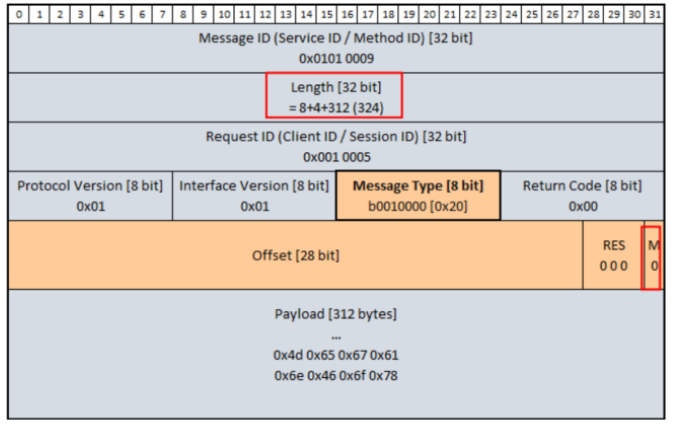
SOME/IP学习笔记3
目录 1.SOMEIP Transformer 1.1 SOME/IP on-wire format 1.2 协议指定 2. SOMEIP TP 2.1 SOME/IP TP Header 3.小结 1.SOMEIP Transformer 根据autosar CP 相关规范,SOME/IP Transformer主要用于将SOME/IP格式的数据序列化,相当于一个转换器。总体…...

【ATTCK】ATTCK开源项目Caldera学习笔记
CALDERA是一个由python语言编写的红蓝对抗工具(攻击模拟工具)。它是MITRE公司发起的一个研究项目,该工具的攻击流程是建立在ATT&CK攻击行为模型和知识库之上的,能够较真实地APT攻击行为模式。 通过CALDERA工具,安全…...

黑窗口连接远程服务
ssh root192.168.x.x 回车输入密码 查看docker docker ps 停止正在运行的服务 docker stop xxxxx 删除服务 docker rm xxxxx 查看镜像 docker images 删除镜像 docker rmi xxxxx 删除镜像 启动并运行整个服务 docker compose up -d jar包名称 idea 使用tcp方式连接docker 配置d…...

好消息!2023年汉字小达人市级比赛在线模拟题大更新:4个组卷+11个专项,助力孩子更便捷、有效、有趣地备赛
自从《中文自修》杂志社昨天发通知,官宣了2023年第十届汉字小达人市级比赛的日期和安排后,各路学霸们闻风而动,在自己本就繁忙的日程中又加了一项:备赛汉字小达人市级比赛,11月30日,16点-18点。 根据这几年…...

SAP 70策略测试简介
在前面的文章中我们已经测试了10、11、20、40、50、52、60、62策略的测试,接下来我们需要对70策略进行测试,很多的项目中也都会用到70策略。 70策略是一种比较常见的、基于按库存且主要用于半成品或者原材料的计划策略。 我们还是按照之前的惯例,先看下70策略的后台配置 我…...
uniapp+vue3+ts+vite+echarts开发图表类小程序,将echarts导入项目使用的详细步骤,耗时一天终于弄好了
想在uniapp和vue3环境中使用echarts是一件相当前卫的事情,官方适配的还不是很好,echarts的使用插件写的是有些不太清晰的,这里我花费了一天的时间,终于将这个使用步骤搞清楚了,并且建了一个仓库,大家可以直…...

分布式服务器架构的优点有哪些?
在当今数字化时代,随着互联网的普及和技术的不断进步,企业和组织面临着处理越来越多的数据和用户请求的挑战。为了应对这些挑战,分布式服务器架构应运而生。分布式服务器架构通过将任务和数据分散到多个服务器上,提供了许多优点&a…...

Zephyr-7B论文解析及全量训练、Lora训练
文章目录 一、Zephyr:Direct Distillation of LM Alignment1.1 开发经过1.1.1 Zephyr-7B-alpha1.1.2 Zephyr-7B-beta 1.2 摘要1.3 相关工作1.4 算法1.4.1 蒸馏监督微调(dSFT)1.4.2 基于偏好的AI反馈 (AIF)1.4.3 直接蒸馏偏好优化&…...
如何使用群晖虚拟机部署本地网页文件实现公网远程访问?
文章目录 前言1. 安装网页运行环境1.1 安装php1.2 安装webstation 2. 下载网页源码文件2.1 访问网站地址并下载压缩包2.2 解压并上传至群辉NAS 3. 配置webstation3.1 配置网页服务3.2 配置网络门户 4. 局域网访问静态网页配置成功5. 使用cpolar发布静态网页,实现公网…...
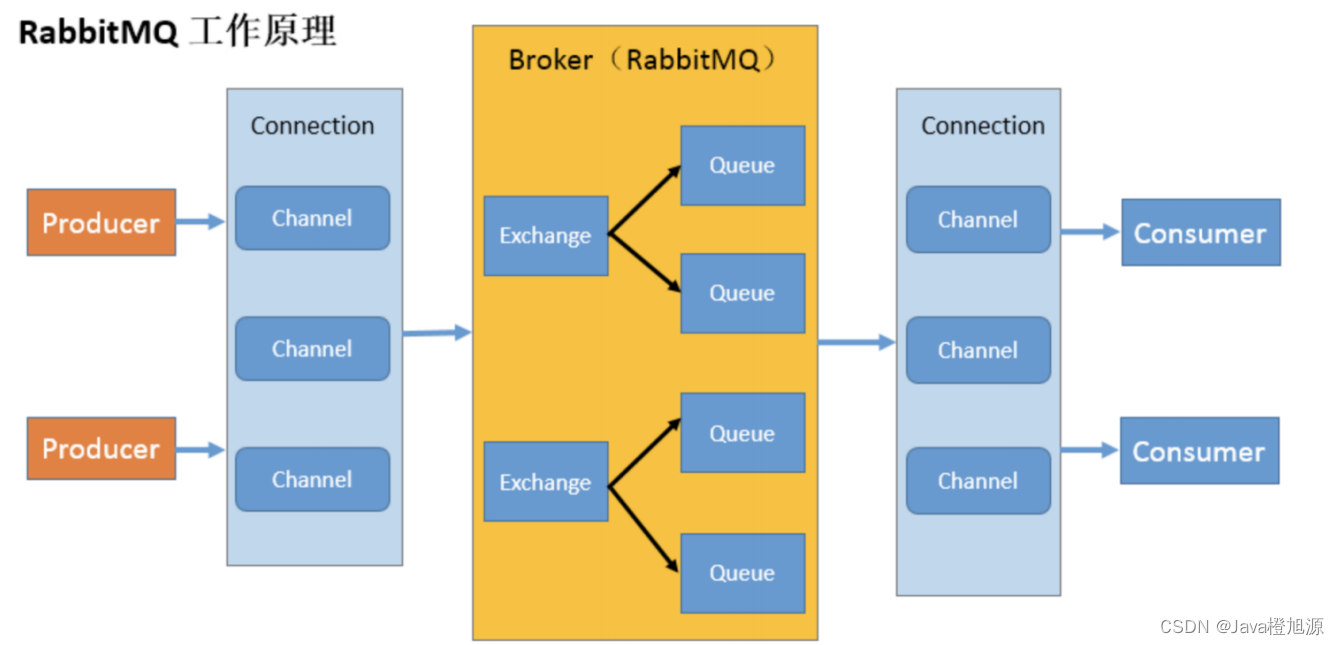
初识RabbitMQ - 安装 - 搭建基础环境
RabbitMQ 各个名词介绍 Broker:接收和分发消息的应用,RabbitMQ Server 就是 Message Broker Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当…...

C/C++ #运算符、##运算符、变参宏 ...和_ _VA_ARGS_ _
文章目录 用宏参数创建字符串:#运算符函数宏#号作为一个预处理运算符,可以把记号转换成字符串 预处理器粘合剂:##运算符变参宏:...和_ _VA_ARGS_ _参考 用宏参数创建字符串:#运算符 函数宏 下面是一个类函数宏&#…...

【全网首发】【Python】Python控制parrot ARDrone 2.0无人机
🎉欢迎来到Python专栏~Python控制parrot ARDrone 2.0无人机 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:Python学习专栏 文章作者技术和水平有限,如果文中出现错误…...
DPU国产生态版图又双叒扩大了
DPU朋友圈迎来30新伙伴!近期,中科驭数已与联想、中科可控、统信、欧拉、龙蜥社区、新支点、亚信科技、人大金仓、瀚高、南大通用、GreatSQL、阿里云、曙光云等超30家关键厂商完成兼容性互认证。测试报告显示,中科驭数DPU系列产品在产品兼容性…...

YOLOv5算法进阶改进(3)— 引入深度可分离卷积C3模块 | 轻量化网络
前言:Hello大家好,我是小哥谈。深度可分离卷积是一种卷积神经网络中的卷积操作,它可以将标准卷积分解为两个较小的卷积操作:深度卷积和逐点卷积。深度卷积是在每个输入通道上分别执行卷积,而逐点卷积是在所有通道上执行卷积。这种分解可以大大减少计算量和参数数量,从而提…...

Linux的root用户
拥有最大权限的用户名为root su和exit命令 su命令就是用于账户切换的系统命令Switch user 语法:su - [用户名] -符号可选,表示是否在切换用户后加载环境变量,建议带上 参数:用户名,表示要切换的用户,用…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...

机器学习势函数在高温超导材料缺陷与相变研究中的应用
1. 项目概述:当机器学习“遇见”高温超导的微观世界高温超导体,尤其是像YBa2Cu3O7(YBCO)这样的铜氧化物,一直是凝聚态物理和材料科学领域的“明星”材料。它们能在相对较高的温度下实现零电阻,为能源传输、…...

You-Get下载视频音画不同步?可能是FFmpeg路径没配对!附Mac/Linux/Windows三平台配置指南
You-Get跨平台音视频同步解决方案:FFmpeg环境配置全指南 当你在Mac上流畅使用you-get下载合并好的视频,切换到Windows却遭遇音画分离的尴尬时,问题往往出在FFmpeg的环境配置上。本文将带你深入理解多平台下FFmpeg的配置差异,并提…...

代码跑偏白盒补漏:判定节点覆盖全路径测试
位于程序逻辑分叉处,起着关键开通作用的判定节点,意义无比重大。于程序运行进程里,每一条if语句、else语句以及switch语句背后,事实上都暗藏着一条独具特色且彼此独立的执行回路。而测试覆盖的核心使命,就是要把这些回…...

后端开发者体验 AI 前端:用 TinyVue 做一个智能业务表单 Demo
摘要 作为 Java 后端开发者,我平时更多关注接口、SQL 和业务逻辑,但后台系统里也绕不开表单、列表和报表页面。本文结合 OpenTiny NEXT 学习体验,用 TinyVue 做一个智能业务表单 Demo,聊聊 AI 前端对后端开发者到底有没有实际帮助…...

Unity URP下缺失的MipMap可视化?手把手教你用Rendering Debugger和自定义Shader搞定
Unity URP下实现MipMap可视化的专业解决方案在Unity的URP(Universal Render Pipeline)环境中,纹理MipMap的调试一直是开发者面临的痛点。与Built-in管线不同,URP默认不提供直观的MipMap级别可视化工具,这使得性能优化过…...