划分VOC数据集,以及转换为划分后的COCO数据集格式
1.VOC数据集
LabelImg是一款广泛应用于图像标注的开源工具,主要用于构建目标检测模型所需的数据集。Visual Object Classes(VOC)数据集作为一种常见的目标检测数据集,通过labelimg工具在图像中标注边界框和类别标签,为训练模型提供了必要的注解信息。VOC数据集源于对PASCAL挑战赛的贡献,涵盖多个物体类别,成为目标检测领域的重要基准之一,推动着算法性能的不断提升。
使用labelimg标注或者其他VOC标注工具标注后,会得到两个文件夹,如下:
Annotations ------->>> 存放.xml标注信息文件
JPEGImages ------->>> 存放图片文件

2.划分VOC数据集
如下代码是按照训练集:验证集 = 8:2来划分的,会找出没有对应.xml的图片文件,且划分的时候支持JPEGImages文件夹下有如下图片格式:
['.jpg', '.png', '.gif', '.bmp', '.tiff', '.jpeg', '.webp', '.svg', '.psd', '.cr2', '.nef', '.dng']
整体代码为:
import os
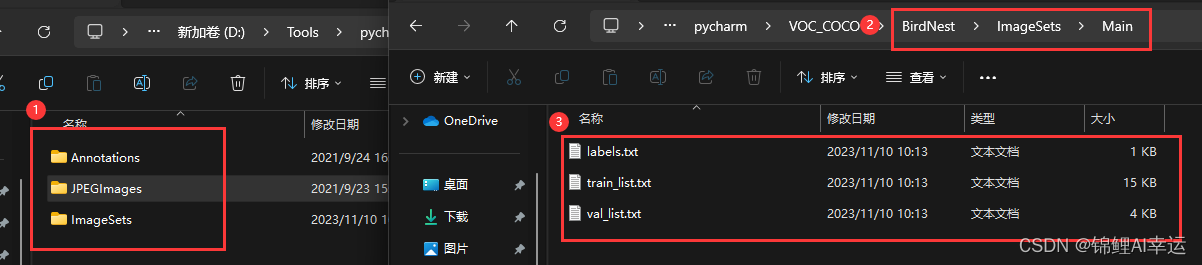
import randomimage_extensions = ['.jpg', '.png', '.gif', '.bmp', '.tiff', '.jpeg', '.webp', '.svg', '.psd', '.cr2', '.nef', '.dng']def split_voc_dataset(dataset_dir, train_ratio, val_ratio):if not (0 < train_ratio + val_ratio <= 1):print("Invalid ratio values. They should sum up to 1.")returnannotations_dir = os.path.join(dataset_dir, 'Annotations')images_dir = os.path.join(dataset_dir, 'JPEGImages')output_dir = os.path.join(dataset_dir, 'ImageSets/Main')if not os.path.exists(output_dir):os.makedirs(output_dir)dict_info = dict()# List all the image files in the JPEGImages directoryfor file in os.listdir(images_dir):if any(ext in file for ext in image_extensions):jpg_files, endwith = os.path.splitext(file)dict_info[jpg_files] = endwith# List all the XML files in the Annotations directoryxml_files = [file for file in os.listdir(annotations_dir) if file.endswith('.xml')]random.shuffle(xml_files)num_samples = len(xml_files)num_train = int(num_samples * train_ratio)num_val = int(num_samples * val_ratio)train_xml_files = xml_files[:num_train]val_xml_files = xml_files[num_train:num_train + num_val]with open(os.path.join(output_dir, 'train_list.txt'), 'w') as train_file:for xml_file in train_xml_files:image_name = os.path.splitext(xml_file)[0]if image_name in dict_info:image_path = os.path.join('JPEGImages', image_name + dict_info[image_name])annotation_path = os.path.join('Annotations', xml_file)train_file.write(f'{image_path} {annotation_path}\n')else:print(f"没有找到图片 {os.path.join(images_dir, image_name)}")with open(os.path.join(output_dir, 'val_list.txt'), 'w') as val_file:for xml_file in val_xml_files:image_name = os.path.splitext(xml_file)[0]if image_name in dict_info:image_path = os.path.join('JPEGImages', image_name + dict_info[image_name])annotation_path = os.path.join('Annotations', xml_file)val_file.write(f'{image_path} {annotation_path}\n')else:print(f"没有找到图片 {os.path.join(images_dir, image_name)}")labels = set()for xml_file in xml_files:annotation_path = os.path.join(annotations_dir, xml_file)with open(annotation_path, 'r') as f:lines = f.readlines()for line in lines:if '<name>' in line:label = line.strip().replace('<name>', '').replace('</name>', '')labels.add(label)with open(os.path.join(output_dir, 'labels.txt'), 'w') as labels_file:for label in labels:labels_file.write(f'{label}\n')if __name__ == "__main__":dataset_dir = 'BirdNest/'train_ratio = 0.8 # Adjust the train-validation split ratio as neededval_ratio = 0.2split_voc_dataset(dataset_dir, train_ratio, val_ratio)划分好后的截图:
3.VOC转COCO格式
目前很多框架大多支持的是COCO格式,因为存放与使用起来方便,采用了json文件来代替xml文件。
import json
import os
from xml.etree import ElementTree as ETdef parse_xml(dataset_dir, xml_file):xml_path = os.path.join(dataset_dir, xml_file)tree = ET.parse(xml_path)root = tree.getroot()objects = root.findall('object')annotations = []for obj in objects:bbox = obj.find('bndbox')xmin = int(bbox.find('xmin').text)ymin = int(bbox.find('ymin').text)xmax = int(bbox.find('xmax').text)ymax = int(bbox.find('ymax').text)# Extract label from XML annotationlabel = obj.find('name').textif not label:print(f"Label not found in XML annotation. Skipping annotation.")continueannotations.append({'xmin': xmin,'ymin': ymin,'xmax': xmax,'ymax': ymax,'label': label})return annotationsdef convert_to_coco_format(image_list_file, annotations_dir, output_json_file, dataset_dir):images = []annotations = []categories = []# Load labelswith open(os.path.join(os.path.dirname(image_list_file), 'labels.txt'), 'r') as labels_file:label_lines = labels_file.readlines()categories = [{'id': i + 1, 'name': label.strip()} for i, label in enumerate(label_lines)]# Load image list filewith open(image_list_file, 'r') as image_list:image_lines = image_list.readlines()for i, line in enumerate(image_lines):image_path, annotation_path = line.strip().split(' ')image_id = i + 1image_filename = os.path.basename(image_path)# Extract image size from XML filexml_path = os.path.join(dataset_dir, annotation_path)tree = ET.parse(xml_path)size = tree.find('size')image_height = int(size.find('height').text)image_width = int(size.find('width').text)images.append({'id': image_id,'file_name': image_filename,'height': image_height,'width': image_width,'license': None,'flickr_url': None,'coco_url': None,'date_captured': None})# Load annotations from XML filesxml_annotations = parse_xml(dataset_dir, annotation_path)for xml_annotation in xml_annotations:label = xml_annotation['label']category_id = next((cat['id'] for cat in categories if cat['name'] == label), None)if category_id is None:print(f"Label '{label}' not found in categories. Skipping annotation.")continuebbox = {'xmin': xml_annotation['xmin'],'ymin': xml_annotation['ymin'],'xmax': xml_annotation['xmax'],'ymax': xml_annotation['ymax']}annotations.append({'id': len(annotations) + 1,'image_id': image_id,'category_id': category_id,'bbox': [bbox['xmin'], bbox['ymin'], bbox['xmax'] - bbox['xmin'], bbox['ymax'] - bbox['ymin']],'area': (bbox['xmax'] - bbox['xmin']) * (bbox['ymax'] - bbox['ymin']),'segmentation': [],'iscrowd': 0})coco_data = {'images': images,'annotations': annotations,'categories': categories}with open(output_json_file, 'w') as json_file:json.dump(coco_data, json_file, indent=4)if __name__ == "__main__":# 根据需要调整路径dataset_dir = 'BirdNest/'image_sets_dir = 'BirdNest/ImageSets/Main/'train_list_file = os.path.join(image_sets_dir, 'train_list.txt')val_list_file = os.path.join(image_sets_dir, 'val_list.txt')output_train_json_file = os.path.join(dataset_dir, 'train_coco.json')output_val_json_file = os.path.join(dataset_dir, 'val_coco.json')convert_to_coco_format(train_list_file, image_sets_dir, output_train_json_file, dataset_dir)convert_to_coco_format(val_list_file, image_sets_dir, output_val_json_file, dataset_dir)print("The json file has been successfully generated!!!")
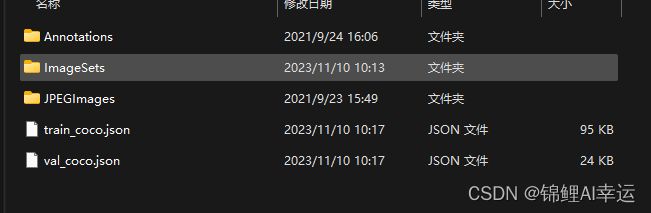
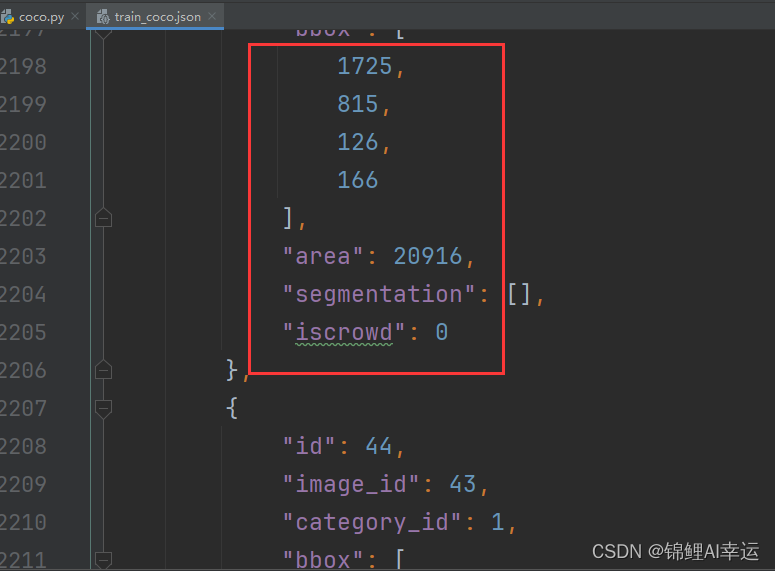
转COCO格式成功截图:
相关文章:
划分VOC数据集,以及转换为划分后的COCO数据集格式
1.VOC数据集 LabelImg是一款广泛应用于图像标注的开源工具,主要用于构建目标检测模型所需的数据集。Visual Object Classes(VOC)数据集作为一种常见的目标检测数据集,通过labelimg工具在图像中标注边界框和类别标签,为…...

JAVA基础8:方法
1.方法概念 方法(method):将具有独立功能的代码块组织成为一个整体,使其具有特殊功能的代码集。 注意事项: 方法必须先创建才可以使用,该过程称为方法定义方法创建后并不是直接运行的,需要手动使用后才执…...

域名反查Api接口——让您轻松查询域名相关信息
在互联网发展的今天,域名作为网站的唯一标识符,已经成为了企业和个人网络营销中不可或缺的一部分。为了方便用户查询所需的域名信息,API接口应运而生。本文将介绍如何使用挖数据平台《域名反查Api接口——让您轻松查询域名相关信息》进行域名…...
果儿科技:打造无代码开发的电商平台、CRM和用户运营系统
连接业务系统:果儿科技与集简云的无代码开发 北京果儿科技有限公司,自2015年成立以来,始终专注于研发创新的企业服务解决方案。其中,集简云无代码集成平台是我们的一项杰出成果,它实现了与近千款软件系统的连接&#…...

C++ 并发编程中condition_variable和future的区别
std::condition_variable 和 std::future 的区别: 用途不同: std::condition_variable: 就好比是一把魔法门,有两个小朋友,一个在门这边,一个在门那边。门上贴了一张纸,写着“开心时可以进来…...
【保姆级教程】Linux安装JDK8
本文以centos7为例,一步一步进行jdk1.8的安装。 1. 下载安装 官网下载链接: https://www.oracle.com/cn/java/technologies/downloads/#java8 上传jdk的压缩包到服务器的/usr/local目录下 在当前目录解压jdk压缩包,如果是其它版本…...
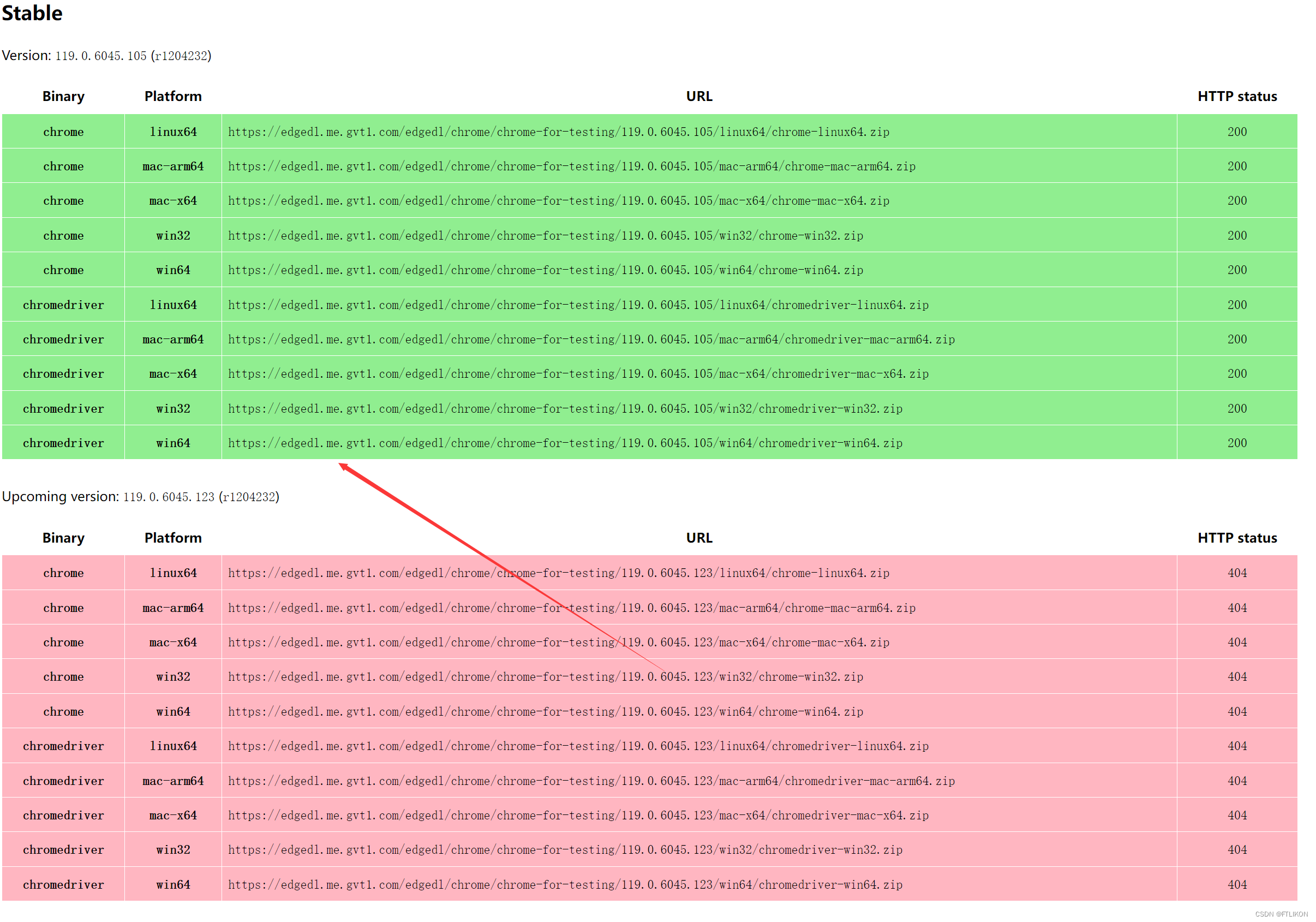
【备忘】ChromeDriver 官方下载地址 Selenium,pyppetter依赖
https://googlechromelabs.github.io/chrome-for-testing/#stable windows系统选择win64版本下载即可...

day08_osi各层协议,子网掩码,ip地址组成与分类
osi各层协议,子网掩码,ip地址组成与分类 一、上节课复习二 今日内容:1、子网划分 来源于http://egonlin.com/。林海峰老师课件 一、上节课复习 1、osi七层与数据传输 2、socketsocket是对传输层以下的封装ipport标识唯一一个基于网络通讯的软件3、tcp与…...
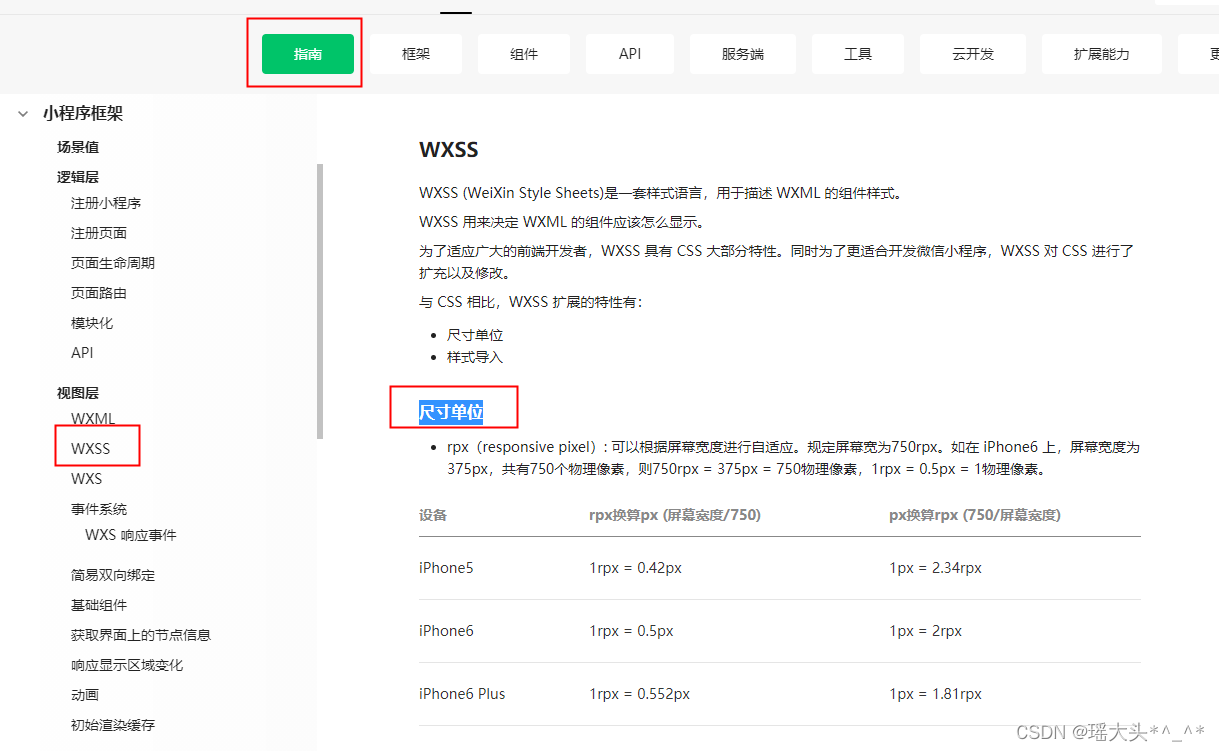
微信小程序:tabbar、事件绑定、数据绑定、模块化、模板语法、尺寸单位
目录 1. tabbar 1.1 什么是tabbar 1.2 配置tabbar 2. 事件绑定 2.1 准备表单 2.2 事件绑定 2.3 冒泡事件及非冒泡事件 3. 数据绑定 3.1 官方文档 4. 关于模块化 5. 模板语法 6. 尺寸单位 1. tabbar 1.1 什么是tabbar 下图中标记出来的部分即为tabbar:…...

AR工业眼镜:智能化生产新时代的引领者!!
科技飞速发展,人工智能与增强现实(AR)技术结合正在改变生活工作方式。AR工业眼镜在生产领域应用广泛,具有实时信息展示、智能导航定位、远程协作培训、智能安全监测等功能,提高生产效率、降低操作风险,为企…...

从0到0.01入门React | 008.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
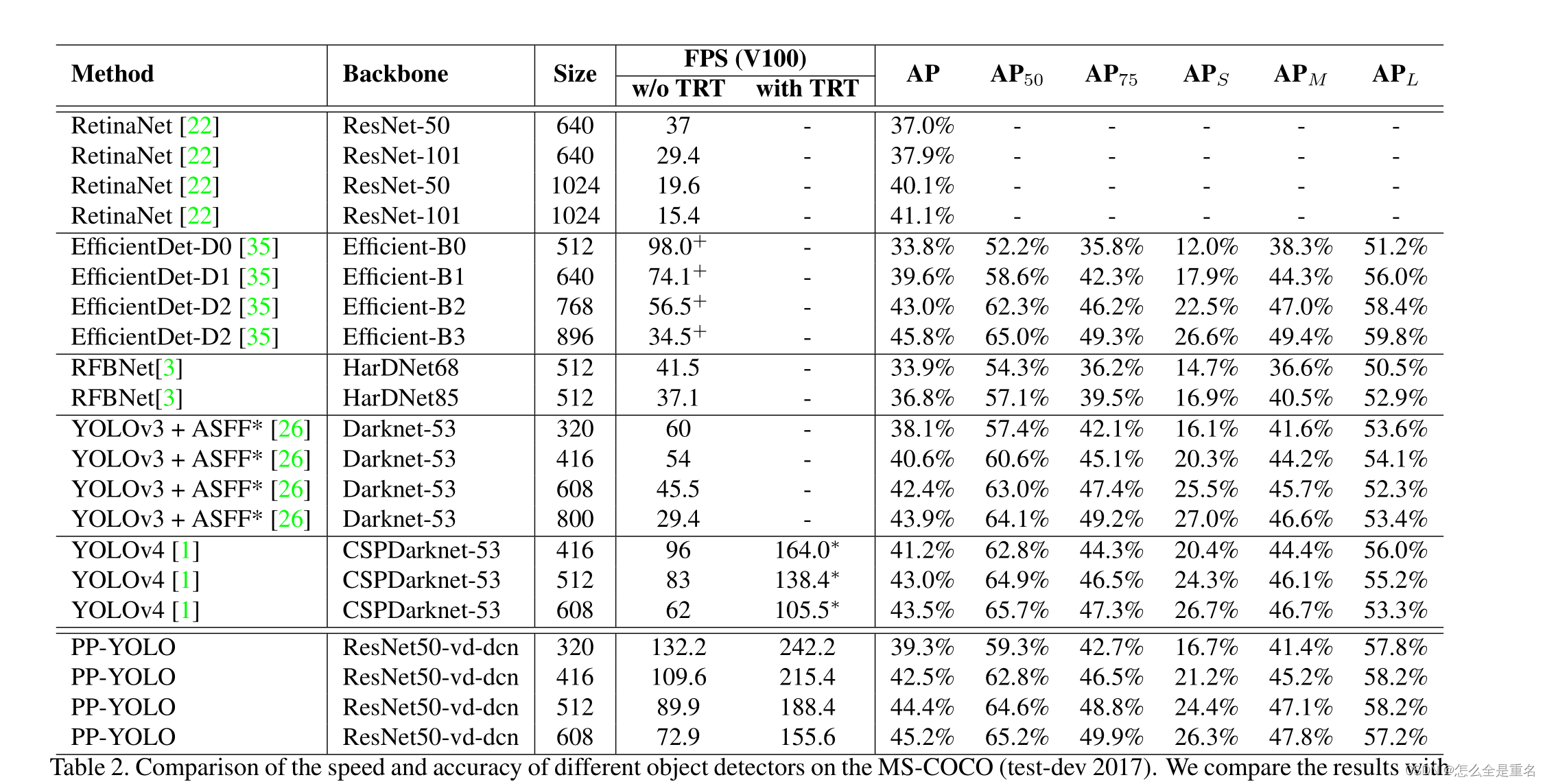
PP-YOLO: An Effective and Efficient Implementation of Object Detector(2020.8)
文章目录 Abstract1. Introduction先介绍了一堆前人的work自己的workexpect 2. Related Work先介绍别人的work与我们的区别 3.Method3.1. ArchitectureBackboneDetection NeckDetection Head 3.2. Selection of TricksLarger Batch SizeEMADropBlockIoULossIoU AwareGrid Sensi…...
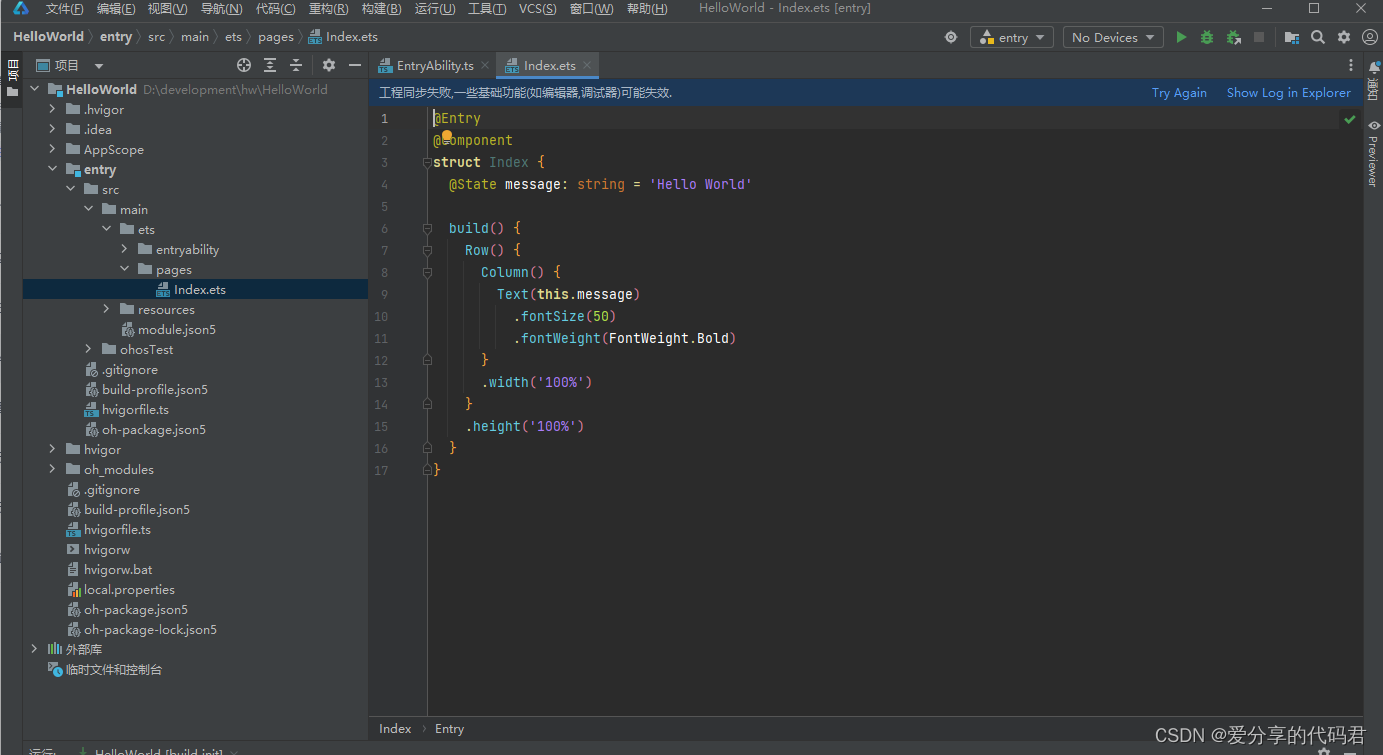
4、创建第一个鸿蒙应用
一、创建项目 此处以空模板为例来创建一个鸿蒙应用。在创建项目前请保持网页的畅通。 1、在欢迎页面点击“Create Project”。 2、左侧默认为“Application”,在“Template Market”中选择空模板(Empty Ability),点击“Next” 3…...

Docker - DockerFile
Docker - DockerFile DockerFile 描述 dockerfile 是用来构建docker镜像的文件!命令参数脚本! 构建步骤: 编写一个dockerfile 文件docker build 构建成为一个镜像docker run 运行脚本docker push 发布镜像(dockerhub࿰…...

2311rust模式匹配
原文 在Rust中混合匹配,改变和移动 结构模式匹配:极大的改进了C或Java风格的switch语句. Match包含命令式和函数式编程风格:可继续使用break语句,赋值等,不必面向表达式. 按需匹配"借用"或"移动",:Rust鼓励开发者仔细考虑所有权和借用.设计匹配时仅支持…...
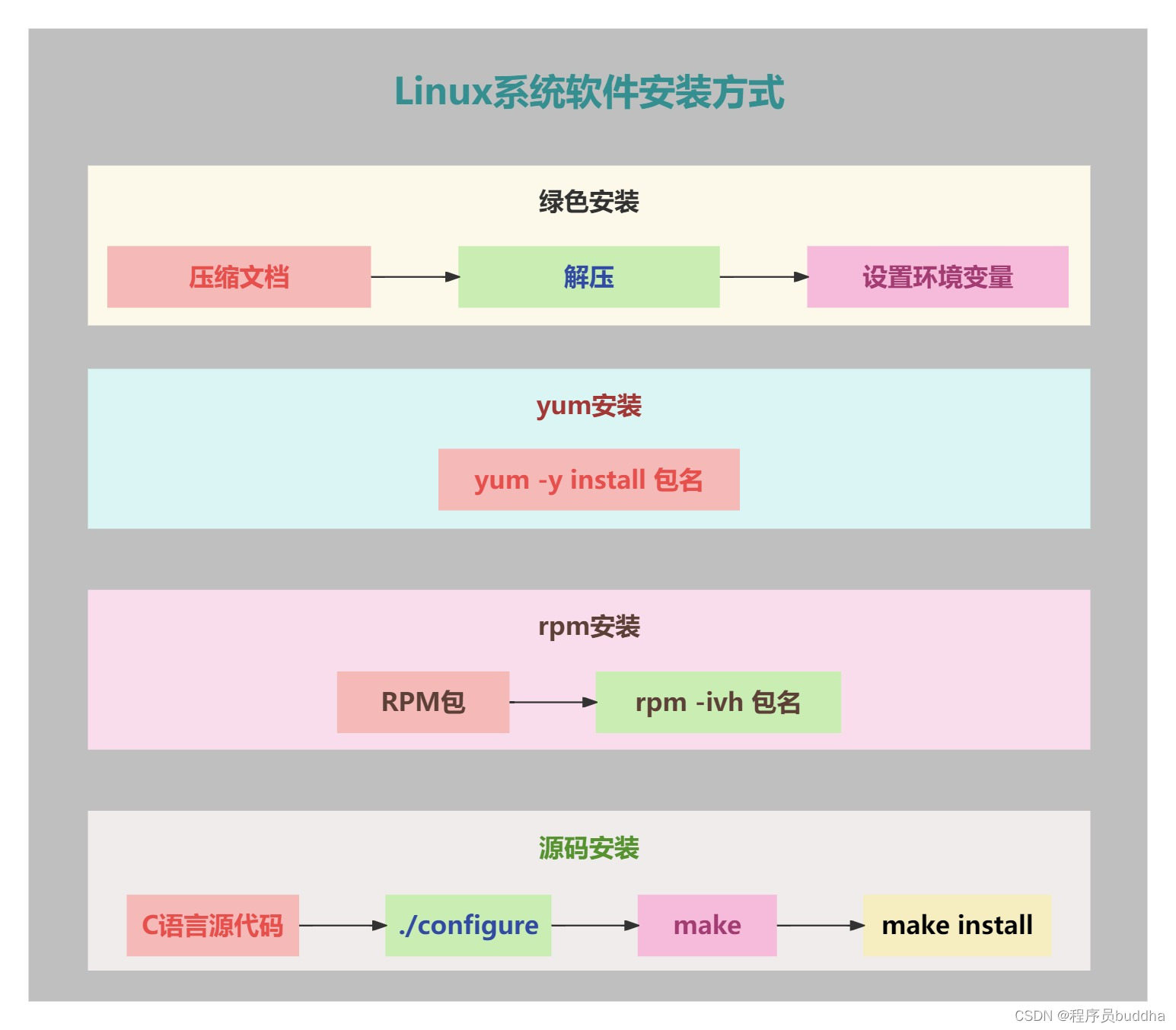
Linux系统软件安装方式
Linux系统软件安装方式 1. 绿色安装2. yum安装3. rpm安装3.1 rpm常用命令 4. 源码安装4.1 安装依赖包4.2 执行configure脚本4.3 编译、安装4.4 安装4.5 操作nginx4.6 创建服务器 1. 绿色安装 Compressed Archive压缩文档包,如Java软件的压缩文档包,只需…...

React + Antd 自定义Select选择框 全选、清空功能
实现代码 import React, { useState, useEffect } from react; import { Select, Space, Divider, Button } from antd;export default function AllSelect (props) {const {fieldNames, // 自定义节点labbel、value、options、grouLabeloptions, // 数据化配置选项内容&#…...
阿里云国际站:应用实时监控服务
文章目录 一、阿里云应用实时监控服务的概念 二、阿里云应用实时监控服务的优势 三、阿里云应用实时监控服务的功能 四、写在最后 一、阿里云应用实时监控服务的概念 应用实时监控服务 (Application Real-Time Monitoring Service) 作为一款云原生可观测产品平台ÿ…...
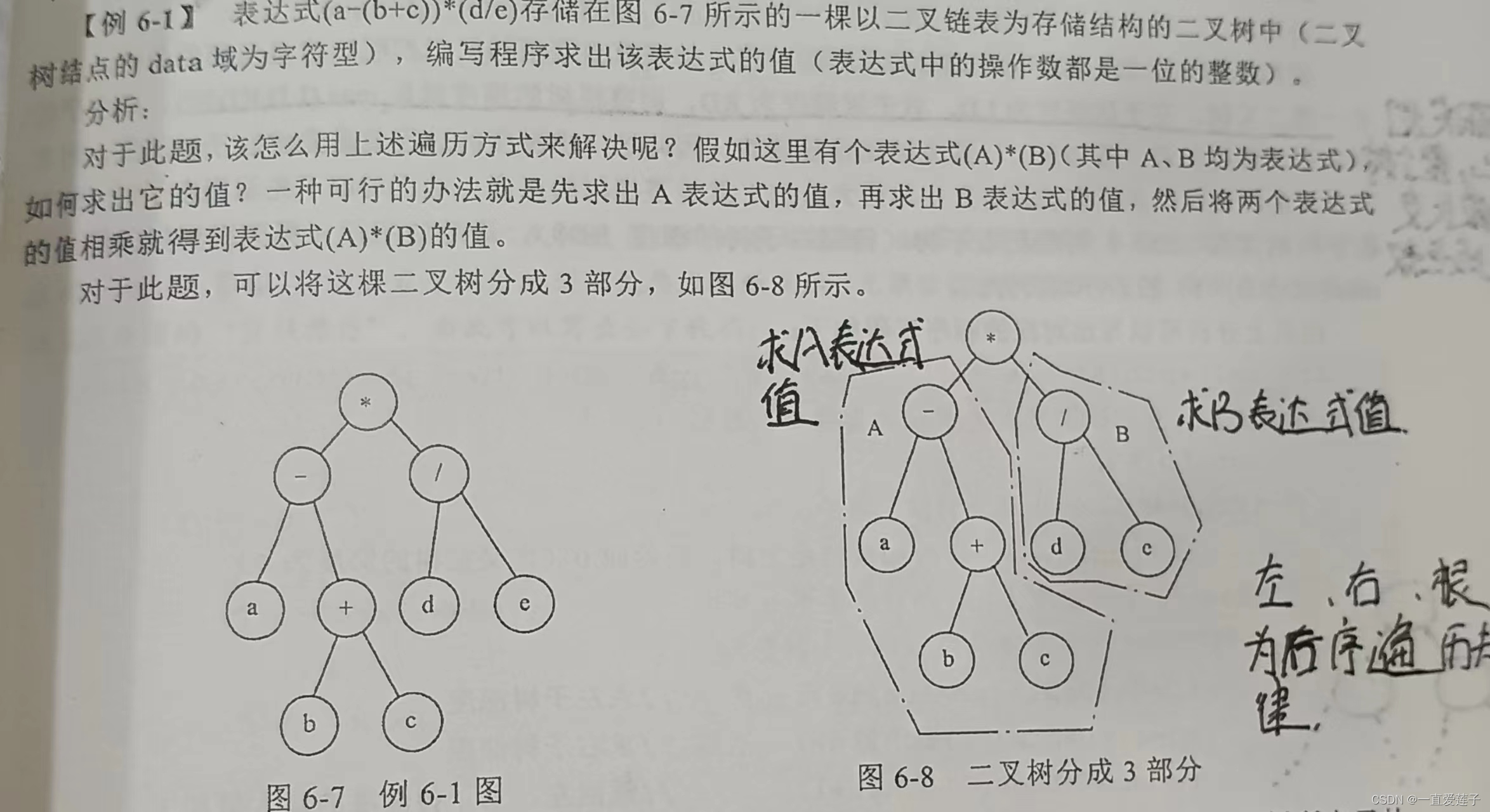
专题知识点-二叉树-(非常有意义的一篇文章)
这里写目录标题 二叉树的基础知识知识点一(二叉树性质 )树与二叉树的相互转换二叉树的遍历层次优先遍历树的深度和广度优先遍历中序线索二叉树二叉树相关遍历代码顺序存储和链式存储二叉树的遍历二叉树的相关例题左右两边表达式求值求树的深度找数找第k个数二叉树非递归遍历代码…...

多路数据写入DDR3/DDR4的两种方法
1.官方IP实现; 2.手写Axi 仲裁器。...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...