【万字长文】Python 日志记录器logging 百科全书 之 日志过滤

Python 日志记录器logging 百科全书 之 日志过滤
前言
在Python的logging模块中,日志过滤器(Filter)用于提供更细粒度的日志控制。通过过滤器,我们可以决定哪些日志记录应该被输出,哪些应该被忽略。这对于复杂的应用程序来说尤为重要,因为它允许我们根据日志记录的特定属性(例如日志级别、日志记录者的名称或日志记录包含的消息、上下文等)来控制日志的输出。
知识点📖📖
| 模块 | 释义 |
|---|---|
logging | Python 的日志记录工具,标准库 |
logging.Filter | 用于自定义日志过滤的类 |
import logging文章脉络:
- 点击直达:万字长文 - Python 日志记录器logging 百科全书 之 基础配置
- 点击直达:Python 日志记录器logging 百科全书 之 日志回滚
- 点击直达:【万字长文】Python 日志记录器logging 百科全书 之 日志过滤
日志过滤简介
1. 疑惑和应用场景
可能读者朋友们会有疑惑,日志记录和日志过滤都是人为的操作,既要记录,又要过滤,那为什么不在一开始就只记录过滤后的信息呢,那是否构成悖论呢?
以下是一些关于为什么需要日志过滤的考虑以及适用的应用场景:
- 动态环境: 根据信息的重要性记录不同级别(如
DEBUG、INFO、ERROR)的日志,如在调试期间记录详细的信息,但在生产环境中记录更少的信息。 - 多个处理程序:如果应用程序同时将日志发送到不同的处理程序(例如,将日志同时写入文件和发送到远程服务器),每个处理程序可能需要记录不同级别的信息。这时需要使用过滤器来控制每个处理程序的输出。
- 隐私保护: 为了保护敏感信息的安全,过滤掉包含敏感信息的日志是必要的,以确保不会意外泄露。
- …
2. 日志过滤的原理
这里解释日志过滤是如何工作的,包括当日志消息被发送到处理程序前,过滤器如何干预日志记录的流程。
日志过滤的原理涉及到以下关键概念:
- 日志记录器(Logger):在
Python的logging模块中,日志记录器是用于创建和处理日志消息的对象。每个日志记录器通常与一个特定的模块或组件相关联。 - 日志处理程序(Handler):处理程序决定了日志消息的最终去向,例如输出到控制台、写入文件等。处理程序通常与一个或多个日志记录器关联。
- 日志过滤器(Filter):过滤器是一个可选组件,它可以附加到处理程序上,用于决定哪些日志消息应该被处理,哪些应该被忽略。过滤器在日志消息被发送到处理程序之前起作用。
- 过滤规则:过滤器根据一组规则或条件来过滤日志消息。这些规则可以包括日志级别、日志记录器名称、关键词等。如果日志消息满足过滤规则,它将被允许传递到处理程序;否则,它将被忽略。
- 日志级别:日志消息通常具有不同的级别,如
DEBUG、INFO、WARNING、ERROR和CRITICAL。通过设置适当的过滤规则,我们可以选择记录特定级别的消息。
过滤器添加到日志记录器:
- 用于控制哪些记录器产生的消息应该被记录,记录器过滤器影响记录器级别
过滤器添加到日志处理程序:
- 用于控制哪些消息应该发送到特定处理程序,处理程序过滤器影响处理程序级别。
当日志消息被发送到处理程序时,会首先经过与之关联的过滤器。如果消息通过了过滤器的检查,它将被处理,否则将被丢弃。这样,过滤器可以在日志记录的不同阶段对消息进行筛选,以确保只有符合条件的消息被记录。
总之,日志过滤通过过滤器提供了一种强大的机制,允许开发人员有选择地记录和处理日志消息,以满足应用程序的特定需求和调试要求。
日志过滤器
logging 的日志过滤一般是基于重写 logging.Filter 类来实现自定义过滤器。
logging.Filter
步骤如下:
- 创建
自定义过滤器类,继承logging.Filter且重写filter方法 - 创建
日志记录器和日志处理器 - 添加
自定义过滤器类到日志处理器 - 设置日志格式
- 添加处理器(
Handler)到记录器(Logger) - 记录日志~
代码示例:
import logging# 步骤1:创建自定义过滤器类
class MyFilter(logging.Filter):def filter(self, record):# 在这里编写过滤逻辑# 返回True表示允许消息通过过滤器,返回False表示不允许return record.levelno >= logging.WARNING # 只允许WARNING级别及以上的消息通过# 步骤2:创建日志记录器和日志处理器
logger = logging.getLogger("my_logger") # 创建记录器
logger.setLevel(logging.DEBUG) # 设置记录器的级别为DEBUGhandler = logging.StreamHandler() # 创建处理器(这里使用了StreamHandler,将日志消息输出到控制台)
handler.setLevel(logging.DEBUG) # 设置处理器的级别为DEBUG# 步骤3:添加自定义过滤器到处理器
my_filter = MyFilter()
handler.addFilter(my_filter)# 步骤4:设置日志格式
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)# 步骤5:添加处理器到记录器
logger.addHandler(handler)# 步骤6:记录日志
logger.debug("This is a debug message") # 这条消息不会被过滤器通过
logger.warning("This is a warning message") # 这条消息会被过滤器通过# 2023-11-14 00:28:28,714 - my_logger - WARNING - This is a warning message代码释义:
上述代码演示了如何创建一个自定义过滤器类(步骤1),将它添加到一个处理器(步骤3),并将处理器添加到记录器(步骤5)。在这个示例中,自定义过滤器MyFilter允许通过级别为logging.WARNING及以上的日志消息。所以,在最后两行日志记录中,只有警告消息被记录。其他级别的消息被过滤掉。
实际开发中需要根据自己的需求定制自定义过滤器的逻辑,以满足不同的过滤条件。
日志过滤的选择
这里列举选择日志过滤的依据,如日志级别、关键字、进程&线程名、上下文、日志记录器名称等,以及如何决定何时使用哪种过滤器。
1. 日志级别
日志级别是特别常见的过滤依据,根据消息的重要性或严重性来过滤日志。常见的日志级别包括DEBUG、INFO、WARNING、ERROR、CRITICAL等。
示例代码:
class LevelFilter(logging.Filter):def __init__(self, level):self.level = leveldef filter(self, record):return record.levelno == self.level2. 关键字
- 目的:过滤包含特定关键字的日志。
- 使用场景:当需要根据消息的内容特征来过滤日志时,可以使用关键字过滤器。例如,筛选包含特定错误代码或事件描述的日志消息。
示例代码:
class KeywordFilter(logging.Filter):def __init__(self, keyword):self.keyword = keyworddef filter(self, record):return self.keyword in record.getMessage()3. 进程名 & 线程名
根据线程&进程名称来过滤日志,以区分不同的应用程序实例或进程。
应用场景:
| 场景 | 适用性 | 应用场景 |
|---|---|---|
| 根据线程名 | 用于多线程应用程序 | 网络服务器处理不同客户端请求,每个请求在不同线程中处理。根据线程名过滤日志可轻松识别和分析各线程的活动。 |
| 根据进程名 | 用于多进程应用程序 | 分布式系统中,不同进程代表不同应用实例或服务节点。根据进程名过滤日志有助于区分和监控不同进程的日志。 |
下面的两份代码基本一致。
进程名示例代码:
- 只记录线程名称为
Process 1的日志信息
import logging
import multiprocessingclass ProcessNameFilter(logging.Filter):def __init__(self, process_name):super().__init__()self.process_name = process_namedef filter(self, record):return record.processName == self.process_name# 创建日志记录器
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG)# 创建处理器(这里使用了StreamHandler,将日志消息输出到控制台)
handler = logging.StreamHandler()# 设置日志格式
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)# 添加处理器到记录器
logger.addHandler(handler)# 添加自定义过滤器到处理器
thread_filter = ProcessNameFilter('Process 1')
handler.addFilter(thread_filter)def worker_function():# 获取当前进程的名称current_process_name = multiprocessing.current_process().name# 记录日志logger.debug(f"This is a debug message {current_process_name}")logger.info(f"This is an info message {current_process_name}")logger.warning(f"This is a warning message {current_process_name}")if __name__ == "__main__":process_tasks = [multiprocessing.Process(target=worker_function, name=f'Process {i}') for i in range(5)][process.start() for process in process_tasks][process.join() for process in process_tasks]线程名示例代码:
- 只记录线程名称为
Thread 1的日志信息
import logging
import threadingclass ThreadNameFilter(logging.Filter):def __init__(self, thread_name):super().__init__()self.thread_name = thread_namedef filter(self, record):return record.threadName == self.thread_name# 创建日志记录器
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG)# 创建处理器(这里使用了StreamHandler,将日志消息输出到控制台)
handler = logging.StreamHandler()# 设置日志格式
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)# 添加处理器到记录器
logger.addHandler(handler)# 添加自定义过滤器到处理器
thread_filter = ThreadNameFilter('Thread 1')
handler.addFilter(thread_filter)def worker_function():# 获取当前线程的名称current_thread_name = threading.current_thread().name# 记录日志logger.debug(f"This is a debug message {current_thread_name}")logger.info(f"This is an info message {current_thread_name}")logger.warning(f"This is a warning message {current_thread_name}")if __name__ == '__main__':thread_tasks = [threading.Thread(target=worker_function, name=f'Thread {i}') for i in range(5)][thread.start() for thread in thread_tasks][thread.join() for thread in thread_tasks]4. 上下文
在日志记录中,上下文信息是一种关键的元素,它允许我们更精细地控制哪些日志消息应该被记录和处理。上下文信息可以是与日志消息相关的任何附加信息,常见的用例包括:
| 用例 | 目的 | 示例 |
|---|---|---|
| 用户会话 | 在多用户系统中,根据不同用户的会话来查看或调试日志。 | 为每个用户的会话创建一个唯一标识符(如用户ID或会话ID),并将其添加到日志消息中。然后,使用过滤器根据特定用户的标识符来过滤日志消息。 |
| 应用状态 | 根据应用的当前状态(如“启动中”、“运行中”、“关闭中”)来过滤日志。 | 将应用状态信息(如状态名称)添加到日志消息中,并使用过滤器根据状态来筛选日志。这可以帮助我们了解应用在不同状态下的行为。 |
| 业务逻辑 | 对于复杂的业务流程,可能需要根据特定的业务逻辑或执行路径来筛选日志。 | 在记录日志时,根据执行的特定业务逻辑或步骤添加标识符或关键字,并使用过滤器根据这些标识符来过滤日志。这有助于跟踪和分析特定业务逻辑的执行情况。 |
下面使用一个简单的案例来展示日志过滤中上下文 的应用。
示例代码:
- 下面代码演示了如何使用自定义过滤器和额外的上下文信息来过滤日志消息。
import loggingclass ContextFilter(logging.Filter):def __init__(self, context):super().__init__()self.context: dict = contextdef filter(self, record):return getattr(record, 'user_id', None) == self.context.get('user_id')# 创建日志记录器
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)# 创建处理器(这里使用了StreamHandler,将日志消息输出到控制台)
handler = logging.StreamHandler()# 设置日志格式
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s - user_id:%(user_id)s')
handler.setFormatter(formatter)# 添加处理器到记录器
logger.addHandler(handler)# 添加自定义过滤器到处理器
# 创建上下文信息
context_info = {'user_id': 'user123', 'request_id': 'abcdef'}
thread_filter = ContextFilter(context_info)
handler.addFilter(thread_filter)# 记录日志
# 这个日志将被显示,因为它匹配了上下文过滤器
logger.debug('This is a debug message', extra={'user_id': 'user123'})
# 这个日志将不会被显示
logger.debug('This log is from another user', extra={'username': 'user456'})代码释义:
在上面的示例中,ContextFilter 过滤器根据user_id来过滤日志,只有当日志消息中的user_id与上下文信息中的匹配时,日志消息才会被记录。这种方法允许根据自定义上下文信息轻松地过滤和分析日志消息。
5. 日志记录名称
- 目的:根据生成它们的日志记录器的名称来过滤日志。
- 使用场景:为不同的模块或子系统创建不同的记录器,并为每个记录器添加不同的过滤器,以根据记录器的名称来过滤消息。
示例代码:
class LoggerNameFilter(logging.Filter):def __init__(self, logger_name):self.logger_name = logger_namedef filter(self, record):return record.name == self.logger_name6. 应用场景
简单总结一下关于日志过滤的几种选择依据的应用场景。
| 过滤依据 | 应用场景 | 描述 |
|---|---|---|
| 日志级别 | - 调试、信息记录、警告、错误、严重错误级别的日志 | 根据消息的重要性或严重性来筛选日志,适用于大多数日志分析场景。 |
| 关键字 | - 根据特定内容特征过滤日志 - 筛选包含特定错误代码或事件描述的日志 | 当需要根据消息的具体内容来过滤日志时使用,如筛选包含特定代码或描述的消息。 |
| 进程&线程名 | - 区分不同的应用程序实例或进程 - 用于多线程或多进程应用程序 | 适用于需要根据进程或线程来区分日志的场景,例如网络服务器或分布式系统中。 |
| 上下文 | - 多用户系统中按用户会话过滤 - 根据应用状态或业务逻辑过滤 | 使用上下文信息(如用户会话ID、应用状态)过滤日志,适用于需要按上下文细节来筛选日志的复杂应用场景。 |
| 日志记录器名称 | - 根据不同模块或子系统的日志记录器名称过滤 | 为不同的模块或子系统创建不同的记录器,并根据记录器名称过滤日志,适用于模块化或分层设计的应用程序。 |
示例代码
这份代码是一个多功能的日志配置示例,适用于需要精确控制日志输出的应用程序。它适合于那些需要在不同环境(如开发和生产环境)下进行不同日志处理的场景。
代码
# -*- coding: utf-8 -*-import logging# 自定义过滤器 - 控制台使用
class ConsoleFilter(logging.Filter):def filter(self, record):# 过滤掉包含敏感信息的日志return "敏感信息" not in record.getMessage()# 自定义过滤器 - 文件处理器使用
class FileFilter(logging.Filter):def filter(self, record):# 过滤掉上下文不匹配的日志if hasattr(record, 'context_id') and record.context_id != 'expected_context':return Falsereturn Truedef setup_logger(name, log_file, level=logging.DEBUG):"""配置日志记录器、处理器和过滤器"""_logger = logging.getLogger(name=name)_logger.setLevel(level=level)# 控制台处理器console_handler = logging.StreamHandler()console_handler.setLevel(logging.DEBUG)console_handler.addFilter(ConsoleFilter())# 文件处理器file_handler = logging.FileHandler(filename=log_file, encoding='utf-8', delay=True)file_handler.setLevel(logging.INFO)file_handler.addFilter(FileFilter())# 设置日志格式formatter = logging.Formatter("%(levelname)-7s - %(asctime)s - %(name)s - %(message)s")console_handler.setFormatter(formatter)file_handler.setFormatter(formatter)# 添加处理器到记录器_logger.addHandler(console_handler)_logger.addHandler(file_handler)return _loggerif __name__ == '__main__':# 设置日志记录器logger = setup_logger("app_logger", "app.log")# 记录日志,包含上下文信息logger.debug("这是一条调试消息", extra={'context_id': 'expected_context'}) # 控制台打印, 日志不记录logger.info("这条消息包含敏感信息:123456", extra={'context_id': 'expected_context'}) # 控制台不打印, 日志记录logger.info("这是一条普通消息", extra={'context_id': 'expected_context'}) # 控制台打印, 日志记录logger.warning("这是一条警告消息", extra={'context_id': 'unexpected_context'}) # 控制台打印, 日志不记录logger.error("这是一条错误消息!", extra={'context_id': 'expected_context'}) # 控制台打印, 日志记录代码释义:
- 自定义过滤器:
ConsoleFilter:用于控制台处理器,过滤掉包含“敏感信息”的日志。FileFilter:用于文件处理器,过滤掉上下文标识符(context_id)与"expected_context"不匹配的日志。
- 日志记录器配置(
setup_logger函数):- 配置一个名为
name的日志记录器。 - 设置两个处理器:控制台处理器(
console_handler)和文件处理器(file_handler)。 - 控制台处理器设置为 DEBUG 级别,文件处理器设置为 INFO 级别。
- 为处理器添加对应的过滤器和格式器。
- 配置一个名为
- 日志记录操作:
- 使用
logger记录不同级别和内容的日志。 - 根据过滤器的设置,不同的日志消息会被不同地处理:
- 包含敏感信息的日志不会在控制台打印,但会记录到文件中。
- 上下文不匹配的日志会在控制台打印,但不会记录到文件中。
- 其他日志根据其级别既会打印到控制台也会记录到文件中。
- 使用
代码运行结果如下:
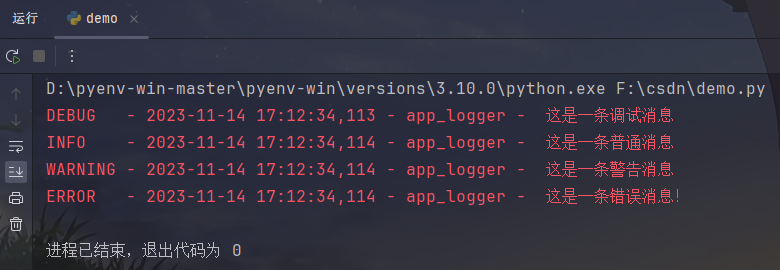
如果没出错的话,日志文件中会显示如下:

总结🚀🚀
在本篇文章中,我们深入探讨了logging模块中的日志过滤功能,展示了其在大型和复杂应用程序中的关键作用。日志过滤器提供了精细的控制机制,允许开发者基于特定条件(如日志级别、关键字、进程&线程名、上下文及日志记录器名称)筛选和处理日志记录。
有效地使用日志过滤器不仅帮助开发者更好地调试和监控应用程序,而且还有助于保护敏感信息,提高应用性能和可维护性。
后话
本次分享到此结束,
see you~😎😎
相关文章:
【万字长文】Python 日志记录器logging 百科全书 之 日志过滤
Python 日志记录器logging 百科全书 之 日志过滤 前言 在Python的logging模块中,日志过滤器(Filter)用于提供更细粒度的日志控制。通过过滤器,我们可以决定哪些日志记录应该被输出,哪些应该被忽略。这对于复杂的应用…...
redis基线检查
1、禁止使用 root 用户启动 | 访问控制 描述: 使用root权限来运行网络服务存在较大的风险。Nginx和Apache都有独立的work用户,而Redis没有。例如,Redis的Crackit漏洞就是利用root用户权限替换或增加authorize_keys,从而获取root登录权限。 加固建议: 使用root切换到re…...
第五章ARM处理器的嵌入式硬件系统设计——课后习题
1ARM处理器的工作状态 ARM处理器有两种工作状态。具体而言,ARM处理器执行32位ARM指令集时,工作在ARM状态,当ARM处理器执行16位thumb指令集时候,工作在thumb状态。 1ARM指令特点 1一个大的,统一的寄存器文件。 2基于…...

Python - GFPGAN + MoviePy 提高人物视频画质
目录 一.引言 二.gif_to_png 三.gfp_gan 四.png_to_gif 五.总结 一.引言 前面我们介绍了 GFP-GAN 提高人脸质量 与 OCR 提取视频台词、字幕,前者可以提高图像质量,后者可以从视频中抽帧,于是博主便想到了将二者进行结合并优化人物 GIF …...
uniapp插件开发
安装android studio:安装目录下bin下的此文件,是用来修改分配给android studio的占用内存。 Android 11足够用。 创建新项目: 目录结构介绍: UI组件介绍:在设计程序界面时可以使用可视化拖拽的方式,没有必要…...

11 Go的作用域
概述 在上一节的内容中,我们介绍了Go的映射,包括:声明映射、初始化映射、操作映射等。在本节中,我们将介绍Go的作用域。在Go语言中,作用域是指变量的可见性范围,它定义了变量在程序中的生命周期和可访问性。…...

RabbitMQ之消息应答和持久化
文章目录 前言一、消息应答1.概念2.自动应答3.消息应答方法4.Multiple 的解释5.消息自动重新入队6.消息手动应答代码7.手动应答效果演示 二、RabbitMQ持久化1.概念2.队列如何实现持久化3.消息实现持久化4.不公平分发5.预取值 总结 前言 在RabbitMQ中,我们的消费者在…...
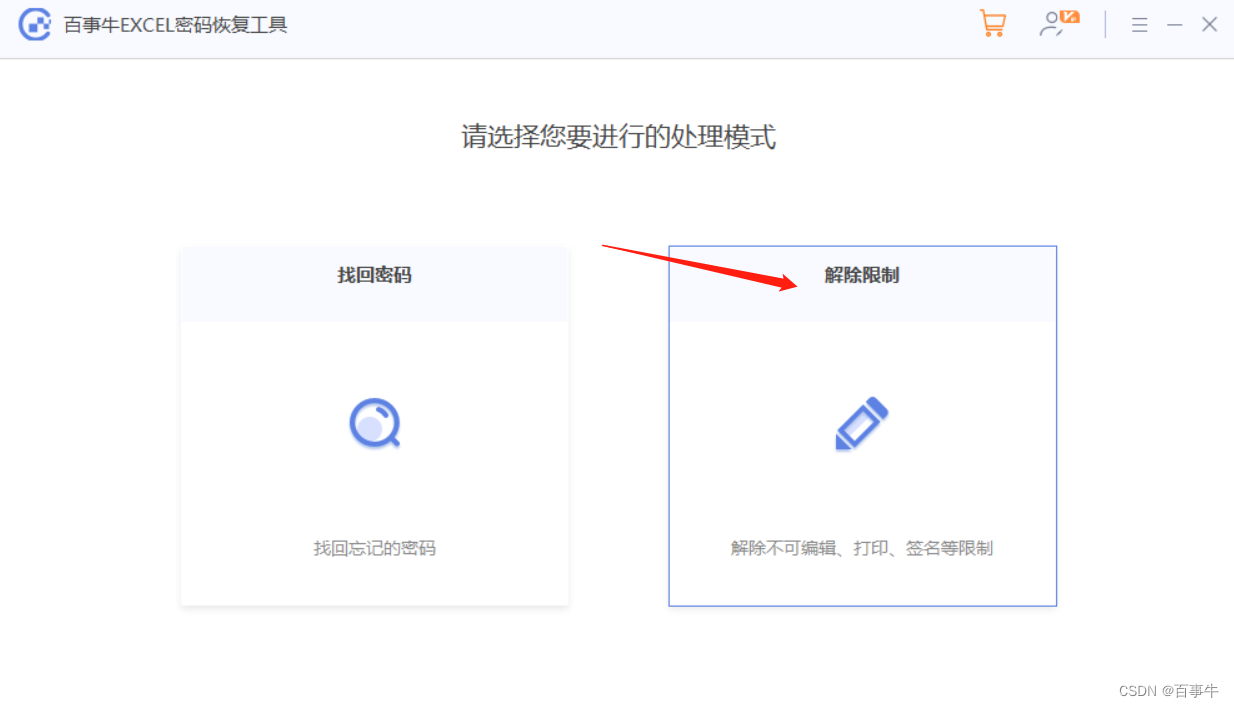
【分享】Excel“只读方式”的两种模式
查阅Excel表格的时候,担心不小心修改了内容,可以给Excel设置以“只读方式”打开,这样就算修改了内容也不能直接保存表格。Excel表格可以设置两种“只读方式”,一起来看看吧! “只读方式” 1: 打开Excel表…...

华为与美团达成合作,正式启动鸿蒙原生应用开发。
11月13日,华为宣布与美团以HarmonyOS为基础进行产业创新、技术应用、商业发展等方面展开全面合作,全力支持美团启动开发鸿蒙原生应用工作。 自9月25日华为宣布全新HarmonyOS NEXT蓄势待发、鸿蒙原生应用全面启动以来,已有金融、旅行、社交等…...

The 8th China Open Source Conference Successfully Concludes
由开源社主办的第八届中国开源年会(COSCon23)于 2023年10月29日在成都圆满收官。本次大会,为期两天,线下参会报名逾千人次,在线直播观看人数总计 168610 人,直播观看次数达 248725 次,官网累计浏…...
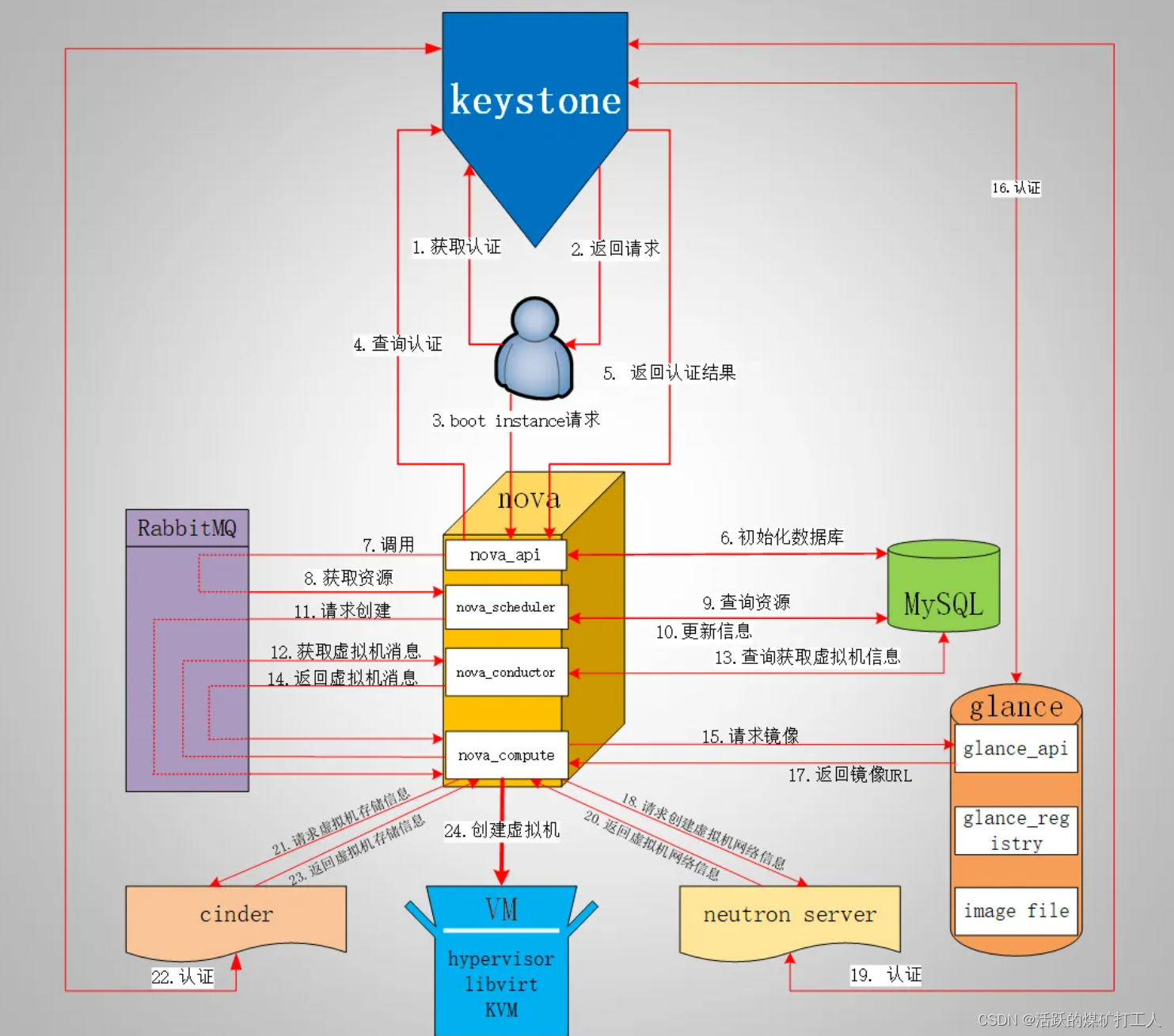
【星海出品】SDN neutron (四) 流分析
Neutron框架之流分析 1.控制端neutron-server通过wsgi接收北向REST API请求,neutron-plugin通过rpc与设备端进行南向通信。 2.设备端agent则向上通过rpc与控制端进行通信,向下则直接在本地对网络设备进行配置。 3.Neutron-agent的实现很多,彼…...
数据分析法宝,一个 SQL 语句查询多个异构数据源
随着企业数据量呈现出爆炸式增长,跨部门、跨应用、跨平台的数据交互需求越来越频繁,传统的数据查询方式已经难以满足这些需求。同时,不同数据库系统之间的数据格式、查询语言等都存在差异,直接进行跨库查询十分困难。 原生跨库查…...

解决:element ui表格表头自定义输入框单元格el-input不能输入问题
表格表头如图所示,有 40-45,45-50 数据,且以输入框形式呈现,现想修改其数据或点击右侧加号增加新数据编辑。结果不能输入,部分代码如下 <template v-if"columnData.length > 0"><el-table-colu…...

Android 透明度设置
目录 一、透明度对照表 二、透明度介绍 三、透明度设置 3.1 xml设置 3.2 代码设置 一、透明度对照表 注:00是完全透明,FF就是完全不透明 我们的UI小姐姐就喜欢给「不透明度」,这个需要自己判断一下。 完全透明:0% HEX: 00 透明度:1%…...

python语言的由来与发展历程
Python语言的由来可以追溯到1989年,由Guido van Rossum(吉多范罗苏姆)创造。在他的业余时间里,Guido van Rossum为了打发时间,决定创造一种新的编程语言。他受到了ABC语言的启发,ABC语言是一种过程式编程语…...
electronjs入门-编辑器应用程序
我们将在Electron中创建一个新项目,如我们在第1章中所示,名为“编辑器”,我们将在下一章中使用它来创建编辑器;在index.js中,这是我们的主要过程;请记住为Electron软件包放置必要的依赖项: npm…...

Xilinx Kintex7中端FPGA解码MIPI视频,基于MIPI CSI-2 RX Subsystem架构实现,提供工程源码和技术支持
目录 1、前言免责声明 2、我这里已有的 MIPI 编解码方案3、本 MIPI CSI2 模块性能及其优缺点4、详细设计方案设计原理框图OV5640及其配置权电阻硬件方案MIPI CSI-2 RX SubsystemSensor Demosaic图像格式转换Gammer LUT伽马校正VDMA图像缓存AXI4-Stream toVideo OutHDMI输出 5、…...

SIMCSE求相似度分数
import torch from transformers import AutoTokenizer, AutoModelForMaskedLM from sklearn.metrics.pairwise import cosine_similarity# simcse相似度分数 def simcse_similar(model, tokenizer, text_a, text_b):inputs_source tokenizer(text_a, return_tensors"pt&…...
java入门,从CK到一部分数据到mysql
一、需求 需要从生产环境ck数据库导数据到mysql,数据量大约100w条记录。 二、处理步骤 1、这里的关键词是生产库,第二就是100w条记录。所以处理数据的时候就要遵守一定的规范。首先将原数据库表进行备份,或者将需要导出的数据建一张新的表了…...
LeetCode(13)除自身以外数组的乘积【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 238. 除自身以外数组的乘积 1.题目 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...