Python 如何实现解释器(Interpreter)设计模式?什么是解释器设计模式?
什么是解释器(Interpreter)设计模式?
解释器(Interpreter)设计模式是一种行为型设计模式,它定义了一种语言文法的表示,并提供了一个解释器,用于解释语言中的句子。该模式使得可以定义一个语言,并且实现该语言的解释器,用于解释语言中的表达式或语句。

主要角色:
-
抽象表达式(Abstract Expression): 定义了一个解释器的接口,其中包含了解释方法
interpret。 -
终结符表达式(Terminal Expression): 实现了抽象表达式接口,表示语言中的终结符,即不再进行进一步解释的元素。
-
非终结符表达式(Non-terminal Expression): 实现了抽象表达式接口,表示语言中的非终结符,即需要进一步解释的元素。
-
上下文(Context): 包含解释器之外的一些全局信息,可能影响解释器的解释过程。
-
客户端(Client): 构建和配置需要解释的语句,然后将其传递给解释器来解释。
工作流程:
-
客户端创建需要解释的语句,并将其表示为抽象表达式的组合。
-
客户端将上下文传递给解释器,并调用解释器的
interpret方法。 -
解释器根据语法规则递归解释语句中的每个元素,返回最终结果。
Python 示例代码(一):
下面是一个简化的四则运算解释器的示例代码:
from abc import ABC, abstractmethod# 抽象表达式
class Expression(ABC):@abstractmethoddef interpret(self, context):pass# 终结符表达式 - 数字
class NumberExpression(Expression):def __init__(self, value):self.value = valuedef interpret(self, context):return self.value# 非终结符表达式 - 加法
class AddExpression(Expression):def __init__(self, left, right):self.left = leftself.right = rightdef interpret(self, context):return self.left.interpret(context) + self.right.interpret(context)# 非终结符表达式 - 减法
class SubtractExpression(Expression):def __init__(self, left, right):self.left = leftself.right = rightdef interpret(self, context):return self.left.interpret(context) - self.right.interpret(context)# 上下文
class Context:pass# 客户端
context = Context()
expression = AddExpression(NumberExpression(10), SubtractExpression(NumberExpression(5), NumberExpression(2)))
result = expression.interpret(context)
print(f"Result: {result}")
在这个示例中,NumberExpression 是终结符表达式,表示数字。AddExpression 和 SubtractExpression 是非终结符表达式,表示加法和减法。客户端可以创建一个复杂的表达式,然后通过解释器计算其结果。
Python 示例代码(二)
假设我们要实现一个简单的自定义查询语言解释器,支持对用户存储的文本数据进行查询。用户可以输入一些简单的查询语句,比如选择某个字段包含特定关键字的记录。以下是一个使用解释器设计模式的示例代码:
from abc import ABC, abstractmethod
import re# 抽象表达式
class QueryExpression(ABC):@abstractmethoddef interpret(self, context):pass# 终结符表达式 - 字段匹配
class FieldMatchExpression(QueryExpression):def __init__(self, field, keyword):self.field = fieldself.keyword = keyworddef interpret(self, context):data = context.get_data(self.field)return [record for record in data if re.search(self.keyword, record)]# 非终结符表达式 - 逻辑与
class AndExpression(QueryExpression):def __init__(self, expression1, expression2):self.expression1 = expression1self.expression2 = expression2def interpret(self, context):result1 = self.expression1.interpret(context)result2 = self.expression2.interpret(context)return list(set(result1) & set(result2))# 非终结符表达式 - 逻辑或
class OrExpression(QueryExpression):def __init__(self, expression1, expression2):self.expression1 = expression1self.expression2 = expression2def interpret(self, context):result1 = self.expression1.interpret(context)result2 = self.expression2.interpret(context)return list(set(result1) | set(result2))# 上下文
class QueryContext:def __init__(self):self.data = {'title': ["Document 1", "Document 2", "Document 3"],'content': ["Python is a programming language", "Design patterns are important", "Interpreter pattern example"]}def get_data(self, field):return self.data.get(field, [])# 客户端
context = QueryContext()# 构建查询语句:(title 包含 "Document" 且 content 包含 "pattern") 或 title 包含 "Python"
query = OrExpression(AndExpression(FieldMatchExpression("title", "Document"), FieldMatchExpression("content", "pattern")),FieldMatchExpression("title", "Python VicRestart")
)result = query.interpret(context)
print("Query Result:", result)
在这个示例中,FieldMatchExpression 是终结符表达式,表示字段匹配。AndExpression 和 OrExpression 是非终结符表达式,表示逻辑与和逻辑或。客户端可以构建复杂的查询语句,然后通过解释器来解释并执行查询,返回匹配的结果。这种设计方式可以用于实现简单的自定义查询语言。
使用解释器设计模式,需要注意哪些地方?
在实现解释器设计模式时,有一些需要注意的地方,以确保模式的有效实施和系统的可维护性:
-
文法设计: 确保定义的语言文法清晰和简单。复杂的文法可能导致难以实现和理解的解释器。
-
抽象表达式的一致性: 确保所有的抽象表达式都有一致的接口。这使得客户端能够一致地对待不同的表达式。
-
终结符和非终结符的区分: 在设计表达式时,明确哪些是终结符表达式(不再解释的元素)和哪些是非终结符表达式(需要进一步解释的元素)。
-
递归结构: 解释器模式通常使用递归结构,确保递归调用的终止条件和递归过程的正确性。
-
上下文对象: 上下文对象存储解释器解释时所需的全局信息,确保它在解释器之间正确传递。
-
灵活性: 使解释器模式具有灵活性,允许客户端根据需要自由组合和嵌套不同的表达式。
-
错误处理: 考虑解释器执行时可能发生的错误,例如语法错误或运行时错误,提供适当的错误处理机制。
-
性能考虑: 在解释器模式中,特别是在处理大型或复杂表达式时,需要注意性能问题。可能需要考虑缓存解释结果以提高性能。
-
复杂度把控: 不要让解释器模式变得过于复杂。如果可能,考虑使用其他模式或技术来简化问题。
-
测试: 编写充分的测试来验证解释器的正确性。由于解释器通常是递归的,测试应该覆盖不同层次的递归。
-
扩展性: 如果预计语言会扩展,确保解释器设计是易扩展的,可以轻松添加新的表达式类型。
-
文档和注释: 提供清晰的文档和注释,解释解释器的设计、使用方法和注意事项,以便其他开发人员更容易理解和使用你的代码。
通过关注这些方面,可以确保实现的解释器模式在系统中稳健且易于维护。
本文就到这里了,感谢您的阅读 。别忘了点赞、收藏~ Thanks♪(・ω・)ノ 🍇
相关文章:
Python 如何实现解释器(Interpreter)设计模式?什么是解释器设计模式?
什么是解释器(Interpreter)设计模式? 解释器(Interpreter)设计模式是一种行为型设计模式,它定义了一种语言文法的表示,并提供了一个解释器,用于解释语言中的句子。该模式使得可以定…...
单片机与PLC的区别有哪些?
单片机与PLC的区别有哪些? 什么是单片机? 单片机(Microcontroller,缩写MCU)是一种集成了中央处理器(CPU)、存储器和输入/输出接口等功能模块的微型计算机系统。它通常被用于嵌入式系统和控制系统中&#x…...

修改浏览器滚动条样式--ios同款
::-webkit-scrollbar{width: 5px;height: 5px; } ::-webkit-scrollbar-thumb{border-radius: 1em;background-color: rgba(50,50,50,.3); } ::-webkit-scrollbar-track{border-radius: 1em;background-color: rgba(50,50,50,.1); } 修改滚动条样式用到的CSS伪类: :…...
python自动化测试selenium核心技术3种等待方式详解
这篇文章主要为大家介绍了python自动化测试selenium的核心技术三种等待方式示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪 UI自动化测试过程中,可能会出现因测试环境不稳定、网络慢等情况&a…...
苹果手机照片如何导入电脑?无损快速的传输办法分享!
前些天小编的朋友联系到我,说是自己苹果手机里面的照片太多,有好几千张,不知道该怎么快而无损地传到电脑。我想遇到这种情况的不止是小编的朋友,生活中遇到手机照片导入电脑的同学不在少数。不管是苹果手机还是安卓手机࿰…...

csh 脚本批量处理文件并将文件扔给程序
文章目录 前言程序批量造 case 并将 cmd 扔给程序运行批量收集数据汇总 前言 Linux下我们经常会写一些shell脚本来辅助我们学习或者工作,从而提高效率。 之前就写过一篇博客:Linux下利用shell脚本批量产生内容有规律变化的文件 程序 批量造 case 并将…...

程序员技能成长树,程序员的曙光
一、背景 初创的计算机公司,主要低市场占有率和日益增长的市场规模之间的矛盾,此时只有一件事情,那就是快速抢占市场,在面对计算机飞速发展的时期,企业广泛的招聘计算机人才进行信息化项目建设,随着公司业…...
灰度图处理方法
做深度学习项目图像处理的时候常常涉及到灰度图处理,这里对自己处理灰度图的方式做一个记录,后续有更新的话会在此更新 一,多维数组可视化 将多维数组可视化为灰度图 img_gray Image.fromarray(img, modeL) # 实现array到image的转换,m…...
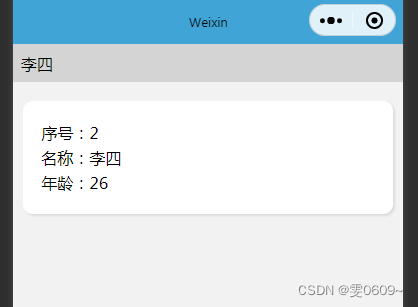
微信小程序:仅前端实现对象数组的模糊查询
效果 核心代码 //对数组进行过滤,返回数组中每一想满足name值包括变量query的 let result array.filter(item > { return item.name.includes(query); }); 完整代码 wxml <input type"text" placeholder"请输入名称" placeholder-styl…...

【done】剑指offer63:股票的最大利润
力扣188,https://leetcode.cn/problems/gu-piao-de-zui-da-li-run-lcof/description/(注意:本题与主站 121 题相同:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/) 动态规划思路; 方…...
桶装水订水小程序app,线上预约订水更便捷
桶装水订水小程序app,线上预约订水更便捷。设置好地址,一键订水,工作人员送水到家。还能配送新鲜果蔬,绿色健康有保证。送水软件手机版,提供各种品牌桶装水,在线发起订水服务,由服务人员送水到家…...
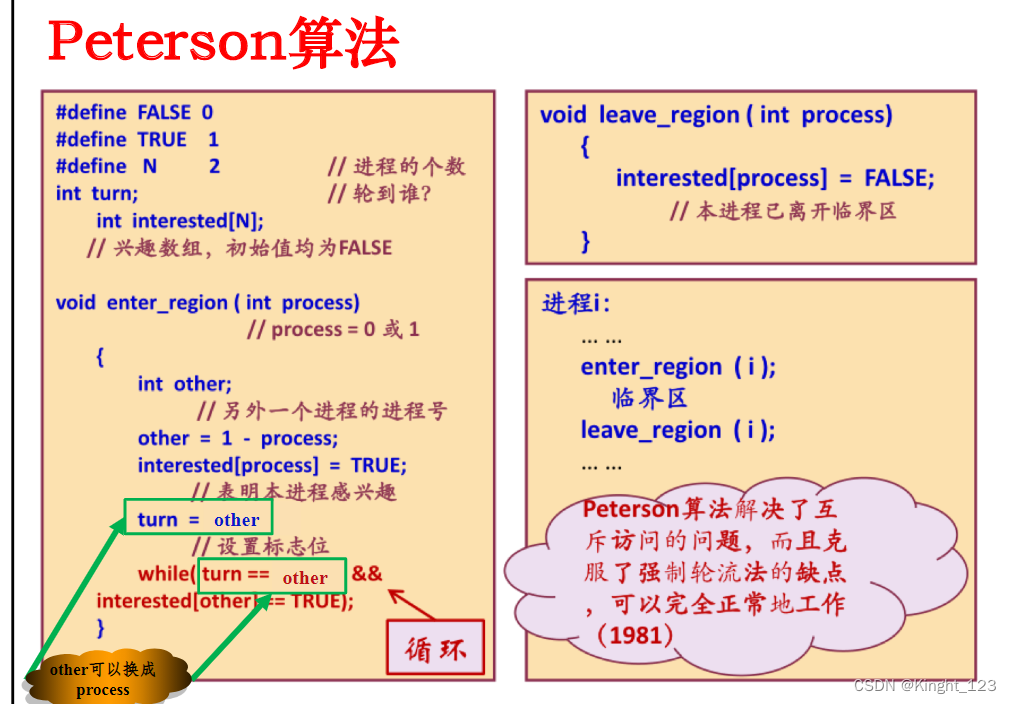
解决进程同步与互斥的Dekker算法与Peterson算法
1. Dekker算法 2. Peterson算法...
confluence无法打开空间目录
confluence无法打开空间目录,打开空间目录后无法显示项目 查看项目的类别信息都在 问题原因 由于索引损坏导致; This issue is caused by acorrupted index. Confluence is trying to fetch information about the spacesfrom the available index, …...
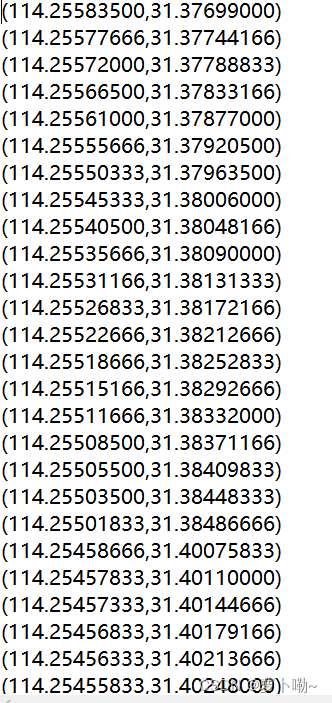
python用pychart库,实现将经纬度信息在地图上显示
python使用pyecharts对给到的经纬度数据进行位置标注,下面是批量更新。给入数据,将地图生成。实验数据在下面附件。 from pyecharts import options as opts from pyecharts.charts import Geo import osfolder_path F:\\GPS file_names os.listdir(f…...

Android Studio的笔记--随机数
android java获取随机数 String String 获取 x 位 由0到9组成的随机字符串。 调用方法 Log.i("lxh", "获取由数字0到9组成的随机字符串:" getStr(12));函数 public String RandomStr(int length) {String characters "0123456789"…...

《诗经》中28首巅峰之作
《诗经》是诗词的先声,是最纯美的诗,也是最接地气的诗。 三千年前,先民们劳作、生活、歌唱、恋爱……有感而歌,于是有了《诗经》。 在《诗经》中,爱情是纯美的,思念是绵长的,相遇是惊喜的&…...

十大适合外贸企业邮箱的Gmail替代品推荐
电子邮件仍然是许多人选择的媒介,因为它是交换信息的最可靠和正式的方法。无论是个人还是小型企业,电子邮件仍然是个人和专业用途的重要通信工具。它提供了一种安全、可靠且正式的方法来交换信息和文档以及共享文件。 对于大多数人来说,Googl…...

在Python中使用sqlite3进行数据持久化操作
目录 引言 一、安装sqlite3模块 二、创建数据库连接 三、创建游标对象 四、执行SQL命令 五、提交更改 六、关闭连接 七、使用参数化查询 八、使用ORM进行数据操作 九、备份和恢复数据库 十、处理大量数据 十一、优化查询性能 十二、处理并发访问 十三、处理数据持…...
file2Udp增量日志转出Udp简介
https://gitee.com/tianjingle/file2udp 很多时候服务产生的日志需要进行汇总,这种统一日志处理的方式有elb,而且很多日志组件也支持日志转出的能力。但是从广义上来说是定制化的,我们需要一个小工具实现tail -f的能力,将增量日志…...

快速创建1个G的文件 -----window平台
window平台下 cmdh中 1G: 1073741824 个字节2G: 21474836483G: 32212254724G: 42949672964.5G: 48318382085G: 5368709120 生成一个G的文件 fsutil file createNew big1g.txt 1073741824...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...

安卓用户如何免费获取大模型API密钥并开始调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 安卓用户如何免费获取大模型API密钥并开始调用 对于安卓开发者或移动端技术爱好者而言,直接体验和调用多种大模型的能力…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...