【机器学习】K近邻算法:原理、实例应用(红酒分类预测)
案例简介:有178个红酒样本,每一款红酒含有13项特征参数,如镁、脯氨酸含量,红酒根据这些特征参数被分成3类。要求是任意输入一组红酒的特征参数,模型需预测出该红酒属于哪一类。
1. K近邻算法介绍
1.1 算法原理
原理:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,那么该样本也属于这个类别。简单来说就是,求两点之间的距离,看距离谁是最近的,以此来区分我们要预测的这个数据是属于哪个分类。
我们看图来理解一下。蓝色点是属于a类型的样本点,粉色点是属于b类型的样本点。此时新来了一个点(黄色点),怎么判断是属于它是a类型还是b类型呢。
方法是:新点找距离自身最近的k个点(k可变)。分别计算新点到其他各个点的距离,按距离从小到大排序,找出距离自身最近的k个点。统计在这k个点中,有多少点属于a类,有多少点属于b类。在这k个点中,如果属于b类的点更多,那么这个新点也属于b分类。距离计算公式也是我们熟悉的勾股定理。

1.2 算法优缺点
算法优点:简单易理解、无需估计参数、无需训练。适用于几千-几万的数据量。
算法缺点:对测试样本计算时的计算量大,内存开销大,k值要不断地调整来达到最优效果。k值取太小容易受到异常点的影响,k值取太多产生过拟合,影响准确性。
2. 红酒数据集
2.1 数据集获取方式
红酒数据集是Scikit-learn库中自带的数据集,我们只需要直接调用它,然后打乱它的顺序来进行我们自己的分类预测。首先我们导入Scikit-learn库,如果大家使用的是anaconda的话,这个库中的数据集都是提前安装好了的,我们只需要调用它即可。
找不到这个数据集的,我把红酒数据集连接放在文末了,有需要的自取。
Scikit-learn数据集获取方法:
(1)用于获取小规模数据集,数据集已在系统中安装好了的
sklearn.datasets.load_数据名()
from sklearn import datasets
#系统中已有的波士顿房价数据集
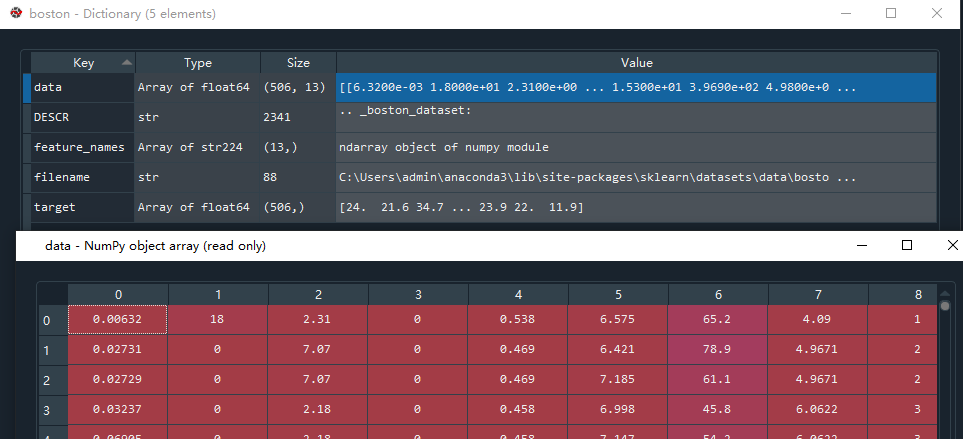
boston = datasets.load_boston()
(2)远程获取大规模数据集安装到本地,data_home默认是位置是/scikit_learn_data/
sklearn.datasets.fetch_数据名(data_home = 数据集下载目录)
# 20年的新闻数据下载到
datasets.fetch_20newsgroups(data_home = './newsgroups.csv') #指定文件位置
这两种方法返回的数据是 .Bunch类型,它有如下属性:
data:特征数据二维数组;相当于x变量
target:标签数组;相当于y变量
DESCR:数据描述
feature_names:特征名。新闻数据、手写数据、回归数据没有
target_name:标签名。回归数据没有
想知道还能获取哪些数据集的同学,可去下面这个网址查看具体操作:
https://sklearn.apachecn.org/#/docs/master/47
2.2 获取红酒数据
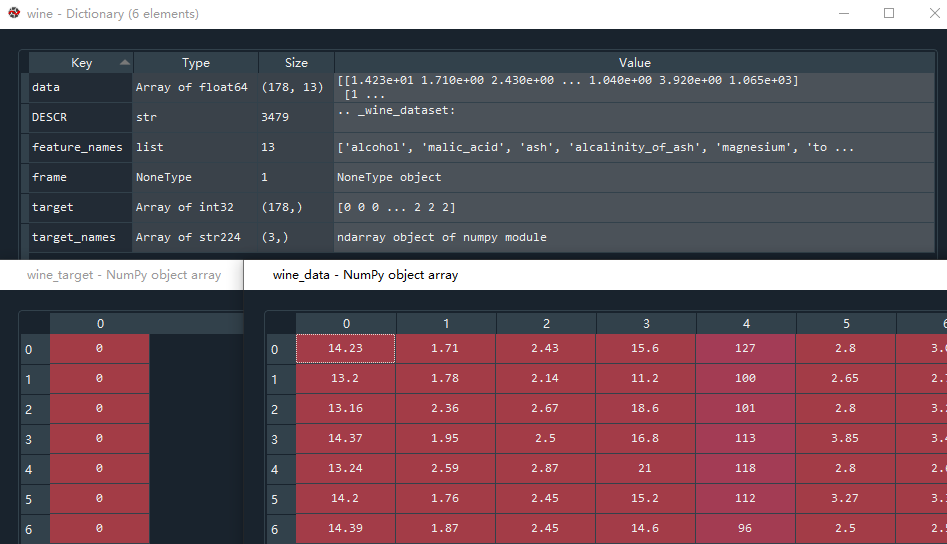
首先导入sklearn的本地数据集库,变量wine获取红酒数据,由于wine接收的返回值是.Bunch类型的数据,因此我用win_data接收所有特征值数据,它是178行13列的数组,每一列代表一种特征。win_target用来接收所有的目标值,本数据集中的目标值为0、1、2三类红酒。如果大家想更仔细的观察这个数据集,可以通过wine.DESCR来看这个数据集的具体描述。
然后把我们需要的数据转换成DataFrame类型的数据。为了使预测更具有一般性,我们把这个数据集打乱。操作如下:
from sklearn import datasets
wine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值# 将数据转换成DataFrame类型
wine_data = pd.DataFrame(data = wine_data)
wine_target = pd.DataFrame(data = wine_target)# 将wine_target插入到第一列,并给这一列的列索引取名为'class'
wine_data.insert(0,'class',wine_target)# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序wine = wine_data.sample(frac=1).reset_index(drop=True) #把DataFrame的行顺序打乱
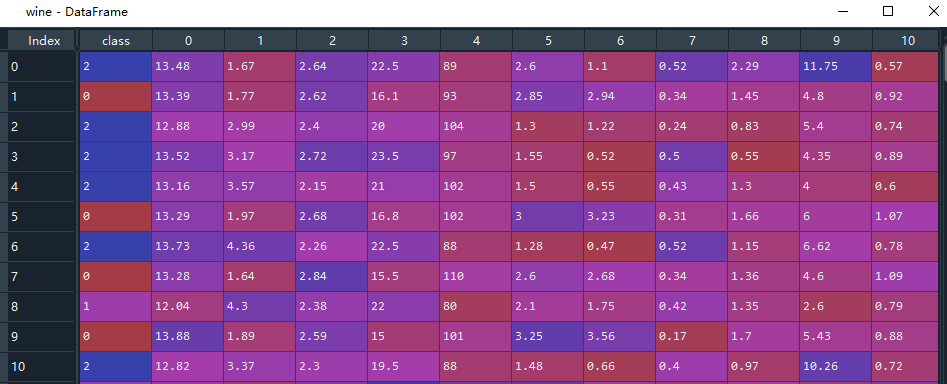
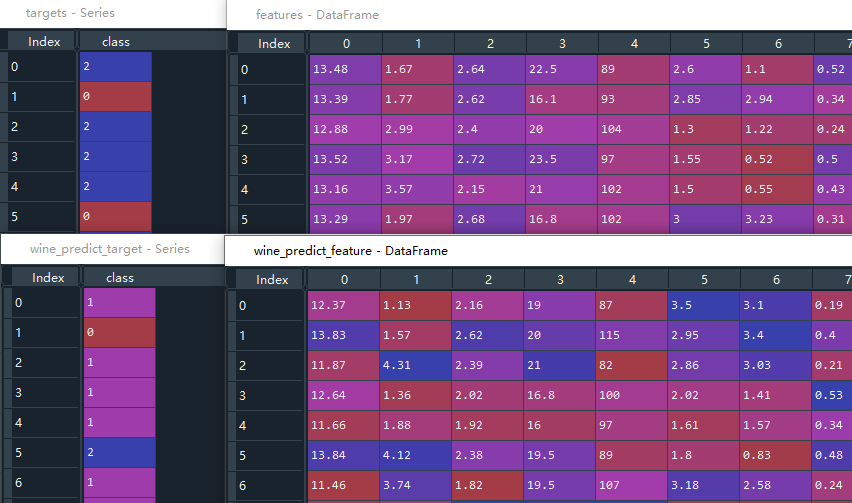
我们取出最后10行数据用作后续的验证预测结果是否正确,这10组数据分出特征值(相当于x)和目标值(相当于y)。剩下的数据也分出特征值features和目标值targets,用于模型训练。剩下的数据中还要划分出训练集和测试集,下面再详述。到此,数据处理这块完成。
#取后10行,用作最后的预测结果检验。并且让index从0开始,也可以不写.reset_index(drop=True)
wine_predict = wine[-10:].reset_index(drop=True)
# 让特征值等于去除'class'后的数据
wine_predict_feature = wine_predict.drop('class',axis=1)
# 让目标值等于'class'这一列
wine_predict_target = wine_predict['class']wine = wine[:-10] #去除后10行
features = wine.drop(columns=['class'],axis=1) #删除class这一列,产生返回值
targets = wine['class'] #class这一列就是目标值
3. 红酒分类预测
3.1 划分测试集和训练集
一般采用75%的数据用于训练,25%用于测试,因此在数据进行预测之前,先要对数据划分。
划分方式:
使用sklearn.model_selection.train_test_split 模块进行数据分割。
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=数据占比)
train_test_split() 括号内的参数:
x:数据集特征值(features)
y:数据集目标值(targets)
test_size: 测试数据占比,用小数表示,如0.25表示,75%训练train,25%测试test。
train_test_split() 的返回值:
x_train:训练部分特征值
x_test: 测试部分特征值
y_train:训练部分目标值
y_test: 测试部分目标值
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
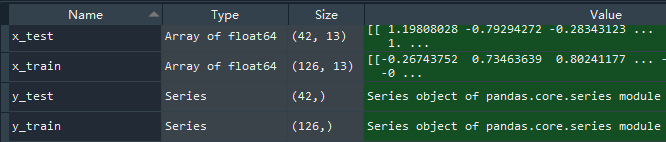
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
3.2 数据标准化
由于不同数据的单位不同,数据间的跨度较大,对结果影响较大,因此需要进行数据缩放,例如归一化和标准化。考虑到归一化的缺点:如果异常值较多,最大值和最小值间的差值较大,会造成很大影响。我采用数据标准化的方法,采用方差标准差,使标准化后的数据均值为0,标准差为1,使数据满足标准正态分布。
# 先标准化再预测
from sklearn.preprocessing import StandardScaler #导入标准化缩放方法
scaler = StandardScaler() #变量scaler接收标准化方法
# 传入特征值进行标准化
# 对训练的特征值标准化
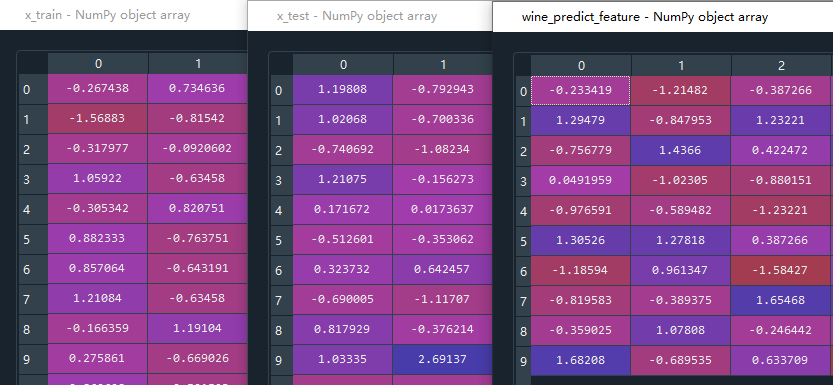
x_train = scaler.fit_transform(x_train)
# 对测试的特征值标准化
x_test = scaler.fit_transform(x_test)
# 对验证结果的特征值标准化
wine_predict_feature = scaler.fit_transform(wine_predict_feature)
3.3 K近邻预测分类
使用sklearn实现k近邻算法
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors = 邻居数,algorithm = '计算最近邻居算法')
.fit(x_train,y_train)
KNeighborsClassifier() 括号内的参数:
n_neighbors:int类型,默认是5,可以自己更改。(找出离自身最近的k个点)
algorithm:用于计算最近邻居的算法。有:'ball_tree'、'kd_tree'、'auto'。默认是'auto',根据传递给fit()方法的值来决定最合适的算法,自动选择前两个方法中的一个。
from sklearn.neighbors import KNeighborsClassifier #导入k近邻算法库
# k近邻函数
knn = KNeighborsClassifier(n_neighbors=5,algorithm='auto')
# 把训练的特征值和训练的目标值传进去
knn.fit(x_train,y_train)
将训练所需的特征值和目标值传入.fit()方法之后,即可开始预测。首先利用.score()评分法输入用于测试的特征值和目标值,来看一下这个模型的准确率是多少,是否是满足要求,再使用.predict()方法预测所需要的目标值。
评分法:根据x_test预测结果,把结果和真实的y_test比较,计算准确率
.score(x_test, y_test)
预测方法:
.predict(用于预测的特征值)
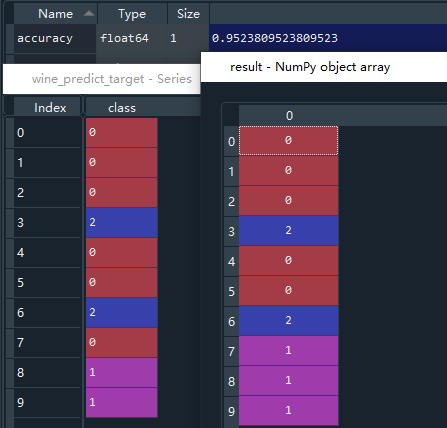
# 评分法计算准确率
accuracy = knn.score(x_test,y_test)
# 预测,输入预测用的x值
result = knn.predict(wine_predict_feature)
accuracy存放准确率,result存放预测结果,最终准确率为0.952,最终的分类结果和wine_predict_target存放的实际分类结果有微小偏差。
完整代码如下:
import pandas as pd
from sklearn import datasetswine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值wine_data = pd.DataFrame(data = wine_data) #转换成DataFrame类型数据
wine_target = pd.DataFrame(data = wine_target)
# 将target插入到第一列
wine_data.insert(0,'class',wine_target)# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序,可以省略这一步
wine = wine_data.sample(frac=1).reset_index(drop=True)# 拿10行出来作验证
wine_predict = wine[-10:].reset_index(drop=True)
wine_predict_feature = wine_predict.drop('class',axis=1) #用于验证的特征值,输入到predict()函数中
wine_predict_target = wine_predict['class'] #目标值,用于和最终预测结果比较wine = wine[:-10] #删除后10行
features = wine.drop(columns=['class'],axis=1) #删除class这一列,产生返回值,这个是特征值
targets = wine['class'] #class这一列就是目标值
# 相当于13个特征值对应1个目标# 划分测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)# 先标准化再预测
from sklearn.preprocessing import StandardScaler #导入标准化缩放方法
scaler = StandardScaler() #变量scaler接收标准化方法# 传入特征值进行标准化
x_train = scaler.fit_transform(x_train) #对训练的特征值标准化
x_test = scaler.fit_transform(x_test) #对测试的特征值标准化
wine_predict_feature = scaler.fit_transform(wine_predict_feature)# 使用K近邻算法分类
from sklearn.neighbors import KNeighborsClassifier #导入k近邻算法库
# k近邻函数
knn = KNeighborsClassifier(n_neighbors=5,algorithm='auto')# 训练,把训练的特征值和训练的目标值传进去
knn.fit(x_train,y_train)
# 检测模型正确率--传入测试的特征值和目标值
# 评分法,根据x_test预测结果,把结果和真实的y_test比较,计算准确率
accuracy = knn.score(x_test,y_test)
# 预测,输入预测用的x值
result = knn.predict(wine_predict_feature)
相关文章:
【机器学习】K近邻算法:原理、实例应用(红酒分类预测)
案例简介:有178个红酒样本,每一款红酒含有13项特征参数,如镁、脯氨酸含量,红酒根据这些特征参数被分成3类。要求是任意输入一组红酒的特征参数,模型需预测出该红酒属于哪一类。 1. K近邻算法介绍 1.1 算法原理 原理&a…...

基于安卓android微信小程序的快递取件及上门服务系统
项目介绍 本文从管理员、用户的功能要求出发,快递取件及上门服务中的功能模块主要是实现管理员服务端;首页、个人中心、用户管理、快递下单管理、预约管理、管理员管理、系统管理、订单管理,用户客户端;首页、快递下单、预约管理…...
leetCode 92.反转链表 II + 图解
92. 反转链表 II - 力扣(LeetCode) 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 206. 反转链表 - 力扣(LeetCode&am…...
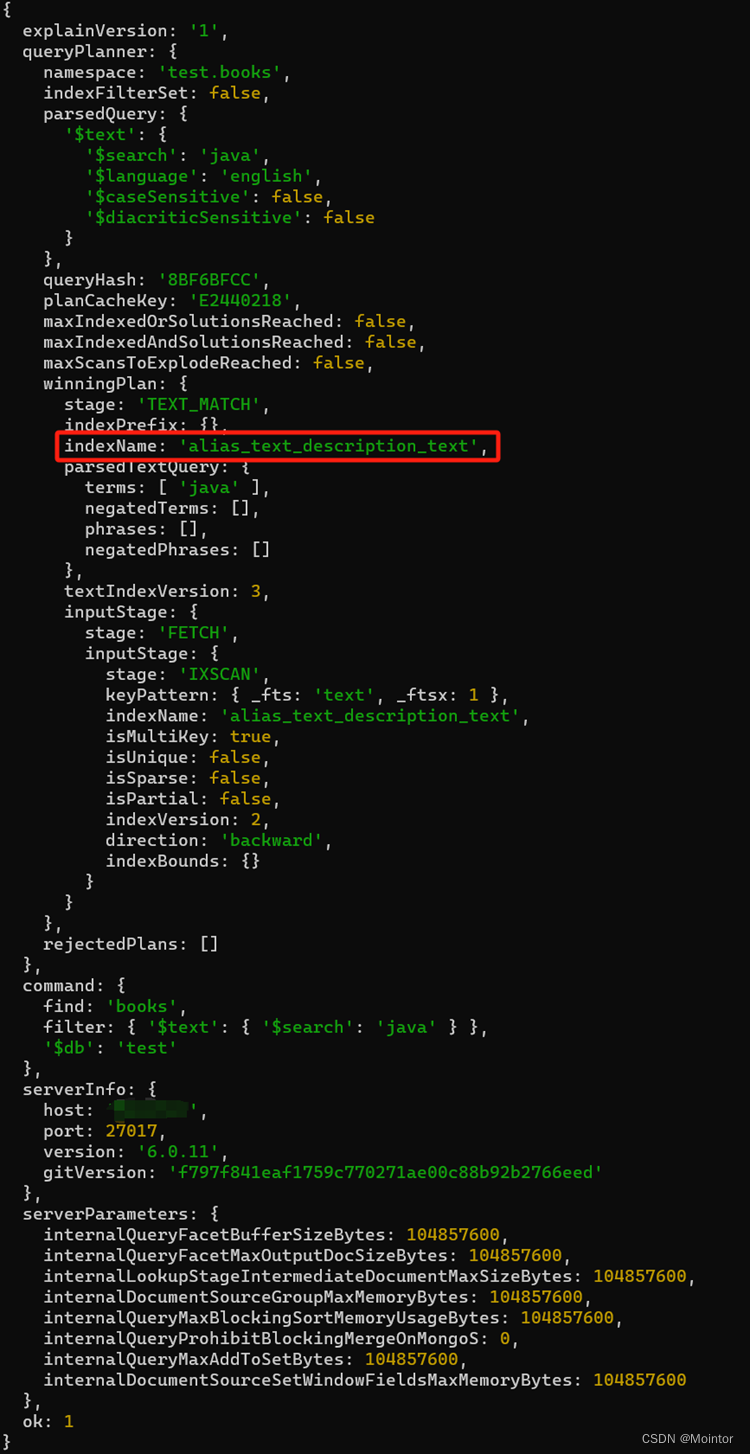
【MongoDB】索引 – 通配符索引
一、准备工作 这里准备一些数据 db.books.drop();db.books.insert({_id: 1, name: "Java", alias: "java 入门", description: "入门图书" }); db.books.insert({_id: 2, name: "C", alias: "c", description: "C 入…...

python安装pip install报错Could not fetch URL https://pypi.org/simple/pip/...更换镜像源
更换镜像源 一. 现象pycharm使用 pip install xxx安装包时,一直报错: 二. 原因:三. 解决办法:一. 临时使用二. 永久更改三. 永久更改1. Windowswindows环境下Windows(示例win10) 2. Linux or Mac3. Pycharm…...

C++ 算数运算符 学习资料
C 算数运算符 在 C 中,算数运算符用于执行各种数学运算。以下是常用的算数运算符: :加法运算符,用于将两个表达式相加。-:减法运算符,用于从一个表达式中减去另一个表达式。*:乘法运算符&…...

问题 H: 棋盘游戏(二分图变式)
题意:要求找到 不放车就无法达到最大数的点 的个数 题解:1.以行列绘制二分图 2.先算出最大二分匹配数 3.依次遍历所有边 删除该边,并计算二分匹配最大值 (若小于原最大值即为重要点)࿰…...

SQL 主从数据库实时备份
在SQL数据库中,主从复制(Master-Slave Replication)是一种常见的实时备份和高可用性解决方案。这种配置允许将一个数据库服务器(主服务器)的更改同步到一个或多个其他数据库服务器(从服务器)&am…...
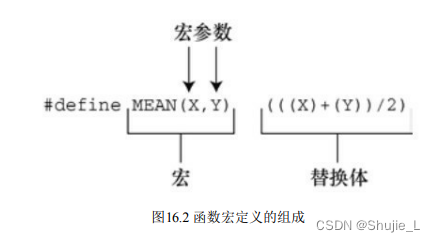
C/C++:在#define中使用参数
文章目录 在#define中使用参数参考资料 在#define中使用参数 在#define中使用参数可以创建外形和作用与函数类似的类函数宏。带有 参数的宏看上去很像函数,因为这样的宏也使用圆括号。类函数宏定义的圆 括号中可以有一个或多个参数,随后这些参数出现在替…...

Hive 查询优化
Hive 查询优化 -- 本地 set mapreduce.framework.namelocal; set hive.exec.mode.local.autotrue; set mapperd.job.trackerlocal; -- yarn set mapreduce.framework.nameyarn; set hive.exec.mode.local.autofalse; set mapperd.job.trackeryarn-- 向量模式 set hive.vectori…...

【Java 进阶篇】JQuery 案例:优雅的隔行换色
在前端的设计中,页面的美观性是至关重要的。而其中一个简单而实用的设计技巧就是隔行换色。通过巧妙地使用 JQuery,我们可以轻松地实现这一效果,为网页增添一份优雅。本篇博客将详细解析 JQuery 隔行换色的实现原理和应用场景,让我…...

Redis 常用的类型和 API
前言 在当今的软件开发中,数据存储与操作是至关重要的一部分。为了满足日益增长的数据需求和对性能的追求,出现了许多不同类型的数据库。其中,Redis 作为一种基于内存且高性能的键值存储数据库,因其快速的读取速度、丰富的数据结…...
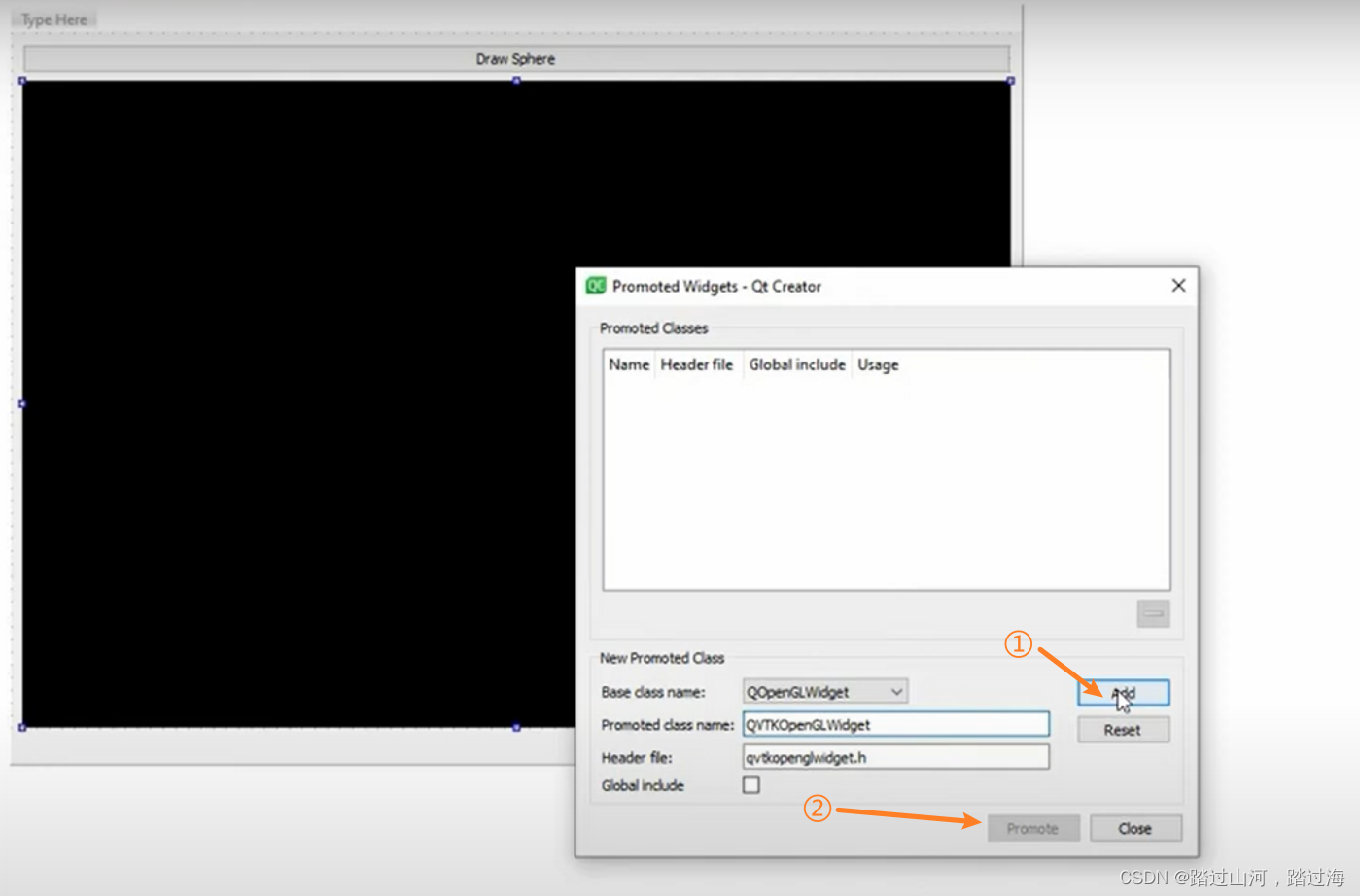
在qt的设计师界面没有QVTKOpenGLWidget这个类,只有QOpenGLWidget,那么我们如何得到QVTKOpenGLWidget呢?
文章目录 前言不过,时过境迁,QVTKOpenGLWidget用的越来越少,官方推荐使用qvtkopengnativewidget代替QVTKOpenGLWidget 前言 在qt的设计师界面没有QVTKOpenGLWidget这个类,只有QOpenGLWidget,我们要使用QVTKOpenGLWidget,那么我们如何得到QVTKOpenGLWidget呢? 不过,时过境迁,Q…...
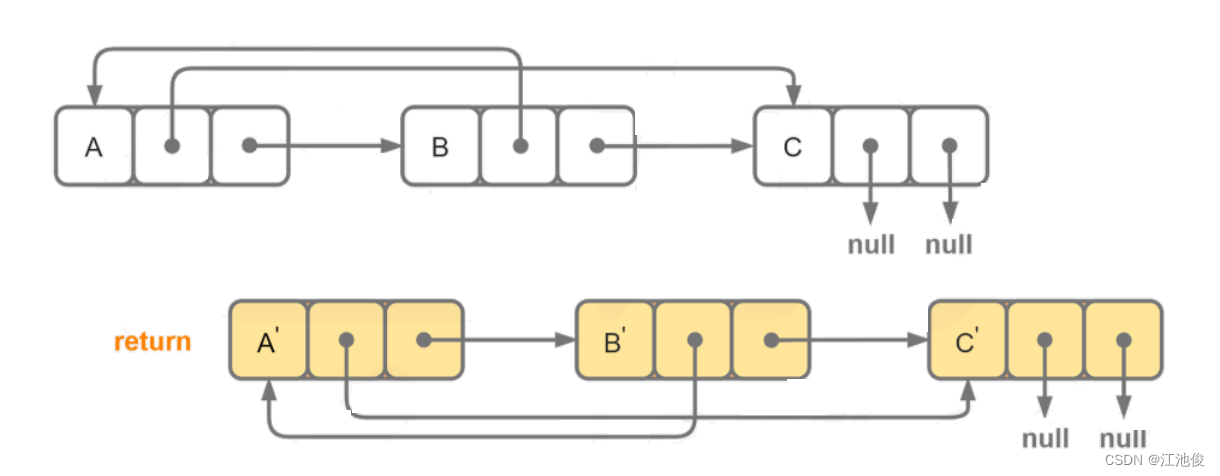
力扣每日一道系列 --- LeetCode 138. 随机链表的复制
📷 江池俊: 个人主页 🔥个人专栏: ✅数据结构探索 ✅LeetCode每日一道 🌅 有航道的人,再渺小也不会迷途。 LeetCode 138. 随机链表的复制 给你一个长度为 n 的链表,每个节点包含一个额外增加…...

无人零售:创新优势与广阔前景
无人零售:创新优势与广阔前景 无人零售在创新方面具有优势。相比发展较为成熟的欧洲和日本的自动贩卖机市场,中国的无人零售市场人均占有量较少,这表明该市场具有广阔的前景和巨大的市场潜力。 此外,无人零售涉及到许多相关行业&…...
【华为OD题库-022】阿里巴巴找黄金宝箱(IV)-java
题目 一贫如洗的椎夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地,藏宝地有编号从0-N的子,每个箱子上面有一个数字,箱子排列成一个环,编号最大的箱子的下一个是编号为0的箱子。请输出每个箱子贴的数字之后的第…...
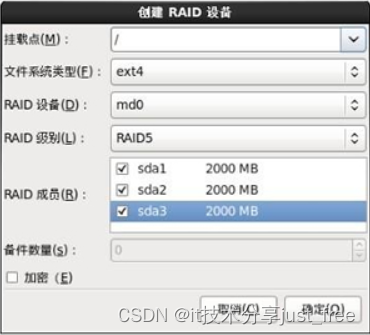
Linux 图形界面配置RAID
目录 RAID 1 配置 RAID 5配置 , RAID 配置起来要比 LVM 方便,因为它不像 LVM 那样分了物理卷、卷组和逻辑卷三层,而且每层都需要配置。我们在图形安装界面中配置 RAID 1和 RAID 5,先来看看 RAID 1 的配置方法。 RAID 1 配置 配置 RAID 1…...
、( 什么是qps,tps,并发量,pv,uv)、(什么是接口幂等性问题,如何解决?))
(脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别)、( 什么是qps,tps,并发量,pv,uv)、(什么是接口幂等性问题,如何解决?)
1 脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么? 2 什么是qps,tps,并发量,pv,uv 3 什么是接口幂等性问题,如何解决? 1 脏读,不可重复读…...
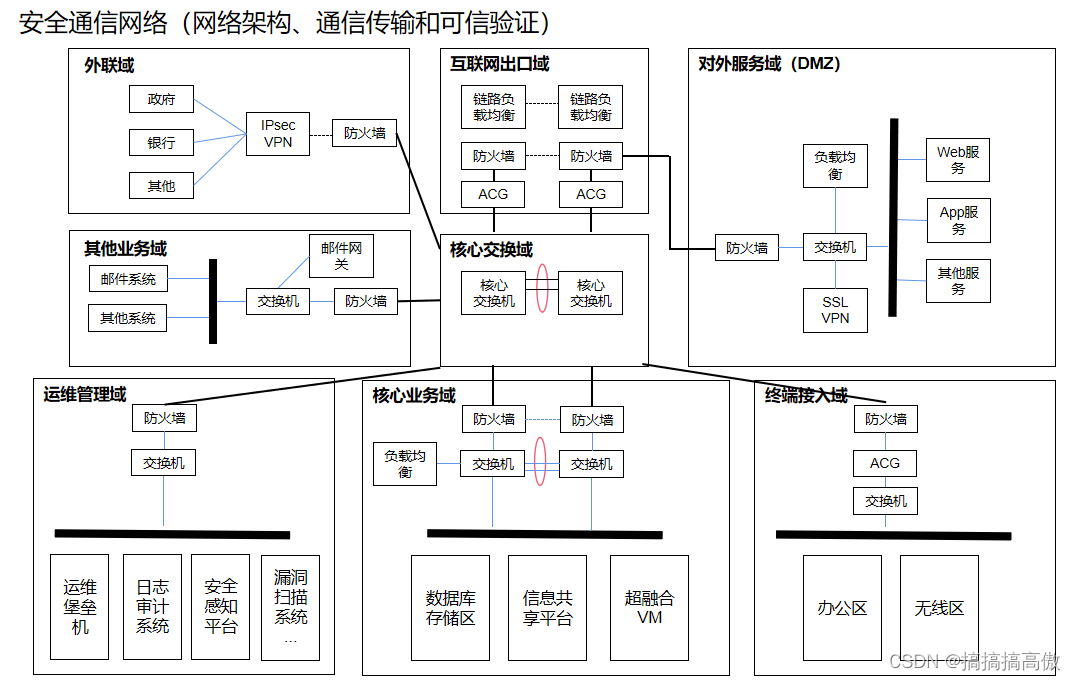
安全通信网络(设备和技术注解)
网络安全等级保护相关标准参考《GB/T 22239-2019 网络安全等级保护基本要求》和《GB/T 28448-2019 网络安全等级保护测评要求》 密码应用安全性相关标准参考《GB/T 39786-2021 信息系统密码应用基本要求》和《GM/T 0115-2021 信息系统密码应用测评要求》 1网络架构 1.1保证网络…...
深度学习_12_softmax_图片识别优化版代码
因为图片识别很多代码都包装在d2l库里了,直接调用就行了 完整代码: import torch from torch import nn from d2l import torch as d2l"获取训练集&获取检测集" batch_size 256 train_iter, test_iter d2l.load_data_fashion_mnist(ba…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...