自定义Graph Component:1.2-其它Tokenizer具体实现
本文主要介绍了Rasa中相关Tokenizer的具体实现,包括默认Tokenizer和第三方Tokenizer。前者包括JiebaTokenizer、MitieTokenizer、SpacyTokenizer和WhitespaceTokenizer,后者包括BertTokenizer和AnotherWhitespaceTokenizer。
一.JiebaTokenizer
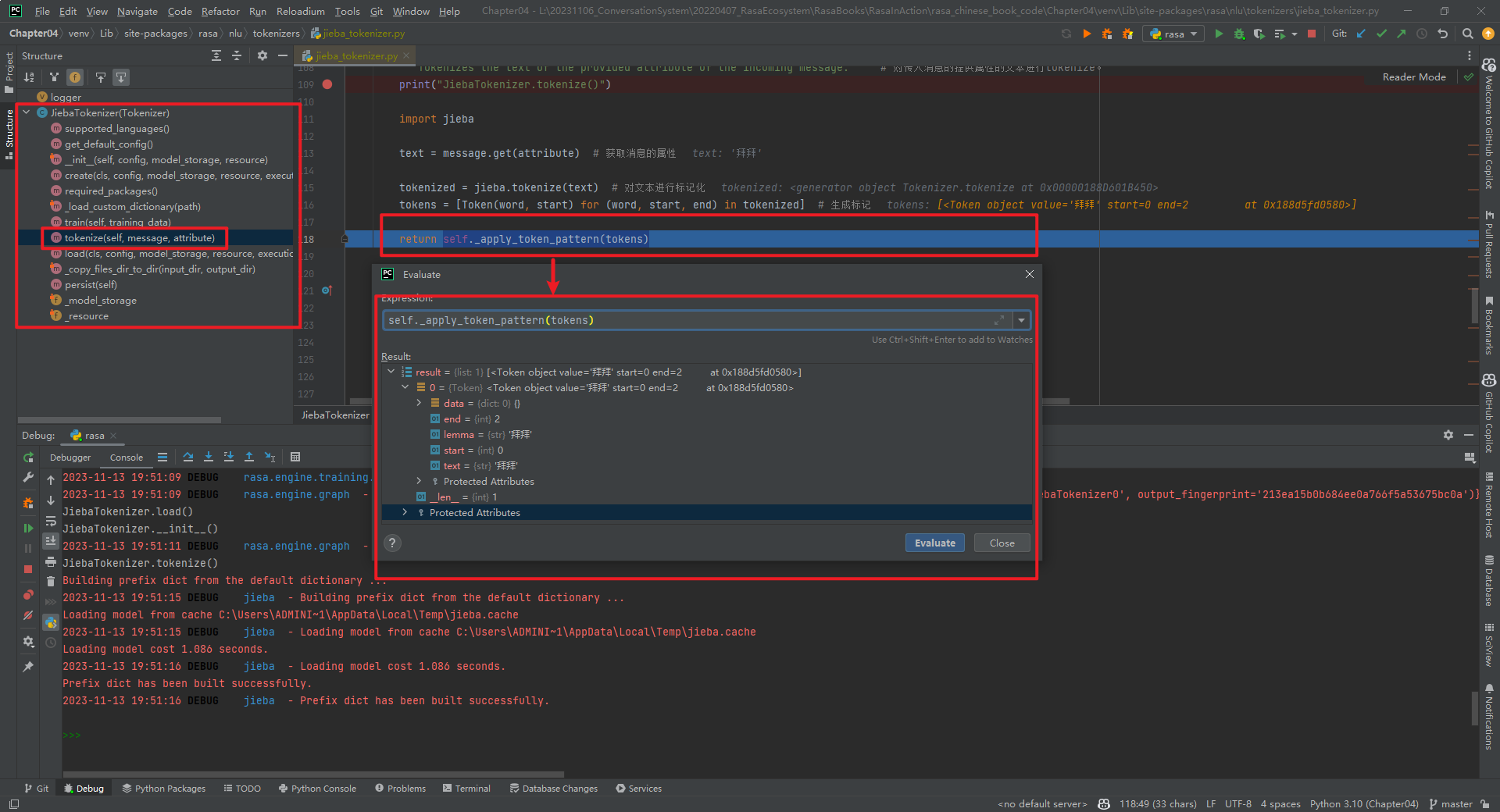
JiebaTokenizer类整体代码结构,如下所示:
加载自定义字典代码,如下所示[3]:
@staticmethod
def _load_custom_dictionary(path: Text) -> None:"""Load all the custom dictionaries stored in the path. # 加载存储在路径中的所有自定义字典。More information about the dictionaries file format can be found in the documentation of jieba. https://github.com/fxsjy/jieba#load-dictionary"""print("JiebaTokenizer._load_custom_dictionary()")import jiebajieba_userdicts = glob.glob(f"{path}/*") # 获取路径下的所有文件。for jieba_userdict in jieba_userdicts: # 遍历所有文件。logger.info(f"Loading Jieba User Dictionary at {jieba_userdict}") # 加载结巴用户字典。jieba.load_userdict(jieba_userdict) # 加载用户字典。
实现分词的代码为tokenize()方法,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenize。print("JiebaTokenizer.tokenize()")import jiebatext = message.get(attribute) # 获取消息的属性tokenized = jieba.tokenize(text) # 对文本进行标记化tokens = [Token(word, start) for (word, start, end) in tokenized] # 生成标记return self._apply_token_pattern(tokens)
self._apply_token_pattern(tokens)数据类型为List[Token]。Token的数据类型为:
class Token:# 由将单个消息拆分为多个Token的Tokenizers使用def __init__(self,text: Text,start: int,end: Optional[int] = None,data: Optional[Dict[Text, Any]] = None,lemma: Optional[Text] = None,) -> None:"""创建一个TokenArgs:text: The token text. # token文本start: The start index of the token within the entire message. # token在整个消息中的起始索引end: The end index of the token within the entire message. # token在整个消息中的结束索引data: Additional token data. # 附加的token数据lemma: An optional lemmatized version of the token text. # token文本的可选词形还原版本"""self.text = textself.start = startself.end = end if end else start + len(text)self.data = data if data else {}self.lemma = lemma or text
特别说明:JiebaTokenizer组件的is_trainable=True。
二.MitieTokenizer
MitieTokenizer类整体代码结构,如下所示:
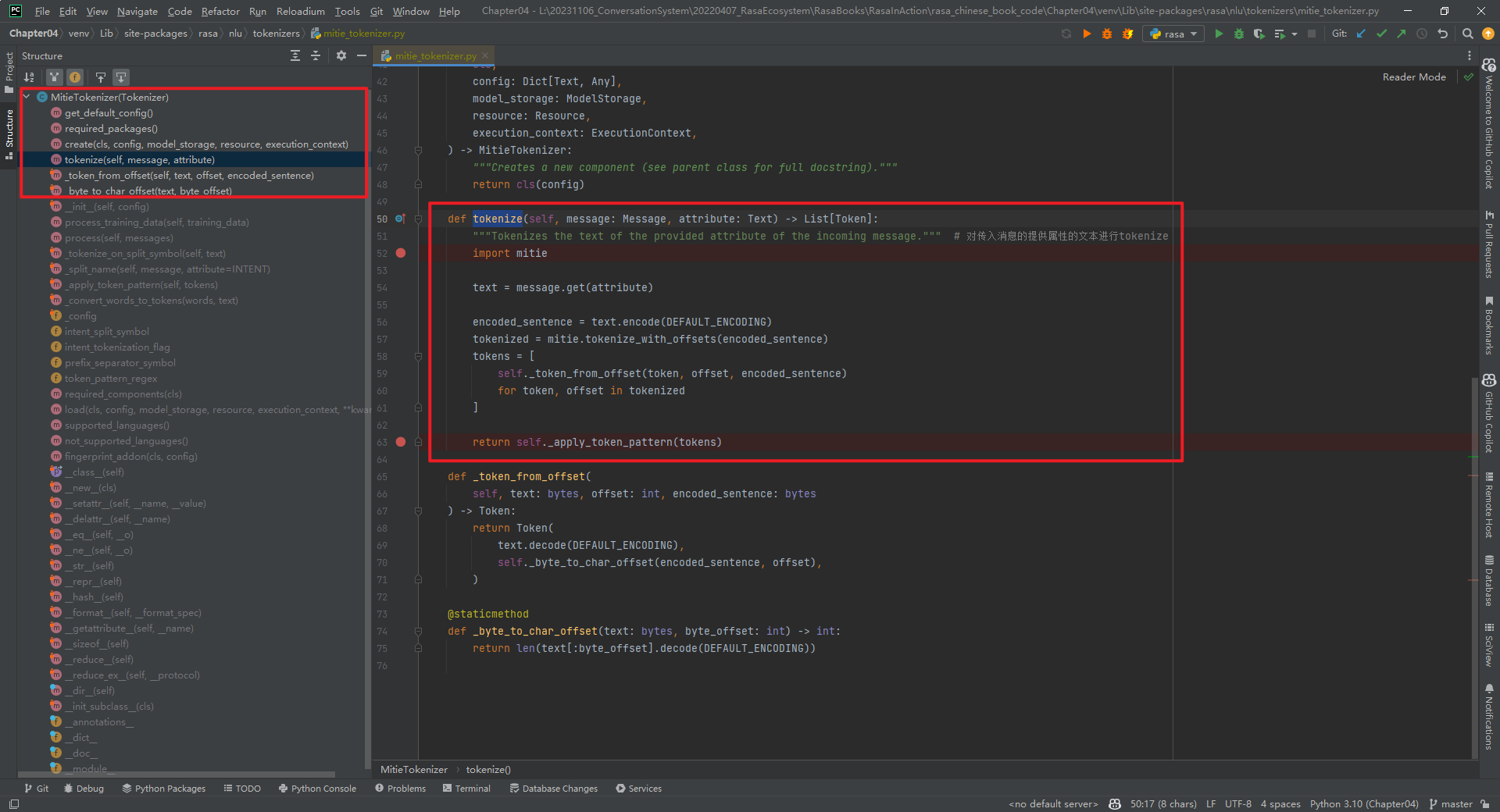
核心代码tokenize()方法代码,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenizeimport mitietext = message.get(attribute)encoded_sentence = text.encode(DEFAULT_ENCODING)tokenized = mitie.tokenize_with_offsets(encoded_sentence)tokens = [self._token_from_offset(token, offset, encoded_sentence)for token, offset in tokenized]return self._apply_token_pattern(tokens)
特别说明:mitie库在Windows上安装可能麻烦些。MitieTokenizer组件的is_trainable=False。
三.SpacyTokenizer
首先安装Spacy类库和模型[4][5],如下所示:
pip3 install -U spacy
python3 -m spacy download zh_core_web_sm
SpacyTokenizer类整体代码结构,如下所示:
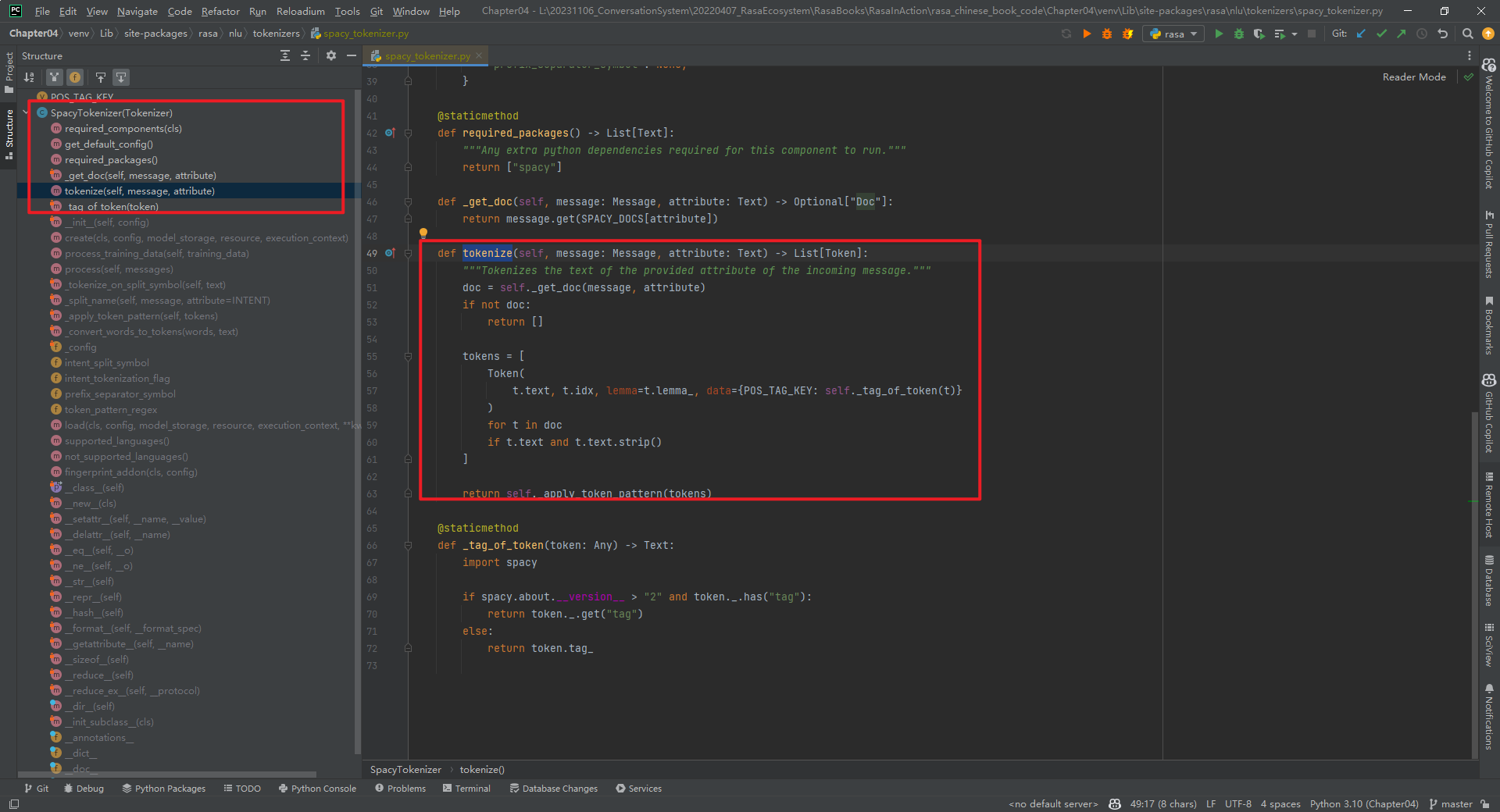
核心代码tokenize()方法代码,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenizedoc = self._get_doc(message, attribute) # doc是一个Doc对象if not doc:return []tokens = [Token(t.text, t.idx, lemma=t.lemma_, data={POS_TAG_KEY: self._tag_of_token(t)})for t in docif t.text and t.text.strip()]
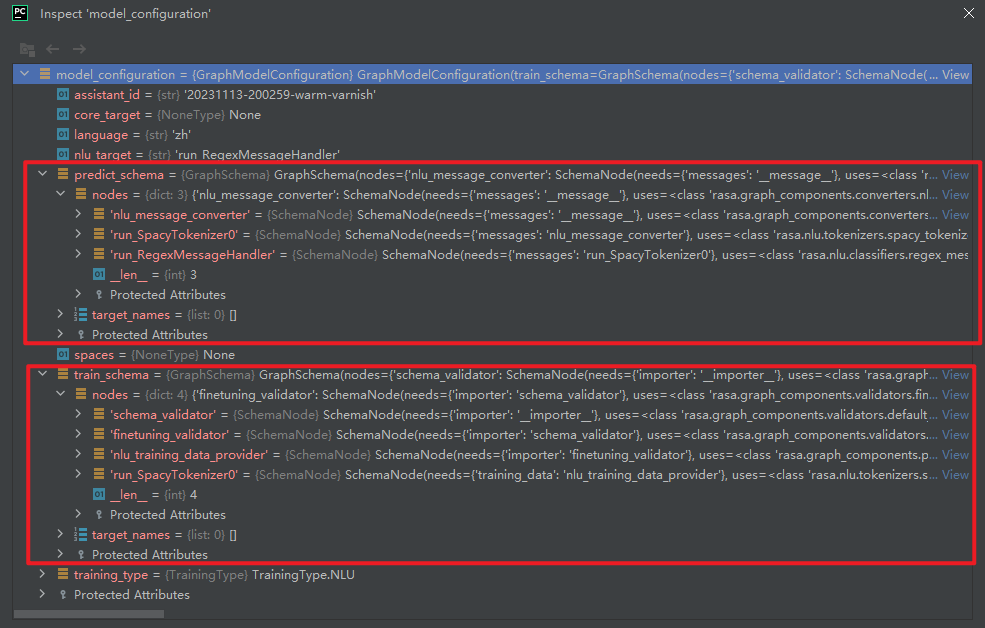
特别说明:SpacyTokenizer组件的is_trainable=False。即SpacyTokenizer只有运行组件run_SpacyTokenizer0,没有训练组件。如下所示:
四.WhitespaceTokenizer
WhitespaceTokenizer主要是针对英文的,不可用于中文。WhitespaceTokenizer类整体代码结构,如下所示:
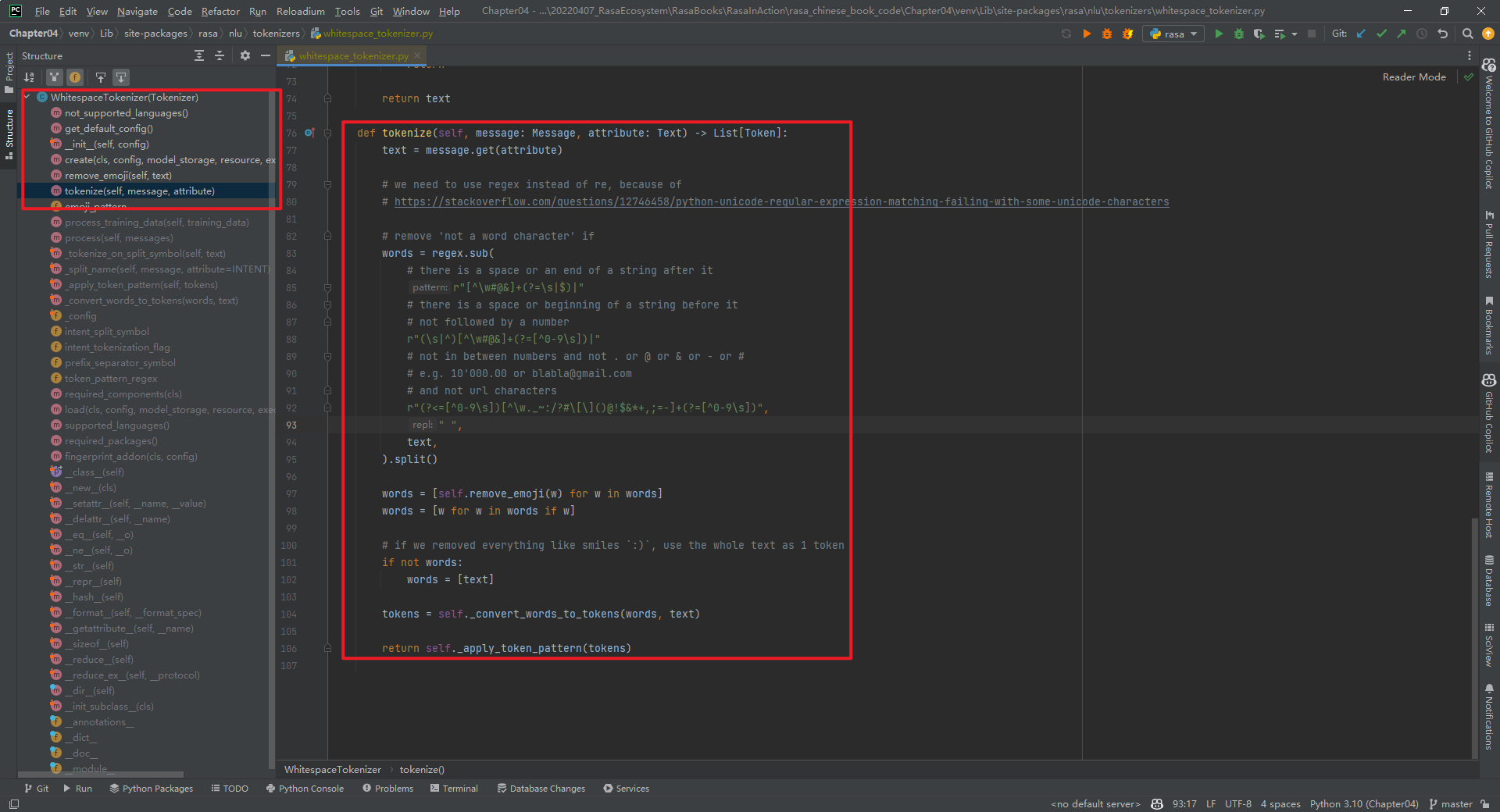
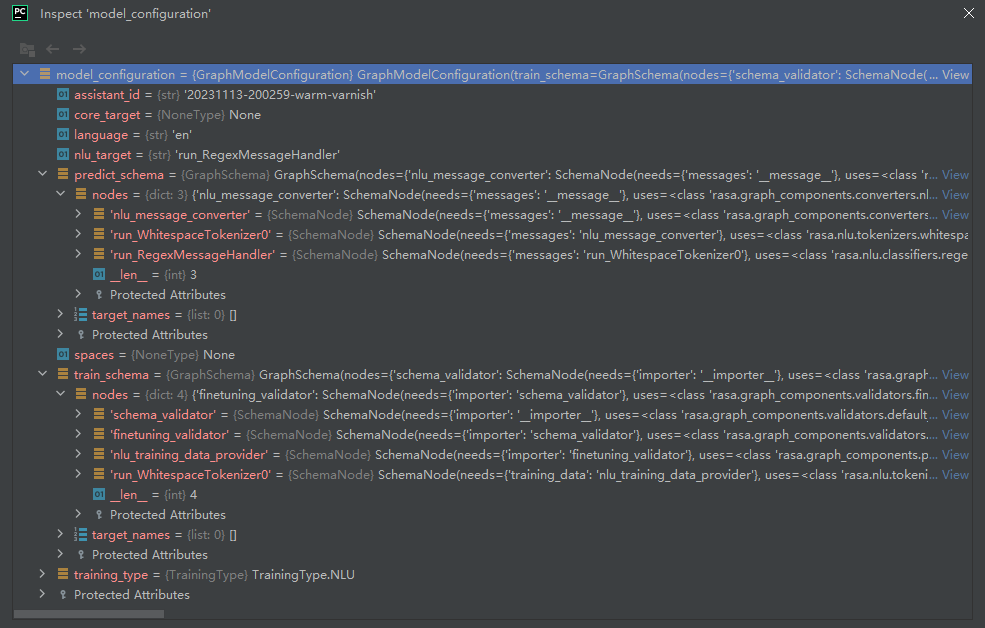
其中,predict_schema和train_schema,如下所示:
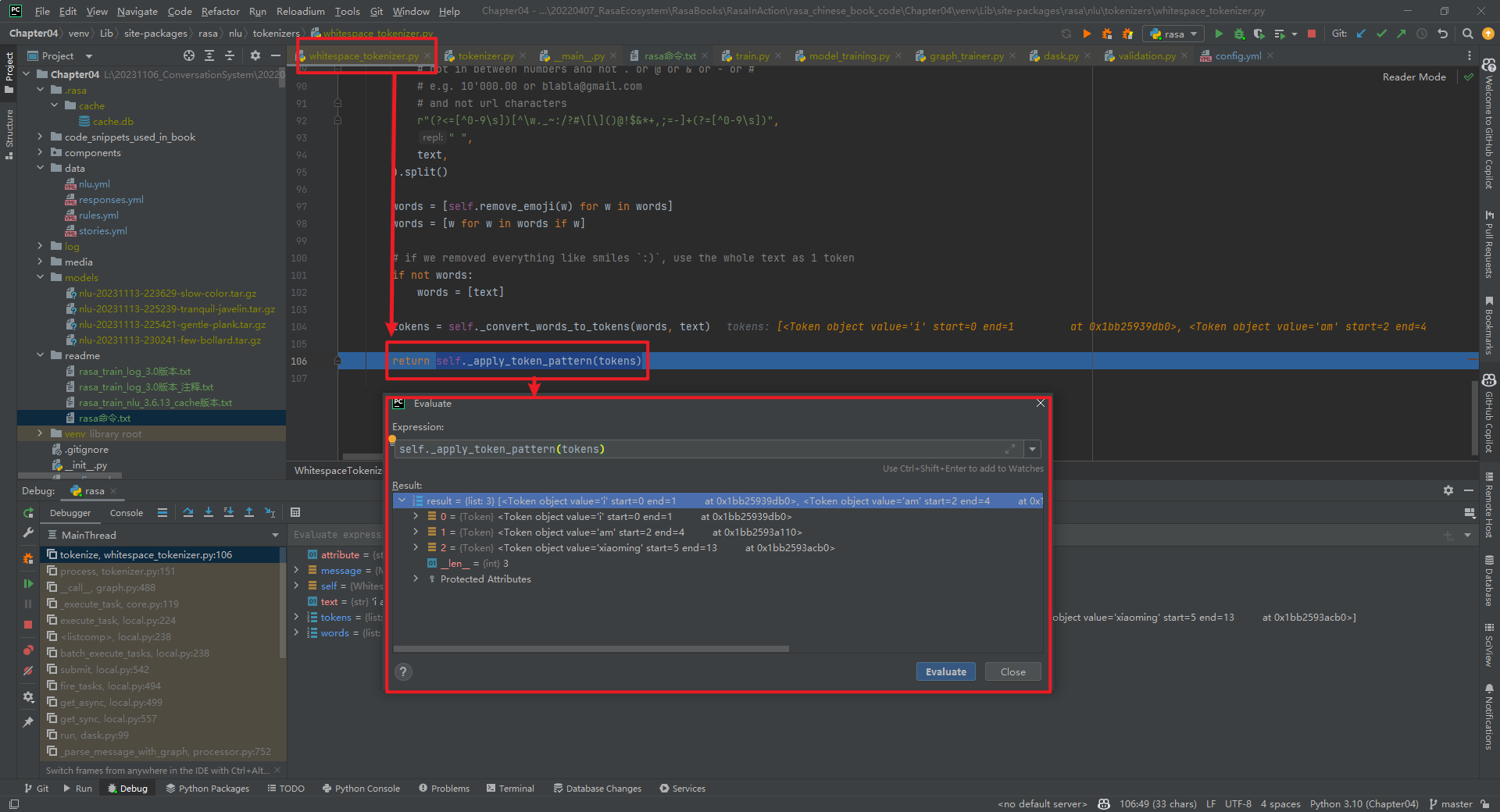
rasa shell nlu --debug结果,如下所示:
特别说明:WhitespaceTokenizer组件的is_trainable=False。
五.BertTokenizer
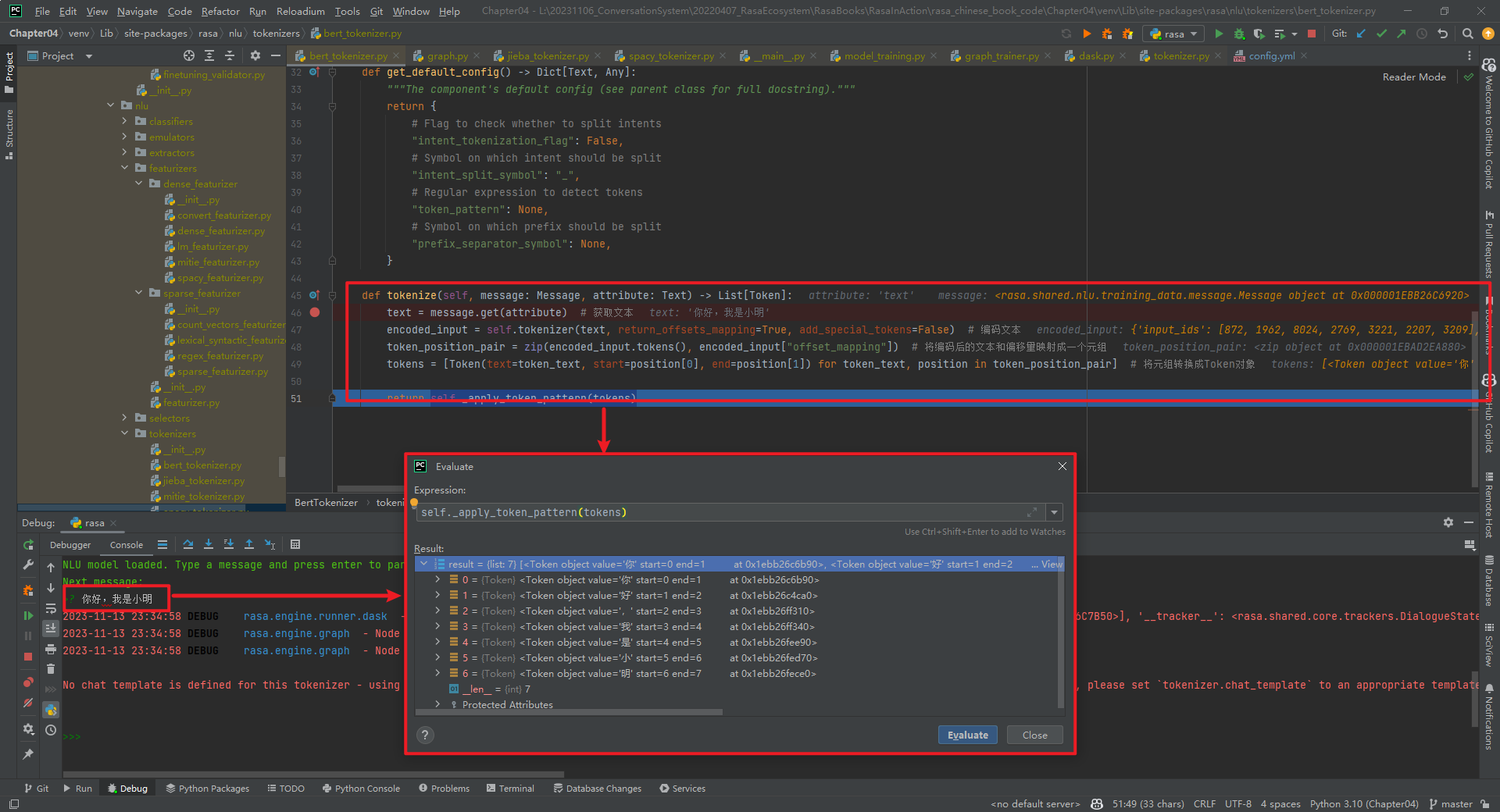
rasa shell nlu --debug结果,如下所示:
  BertTokenizer代码具体实现,如下所示:
"""
https://github.com/daiyizheng/rasa-chinese-plus/blob/master/rasa_chinese_plus/nlu/tokenizers/bert_tokenizer.py
"""
from typing import List, Text, Dict, Any
from rasa.engine.recipes.default_recipe import DefaultV1Recipe
from rasa.shared.nlu.training_data.message import Message
from transformers import AutoTokenizer
from rasa.nlu.tokenizers.tokenizer import Tokenizer, Token@DefaultV1Recipe.register(DefaultV1Recipe.ComponentType.MESSAGE_TOKENIZER, is_trainable=False
)
class BertTokenizer(Tokenizer):def __init__(self, config: Dict[Text, Any] = None) -> None:""":param config: {"pretrained_model_name_or_path":"", "cache_dir":"", "use_fast":""}"""super().__init__(config)self.tokenizer = AutoTokenizer.from_pretrained(config["pretrained_model_name_or_path"], # 指定预训练模型的名称或路径cache_dir=config.get("cache_dir"), # 指定缓存目录use_fast=True if config.get("use_fast") else False # 是否使用快速模式)@classmethoddef required_packages(cls) -> List[Text]:return ["transformers"] # 指定依赖的包@staticmethoddef get_default_config() -> Dict[Text, Any]:"""The component's default config (see parent class for full docstring)."""return {# Flag to check whether to split intents"intent_tokenization_flag": False,# Symbol on which intent should be split"intent_split_symbol": "_",# Regular expression to detect tokens"token_pattern": None,# Symbol on which prefix should be split"prefix_separator_symbol": None,}def tokenize(self, message: Message, attribute: Text) -> List[Token]:text = message.get(attribute) # 获取文本encoded_input = self.tokenizer(text, return_offsets_mapping=True, add_special_tokens=False) # 编码文本token_position_pair = zip(encoded_input.tokens(), encoded_input["offset_mapping"]) # 将编码后的文本和偏移量映射成一个元组tokens = [Token(text=token_text, start=position[0], end=position[1]) for token_text, position in token_position_pair] # 将元组转换成Token对象return self._apply_token_pattern(tokens)
特别说明:BertTokenizer组件的is_trainable=False。
六.AnotherWhitespaceTokenizer
AnotherWhitespaceTokenizer代码具体实现,如下所示:
from __future__ import annotations
from typing import Any, Dict, List, Optional, Textfrom rasa.engine.graph import ExecutionContext
from rasa.engine.recipes.default_recipe import DefaultV1Recipe
from rasa.engine.storage.resource import Resource
from rasa.engine.storage.storage import ModelStorage
from rasa.nlu.tokenizers.tokenizer import Token, Tokenizer
from rasa.shared.nlu.training_data.message import Message@DefaultV1Recipe.register(DefaultV1Recipe.ComponentType.MESSAGE_TOKENIZER, is_trainable=False
)
class AnotherWhitespaceTokenizer(Tokenizer):"""Creates features for entity extraction."""@staticmethoddef not_supported_languages() -> Optional[List[Text]]:"""The languages that are not supported."""return ["zh", "ja", "th"]@staticmethoddef get_default_config() -> Dict[Text, Any]:"""Returns the component's default config."""return {# This *must* be added due to the parent class."intent_tokenization_flag": False,# This *must* be added due to the parent class."intent_split_symbol": "_",# This is a, somewhat silly, config that we pass"only_alphanum": True,}def __init__(self, config: Dict[Text, Any]) -> None:"""Initialize the tokenizer."""super().__init__(config)self.only_alphanum = config["only_alphanum"]def parse_string(self, s):if self.only_alphanum:return "".join([c for c in s if ((c == " ") or str.isalnum(c))])return s@classmethoddef create(cls,config: Dict[Text, Any],model_storage: ModelStorage,resource: Resource,execution_context: ExecutionContext,) -> AnotherWhitespaceTokenizer:return cls(config)def tokenize(self, message: Message, attribute: Text) -> List[Token]:text = self.parse_string(message.get(attribute))words = [w for w in text.split(" ") if w]# if we removed everything like smiles `:)`, use the whole text as 1 tokenif not words:words = [text]# the ._convert_words_to_tokens() method is from the parent class.tokens = self._convert_words_to_tokens(words, text)return self._apply_token_pattern(tokens)
特别说明:AnotherWhitespaceTokenizer组件的is_trainable=False。
参考文献:
[1]自定义Graph Component:1.1-JiebaTokenizer具体实现:https://mp.weixin.qq.com/s/awGiGn3uJaNcvJBpk4okCA
[2]https://github.com/RasaHQ/rasa
[3]https://github.com/fxsjy/jieba#load-dictionary
[4]spaCy GitHub:https://github.com/explosion/spaCy
[5]spaCy官网:https://spacy.io/
[6]https://github.com/daiyizheng/rasa-chinese-plus/blob/master/rasa_chinese_plus/nlu/tokenizers/bert_tokenizer.py
相关文章:
自定义Graph Component:1.2-其它Tokenizer具体实现
本文主要介绍了Rasa中相关Tokenizer的具体实现,包括默认Tokenizer和第三方Tokenizer。前者包括JiebaTokenizer、MitieTokenizer、SpacyTokenizer和WhitespaceTokenizer,后者包括BertTokenizer和AnotherWhitespaceTokenizer。 一.JiebaTokenizer Ji…...
docker-compose 部署 MySQL 8
目录 前言MySQL 配置文件(my.cnf)docker-compose.yml安装卸载 前言 Windows/Linux 系统通过 docker-compose 部署 MySQL8.0。 MySQL 配置文件(my.cnf) # 服务端参数配置 [mysqld] usermysql # MySQL启动用户 default-storage-engineINNODB # 创建新表时…...

Java设计模式-结构型模式-适配器模式
适配器模式 适配器模式应用场景案例类适配器模式对象适配器模式接口适配器模式适配器模式在源码中的使用 适配器模式 如图:国外插座标准和国内不同,要使用国内的充电器,就需要转接插头,转接插头就是起到适配器的作用 适配器模式&…...

CCF编程能力等级认证GESP—C++4级—样题1
CCF编程能力等级认证GESP—C4级—样题1 单选题(每题 2 分,共 30 分)判断题(每题 2 分,共 20 分)编程题 (每题 25 分,共 50 分)第一题 绝对素数第二题 填幻方 参考答案单选题判断题编程题1编程题…...
Git用pull命令后再直接push有问题
在gitlab新建一个项目,然后拉取到本地,用: git init git pull <远程主机名> 然后就是在本地工作区增加所有文件及文件夹。再添加、提交,都没问题: 但是,git push出问题: 说明本地仓库和…...
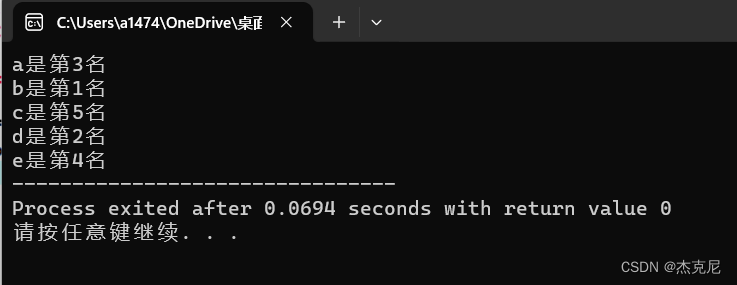
C语言不可不敲系列:跳水比赛排名问题
目录 1题干: 2解题思路: 3代码: 4运行结果: 5总结: 1题干: 5位运动员参加了10米台跳水比赛,有人让他们预测比赛结果 A选手说:B第二,我第三; B选手说:我第二,E第四&am…...
获取地图文档)
Python与ArcGIS系列(二)获取地图文档
目录 0 简述1 获取当前地图文档2 获取磁盘中的地图文档3 获取地图文档的图层0 简述 本篇开始介绍实际代码操作,即利用arcpy(python 包)执行地理数据分析、数据转换、数据管理和地图自动化。通过arcpy调用ArcGIS中任意工具,将其与其他python工具结合使用,形成自己的工作流…...

Ansible自动化部署工具-role模式安装filebeat实际案例分析
语法以及实际案例 平时我们在进行日志收集的时候,往往会在每台机器上安装filebeat,并且由于每台机器运行服务的不同,那么收集日志的配置文件也是不一样的,如何快速高效的部署filebeat以及拥有不同的配置文件就是我们要思考的问题&…...

B2B企业如何打造独立站:从策略到实施的全面指南
随着数字化转型的加速,B2B企业越来越认识到独立站的重要性。然而,如何建设一个优秀的独立站,以及如何将独立站与企业的整体战略相结合,是许多企业面临的挑战。本文将详细探讨B2B企业如何从策略到实施打造一个成功的独立站。 一、…...
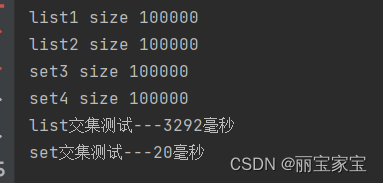
JAVA 中集合取交集
日常工作 经常需要取两个数据集的交集。对常用的List 和Set集合做了一个测试 public static void main(String[] args) {List<Integer> list1 Lists.newArrayList();List<Integer> list2 Lists.newArrayList();Set<Integer> set3 Sets.newHashSet();Set&l…...

Android13 Launcher3 定制
去掉Google搜索栏 aosp/packages/apps/Launcher3/src_build_config/com/android/launcher3/BuildConfig.java 修改QSB_ON_FIRST_SCREEN为false public static final boolean QSB_ON_FIRST_SCREEN false;去掉抽屉菜单,所有应用都放到桌面 增加控制变量 aosp/pac…...

其他word转化为PDF的方式
将 Word 文档转换为 PDF 格式,除了使用 COM 自动化外,还有其他一些方法可以在 Java 中实现。这些方法通常更加可靠和跨平台。以下是一些常用的方法: 1. 使用 Apache POI 和 Apache PDFBox 这种方法涉及使用 Apache POI 库读取 Word 文档&am…...
【Axure】axure rp 导入元件库和使用,主流元件库下载使用
vant 元件库下载:Vant4 设计资源 element UI 元件库下载:element ui 设计资源 Andt Design Vue 下载设计资源:Andt Design Vue Andt Design Pro下载设计资源:Andt Design Pro Arco Design 设计资源:Arco Design …...

ISP 处理流程
#灵感# 摆烂时间太长了,感觉知识忘光光了。重新学习,常学常新。 因为公司文档都不让摘抄、截取,所以内容是工作的一些自己记录和网络内容,不对的欢迎批评指正。 1、ISP概述 ISP是Image Signal Processor 的简称,也就…...

【计算思维】少儿编程蓝桥杯青少组计算思维题考试真题及解析C
【科技素养】少儿编程蓝桥杯青少组计算思维题考试真题及解析 1.天平的左右两端分别放有一些砝码,如下图所示,右边的砝码不变,从左边最多拿走几个砝码,可以使天平左右两边平衡: A、1 B、2 C、3 D、4 2.把下面的图形…...
百望云斩获“新华信用金兰杯”ESG优秀案例 全面赋能企业绿色数字化
近年来,中国ESG蓬勃发展,在政策体系构建、ESG信披ESG投资和国际合作等方面都取得了阶段性成效,ESG生态不断完善。全社会对ESG的认识及实践也在不断深化,ESG实践者的队伍在不断发展壮大。 ESG作为识别企业高质量发展的重要指标&…...
bclinux aarch64 ceph 14.2.10 对象存储 http网关 CEPH OBJECT GATEWAY Civetweb
相关内容 bclinux aarch64 ceph 14.2.10 文件存储 Ceph File System, 需要部署mds: ceph-deploy mds-CSDN博客 ceph-deploy bclinux aarch64 ceph 14.2.10【3】vdbench fsd 文件系统测试-CSDN博客 ceph-deploy bclinux aarch64 ceph 14.2.10【2】vdbench rbd 块设…...

2023年亚太杯数学建模思路 - 复盘:人力资源安排的最优化模型
文章目录 0 赛题思路1 描述2 问题概括3 建模过程3.1 边界说明3.2 符号约定3.3 分析3.4 模型建立3.5 模型求解 4 模型评价与推广5 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 描述 …...

【广州华锐互动】VR居家防火逃生模拟演练增强训练的真实性
VR软件开发公司广州华锐互动在消防培训领域已开发了多款VR产品,今天为大家介绍VR居家防火逃生模拟演练系统,这是一种基于虚拟现实技术的消防教育训练设备,通过模拟真实的火灾场景,让使用者身临其境地体验火灾逃生过程,…...
)
PaddleClas学习1——使用PPLCNet模型对车辆属性进行识别(python)
使用PPLCNet模型对车辆属性进行识别 1. 配置PaddlePaddle,PaddleClas环境1.1 安装PaddlePaddle(1)创建 docker 容器(2)退出/进入 docker 容器(3) 安装验证1.2 安装python3.8(可选)1.3 安装 PaddleClas2. 模型推理2.1 下载官方提供的车辆属性模型2.2 基于 Python 预测引…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...