简单的python爬虫工具,B站视频爬虫
分享一个我自己写的pythonB站视频爬虫,写的比较粗糙
当然网上一堆B站视频获取的工具,也不差我这个粗糙的python脚本,就是分享出来大家一起讨论学习,如果大家有什么好的想法和功能我们可以一起聊聊。
这里分享一个我自己用的B站视频下载的工具BBDown,很好用,作者也是在一直更新。
必要工具ffmpeg,建议还是放在你的python项目目录下(我不知道为什么配置的环境变量没有生效)
这个如果想爬取高清视频就把自己的cookie加到api_headers。这里进度条加载有点问题,就是视频太小了进度条可能加载不完全,还有就是视频合成也有点问题,有时视频合成不了
代码如下:
import argparseimport requests, re, sys, os, time
from contextlib import closing
from urllib import parse
from lxml import etree
import subprocess
from tqdm import tqdmclass BiliBili:def __init__(self, dirname):self.search_headers = {'authority': 'search.bilibili.com','Accept': '*/*','Referer': 'https://www.bilibili.com/','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61',}self.video_headers = {'authority': 'www.bilibili.com','Referer': 'https://www.bilibili.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/118.0.0.0 Safari/537.36'}self.api_headers = {'authority': 'api.bilibili.com','Accept': '*/*','Referer': 'https://www.bilibili.com/','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9',# 'cookie':"",'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/119.0.0.0 Safari/537.36'}self.sess = requests.Session()self.dir = dirnamedef downloader(self, data_url, title):"""数据下载Parameters:data_url: 数据地址title: 标题"""if self.dir not in os.listdir():os.mkdir(self.dir)size = 0with closing(self.sess.get(data_url, headers=self.video_headers, stream=True)) as response:chunk_size = 1000content_size = int(response.headers['content-length'])content_mb = content_size / 1000 / 1000if response.status_code == 200:sys.stdout.write(' [开始下载]\n')sys.stdout.write(' [文件大小]: %0.2f MB\n' % content_mb)video_name = os.path.join(self.dir, title)# 保存视频,并输出进度with tqdm(total=content_size, desc=' [下载进度]',leave=False, ncols=100, unit='B',unit_scale=True) as pbar:with open(video_name, 'wb') as file:if content_mb < 3:file.write(response.content)for i in range(5):pbar.update(content_size/5)else:for data in response.iter_content(chunk_size=chunk_size):file.write(data)pbar.update(len(data))size += len(data)file.flush()sys.stdout.write('\n')sys.stdout.write(' [下载完成]' + '\r')sys.stdout.flush()if size / content_size == 1:print('\n')else:print('~~~链接异常~~~'+'\r')time.sleep(1)def search_video(self, keyword, page=1):"""搜索页视频信息Parameters:keyword: 关键词page: 页码Returns:videos[titles,bvs]titles:标题bvs: bv号"""url = f'https://search.bilibili.com/all?keyword={parse.quote(keyword)}&page={page}&o=30'req = self.sess.get(url=url, headers=self.search_headers)html = etree.fromstring(req.text, etree.HTMLParser())bvs = html.xpath('//div[@class="bili-video-card__info--right"]/a/@href')[:3]titles = html.xpath('//div[@class="bili-video-card__info--right"]/a/h3/@title')[:3]videos = []for i, j in zip(titles, bvs):for c in u'´★☆❤◦\/:*?"<>|':i = i.replace(c, '')tmp = [i, j]videos.append(tmp)# 输出搜索页面视频标题和视频urlprint(videos)return videos# titles, bvsdef get_download_url(self, arcurl):"""获取详情页数据信息Parameters:arcurl: 视频播放地址Returns:accept_description: 视频清晰度video_data: 视频地址audio_data: 音频地址title: 标题"""xp = 'BV\d.{9}'if re.findall(xp, arcurl):bv = re.findall(xp, arcurl)[0]url = f'https://api.bilibili.com/x/web-interface/view?bvid={bv}' # avid&cidelse:print('视频BV号解析失败,请检查输入的bv号是否正确')exit(0)req1 = self.sess.get(url=url, headers=self.video_headers)ac_json = req1.json()avid = ac_json['data']['aid']cid = ac_json['data']['cid']url2 = f'https://api.bilibili.com/x/player/wbi/playurl?avid={avid}&cid={cid}&fnval=4048' # playurltitle = ac_json['data']['title']req2 = self.sess.get(url=url2, headers=self.api_headers)playinfo_dict = req2.json()accept_description = playinfo_dict["data"]["accept_description"] # 视频清晰度# id = [playinfo_dict["data"]["dash"]["video"][0]["id"]]audio_data = [playinfo_dict["data"]["dash"]["audio"][0]["baseUrl"]] # 音频数据video_data = [playinfo_dict["data"]["dash"]["video"][0]["baseUrl"]]# print(id)if not audio_data and not video_data:print('视频解析失败')exit(0)return [accept_description, video_data, audio_data,title]def merge_data(self, dir, video_name):"""视频合成Parameters:dir: 目录video_name: 视频名"""time.sleep(0.1)if video_name+'_2' in os.listdir(self.dir):print( '合成视频已存在')exit(0)else:print('视频合成开始:', video_name)cmd = f"cd {dir} & ffmpeg -y -i {video_name}.mp4 -i {video_name}.mp3 -c:v copy -c:a aac -strict experimental -map 0:0 -map 1:0 {video_name}_2.mp4 && del {video_name}.mp4 {video_name}.mp3"subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)print('视频合成结束:', video_name+'\r')def search_downloader(self, keyword,page=1):"""批量爬取搜索页视频Parameters:keyword: 关键词page: 页码"""if self.dir not in os.listdir():os.mkdir(self.dir)for j in range(page):s_video = self.search_video(keyword, j+1)for i in range(len(s_video)):title = s_video[i][0]arcurl = s_video[i][1]if title not in os.listdir(self.dir):videos_data = self.get_download_url(arcurl)[1]audio_data = self.get_download_url(arcurl)[2]if not videos_data[0] or not audio_data[0]:print('第[ %d ]页:%s视频或音频解析失败,跳过下载:' % (1 + j, title))continue # Skip video download if video or audio parsing failsfname = title + '.mp4'print('第[ %d ]页:视频[ %s ]下载中:' % (1 + j, fname)) # 打印页码和指定下载视频self.downloader(videos_data[0], fname)print('视频下载完成!')fname = title + '.mp3'print('第[ %d ]页:音频[ %s ]下载中:' % (1 + j, fname)) # 打印页码和指定下载视频self.downloader(audio_data[0], fname)print('音频下载完成!')# 创建临时文本文件用于合并视频音频try:video_name = titledirz = self.dirself.merge_data(dirz, video_name)except:print('请安装FFmpeg,并配置环境变量 http://ffmpeg.org/')def a_video_download(self,bv):"""单个视频爬取Parameters:bv: 关bv号"""video_info = self.get_download_url(bv)title = video_info[3]fname = "{0}.mp4".format(title)print('视频[ %s ]下载中:' % fname) # 打印页码和指定下载视频self.downloader(video_info[1][0], fname)print('视频下载完成!')fname = '{0}.mp3'.format(title)print('音频[ %s ]下载中:' % fname) # 打印页码和指定下载视频self.downloader(video_info[2][0], fname)print('音频下载完成!')self.merge_data(self.dir,video_info[3])if __name__ == '__main__':if len(sys.argv) == 1:sys.argv.append('--help')parser = argparse.ArgumentParser()parser.add_argument('-d', '--dir', required=True, help='必要,下载路径')parser.add_argument('-bv', '--bvid', required=False, help='下载指定bv视频')parser.add_argument('-s', '--search', required=False, action='store_true', help='批量下载搜索页视频')parser.add_argument('-k', '--keyword', required=False, help='搜索关键词内容')parser.add_argument('-p', '--pages', required=False, help='需要下载页码数', type=int)args = parser.parse_args()B = BiliBili(args.dir)if args.search:if args.keyword and args.pages is None:print('请输入搜索关键词和页码')exit(0)B.search_downloader(args.keyword, args.pages)if args.bvid:if args.search or args.keyword or args.pages:print('下载单个视频请只输入BV号')exit(0)B.a_video_download(args.bvid)# return [accept_description, video_data, audio_data, title]# B = BiliBili('猫')# url = 'https://www.bilibili.com/video/BV1Jy4y1K7yp/'# a=B.get_download_url(url)# B.downloader(a[1][0], a[3])
相关文章:

简单的python爬虫工具,B站视频爬虫
分享一个我自己写的pythonB站视频爬虫,写的比较粗糙 当然网上一堆B站视频获取的工具,也不差我这个粗糙的python脚本,就是分享出来大家一起讨论学习,如果大家有什么好的想法和功能我们可以一起聊聊。 这里分享一个我自己用的B站视…...
Shopee买家号有什么作用?如何才能拥有大量的虾皮买家号?
对于卖家而言,用shopee买家号进行测评有以下几点好处: 1、随时随地可以给自己店铺下单、评价、点星 2、成本很低:都是自己准备一些资料进行注册的,因此成本也是比较可控的。 3、自己管理更加安全可控:每个账号都是独…...

OCR名片识别:手机电脑大比拼,哪个更胜一筹?
随着名片的使用越来越普遍,如何快速准确地识别名片信息成为很多人的需求。而名片OCR识别技术正好能够满足这一需求,但是面对不同的识别方案,很多人会感到困惑。本文将介绍名片OCR识别的方案选择,分别介绍手机和电脑上的识别方案&a…...

深度学习OCR中文识别 - opencv python 计算机竞赛
文章目录 0 前言1 课题背景2 实现效果3 文本区域检测网络-CTPN4 文本识别网络-CRNN5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习OCR中文识别系统 ** 该项目较为新颖,适合作为竞赛课题方向,…...
 条件控制、循环语句)
Python(七) 条件控制、循环语句
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...

SpringCloud GateWay自定义过滤器之GatewayFilter和AbstractGatewayFactory
一、GatewayFilter GatewayFilter 是一个简单的接口,用于定义网关过滤器的行为。一个网关过滤器就是一个实现了 GatewayFilter 接口的类,它可以执行在请求进入网关或响应离开网关时的某些操作。过滤器可以用于修改请求或响应,记录日志&#…...
不会英语能学编程吗?0基础学编程什么软件好?
不会英语能学编程吗?0基础学编程什么软件好? 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件,象如图这个…...

程序员副业接单做私活避坑指南
不建议大家在接单这个事情上投入太大精力,如果你“贼心不改”,建议大家以比较随缘的方式对待这件事情。 接单平台 下文是接单平台,内容来自知乎,转载过来的原因有2个: 方便大家了解这些平台各自的优势,可以…...

day57
今日内容概要 模板层 模板之过滤器 模板之标签(if else for) 模板之继承 导入模板 模型层 单表的操作 十几种常见的查询方法 基于下划线的查询方法 外键字段的增删改查 正反向查询(多表跨表) 模板之过滤器 语法: {{obj|filter__name:param}} 变量名字|…...

以太坊链多节点本地化【最详细的部署搭建及维护文档】
文章目录 一、维护人员素养1.1 岗位技能1.2 人员素质二、区块链节点及区块链浏览器搭建2.1 编写说明2.1.1 文档说明2.1.2 配置信息2.1.3 部署文档信息2.2 node环境安装2.2.1 基础命令安装2.2.2 安装node2.3 centos7 部署docker环境2.3.1 卸载旧版本2.3.2 使用 yum 安装2.3.3 使…...
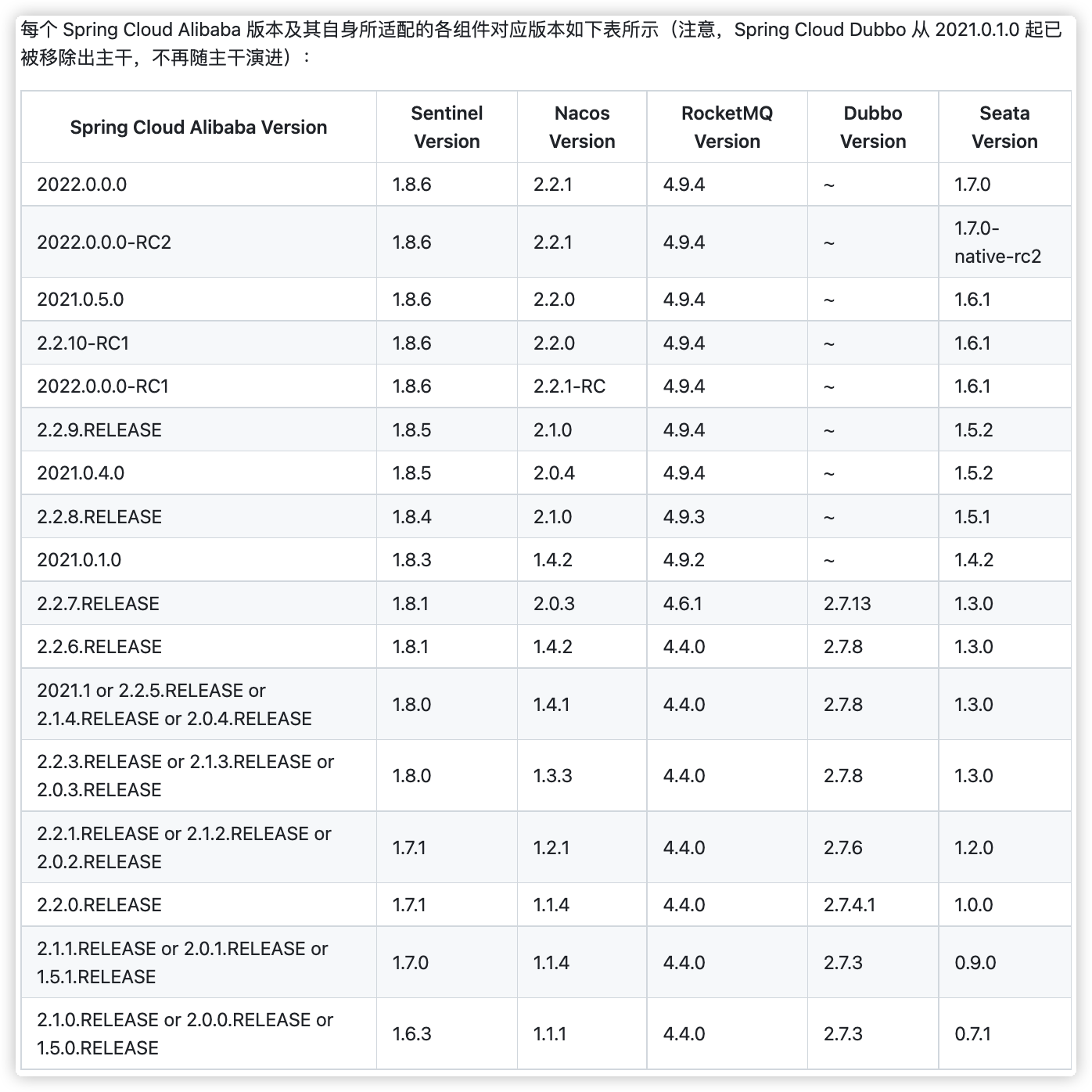
微服务架构演进
系统架构演变 没有最好的架构,只有最合适的架构;架构发展过程:单体架构》垂直架构》SOA 面向服务架构》微服务架构;推荐看看《淘宝技术这十年》; 单体架构 互联网早期,一般的网站应用流量较小࿰…...
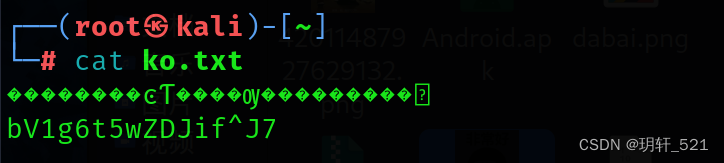
BUUCTF 九连环 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 下载附件,解压得到一张.jpg图片。 密文: 解题思路: 1、一张图片,典型的图片隐写。放到Kali中,使用binwalk检测,确认图片中隐藏zip压缩包。 使…...

编码自动化:使用MybatisX初体验,太爽了!
使用Mybatis当前最火的插件:MybatisX。 在IDEA中安装MyBatisX插件。 该插件主要功能如下: 生成mapper xml文件 快速从代码跳转到mapper及从mapper返回代码 mybatis自动补全及语法错误提示 集成mybatis Generate GUI界面 根据数据库注解,…...
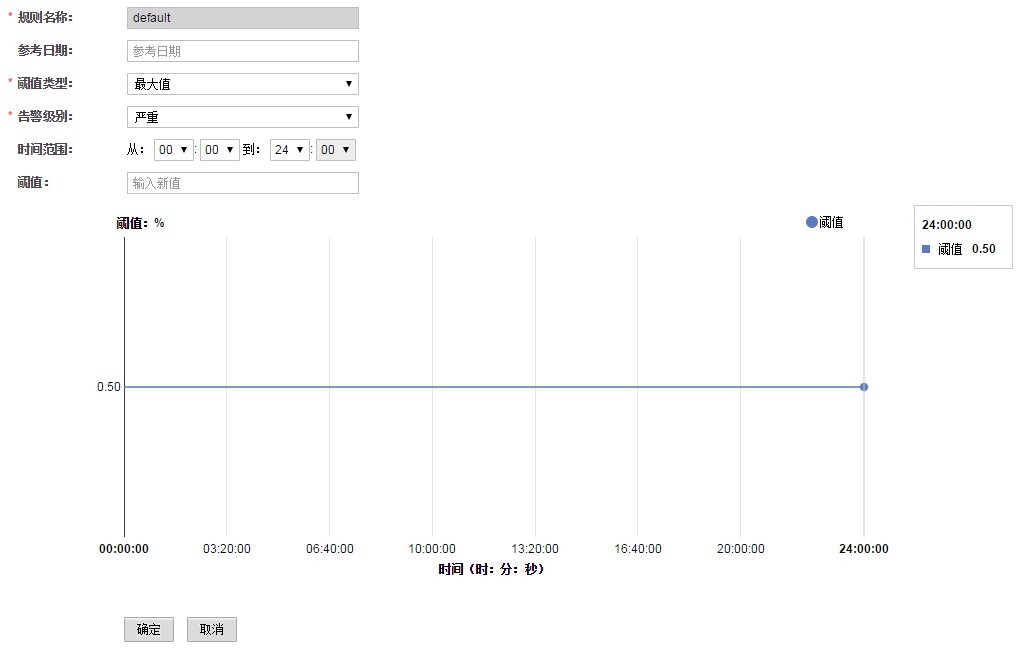
大数据-之LibrA数据库系统告警处理(ALM-12047 网络读包错误率超过阈值)
告警解释 系统每30秒周期性检测网络读包错误率,并把实际错误率和阈值(系统默认阈值0.5%)进行比较,当检测到网络读包错误率连续多次(默认值为5)超过阈值时产生该告警。 用户可通过“系统设置 > 阈值配置…...
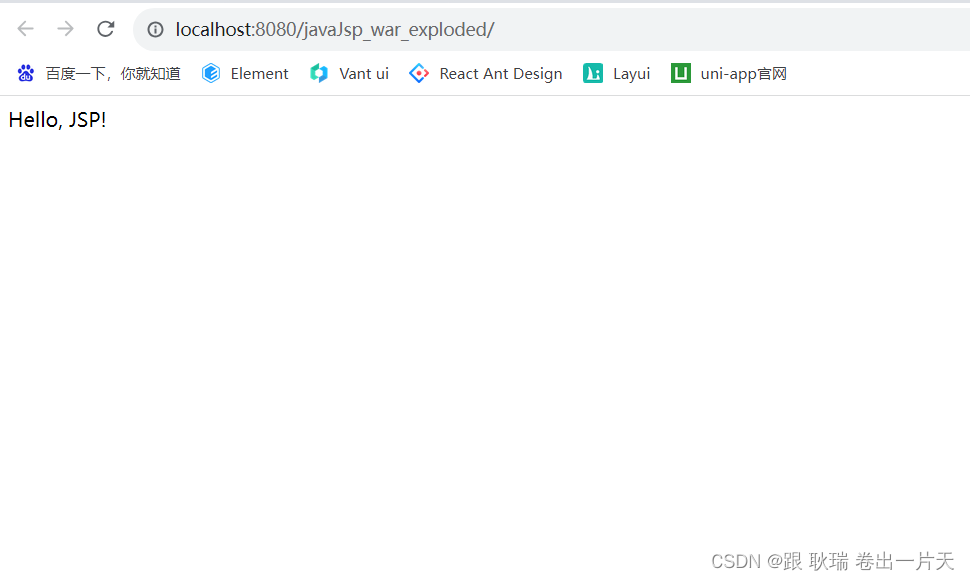
JSP 报错 Cannot resolve method ‘print(java.lang.String)‘问题解决
这里 我写了一段比较基础的代码 <%// 定义局部变量String message "Hello, JSP!";out.print(message); %>但是 项目跑起来又是可以的 其实就是缺少了 JAR包 依赖 我们 可以在项目环境中找到 pom.xml dependencies标签内 加入 如下代码 <dependency>…...
(Centos8))
Linux系统下安装RabbitMQ超简单教程(非详细)(Centos8)
文章目录 一、下载所需安装包二、安装三、启动rabbitmq四、添加远程用户五、图形化访问六、修改rabbitmq的启动端口和管理端口(没有这个需求就不用看了)七、需要注意版本问题可能遇到的错误和解决方式version GLIBC_2.34 类型错误undefined function rab…...

2024江苏专转本流程与时间节点
2024江苏专转本考生,提前看一下转本的流程与时间节点!适用于江苏三年制、五年一贯制专转本考试: 1. 专转本工作通知(2023年12月上旬) 若无特殊情况,到12月中旬,江苏省教育厅会发布关于做好2024…...
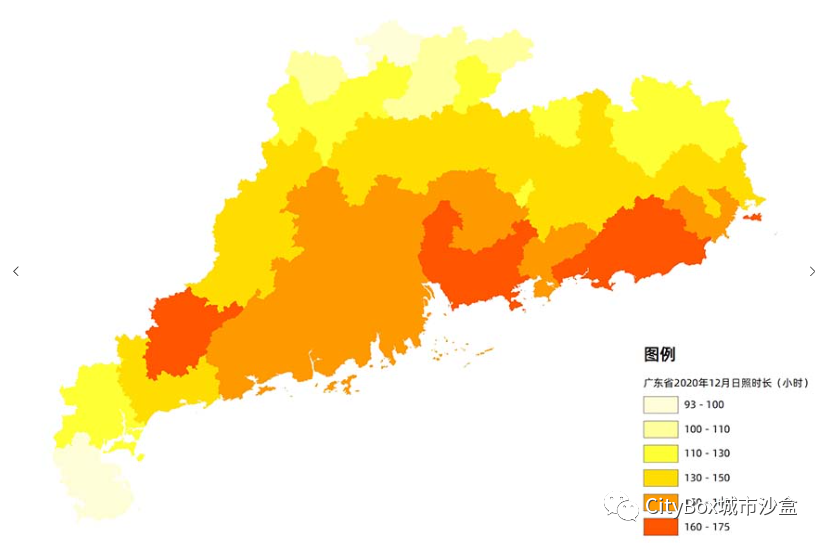
全国各区县日照时长数据,逐月数据均有!
今天给大家分享的是全国各区县日照时长月数据,包括不同月份不同地区的日照时长。这些数据可以帮助我们了解不同地区在不同月份的日照情况,为能源利用、农业生产和气候变化研究提供参考。 基本信息 数据名称: 全国各区县日照时长月数据 数据格式: shpex…...
candence出现no connect property onpin,,,,错误,该怎么办?
原因是上面有引脚添加了 属性no connect,但依然连接了网络,这个时候需要把线剪切,然后看到引脚上有个X, 解决方法: 工具栏"place >no connect "X 再连上线,再生成网标的时候, 就不报错了…...
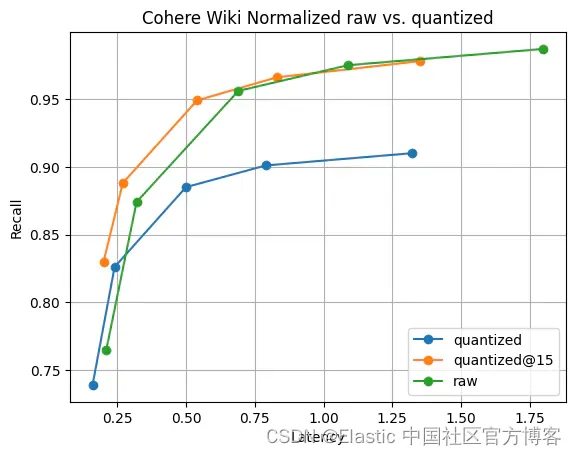
Elasticsearch:Lucene 中引入标量量化
作者:BENJAMIN TRENT 我们如何将标量量化引入 Lucene。 Lucene 中的自动字节量化 虽然 HNSW 是一种强大而灵活的存储和搜索向量的方法,但它确实需要大量内存才能快速运行。 例如,查询 768 维的 1MM float32 向量大约需要 1,000,000*4*(7681…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...

基于Matter与Thread协议实现本地化智能电表数据采集与家居集成
1. 项目概述:将传统电表接入智能家居的“最后一公里”家里那个不起眼的电表,每个月只在抄表员来或者收到账单时才会被想起。但你知道吗?在法国,以及许多其他采用类似标准的地区,这个默默无闻的“铁盒子”其实一直在实时…...

Charles弱网测试六维参数实战:从丢包率到DNS延迟的精准复现
1. 为什么弱网测试不能只靠“模拟3G”按钮点一下就完事做移动端或Web前端的同学,大概率都听过这句话:“上线前跑一遍Charles,切个2G网络测下加载。”——听起来很专业,实际一查日志,发现90%的团队连Charles的Throttlin…...

yuzu模拟器:在PC上完美运行Switch游戏的终极解决方案
yuzu模拟器:在PC上完美运行Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想要在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器作为目前最成熟的开源Switch模拟…...

开发者在构建多模态AI应用时如何借助TaoToken简化模型集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在构建多模态AI应用时如何借助TaoToken简化模型集成 构建一个集成了文本、图像等多模态能力的AI应用,开发者常常…...