深度学习OCR中文识别 - opencv python 计算机竞赛
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 文本区域检测网络-CTPN
- 4 文本识别网络-CRNN
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习OCR中文识别系统 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
在日常生产生活中有大量的文档资料以图片、PDF的方式留存,随着时间推移 往往难以检索和归类 ,文字识别(Optical Character
Recognition,OCR )是将图片、文档影像上的文字内容快速识别成为可编辑的文本的技术。
高性能文档OCR识别系统是基于深度学习技术,综合运用Tensorflow、CNN、Caffe
等多种深度学习训练框架,基于千万级大规模文字样本集训练完成的OCR引擎,与传统的模式识别的技术相比,深度学习技术支持更低质量的分辨率、抗干扰能力更强、适用的场景更复杂,文字的识别率更高。
本项目基于Tensorflow、keras/pytorch实现对自然场景的文字检测及OCR中文文字识别。
2 实现效果
公式检测

纯文字识别

3 文本区域检测网络-CTPN
对于复杂场景的文字识别,首先要定位文字的位置,即文字检测。
简介
CTPN是在ECCV
2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。由于CTPN是从Faster
RCNN改进而来,本文默认读者熟悉CNN原理和Faster RCNN网络结构。

相关代码
def main(argv):pycaffe_dir = os.path.dirname(__file__)parser = argparse.ArgumentParser()# Required arguments: input and output.parser.add_argument("input_file",help="Input txt/csv filename. If .txt, must be list of filenames.\If .csv, must be comma-separated file with header\'filename, xmin, ymin, xmax, ymax'")parser.add_argument("output_file",help="Output h5/csv filename. Format depends on extension.")# Optional arguments.parser.add_argument("--model_def",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/deploy.prototxt.prototxt"),help="Model definition file.")parser.add_argument("--pretrained_model",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel"),help="Trained model weights file.")parser.add_argument("--crop_mode",default="selective_search",choices=CROP_MODES,help="How to generate windows for detection.")parser.add_argument("--gpu",action='store_true',help="Switch for gpu computation.")parser.add_argument("--mean_file",default=os.path.join(pycaffe_dir,'caffe/imagenet/ilsvrc_2012_mean.npy'),help="Data set image mean of H x W x K dimensions (numpy array). " +"Set to '' for no mean subtraction.")parser.add_argument("--input_scale",type=float,help="Multiply input features by this scale to finish preprocessing.")parser.add_argument("--raw_scale",type=float,default=255.0,help="Multiply raw input by this scale before preprocessing.")parser.add_argument("--channel_swap",default='2,1,0',help="Order to permute input channels. The default converts " +"RGB -> BGR since BGR is the Caffe default by way of OpenCV.")parser.add_argument("--context_pad",type=int,default='16',help="Amount of surrounding context to collect in input window.")args = parser.parse_args()mean, channel_swap = None, Noneif args.mean_file:mean = np.load(args.mean_file)if mean.shape[1:] != (1, 1):mean = mean.mean(1).mean(1)if args.channel_swap:channel_swap = [int(s) for s in args.channel_swap.split(',')]if args.gpu:caffe.set_mode_gpu()print("GPU mode")else:caffe.set_mode_cpu()print("CPU mode")# Make detector.detector = caffe.Detector(args.model_def, args.pretrained_model, mean=mean,input_scale=args.input_scale, raw_scale=args.raw_scale,channel_swap=channel_swap,context_pad=args.context_pad)# Load input.t = time.time()print("Loading input...")if args.input_file.lower().endswith('txt'):with open(args.input_file) as f:inputs = [_.strip() for _ in f.readlines()]elif args.input_file.lower().endswith('csv'):inputs = pd.read_csv(args.input_file, sep=',', dtype={'filename': str})inputs.set_index('filename', inplace=True)else:raise Exception("Unknown input file type: not in txt or csv.")# Detect.if args.crop_mode == 'list':# Unpack sequence of (image filename, windows).images_windows = [(ix, inputs.iloc[np.where(inputs.index == ix)][COORD_COLS].values)for ix in inputs.index.unique()]detections = detector.detect_windows(images_windows)else:detections = detector.detect_selective_search(inputs)print("Processed {} windows in {:.3f} s.".format(len(detections),time.time() - t))# Collect into dataframe with labeled fields.df = pd.DataFrame(detections)df.set_index('filename', inplace=True)df[COORD_COLS] = pd.DataFrame(data=np.vstack(df['window']), index=df.index, columns=COORD_COLS)del(df['window'])# Save results.t = time.time()if args.output_file.lower().endswith('csv'):# csv# Enumerate the class probabilities.class_cols = ['class{}'.format(x) for x in range(NUM_OUTPUT)]df[class_cols] = pd.DataFrame(data=np.vstack(df['feat']), index=df.index, columns=class_cols)df.to_csv(args.output_file, cols=COORD_COLS + class_cols)else:# h5df.to_hdf(args.output_file, 'df', mode='w')print("Saved to {} in {:.3f} s.".format(args.output_file,time.time() - t))
CTPN网络结构

4 文本识别网络-CRNN
CRNN 介绍
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用
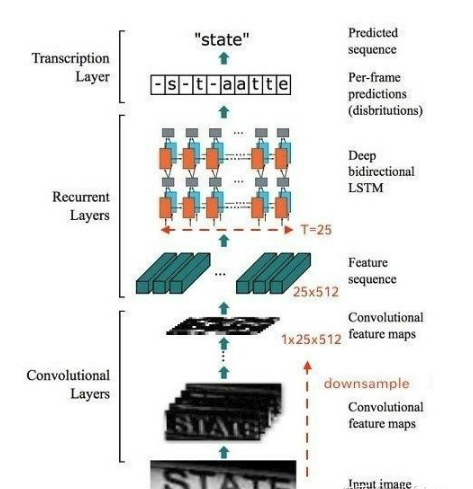
整个CRNN网络结构包含三部分,从下到上依次为:
- CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
- RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
- CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
CNN
卷积层的结构图:
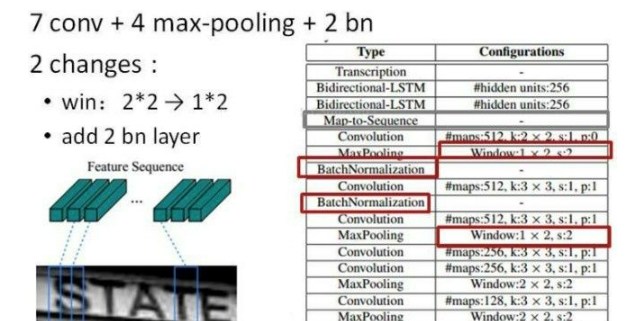
这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以 2^4
),而宽度则只减半了两次(除以2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature
map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN
后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height,
width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 40)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为40。
Map-to-Sequence
我们是不能直接把 CNN 得到的特征图送入 RNN 进行训练的,需要进行一些调整,根据特征图提取 RNN 需要的特征向量序列。
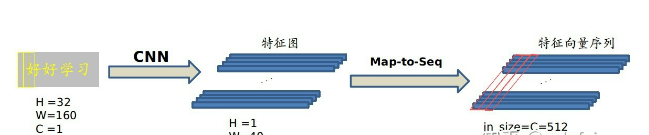
现在需要从 CNN 模型产生的特征图中提取特征向量序列,每一个特征向量(如上图中的一个红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第
i 个特征向量是所有的特征图第 i 列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。
如下图所示:

这些特征向量序列就作为循环层的输入,每个特征向量作为 RNN 在一个时间步(time step)的输入。
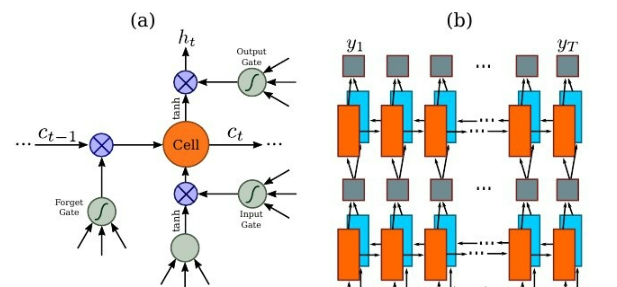
RNN
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM
的特殊设计允许它捕获长距离依赖,不了解的话可以看一下这篇文章 对RNN和LSTM的理解。
LSTM
是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
这里采用的是两层各256单元的双向 LSTM 网络:
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分
我们知道一个特征向量就相当于原图中的一个小矩形区域,RNN
的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。
因为每个时间步都会有一个输入特征向量 x^T ,输出一个所有字符的概率分布 y^T ,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵。
如下图所示:

然后将这个后验概率矩阵传入转录层。
CTC loss
这算是 CRNN 最难的地方,这一层为转录层,转录是将 RNN
对每个特征向量所做的预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率组合的标签序列。
端到端OCR识别的难点在于怎么处理不定长序列对齐的问题!OCR可建模为时序依赖的文本图像问题,然后使用CTC(Connectionist Temporal
Classification, CTC)的损失函数来对 CNN 和 RNN 进行端到端的联合训练。
相关代码
def inference(self, inputdata, name, reuse=False):"""Main routine to construct the network:param inputdata::param name::param reuse::return:"""with tf.variable_scope(name_or_scope=name, reuse=reuse):# centerlized datainputdata = tf.divide(inputdata, 255.0)#1.特征提取阶段# first apply the cnn feature extraction stagecnn_out = self._feature_sequence_extraction(inputdata=inputdata, name='feature_extraction_module')#2.第二步, batch*1*25*512 变成 batch * 25 * 512# second apply the map to sequence stagesequence = self._map_to_sequence(inputdata=cnn_out, name='map_to_sequence_module')#第三步,应用序列标签阶段# third apply the sequence label stage# net_out width, batch, n_classes# raw_pred width, batch, 1net_out, raw_pred = self._sequence_label(inputdata=sequence, name='sequence_rnn_module')return net_out
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
深度学习OCR中文识别 - opencv python 计算机竞赛
文章目录 0 前言1 课题背景2 实现效果3 文本区域检测网络-CTPN4 文本识别网络-CRNN5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习OCR中文识别系统 ** 该项目较为新颖,适合作为竞赛课题方向,…...
 条件控制、循环语句)
Python(七) 条件控制、循环语句
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...

SpringCloud GateWay自定义过滤器之GatewayFilter和AbstractGatewayFactory
一、GatewayFilter GatewayFilter 是一个简单的接口,用于定义网关过滤器的行为。一个网关过滤器就是一个实现了 GatewayFilter 接口的类,它可以执行在请求进入网关或响应离开网关时的某些操作。过滤器可以用于修改请求或响应,记录日志&#…...
不会英语能学编程吗?0基础学编程什么软件好?
不会英语能学编程吗?0基础学编程什么软件好? 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件,象如图这个…...

程序员副业接单做私活避坑指南
不建议大家在接单这个事情上投入太大精力,如果你“贼心不改”,建议大家以比较随缘的方式对待这件事情。 接单平台 下文是接单平台,内容来自知乎,转载过来的原因有2个: 方便大家了解这些平台各自的优势,可以…...

day57
今日内容概要 模板层 模板之过滤器 模板之标签(if else for) 模板之继承 导入模板 模型层 单表的操作 十几种常见的查询方法 基于下划线的查询方法 外键字段的增删改查 正反向查询(多表跨表) 模板之过滤器 语法: {{obj|filter__name:param}} 变量名字|…...

以太坊链多节点本地化【最详细的部署搭建及维护文档】
文章目录 一、维护人员素养1.1 岗位技能1.2 人员素质二、区块链节点及区块链浏览器搭建2.1 编写说明2.1.1 文档说明2.1.2 配置信息2.1.3 部署文档信息2.2 node环境安装2.2.1 基础命令安装2.2.2 安装node2.3 centos7 部署docker环境2.3.1 卸载旧版本2.3.2 使用 yum 安装2.3.3 使…...
微服务架构演进
系统架构演变 没有最好的架构,只有最合适的架构;架构发展过程:单体架构》垂直架构》SOA 面向服务架构》微服务架构;推荐看看《淘宝技术这十年》; 单体架构 互联网早期,一般的网站应用流量较小࿰…...
BUUCTF 九连环 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 下载附件,解压得到一张.jpg图片。 密文: 解题思路: 1、一张图片,典型的图片隐写。放到Kali中,使用binwalk检测,确认图片中隐藏zip压缩包。 使…...

编码自动化:使用MybatisX初体验,太爽了!
使用Mybatis当前最火的插件:MybatisX。 在IDEA中安装MyBatisX插件。 该插件主要功能如下: 生成mapper xml文件 快速从代码跳转到mapper及从mapper返回代码 mybatis自动补全及语法错误提示 集成mybatis Generate GUI界面 根据数据库注解,…...
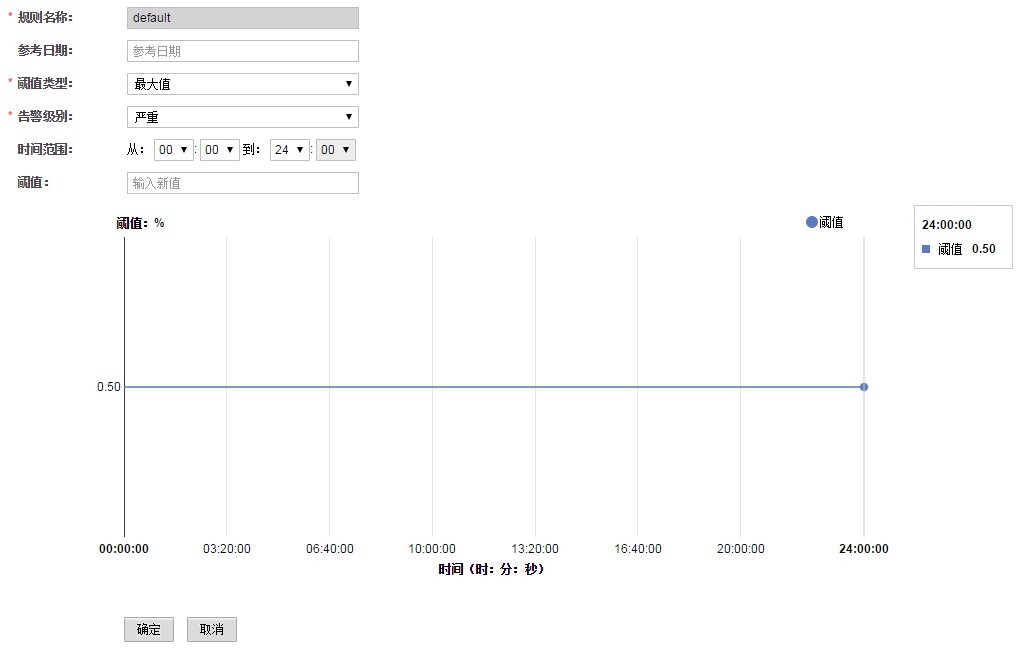
大数据-之LibrA数据库系统告警处理(ALM-12047 网络读包错误率超过阈值)
告警解释 系统每30秒周期性检测网络读包错误率,并把实际错误率和阈值(系统默认阈值0.5%)进行比较,当检测到网络读包错误率连续多次(默认值为5)超过阈值时产生该告警。 用户可通过“系统设置 > 阈值配置…...
JSP 报错 Cannot resolve method ‘print(java.lang.String)‘问题解决
这里 我写了一段比较基础的代码 <%// 定义局部变量String message "Hello, JSP!";out.print(message); %>但是 项目跑起来又是可以的 其实就是缺少了 JAR包 依赖 我们 可以在项目环境中找到 pom.xml dependencies标签内 加入 如下代码 <dependency>…...
(Centos8))
Linux系统下安装RabbitMQ超简单教程(非详细)(Centos8)
文章目录 一、下载所需安装包二、安装三、启动rabbitmq四、添加远程用户五、图形化访问六、修改rabbitmq的启动端口和管理端口(没有这个需求就不用看了)七、需要注意版本问题可能遇到的错误和解决方式version GLIBC_2.34 类型错误undefined function rab…...

2024江苏专转本流程与时间节点
2024江苏专转本考生,提前看一下转本的流程与时间节点!适用于江苏三年制、五年一贯制专转本考试: 1. 专转本工作通知(2023年12月上旬) 若无特殊情况,到12月中旬,江苏省教育厅会发布关于做好2024…...
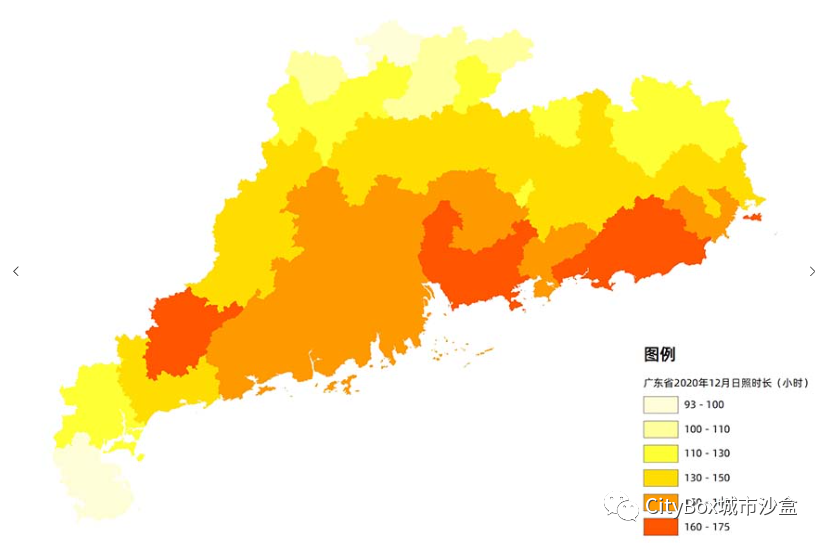
全国各区县日照时长数据,逐月数据均有!
今天给大家分享的是全国各区县日照时长月数据,包括不同月份不同地区的日照时长。这些数据可以帮助我们了解不同地区在不同月份的日照情况,为能源利用、农业生产和气候变化研究提供参考。 基本信息 数据名称: 全国各区县日照时长月数据 数据格式: shpex…...
candence出现no connect property onpin,,,,错误,该怎么办?
原因是上面有引脚添加了 属性no connect,但依然连接了网络,这个时候需要把线剪切,然后看到引脚上有个X, 解决方法: 工具栏"place >no connect "X 再连上线,再生成网标的时候, 就不报错了…...
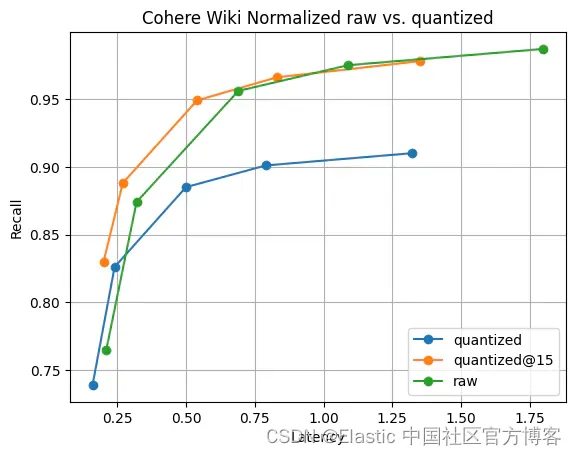
Elasticsearch:Lucene 中引入标量量化
作者:BENJAMIN TRENT 我们如何将标量量化引入 Lucene。 Lucene 中的自动字节量化 虽然 HNSW 是一种强大而灵活的存储和搜索向量的方法,但它确实需要大量内存才能快速运行。 例如,查询 768 维的 1MM float32 向量大约需要 1,000,000*4*(7681…...

如何做好测试用例设计
做好测试用例设计是确保软件质量的重要环节之一。以下是一些建议,可以帮助您设计出高效、全面和可靠的测试用例: 明确测试目标和需求 在开始设计测试用例之前,要明确测试的目标和需求,包括测试的范围、重点、预期结果等。这有助于…...

云计算是否正在“杀死”运维
一、云计算正在杀死运维吗? 随着云计算的发展,企业上云已经成为一种趋势。企业上云的初衷是把复杂的IT基础设施交给云平台去管理,企业可以专注于业务与应用、从而降低企业IT运营成本,提高IT部门工作效率。 因此有人会误以为&…...
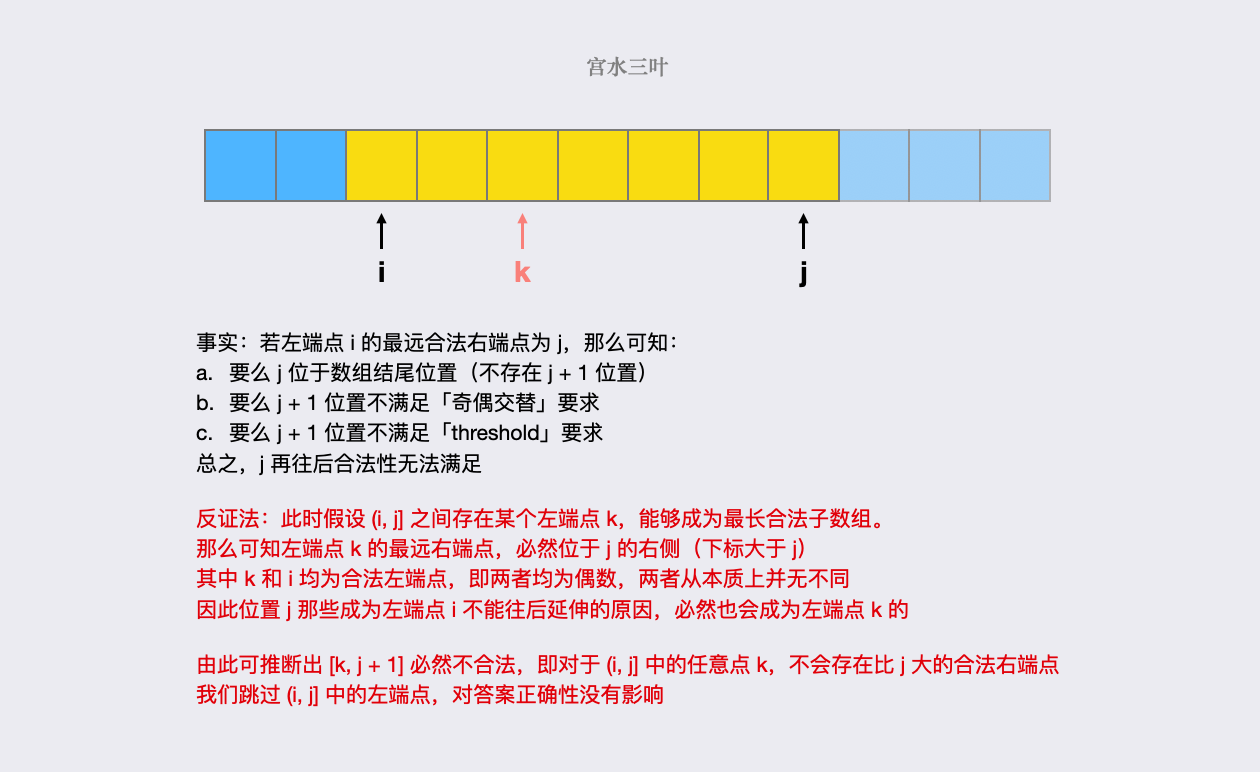
2760. 最长奇偶子数组 : 抽丝剥茧,图解双指针做法正确性
题目描述 这是 LeetCode 上的 「2698. 求一个整数的惩罚数」 ,难度为 「简单」。 Tag : 「双指针」、「滑动窗口」 给你一个下标从 开始的整数数组 nums 和一个整数 threshold。 请你从 nums 的子数组中找出以下标 l 开头、下标 r 结尾 ( ) 且满足以下条件的 最长子…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...
)
DeepSeek代码审查能力白皮书(2024企业级实测报告)
更多请点击: https://kaifayun.com 第一章:DeepSeek代码审查能力白皮书(2024企业级实测报告)概述 本报告基于2024年Q1至Q3期间,面向金融、电信与云原生三大垂直行业的17家头部企业客户开展的深度实测,覆盖…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...
)
【Sora 2 HDR生成黄金公式】:曝光补偿系数×动态范围压缩阈值×时域一致性权重=可商用HDR帧率(附Python验证脚本)
更多请点击: https://codechina.net 第一章:Sora 2 HDR视频生成黄金公式的提出与商业意义 Sora 2 的HDR视频生成能力不再依赖传统多曝光融合或后期调色管线,而是通过一个端到端可微分的物理感知渲染公式实现原生高动态范围建模。该公式被业界…...

多智能体协作系统:2026年企业级AI应用的核心架构范式
引言:AI Agent从单兵作战到团队协作的范式跃迁 2026年,人工智能领域正在经历一场深刻的架构变革。回想2024年,当ChatGPT、Claude等大语言模型横空出世时,我们惊叹于单个AI模型的强大能力。然而,随着企业级应用的深入,单一AI Agent的局限性日益凸显:它无法同时处理多领域…...

VMware Workstation Pro 17许可证密钥:技术深度解析与最佳实践指南
VMware Workstation Pro 17许可证密钥:技术深度解析与最佳实践指南 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major versions…...
)
ChatGPT自动回复失效真相:微信API接口变更后,必须重写的4段核心Prompt代码(含防封逻辑)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT公众号运营技巧 在微信生态中,将ChatGPT能力深度融入公众号运营,需兼顾合规性、用户体验与自动化效率。微信官方明确禁止直接调用外部AI接口响应用户消息(如透…...

终极指南:如何用猫抓浏览器扩展构建高效的流媒体资源嗅探工作流
终极指南:如何用猫抓浏览器扩展构建高效的流媒体资源嗅探工作流 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-c…...