Python爬虫教程:从入门到实战

更多Python学习内容:ipengtao.com
大家好,我是涛哥,今天为大家分享 Python爬虫教程:从入门到实战,文章3800字,阅读大约15分钟,大家enjoy~~
网络上的信息浩如烟海,而爬虫(Web Scraping)是获取和提取互联网信息的强大工具。Python作为一门强大而灵活的编程语言,拥有丰富的库和工具,使得编写爬虫变得更加容易。本文将从基础的爬虫原理和库介绍开始,逐步深入,通过实际示例代码,带领读者学习Python爬虫的使用和技巧,掌握从简单到复杂的爬虫实现。
1. 基础知识
1.1 HTTP请求
在开始爬虫之前,了解HTTP请求是至关重要的。Python中有许多库可以发送HTTP请求,其中requests库是一个简单而强大的选择。
import requestsresponse = requests.get("https://www.example.com")
print(response.text)1.2 HTML解析
使用BeautifulSoup库可以方便地解析HTML文档,提取所需信息。
from bs4 import BeautifulSouphtml = """
<html><body><p>Example Page</p><a href="https://www.example.com">Link</a></body>
</html>
"""soup = BeautifulSoup(html, 'html.parser')
print(soup.get_text())2. 静态网页爬取
2.1 简单示例
爬取静态网页的基本步骤包括发送HTTP请求、解析HTML并提取信息。
import requests
from bs4 import BeautifulSoupurl = "https://www.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 提取标题
title = soup.title.text
print(f"Title: {title}")# 提取所有链接
links = soup.find_all('a')
for link in links:print(link['href'])2.2 处理动态内容
对于使用JavaScript渲染的网页,可以使用Selenium库模拟浏览器行为。
from selenium import webdriver
from selenium.webdriver.common.keys import Keysurl = "https://www.example.com"
driver = webdriver.Chrome()
driver.get(url)# 模拟滚动
driver.find_element_by_tag_name('body').send_keys(Keys.END)# 提取渲染后的内容
rendered_html = driver.page_source
soup = BeautifulSoup(rendered_html, 'html.parser')
# 进一步处理渲染后的内容3. 数据存储
3.1 存储到文件
将爬取的数据存储到本地文件是一种简单有效的方法。
import requestsurl = "https://www.example.com"
response = requests.get(url)
with open('example.html', 'w', encoding='utf-8') as file:file.write(response.text)3.2 存储到数据库
使用数据库存储爬取的数据,例如使用SQLite。
import sqlite3conn = sqlite3.connect('example.db')
cursor = conn.cursor()# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS pages (id INTEGER PRIMARY KEY, url TEXT, content TEXT)''')# 插入数据
url = "https://www.example.com"
content = response.text
cursor.execute('''INSERT INTO pages (url, content) VALUES (?, ?)''', (url, content))# 提交并关闭连接
conn.commit()
conn.close()4. 处理动态网页
4.1 使用API
有些网站提供API接口,直接请求API可以获得数据,而无需解析HTML。
import requestsurl = "https://api.example.com/data"
response = requests.get(url)
data = response.json()
print(data)4.2 使用无头浏览器
使用Selenium库模拟无头浏览器,适用于需要JavaScript渲染的网页。
from selenium import webdriverurl = "https://www.example.com"
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
driver = webdriver.Chrome(options=options)
driver.get(url)# 处理渲染后的内容5. 高级主题
5.1 多线程和异步
使用多线程或异步操作可以提高爬虫的效率,特别是在爬取大量数据时。
import requests
from concurrent.futures import ThreadPoolExecutordef fetch_data(url):response = requests.get(url)return response.texturls = ["https://www.example.com/1", "https://www.example.com/2", "https://www.example.com/3"]
with ThreadPoolExecutor(max_workers=5) as executor:results = list(executor.map(fetch_data, urls))for result in results:print(result)5.2 使用代理
为了防止被网站封禁IP,可以使用代理服务器。
import requestsurl = "https://www.example.com"
proxy = {'http': 'http://your_proxy_here','https': 'https://your_proxy_here'
}
response = requests.get(url, proxies=proxy)
print(response.text)6. 防反爬虫策略
6.1 限制请求频率
设置适当的请求间隔,模拟人类操作,避免过快爬取。
import timeurl = "https://www.example.com"
for _ in range(5):response = requests.get(url)print(response.text)time.sleep(2) # 2秒间隔6.2 使用随机User-Agent
随机更换User-Agent头部,降低被识别为爬虫的概率。
import requests
from fake_useragent import UserAgentua = UserAgent()
headers = {'User-Agent': ua.random}
url = "https://www.example.com"
response = requests.get(url, headers=headers)
print(response.text)总结
这篇文章全面涵盖了Python爬虫的核心概念和实际操作,提供了从基础知识到高级技巧的全面指南。深入剖析了HTTP请求、HTML解析,以及静态和动态网页爬取的基本原理。通过requests、BeautifulSoup和Selenium等库的灵活运用,大家能够轻松获取和处理网页数据。数据存储方面,介绍了将数据保存到文件和数据库的方法,帮助大家有效管理爬取到的信息。高级主题涵盖了多线程、异步操作、使用代理、防反爬虫策略等内容,能够更高效地进行爬虫操作,并规避反爬虫机制。最后,提供了良好的实践建议,包括设置请求频率、使用随机User-Agent等,以确保爬虫操作的合法性和可持续性。
总体而言,本教程通过生动的示例代码和详实的解释,为学习和实践Python爬虫的读者提供了一份全面而实用的指南。希望大家通过学习本文,能够在实际应用中灵活驾驭爬虫技术,更深入地探索网络世界的无限可能。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容
相关文章:
Python爬虫教程:从入门到实战
更多Python学习内容:ipengtao.com 大家好,我是涛哥,今天为大家分享 Python爬虫教程:从入门到实战,文章3800字,阅读大约15分钟,大家enjoy~~ 网络上的信息浩如烟海,而爬虫(…...
C++实现高频设计模式
面试能说出这几种常用的设计模式即可 1.策略模式 1.1 业务场景 大数据系统把文件推送过来,根据不同类型采取不同的解析方式。多数的小伙伴就会写出以下的代码: if(type"A"){//按照A格式解析 }else if(type"B"){//按照B格式解析 …...
opencv(2): 视频采集和录制
视频采集 相关API VideoCapture()cap.read(): 返回两个值,第一个参数,如果读到frame,返回 True. 第二个参数为相应的图像帧。cap.release() VideoCapture cv2.VideoCapture(0) 0 表示自动检测,如果在笔记本上运行&…...

SpringBoot+EasyExcel设置excel样式
方式一:使用注解方式设置样式 模板可通过HeadFontStyle、HeadStyle、ContentFontStyle、ContentStyle、HeadRowHeight ContentRowHeight等注解设置excel单元格样式; //字体样式及字体大小 HeadFontStyle(fontName "宋体",fontHeightInPoints…...
)
自定义View之Measure(二)
measure 用来测量 View 的宽和高,它的流程分为 View 的 measure 流程和 ViewGroup 的measure流程,只不过ViewGroup的measure流程除了要完成自己的测量,还要遍历地调用子元素的measure()方法。 上一回说到performMeasur…...
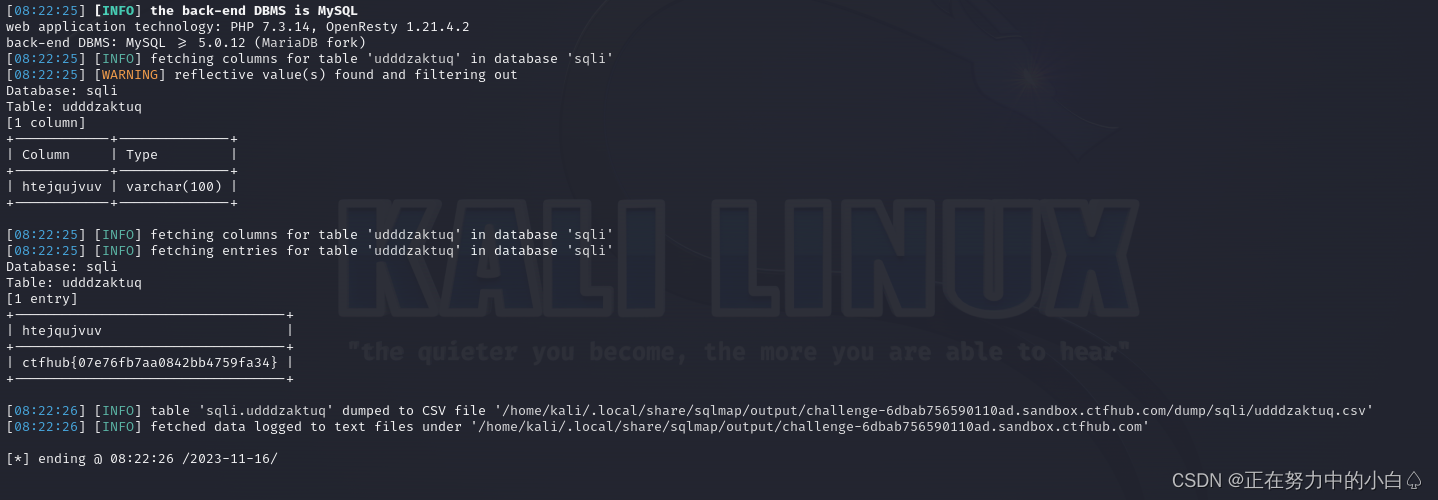
SQL注入学习--GTFHub(布尔盲注+时间盲注+MySQL结构)
目录 布尔盲注 手工注入 笔记 Boolean注入 # 使用脚本注入 sqlmap注入 使用Burpsuite进行半自动注入 时间盲注 手工注入 使用脚本注入 sqlmap注入 使用Burpsuite进行半自动注入 MySQL结构 手工注入 sqlmap注入 笔记 union 联合注入,手工注入的一般步骤 …...

Kubernetes学习-概念2
参考:关于 cgroup v2 | Kubernetes 关于 cgroup v2 在 Linux 上,控制组约束分配给进程的资源。 kubelet 和底层容器运行时都需要对接 cgroup 来强制执行为 Pod 和容器管理资源, 这包括为容器化工作负载配置 CPU/内存请求和限制。 Linux 中…...
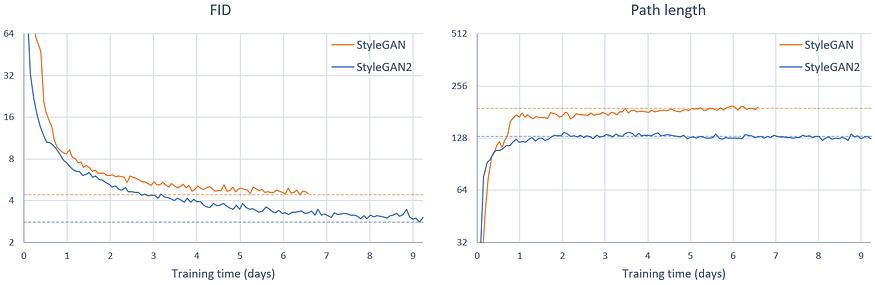
StyleGAN:彻底改变生成对抗网络的艺术
一、介绍 多年来,人工智能领域取得了显着的进步,其中最令人兴奋的领域之一是生成模型的发展。这些模型旨在生成与人类创作没有区别的内容,例如图像和文本。其中,StyleGAN(即风格生成对抗网络)因其创建高度逼…...

黑马程序员微服务第四天课程 分布式搜索引擎1
分布式搜索引擎01 – elasticsearch基础 0.学习目标 1.初识elasticsearch 1.1.了解ES 1.1.1.elasticsearch的作用 elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容 例如: …...

向量以及矩阵
0.前言 好了那我们新的征程也即将开始,那么在此呢我也先啰嗦两句,本篇文章介绍数学基础的部分,因为个人精力有限我不可能没一字一句都讲得非常清楚明白,像矩阵乘法之类的一些基础知识我都是默认你会了(还不会的同学推…...
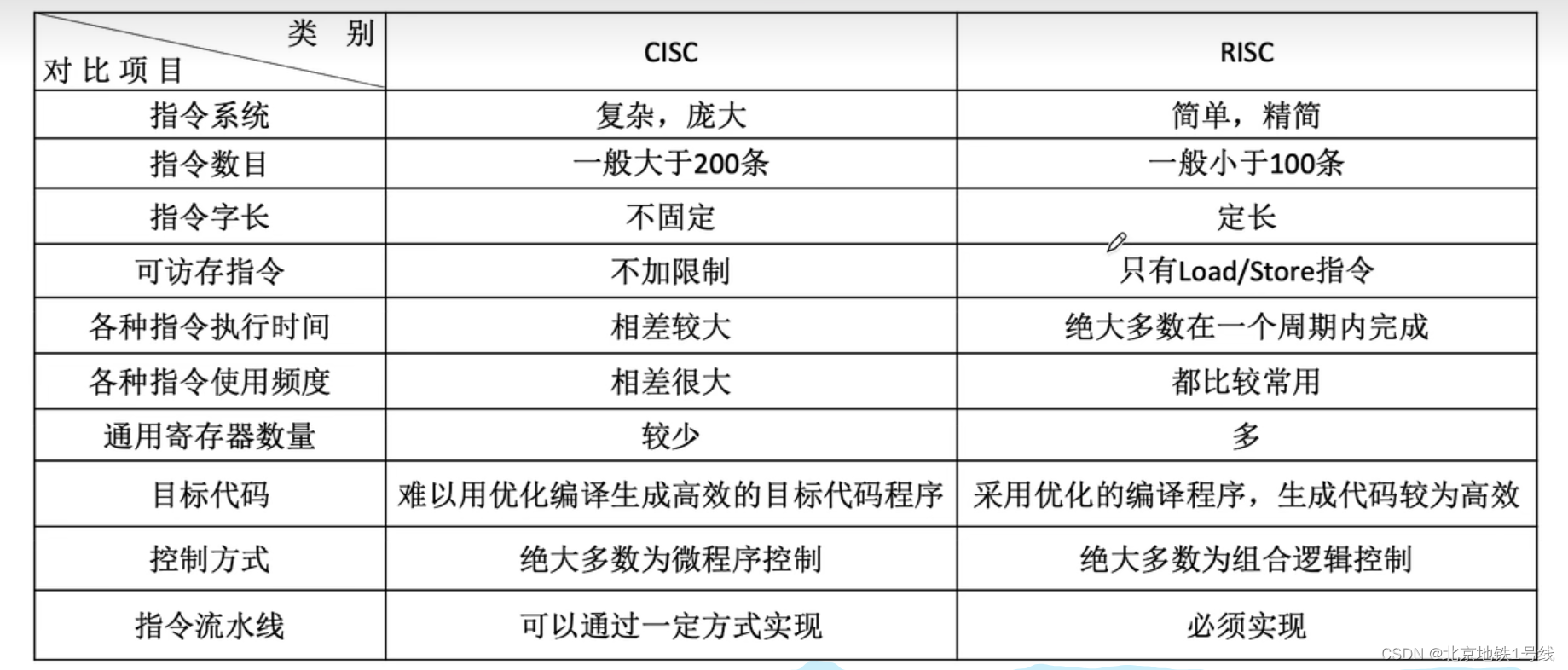
9.程序的机器级代码表示,CISC和RISC
目录 一. x86汇遍语言基础(Intel格式) 二. AT&T格式汇编语言 三. 程序的机器级代码表示 (1)选择语句 (2)循环语句 (3)函数调用 1.函数调用命令 2.栈帧及其访问 3.栈帧的…...

《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》《从零开始读懂相对论》
文章目录 《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》内容简介核心精华使用ChatGPT可以高效搞定写作的好处如下 《从零开始读懂相对论》内容简介关键点书摘最后 《硅基物语.AI写作高手:从零开始用ChatGPT学会写作》 内容简介 本书从写作与ChatG…...

【2016年数据结构真题】
已知由n(M>2)个正整数构成的集合A{a<k<n},将其划分为两个不相交的子集A1 和A2,元素个数分别是n1和n2,A1和A2中的元素之和分别为S1和S2。设计一个尽可能高效的划分算法,满足|n1-n2|最小且|s1-s2|最大。要求…...
创作者等级终于升到4级了
写了两个月的文章,终于等到4级了。发文纪念一下:...
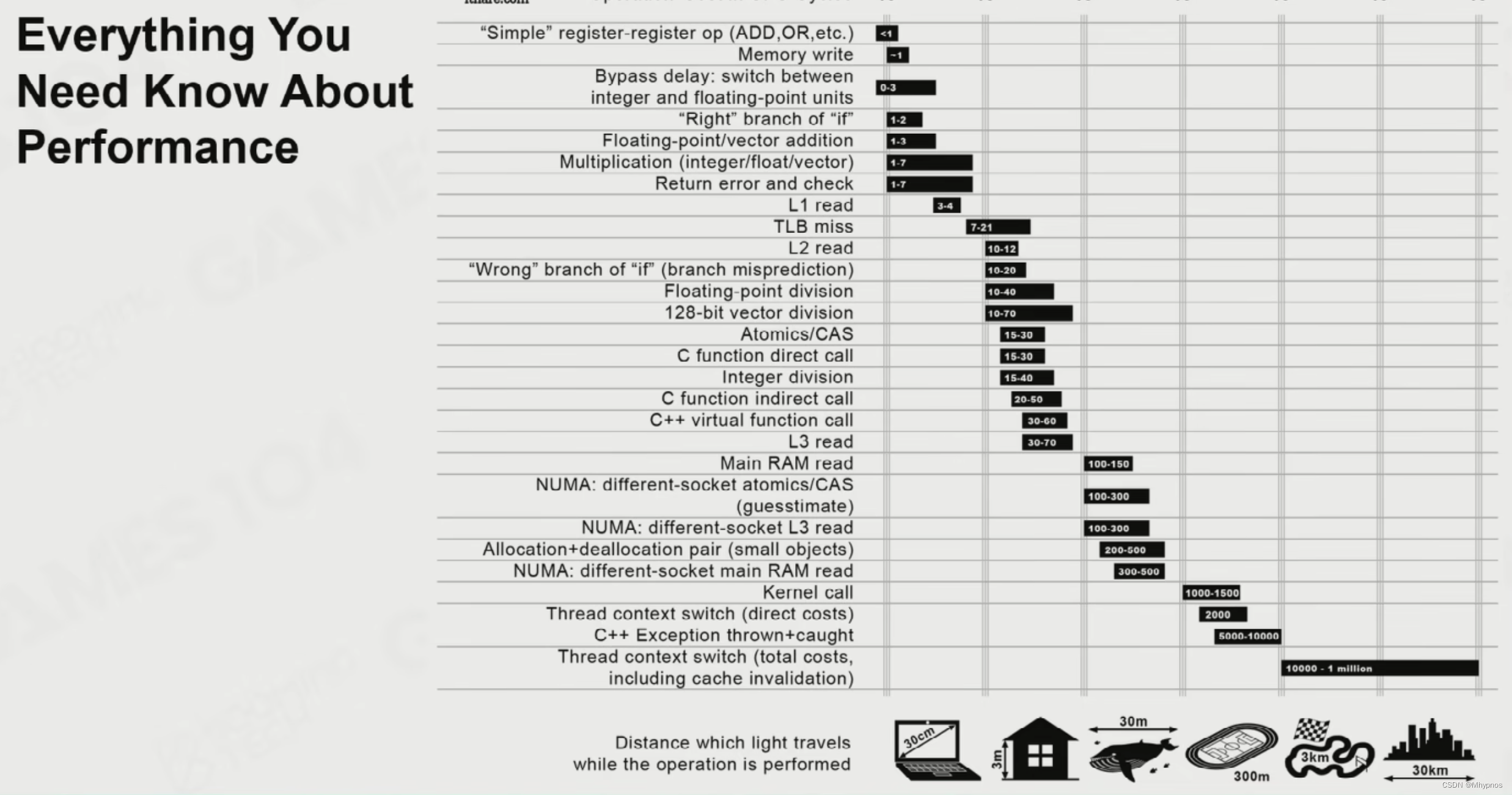
Games104现代游戏引擎笔记 面向数据编程与任务系统
Basics of Parallel Programming 并行编程的基础 核达到了上限,无法越做越快,只能通过更多的核来解决问题 Process 进程 有独立的存储单元,系统去管理,需要通过特殊机制去交换信息 Thread 线程 在进程之内,共享了内存…...
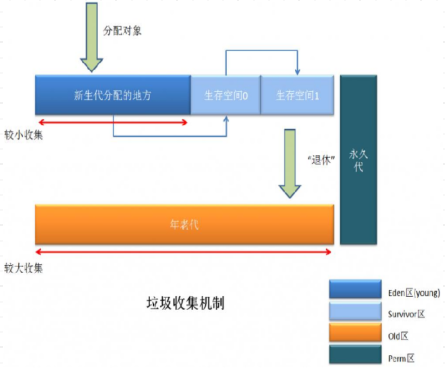
系列三、GC垃圾回收【总体概览】
一、GC垃圾回收【总体概览】 JVM进行GC时,并非每次都对上面的三个内存区域(新生区、养老区、元空间/永久代)一起回收,大部分回收的是新生区里边的垃圾,因此GC按照回收的区域又分为了两种类型,一种是发生在新…...
WPA破解-创建Hash-table加速并用Cowpatty破解)
无线WiFi安全渗透与攻防(N.3)WPA破解-创建Hash-table加速并用Cowpatty破解
WPA破解-创建Hash-table加速并用Cowpatty破解 WPA破解-创建Hash-table加速并用Cowpatty破解1.Cowpatty 软件介绍2.渗透流程1.安装CoWPAtty2.抓握手包1.查看网卡2.开启监听模式3.扫描wifi4.抓握手包5.进行冲突模式攻击3.STA重新连接wifi4.渗透WPA wifi5.使用大字典破解3.hash-ta…...

golang 动态库
目录 1. golang 动态库2. golang 语言使用动态库、调用动态链接库2.1. Go 插件系统2.2. 动态加载的优劣2.3. Go 的插件系统:Plugin2.4. 插件开发原则2.4.1. 插件独立2.4.2. 使用接口类型作为边界2.4.3. Unix 模块化原则2.4.4. 版本控制 2.5. 插件开发示例2.5.1. 编写…...

Python的2042小游戏及其详解
源码: import random import os# 游戏界面尺寸 SIZE 4# 游戏结束标志 GAME_OVER False# 初始化游戏界面 board [[0] * SIZE for _ in range(SIZE)]# 随机生成一个初始方块 def add_random_tile():empty_tiles [(i, j) for i in range(SIZE) for j in range(SIZ…...
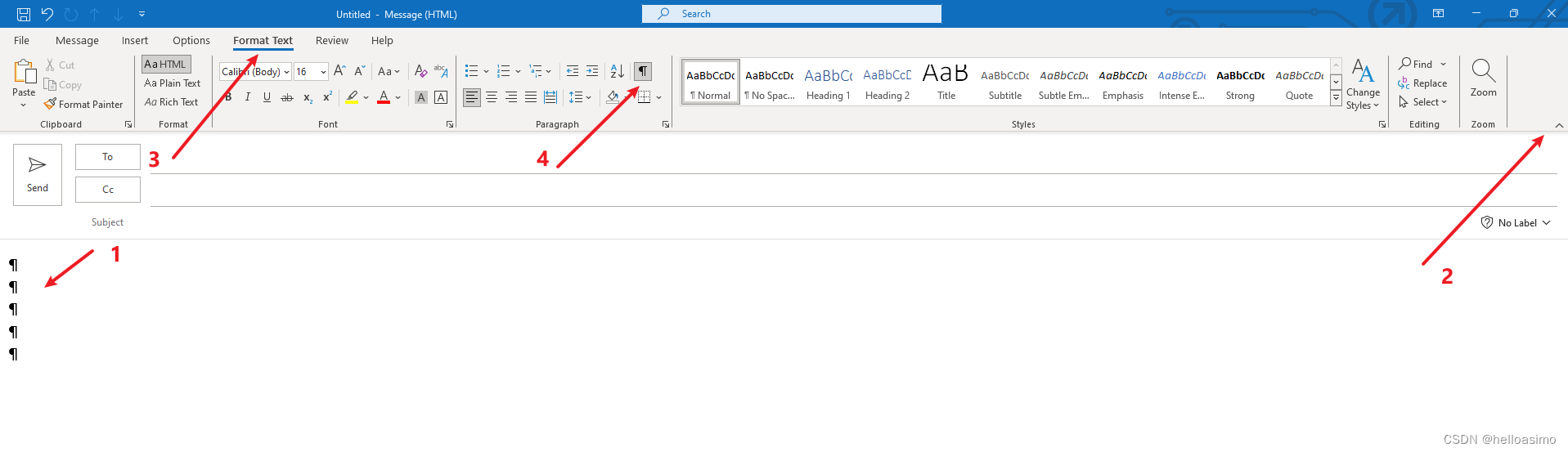
怎么去掉邮件内容中的回车符
上图是Outlook 截图,可见1指向的总有回车符; 故障原因: 不小心误按了箭头4这个选项; 解决方法: 点击2箭头确保tab展开; 点击3以找到箭头4. 取消勾选或者多次点击,即可解决。...

JEECG-Boot接口幂等性架构深度解析:Token机制与分布式锁实战指南
JEECG-Boot接口幂等性架构深度解析:Token机制与分布式锁实战指南 【免费下载链接】jeecg-boot AI 低代码平台,「低代码 零代码」双模式驱动:低代码一键生成前后端代码,零代码 5 分钟搭建系统,AI Skills 一句话画流程、…...

安卓HTTPS抓包证书信任问题深度解析与系统级迁移方案
1. 为什么安卓抓包总在“证书信任”这关卡住?——一个被低估的系统级权限问题你是不是也经历过:Fiddler、Charles 或 mitmproxy 在电脑上配置得严丝合缝,手机 Wi-Fi 代理一设就通,HTTP 流量哗哗跑,可一到 HTTPS&#x…...

手把手教你用Wireshark抓包分析:一个Easymesh设备到底是怎么‘发现’并‘加入’你家网络的?
用Wireshark解密Easymesh组网:从设备发现到网络接入的全流程解析 当你在客厅新添置了一台支持Easymesh的路由器,通电后它就像有自主意识般自动加入了现有的家庭网络——这种看似"魔法"般的体验背后,其实是一系列精密的协议交互在发…...
代码平台的方法)
在fnOS飞牛NAS上部署宝塔+NocoBase低(零)代码平台的方法
在fnOS飞牛NAS上部署宝塔NocoBase低(零)代码平台的方法 温馨提醒:本文全文免费,严禁盗用、二次收费行为! 更新日志: 2026/03/29 首次发布 2026/05/22 1、新增通过systemd托管进程,实现重启后自…...

Docker编译镜像实战:为嵌入式Linux开发打造标准化环境
1. 项目概述:为什么我们需要一个专属的Docker编译镜像?如果你是一名嵌入式Linux开发者,或者正在学习诸如全志Tina Linux这样的开源嵌入式系统,那么“编译环境”这个词对你来说一定不陌生。它就像是一个厨师的后厨,锅碗…...

电赛小车结构翻车实录:从STM32F407到剪叉式结构,我们踩过的那些坑
电赛智能车避坑指南:从机械结构到控制系统的实战复盘 第一次参加电子设计竞赛的团队,往往会被智能车项目中隐藏的"坑"绊得措手不及。作为一支从零开始的参赛队伍,我们在机械结构选型、核心器件采购、系统调试等环节踩遍了几乎所有常…...

MakeMeAHanzi完整指南:如何免费获取9000+汉字笔画动画数据
MakeMeAHanzi完整指南:如何免费获取9000汉字笔画动画数据 【免费下载链接】makemeahanzi Free, open-source Chinese character data 项目地址: https://gitcode.com/gh_mirrors/ma/makemeahanzi MakeMeAHanzi是一个免费开源的汉字数据项目,为开发…...

蛋白质基础模型:从AlphaFold2到Chai-1的范式跃迁
1. 项目概述:一场悄然发生的蛋白质结构预测范式迁移最近在实验室跑完第7轮Chai-1的微调任务后,我盯着屏幕上跳出来的pLDDT值曲线,突然意识到:我们正在经历的不是一次工具升级,而是一场底层建模逻辑的彻底重写。标题里提…...

Java Web中基于JWT的七层权限控制系统设计
1. 为什么JWT不是“万能钥匙”,而是一个需要精心设计的权限信封在Java Web开发中,一提到权限控制,很多人第一反应就是“加个Spring Security,配个JWT,不就完事了?”我去年接手一个医疗SaaS系统的权限模块重…...

AI学习 Newsletter 的手工感设计:从断点驱动到可追溯实践
1. 项目概述:这不是一份 newsletter,而是一份 AI 社区共建的实践手记 “Learn AI Together — Towards AI Community Newsletter #14”——看到这个标题,你第一反应可能是:又一份 AI 领域的资讯汇总?点开看看最新论文…...