大数据研发工程师面试
文章目录
- 面试
- 1.AUC,ROC,准确率与召回率都是怎么计算的?
- 2.数据清洗是如何清洗的,要做哪些清洗的工作?
- 3.什么是数据的完整性?
- 4.数仓是怎么设计的?
- 5.linux查看进程的命令是什么,如何查看具体某一行的内容(查看第n至m行)?
- 6.从浏览器输入网址到返回页面,中间发生了什么?
- 7.具体说一下三次握手四次挥手?
- 8.HTTP和HTTPS的区别?
- 9.HDFS的理解?
- 10.hadoop对put一个文件,集群发生了什么?
- 11.hadoop数据如何存储?
- 12.UDF函数有哪些,工作原理是什么?
- 13.spark的driver和executor的理解
- 14.python的垃圾回收机制
- 15.深拷贝和浅拷贝是什么?
- 16.如何复制一个python对象?
- 笔试题:
- 一个时间复杂度小于n^n的排序算法
面试
1.AUC,ROC,准确率与召回率都是怎么计算的?
AUC(Area Under Curve)是ROC(Receiver Operating Characteristic)曲线下的面积。它用于评估二分类模型在连续预测概率下的性能。计算方法是:对于正负样本对的预测概率,计算真阳性(TP)、假阴性(FN)、真阴性(TN)和假阳性(FP)的累积值,然后计算曲线下的面积。
ROC曲线是敏感性(真阳性率)与1-特异性(假阳性率)之间的关系。在ROC曲线中,横坐标为假阳性率,纵坐标为敏感性。AUC值的范围在0.5到1之间,其中0.5表示模型性能与随机猜测相同,1表示模型完全准确。
准确率(Accuracy)是指模型预测正确的样本占总样本数的比例。计算方法是:正确预测的样本数 / 总样本数。
召回率(Recall)又称查全率,是指模型能正确预测为正类的样本占实际为正类的样本的比例。计算方法是:正确预测为正类的样本数 / 实际为正类的样本数。
以下是Python代码示例,用于计算AUC、ROC曲线、准确率和召回率:
import numpy as npdef compute_auc(y_true, y_pred):fpr, tpr, _ = roc_curve(y_true, y_pred)return auc(fpr, tpr)def compute_roc_curve(y_true, y_pred):fpr, tpr, _ = roc_curve(y_true, y_pred)return fpr, tprdef compute_accuracy(y_true, y_pred):return np.mean(y_true == np.argmax(y_pred, axis=1))def compute_recall(y_true, y_pred):y_pred = np.argmax(y_pred, axis=1)return np.mean(np.in1d(y_true, y_pred))# 示例
y_true = np.random.randint(0, 2, size=(100,))
y_pred = np.random.rand(100)auc = compute_auc(y_true, y_pred)
fpr, tpr = compute_roc_curve(y_true, y_pred)
accuracy = compute_accuracy(y_true, y_pred)
recall = compute_recall(y_true, y_pred)print("AUC:", auc)
print("ROC曲线:", fpr, tpr)
print("准确率:", accuracy)
print("召回率:", recall)
注意:这个示例仅适用于二分类问题。对于多分类问题,需要先将预测概率转换为二分类问题,然后再计算AUC、ROC曲线、准确率和召回率。
2.数据清洗是如何清洗的,要做哪些清洗的工作?
数据清洗主要包括以下几个步骤:
-
删除重复数据:检查数据中是否存在重复记录,如有,则删除其中之一。
-
处理缺失值:对于缺失值,可以采用填充、删除或根据上下文进行推测等方法。
-
数据类型转换:将数据中不一致的数据类型进行转换,使其统一。
-
字符串处理:清理数据中的异常字符、换行符等,使字符串格式统一。
-
数据规范化:对数据进行标准化、归一化等操作,使其符合统一标准。
-
数据合并:将分散在不同位置的相同数据进行合并。
-
数据分类:对数据进行分类,将相似的数据归为一类。
-
异常检测:识别数据中的异常值,并对其进行处理。
-
数据验证:检查数据是否符合预期的规则,如唯一性、合法性等。
-
数据简化:删除或合并冗余数据,减少数据量。
具体清洗方法可根据实际数据特点和需求进行选择和调整。
3.什么是数据的完整性?
数据的完整性是指数据在存储、处理和传输过程中保持完整、准确和可靠的程度。确保数据完整性是数据库管理、数据处理和信息安全的重要任务,它可以防止数据丢失、篡改或损坏。数据的完整性有助于保证数据的正确性和可靠性,从而为企业的正常运营和决策提供准确的信息支持。
4.数仓是怎么设计的?
数仓的设计过程可以分为以下步骤:
- 分析业务需求,确定数据仓库主题。
- 构建逻辑模型。
- 数据仓库技术选型。
- 逻辑模型转换为物理模型。
- 数据源接入。
- 数据存储清洗和转换。
- 开发数据仓库的分析应用。
- 数据仓库管理和维护。
此外,数仓模型设计时需要考虑到数据仓库的分层设计。数据仓库的分层设计可以提高数据处理效率、简化数据处理流程、提高系统的可维护性、可重用性和可扩展性。通常,数据仓库可以分为以下几层:
- ODS层:操作型数据存储,主要存储与源系统基本保持一致的增量或全量数据,起到备份数据的作用,同时可以创建分区表,防止后续的全表扫描。
- CDM层:通用数据模型,又称为数据中间层,包含DWD、DWS、DIM层。DWD层是数据仓库明细层数据,对ODS层数据进行清洗转化,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细事实表。
总之,数仓的设计需要结合业务需求和技术实现,确保数据仓库的可用性、可扩展性和高效性。
5.linux查看进程的命令是什么,如何查看具体某一行的内容(查看第n至m行)?
Linux 查看进程的命令是:ps。
查看具体某一行的内容(查看第 n 至 m 行),可以使用以下命令:
ps aux | grep 关键词 | awk 'NR>=n && NR<=m'
将 n、m 替换为具体的行号,关键词 替换为需要查找的关键词。执行此命令后,会显示第 n 至 m 行的内容。
6.从浏览器输入网址到返回页面,中间发生了什么?
浏览器输入网址后,中间发生的过程如下:
- DNS 解析:浏览器首先会将网址中的域名发送给本地 DNS 服务器,请求将其解析为 IP 地址。本地 DNS 服务器会从缓存或远程 DNS 服务器获取对应的 IP 地址,并返回给浏览器。
- 建立 TCP 连接:浏览器根据获取到的 IP 地址,与目标服务器建立 TCP 连接。这个过程涉及到三次握手,以确保双方建立的连接稳定。
- 发送 HTTP 请求:TCP 连接建立后,浏览器向服务器发送 HTTP 请求。请求中包含请求方法(如 GET、POST 等)、请求路径和 HTTP 版本等信息。
- 服务器响应:服务器接收到浏览器发送的请求后,根据请求内容生成 HTTP 响应。响应中包含响应状态码、响应头和响应体等信息。
- 传输数据:浏览器与服务器之间通过 TCP 连接传输数据。浏览器接收服务器返回的 HTTP 响应,并解析响应体中的 HTML、CSS、JavaScript 等资源。
- 渲染页面:浏览器根据解析后的 HTML 代码,构建文档对象模型(DOM),然后根据 CSS 样式和 JavaScript 代码渲染页面。最终将渲染好的页面呈现给用户。
- 关闭连接:浏览器和服务器完成数据传输后,关闭 TCP 连接。
7.具体说一下三次握手四次挥手?
三次握手:
- 客户端向服务器发送一个带有SYN(同步)标志位的数据包,请求建立连接。
- 服务器收到请求后,返回一个带有SYN和ACK(确认)标志位的数据包,表示同意连接。
- 客户端再发送一个带有ACK标志位的数据包给服务器,确认连接已建立。
四次挥手:
- 服务器向客户端发送一个带有FIN(结束)标志位的数据包,表示要关闭连接。
- 客户端收到服务器的通知后,返回一个带有ACK标志位的确认数据包。
- 客户端向服务器发送一个带有FIN标志位的数据包,表示同意关闭连接。
- 服务器收到客户端的确认后,发送一个带有ACK标志位的数据包给客户端,表示确认连接已关闭。
以上是TCP协议中的三次握手和四次挥手的过程。
8.HTTP和HTTPS的区别?
HTTP和HTTPS的区别主要在于安全性和加密性。HTTP是超文本传输协议,是一种基于TCP/IP协议的无状态协议,不提供数据加密和身份验证功能。而HTTPS是基于HTTP协议,但使用安全套接层协议(SSL)或传输层安全协议(TLS)来加密数据并验证服务器身份。HTTPS比HTTP更安全,可以防止数据在传输过程中被窃取或篡改。
9.HDFS的理解?
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统中的一种分布式文件系统。它被设计用于在大规模集群上存储和处理大数据。
HDFS的设计目标之一是容错性,它通过将数据分散存储在集群中的多个节点上来实现高可靠性。数据被分割成块,并在集群中的多个节点上进行复制存储,以防止数据丢失。这种冗余存储的方式使得HDFS能够容忍节点故障,并自动进行数据恢复。
HDFS的另一个重要特性是高吞吐量。它通过将大文件划分为多个块,并将这些块并行地存储在集群中的多个节点上,从而实现了高效的数据读写操作。同时,HDFS还提供了数据本地性优化机制,即将计算任务调度到存储有所需数据块的节点上,以减少数据传输的开销。
HDFS还具有可扩展性的特点。它可以在集群中添加更多的节点来扩展存储容量和处理能力,并且可以自动进行数据的重新平衡,以保持数据的均衡分布。
总之,HDFS是一个分布式文件系统,它提供了高可靠性、高吞吐量和可扩展性的特性,使得它成为处理大规模数据的理想选择。
10.hadoop对put一个文件,集群发生了什么?
当在Hadoop集群中使用hadoop put命令上传一个文件时,以下事情会发生:
- 客户端将文件分割成多个数据块(根据文件大小和块大小确定)。
- 客户端将每个数据块加密并压缩。
- 客户端将加密后的数据块发送到集群中的一个节点(根据NameNode的调度)。
- 客户端同时发送文件的元数据(如文件名、长度等)到NameNode。
- NameNode接收到元数据后,将其存储在分布式文件系统(HDFS)的元数据文件中。
- NameNode根据数据块的哈希值将数据块映射到相应的DataNode。
- DataNode接收并存储数据块。
在这个过程中,Hadoop采用了分布式处理和数据冗余存储来提高数据可靠性和性能。
11.hadoop数据如何存储?
Hadoop数据主要通过分布式文件系统(HDFS)进行存储。HDFS是一个高度可扩展、容错能力强的分布式存储系统,适用于大规模数据存储。数据被分成多个块,分布在多个数据节点上,并采用冗余备份策略以确保数据可靠性。
存储过程简要如下:
- 将数据分成多个块。
- 将块分配到各个数据节点。
- 在数据节点上存储块数据。
- 每个数据节点保存数据的元数据(如文件名、块大小等)。
- 配置NameNode(主节点)来维护整个集群的文件系统 namespace 和元数据。
这种分布式存储方式使得Hadoop具有良好的扩展性和容错性,可以处理PB级别的数据。同时,Hadoop还支持其他存储方案,如HBase(基于列的分布式数据库)和MapReduce(分布式计算框架)。
12.UDF函数有哪些,工作原理是什么?
UDF(User-Defined Function)函数,即用户自定义函数,是在编程语言中由用户自己编写的一类函数。它们允许你在程序中执行特定的任务,根据输入的参数生成输出。
UDF函数的工作原理:
- 定义:首先,你需要定义一个函数,包括函数名、输入参数(可选)和返回值类型。
- 实现:接下来,编写函数体,即函数内部执行的代码。这段代码根据输入的参数(如果有)进行计算,并返回一个结果。
- 调用:在程序中,你可以通过调用 UDF 函数来执行自定义的任务。调用时,可能需要传递输入参数(如果有),然后函数会返回一个结果。
- 应用:UDF 函数可以应用于各种场景,如数据处理、算法实现、业务逻辑等。
不同编程语言中的UDF函数实现细节可能有所不同,但总体原理和工作方式类似。例如,在Python中,你可以使用以下方式定义和调用一个UDF函数:
def add(a, b):return a + bresult = add(1, 2)
print(result) # 输出:3
在Java中,你可以这样做:
public class Main {public static void main(String[] args) {int sum = add(1, 2);System.out.println(sum); // 输出:3}public static int add(int a, int b) {return a + b;}
}
总之,UDF函数是编程过程中非常有用的一种工具,可以帮助你实现自定义的任务和逻辑。
13.spark的driver和executor的理解
-
Spark的Driver:驱动程序,负责整个 Spark 应用的协调和调度。它主要包括两个部分:应用的主要入口点(如 main 方法)和集群管理器(如 YARN,Mesos 或 Standalone)。Driver 负责创建 Spark 上下文(SparkConf 和 SparkContext),启动集群管理器,并将其分配给 Executor。此外,Driver 还负责监控应用的进度和资源使用情况。
-
Spark的Executor:执行器,负责在集群中的各个节点上执行任务。Executor 由 Driver 启动,并为每个任务分配内存和 CPU 资源。Executor 运行在一个独立的 JVM 进程中,可以执行各种类型的任务,如计算任务(使用 Spark 核心 API)或行动任务(如数据处理和聚合操作)。Executor 还负责将任务的结果返回给 Driver。
总结:Driver 和 Executor 是 Spark 应用的两个关键组件,Driver 负责协调和调度,Executor 负责执行任务。它们共同协作,使 Spark 能够在集群中高效地处理大规模数据。
14.python的垃圾回收机制
Python的垃圾回收机制是通过引用计数和循环引用检测来实现的。
引用计数是一种简单而高效的垃圾回收机制。每个对象都有一个引用计数,当对象被引用时,引用计数加1;当对象不再被引用时,引用计数减1。当引用计数为0时,对象就会被销毁。
循环引用是指两个或多个对象之间相互引用形成的环状结构。Python的垃圾回收机制还会检测和处理循环引用,通过使用标记-清除算法来回收这些无法通过引用计数检测到的垃圾对象。
总结起来,Python的垃圾回收机制主要依靠引用计数和循环引用检测来自动回收不再被引用的对象,以减少内存的占用。
15.深拷贝和浅拷贝是什么?
深拷贝和浅拷贝是对象拷贝的两种方式。
浅拷贝是指创建一个新对象,然后将原对象的成员变量复制到新对象中。如果成员变量是引用类型,那么复制的是引用,而不是引用指向的对象。这种方式的缺点是,如果原对象和拷贝对象共享引用类型的成员变量,那么对其中一个对象的修改会影响另一个对象。
深拷贝是指不仅创建一个新对象,而且将原对象的成员变量以及成员变量指向的对象(递归地)都复制到新对象中。这种方式的优点是,原对象和拷贝对象是完全独立的,对其中一个对象的修改不会影响另一个对象。
总结:浅拷贝是复制原对象的成员变量,深拷贝是复制原对象及其成员变量指向的对象(递归地)。深拷贝比浅拷贝更耗时,但能确保原对象和拷贝对象之间的独立性。
16.如何复制一个python对象?
在Python中,可以使用copy模块的copy()或deepcopy()方法来复制对象。copy()方法仅复制对象的顶层结构,而deepcopy()方法则会递归复制整个对象。
例如,如果你有一个名为obj的对象,可以使用以下代码复制它:
import copy# 使用 copy() 方法
copied_obj = copy.copy(obj)# 或者使用 deepcopy() 方法
deep_copied_obj = copy.deepcopy(obj)
注意:copy()方法仅复制对象本身,而不复制对象中包含的其他对象。如果需要复制整个对象图,建议使用deepcopy()方法。
笔试题:
一个时间复杂度小于n^n的排序算法
快速排序(Quick Sort)。这是一种基于分治思想的排序算法,平均时间复杂度为O(n log n)。
以下是快速排序的Python实现:
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 示例
arr = [3, 6, 8, 10, 1, 2, 1]
print(quick_sort(arr))
执行结果:
[1, 1, 2, 3, 6, 8, 10]
快速排序在最好情况下(输入已经是升序或降序)的时间复杂度为O(n)。但请注意,在最坏情况下(输入是降序或升序),时间复杂度会上升到O(n^2)。不过,这种情况的概率非常低,因此在实际应用中,快速排序仍然具有较好的性能。
相关文章:

大数据研发工程师面试
文章目录 面试1.AUC,ROC,准确率与召回率都是怎么计算的?2.数据清洗是如何清洗的,要做哪些清洗的工作?3.什么是数据的完整性?4.数仓是怎么设计的?5.linux查看进程的命令是什么,如何查看具体某一行的内容(查看第n至m行࿰…...
【星海出品】云存储 ceph
https://ceph.com/en/ ceph组件介绍 Monitor 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。 OSD OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有…...

[nlp] grad norm先降后升再降
grad norm先降后升再降正常嘛 在深度学习中,梯度的范数通常被用来衡量模型参数的更新程度,也就是模型的学习进度。在训练初期,由于模型参数的初始值比较随机,梯度的范数可能会比较大,这是正常现象。随着模型的训练&…...

云积天赫AI全域营销系统,为品牌营销注入新活力
AIGC(生成式人工智能)的出现,标志着人工智能已经进入了一个全新的时代,它与传统的人工智能不同,可以更好地理解品牌的需求,并提供更精准的答案。目前,AIGC已经深入到各个领域,其中营…...

Arthas在线修改Java代码
Arthas在线修改Java代码 jad --source-only com.example.demo.arthas.user.UserController > /tmp/UserController.javamc /tmp/UserController.java -d /tmpretransform /tmp/com/example/demo/arthas/user/UserController.class参考链接: arthas retransform...

mapbox支持的坐标系
mapbox 中只支持 web墨卡托坐标系,不支持经纬度坐标系。 栅格数据 基于经纬度坐标系的栅格数据没有办法渲染。矢量数据 矢量数据代码中会自动转换成墨卡托投影坐标系再渲染。 输出坐标时候还是经纬度。...

腾讯云新客户优惠服务器88元/年,540元/3年,另有5年优惠服务器
在选择云服务器时,首先需要考虑的是性能与配置是否与自己的需求相匹配。对于小型网站或者个人博客,轻量应用服务器是一个不错的选择。腾讯云双十一活动中,2核2G轻量应用服务器的活动优惠价为88元/年,2核4G轻量应用服务器的活动优惠…...

伦敦银和美白银的关系
与黄金相似,世界上白银交易的基础就是伦敦白银市场,人们利用设立在伦敦的专们负责清算银行(与黄金的清算银行相同)所开设的账户进行白银保证金交易。在伦敦市场,以美元清算的伦敦白银价格,是以美元买进1金衡…...
Matplotlib的使用方法
Matplotlib是Python最著名的绘图库,它提供了一整套和Matlab相似的命令API,十分适合交互式地进行制图。而且也可以方便地将它作为绘图控件,嵌入到GUI应用程序中。Matplotlib能够创建多数类型的图表,如条形图、散点图、条形图、饼图…...
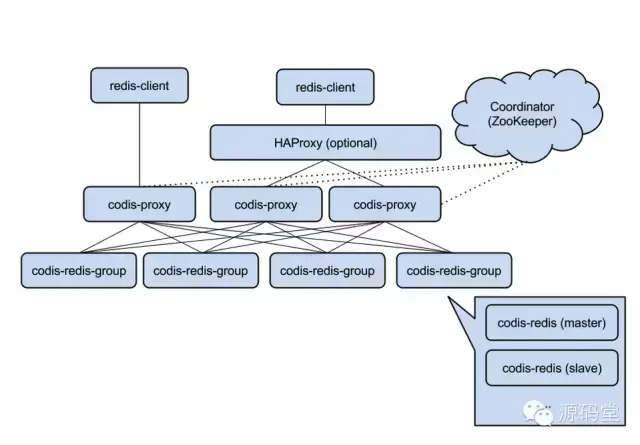
【入门篇】1.7 Redis 之 codis 入门介绍
文章目录 1. 简介2. Codis的安装与配置下载编译源码安装1. 安装 Go 运行环境2. 设置编译环境3. 下载 Codis 源代码4. 编译 Codis 源代码 Docker 部署 3. Codis的架构Codis的架构图和组件Codis的工作流程 4. Codis的核心特性自动数据分片数据迁移高可用性全面支持Redis命令分布式…...
【JavaEE】Servlet API 详解(HttpServlet类)
一、HttpServlet 写 Servlet 代码的时候, 首先第一步就是先创建类, 继承自HttpServlet, 并重写其中的某些方法 1.1 HttpServlet核心方法 1.2 Servlet生命周期 这些方法的调用时机, 就称为 “Servlet 生命周期”. (也就是描述了一个 Servlet 实例从生到死的过程) 1.3 处理G…...
微软宣布计划在 Windows 10 版本 22H2 中引入 AI 助手 Copilot
根据之前的传言,微软宣布计划在 Windows 10 版本 22H2 中引入 AI 助手 Copilot。Copilot 将包含在 Windows 10 家庭版和专业版中。该更新的发布日期尚未公布,但预计将在不久的将来发布。 在一份新闻稿中,微软表示在向 Windows 11 用户提供 Co…...

ubuntu 怎么安装图形界面
ubuntu 安装图形界面的方法,可以通过以下步骤操作来实现: 1、确认版本首先登录一下服务纯缺器ubuntu,查看系统版本。然后用root账号登录,如下图所示: 2、更新apt-get首先要先更新一下apt-get源,输入apt-g…...
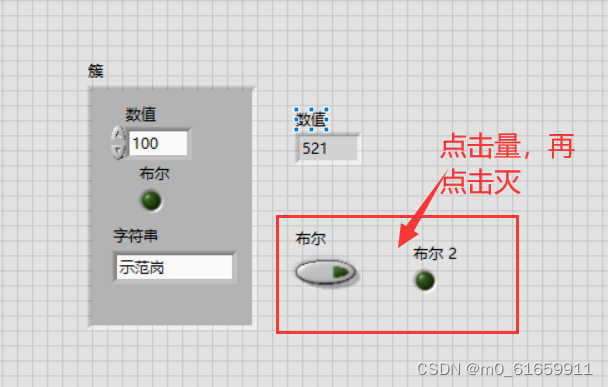
【LabVIEW学习】2.for,while,事件
1.for实例(随机输出数据100次) 结果: 2.while实例(i<50灯亮,大于之后灯灭) 结果:(先亮后灭) 3.事件结构的实例(点击按钮数据增加)事件监听应该…...

JVM bash:jmap:未找到命令 解决
如果我们在使用JVM的jmap命令时遇到了"bash: jmap: 未找到命令"的错误,这可能是因为jmap命令没有在系统的可执行路径中。 要解决这个问题,可以尝试以下几种方法: 1. 检查Java安装:确保您已正确安装了Java Development …...

基于单片机的温度控制器系统设计
**单片机设计介绍, 基于单片机的温度控制器系统设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机的温度控制器系统是一种利用单片机来检测环境温度并控制温度的系统。它通常由以下几个部分组成ÿ…...

oracle数据库中job和dbms_job比较
oracle中job和dbms_job比较 一、概述 Oralce中的任务有2种:Job和Dbms_job,两者的区别有: ①、Job是通过调用dbms_scheduler.create_job包创建的,Dbms_job则是通过调用dbms_job.submit包创建的。 ②、两种任务的查询视图都分为db…...

# Python基础:输入输出详解-读写文件(还需完善)
open() 返回一个 file object ,最常使用的是两个位置参数和一个关键字参数:open(filename, mode, encodingNone) f open(workfile, w, encoding"utf-8")第一个实参是文件名字符串。第二个实参是包含描述文件使用方式字符的字符串。mode 的值…...

【Spring】 Spring中的IoC(控制反转)
以往在定义业务层实现时,在指定具体地Dao时候需要具体地定义出其实现: public class BookServiceImpl implements BookService{private BookDao bookDao new BookDaoImpl();public void save(){bookDao.save()} }public class BookDaoImpl implements …...

playwright在vscode+jupyter中出现NotImplementedError问题
近期因个人需要接触playwright,由于playwright新接触,想用jupyter进行API测试学习。刚开始使用sync_playwright,在playwright的Conda运行环境中,以console模式和单文件直接运行模式,都能正常运行。但是进入jupyter中后…...

Wan2.2-I2V-A14B实战案例:地方政府生成‘乡村振兴’政策解读动画短视频系列
Wan2.2-I2V-A14B实战案例:地方政府生成乡村振兴政策解读动画短视频系列 1. 项目背景与需求分析 近年来,随着数字政务的快速发展,各级地方政府越来越重视利用新媒体技术进行政策宣传。某地方政府计划开展"乡村振兴"系列政策解读工…...

C++数组和指针的声明与使用指南
数组声明语法 在 C 中声明数组的语法为: 数据类型 数组名[数组大小]; 示例: int myArray[10]; // 声明一个包含 10 个整数的数组 数组初始化 声明时可直接初始化: int myArray[5] {10, 20, 30, 40, 50}; 部分初始化时,未指定值的…...

良久团购报单查单小程序开发
需求分析与规划 明确小程序的核心功能:报单(提交订单)、查单(查询订单状态)、团购管理(商品展示、拼团进度)。 确定用户角色:普通用户(参与团购)、管理员&…...
)
CasADi实战:用Python搞定机器人路径规划中的数值优化问题(附IPOPT配置)
CasADi实战:用Python搞定机器人路径规划中的数值优化问题(附IPOPT配置) 机器人路径规划的核心在于如何在复杂环境中找到一条既安全又高效的轨迹。这本质上是一个带约束的数值优化问题——我们需要最小化某种代价函数(如路径长度或…...

超轻量级OpenClaw与LaTeX结合:学术文档自动化处理
超轻量级OpenClaw与LaTeX结合:学术文档自动化处理 科研工作者每天需要处理大量的文献整理、公式编辑和文档排版工作,传统手动方式耗时且容易出错。本文将展示如何用超轻量级OpenClaw实现学术文档的自动化处理,让LaTeX文档编写变得轻松高效。 …...

告别天价桥接芯片!用高云GW5AT-LV15MG132 FPGA搞定MIPI C-PHY摄像头测试盒
国产FPGA革新摄像头测试方案:高云GW5AT-LV15MG132的MIPI C-PHY实战解析 在摄像头模组生产线上,测试环节的成本与效率直接关系到企业竞争力。传统测试方案依赖进口FPGA搭配昂贵桥接芯片,不仅物料清单(BOM)成本居高不下…...
)
告别复制粘贴!用Qwen Code在终端里直接重构500行烂代码(附真实项目截图)
告别复制粘贴!用Qwen Code在终端里直接重构500行烂代码(附真实项目截图) 接手一个满是技术债的项目,就像走进一间多年无人打扫的仓库——到处是随意堆放的代码、重复的逻辑、难以理解的函数命名。更糟的是,传统的AI辅助…...

不会画画也能创作!梦幻动漫魔法工坊新手入门全攻略
不会画画也能创作!梦幻动漫魔法工坊新手入门全攻略 1. 为什么你需要这个工具 你是否曾经有过这样的经历:脑海中浮现出一个绝妙的动漫角色形象,却因为不会画画而无法将它呈现出来?或者想为社交媒体创作独特的二次元头像ÿ…...

半导体制造中的ProcessJob与Control Job:从定义到实战避坑指南
半导体制造中的ProcessJob与Control Job:从定义到实战避坑指南 在半导体制造的高精度世界里,每一片晶圆的流转都像一场精密编排的交响乐。而ProcessJob(PJ)和Control Job(CJ)就是这场演奏中不可或缺的指挥…...
选型指南)
Web3D开发入门:5大引擎(Direct3D、OpenGL、UE、Unity、Three.js)选型指南
Web3D开发入门:5大引擎选型实战指南 当虚拟展厅、数字孪生和元宇宙应用席卷各行业时,选择合适的三维引擎成为开发者面临的首个关键决策。本文将带您深入剖析Direct3D、OpenGL、Unreal Engine、Unity和Three.js五大主流方案的技术特性与商业价值ÿ…...